
基于BERT 模型的方面级情感分析
2023-08-19 09:59李壮李鸿燕
电子设计工程 2023年16期
李壮,李鸿燕
(太原理工大学信息与计算机学院,山西 晋中 030600)
方面级情感分析[1]是针对给定文本的特定方面进行细粒度情感分析的任务,是情感分析领域[2]中的重要分支。传统机器学习方法依赖于人工特征提取的质量,导致分类精度较低。近年来,深度学习凭借良好的特征提取能力,在该领域中得到广泛应用[3-5]。经研究,注意力机制可有效提升情感分类效果[6],因此成为该领域的常用方法[7-9]。Li[10]等人发现对输入信息进行加权处理,可有效提升方面级特征提取能力。此外,相关学者提出GPT[11]和ELMO[12]提升分类效果,但两种模型均需大量人工标注数据集进行训练。He[13]等人则利用迁移学习将文档级知识转移到方面级情感分类任务中,并有效提升分类精度。然而,以上研究均未考虑到该领域数据集较少,且目前工作迁移层次不够深的问题。为了丰富方面级数据的获取形式并提高分类精度,文中提出了BERTDTL-HAN 模型,该模型结合层次注意力网络[14],可以将同领域句子级别的情感知识深层次迁移[15]到方面级任务中,通过与基准模型进行对比实验,证明该方案的可行性和有效性。
1 BERT-DTL-HAN模型
1.1 模型结构
文中提出的模型是基于BERT[16]作为预训练模型,结合深度迁移学习(Deep Transfer Learning,DTL)方法和层次注意力网络(Hierarchical Attention Networks,HAN)的细粒度情感分析模型。BERTDTL-HAN 模型结构如图1 所示。
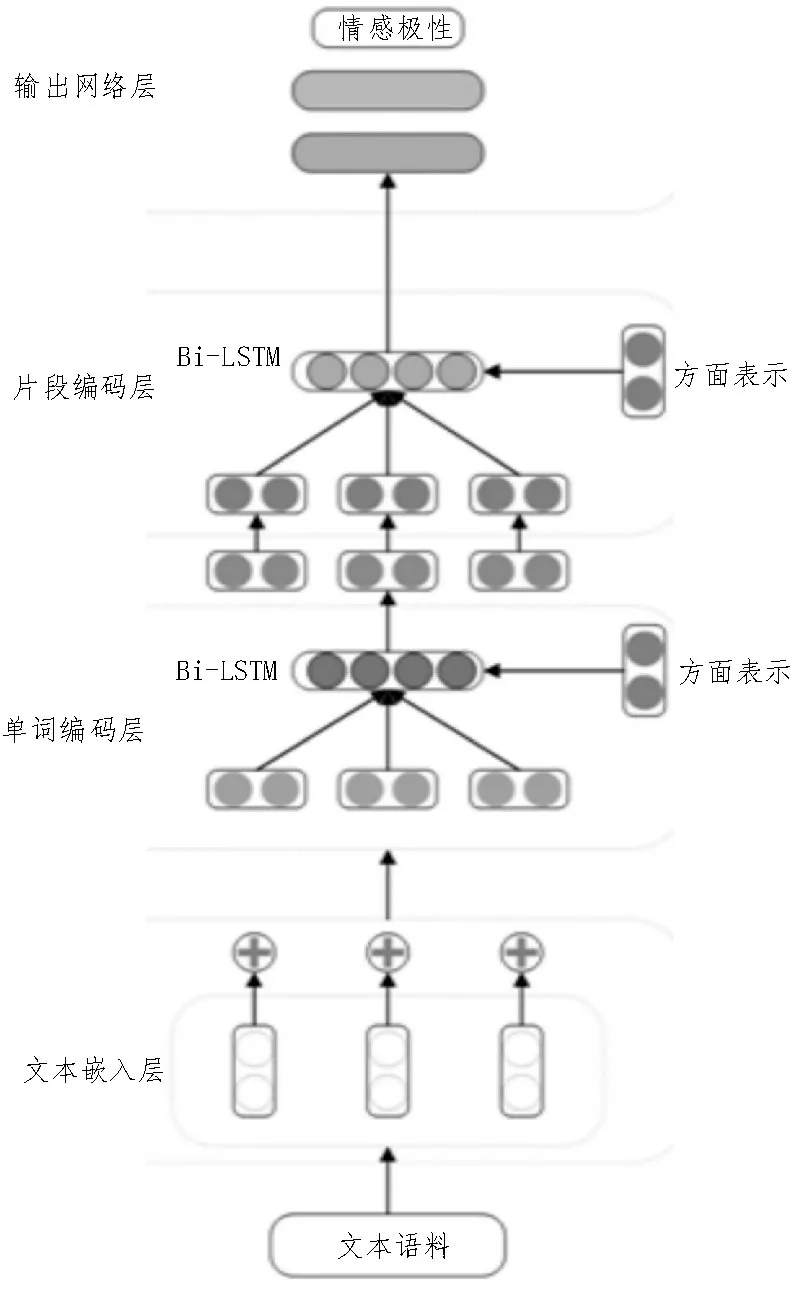
图1 BERT-DTL-HAN模型结构图
模型包含四个部分,分别为基于BERT 模型的文本嵌入层、进行深层次迁移学习的单词编码层和片段编码层,以及进行情感极性分类的输出网络层。
1.2 文本嵌入层
文本嵌入层将输入的文本语料转换为深度学习模型输入的词向量的数学形式,并进行中文语料预处理的工作。
传统语言模型如独热编码和Word2Vec,仅可实行单向特征提取,且特征向量维度单一。为了解决传统的词嵌入方法不能很好地表征深层次的字词向量信息,文中引入了图2 所示的BERT 模型,该模型可以进行词义向量、分段向量和位置向量三个维度的特征提取,且采用双向Transfoemer 结构获取上下文特征信息。
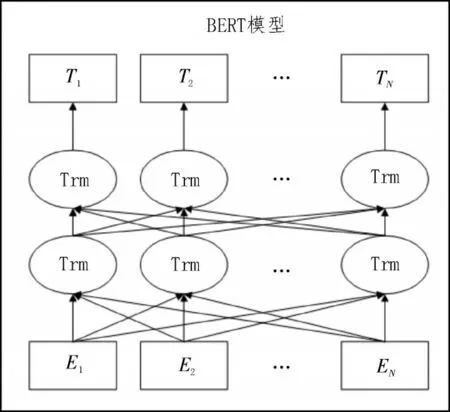
图2 BERT模型图
以“My dog is cute”为例句,其词向量、分段向量和位置向量三个维度的向量信息如图3 所示。
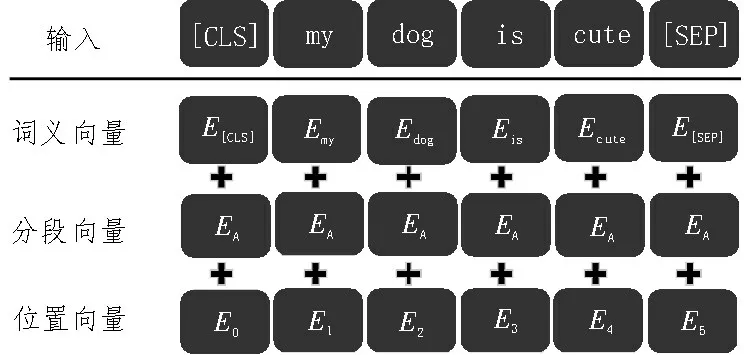
图3 BERT模型输入图
三个维度大小相同,其中位置向量是通过三角函数对输入文本中各个位置分别进行编码得到的,计算公式如下式:
式中,pos 表示第pos 个词,i表示在词向量嵌入模型中的第i维。
文本嵌入层通过BERT 模型进行预训练时,序列长度被控制在BERT 能处理的最大序列长度512以内,其中长度不足512 的用0 填充,以方便进行模型进行矩阵运算。
1.3 单词编码层
单词编码层采用双向长短时记忆网络(Long Short-Term Memory,LSTM)编码,该网络包含前向LSTM 和后向LSTM,可以从单词层面的两个方向读取方面级的特征信息。单词编码层将句子级别的特征信息深层迁移到单词层面。正向LSTM 建模定义为,后向LSTM 建模定义为,总建模为hit,建模的具体公式如下:
其中,xij表示输入文本中第i个句子中第j个单词的编码信息,θLSTMw表示用于单词编码器的LSTM的参数。
单词层次注意力机制的构建公式如下:
式中,Kit为权重参数,Rit为偏置参数,uw为单词编码模型学习得到的向量,oi为单词编码层的输出。
1.4 片段编码层
片段编码层也采用双向LSTM 架构,实现对片段层次的特征信息的双向编码。片段编码层将句子级别的特征信息深层迁移到片段层面。片段编码器的正向建模定义为,后向建模定义为,总建模定义为hi。建模的具体公式如下。
其中,xij表示输入文本中第i个句子中第j个片段的编码信息,θLSTMw表示用于片段编码器的LSTM 的参数。
片段层次注意力机制的构建公式如下:
式中,Wi为权重参数,bi为偏置参数,us为片段编码模型学习得到的向量,S为片段编码器注意力层输出。
1.5 输出网络层
输出网络层采用全连接和softmax 函数进行情感分类和归一化处理,模型的最终输出向量为Z,公式如下:
式中,W为权重参数,b为偏置参数。
采用Adam 优化方法进行参数更新,并使用最小化交叉熵损失函数作为目标函数优化模型的情感分类效果,公式如下:
式中,B为训练集的数据量,L为情感具体分类的个数,实验中数据量的大小为3,为预测类别数,y为实际类别数,φ‖θ‖2为交叉正则项。
2 实验结果与分析
2.1 实验数据集
文中采用了三个领域的公开数据集,分别为餐馆(Restaurant)评论数据集和笔记本电脑(Laptop)数据集以及推特(Twitter)数据集,数据集被划分为训练集和测试集,具体数据如表1 所示。
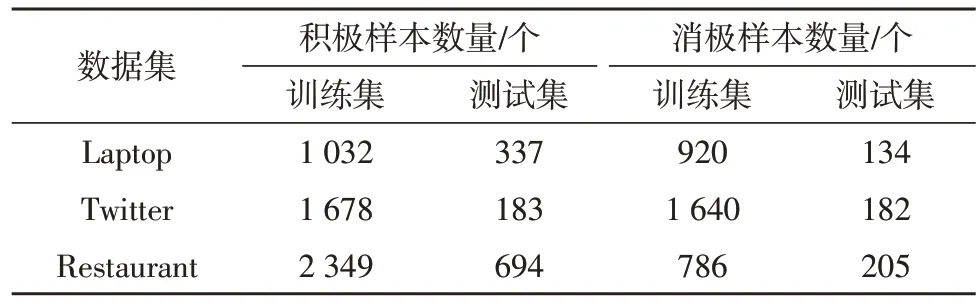
表1 实验数据集
2.2 评价指标
实验的评估标准采用二分类问题中常用标准ACC(Accuracy,准确率)和F1 值。其中ACC 标准计算的是正确分类样本数占总样本数的比例,计算公式如下:
F1 值为精确率和召回率的调和均值,两者公式换算如下:
其中,TP 为模型预测为积极情绪,样本本身为积极情绪的样本个数;TN 为模型预测为消极情绪,样本本身为消极情绪的样本个数;FP 为模型预测为积极情绪,但样本本身为消极情绪的样本个数;FN为模型预测为消极情绪,但样本为积极情绪的样本个数。
2.3 实验环境
文中实验具体的环境如表2 所示。
表2 实验环境
2.4 实验过程
将文中提出的BERT-DTL-HAN 模型在三个领域的数据集中与七个基准模型进行广泛性实验。
为验证单词编码层和片段编码层深层迁移学习的有效性,采用准确率和F1 值作为评价指标。文中分别对无迁移学习、只迁移单词层面、只迁移片段层面和单词级别以及片段级别均迁移四种情况进行了对照实验,实验结果如表3 所示。
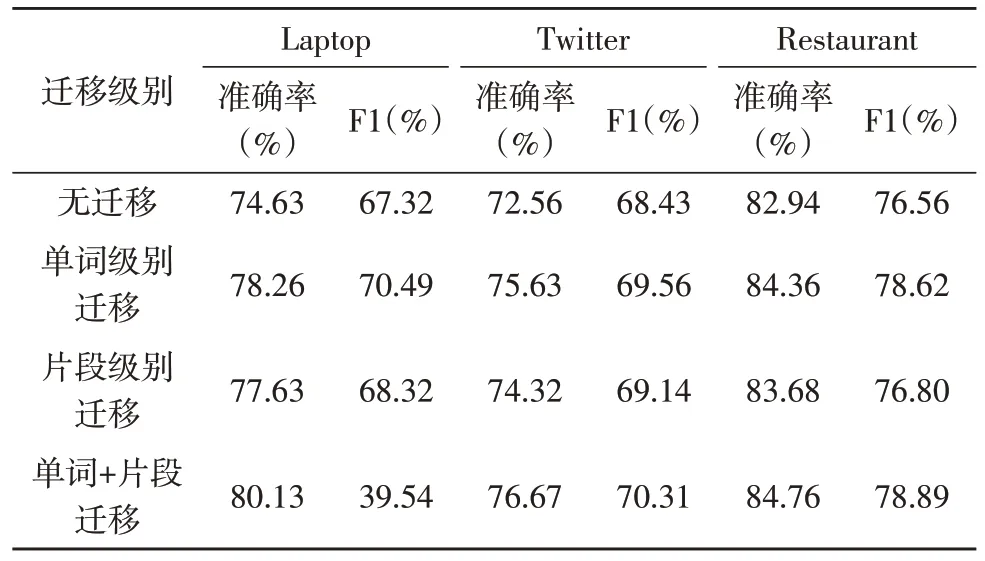
表3 不同迁移级别的实验结果
为了研究模型情感极性分类的有效性,设置七组模型进行性能对比,相关的基准模型均为方面级情感分析任务常用模型,文中提出的模型与各个基准模型在三个领域数据集中的准确率数据记录如表4 所示。
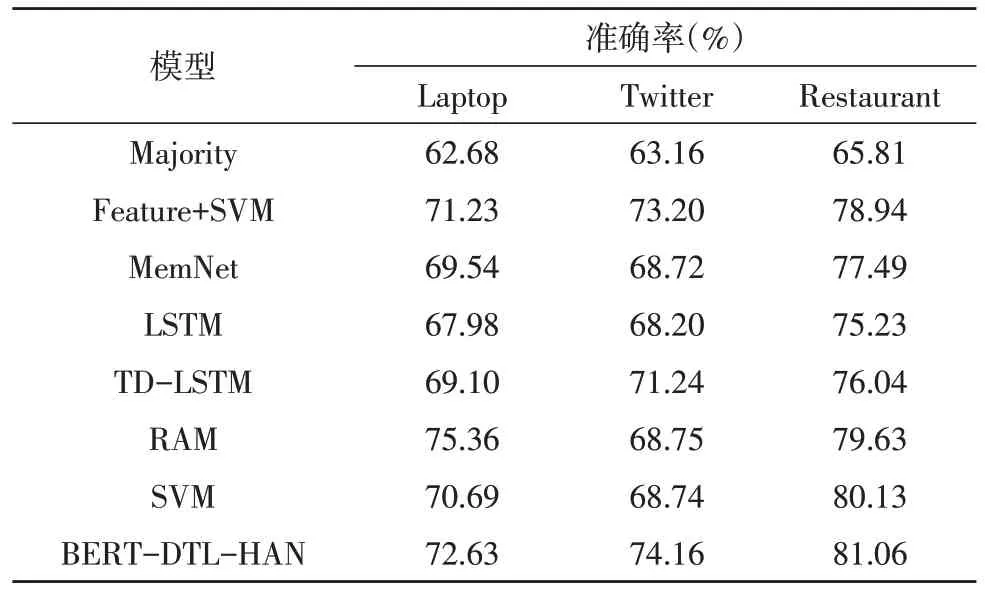
表4 准确率实验结果对比
2.5 实验结果
表3 实验结果表明,在三个领域的数据集中,进行单词级别或片段级别深层迁移学习的模型准确率和F1 值均优于无迁移的模型。相比较于片段级别迁移,单词级别对模型的准确率提升更为明显,其中单词+片段迁移(全迁移)模型的情感分类效果最好。该实验证明了结合深层次迁移学习和层次注意网络机制将数据量大的句子级别情感分析数据集迁移到数据量小的基于方面级情感分析任务中的可行性和有效性。
表4 实验结果表明,BERT-DTL-HAN 模型在三个数据领域中相较于七个基准模型都取得了最好的实验结果。在笔记本电脑评论语料数据集中,相对于基准模型中最优结果模型Feature+SVM,准确率提升了1.40%;在推特评论语料数据集中,相比较于基准模型中的最优结果模型Feature+SVM 模型,其准确率提升了0.96%;在餐馆评论数据集中本模型的效果相较于基准模型的最优结果SVM 模型的80.13%提升了0.93%。
3 结束语
针对由于数据集偏小且特征提取不足而导致方面级情感分析分类效果不佳问题,文中构建了一种BERT-DTL-HAN 模型,模型首先通过BERT 进行预处理获得多维度的词向量信息,再通过深层次迁移学习将数据量丰富的句子级别信息迁移到数据量较小的方面级情感分析任务中,最后通过层次迁移网络增强对方面级特征信息的提取。实验结果表明,该模型有效解决了基于方面级情感分析任务中数据量小和方面级特征获取不足的问题,其分类精度也优于对比实验中的一众基准模型。
在后续的工作中,将会尝试进一步增强深度迁移学习的维度来更高效地丰富基于方面级情感分析的数据集并进一步优化模型的分类效果。
猜你喜欢
基层中医药(2021年8期)2021-11-02
北京大学学报(自然科学版)(2021年3期)2021-07-16
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
电子制作(2019年13期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
家庭影院技术(2018年5期)2018-06-29
