
基于Scrapy-redis 的网站敏感信息监测系统设计与实现
2023-08-16 05:01杨秉杰
无线互联科技 2023年11期
杨秉杰,薛 钰
(国家计算机网络与信息安全管理中心河南分中心,河南 郑州 450000)
0 引言
随着互联网的飞速发展,社会的发展已经与互联网密不可分,网络安全的重要性日益凸显。 近年来,大规模的数据泄露事件频频发生,敏感信息泄露问题已经成了一个全球性的问题,在全球范围带来的损失与造成的影响与日俱增。 根据相关机构研究报告显示,2022 年第一季度全球范围内发生35 起影响较大的已公开信息泄露事件,数据泄露规模超过17 TB,敏感信息泄露涉及人数近9 000 万人,涉及行业包括政府、金融、能源、交通、医疗等[1]。 造成敏感数据泄露频发的原因主要有两方面:一是来自外部的网络攻击形势日益严峻,攻击者为了获取利益持续针对重点目标进行网络攻击,进而窃取单位内部敏感数据;二是内部员工缺乏安全意识,在工作中无意识进行了错误的系统配置或将未经审核的信息发布,造成敏感数据信息的非授权访问等问题。 本文提出了一种基于爬虫技术的网站敏感数据信息监测系统,利用Scrapyredis 框架定时对目标网站进行全量爬取,通过非授权URL 地址库构造URL,检测系统或网站是否存在敏感信息未授权访问,通过敏感信息检测规则对爬取结果进行分析,检测网站内容是否存在敏感数据信息泄露。
1 Scrapy-redis 框架工作原理
1.1 Scrapy 框架
Scrapy 框架是一个开源的Python 爬虫框架,主要用于抓取网站和提取结构化数据,广泛地用于数据挖掘、信息处理或历史存档等。 它可以处理从网页爬取数据到处理HTML、XML、JSON 等各种格式的数据。Scrapy 框架采用Twisted 异步网络库,可以高效地处理异步IO 操作,支持并发、分布式爬取等多种高性能扩展,经常被用于构建大规模的爬虫项目[2]。
1.2 Scrapy-redis 框架
Scrapy-redis 框架是在Scrapy 框架基础上进行扩展的一种分布式爬虫框架,它将Scrapy 框架的爬取、解析、存储等功能与Redis 分布式队列相结合,实现了高效、稳定的分布式爬取。 其重要特点包括5 个方面:(1)框架基于Redis 的分布式队列管理,支持多个爬虫节点同时抓取同一个网站,提高了爬取效率和速度。 (2)框架支持断点续爬,即在网络或程序异常中断后能够自动恢复爬取任务。 (3)框架支持分布式爬取过程中的数据去重,避免重复爬取。 (4)框架支持对爬取结果进行持久化存储,支持多种数据存储方式,如MySQL、MongoDB、Redis 等。 (5)框架支持自定义的中间件和扩展,方便进行各种自定义功能的开发和集成[3]。
2 系统设计
2.1 功能设计
网站敏感信息监测系统主要包含以下4 个功能模块:定时任务模块、非授权检测模块、网络爬虫模块、数据分析与存储模块。
2.2 定时任务模块
用户通过配置定时任务,完成对目标网站的持续监测。 用户需要配置爬虫任务,定义爬虫初设页面(start_urls)和爬虫作用域名范围(allowed_domains)。用户配置添加定时任务。 其中,爬虫任务ID 与爬虫任务进行关联。 系统将根据定时任务启动频率(cron表达式)和最后启动时间(last_start_time)定时启动关联的爬虫任务。
2.3 非授权检测模块
根据已有知识配置可能造成非授权的URL 地址库,构造非授权检测URL,用于检测网站非授权访问情况。 非授权URL 地址库是根据互联网情报、知识积累等方式获得的,并不断进行更新增加的知识库。其记录的是可能存在非授权访问情况的URL,比如管理员会无意间将备份文件(. bak)和配置文件(.settings)放在网站目录下造成非授权访问,还有一些网站配置不当导致目录列出问题(如Upload、Edit、phpinfo 目录),造成网站敏感配置信息或数据信息泄露。 URL 地址库规则如“admin. {}”“Info. {}”“css.{}”等。 非授权检测是根据域名启动检测的。 爬虫过程中,系统持续获取爬虫队列中URL 对应的域名,当发现队列中存在未曾检测的域名时,启动非授权检测模块,将当前域名与非授权URL 地址库按照规则构造检测URL 并发送给爬虫队列进行检测,数据分析与存储模块将根据爬虫结果判断是否存在敏感信息泄露情况。 在发送构造检测URL 给爬虫队列后,系统会在request 请求时传递泄露类型参数(re_type),告知数据分析与存储模块此爬虫队列是在进行非授权检测[4]。 如果构造的检测URL 访问不存在,则该队列任务将直接结束,不进入数据结果分析。
2.4 网络爬虫模块
启动网站爬取任务,按照递归方式,完成站点所有页面的爬取。 网络爬虫模块主要利用Scrapy-redis框架实现针对目标网站的爬取。 该框架是在Scrapy框架基础上,加入了Redis 分布式队列支持的爬虫框架。 网络爬虫模块的功能如下:(1)引擎主要处理整个系统的数据流,触发对应的事务。 (2)调度器模块负责分发爬虫的请求,并使用Redis 的Sorted Set 数据结构来管理爬取请求,并使用Redis 的Key-Value 数据结构来管理已爬取的URL 集合。 一方面调度器模块从引擎接收新提取的URL 任务请求,将其压入Redis 队列中;另一方面当引擎请求爬取时,调度器模块根据爬取优先级从Redis 中抽取URL 链接,返回给引擎启动爬取任务。 调度器模块在从Redis 队列中抽取URL 时,使用Redis 的Set 数据结构来管理已经爬取过的URL,在调度时利用DupeFilter 防止重复爬取。 (3)队列处理模块主要进行爬取URL链接管理,供爬虫使用。 Scrapy-redis 框架使用Redis 存储需要爬取的URL,可以多个爬虫实例共享同一个队列,实现系统的分布式爬虫。 (4)下载器模块:接收调度器下发的请求,获取下载URL 的Response 数据。 (5)爬虫模块:接收下载器下载到的HTML 页面,通过Xpath 表达式和正则表达式提取网页中的数据。
此外,系统采用递归式爬取方式,即每次下载器获取到Response 数据后提取所有链接压如爬虫队列,由系统进行URL 去重操作,删除已经爬取的URL。Scrapy-redis 去重主要使用request_fingerprint 接口的Request 指纹计算和布隆过滤器实现。
2.5 数据分析与存储模块
根据下载器模块提供的Response 数据进行数据结果分析,利用敏感信息检测规则库判断Response 中是否存在敏感信息,并将结果存入MySQL 数据库中。当Response 获取的数据为Word、PDF 等文件,则需要借助Python-docx、PyPDF2 等第三方库类完成文件读取,获取内容信息后再进行分析。
系统在进行结果数据分析和数据存储时需要花费一定的时间,若使用同步方式处理,则造成线程的堵塞,影响系统的性能。 为了提高系统性能,系统采用异步方式进行数据分析及存储,其方法是构造自定义pipeline 实例ProcessTwistedPipeline, 通过使用Twisted 框架实现异步处理和存储。
敏感信息检测规则库:用户可通过正则匹配等方法配置敏感信息检测规则,用来检测下载结果中是否存在敏感信息。 比如:检测页面中是否存在身份证号、手机号等敏感信息,检测网页源代码中是否存在password、Secret_Key 等敏感代码,检测规则如:身份证号检测((([1-9] d{5}(19|20) d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)d{3}[0-9Xx])|身份证|身份证号|证件号))、手机号检测(((13[4-9]|14[7-8]|15[0-27-9]|178|18[2-47-8]|198|13[0-2]|14[5-6]|15[5-6]|166|17[5-6]|18[5-6]|133|149|153|17[37]|18[0-19]|199|17[0-1])[0-9]{8}))等。
3 系统实现
系统流程如图1 所示,(1)根据初始URL 初始化队列,启动网络爬取模块开始进行数据爬取。 (2)队列获取目标URL,通过检测去重,发送给下载器下载网页。 同时,从目标URL 提取域名信息,如果判断为新增域名,则同时启动非授权检测模块,根据字典构造检测URL 加入队列。 (3)下载网页完成后,提取页面所有有效链接,重新加入爬虫队列,同时下载的页面结果发送给数据分析和存储模块处理。 (4)数据分析和存储模块根据检测规则,进行敏感信息泄露检测,并将结果存入数据库。
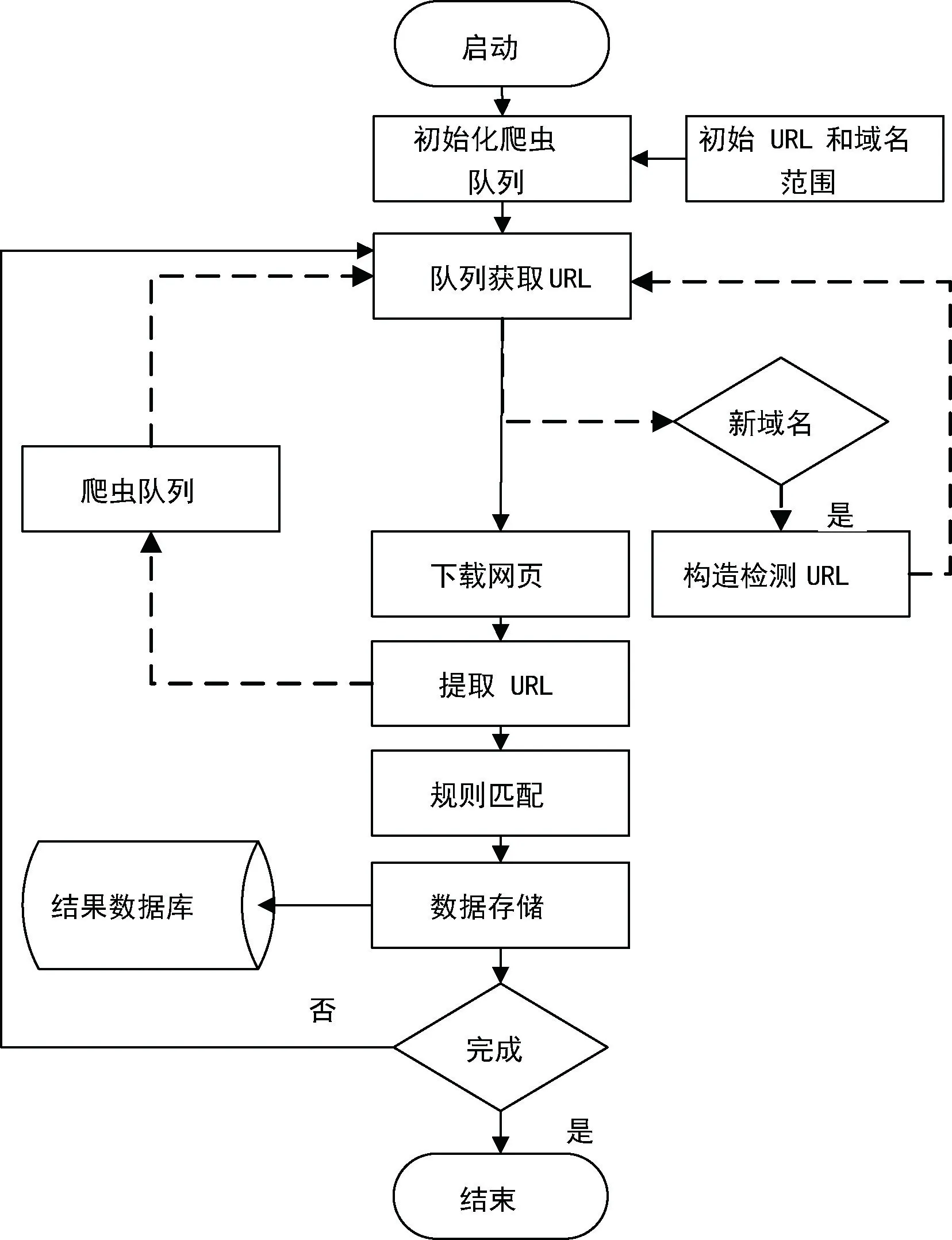
图1 系统流程
系统测试部署在3 台主机上(配置均为Intel Core i7-7500U CPU 2.7 GHz 2.90 GHz,32 G 内存),模拟监测郑州大学敏感信息泄露情况。 配置起始URL为:www. zzu. edu. cn,配置域名作用范围为zzu. edu.cn,运行24 h,获取网站页面信息约20 万条,发现存在手机号泄露页面3 102 个,邮箱泄露页面5 138 个,部分数据如图2 所示。
4 结语
本文提出一个基于Scrapy 的网站敏感信息监测系统设计方案,通过实验可以发现系统单日采集分析处理页面约为20 万条,系统性能满足要求。 根据敏感信息检测规则库,系统能够发现存在手机号或邮箱账号泄露的页面,达到系统预期的功能要求。 本文设计的系统具有一定的扩展性,用户可根据需要增加非授权检测URL库和敏感信息检测规则库,后续在实际使用中,仍需进一步扩充相应的规则,达到更好的监测效果。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
保健医苑(2022年1期)2022-08-30
现代信息科技(2021年21期)2021-05-07
小学生学习指导(低年级)(2020年4期)2020-06-02
军营文化天地(2018年2期)2018-12-15
电子测试(2018年1期)2018-04-18
产品可靠性报告(2017年7期)2017-09-05
电子制作(2017年9期)2017-04-17
网络安全技术与应用(2011年3期)2011-03-14
河北软件职业技术学院学报(2010年3期)2010-06-06
