
针对情境感知的自然语言的因果去偏推理方法
2023-08-15 02:53张大操
计算机研究与发展 2023年8期
张大操 张 琨 吴 乐 汪 萌
1 (合肥工业大学计算机与信息学院 合肥 230027)
2 (大数据知识工程重点实验室(合肥工业大学)合肥 230027)(zhdacao@gmail.com)
自然语言推理(natural language inference, NLI)是自然语言处理研究中的一个基础但重要的研究任务.该任务要求模型能够准确理解并分析前提句子和假设句子之间的语义推理关系,即蕴含(entailment)、矛盾(contradiction),或者中立(neutral),是文本表示的一个典型应用,对信息检索、问答系统、对话系统等领域的发展有着重要的研究意义和应用价值[1-2].
伴随着深度学习,特别是预训练语言模型的迅速发展,大量针对自然语言推理的相关工作被提出并取得了突出成绩[3-5],甚至在一些数据集上的表现超越了人类[6].与此同时,有研究指出现有的语义推理模型在很大程度上利用了数据中的虚假关联,并未真正理解输入句子的语义表示,导致模型在实际应用中存在泛化能力差的问题.如图1所示,训练集中存在大量词汇重叠的蕴含样本,但是大量词汇重叠的语言偏见并不能作为判断蕴含关系的特征,如果模型对该语言偏见过度依赖,就会对测试集中存在词汇重叠但关系为矛盾的样本做出错误的判断.文献[7-8]利用一些启发式的方法生成了一些不包含虚假关联的测试集,验证了现有模型在语义推理时存在对语言偏见高度依赖的问题.文献[9-10]通过仅使用假设句进行训练和推理,发现预测效果远高于随机猜测,从模型的角度证明了假设句子和标签之间的虚假关联会导致模型的语义表示学习有偏.因此,如何有效缓解数据中的语言偏差对模型语义表示学习及推理的影响成为当前自然语言推理研究的一个热点问题.
在去偏自然语言推理研究中,结合因果推断(causal inference)实现无偏学习是一个非常具有潜力的研究方向[11].通过识别、区分观测数据中的虚假关联,因果推断方法能够缓解模型对这些虚假关联的依赖,其中反事实推理就是一种代表性的研究手段.例如自然语言推理中针对模型依赖假设句的语言偏见,反事实推理会假设:“如果模型只看到假设句子,模型的预测结果是什么”.通过对比模型在真实世界中观测到完整数据的预测结果以及在反事实世界中观测到假设句子的预测结果,模型对假设句中语言偏见的依赖就能够被有效缓解.在该方向上,研究人员已经进行了初步的尝试.从数据角度,文献[7-8,12-14]通过生成反事实的样本消除数据中存在的语言偏差,保证模型学习的无偏数据基础.从模型角度,文献[15]通过反转假设句反向传播的梯度,阻止编码器学习到假设句所带来的有偏信息;文献[16]通过比较样本与反事实样本之间的差异和它们的预测结果之间的差异让模型学会利用反事实的思维去进行预测;文献[17-18]则从传统预测结果的有偏性出发,通过在预测时减去文本所带来的有偏信息,从而实现无偏推理.
虽然这些文献工作[7-8,12-18]已经取得了一定的效果,但仍存在一些不足.具体而言,文本语义表达存在多义、歧义、模糊等问题,引入情境信息是保证文本语义准确表示的一种代表性方法.如图2所示,针对相同的前提句和假设句,不同的情境信息能够明确句子的语义表示,从而导致2个句子之间的语义推理关系出现不同,体现了情境信息在自然语言推理建模过程中的重要性和必要性.文献[19]也指出情境信息对文本语义表示与推理的必要性,同时文献[20]提出了一种全新的情境感知的自然语言推理任务,通过为文本句子提供图像情境信息,研究更符合应用场景的自然语言推理.因此,在去偏自然语言推理研究中同样需要充分考虑情境信息.然而,情境信息的引入会为自然语言推理带来更多的挑战.情境信息与文本句子之间是否存在虚假关联,情境信息是否有助于缓解语言偏见对模型的语义表示学习的有偏影响,这些都是情境感知的无偏自然语言推理所必须解决的问题.

Fig.2 Different contextual information leads to different relationships图2 不同情境信息导致关系不同
为了解决这些问题,我们通过融合因果推断方法,提出了一种全新的因果去偏推理方法CBDRM(causal-based debiased reasoning method),用于缓解模型在文本语义表示及自然语言推理中语言偏见所带来的有偏影响.具体而言,先使用预训练模型在原始数据集上微调得到一个有偏模型,将这个模型的预测结果视为输入数据对标签的总因果效应;然后通过添加仅将假设句作为输入的额外支路来捕获数据集中的假设句带来的语言偏见,利用因果反事实方法将其建模为语言偏见所导致的直接因果效应;最后通过从总因果效应中减去语言偏见导致的直接因果效应,得到去偏之后的预测结果.此外,为了进一步提高模型对情境信息的理解,本文设计了一个对比学习模块,让模型在推理时充分考虑图片情境信息来缓解语言偏见,提高模型的无偏推理性能.然后在自然语言推理、视觉蕴含(visual entailment, VE)任务和情境感知的自然语言推理(grounded text entailment, GTE)任务上进行了大量充分的实验,用于证明本文所提出方法的有效性.同时,还为情境感知的自然语言推理任务构造了一个无偏的挑战测试集,并将相关测试集数据公开,以促进相关研究的发展.
本文的贡献主要包括:
1)提出情境信息对无偏自然语言推理有着重要的影响作用,并将因果推断相关技术引入到情境感知的无偏自然语言推理建模中.
2)提出一种全新的因果去偏推理方法CBDRM,用于去除语言偏见,实现更高质量的情境感知的无偏自然语言推理.
3)在公开的数据集上进行了大量的实验,充分验证了模型的有效性,同时构造并公开了一个无偏的情境感知的自然语言推理挑战集,以丰富该领域的相关研究.
1 相关工作
本节将介绍与情境感知的无偏自然语言推理相关的研究工作,主要分为因果推断方法、情境感知的自然语言推理、基于对比学习的语义表示方法.
1.1 因果推断方法
近年来在文本去偏方向的研究工作有很多,这些方法主要可以分为2类:一类从数据集的角度出发,致力于去除数据集中存在的语言偏见,从根源上解决问题;另一类则从模型的角度出发,通过隐式或显式的方式去除学习到的语言偏见.这2类方法各有优缺点.
首先,第1类方法都是从数据集角度考虑生成一些新的样本来缓解原数据集中的语言偏见.文献[7-8, 12]通过统计自然语言推理数据集中假设句的生成方式来推测偏差来源,然后设计了独特的启发式的方式生成新的样本;文献[13]通过人工以最小的扰动修改前提句或假设句,生成与原样本关系不同的反事实样本;文献[14]通过人类与模型对抗的方式让人类合成可以欺骗模型的样本.通过将这些生成的样本与现有数据集里的样本融合,让模型取得更好的效果.但是这些基于数据的方法也有一些不足,例如自动生成的方式并不能涵盖所有类型的偏差,同时人工标注的方式面临成本过高的问题.
其次,从模型角度考虑的方法也有很多.文献[15]通过增加一个仅使用假设句作为输入的支路来学习假设句所带来的偏差,然后在梯度回传时将梯度反向以抑制模型学习到有偏信息;文献[16]利用向量的正交分解思想,从样本中分解出只和上下文有关的分量,再通过分量合成反事实样本,综合比较样本之间的差异以及预测结果之间的差异实现反事实推理;文献[21]在视觉问答(visual question answering,VQA)任务上通过增加仅假设支路来缩小容易分类的样本损失,放大需要多模态信息才能分类正确的样本损失来强迫模型学习多模态信息.这些基于模型的方法虽然避免了高成本的标注问题,也取得了一定的效果,但是它们大多依赖于精巧的平衡策略的设计,可解释性也比较差.因此另一些基于结构因果模型(structural causal model,SCM)的方法也逐渐被提出.文献[17]通过构建VQA任务的因果模型,将VQA任务中的语言偏见视为直接因果效应,通过从总的因果效应中减去文本的直接因果效应,得到去偏之后的间接因果效应,然后进行预测;文献[18]关注文本分类任务中的标签偏差和关键词偏差,把它们视为混杂因素,并将它们从句子中蒸馏出来,通过使用有偏的预测结果减去偏差,得到去偏之后的预测结果.这些基于因果模型的方法有着比较完备的理论基础[22],在有效性和可解释性上面都有明显的优势.
1.2 情境感知的自然语言推理
近年来,已经提出了一些任务来结合语言和视觉2个模态,包括图像捕获(image captioning, IC )[23-24]、VQA[25-26]、视觉推理(visual reasoning )[27]和视觉对话(visual dialogue)[28]等.但在情境感知的自然语言推理方面所做的工作很少.为了更好地理解图片和文本之间的关系,也有一些工作提出了视觉蕴涵(visual entailment, VE)任务[29-30],即把自然语言推理任务中的前提句用图像替代,推理图像和假设句之间的关系,但是这并不能确定在自然语言推理任务中引入情境信息是否可以提高模型的推理能力.所以最新的一些工作考虑不是替换而是增加图片来提供情境信息,希望模型可以从情境信息中提取出对推理有用的信息,来提高自然语言推理任务的性能.文献[20]在自然语言推理任务中引入情境信息的工作,初步证明了增加视觉信息对推理的有效性;文献[31]则从不同尺度上结合图片特征,更深层次地挖掘图片中的有用信息.
1.3 基于对比学习的语义表示方法
对比学习(contrastive learning)是一种无监督学习方法,它通过训练模型来学习如何比较2个样本之间的相似度或差异性.具体来说,在对比学习中,模型通过优化目标函数,拉近锚点样本和正样本之间的距离,同时拉开锚点样本与负样本之间的距离,以获得更具区分性的特征表示.这种方法在自然语言处理、计算机视觉和其他领域得到广泛应用,因为它不需要人工标注的标签,能够更好地利用大量未标注数据进行训练,提高模型的泛化能力[32].
在自然语言处理领域,对比学习得到了广泛的应用.文献[33]提出在BERT结构上添加一维卷积神经网络(CNN)层,并通过最大化全局句子嵌入与其相应的局部上下文嵌入之间的互信息来训练CNNs.文献[34]采用了与MoCo[35]类似的结构,并使用反向翻译进行数据增强.文献[36]使用2个单独的编码器来进行对比学习.文献[37]采用了SimCLR[38]的体系结构以对比目标和遮蔽语言模型目标共同训练模型.文献[39]设计了多种文本级别的数据增强方法,极大提高了对比学习的效果.文献[40]提出的SimCSE模型采用最简单的数据增强方式dropout在语义相似度任务上取得了非常好的效果.后来很多基于SimCSE的模型都不断刷新着模型性能的上限[41-42].
2 因果效应先验知识
因果图(cause graph)是一种用于可视化因果关系的图形工具,它可以帮助我们理解和识别变量之间的因果关系,从而提高对系统或现象的理解[43].因果图一般使用有向无环图(directed acyclic graph, DAG )表示,图中的节点表示变量,箭头表示变量之间的因果关系.图3展示了一些因果图和反事实符号的例子,其中X,M,Y分别表示因果变量、中介变量和结果变量;*表示对变量的干预;实线箭头表示变量间有直接的因果关联,虚线箭头表示变量间的因果关联被切断.如图3(a)所示,X→Y表示变量X与变量Y有直接的因果关联,X→M→Y表示变量X与变量Y以M为中介节点有间接的因果关联.为了简单起见,我们可以用公式简化因果图的表示.如在图3(b)中,当变量X的值为x时,变量M的值可以表示为m=Mx=M(X=x),所以变量Y可以表示为:

Fig.3 Examples of causal graph and counterfactual notation图3 因果图和反事实符号示例
图3(b)和图3(c)分别表示当因果变量X取不同的值(x或者x*)时的情况.因为X会同时作用于M和Y,因此当X取值为x*时,变量M*的值为m*=Mx*=M(X=x*),此时变量Y的值为Yx*,m*=Y(X=x*,M=m*).而图3(d)则展示了经过干预之后的反事实场景.通过干预切段了变量X与M之间的联系,这样就能够估计出X对Y的直接影响,在图3(d)中就是用Yx,m*=Yx,Mx*进行表示.
为了评估该影响的具体大小和程度,通常使用因果效应(cause effect)来计算.因果效应的计算是通过构建反事实世界来实现的,即改变变量X的取值,以推断如果X发生变化,Y将有何不同的结果.通过比较真实场景和反事实世界的结果,可以计算出X对Y的因果效应.具体来说,图3(b)代表真实场景,而图3(c)则代表反事实世界.可以得到X通过直接路径和间接路径对Y产生的总因果效应(total effect, TE):
X对Y的总因果效应可以分解为X→Y的直接因果效应和X→M→Y的间接因果效应.在图3(d)中通过干预切断间接因果效应,则X对Y的直接因果效应(natural direct effect, NDE)可以通过式(3)计算:
通过从总因果效应中减去直接因果效应就可以得到X对Y的间接因果效应(total indirect effect, TIE):
在实际场景中,由于变量数量很多,直接计算2个变量之间的间接因果效应是比较难以实现的,直接因果效应则往往较容易计算,因此可以使用这种方式来计算所需要的间接因果效应.
3 CBDRM模型
本节首先介绍了针对情境感知的自然语言推理任务所构建的因果图,并在此基础上详细介绍了所提出的CBDRM方法的技术细节.
3.1 针对情境感知的自然语言推理的因果图
按照传统的方法,自然语言推理任务通常被形式化为文本分类任务,即通过把前提句和假设句一起输入模型,让模型捕获到2个句子之间的推理关系并进行预测.如图4(a)所示,P和H分别表示前提句和假设句,变量M代表模型学习到的融合了2个句子推理关系的中介变量,Y表示预测结果.
但是,自然语言推理数据集中假设句与标签之间可能存在着虚假关联,所以图4(a)并不能准确地建模出自然语言推理任务.认为只有在因果图中准确地描述出这种虚假关联,才可以在后续处理过程中消除它.同时,在给定情境信息的情况下,也需要在因果图中准确描述出情景信息与文本之间的关联,才能更好地捕获情景信息中有助于推理的部分.基于以上观点,我们重新构建了针对情境感知的自然语言推理的因果图,如图4(b)所示,V表示图像情境信息,考虑在数据构建过程中,前提句是根据给定的图像信息标注得到而生成假设句的过程中并没有看到图片信息,所以有V→P这条路径.变量M1代表融合了前提图像和假设文本之间推理关系的中介变量,变量M2代表融合了前提文本和假设文本之间推理关系的中介变量.(V,H)→M1→Y和(P,H)→M2→Y这2条路径分别表示前提图像与假设文本对预测结果的影响、前提文本与假设文本对预测结果的影响,这是模型真正需要学习的从输入到输出之间的因果推理关系.路径H→Y则表示假设句子与标签之间的虚假关联,是导致模型学习有偏的因素,也是在学习过程中需要被去除的内容.通过构建图4(b)所示的因果图,数据中不同变量之间的关系就能够被更为准确地描述,为后续计算不同变量之间的因果效应奠定了坚实的基础.
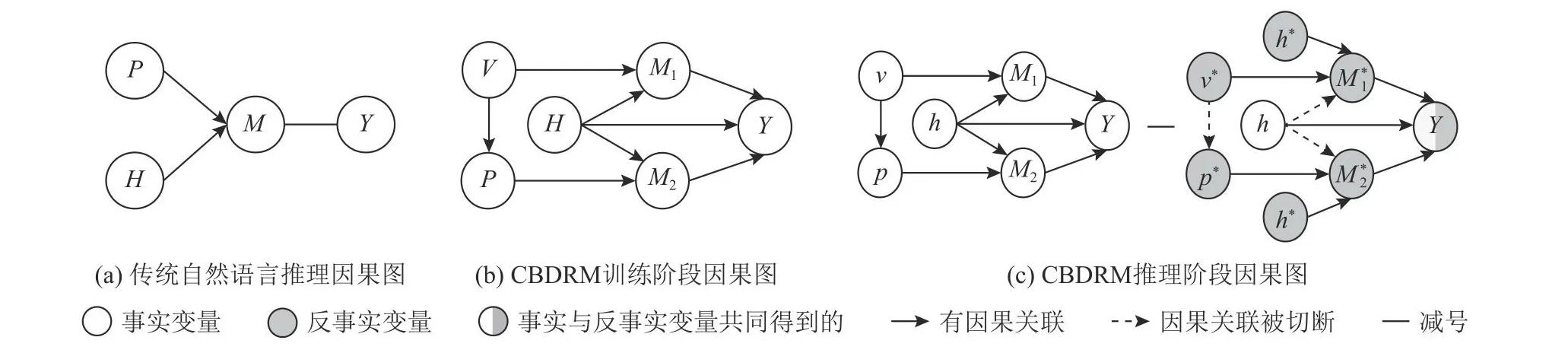
Fig.4 Comparison of traditional NLI and our proposed CBDRM causal graph图4 传统自然语言推理和本文提出的CBDRM因果图比较
3.2 CBDRM模型推理
基于第2节所介绍的因果图的表示,将图4(b)中变量Y表示为:
其中m1=M1(V=v,H=h),m2=M2(P=p,H=h).接着计算得到作用于Y上的总因果效应:
其中v*,p*,h*,M1*,M2*均表示经过干预之后的输入,m*1=M1(V=v*,H=h*),m*2=M2(P=p*,H=h*).为了简化表示,省略了中介变量M1和M2.
由前文的分析可知,路径H→Y描述了假设句子到标签之间的虚假关联,因此将其计入总因果效应中会导致预测偏差,所以应该阻断路径H→Y,从总因果效应中去除有偏的因果效应,得到无偏的间接因果效应.由于因果图的复杂性,难以直接计算间接因果效应,但是H对Y的直接因果效应是比较容易得到的,因此可以计算:
通过对NDE的计算可以估计出假设句所带来的语言偏见.通过用总因果效应减去直接因果效应(如图4(c)所示),得到:
这样就可以用TIE来表示去偏之后的因果效应.在具体的实现过程中用预训练语言模型(pre-trained language model, PLM)来计算因果效应,如式(6)中的Yv,p,h的计算方式如下:
其中Yv,h表 示的因果路径(V,H)→M1→Y的因果效应,Yp,h表示因果路径(P,H)→M2→Y的因果效应,f表示编码器,可以是BERT,RoBERTa 等相关的预训练语言模型,H表示融合函数.我们使用了2种融合函数CON和SUM,并在后续实验中比较了2种融合方式的性能:
同样地,对于经过干预之后的反事实世界的Yv*,p*,h有类似的计算方式:
反事实世界的值通常需要干预来实现,基于现有的事实,可以假设一个不真实或未发生的事实为反事实.因为模型不能处理空的无效输入,所以在模型中通常通过将变量设置为常数值来实现反事实[17-18,44].这里也是同样的做法,为了保持一致性,反事实输入v*,p*,h*使用了与原来的维度相同的零向量来表示.
在训练时得到的是作用于Y上的总因果效应,如图5(c)左图所示,使用式(12)的损失函数联合训练:
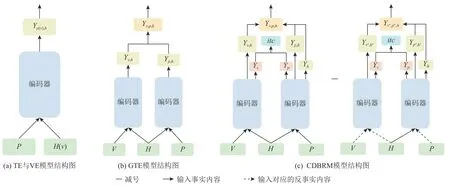
Fig.5 Traditional models and CBDRM model图5 传统模型与CBDRM模型
其中α,β,γ是用来平衡损失函数权重的超参数,Lv,p,h,Lv,h,Lp,h,Lh分别是Yv,p,h,Yv,h,Yp,h,Yh经过分类层之后与真实标签计算得到的交叉熵损失,如Lv,p,h=其中C表示标签的类别数,p(a|x)表示样本x的真实标签分布,p(a|v,p,h)=softmax(g(Yv,p,h))是模型预测的标签概率分布,g(·)表示分类层.
介绍完CBDRM核心的因果去偏模块,接下来将介绍对比学习模块.这个模块对于提升情境信息的理解起到了关键作用.
回顾自然语言推理数据的构建过程[1-2],前提句是由标注工人基于给定的图片生成的,因此图片与前提句之间有密不可分的联系.然而,如果不进行任何干预,模型可能无法捕捉到图片和前提句之间的关系,也就难以判断图片和假设句之间的关系.对比学习在多模态任务上已经被证明是非常有效的[45-46].因此,考虑使用对比学习来对齐图片和前提句之间的特征,使模型能够理解图片和前提句之间的联系,进一步提高文本对情态信息的理解.
本文使用预训练模型CLIP[46]的视觉部分对图片的特征进行提取,然后将提取的向量特征输入共享编码器f,以使其可以进一步在训练中得到学习.图片编码后得到的嵌入序列为(vcls,v1,v2,…,vN).我们取vcls作 为图片的表征向量I.同样地,我们将前提句P也输入共享编码器f得到嵌入序列(wcls,w1,w2,…,wN),我们取wcls作 为前提句的表征向量T.然后使用式(13)进行对比学习.
其中Tm表示与图片I匹配的前提句;s(·)表示相似度函数,用于计算图像和文本之间的相似度,s(I,T)=·wcls;τ表示温度系数;K表示一个批量大小.
结合因果去偏和对比学习2个模块,CBDRM模型使用式(14)的损失函数来联合优化:
其中λ用来平衡对比学习损失的权重.
模型训练完成之后,本文的推理框架图如图5(c)所示.图中减号左边表示作用于Y上的总因果效应TE,减号右边则表示假设句和标签之间的虚假关联所带来的直接因果效应NDE,通过从总因果效应中减去直接因果效应来实现无偏推理.我们去偏之后的预测结果为:
4 实验结果与分析
本节首先介绍了实验设置,包括实验数据集、参数设置、基线方法等内容;接下来对实验结果和模型技术细节进行了详细的分析.
4.1 数据集介绍
本文使用的数据集是基于斯坦福大学发布的SNLI数据集[1],该数据集只包含文本.通过对SNLI数据集合成过程分析,发现其前提句来源于Flick30K数据集中图片的标题[45],假设句由标注人员根据给定的前提句和标签信息人工生成,每个前提句分别对应3种不同关系的假设句.后来人们根据SNLI数据集构造了多模态数据集SNLI-VE[29-30],即把SNLI数据集中的前提句用图片替代.文献[20]则直接在SNLI数据集中引入了图片构造成三元组(图片,前提,假设)的形式.但是发现该合成方法存在一定的不足,因为SNLI数据集中训练集和测试集中有部分前提句对应的是同一张图片,这不符合数据集构建的一般规范,即不同数据集之间不应该有重叠的样本.SNLIVE数据集则考虑到了这个问题,并对于训练集和测试集进行了重新划分,以避免这样的情况.本文以SNLI-VE数据集为基础,为每对图片-假设句找到在SNLI数据集中对应的前提句,构建出多模态数据集.
为了更好地验证模型的去偏自然语言推理能力,受SNLI挑战集构建方式[10]的启发,本文在这个多模态数据集上也构建了一个挑战集,具体而言,使用BERT-base-uncased[3]模型作为编码器,先仅使用假设句作为输入训练一个分类模型,然后在测试集中选择预测置信度较低的样本加入挑战集,即p(Lx|x)<ε,p(Lx|x)表示样本x的预测结果为真实标签Lx的概率,ε表示设置的阈值.在有偏的测试集中,模型严重依赖假设句和标签之间的虚假关联来进行预测,而构建挑战集的方法正是阻止模型利用虚假关联.数据集的具体信息如表1所示.
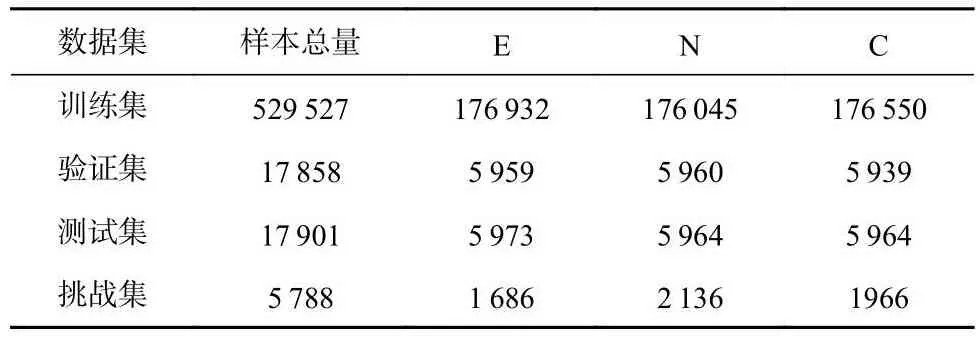
Table 1 Statistics of Multi-modal Datasets表1 多模态数据集统计
4.2 参数设置
为了获得最好的模型效果,我们在验证集上对所有模型的超参数进行验证,以获取最优的超参数组合用于模型测试.部分通用的超参数设定为:
在输入文本编码过程中,我们选择预训练模型BERT-base-uncased[3]和RoBERTa-base[4]作为主干网络,并使用Adam优化器来微调整个网络.学习率设置为0.00003,批大小设置为32,训练的epoch数设置为4.损失函数的超参α,β,γ,λ分别设置为0.5,0.5,1.0,1.0.对比学习模块的温度超参数τ设置为0.05.
4.3 基线方法
为了更全面地评估CBDRM模型的效果,本文选取基线模型:
1)H-only.仅使用假设句子作为输入,其结果展示了模型对假设句子和标签之间的虚假关联的依赖.
2)BERT-TE,RoBERTa-TE.自然语言推理的预训练基线模型,通过充分建模句子对之间的语义关系实现准确的自然语言推理.对应的模型图如图5(a)所示.
3)BERT-VE, RoBERTa-VE.多模态的自然语言推理的预训练基线模型,将前提句子替换为多模态图像信息,实现从图像语义到文本语义的推理关系判断.
4)BERT-GTE, RoBERTa-GTE.情境感知的自然语言推理的预训练基线模型,通过在文本语义推理过程中考虑图像情境信息,实现更全面的语义推理.对应的模型图如图5(b)所示.
5)SimCSE-TE, SimCSE-GTE.经典的对比学习语言模型,具有更强的表征能力.
6)CORSAIR.文本分类去偏方法的最先进(stateof-the-art,SOTA)方法.
4.4 实验结果分析
表2展示了模型在不同设置下的实验结果.从这些实验结果观察到3点实验现象:
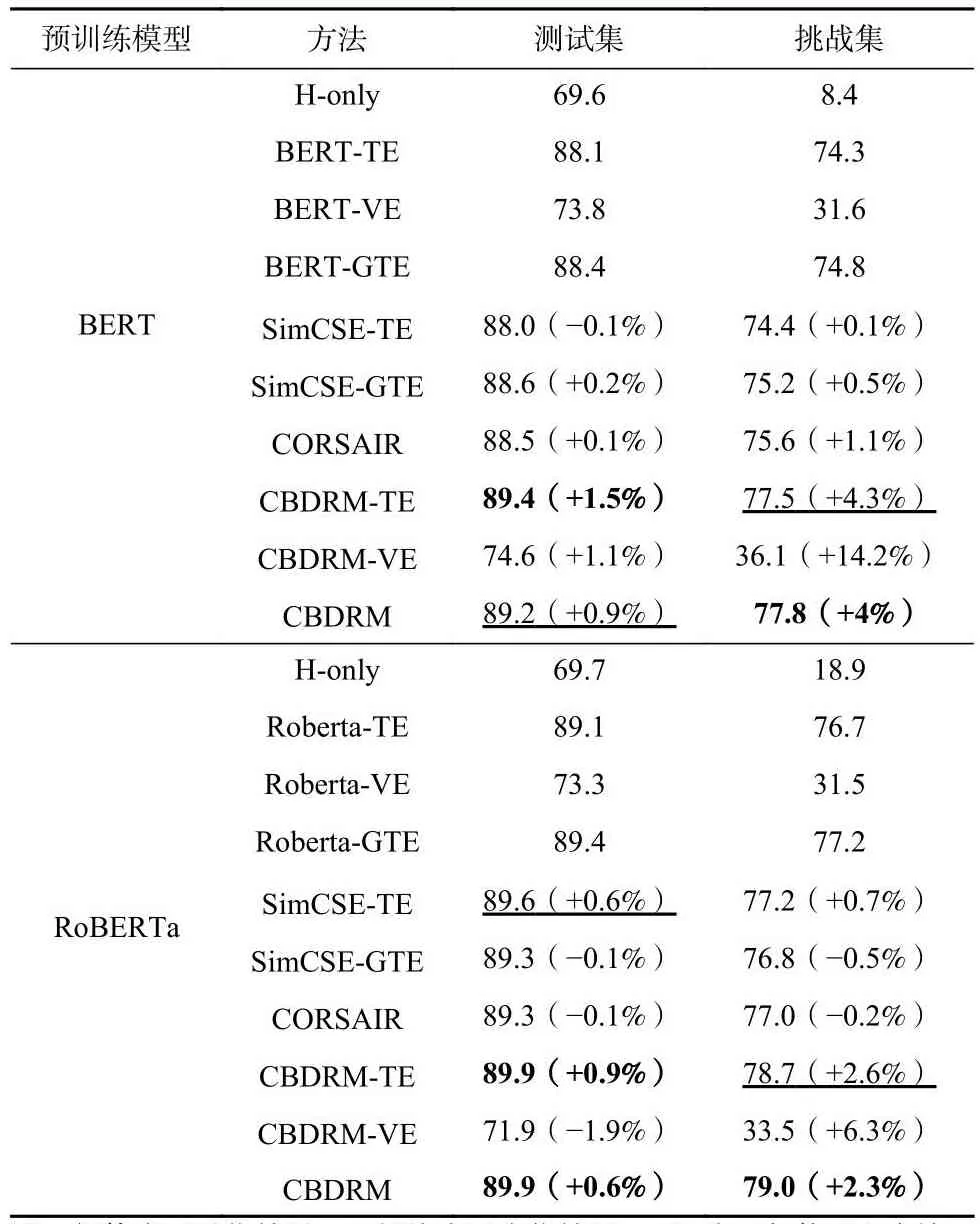
Table 2 Experimental Results of Different Methods on Multi-modal Datasets表2 不同方法在多模态数据集上的实验结果
1)无论是传统的自然语言推理还是情境感知的自然语言推理,模型都会利用数据中的语言偏见进行语义推理关系的预测(H-only和GTE方法在挑战集上的效果均远远低于在测试集上的效果),说明语言偏见会影响模型对文本语义的准确建模,也证明了无偏语义表示与推理的必要性.H-only模型在测试集和挑战集上的巨大差异也验证了模型无法通过假设句和标签之间的虚假关联来进行预测,进一步证明了本文构造的挑战集的无偏性.
2)图像情境信息的加入能够有效缓解文本中的有偏信息对模型的影响.图像情境信息能够为文本语义的准确表示提供更全面的辅助信息,对文本语义表示与自然语言推理具有重要的意义.
3)CBDRM方法在测试集和挑战集中性能都取得了提升 (以BERT模型为主干网络分别提升了0.9%和4%).在测试集中相比于SimCSE(+0.2%)和CORSAIR(+0.1%),CBDRM的提升是明显的;在挑战集中相比于SimCSE(+0.5%)和CORSAIR(+1.1%),CBDRM的提升则更加显著.说明本文的方法确实有效去除了模型学习到的偏差,使其推理能力得到了提高.在模态缺失的情况下,可以看到CBDRM也取得了比TE和VE更好的效果,说明我们设计的对比学习模块让模型更充分地学习到了多模态信息,从而促进了其在子任务上的性能,其在挑战集上的性能也说明了本文设计的去偏模块的有效性.但是,我们发现以RoBERTa为主干网络的CBDRM-VE效果比VE略有下降,推测原因可能是RoBERTa模型不太适用于多模态任务(RoBERTa的VE性能也弱于BERT的VE),因为其在预训练中去除了下一句预测(next sentence prediction, NSP)[3]任务,该任务可能在纯文本中作用不大,但是在多模态任务中具有良好的效果.
4.5 消融实验结果分析
4.4节中的实验结果已经充分证明了CBDRM方法的有效性,但是目前还不能明确不同模块在训练中所起到的作用.为此,我们进一步对前面CBDRM中的不同模块进行消融实验,并根据模型在每个类别上的性能进行详细比较,以更清晰地展示每个模块的作用.消融实验结果如表3所示.
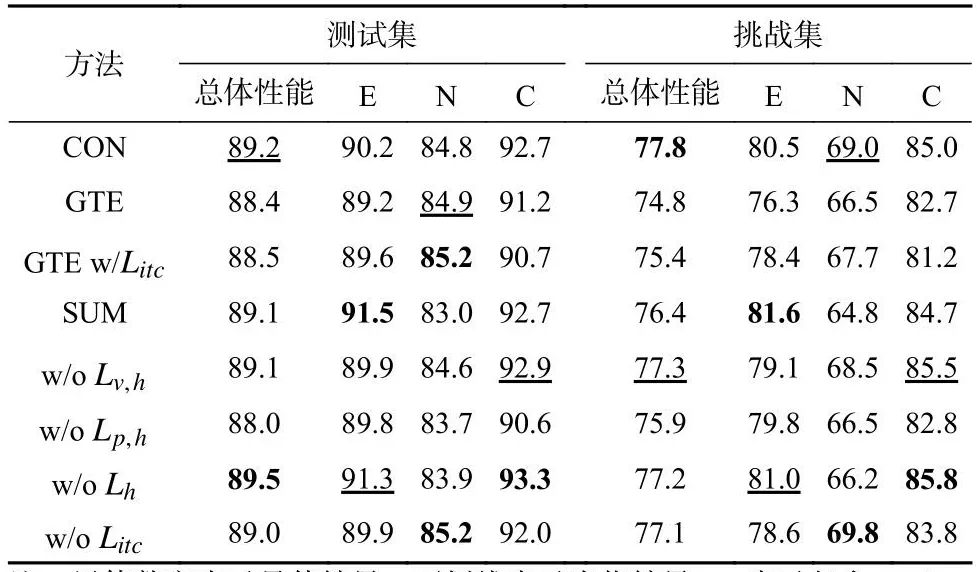
Table 3 Results of Module Ablation Experiments for CBDRM(BERT)表3 CBDRM(BERT)的模块消融实验结果
1)对比学习模块.首先是对对比学习模块效果的验证,在GTE任务上加上对比学习模块在测试集上取得了微小提升,但是在挑战集上取得了明显的提升(0.6%的绝对提升).与此同时,将对比学习模块从CBDRF中去除,可以看到,模型的整体实验结果以及在不同类别上的性能均有不同程度的下降,说明模型对情境信息的理解能力变弱,导致对文本语义的建模能力变差.这些现象说明了对比学习模块不只是对本文的去偏模型中有效,在其他模型中也同样可以促进多模态信息的学习.
2)融合策略.从表3实验结果可以看出CON的融合方式在测试集和挑战集上的表现要优于SUM融合方法.我们分析可能的原因是CON融合策略通过不同信息进行拼接,然后进行语义推理关系的预测.该方式能够更大程度保留学习到的特征信息,辅助模型实现更精准的无偏语义推理.
3)优化目标策略.为了更充分验证CBDRF对不同因果路径的建模学习能力,以及不同因果路径对无偏语义表示学习及推理的影响,我们在CBDRF模型中去掉了对应于不同因果路径的损失函数(如Lv,h对应路径(V,H)→M1→Y,Lh对应路径H→Y等),以观察不同因果路径的影响程度.从结果可以看出,去除这些损失函数均会造成CBDRF性能有不同程度的下降,证明了每个模块的有效性以及必要性.其中去除Lp,h性能下降最多,因为模型推理性能主要依靠的路径还是(P,H)→M2→Y;去除Lh会导致模型对于偏差的学习不够充分,去偏性能有所下降;去除Lv,h会削弱(V,H)→M1→Y路径的影响.
4)不同类别性能分析.除了分析不同模块对模型性能的影响,我们同时也对模型在不同语义推理关系上的表现进行了深入的分析.从每个类别的预测结果可以看出,模型在中立关系上的预测性能要明显低于另外2类,该现象和人类的语义推理能力是一致的.对于人类而言,中立情况包含了非常多的模糊信息,造成了判断上的困难;同时,标注者生成中立假设句的时候可以利用的先验知识也更丰富.这些都为中立关系的判断带来了比较大的挑战.但从表3中的结果可以看出,在挑战集中,CBDRM在不同类别的语义推理关系识别准确率都有比较大的提升,充分说明了CBDRM在无偏语义推理方面的优越性能.
4.6 参数敏感性实验分析
为了更深入地分析式(14)中各权重超参数α,β,γ,λ对模型性能的影响,对每个参数进行了额外的参数敏感性实验.这些超参数的取值范围均设定在{0,0.5,1.0,1.5}中.图6展示了对应的实验结果.
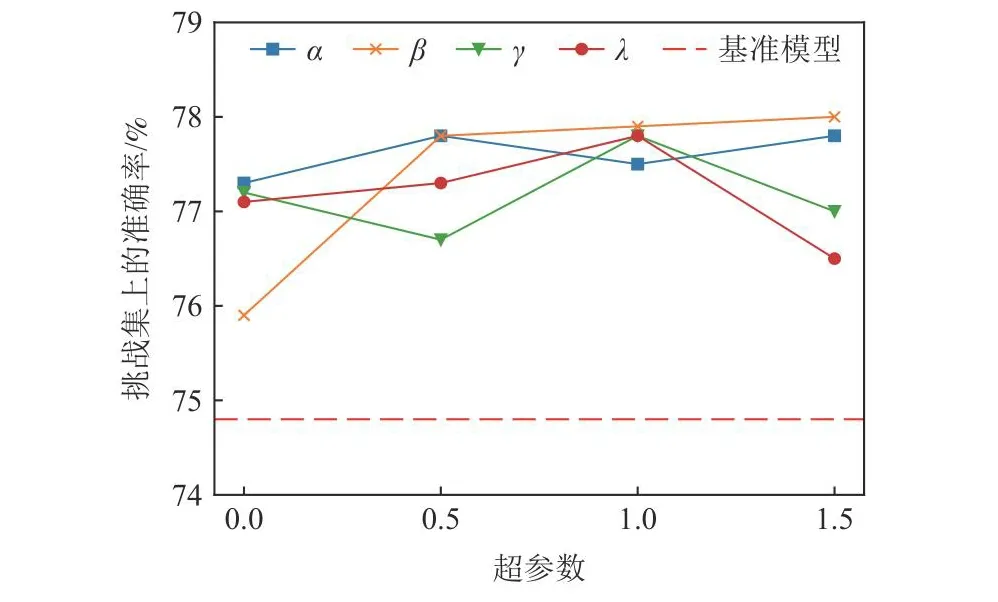
Fig.6 Hyperparameter sensitivity test plot图6 超参数敏感性测试图
从图6的实验结果可以看出,超参数的变化确实会影响模型的性能,其中模型对β最敏感,对应于Lp,h,说明该模块对模型的影响最大,该结果也与4.5节中的实验结果保持一致.以此同时,模型对λ也较为敏感,对应于对比学习损失函数.该结果说明了对比学习对模型充分利用图像情境信息,实现对文本语义的准确无偏表示及推理具有重要的作用.同时发现过大的λ反而会造成性能的下降,推测过度的对比学习可能会造成正负样本的反向塌缩,导致性能下降.γ控制着偏差的学习程度,可以发现太小或太大的γ都不利于偏差的学习.
4.7 案例分析
为了进一步说明CBDRM方法的有效性,从数据集中抽取了一些例子来更直观地展示CBDRM的效果,同时也对模型产生效果的原因进行定性分析.结果如图7所示.

Fig.7 Case analysis图7 案例分析
图7(a)展示了CBDRM和GTE都预测正确的情况,在GTE没有太高的预测置信度的情况下,CBDRM有效去除了在矛盾类上的偏差,从而在蕴含类上取得了更高的置信度.图7(b)展示的是CBDRM和GTE都预测错误的情况,可以看到CBDRM在中立标签上的预测置信度比GTE要高.
图7(c)~(e)则展示了GTE预测错误,但是CBDRM预测正确的典型例子.如图7(c)所示,GTE错误预测了假设句中含有“not”的样本为矛盾,图7(d)中GTE错误地将有词汇重叠的矛盾样本预测为蕴含.而CBDRM则有效捕获到了这些偏差,做出了正确的预测.图7(e)展示了CBDRM比GTE有对情境信息更强大的理解能力.在GTE对标签结果很困惑的时候,CBDRM则给出了更确切的预测.
图7(f)则展示了GTE预测正确,但是CBDRM却预测错误的情况.可能的原因是这个例子中假设句的偏差并没有被明显捕获,GTE在矛盾类别上的预测置信度也不是很高,但是CBDRM却过度去除偏差,导致最后的预测结果发生了错误.如何合理控制偏差去除的程度也是我们未来工作将要深入研究的方向.
5 结 论
为了实现情境感知的无偏自然语言推理,本文提出了一种全新的融合因果推断方法的因果去偏推理方法CBDRM.该方法能够在考虑情境信息的条件下,有效识别并消除语言偏见对文本语义理解及语义推理的不利影响,实现更准确、更鲁棒的无偏自然语言推理.具体而言,通过对情境感知的自然语言推理数据进行深入分析,构建了一个因果图,用于准确描述输入数据和标签之间存在的虚假关联;在此基础上,通过分别计算总因果效应,描述虚假关联的直接因果效应,以及从总因果效应中减去直接因果效应实现了语义的准确表示以及语义推理关系的无偏预测.更进一步,为了充分利用图像情境信息实现更为准确的文本语义理解与语义推理,设计了一个全新的对比学习模块,提升了在给定情境信息时输入文本的语义表示能力.在公开数据集上的大量实验充分证明了CBDRM的优越性.同时,还通过消融实验、参数敏感性实验等深入分析了CBDRM各个模块对模型性能的影响.最后构建并公开了一个全新的情境感知的无偏自然语言推理挑战集,用于支持相关方向的研究.
在未来,我们计划对图像情境信息进行深入挖掘,考虑使用可学习的视觉编码器,实现端到端的训练,进一步提高模型对多模态信息的学习能力.另外,如何更合理地控制偏差的去除程度也是影响去偏效果的关键因素之一,这也是未来需要进一步研究的.现如今大型语言模型(large language models, LLMs)同样也存在着偏差问题,而LLMs使用的数据集的无偏性更是难以保证,所以如何通过因果推断来去除LLMs学习到的偏差也是非常值得探索的问题.
作者贡献声明:张大操和张琨提出算法思路、完成实验,并撰写论文;吴乐和汪萌提出指导意见并参与论文修改.
猜你喜欢
核科学与工程(2021年4期)2022-01-12
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2020年19期)2020-12-14
开放教育研究(2020年2期)2020-03-31
知识经济·中国直销(2018年8期)2018-08-23
中学物理·高中(2016年12期)2017-04-22
数学学习与研究(2017年3期)2017-03-09
现代语文(2016年21期)2016-05-25
中国老区建设(2016年1期)2016-02-28
大连民族大学学报(2015年2期)2015-02-27
