
基于卷积神经网络特征提取的莴苣生长无损监测
2023-08-15 02:02刘欣然王中举
计算机技术与发展 2023年8期
阳 昊,黄 超,2,刘欣然,王中举,王 龙,2
(1.北京科技大学 计算机与通信工程学院,北京 100083;2.北京科技大学 顺德创新学院,广东 佛山 528399)
0 引 言
莴苣作为一种叶用蔬菜因其丰富的口感和质地而受到广大消费者的喜爱[1]。有研究表明,生菜富含维生素、胡萝卜素、铁元素,对减少心血管疾病和慢性病有积极作用[2]。莴苣的生长状态监测对最大化产量和提高莴苣品质具有重要意义[3]。叶片鲜重(LFW)、叶片干重(LDW)、生菜高度(H)、生菜直径(D)、和叶面积(LA)是表征莴苣生长的关键指标。准确地获取生长状态指标(LFW、LDW、H、D和LA),对采取相应的生产措施有极大的参考价值。人为采集农作物样本获取生长指标的方法简单,能获取较为准确的结果,但会破坏作物,费时费力[4]。卷积神经网络作为类脑领域重要的研究成果,能高效地处理图像输入,在工业界和学术界得到了广泛的应用[5-6]。随着计算机视觉技术的发展,基于图像的农作物识别、无损监测方法具有广泛的前景[7]。基于图像的监测方法通常从图像中抽取人为设计的特征,通过对这些特征与生长指标构建回归模型,进行无损的生长监测。Chen等人[8]从彩色图像、荧光图像、近红外图像中提取结构特征和近红外反应生理特征,利用支持向量机、随机森林、线性回归等机器学习算法估计大麦生物量的积累。结果表明,随机森林能更好地建立图像特征与生物量之间的关系。Tackenberg等人[9]提出了一种基于数字图像分析的牧草生长状态估计方法,以线性回归估计地表干物质量、新鲜生物量等。实验结果显示所有模型的决定系数都高于0.85,表明这些特征和生长特性有较好的线性关系。Casadesús等人[10]从不同彩色空间的图片中提取色彩特征来估计大麦的叶面积、绿色面积指数和干重,这些特征包括HIS色彩空间的H分量,CIELUV色彩空间的U分量,实验结果表明这些特征与不同生长阶段的生长指标有很强的相关性。Fan等人[11]设计可见光和近红外摄像系统用于获取意大利黑麦草的时间序列图像,基于这些图像的R、G和NIR通道数值,利用多元线性回归模型估计叶面积指数从而量化麦草的生长。实验结果表明,对图像进行分割预处理能获得更好的准确率。Liu等人[12]利用基于直方图的阈值分割方法从图像中分割植被区域,再提取垂直间隙指数来估计大豆、玉米、小麦的叶面积指数。Sakamoto等人[13]从彩色图像和近红外图像中提取植被系数用于估计叶面积指数、总叶面积指数、生物量。实验表明,彩色图像提取的特征能准确地估计叶面积指数和叶片生物量,而从近红外图像中提取的特征能更准确地估计总叶面积指数。Daniel等人[14]从彩色图像和多光谱图像中提取归一化植被差异指数、绿色区域面积、简单比指数,利用最小二乘法估计木薯的生长和关键营养特性,实验表明,木薯矿物元素的含量与多光谱特征的关联性较低。为了评估杂草对小麦生长的影响,Gée等人[15]利用支持向量机和视觉词汇袋技术从图像中估计杂草和小麦的覆盖率。除了二维图片,Briglia等人[16]利用3D图像来获得葡萄叶片角度的变化,由此来监测葡萄水分状况。根据以往的研究,图像的来源包括彩色图片、近红外图片、荧光图片和3D图片,针对不同的图片和具体估计的指标,需要设计不同的特征,如色彩特征、几何特征等。并且在设计之前,特征与指标之间的相关性是未知的,导致这类方法的泛化性能较差,特别是对于不同场景、不同的光照和复杂背景下获取的图片。Zhang等人[17]设计了一种基于卷积网络的莴苣生长指标估计算法,以图片作为模型的输入,直接输出LFW、LDW和LA。实验表明相比于人工设计的从不同色彩空间提取的特征,卷积网络具有更好的精度,作者认为卷积网络的优势是能够更有效地从图像中提取复杂的特征。基于这一启发[17],该文结合深度学习和机器学习,设计了两阶段的莴苣生长指标估计算法。在第一阶段通过训练卷积神经网络作为自动的特征提取工具;第二阶段利用神经网络自动从图像中提取的高维特征训练集成机器学习模型直接估计LFW、LDW、LA、H和D。该文输入的图像包括彩色图像和深度图像。通过卷积网络提取特征,免除了人为特征的设计与筛选,算法具有鲁棒性,同时,特征提取网络和机器学习模型有广泛的选择,算法的设计具有灵活性。实验表明,相比直接利用卷积网络估计生长指标,文中算法能够显著降低误差。
1 算法设计
算法整体流程如图1所示,输入包括RGB彩色图像和深度图,伪代码如算法1所示。在第一阶段,通过梯度下降训练卷积网络估计莴苣生长指标,在达到最大训练周期后,卷积网络的参数固定。第二阶段,利用训练的卷积网络作为特征提取工具,从图像中提取特征向量,用于训练机器学习模型。测试阶段,利用参数固定的卷积网络从图像中提取特征向量,机器学习模型利用提取的特征估计莴苣的生长参数。
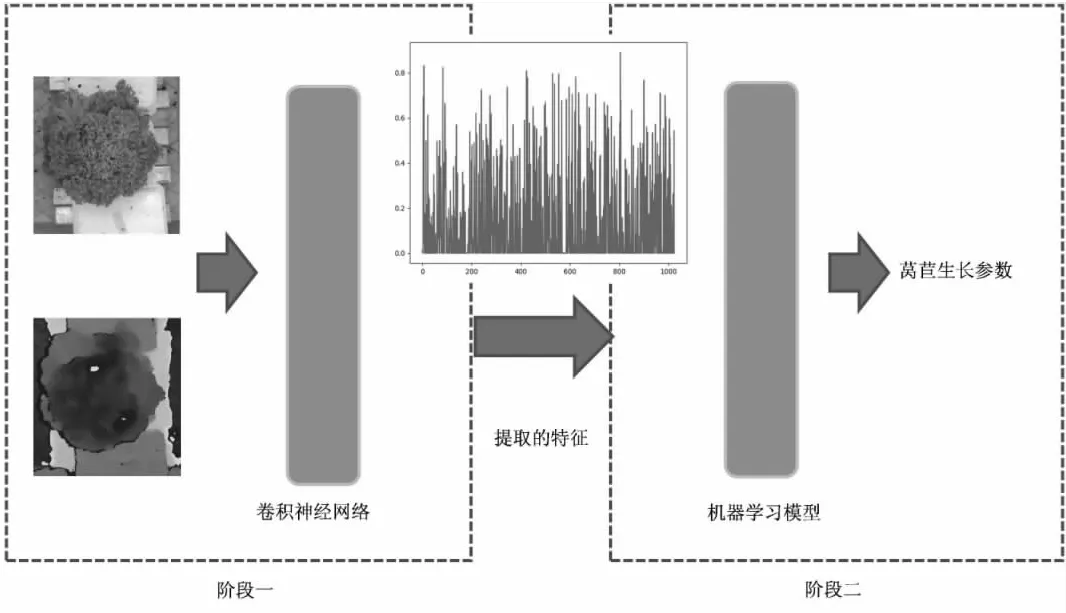
图1 莴苣生长状态参数估计算法流程
算法1:二阶段的莴苣生长监测算法
1.fori=1,2,…,5 do //对生长参数逐个训练模型
2.for each batch do //循环训练
3.L←0 //损失函数置0
4.Xr,Xd,Yi← dataloader.iter() //数据生成
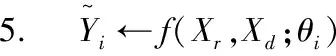
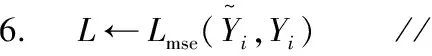
7.L.backward() //模型通过梯度下降优化
8. end for //第一阶段卷积网络训练完成
9.fori=1,2,…,5 do//第二阶段机器学习模型训练
10.Xr,Xd,Yi← dataloader.load()
11.Xf←f(Xr,Xd;θi)//卷积网络提取特征
12.f(θ1,θ2,θ3).fit(Xf,Yi) //机器学习训练
13.end for
1.1 数据集及图像预处理
该文使用的数据包括338张RGB图和对应的深度图[18],原始图片大小为1 920×1 080,来自四类莴苣品种,包含从幼苗到收获的五个生长阶段,数据集还提供每张图片对应的LFW,LDW,H,D和LA。图2给出了数据集的示例,四列分别表示不同品种的莴苣,其中第一列给出了对应的标签,一行表示同一生长阶段。由图2可以看出,原始图像中目标区域只占整体图像的一部分,特别是对于早期生长阶段的莴苣,并且生菜的空间位置并不固定。为了减少卷积网络模型的计算量,同时移除无关区域,设计了基于莴苣中心的图片裁剪。裁剪过程如图3所示。为了确定莴苣中心,首先根据阈值分割深度图,然后通过计算分割产生的掩膜的空间位置的平均值得到莴苣中心点,最后根据中心点将图片裁剪为600×600的大小。深度图也通过同样的方式进行裁剪,确保RGB图像和深度图空间分布的一致性。

(a、b、c和d分别来自四个不同的莴苣品种,图像的左上角标出了对应的真实测量值。LFW(克),LDW(克),H(厘米),D(厘米),LA(平方厘米))

图3 图像的预处理过程(包括深度图阈值分割,中心点获取,深度图和原图裁剪)
1.2 卷积神经网络
为了卷积网络能从图像中提取莴苣生长参数相关的特征,首先训练模型估计莴苣生长参数。模型的整体结构包括卷积神经网络和全连接层。图像经过卷积神经网络连续的卷积、正则化、激活函数提取高维特征,生长指标的估计通过两层全连接层输出。在卷积网络的输出送到全连接层之前,将其展平为一维特征。第一层全连接层将特征维度压缩一半,之后添加Dropout[19]以缓解过拟合的问题。如图2所示,五个指标之间的数量级差异较大,并且有不同的物理意义。不同于文献[17]中的研究,该文对于五个指标分别训练模型,免除归一化的问题。对于单独的RGB图像输入,选取ResNet[20]提取特征;对于RGB和深度图的组合输入,选取RD3D[21]提取特征。RD3D来自于ResNet的改进,将ResNet中所有的3×3卷积替换成3×3的3D卷积。深度图是单通道图片,为了与彩色图组成3D的输入,首先以复制的方式将深度图扩展为三个通道,再与RGB图像堆叠,构成三维图像送入3D卷积网络中,输入的维度可以表示为“T×H×W×C”,其中T=2,H和W和图像的高度和宽度(文中H=W=600),C为3。不同深度的卷积网络展平后的一维特征维度有所不同,模型深度为34时,d=512,深度为50或者101时,d=2 048。卷积网络训练采用均方误差损失函数:

(1)
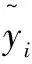
1.3 集成机器学习
通过训练后的卷积神经网络自动提取的特征,作为机器学习的输入,该文选择表1中第一层全连接层的输出作为提取的特征向量(不经过激活函数)。在机器学习算法的选择上,采用了Stacking[22-23]的集成方式,第一层使用随机森林[24]和深度森林[25],在第二层使用岭回归。第一层选择基于森林的算法,可以对提取的高维特征自动处理。随机森林在分裂节点时随机选择部分特征,能自动对特征进行筛选。深度森林是一种级联的森林网络,当前层次的输入是上一层的输出与初始输入特征的拼接。为了利用特征之间的相互关系,深度森林引入了多粒度扫描来构建初始的输入特征,具体地,使用不同大小的窗口在特征上滑动,构建出一组初始输入特征,对这一组初始输入特征,其中的每一个都会训练一个级联的森林,最后的输出是所有级联森林输出的均值。
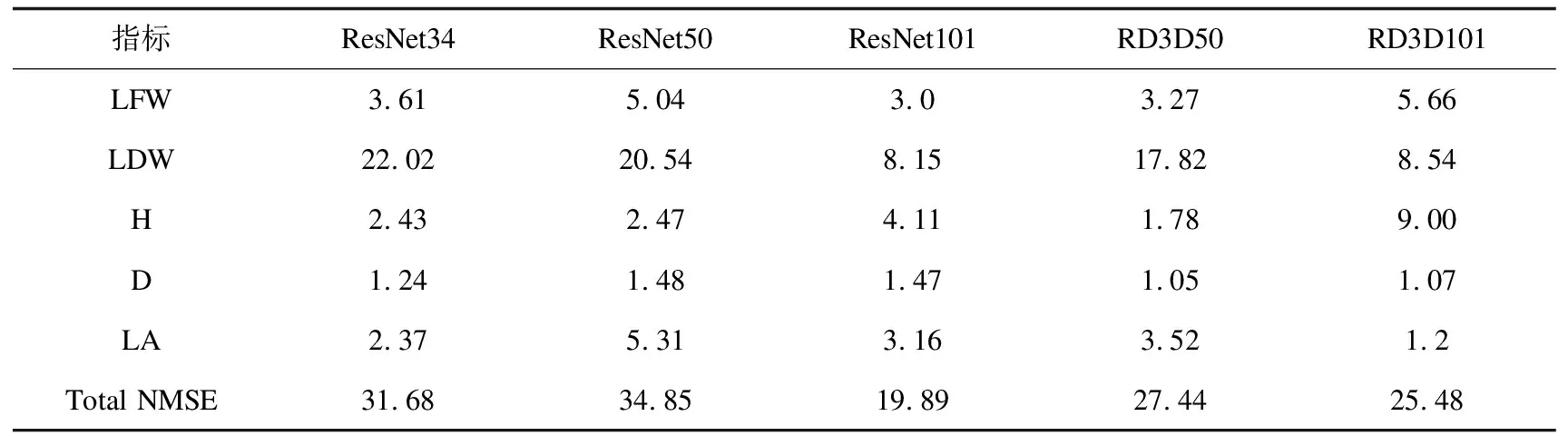
表1 卷积网络估计结果(RD3D输入由彩色图和深度图构成,误差由归一化均方误差表示) %
定义集成机器学习的训练集为L={(yn,xn),n=1,2,…,N},其中xn表示卷积网络提取的特征向量,yn表示莴苣生长参数的真实值,N为样本个数。Stacking第一层包含的随机森林、深度森林表示为vk,k∈{1,2},第一层两个模型通过留一法进行训练,训练完成后模型的输出为:

(2)
留一法保留的数据组成新的训练集,用于训练第二层岭回归算法,将第一层两个算法组合。新的训练集定义为{{yn,zn},n-1,…,N},岭回归算法的训练:
s.t.αk≥0
(3)
αk即需要求解的第一层算法的组合权重。
2 实验与分析
2.1 实验设置
实验环境基于Linux操作系统,使用Python语言,在Pytorch框架中搭建卷积网络,机器学习使用Scikit-learn包。主要硬件环境为:GPU为GTX 3080 10 GB显存,CPU为AMD 3950X 16核。
数据集划分为训练集和测试集,其中训练集288张,测试集50张。卷积网络的训练使用均方误差损失函数,优化器选择AdaBound[26]以加速模型的收敛,初始学习率设定为1e-3,所有的模型训练50个周期。训练过程中每张图片有50%的几率采用数据增强,增强方式包括左右翻转,上下翻转,旋转10、30、60、90度角。随机森林和深度森林中,树的个数设为100,特征选择的判断基于均方误差。
2.2 评价指标
实验结果的评价指标采用归一化均方误差(NMSE),计算方式如下:
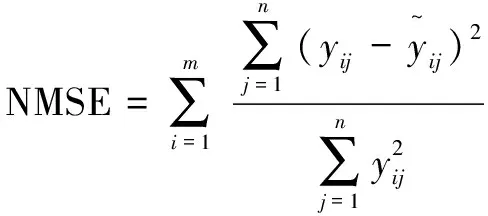
(4)
其中,m表示莴苣指标的种类(文中m=5),包括LFW、LDW、H、D和LA,n表示测试样本的个数(文中n=50)。
2.3 结果与分析
算法的整体可以分为两个阶段,第一阶段训练卷积网络提取特征,第二阶段利用训练好的卷积网络提取特征训练Stacking模型。第一阶段训练完成后模型在测试集上的估计结果如表1所示。根据表1,随着模型深度的增加,五个指标的总误差(Total NMSE)是降低的,表明网络复杂度的增加能在一定程度上提升准确率。其中单个指标下降最为明显的是LDW(只输入彩色图片时,误差从22.02%下降到8.15%,对深度图和彩色图片的组合输入,从17.82%下降到了8.54%)。另外,对比ResNet和RD3D,ResNet101的误差是最小的。同样深度下,RD3D50的误差比ResNet50低(27.44%和34.85%),而RD3D101的误差却比ResNet101高(25.48%和19.89%),可能的原因是RD3D101的模型复杂度高,参数量大,需要更多的样本进行学习。
在卷积网络训练完成后,提取的特征用于训练Stacking模型。Stacking模型在测试集上的表现如表2所示。根据表2,基于卷积网络提取的特征,所有模型的误差都有明显的降低,如对于ResNet50,误差从34.85%下降到12.78%,证明使用卷积网络自动提取特征是可行的,对于卷积网络提取的高维特征,使用随机森林、深度森林来自动处理,能有效减小误差。其中NMSE下降最为明显的是LDW,直接使用卷积网络估计LDW的误差范围为8.15%~22.02%,二阶段算法LDW的误差范围为2.61%~3.08%。在所有的模型当中,Total NMSE最低的是ResNet101(10.53%),其次是RD3D50(10.62%)。图4是使用卷积网络直接估计和提出的二阶段的算法的误差对比图,可以直观看出二阶段算法对降低误差是有效的。
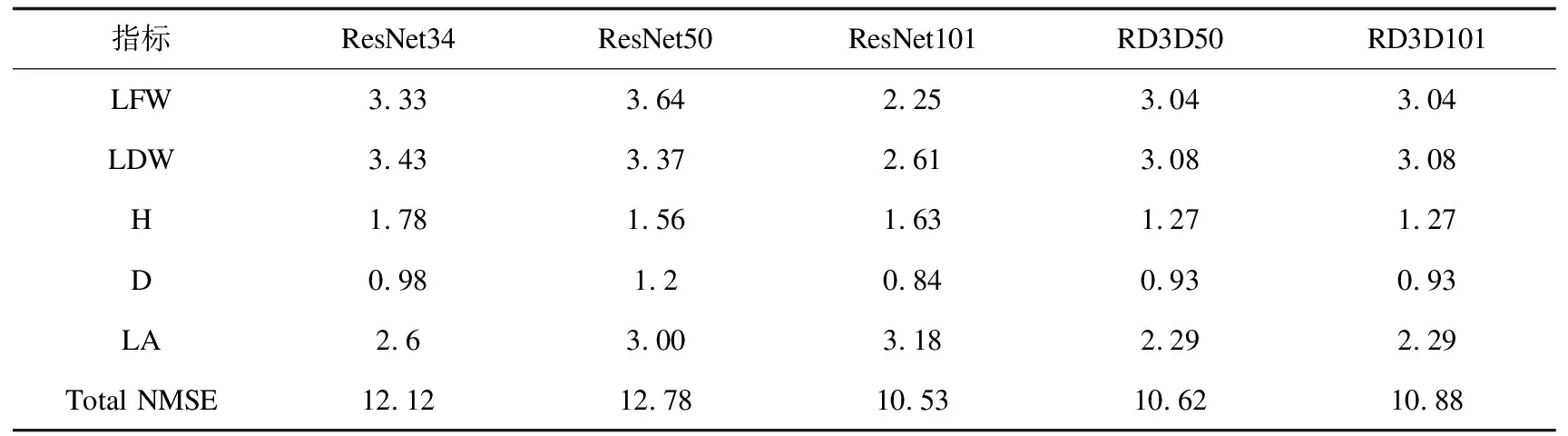
表2 二阶段算法估计结果(误差由归一化均方误差表示) %

图4 直接估计和设计的两阶段算法误差对比
图5和图6分别是ResNet101和RD3D50+Stacking的估计结果与真实值的对比图。两种算法对五个指标的决定系数(R2)范围分别是0.884 4~0.957 8、0.872 9~0.952 7,表明卷积网络提取的特征与生长参数有较好的相关性。五个指标当中,决定系数较高的是LFW(0.955 2和0.942 4)、LDW(0.957 8和0.952 7)和LA(0.936 2和0.947 2),而H(0.892 1和0.916 1)和D(0.884 4和0.872 9)的决定系数相对较低。值得注意的是RD3D对高度的估计更为准确,可能的原因是高度是三维空间的信息,而彩色图像只提供了平面的信息,所以ResNet101对高度的估计较为困难,而RD3D包含深度图,提供了关于高度的信息,从而能较为准确地估计。此外,对直径的估计较为困难,可能是在图像数据的采集过程中,摄像机和莴苣的相对位置不固定,空间比例不一致,导致无法准确估计。Zhang等人[17]在预处理中对图片进行了分割,之后采用卷积网络来估计莴苣的生长参数。在实验中,考虑到图像中莴苣的背景并不复杂,也尝试用超像素分割的方法对图像进行预处理,将莴苣与背景进行分割,然而超像素分割需要迭代较长的时间才能获得良好的效果,并且对比使用分割后的图片估计的误差与直接利用图片的误差,并没有显著的差异,所以该文最终没有采用类似的方法对图片进行预处理。另外,为了对比设计的二阶段算法与直接通过卷积网络直接预测,只在ResNet和RD3D进行了对比实验,Zhang等人[17]的工作是基于卷积网络直接预测,但代码并未开源,不参与比较。
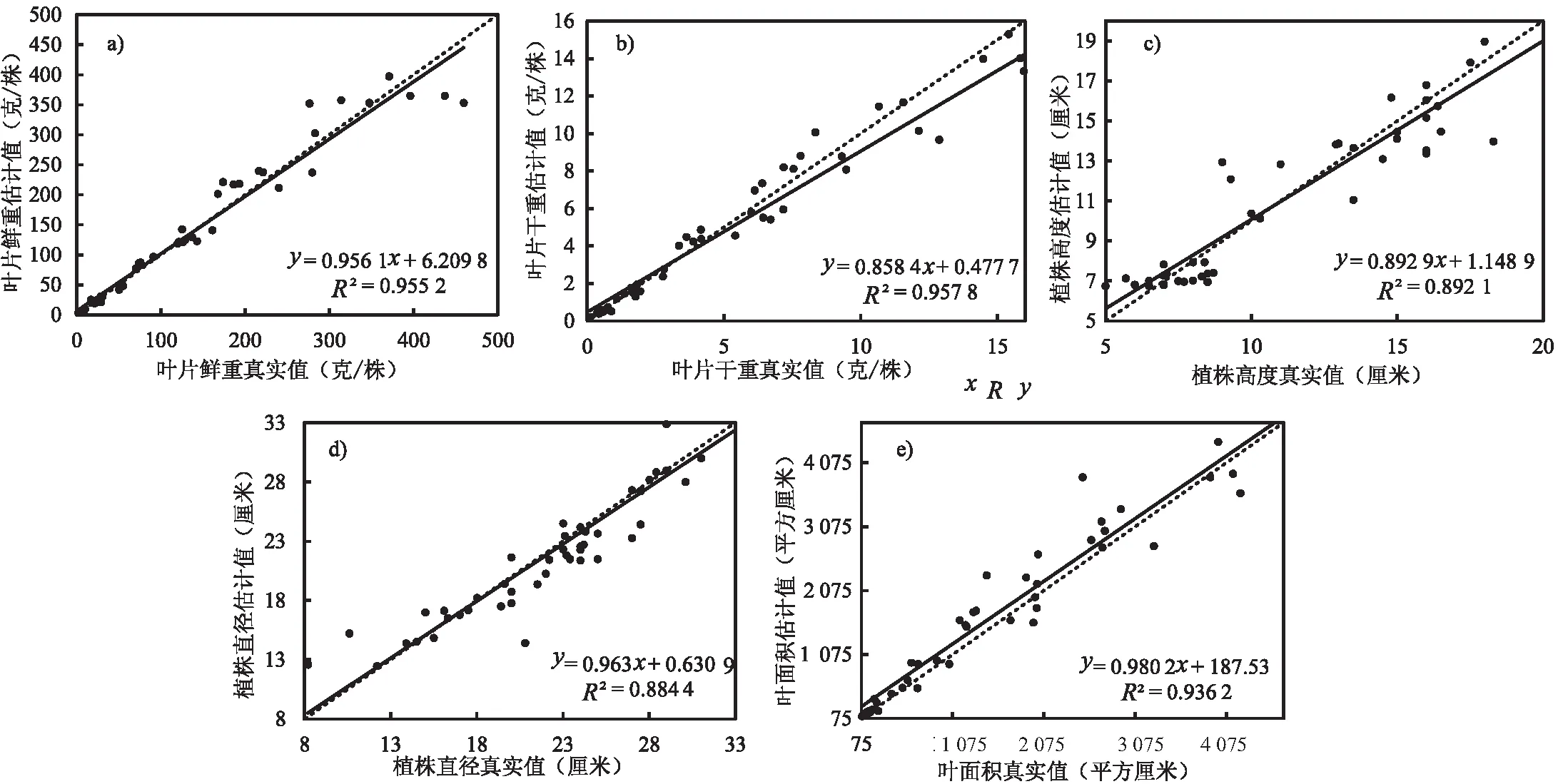
图5 ResNet101对五种莴苣生长状态参数的估计结果(输入只包括彩色图片,a-e分别是LFW、LDW、H、D和LA)

图6 RD3D50+Stacking模型对莴苣五种生长状态参数的估计结果(a-e分别是LFW、LDW、H、D和LA)
3 结束语
针对莴苣的生长状态参数监测,设计了一种两阶段的算法。第一阶段训练卷积网络自动从图像中提取特征,第二阶段利用提取的特征训练机器学习模型估计莴苣生长状态参数。输入的图像包括彩色图片和深度图,通过自适应的中心裁剪对图片进行预处理。使用ResNet从彩色图片中提取特征,使用RD3D从彩色图和深度图的组合输入中提取特征。在机器学习算法的选择上,采用随机森林和深度森林自动对提取的高维特征进行处理。
实验表明,相比直接使用卷积网络估计莴苣生长参数,设计的二阶段算法能明显降低误差(0.84%~3.18%),并且真实值和估计值之间的决定系数较高(0.87~0.95),表明卷积网络提取的特征与生长参数之间有较强的相关性。此外,对于莴苣高度的估计,引入深度图提供空间信息能进一步减小误差。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
哈尔滨轴承(2020年2期)2020-11-06
今日中国·法文版(2020年7期)2020-07-04
儿童时代·幸福宝宝(2019年9期)2019-10-28
电子制作(2019年11期)2019-07-04
中国特种设备安全(2019年1期)2019-03-13
北京航空航天大学学报(2018年1期)2018-04-20
红领巾·萌芽(2017年2期)2017-03-09
山东青年(2016年2期)2016-02-28
电视技术(2014年19期)2014-03-11
