
前列腺癌3种早期诊断预测模型效能比较
2023-08-04 03:49:04李姝婷骆仕俐李远盛许望东张俊辉
西南医科大学学报 2023年4期
李 翔 ,李姝婷 ,陈 容 ,骆仕俐 ,张 溪 ,李远盛 ,许望东,张俊辉
西南医科大学:1.公共卫生学院;2.科技处(泸州 646000)
前列腺癌(prostate cancer)是指发生在前列腺的上皮性恶性肿瘤,是最常见的男性泌尿生殖系统恶性肿瘤之一,占男性恶性肿瘤病死率的第2位[1-2]。据《全球癌症统计报告》数据显示[3]2020 年中国前列腺癌标化发病率为10.2/10万,标化死亡率为4.6/10万。目前,中国前列腺癌的总体发病率和死亡率低于世界水平,但前列腺癌的发病率和死亡率仍在不断升高[4],癌症顺位前移,其疾病负担有向年轻人群转移的趋势[5]。前列腺癌患者在发病早期往往缺乏典型的临床表现。早期诊断指标主要是前列腺特异性抗原(prostate special antigen,PSA),该指标具有器官特异性而非肿瘤特异性,在前列腺增生、前列腺炎和其他前列腺良性疾病中都可能会升高[6],导致前列腺癌过度诊断和过度治疗的风险很高[7]。因此,本研究首先采用单因素Logistic 回归初步筛选了前列腺癌的预测因子,并据此建立了Logistic 回归、Lagrangian 支持向量机(Lagrangian Support Vector Machine,LSVM)和随机森林模型三种前列腺癌早期诊断预测模型,再采用ROC 曲线对其预测效能进行比较,以探讨三种模型在前列腺癌早期诊断中的应用价值,为前列腺癌早期诊断提供理论支持。
1 资料与方法
1.1 数据来源
数据来源于临床医学科学数据中心(301 医院)的《前列腺肿瘤预警数据集》[8]。数据集包含基本信息表、诊断表、检查信息表、病理信息表、PSA信息表、生化检查表、导尿信息表、血常规信息表、放疗信息表、手术情况表、性腺激素表、药物信息表、膀胱镜信息表等。包括患者编号、检查结果标签、年龄、身高、体重、骨钙素、载脂蛋白A2、快速微量尿白蛋白/肌酐测定、磷脂、血清血白蛋白、α1 球蛋白、α2 球蛋白、β1 球蛋白、β2 球蛋白、γ 球蛋白、游离PSA、总PSA、钠、脑利钠肽前体、尿钠、钙、尿钙等共46项信息。
1.2 数据清洗
将该数据中前列腺癌预测的结果变量重新定义为有无前列腺癌(1=有,0=无)。把前列腺增生、前列腺癌、同时有前列腺增生和前列腺癌三类重新赋值为两类,其中前列腺增生归为无前列腺癌(0=无),前列腺癌和同时有前列腺癌和前列腺增生归为有前列腺癌(1=有)。由于原始数据中含有文字的数据不能导入SPSS 25.0,会导致数据的缺失,因此将数据中含有的文字删除,再对数据进行核实补充。将每个变量由小到大排序,根据逻辑关系判断各变量的极大值和极小值是否为异常值,结果发现有个别异常值存在。由于存在少量数据缺失和个别异常值,快速微量尿白蛋白/肌酐测定、骨钙素、脑利钠肽前体、α1球蛋白、α2球蛋白、β1球蛋白、β2球蛋白、γ球蛋白、尿酸、尿钠、尿钙、尿氯化物、尿磷、尿肌酐、肌钙蛋白T等19项变量被去除,剩余25 项变量。对信息清洗整理后分析得到数据库共有2 987例个案,其中前列腺癌个案222例,占7.4%;无前列腺癌个案2 765 例,占92.6%。考虑到样本含量较大,数据有少量缺失对模型比较结果影响有限,因此本文未作数据填补。
1.3 纳入和排除标准
本文研究对象的纳入标准为:①各项指标齐全;②诊断信息明确。排除标准为:①重复个案;②变量缺失过多。根据上诉纳入排除标准删除个案324 例,最终确定2 663 例研究对象,其中患前列腺癌个案数220例,对照组为未患前列腺癌个案数2 443例。
1.4 变量定义
变量赋值参考《前列腺癌筛查专家共识》[9]和《中国成人血脂异常防治指南》[10]。
1.5 统计学分析
将整理好的2 663例研究对象按7:3的比例随机划分为训练集和测试集,其中用来训练模型的训练集一共1 864例,用来测试模型的测试集一共799例。
采用SPSS 25.0 及SPSS Modeler client 进行数据整理及分析,基于训练集数据采用单因素Logistic 回归筛选前列腺癌的关联因素,并据此建立多因素Logistic 回归分析、LSVM模型和随机森林模型三个前列腺癌早期诊断预测模型,用验证集数据验证三个模型的预测准确性并用ROC 曲线下面积(area under curve,AUC)对三种模型的预测性能进行比较[11]。
1.5.1 LSVM 模型介绍 支持向量机(SVM)是一类有监督学习的广义线性分类器,是由VAPNIK 等提出的一种机器学习算法,能较好地解决小样本、高维数、非线性和局部极小点等实际问题[12]。SVM包括Proximal支持向量机(简称PSVM)和LSVM等,LSVM的精度优于其他模型,其分类效果在临床实践中也得到了广泛验证。
1.5.2 随机森林模型 随机森林算法是一种包含多个决策树的集成学习方法,以决策树为基学习器,运用Bagging 的方法进行集成,能显著提高基学习器的性能,具有算法精度高、能处理大规模数据和减少过拟合等优点,在特征选择和高维数据分析等领域已得到许多关注[13]。
2 结果
2.1 单因素Logistic回归分析
将训练集中的变量逐个纳入单因素Logistic 回归模型,结果显示血清白蛋白、乳酸脱氢酶、碱性磷酸酶、钠、肌酸激酶等无统计学意义(P>0.05)。年龄、磷脂、游离PSA、总PSA、钙、血清尿酸、载脂蛋白A1、载脂蛋白B、载脂蛋白C3 等指标有统计学意义(P <0.05),可以作为预测模型的备选指标进一步分析,见表1。
2.2 三种前列腺癌预测模型的建立
2.2.1 多因素非条件Logistic 回归分析 有序多分类的似然比结果见表2,可见载脂蛋白C3 的有序多分类变量似然比结果差异无统计学意义(P>0.05),应以分组线性变量形式纳入模型,其余变量以哑变量形式纳入模型,自变量赋值表见表1。将训练集中单因素分析后有统计学意义的变量纳入多因素非条件Logistic 回归经逐步向后回归(纳入标准为P <0.05,排除标准为P>0.1)筛除变量后,筛选出的主要影响因素为:年龄、肌酸激酶同工酶、游离PSA、总PSA,各影响因素P值及OR值见表3。
2.2.2 LSVM模型 利用训练集中单因素Logistic 回归筛选出的有统计学意义的变量建立LSVM 模型。结果显示,总PSA、年龄、载脂蛋白A1、磷脂、载脂蛋白B、甘油三酯、血清尿酸、游离PSA、肌酸激酶同工酶、载脂蛋白E为主要的影响因素。变量重要性排序见图1。

图1 LSVM模型预测变量重要性排序Figure 1 Importance diagram of LSVM predictive variables
2.2.3 随机森林模型 利用训练集中单因素Logistic 回归筛选出的有统计学意义的变量建立随机森林模型。结果显示,以变量重要性为顺序包括:载脂蛋白C3、磷脂、游离PSA、载脂蛋白B、载脂蛋白E、钙、血清尿酸、载脂蛋白A1、载脂蛋白C2、肌酸激酶同工酶。变量重要性排序如图2。

图2 随机森林模型预测变量重要性排序Figure 2 Importance of variables predicted by random forest plot
2.3 三种模型的预测效果比较
将建立好的三种模型用于测试集中做预测,结果显示,多因素非条件Logistic回归、LSVM 和随机森林的ROC曲线下面积(AUC)分别为:0.895(0.876,0.913)、0.918(0.902,0.934)、0.724(0.688,0.760),详见表4。LSVM 模型预测效果最好(AUC >0.9),而Logistic 回归模型和随机森林模型的AUC 在0.7~0.9 之间,拟合效果虽不如LSVM但效果仍可接受。预测结果的ROC曲线见图3。
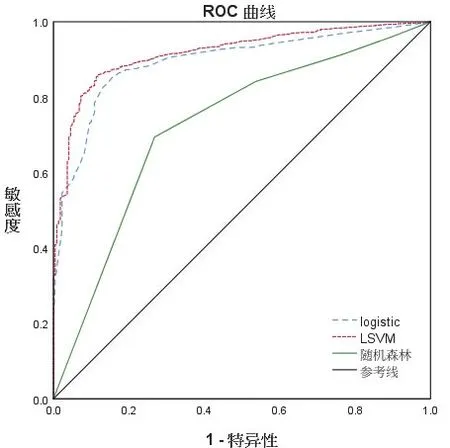
图3 三种模型的ROC曲线比较Figure 3 Comparison of ROC curves of the three models

表4 三种模型的ROC曲线下面积(AUC)比较Table 4 Comparison of area under ROC curve(AUC)among the three models
3 讨论
本研究采用单因素Logistic 回归初步筛选了前列腺癌的预测因子,并据此建立了Logistic回归、LSVM和随机森林三种前列腺癌早期诊断预测模型。其中,LSVM模型的AUC最高,提示如果用LSVM来建立前列腺癌早期诊断预测模型准确性可能会更高。三种模型筛选出的变量不全相同,随机森林预测效果欠佳,因此可将Logistic回归模型和LSVM两种方法的结果相互印证补充,结合专业知识确定前列腺癌的重要预测因子。Logistic回归模型和LSVM模型共同筛选出的预测因子为总PSA、游离PSA、年龄、肌酸激酶同工酶,这四个变量可作为前列腺癌的预测因子也在相关研究中得到过验证[14]。
PSA和年龄是公认的前列腺癌预测模型的重要预测因子,我们的研究也显示,PSA和年龄可能是预测模型最重要的两个预测因子。1994 年以来,PSA 广泛应用于前列腺癌的早期诊断、筛查、预后随访等方面,也是美国食品和药物管理局(FDA)批准的第一个肿瘤生物标志物[15-17]。年龄增大是前列腺癌最重要的不可控因素,随着年龄的增加,患前列腺癌的可能性也随之增加,年龄升高也常常伴随前列腺癌病理Gleason评分以及临床分期的明显升高[18-19]。因此老年人应作为前列腺癌的重点关注人群,在诊断时提高警惕。
本研究结果提示肌酸激酶同工酶CK-MB 是前列腺癌的重要预测因子。丁慧等[20]研究发现,前列腺癌患者CK 和CK-MB 含量较正常组均显著升高,其原因可能是由于人体免疫系统对于肿瘤组织和细胞的攻击从而导致其破裂释放出一定CK 及CK-MB 含量,因此一部分恶性肿瘤患者会出现血清CK及CK-MB含量升高的体征。
本研究也发现了一些具有争议性的预测因子,如载脂蛋白E、载脂蛋白C2、载脂蛋白C3 等。在既往的研究中,LIU 等[21]认为E4 基因及其等位基因与前列腺癌的发病和预后无关,但FARUK 等[22]的一项研究表明,载脂蛋白E影响前列腺癌发生和高Gleason 评分的出现,其可能是一个区分前列腺癌的生物标志物,我们的研究也支持了这一观点。
目前国外已有较多基于临床数据建立的前列腺癌早期诊断预测模型,如目前最常使用的两种风险预测模型为:前列腺癌预防试验风险计算器(PCPT-RC)模型、欧洲前列腺癌风险计算器筛查随机研究(ERSPCRC)模型;此外TOMLINS 等[23]基于Logistic 回归模型,利用血清PSA、PSAD 以及PCA3 等预测因子建立了前列腺评分系统。国内关于前列腺癌早期诊断预测模型的研究较少,且这些模型并未纳入如磷脂、载体蛋白等较易获得的生化检查指标;而目前已有研究[24]表明这些生化检查指标可能能够提高前列腺癌早期诊断的特异度和灵敏度。因此本研究在常规前列腺癌诊断预测因子的基础上,加入了这些容易获得的生化检测指标作为备选预测因子。研究结果显示,纳入了生化检查指标的LSVM模型与LEE等[25]建立的SVM前列腺癌诊断模型相比,拥有更高的AUC值。
本研究的不足之处:首先,由于国家临床医学科学数据中心(301 医院)提供的《前列腺癌数据集》有部分数据缺失,可能会对结果有一定的影响。另外,我们建立的前列腺癌预测模型只利用了测试集进行内部数据验证,是否可以外推至其他数据集还有待进一步验证。
4 结论
本研究利用国家临床医学科学数据中心(301 医院)的《前列腺肿瘤数据集》,筛选出年龄、PSA、肌酸激酶同工酶等前列腺癌早期诊断预测因子,并在此基础上构建了基于PSA 联合指标的多因素Logistic 回归模型、随机森林模型和LSVM 前列腺癌早期诊断预测模型。研究结果显示,LSVM 模型预测效果最好,多因素Logistic 回归模型预测效果尚可,随机森林模型的预测效果不佳。
猜你喜欢
冰雪运动(2021年1期)2021-07-28 07:12:46
安徽医专学报(2020年3期)2020-12-25 19:41:17
家庭医学(下半月)(2020年3期)2020-05-30 12:42:02
家庭医学(下半月)(2020年3期)2020-05-30 12:42:00
家庭医学(下半月)(2020年3期)2020-05-30 12:42:00
中国生殖健康(2019年7期)2019-01-06 09:27:34
当代医学(2015年35期)2015-08-01 00:23:02
医学研究杂志(2015年4期)2015-06-10 06:42:43
中国当代医药(2015年21期)2015-03-01 02:04:50
当代体育科技(2015年8期)2015-02-27 06:23:42
