
融合自注意力机制的入侵检测数据生成方法
2023-08-01 17:56:01张宣琦缪祥华张如雪李响
化工自动化及仪表 2023年2期
张宣琦 缪祥华 张如雪 李响


摘 要 针对传统入侵检测领域由于数据不平衡而出现少数类检测率低的问题,设计了一种基于条件生成对抗网络和CatBoost算法的数据生成模型(SA?WCGAN)。首先,采用CatBoost算法对原始数据集进行特征选择,减少模型训练时间。之后,利用SA?WCGAN生成模型进行数据扩充,解决数据不平衡问题,该生成模型引入自注意力机制(SA),提取攻击样本的全局特征,提高少数类攻击样本生成的质量;同时,引入Wasserstein距离和梯度惩罚,提高模型训练过程的收敛速度和稳定性。实验结果表明:在公开基准数据集NSL?KDD上,SA?WCGAN生成模型在只有少数样本的攻击类型上具有较高的精确率、召回率和F1分数。同时,与现有5种方法的比较分析也证实了该模型的优越性。
关键词 入侵检测 SA?WCGAN生成模型 自注意力机制 数据增强 少数类攻击 数据不平衡 Wasserstein距离 梯度惩罚
随着网络安全威胁日益严重,入侵检测作为一种可以有效识别恶意攻击的防御手段,被广泛应用于目前复杂的网络环境。同时,由于机器学习能够针对不同情境进行精确的预测分析,能够准确检测到攻击类型,因此机器学习在现代入侵检测系统中起着至关重要的作用。机器学习模型的学习能力大多依赖所提供的样本数量,然而现实网络安全防御场景中,网络检测数据很少,同时大部分类型的攻击都是罕见的,因此入侵检测数据训练样本会出现少数类的现象,从而影响模型学习效果。
为了解决少数类的问题,目前的研究大多集中在以下两种方法:一种是算法的改进,保留原始数据的分布特征和数据数量的同时,对分类思想采取优化和改进,如代价敏感学习、集成学习[1]等;另一种是利用数据采样改变原始数据分布,以增加少数类所占比例,主要通过过采样、欠采样或两者融合的方式实现。
过采样技术是增加少数类数量最常用最简单的方法,通过对少数类样本进行复制采样来提高少数类所占比例,实现较为简单,但容易出现过拟合现象。另一种方法是采用线性插值方法生成少数类,虽然能解决过拟合问题,但该方法主要解决了二分类情况下的数据不平衡问题,很难解决多分类场景中存在少數类的问题[2]。在这种情况下,生成对抗网络(Generative Adversarial Networks,GAN)在数据平衡情境下发挥了极为重要的作用,并且与传统数据生成方法相比,基于纳什均衡理论的GAN更能生成真实的样本,还能从复杂的概率分布中进行采样,生成足够接近真实的新数据样本。同时,基于GAN的数据生成方法可以有效处理恶意流量带来的数据不平衡问题[3]。而条件生成对抗网络(Conditional generative adversarial network,CGAN)[4]在GAN的基础上加入了条件变量(如类别标签),降低了生成样本的不确定性,同时也可以采用条件变量来约束模型生成所需样本。
本课题重点采用数据采样技术解决少数类问题。首先针对原始数据集采用CatBoost算法进行特征选择,并在CGAN模型的基础上进行改进,加入Wasserstein距离和梯度惩罚,同时在CGAN模型的生成器中引入自注意力机制(self?attention,SA)来减少训练时间,使得模型训练更加稳定,并且提高了样本的生成质量。本课题的改进工作主要解决了入侵检测中样本特征冗余和少数攻击样本检测困难的问题。
1 相关工作
学者们提出了基于统计模型和机器学习的方法来解决存在少数类导致数据不平衡的问题,最简单的就是欠采样技术[5]和过采样技术。欠采样技术的局限性在于丢弃数据时,可能会导致丢失潜在的有用信息。过采样技术则会导致过度拟合[6],但由于容易实现,仍被大量应用于入侵检测领域,用于提高对少数攻击类型的检测精度。
文献[7]将随机过采样SMOTE技术和欠采样技术结合,用于异常检测领域合成少数攻击类样本,在该文献中,通过采用当前流行的机器学习算法来衡量SMOTE欠采样的有效性,如支持向量机(SVM)、决策树、随机森林、神经网络和K?means。文献[8]针对网络流量存在冗余特征、数据分布不均衡等问题,结合LightGBM提出一种基于自动编码器和LightGBM的网络入侵检测模型AE?LightGBM,首先通过Borderline?SMOTE优化数据分布,使得少数类和多数类的权重得到有效设置,然后采用自动编码器(AE)选取特征减少了特征冗余,最后使用LightGBM模型对处理后的数据进行训练,该模型相较于传统模型具有更高的精确率和正确率。文献[9]针对由于入侵检测数据集的类不平衡导致分类器对少数类检测精度低的问题,提出SMOTE和高斯模型相结合的欠采样技术,并使用CNN对数据集进行分类,该模型在UNSW?NB15和CICIDS2017两个数据集上都相较于其他数据不平衡处理方法和分类方法有较高的准确率。
GAN作为一种数据生成方法,在入侵检测领域被证明是行之有效的方法。文献[10]对CGAN进行改进,引入KL散度代替原始的JS(Jensen?Shannon)散度,以确保模型生成的数据能足够接近原始数据,该模型在NSL?KDD和UNSW?NB15数据集上被证明为有效的,但该模型依旧存在过拟合和训练不稳定的问题。文献[11]为了减少数据生成模型训练带来的开销,采取判别器和生成器不进行同步训练的方法,对生成器进行更严格的训练迭代,以生成更可靠的数据,该数据集与真实流量样本非常相似,有效消除了由于过度训练判别器而带来的开销,并将编码器引入生成器中,学习数据低维特征表达,该模型在NSL?KDD和CIC?DDoS2019数据集上的F1分数分别达到了92%和99%,但是该模型无法针对特定的攻击类型进行数据生成。
鉴于GAN在入侵检测领域的显著效果,笔者设计了SA?WCGAN攻击样本生成模型,以期有效处理入侵检测领域中存在少数类的问题。
2 相关理论及方法
2.1 生成对抗网络
原始的GAN通过轮流对生成器和判断器进行训练,使其相互对抗,以此不断优化判别器和生成器,最后实现纳什平衡。同时,GAN可以通过学习真实的数据分布来生成与训练集具有相似统计信息的新数据,其目标函数为:
其中,θ为生成器参数;θ为判别器参数;E为期望;x为从真实数据P中采样;D(·)为判别器判断为真实数据的概率;x为从生成数据P中采样得到的数据,x=G(z),z~N(0,I)为服从高斯分布的随机噪声向量,G(z)为生成的数据。
然而GAN只根据噪声生成数据,但无法控制数据生成类别。因此,CGAN在生成器和判别器中加入条件变量c,如分类标签,来减少GAN的不确定性。同时,CGAN可以根据条件变量c控制生成器生成特定数据,其目标函数为:
然而,传统的生成对抗网络(GAN)存在梯度消失、训练时梯度不稳定及模型崩溃等问题,即判别器过于强大时,在训练生成器时无法提供有意义的梯度。Wasserstein GAN(WGAN)则对传统GAN的损失函数进行了改进,有效地解决了梯度消失等问题。
2.2 WGAN
由于传统GAN中采用的JS(Jensen?Shannon)散度容易导致模型训练不稳定等问题,因此WGAN模型[12]采用Wasserstein距离代替JS散度,以此衡量生成器生成样本与真实样本之间的距离,其将传统GAN的目标函数改写为:
式(3)与式(1)不同的是,WGAN中生成器和判别器的损失函数都不使用对数函数,同时,判别器的输出也不采用Sigmoid激活函数,而是使用1?Lipschitz对其进行约束,算式如下:
根据文献[16]将系数γ初始化为0。同时,最终的输出也会在下一个注意力机制网络中继续进行特征提取与学习。
2.5 CatBoost算法
CatBoost是PROKHORENKOVA L[17]和DOROGUSH A V[18]等提出的一种新的梯度提升算法,该算法能以最小的损失处理类别型特征。
CatBoost不同于其他梯度提升算法,首先,该算法采用排序提升算法来解决目标泄露的问题;其次,该算法能有效处理类别型特征;同时,CatBoost算法采用對称二叉树作为基模型,克服了预测过程较慢的问题。CatBoost已经成功应用于各种类型和格式的数据,如时间序列数据[19]、金融领域[20]等。
2.6 特征重要性评估
CatBoost模型训练时,能够采用某个评价指标获取特征系数或重要性,如使用预测值变化(Prediction Values Change,PVC)和损失函数变化(Loss Function Change,LFC)对数据集中的特征进行排序[21]。
PVC显示的是如果当前特征的值产生变化,相应的预测值平均会发生多少变化。假设该特征越重要,其值产生变化时,相应的预测值的平均变化就越大。在CatBoost模型内默认采用PVC算法。
LFC表示的是具有某个特征和不具有该特征的模型之间损失值的差异,通常用于排序模型。
本课题基于PVC对数据集特征进行排序选择。计算方法是:在建树过程中,通往叶子对的路径上的节点上包含不同的分割值,假如符合分割条件(该条件取决于特征F),则对象转到左子树,否则为右子树。同时,还需考虑特征间的组合。特征F的重要度featureimportanceF的计算式如下:
其中,trees为树节点;leafsF为叶子节点;avr为左右叶子节点的加权平均值;c、c分别为左叶子节点和右叶子节点中对象的总权重,假设该权重没有特别设置,那么该权重为每个叶子节点中对象的数目;v、v表示左叶子节点和右叶子节点的取值。
3 基于SA?WCGAN的入侵检测数据生成模型
基于SA?WCGAN的入侵检测数据生成模型主要包含数据处理及特征工程模块、数据生成模块和机器学习模型分类模块。首先,为了减少冗余特征,减少GAN网络的训练时间,采用CatBoost特征重要性评估方法进行特征选取;然后,利用SA?WCGAN数据生成模型生成少数攻击样本,提高检测准确率;最后,采用机器学习模型对攻击样本进行分类。模型的基本架构如图1所示。
本课题采用的基模型为CGAN,为了保证模型训练的稳定性和收敛速度,在模型中引入Wasserstein距离以代替JS距离,同时采用梯度惩罚解决训练过程中梯度消失的问题。为了提高生成样本质量,在生成器中引入自注意力机制。
3.1 生成器总体网络
本课题提出少数攻击样本生成模型的生成器结构以DCGAN[22](deep convolutional generative adversarial network,DCGAN)模型中的生成器为基准框架。同时,本模型在第1反卷积块和第2反卷积块中加入自注意力机制模块,提取攻击样本的全局特征。该生成器采用BatchNormalization层加速模型训练,保证训练的稳定性;同时使用ReLU作为激活函数,最后一层使用Tanh激活函数。生成器的网络结构见表1。
3.2 判别器总体网络
本课题采用的判别器结构是卷积神经网络(convolutional neural network,CNN),其网络中采用了LeakyReLU激活函数,并将其负值斜率设置为α=0.2。同时加入Dropout层,防止模型出现过拟合。判别器的网络结构见表2。
4 仿真结果与分析
4.1 数据集
本课题采用的数据集为NSL?KDD,该数据集是对KDD?99的改进,不包含冗余和重复记录,因此将其作为评估入侵异常检测模型的基准数据集[23]。NSL?KDD数据集包含41个特征和4种类型的异常攻击,分别为拒绝服务攻击(Dos)、探测攻击(Probe)、远程侵入(R2L)和获取权限(U2R)。NSL?KDD测试集和训练集的数据分布见表3,可以看出,该数据集也存在明显的类不平衡情况,Probe、R2L和U2R攻击在训练集中所占比例分别为9.25%、0.79%、0.041%,在测试集中所占比例分别为10.74%、12.22%、0.89%,判断为少数类。
通过对数据集中少数类型攻击进行过采样来增加攻击数量,过采样前、后的数据分布见表4。
4.2 特征选择
采用基于CatBoost特征的重要性评估实现特征选择过程,从而减少生成模型训练模型。进行特征选择后,NSL?KDD数据集的特征子集共21个,即
duration、protocol_type、flag、src_bytes、dst_bytes、wrong_fragment、hot、logged_in、root_shell、count、srv_count、serror_rate、srv_serror_rate、rerror_rate、diff_srv_rate、dst_host_same_srv_rate、dst_host_diff _srv_rate、host_same_src_port_rate、dst_host_serror _rate、dst_host_srv_serror_rate、dst_host_rerror_rate。
4.3 评价指标
少数攻击类型样本生成是为了提高入侵检测模型的准确率,因此通过衡量入侵检测性能来进一步衡量SA?WCGAN入侵监测数据生成模型的性能。
本课题采用3种评价指标对模型性能进行衡量,即精确率(Precision)、召回率(Recall)和F1分数(F1?score)。精确率是判定为攻击的样本中真正为攻击所占的百分比;召回率是在全部攻击样本中被正确判定为攻击的比例;F1分数是结合了精确率和召回率的综合指标。计算式分别为:
其中,TP为真阳性,FP为假阳性,FN为真阴性,FP为假阳性。
4.4 实验结果及分析
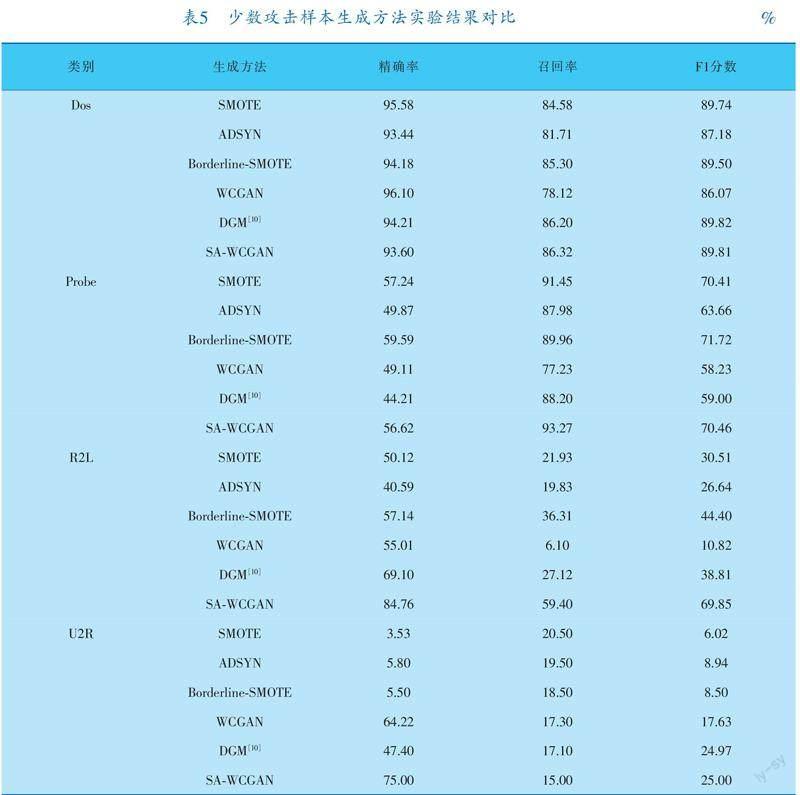
CatBoost是一种梯度提升算法,在处理数据不平衡方面有很好的效果[24]。因此,本课题采用CatBoost构建分类器。同时,为了进一步证明本课题提出的少数攻击样本生成方法的综合性能,在相同实验条件下,与已有的4种数据平衡算法以及文献[10]的算法进行对比,结果列于表5。
由表5可以看出,在与其他数据平衡算法进行比较时,SA?WCGAN数据平衡算法在Probe和R2L两种攻击类型上的精确率、召回率和F1分数3项指标都追平或超过其他的方法;对于Dos攻击类型,SA?WCGAN数据平衡算法虽在精确率上落后于SMOTE、Borderline?SMOTE和DGM(1.98%、0.58%和0.4%),但在F1分数上都持平或高于其他数据平衡算法;对于U2R攻击类型,SA?WCGAN数据平衡算法虽然在召回率上落后于其他方法,但在精确率和F1分数上均高于其他算法。
结合上述分析可知,SA?WCGAN生成模型在少数类数据生成方面能够达到较高的性能,即能够生成较高质量的样本,具备了一定的实用价值。
5 结束语
在入侵检测领域,由于数据分布不均衡而导致少数攻击类型的检测率低,并且影响机器学习模型的性能。因此,本课题提出SA?WCGAN数据生成模型来生成入侵检测领域的少数类数据,SA?WCGAN可以以少数类为条件对数据进行采样,提高了机器学习分类器对少数类的检测率。本课题的改进工作主要解决了入侵检测中样本特征冗余和少数攻击样本检测困难的问题,主要贡献如下:
a. 在CGAN中引入Wasserstein距离代替JS散度,同时又引入梯度惩罚,解决了原始CGAN模型训练中梯度消失的问题;
b. 引入自注意力机制,提高了少数攻击样本生成的质量和性能,在一定程度上提高了少数攻击样本的检测率;
c. 采用基于CatBoost的特征重要性评估方法进行特征选择,去除了数据中的冗余特征,缩短了模型训练时间,提高了分类精度。
在公开的基准数据集NSL?KDD上进行实验,与已有的5种数据平衡算法进行对比,结果显示,SA?WCGAN生成模型在少数类生成上能够达到较高的检测性能。
在未来的研究中,会进一步将该入侵检测模型应用于实际流量场景中,使其在实际应用中发挥更大的价值。同时,由于SA?WCGAN存在训练时间较长的问题,还将持续研究,以缩短训练时间。
参 考 文 献
[1] KIM J,KANG J,SOHN M.Ensemble learning?based filter?centric hybrid feature selection framework for high?dimensional imbalanced data[J].Knowledge?Based Systems,2021,220:106901.
[2] ZHU T,LIN Y,LIU Y.Synthetic minority oversampling technique for multiclass imbalance problems[J].Pattern Recognition,2017,72:327-340.
[3] ANDRESINI G,APPICE A,DE ROSE L,et al.GAN augmentation to deal with imbalance in imaging?based intrusion detection[J].Future Generation Computer Systems,2021,123:108-127.
[4] LEE J,PARK K.AE?CGAN model based high performance network intrusion detection system[J].Applied Sciences,2019,9(20):4221.
[5] HASANIN T,KHOSHGOFTAAR T.The effects of random undersampling with simulated class imbalance for big data[C]//Proceedings of the 2018 IEEE International Conference on Information reuse and Integration(IRI).Picataway NJ:IEEE,2018:70-79.
[6] LAST F,DOUZAS G,BACAO F.Oversampling for imbalanced learning based on k?means and smote[J].arXiv Preprint arXiv:171100837,2017.
[7] DIVEKAR A,PAREKH M,SAVLA V,et al.Benchmar? king datasets for Anomaly?based Network Intrusion Detection:KDD CUP 99 Alternatives[C]//Proceedings of the 2018 IEEE 3rd International Conference on Computing,Communication and Security(ICCCS).Prcataway NJ:IEEE2018:1-8.
[8] YAO R,WANG N,LIU Z,et al.Intrusion detection system in the Smart Distribution Network:A feature engineering based AE?LightGBM approach[J].Energy Reports,2021,7:353-361.
[9] LIU J,LI T,XIE P,et al.Urban big data fusion based on deep learning:An overview[J].Information Fusion,2020,53:123-133.
[10] DLAMINI G,FAHIM M.DGM:A data generative mod? elto improve minority class presence in anomaly detection domain[J].Neural Computing and Applications,2021.
[11] XU W,JANG?JACCARD J,LIU T,et al.Improved Bidirectional GAN?Based Approach for Network Intrusion Detection Using One?Class Classifier[J].Computers,2022,11(6):15-22.
[12] ARJOVSKY M,CHINTALA S,BOTTOU L.Wasserstein generative adversarial networks[C]//Proceedings of the International Conference on Machine Learning.PMLR,2017:214-223.
[13] GULRAJANI I,AHMED F,ARJOVSKY M,et al.Improved training of wasserstein gans[J].Advances in Neural Information Processing Systems,2017,30(2):27-33.
[14] NIU Z,ZHONG G,YU H.A review on the attention mechanism of deep learning[J].Neurocomputing,2021,452:48-62.
[15] VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all you need[J].Advances in Neural Information Processing Systems,2017,30(4):66-78.
[16] ZHANG H,GOODFELLOW I,METAXAS D,et al.Self?attention generative adversarial networks[C]//Proceedings of the International Conference on Machine Learning.PMLR,2019:7354-7363.
[17] PROKHORENKOVA L,GUSEV G,VOROBEV A,et al.CatBoost:Unbiased boosting with categorical features[J].Advances in Neural Information Processing Systems,2018,31(1):72-80.
[18] DOROGUSH A V,ERSHOV V,GULIN A.CatBoost:Gradient boosting with categorical features support[J].arXiv Preprint arXiv:181011363,2018.
[19] SUN H,HE J,CHEN Y,et al.Space?Time Sea Surface pCO2 Estimation in the North Atlantic Based on CatBoost[J].Remote Sensing,2021,13(14):2805.
[20] XIA Y,LIU C,LI Y,et al.A boosted decision tree approach using Bayesian hyper?parameter optimiza? tion for credit scoring[J].Expert Systems with Applications,2017,78:225-241.
[21] DHANANJAY B,SIVARAMAN J.Analysis and classification of heart rate using CatBoost feature ranking model[J].Biomedical Signal Processing and Control,2021,68:102610.
[22] YANG J,LI T,LIANG G,et al.A simple recurrent unit model based intrusion detection system with DCGAN[J].IEEE Access,2019,7:83286-83296.
[23] MEENA G,CHOUDHARY R R.A review paper on IDS classification using KDD 99 and NSL KDD dataset in WEKA[C]//Proceedings of the 2017 International Conference on Computer,Communications and Electronics (Comptelix).Piscataway NJ:IEEE,2017:553-558.
[24] TANHA J,ABDI Y,SAMADI N,et al.Boosting methods for multi?class imbalanced data classification:An experimental review[J].Journal of Big Data,2020,7(1):1-47.
(收稿日期:2022-09-04,修回日期:2022-12-14)
Intrusion Detection Data Generation Method withSelf?attention Mechanism
ZHANG Xuan?qia, MIAO Xiang?huaa,b , ZHANG Ru?xuea, LI Xianga
(a. Faculty of Information Engineering and Automation; b. Yunnan Provincial Key Laboratory of Computer Technology Application, Kunming University of Science and Technology)
Abstract Aiming at the low detection rate of minority classes caused by the existence of data imbalance in the current traditional intrusion detection field, a data generation model (SA?WCGAN) based on condition? al generative adversarial network and CatBoost was designed. Firstly, CatBoost algorithm was adopted to select features of the original dataset so as to reduce model training time; secondly, the SA?WCGAN generative model was used for data expansion to solve data imbalance. The generative model introduced a self?attention mechanism (SA) to extract global features of the attack samples so as to improve performance of the minority class of attack samples; meanwhile, the Wasserstein distance and gradient penalty were introduced to improve convergence speed and stability during the model training. Experimental results show that, on the public benchmark dataset NSL?KDD, the SA?WCGAN generative model proposed in this paper has high precision, recall and F1 score on attack types with only a few samples. Furthermore, comparative analysis with existing five methods confirmed the superiority of the model proposed.
Key words intrusion detection, SA?WCGAN generative model, self?attention mechanism, data enhancement, minority class attack, data imbalance, Wasserstein distance, gradient penalty
中图分类号 TP393.08 文献标识码 A 文章编号 1000?3932(2023)02?0199?08
作者简介:张宣琦(1998-),硕士研究生,从事信息安全、入侵检测的研究。
通讯作者:缪祥华(1972-),副教授,从事信息安全、网络安全的研究,xianghuamiao@126.com。
引用本文:张宣琦,缪祥华,张如雪,等.融合自注意力机制的入侵检测数据生成方法[J].化工自动化及仪表,2023,50(2):199-206.
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
应用数学(2020年2期)2020-06-24 06:02:50
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
