
基于RFM模型的信用卡客户特征自动挖掘方法研究
2023-08-01 09:51:58铁锦程
上海管理科学 2023年4期
关键词:数据挖掘
铁锦程

摘 要: 基于数据驱动的决策已经成为信用卡客户经营的关键,各类业务场景中的决策需要大量的客户深层次特征,同时对特征的可解释性有较高的要求。论文借鉴RFM模型和蒙特卡洛思想,提出了一种自动构造特征、智能筛选特征的数据挖掘方法,并以客户风险识别模型为场景进行了实验验证。结果表明,基于RFM模型的自动化数据挖掘方法,一方面能够提高特征挖掘的效率,发掘更深层次的复合特征,提升模型的识别能力;另一方面产出的特征可溯源、可解释,能更好地帮助业务人员理解模型的结果。
关键词: 数据挖掘;RFM模型;自动特征构造;智能筛选
中图分类号: TP 391
文献标志码: A
Tapping the Automatic Mining Method of Credit CardCustomer Features Based on RFM Model
TIE Jincheng
(Shanghai Pudong Development Bank, Shanghai 200120, China)
Abstract: Data-driven decision-making has become critical to credit card customer operations. Decision-making in various business scenarios requires a large number of deep-level features of customers, and has high requirements for the interpretability of features. In this paper, based on the RFM model and the Monte Carlo method, a data mining method is proposed to automatically construct and intelligently filter features. A numerical experiment is carried out with the customer risk identification model scenario. The results show that the automatic data mining method can improve the efficiency of feature mining and discover deeper composite features. It is also able to improve the recognition ability of the model to help people understand the results of the model.
Key words: data mining; RFM model; automatic feature construction; intelligent filtering
1 特征工程現状及问题
1.1 特征工程重要性
分析建模一般包括数据清洗、特征构造、筛选、模型训练、部署和监控等步骤,其中数据清洗、特征构造、筛选的过程称为特征工程。在分析建模中,特征工程是非常重要的环节,目的是尽可能地从原始数据中提取信息供算法使用。“数据和特征决定着机器学习模型的上限”,机器学习算法结果的好坏在很大程度上取决于特征质量,因此在机器学习模型算法和参数配置相同的情况下,特征的微小变化都可能对预测结果产生较大的影响。同时,特征工程也是一项复杂并耗时的活动,往往需要人工花费大量的时间参与,且高度依赖工程师的业务经验和直觉。
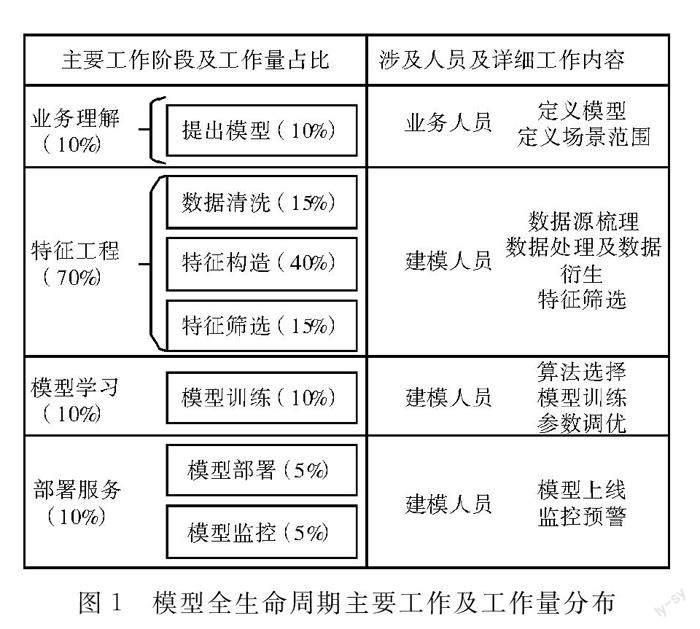
图1展示了一般情况下建模全流程中的主要工作内容及工作量分布,特征工程占到全部工作的70%左右,是非常重要的一环。
1.2 特征工程的现状及问题
当前,特征工程工作大多仍采用人工方式。人工方式由建模人员依靠其领域内的专业知识,通过迭代试错、模型评估等方法来进行。这种方法具有非常大的局限性:一是加工的数据源始终局限在自己的认知范围,很难在有限的时间内从更多角度、维度发现客户的特征并加以构造,导致无法跟上客户的行为变化;二是挖掘层次低,较难进行深层次的特征挖掘,难以有效地挖掘客户潜藏的特征;三是人工加工费时费力,需要开发大量的代码和脚本,逻辑设计、特征梳理中很大一部分工作是重复的,得到的特征还需验证之后才能使用。同时随着数据量的持续爆炸式增长,人工特征的构造速度已经远远跟不上数据的发展规模,长尾数据也很难得到有效挖掘,且随着建模人员的流失,好的特征构造经验也很难得到传承。
由于特征工程的重要性,而人工特征挖掘限制较多,不少公司、组织开始尝试用深度学习方式来实现自动特征挖掘。这种方式是通过大数据深度学习技术,通过预制的算子来实现特征的自动产出。但其也存在一些问题:一是无效特征多,由于采用固定的方法和算子,挖掘出来的不少特征只是数据间的简单运算,很多特征无实际含义,无法发挥实效;二是深度学习产出的特征可解释性较差,难以满足监管要求。因此,深度学习自动产出的特征难以直接应用于金融领域。
2 基于RFM模型的自动数据挖掘方法研究
2.1 RFM模型简介
RFM 模型是客户关系管理的常见分析模型,是衡量客户价值的一种常见方法。RFM 模型包括近度R (recency)、频度F (frequency)以及金额M (monetary)三个参数。R表示用户最近一次消费时间点距离分析时间点的时间间隔; F 表示在一段时间内用户的交易次数; M 表示在一定时间内用户消费的总金额。
RFM模型思路清晰、操作简单,且能够快速区分出不同价值的客户群体,在客户价值的分析中较实用。
2.2 深度特征合成算法简介
深度特征合成算法(Deep Feature Synthesis, DFS)是一种能够直接从关系型数据库中自动提取信息,并转化有意义的交叉特征的方法。该方法基于原始数据信息,按照一定的顺序应用数学逻辑创造出新的特征。因为衍生是有顺序的,且衍生可以是多层次的,所以产出的特征是有深度且可以解释的。
算法的输入是一系列有关系的实体组合,如E1,2,…,K表示有K个实体的数据集,xki,j表示第k个实体第i个实例特征j的值。算法最终衍生出三种类型的特征:实体特征efeat、直接特征dfeat、关系特征rfeat,三类特征的产生方式如下:
1)efeat: 实体本身的特征,由实体中的每个值推导出新的特征,推导过程可由公式(1)表示:
xi,j′=efeat(x:,j,i)(1)
2)dfeat: 用于两个具有前向关系(多对一)的实体之间,可直接进行转换,即对于属于实体Ek的特征(i∈Ek) 可直接转化成实体El的特征(m∈El)。
3)rfeat: 用于两个具有后向关系(一对多)的实体之间,即在实体El中进行聚合操作,得到Ek中一系列新的特征,聚合条件为ek=i,转化过程可由公式(2)表示:
xki,j′=rfeat(xl:,j|ek=i(2)
最终衍生出的特征数量zi可由公式(3)表示:
zi=(e·j)∑iu=0[(r·m+n)u·(e+1)u](3)
式中 i表示迭代次数;e表示efeat的个数;r表示rfeat的个数;n、m表示前向关系和后向关系的个数。
2.3 基于RFM模型的自动数据挖掘思路
本研究借鉴了RFM模型,并对参数R、F、M的含义进行了拓展。新方法中各参数的含义见表1,其中R代表时间、间隔等时间类特征,F代表次数、频次等特征,M代表金额、数量、期数等数值类特征。
为使特征自动化产出,本研究引入了算子的概念。将数据分析人员常用的特征挖掘逻辑,即变量之间的运算关系,加工为一段固定代码,形成一个函数,该函数就被称为算子。一个完整的算子包含如下几个部分,见表2。
整体衍生过程思路如下:将处理后的基础数据划分成R、F、M不同类别,随后调用算子衍生出各类别的基础特征,此类的组合是有顺序的,一般是R类、F类、M类单独,或R类和F、M类的组合,衍生出R类、F类、M类、RF类、RM类等各类别基础特征,如R类特征“上次交易距今时间”、M类特征“金额是否大于100”、RF类特征 “近一个月交易次数是否大于5次”等。然后通过不同基础特征间的随机交叉组合,衍生出大量的交叉特征,如RF类特征“近一个月交易次数大于5次”和RM类特征“近一个月交易金额大于1000元”交叉组合成RFM类特征“近一个交易金额大于5次且交易金额大于1000元”。同时基础特征、一层交叉特征及新产生的交叉特征之间还可以进行随机交叉组合,衍生出更多、更深层次的特征。整个衍生过程中按照DFS算法进行有序的特征衍生,这样可通过衍生层次的控制,挖掘更多潜藏的客户特征。衍生思路如图2所示。
3 基于RFM模型的自动数据挖掘过程
3.1 总体方案
图3展示了基于RFM模型的自动数据挖掘总体流程,整体分为三个阶段:一、数据梳理,包含数据清洗、行为数据分类两个步骤,是对数据进行的整理和归类工作,便于之后进行特征挖掘;二、特征构造,是特征挖掘的核心阶段,包含算子开发和特征衍生两个步骤;三、特征筛选,过滤出更加有用、区分度高、鲁棒性强的特征,便于后续模型调用。
3.2 数据梳理
数据梳理阶段,主要是对数据的前期整理工作,包含数据的清洗和归类,最终梳理出有用且归类好的数据用于后续的特征挖掘。同时,对数据进行维度分类,将杂乱无章的数据进行细分,使产生的特征具有业务含义,使得后续的特征挖掘在有序的空间内进行。这样的特征衍生是有序的,避免暴力衍生的发生。
3.2.1 数据清洗
数据的预处理工作,主要操作如下:
1)无效数据剔除:如全空值数据、全唯一值数据等。
2)数据类型识别:识别数据的基础类型,如布尔型、数值型、枚举型、时间型和文本型等。
3)空值填充:数值型填充为平均值,其余类别数据填充为-999999。
4)数据处理:将时间型数据转换为标准时间,文本型数据进行分词等。
5)数据标准化:对数值型数据进行归一化处理等。
3.2.2 行为数据分类
在得到干净的数据后,依据数据描述的行为类型,对数据进行分类。根据信用卡数据的特点,将数据分成交易类、埋点类等不同大类,每个大类又包含多个小类。表3为部分分类示例。
3.3 自动特征构造
特征构造是自动特征工程中的核心部分,也是自动特征工程中的难点。在得到清洗且分类好的数据后,基于RFM衍生框架和算子匹配,得到大量、有序、有深度且可解释的基础特征和衍生特征。
3.3.1 算子構造
算子固化了建模人员特征加工的经验,将其转化为固定程序,实现了特征的自动挖掘和衍生,大幅提升了特征生成的效率。当前已梳理加工八大类219个算子,算子类型及示例如表4所示。
3.3.2 基于RFM模型的交叉特征衍生
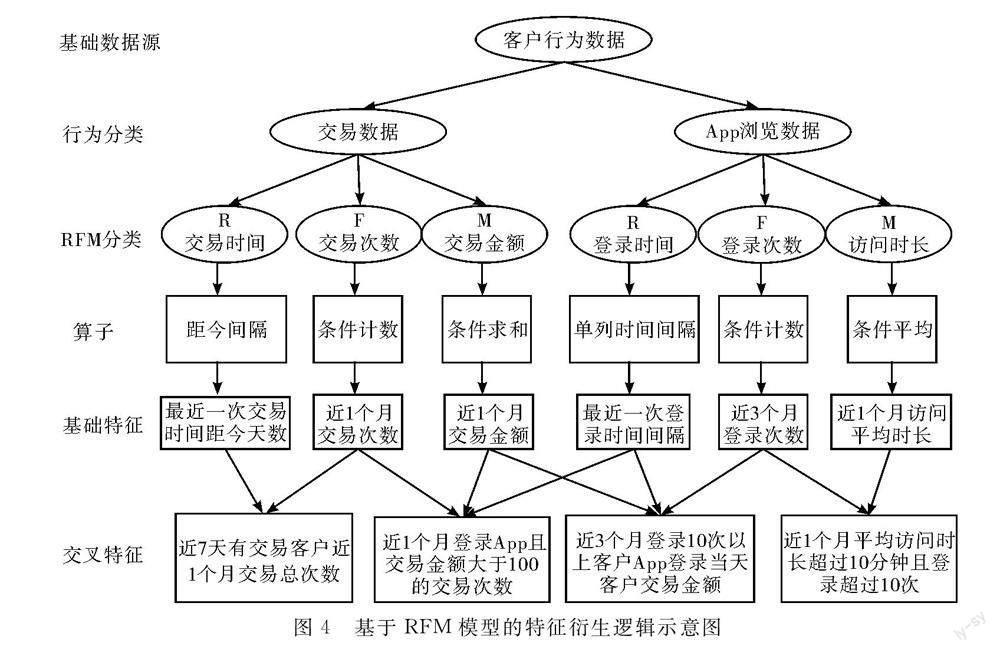
在得到清洗过且分类好的数据后,进一步按照RFM模型,将数据划分成R、F、M等不同类别,并调用算子生成基础特征;随后在RFM的框架下,按照DFS算法随机且有序地生成大量交叉特征。
表5与表6分别是用户交易数据和app浏览数据的部分字段示例。图4为利用基于RFM模型的自动特征衍生方法特征生成路径演示。
这种基于RFM模型框架下衍生机制的主要好处有:
1)特征衍生是有序的:交叉特征衍生基于RFM框架和DFS算法,通过不同类别特征间的有序组合,避免大量杂乱无章的特征衍生,所产生的特征都是有逻辑的。
2)特征衍生是大量的:特征间的组合是随机的,这就保证能充分利用所有数据,尽可能全面地挖掘客户所有特征。
3)特征衍生是有深度的:可通过控制交叉特征衍生的层次,实现特征挖掘的深度,尽可能发掘客户潜藏的信息。
4)产生的特征是可解释的:由于特征已按信息维度和指标维度进行分类,且数据间的衍生组合是有顺序、有逻辑的,这就保证每个产出的特征都可以翻译成业务逻辑,都是可以解释的。
3.4 智能特征筛选
特征筛选也是非常重要的一个环节,能够降低特征维度、减少数据冗余,保留更有效的特征。由于金融业务场景中数据特征维度较大,存在大量无关或冗余的特征,这些特征对模型的性能没有贡献,甚至会降低模型的效果,因此需要筛选更有用、区分能力更强的特征,减少特征维度和模型复杂度,在增强模型性能的同时降低计算迭代成本。本研究通过统计指标筛选和模型筛选来筛选出有效的特征。其中,统计指标筛选包括极值、缺失值、分位数、信息值IV等统计量指标过滤出有效的特征;模型筛选是对训练样本随机抽取并建立模型,通过模型群自动筛选入模特征。
由于在建模过程中使用的是历史数据集训练模型,而随着不同时间段策略、政策等因素的变化,人群结构也发生变化,这使得很多特征虽然在总体训练集、测试集、跨时间验证集上的效果很好,但策略发生变动后,特征的稳定性和区分度变差。因此,本研究创新性地引入多模型筛选方法,可以解决特征在不同切片数据源上不稳定的问题,使得最终产出的特征在满足区分能力的前提下稳定性更好,在不同场景、不同数据集上的鲁棒性更强。
该方法的理论基础是蒙特卡洛法。蒙特卡洛法的基本思路是,为了求解问题,首先建立一个随机过程,使随机过程的参数或特征等于问题的解,然后通过抽样实验来计算这些参数或特征,最后给出所求解的近似值。在计算仿真中,通过构造一个系统性能近似概率模型,并进行随机试验,可以模拟系统的随机特性。具体做法如下:
1)将训练数据按7∶3切分成训练集和测试集。
2)每随机切割一次训练集和测试集,进行模型训练,统计训练后的入模特征、特征的重要性及特征的假设检验,剔除不满足的特征。
3)重复第二步,统计各特征的入模次数并结合假设检验,剔除不满足条件的特征,利用最终特征集训练模型,若测试集和训练集区分度最优且各性能指标稳定,说明模型训练收敛。
4)进行跨时间验证,检验特征在跨时间训练集上的稳定性,若不稳定,结合具体特征并按照同样的方式切割数据,重复步骤1~3,直至模型收敛。
特征筛选的流程如图5所示。
4 效果分析
本文设计的客户特征自动挖掘方法已经在卡中心多个客户经营场景下得到了应用,在此我们以客户风险识别场景为例,来验证自动挖掘方法的效果。
客户风险识别场景是指在客户申请信用卡时决策是否接受客户准入的环节。银行需要预判每个客户的风险,如果客户风险过高则进行拦截。传统的方法都是基于专家经验的评分积分卡对客户进行打分。这种方法颗粒度较大,不仅会遗漏一些中高风险的客户,也会拦截掉一些高质量的中低风险的客户,因此最近几年各银行都采用机器学习的算法来进行建模打分。我们构建了一个机器学习模型,来评估每一位客户的指标,其重要输入则是客户大量的多方面的特征,其涉及的原始数据表有11张。假设只分析1万个客户,则大约需要分析10万行数据。使用本文提出的特征自动构造、自动筛选的数据挖掘方法,我们大约构建了2000个特征,然后和基于专家经验指定的55个特征一起输入机器学习模型。该模型中,最终入模的84个变量中,有60个特征是用此机制产出的自动特征。按重要性排序,前10个最重要特征中,有6个是自动产出的特征,如表7所示。
同时本文也对比了基于自动特征的新模型和现有模型的效果。对比6个月的模型运行数据,可以发现新模型的KS值提升4%左右。
由于采用了特征自動构造、自动筛选的数据挖掘方法,减少了分析建模人员大量的数据加工开发工作,简化了特征筛选的过程,实现了特征挖掘效率的大幅提升,提升了建模效率。
5 总结与展望
本研究基于信用卡行业数据特点,建立的基于RFM模型的自动特征衍生机制和基于蒙特卡洛思想的模型筛选机制,极大提升了特征挖掘的效率、深度和广度,且产生的特征具有高度的稳定性、区分能力和可解释性,能够实现在信用卡领域的快速应用,取得了较好的业务效果。本研究探索出一套针对信用卡领域知识的自动化特征挖掘方法,对于金融领域传承业务经验、规范特征管理、提升数据挖掘效率、缩短建模周期等具有借鉴意义。
本研究虽然实现了特征衍生和筛选环节的自动化、智能化,但数据分析理解环节仍需要人工参与。后续将深入研究数据业务含义自动推断,探索信用卡数据自动分析识别机制,从而实现数据挖掘的全流程自动化,进一步解放人力,让科技在更深、更广的层面助力业务发展。
参考文献:
[1] 崔嘉桐. 特征变量数据挖掘技术助力信用卡业务智慧决策[J]. 中国信用卡, 2020(11): 92-93.
[2] 高富平, 冉高苒. 数据要素市场形成论:一种数据要素治理的机制框架[J]. 上海经济研究, 2022(9): 70-86.
[3] 黄宝凤, 祁婷婷. 基于特征工程的个人信用风险评估组合模型[J]. 中国统计, 2021(6): 37-39.
[4] 闫永君. 基于时间特性的信息用户行为特征挖掘研究[J]. 情报科学, 2021, 39(8): 126-131.
[5] ZHANG X, HAN Y, XU W, et al. HOBA: a novel feature engineering methodology for credit card fraud detection with a deep learning architecture[J]. Information Sciences, 2021, 557: 302-316.
[6] 王成, 王昌琪. 一种面向网络支付反欺诈的自动化特征工程方法[J]. 计算机学报, 2020, 43(10): 1983-2001.
[7] 周俊妍, 薛文良, 魏孟媛, 等. 基于在线评论的服装质量特征挖掘方法[J]. 东华大学学报(自然科学版), 2021, 47(5): 68-73.
[8] 朝乐门, 王锐. 数据科学平台:特征、技术及趋势[J]. 计算机科学, 2021, 48(8): 1-12.
[9] 卓灵, 孙昕. 一种基于改进RFM模型的数字集群用户分类方法[J]. 计算机应用研究, 2020, 37(9): 2822-2826.
[10] KANTER J M,VEERAMACHANENI K. Deep feature synthesis:towards automating data science endeavors[C]// Proceedings of the 2015 IEEE International Conference on Data Science and Advanced Analytics. Piscataway:IEEE,2015:1-10.
[11] 潘婧, 柴洪峰, 孙权, 等. 超高维刪失数据的联合特征筛选方法研究[J]. 系统工程理论与实践, 2023,43(1): 1-22.
[12] RTAYLI N, ENNEYA N. Selection features and support vector machine for credit card risk identification[J]. Procedia Manufacturing, 2020, 46: 941-948.
收稿日期:2023-04-20
作者简介:铁锦程(1970—),男,河南开封人,博士,高级工程师,主研领域:计算机应用。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
中国交通信息化(2020年1期)2020-07-27 02:50:04
电力与能源(2017年6期)2017-05-14 06:19:37
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
信息通信技术(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
河南科技(2014年19期)2014-02-27 14:15:26
电子设计工程(2014年18期)2014-02-27 12:00:13
电子设计工程(2014年18期)2014-02-27 12:00:12
智能系统学报(2013年1期)2013-01-28 10:16:55
