
离散制造车间实时定位数据可视化平台设计
2023-07-27 07:06耿向征袁逸萍吴正春
机械设计与制造 2023年7期
耿向征,袁逸萍,毛 军,吴正春
(1.新疆大学机械工程学院,新疆 乌鲁木齐 830047;2.卓郎新疆智能机械有限公司,新疆 乌鲁木齐 830000)
1 引言
近年来,随着数据采集技术和信息传输技术的迅猛发展,离散制造车间中获取的制造数据呈爆炸式增长,这使得制造业大数据成为制造行业的研究热点之一。
在此环境下,传统的单机计算速度已无法满足实时性要求,为实现对车间中多类制造资源的实时定位、追踪、监控,急需将车间定位技术与大数据技术结合。
在车间定位技术方面,紫蜂(Zigbee)、超宽带技术(Ultra Wide Band,UWB)、无线射频识别技术(Radio Frequency Identification,RFID)等技术常被用于车间定位[1]。文献[2]通过对车间生产过程中生产要素定位需求和射频识别技术的研究,开发出一套基于RFID的应用系统,满足了对批量化零件的自动化监控和对人员实时定位与管理的需求;文献[3]将UWB定位技术集成到数据系统中,对仓库内的叉车和其他移动实体进行定位和跟踪,提高了仓库的安全性和操作效率;文献[4]提出了一种RFID和无线保真技术相融合的实时定位平台,通过对物料进行监控,实现了仓库的自动化、数字化和智能化。
在大数据技术应用方面,文献[5]为了实现实时网络中异常流量的快速分析和识别,设计了融合Spark流和Kafka的分布式实时网络异常流量检测系统(DRNATDS),并提出了一种基于相对密度和距离的K-means算法,有效地分析网络异常流量,检测实时数据流下的各种网络攻击;为解决在视频检索过程中由于视频数据的海量性、复杂性、冗余性所导致的计算能力和资源需求过高问题,文献[6]提出利用Hadoop、Hbase、Spark 和Opencv 实现了基于内容的视频检索系统;文献[7]提出一种利用Spark Streaming和改进的网格索引技术对车辆位置和交通事件进行快速处理的方法,使与应用了WEVING服务的司机实时共享周围车辆信息、行人信息和交通事件信息更方便。
在离散制造车间中包含众多的生产要素,能够实时准确的获取生产要素位置信息和状态信息将降低车间的管理难度和提升生产效率。在实际生产过程中,传统的数据收集技术和单机计算模式难以保证数据的实时性、价值性。上述研究提供了基础的研究理论与方法,通过借鉴传统大数据技术对现有问题进行解决。选择UWB定位系统作为生产要素位置信息的获取手段,设计一种利用大数据技术对生产要素定位数据进行实时地采集、处理、存储,利用Demo 3D 软件进行可视化的平台,并采用基于Spark Streaming 框架的多线程卡尔曼滤波器解决单机进行卡尔曼滤波时间过长和轨迹平滑度问题。最后,以新疆某农机制造车间为实践对象、相应设备及软件为基础,对定位要素的位置数据进行实时可视化显示。
2 平台设计及关键技术
2.1 实时定位数据可视化平台结构
大数据环境下离散制造车间实时定位数据可视化平台整体架构,如图1所示。其中UWB定位系统是数据采集层,负责对生产要素的位置信息进行实时采集;Kafka是数据接收层,负责对采集到位置数据流进行接收并传递;Spark Streaming作为数据预处理层,负责对Kafka传递的数据进行实时处理,并将处理后的数据存入HBase 数据存储系统中。Demo 3D 是数据应用层,利用HBase提供的API接口和TCP协议,将数据传递给Demo 3D进行生产要素的定位信息显示。

图1 平台结构Fig.1 Structure of Platform
2.2 实时定位技术
选用Ubisense UWB 定位设备对位置信息进行采集。在实际工作中,通过定位传感器与定位标签之间的脉冲信号传输来测定AOA、TDOA信息,再使用定位引擎对测定的信息进行解析,获得定位标签的精确位置信息,如图2所示。定位传感器选择Series 7000系列传感器,定位标签选择Ubitag(紧凑型)。

图2 UWB定位系统硬件Fig.2 Hardwares of UWB Positioning System
2.3 数据流实时传输技术
在多种传感器并存、通信感知技术广泛应用的情况下,一方面要保证数据的实时性,另一方面又要减少数据的丢失,这些都给工业数据的收集带来了巨大挑战。
Kafka是一种分布式发布订阅消息传递系统[8],在流式计算中被广泛应用。Kafka中可以包含一个或多个代理的服务器,它们收集并存储信息,然后发布相关的Topic。Apache Zookeeper被用于跟踪Kafka中集群节点的状态。生产者将消息发送给代理,代理保存消息,确保消费者可以接受完整的消息。Kafka架构,如图3所示。
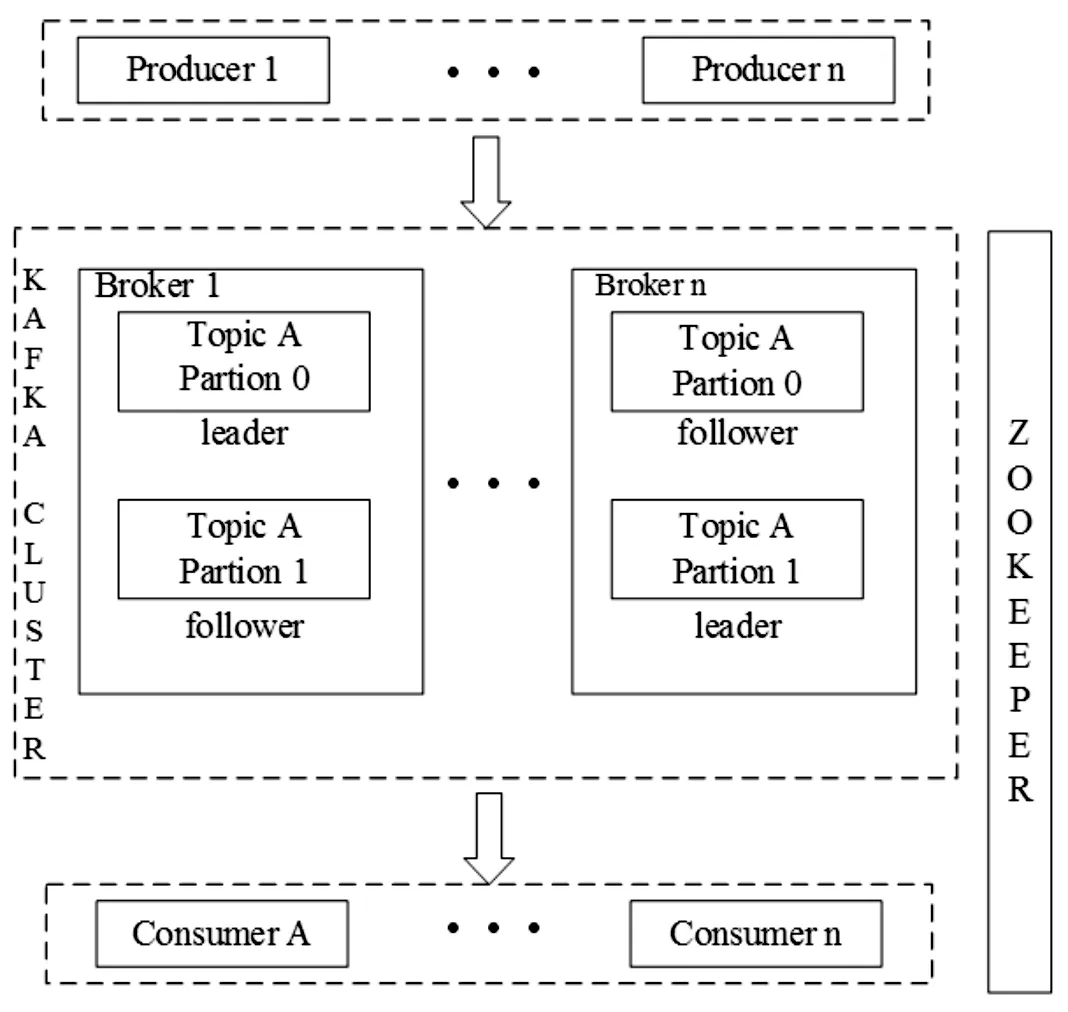
图3 Kafka架构Fig.3 Architecture of Kafka
2.4 实时数据处理技术
Apache Spark 是一个开放源码的、分布式的、快速的、集群的、用于处理大数据的计算框架。其速度比Hadoop更快[9]。
Spark Streaming是Spark中基于内存的流处理计算框架。可以轻松处理实时数据,其处理结果能够满足实时的要求。此外,它可以接收多个数据源的数据,如Apache Kafka、Apache Flume、Amazon Kinesis等。
Spark Streaming在处理数据时,首先Spark接收流式数据,并将数据先按指定的批处理间隔分割为大量的批数据。然后通过Spark引擎对每个批进行处理,最后将各个批的结果进行汇总,得到最终结果。处理过程,如图4所示。

图4 Spark Streaming处理过程Fig.4 Processing of Spark Streaming
2.5 数据存储技术
Apache HBase 是一种基于Hadoop 存储系统的分布式数据库,HBase 利用HDFS 作为底层文件系统和分布式编程框架mapreduce作为实现框架[10]。
HBase数据表的基本单元是列族,它由一个或多个列组成。两个列族,即Column Family 和Column,分别包括列X、Y和列V_x、V_y,如图5所示。

图5 HBase存储模型Fig.5 HBase Storage Model
HBase 能够提供实时性的查询需求。Client 通过内部缓存的信息定位到与客户查询请求相对应的Region,首先会根据查询需求在Region 的Memstore(内存缓冲区)内查找,如果查询到结果,则将结果传出;如果没有查询到结果,将在已持久化的Store-File中继续查找。在这种数据查询机制下,实时的位置数据被存放在Region的Memstore中,保证了数据查询的实时性。
2.6 可视化技术
Demo 3D是一款能够将某些真实物理特性融合到生产仿真中的仿真软件,相比于国内常用的Tecnomatix Plant Simulation、witness等仿真软件具有更好的视觉效果[11]。画面在经过高清渲染过后,可以生成高质量的影像,使动态仿真模型更加逼真。
Demo 3D提供了大量的设备模块的同时也支持导入多种格式的三维模型,并且用户可以使用面向对象的语言C#、Jscript进行开发,这使得编程难度降低、仿真模型的搭建效率大大提升。
3 关键算法设计
3.1 卡尔曼滤波器原理
卡尔曼滤波器是一种对系统中的未知状态进行最优估计的递推算法。
预测阶段:

图6 卡尔曼滤波器工作流程Fig.6 Workflow of Kalman Filter
3.2 Spark Streaming的卡尔曼滤波器设计
传统的卡尔曼滤波器无法直接在Spark Streaming集群中运行。本小节将对卡尔曼滤波器实现基于Spark Streaming集群的多线程设计。在kafka消息传输过程中,kafka的Producer根据数据中标签ID 的不同,将数据推送到同一Topic 中相应的Parition中。Spark Streaming 作为kafka 中数据的消费者,通过多线程技术对同一Topic中不同的parition数据进行消费。每个线程单独创建一个KafkaConsumer且只消费Kafka中一个Partition队列中的数据,如图7所示。在这种模式下,多个线程被分发给集群的各个节点进行计算,提高了计算速度。

图7 消费数据过程Fig.7 The Process of Consuming Data
线程中的算法步骤如下:
(1)在Kafka 中一个partition 消息队列中创建一个间隔为1秒的Dstream(key,value)。
(2)调用转换接口,将Dstream 的格式重写,形成新的rddqueue。在使用Kafka传输数据时,数据以时间为序列的K-V对形式存在,在本平台中k为标签ID拼接上系统获取数据的时间,V为x坐标与y坐标的拼接。例如:Dstream((ID0_time0),”x0#y0”)转化为rddqueue((“ID0_time0”),DenseVector(x0,y0))。
(3)将rddqueue放入到Spark Streaming的流序列中,并对生成的对象运用updataStateBykey算子对每条数据进行计算并将状态更新。
(4)创建put对象,将计算结果放入到HBase数据表中。
(5)重复步骤(1)~步骤(4)。
主要代码如下:
object KFUpdateFunction{
val updateFunc=(values:Seq[KalmanFilterData],
state:Option[KalmanFilterState])=>{
if(values.length==0){
state
}else{
val x:DenseVector[Double]=values(0).actualState
val z:DenseVector[Double]=values(0).observedState
val prevState=state.getOrElse(new KalmanFilterState())
val NC:Long=prevState.count+values.size
val F:DenseMatrix[Double]=KalmanFilterConstants.F
val GA:DenseVector[Double]=KalmanFilterConstants.GA
val H:DenseMatrix[Double]=KalmanFilterConstants.H
val I=DenseMatrix.eye[Double](4)
val xe= F*prevState.xe+GA
val p=F*prevState.p*F.t+KalmanFilterConstants.Q
val s=H*p*H.t+KalmanFilterConstants.r
val k=p*H.t*inv(s)
val y=z-(H*xe)
val NewXe=xe+(k*y)
val NewP=(I-(k*H))*p
Some(new KalmanFilterState(NC,x,NewXe,NewP))
}
}
}
4 实验与效果展示
4.1 实验场地及数据量分析
实验选自新疆某农机制造企业的综合一机加工车间,长170m、宽72.5m、高11m,实验环境为室温,高干扰噪声。
通过对车间分析,拟采用5个定位单元,其中包括30个定位节点和60个标签,在车间进行部署。
根据Ubisense提供的资料,每个标签的位置刷新频率在(1~40)Hz之间,在实验车间定位系统中设置最高的位置刷新频率并对标签产生的位置数据量进行统计,如表1所示。

表1 实验车间的数据量统计Tab.1 Data Volume Statistics of the Experimental Workshop
每个标签每秒约产生39 条数据,60 个标签每分钟约产生140400条定位数据,如表1所示。在定位系统中,通过对每个标签与不同实体绑定来获取实体的位置数据,由于每个标签是独立的,所以获取的位置数据也是独立。单机程序在处理这种多数据源且海量数据时难以保证数据的实时性要求。
4.2 单机多线程方式与Spark Streaming性能对比
在单机数据处理模式下,Java程序将对每个标签的数据流分配一个线程并提交到线程池中,线程池控制工作线程并发地对不同标签的数据进行卡尔曼滤波处理。由于单CUP环境下多线程属于并发模式,CPU在不同线程间切换执行,并且不同线程需要进行大量的数据交换和卡尔曼滤波的迭代计算,在标签数量增加时无法保证数据的实时性处理。
由4.1节可知,每个标签每秒产生39条数据,人工生成60个标签5分钟的数据,每个标签11700条数据,分别命名为id1、id2...id60。多线程数据处理基于Intel(R)Pentium(R)G3260,双核心双线程,4G 内存。Spark Streaming 基于CPU 为Intel(R)Pentium(R)G3260 三台机器搭建的集群。多线程处理方式与Spark Streaming的耗时对比,如图8所示。

图8 两种方案耗时对比Fig.8 Comparison of Time-Consumption Between the Two Schemes
根据图8可以看出,随着标签数量的增加,耗费的时间也增加,当标签数量超过34个时,由于单机计算机性能的约束,传统的多线程方式不能满足数据的实时性。Spark Streaming 通过分布式并行的计算方式,耗费的时间远小于单机多线程计算方式。当标签数量达到60个时,耗时比单机多线程方式少218.2s。
4.3 Spark Streaming集群的扩展性分析
以不同标签数量为基础,通过改变集群节点的数量分析集群的运行时间,如图9所示。当集群中的节点数量增加时,不同数量标签的耗时均有所下降。这说明,当标签数量不断增加,使当前集群的计算性能无法满足系统的实时性要求时,可以增加集群的节点数量。

图9 集群节点数量对数据处理效率的影响Fig.9 Effect of Number of Cluster Nodes on Data Processing Efficiency
4.4 实验平台的搭建
选择VMware Workstation Pro 虚拟机搭建三台以Centos6.9系统为运行环境的集群,需安装的组件及版本如下:Hadoop-2.7.7、Zookeeper-3.4.14、Hbase-2.1.7、spark-2.1.1、Kafka、JDK1.8,并以YARN模式运行。另在DELL 15-7572笔记本上安装远程控制软件—SecureCRT和Demo 3D。
平台搭建过程如下:
(1)根据车间实际情况和对要素的定位需求布置UWB定位基站位置,节点布置,如图10所示。

图10 实验路线及节点布置Fig.10 Experiment Route and Nodes Arrangement
(2)按图中的位置坐标,将定位基站安装在3m高的高脚支架上,倾斜向下。
(3)将标签固定在叉车顶端,减小噪声对测量的干扰。
(4)使用定位软件对基站进行调试,并使用AOA、TDOA算法获取叉车位置信息。
(5)启动大数据集群,对获取的位置数据进行实时收集、处理、存储。
(6)启动Demo3D仿真软件,对叉车轨迹进行显示。
4.5 卡尔曼滤波器在实验平台中的应用
在离散制造车间中,由于地面约束的存在,叉车只在二维空间中运动,所以本实验只研究二维的位置坐标。在车间中选择一条叉车频繁通过的路径匀速运动,如图10所示。在此条件下将X=[px,py,vx,vy]T作为系统的状态变量,其中px、py—叉车的x、y坐标,vx、vy—x、y轴的速度分量。
状态转移矩阵:
式中:Δt—两次定位的间隔时间。
由于UWB定位系统只能测得标签的位置坐标,而不能测得标签的运动速度,所以,观测矩阵:
因为卡尔曼滤波器可以不断的对误差协方差矩阵和预测值进行修正,所以对初始值的要求比较宽泛。在这里中,将px0、py0设置成叉车的初始位置,vx0,vy0为0,误差协方差矩阵的初始值:
为叉车行驶时的轨迹对比结果,如图11所示。

图11 结果对比Fig.11 Comparison of Results
在干扰噪声较大的离散制造车间,仅使用UWB定位系统获取的位置点稀疏不均,位置跳动现象严重。再经过卡尔曼滤波器处理过之后使得误差整体降低,整体的轨迹平滑度明显提升,具有更好的展示效果,如图11和表2所示。

表2 误差统计对比Tab.2 Statistical Comparison of Error
4.6 Demo3D在实验平台的应用
利用HBase提供的API接口和TCP技术,将HBase中存储的位置数据传输到Demo 3D 中。Demo 3D 使用C#语言进行开发,首先,搭建比例尺为1:1的车间物理模型,保证虚拟车间布局与实际车间相同。
其次,在叉车模型中编写移动方法。最后,运行整体模型,Demo 3D将从HBase中读取数据驱动叉车模型运动;将模型映射在网页上,当鼠标点击叉车时,弹出窗获得数据信息并进行可视化展示,如图12所示。

图12 叉车定位信息可视化Fig.12 Visualization of Forklift Location Information
5 结论
(1)这里将车间定位技术与大数据流式计算技术相结合,搭建了大数据情况下车间位置数据收集、处理、存储系统,其可视化效果达到了预期。
(2)设计了基于Spark Streaming的卡尔曼滤波器。在定位标签数量为60个时,比单机多线程卡尔曼滤波器耗时少218.2s,其定位精度和轨迹的平滑度均有明显提高,展示效果更好。
(3)虽然整体大数据处理系统能够达到预想要求,但是对性能的优化方面尚有不足,没能发挥大数据技术的最大潜能。在可视化界面上,交互性能和界面美化较差,是今后改进的重点。
猜你喜欢
中国储运(2022年6期)2022-06-18
中国特种设备安全(2021年12期)2021-04-26
北京航空航天大学学报(2017年9期)2017-12-18
环球市场(2017年36期)2017-03-09
广州大学学报(自然科学版)(2016年2期)2017-01-15
中国储运(2016年8期)2016-09-02
电源技术(2016年9期)2016-02-27
电源技术(2015年1期)2015-08-22
电子设计工程(2014年6期)2014-02-27
计算机工程与科学(2013年2期)2013-06-07
