
卫星遥感提取烟田种植面积应用分析
2023-07-27 02:20李莉王丽丽李长军陈秀斋谭效磊高强张超田洪彰
中国农学通报 2023年13期
李莉,王丽丽,李长军,陈秀斋,谭效磊,高强,张超,田洪彰
(1北京工业大学,北京 100010;1临沂市气象局,山东临沂 276000;2山东临沂烟草有限公司,山东临沂 276000;3山东省信息中心,济南 250000)
0 引言
烟草是中国重要的经济作物之一。长期以来,烟草种植面积是烟草生产管理、国家宏观管控决策的重要依据[1]。国内烟草种植面积大、分布范围广,而且通常情况下,种植烟草的地块不大,分布比较零散,形状也不规则[2-3]。传统上,烟草主管部门主要采用地面调查方式进行统计了解,需要人工丈量种植地块的面积,并随时记录地块的具体位置,这种方式工作量大,不仅需要大量的劳动力和经济资源,耗费时间较长,而且容易受人为主观因素影响,精确度不稳定[4-6]。
近40 年来,遥感技术因具有覆盖面积广、时效性强、周期短、获取信息快速等优点,在作物面积、长势监测中发挥着越来越重要的作用。目前应用比较广泛的有随机森林算法,它是由一系列分类器组合在一起进行决策,期望得到一个最“公平”的集成学习方法,它是随机理论在实际应用中取得的成果,可以看成是Bagging 和随机子空间的结合[7-9],和传统的决策树相比,更加灵活、高效、准确,分类效果更好,被广泛应用于中高分辨率的影像分类中[10]。还有阈值分割法,可以说是图像分割中的经典方法,它利用图像中要提取的目标与背景在灰度上的差异,通过设置阈值把像素级分成若干类,从而实现目标与背景的分离。目前,遥感技术在农作物种植面积监测等方面的应用较为成熟,但对于烟田信息提取还鲜有报道,烟草信息的遥感监测起步相对较晚,基于遥感的烟草研究国内外都还相对比较匮乏,不能满足实际应用的需要[11-13]。
鉴于此,笔者以山东省临沂市为研究区,Sentinel-2A多时相卫星遥感影像为数据源,利用机器学习设置阈值提取临沂市3区9县烟草种植面积及区域,拓展烟草种植面积监测手段,旨在为烟草种植业的科学管理、宏观调控提供科学依据,有利推进烟草行业的信息化和科学化[14-16]。
1 研究区和数据来源
1.1 研究区域
临沂地区位于山东省东南部,地跨34°22′—36°13′N、117°24′—119°11′E之间,总面积17191.2 km2[17-18],辖兰山等3 区和郯城等9 县,地理区位如图1 所示,属暖温带大陆性季风气候,四季分明,冬季干冷,春季干旱,夏季湿热,秋高气爽,阳光充足,雨量丰沛。该地区年平均气温13℃,一般西部高于东部,南部高于北部,全年日照时数在2500 h左右,有利于农作物、植被的生长发育,是粮食作物和经济作物的重要原产地,全市常年种植烤烟8000 hm2左右[19]。
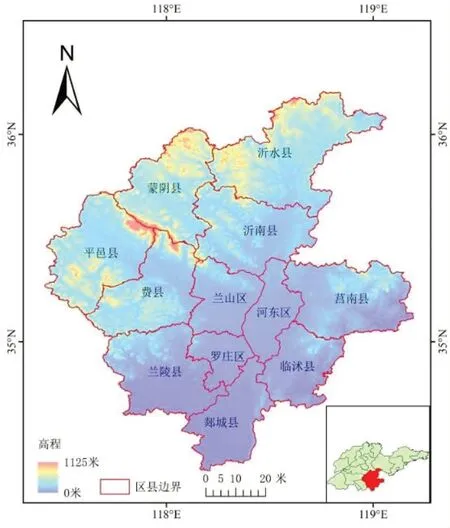
图1 临沂市地理区位图
1.2 数据源
1.2.1 遥感数据哨兵2A(Sentinel-2A)卫星是“全球环境与安全监测”计划的第2颗卫星,于2015年6月23日发射,并于当年年底正式投入使用。该卫星携带一枚多光谱成像仪(MSI),可以覆盖从可见光到红外共13个光谱波段,还包括3 个QA 波段,反演的信息比较丰富,空间分辨率最高可达10 m,幅宽290 km,重访周期5 d[20-22]。本研究选取2021 年1 月1 日—年9 月30日云覆盖度低于1%的Sentinel-2A Level-1C 产品数据(从欧空局数据共享网站https://scihub.copernicus.eu/dhus/#/home 下载),该产品已经经过亚像元级几何精校正和辐射校正,可以提供大气顶层的表观反射率数据[23-25]。
1.2.2 地面样本数据根据临沂市实际土地利用情况,在水体、工业建筑、民用建筑、林地、耕地等5种地类中取样,样本点的选取遵循随机、均匀分布的原则,覆盖全市范围,并将各类样本随机分为验证样本和训练样本,分别用于各类地物的识别以及识别后的精度评价[26]。
2 研究方法
2.1 技术路线
烟田信息的提取首先是区域各地类样本库的建立,在此基础上,第1次应用随机森林机器学习算法,实现耕地与其他地类的区分;在耕地信息准确提取的基础上,再利用第2次随机森林机器学习算法,实现覆膜耕地的提取;最后在覆膜耕地上,应用多时相阈值法实现烟田信息的提取。整个分类的技术路线如图2所示。

图2 烟田分类技术路线
2.2 样本库的建立
为减少分类数据的运算量,首先通过阈值算法剔除明显不同于烟田的农作物。研究时段内大面积种植的农作物主要是小麦和玉米,这2 种作物在区域内以轮作为主,因此可同时剔除,而水稻在4月具有明显的灌水特征,在水体提取时也可一并剔除。剔除小麦、玉米、水稻种植区后,采用机器学习分类算法,实现一级地类信息提取,再基于采样的随机森林机器学习算法实现覆膜耕地信息的提取。因为临沂地区烟田在4—5月需要在田间覆膜种植,同期覆膜的耕地还有花生、红薯,且花生作为重要的油料作物,在临沂大面积种植,而花生与烟草又具有相似的生育阶段,本研究通过多时相阈值算法实现与烟田同期种植、同期收获的花生、红薯种植区的去除,最终达到烟田信息准确提取的目的。综上所述,本研究需要建立2次样本库,第1次实现小麦、玉米和水稻的准确剔除,即一级地类样本库;第2次实现覆膜耕地、未覆膜耕地和已种植耕地的分类样本库,称为二级地类样本库。
2.2.1 一级地类样本库建立基于GEE 云平台提供的高分辨率谷歌影像数据,及区域实地调查数据,将区域土地利用/土地覆被类型划分为耕地、水体、工业建筑、民用建筑、林地5个类别,这5个土地利用/土地覆被类别,在真彩色、标准假彩色影像及纹理特征上存在显著差异,因此,可通过GEE 云平台的在线功能完成一级分类的样本采集。样本采集的基本原则是:(1)每类样本在数量上分布均匀,其中耕地样本数量要稍多一些;(2)每类样本在空间分布均匀,并且兼顾同一类别在不同区域影像特征的差异性;(3)每类样本的数量要足够多,能够满足机器学习算法对样本的需求。
基于上述原则,最终建立一级分类样本595个,其中水体样本105 个、工业建筑样本131 个、民用建筑127个、林地样本103个、耕地样本数据129个(表1)。2.2.2 二级地类样本库建立二级分类可以实现耕地范围内烟田与非烟田的区分,主要是区分与烟田同期种植的花生、红薯等主要作物,因此在进行二级分类样本库建立时,既要考虑作物的时相特征,又要考虑影像特征。在二级分类取样时,将耕地区域分为3类,分别为4—5 月覆膜耕地、未种植的耕地和已种植的耕地,累计提取二级分类的耕地样本879 个,其中覆膜耕地样本435个、未种植耕地234个、已种植耕地样本210个,在哨兵标准假彩色影像上的特征见表2。

表1 5种一级地类真彩色影像特征及数量

表2 3类二级分类耕地样本提取影像特征及数量
图3为谷歌地图5月各种二级地类的高分辨率真彩色影像图。图4为基于哨兵多光谱影像数据的二级地类样本采样的空间分布示意图,其中红色采样点表示覆膜耕地、绿色表示未种值耕地、紫色表示已种植耕地。

图3 二级分类实际采样点真彩色谷歌影像示意图

图4 二级分类耕地GEE云平台采样点哨兵标准假彩色分布示意图
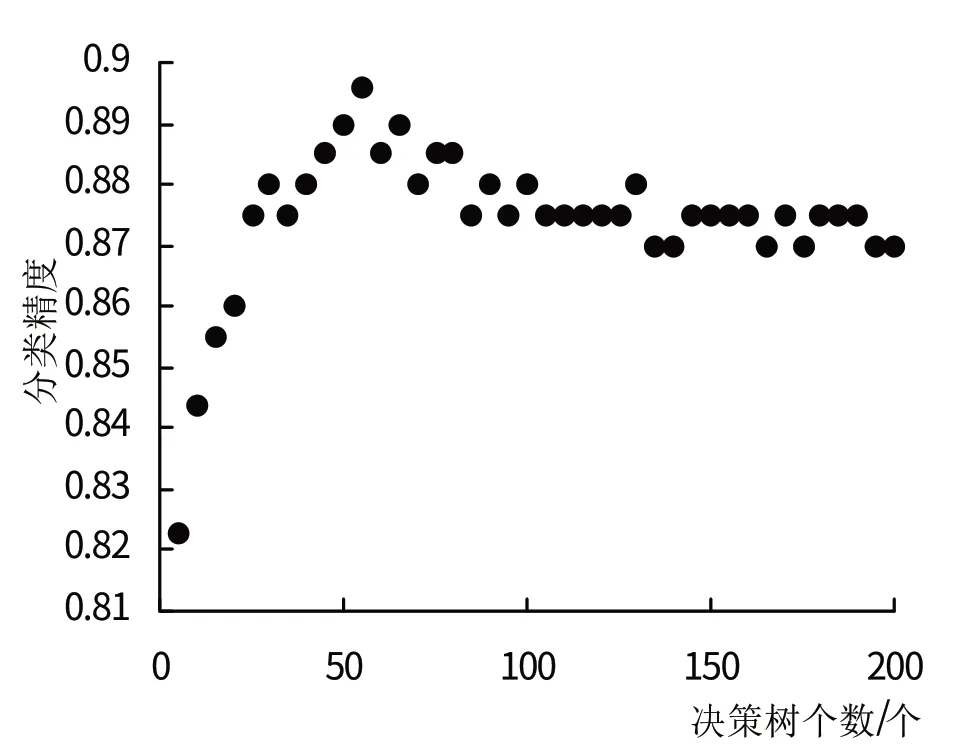
图5 决策树数量与精确度关系图
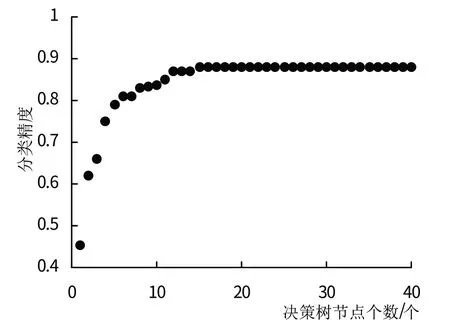
图6 决策树节点个数与精确度关系图
2.3 随机森林算法支持下的一级地类分类
2.3.1 小麦种植掩膜区提取小麦种植区在5月植被指数较高,与其他作物明显不同,因此通过简单的阈值法就可以实现较高精度的分类。利用5月哨兵影像数据计算得到归一化植被指数NDVI,设置NDVI阈值为0.38~0.54,提取出小麦种植区作为掩膜,在后续的分类数据中将小麦种植区掩膜掉,从而降低运算量及错分概率。
2.3.2 一级地类特征值的提取基于前面建立的一级分类样本,应用GEE 云平台支持下的随机森林分类算法,对研究区的5 种一级地类进行识别和自动化提取。依据哨兵2 号多光谱卫星的单波段数据,应用波段比值运算,得到增强植被指数特征值。波段比值增强运算可增强地物波谱特征间的微小差别,压制图像中乘性光照差异的影响,如地形和阴影的影响,突出地物的反射辐射特征,一些特定波段的简单或复杂比值可作为识别某些特定地物的标志,对数据作归一化处理,压制亮度差异或大气选择性吸收等的影响,突出地物间的波谱差异,最终达到提高地物类别之间区分度的目的。
哨兵1号的被动微波雷达数据可以补充多光谱数据所不能提供的地物空间结构、形状等信息,辅助分类结果精度的提高。本研究采用2 个指数,即VV 指数(哨兵雷达卫星数据的垂直极化数据计算得到)和VH指数(哨兵雷达数据的水平垂直极化数据计算得到),为一级地物分类提供辅助的结构、形态等信息。
2.3.3 随机森林支持下的一级地类提取测试随机森林决策树的个数与精度关系后发现,当决策树的个数为55 时,随机森林分类精度最高,并且随着决策树节点数量的增多分类精度提高,如图5~6所示。
根据上述原理,一级地类分类用了55棵决策树,每颗树的深度为13,同时利用袋外数据误差对每个特征参量的贡献度进行计算,如表3。Sentinel-2A第11波段对分类结果的贡献度最大,重要性达到904.8,贡献度最小的是第9波段,其重要性值为342.4,21个特征值的平均重要性为532.3,超过平均值的特征参量有7个,按照由大到小排序为B11、B10、B1、B2、B7、B6和B5。
基于上述特征值,及所建立的一级地类样本库(其中70%样本用于训练,30%样本用于精度验证),应用随机森林机器学习算法,实现云平台支持下的一级地类的自动提取,耕地的提取精度通过卡帕系数测算达到96%,结果如图7所示。
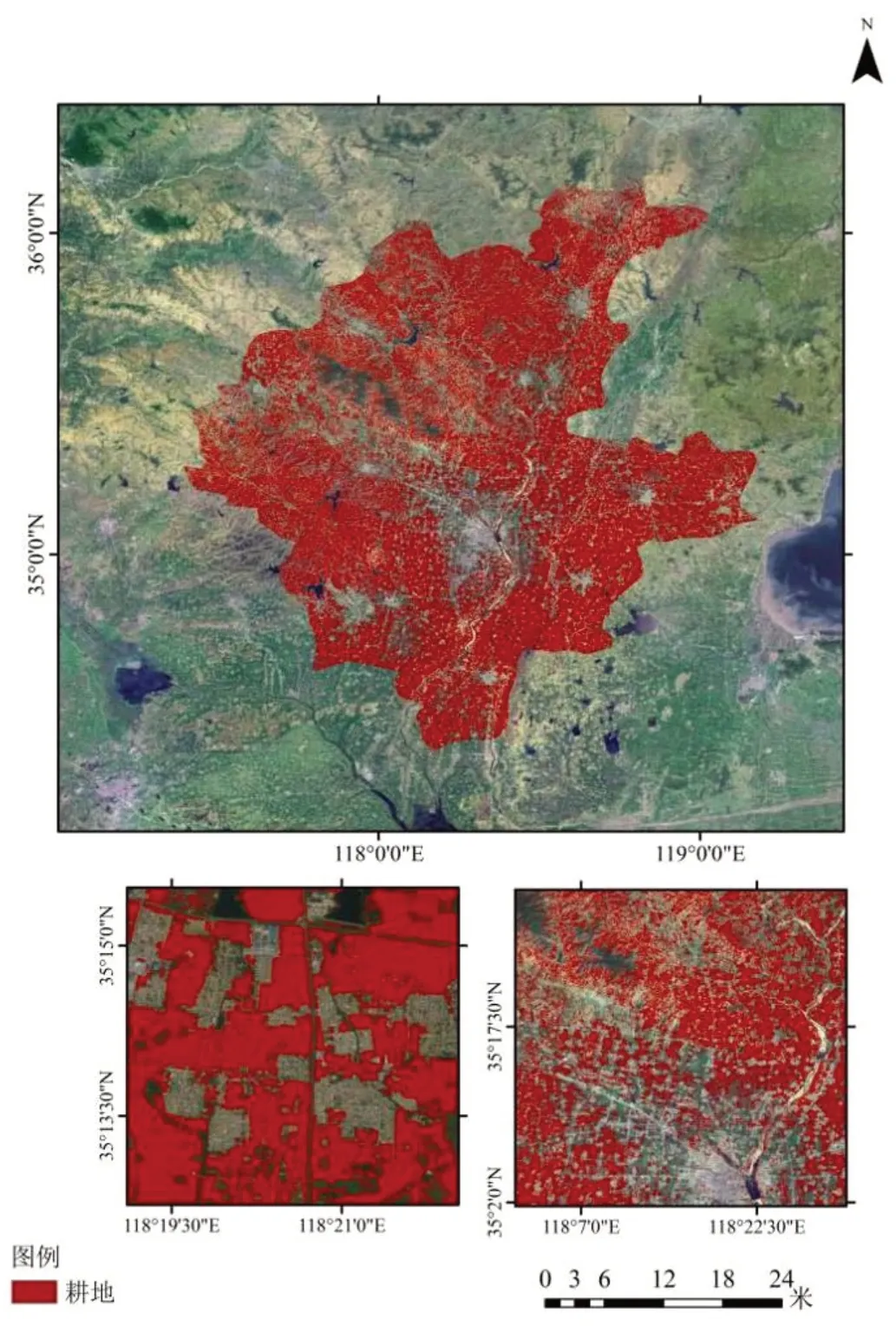
图7 2021年临沂市耕地分布
2.4 二级地类自动提取
在临沂市一级地类的分类基础上,掩膜掉非耕地区域,采用与一级分类同样的特征参量,基于二级分类的879个样本,在云平台支持下,应用随机森林自动分类算法,实现耕地区域的覆膜耕地、未种植耕地和已种植耕地的信息自动提取,分类结果精度较高,其中覆膜耕地提取精度达到93%。
2.5 多时相阈值算法实现烟田信息自动提取
二次随机森林机器学习算法得到的覆膜耕地主要为烟田、花生及红薯等与黄烟同期种植、收割的农作物,虽然这些农作物的生育期与黄烟相似,但不同发育期的植被指数特征不同。因此,基于MODIS 的NDVI产品数据,统计黄烟种植区不同时相的NDVI值及区域黄烟实际生长数据,从而得到烟田信息多时相阈值算法的具体参考值(表4),最终实现烟田种植区的准确提取。

表4 烟田提取的NDVI多时相阈值
2.6 实地核查
由于烟田与红薯、花生的同时期光谱特征有较大相似性,因此需要通过现场调查对容易混淆的典型作物进行识别及核查。根据遥感监测提取旱田经纬度信息,于2021 年在临沂市实地进行地类定位验证,共验证了2207个点位,点位分布如图8所示,验证发现本研究提取精度达到96%以上。
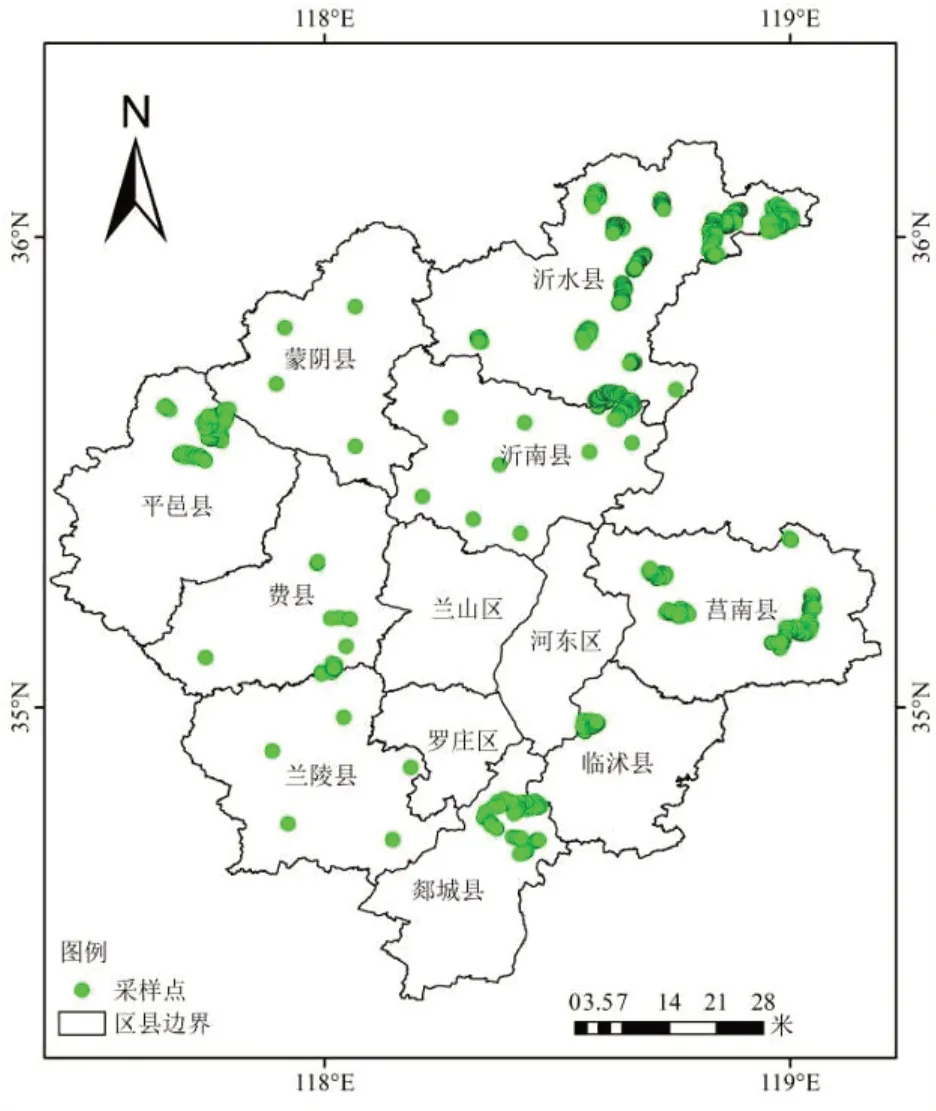
图8 采样点分布图
通过遥感监测得到各地类经纬度信息,并进行地类定位验证,记录定位点类型及其所对应的现场照片、遥感影像,如表5所示。

表5 部分采样点信息
根据地面核查结果,对解译过程中不易判读的土地利用类型进行补充,对错别误判的地类进行参数修改,通过地面核查和室内修正、解译,本研究采样点处土地利用遥感解译的精度最终达到了100%。
3 结果与分析
3.1 烟田空间分布情况
运用上述研究方法,利用Sentinel-2A卫星遥感影像数据,基于GEE平台,提取出2021年度临沂市3区9县的烟田种植区域,空间分布格局如图9 所示。从图中可以直观看出临沂市烟田种植的分布情况,全市烟田提取面积为9053.3 hm2,市区没有种植烟草,全市烟田主要分布在沂水、费县、兰陵(图10),分别是2400、1546.7、1253.3 hm2,其中沂水占26.5%。沂南和蒙阴紧跟其后,临沭和郯城面积最少,分别是253.3、206.7 hm2,分布比较零散。总体而言,临沂市烟田在各区县面积中所占比例并不高。

图9 2021年临沂市烟田分布图
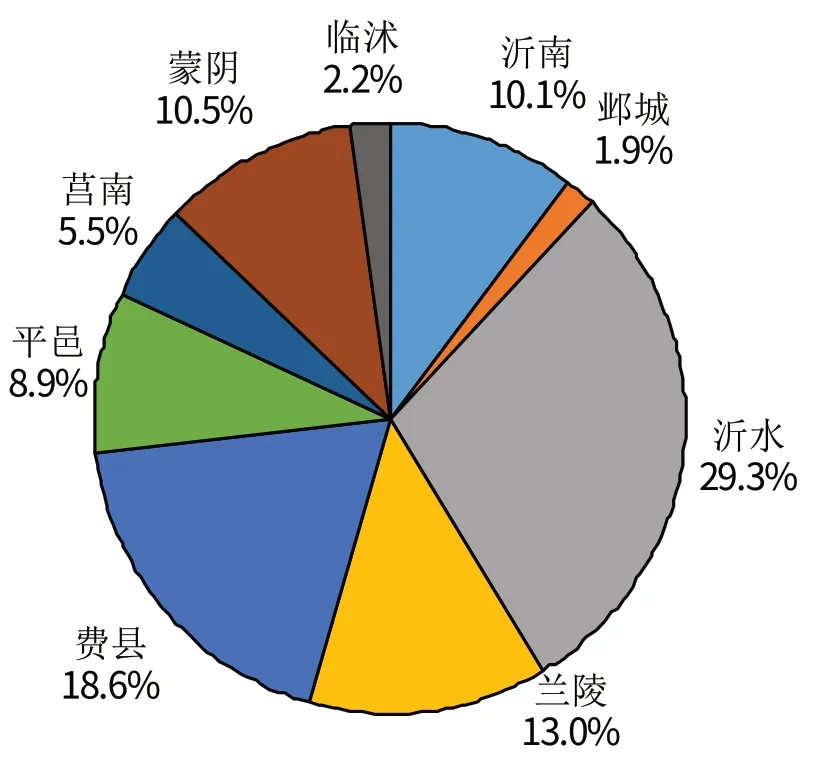
图10 临沂各县烟田种植面积提取数据
3.2 基于统计数据的提取结果分析
基于上述研究方法得到临沂市2021 年度烟草种植面积信息,实际空间分布情况基本和机器自动计算结果吻合,并且具有较高的提取精度(表6),其中平邑、蒙阴和兰陵提取精度高达96%以上,郯城、临沭的提取精度略低,不足85%,这可能是因为临沭、郯城属于平原地区,以种植粮食、蔬菜为主,烟草种植区域本身较少,而且周边其他地物(花生、红薯等)混杂,不易区分。烟田的总体提取精度达到96.04%,且大部分县区的提取精度在85%以上,可以满足研究需求。
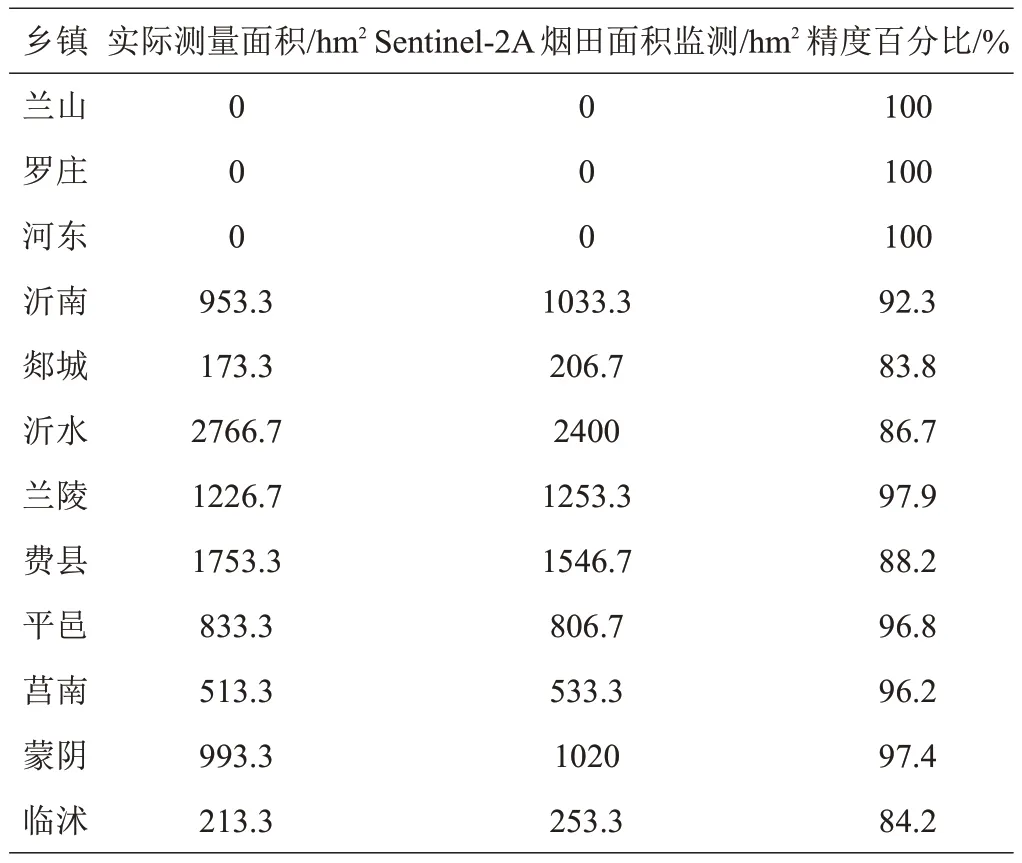
表6 面积提取精度验证
3.3 误差分析
(1)卫星遥感影像本身带来的误差。卫星在获取地面影像时,既会受外在因素的影响,比如地形、气象因素,也有来自内在的原因,如系统本身的误差、数据处理过程以及卫星运动轨迹产生的误差等,这些都会对提取精度产生一定影响。
(2)人为主观因素造成的误差。在野外调查中,由于时间、人为的原因,在实地测量烤烟种植区域的地理信息时出现偏差,或者是在对影像进行目视解译辅助绘制矢量真值图时,将与种植区域相邻的边界归入类别,也可能由于同一时期种植的其他农作物生长周期和体貌形态与烤烟很相似,导致在采样时存在样本混淆。
(3)从遥感影像上可以看出研究区地域复杂,地貌类型多样,烟田种植地块多存在零散、不连续的情况,在一个小区域内可能同时存在多种农作物,因此可能会导致单一像元内存在多种地物类别信息,再加上烟叶特征不明显,从而增加了分类的难度,影响分类精度。
(4)训练样本带来的误差。种植地块中可能存在少量其他作物或不同地类类别,影响训练结果,从而可能影响参数设置,最终影响判别结果。另外,算法在处理10 m分辨率的遥感数据时存在误差,对于特征值相差不大的地类存在误判情况,而且随机森林对样本的要求比较高,样本数量和样本分布都会间接或直接影响分类精度,其次随机森林算法也属于监督分类算法之一,在分类时受人的主观意识影响,类别数量的选择也会带来一定的误差。
4 结论与讨论
由于烟田种植地块较小,存在同谱异物的混合像元问题,因此提取比较困难,本研究采用2次随机森林分类算法再结合阈值法,最终提取出烟草种植信息。通过与实际调查统计数据进行对比验证分析得出,大部分县区的提取精度在85%以上,可以满足烟草种植管理的需求。通过遥感手段提取的烟田数据,比农户上报的更客观、准确。下一步可以在本研究提取的区域烟田分布数据基础上,开展烟田区域气象要素的精细化插值,烟田产质量的精准化预报,及烟田气象灾害的风险评估及预报预警等工作。笔者的研究区域是临沂市,分类规则虽然可以较为准确地提取出临沂市的烟草种植区域,为山地丘陵地区烟田种植信息的提取提供一定的参考依据,但该研究方法是否适用于其他植烟区还有待进一步考证。
猜你喜欢
老年教育(老年大学)(2022年2期)2022-02-23
河北果树(2022年1期)2022-02-16
河北果树(2021年4期)2021-12-02
今日农业(2021年17期)2021-11-26
新农民(2020年21期)2020-12-08
新乡学院学报(2016年6期)2016-12-01
信息记录材料(2016年4期)2016-03-11
现代农业(2016年6期)2016-02-28
现代农业(2016年4期)2016-02-28
杂草学报(2015年2期)2016-01-04
