
基于 Neo4j 的语言学术语知识图谱构建研究
2023-07-23 18:31:25王浩学王兴隆
中国科技术语 2023年3期
关键词:知识图谱
王浩学 王兴隆

摘 要:此研究以《语言学名词》为数据源,使用Neo4j图数据库,采用自顶向下的图谱构建模式,融合事件理论与事理知识图谱构建方法生成语言学术语知识图谱,直观展现语言学术语内部的五类属性值及术语节点之间的九类关系,提供了一种较为合理的学科知识图谱构建模式,对语言学术语知识图谱的部分特征进行了分析,并对语言学术语知识图谱研究进行了总结和展望。
关键词:事理图谱;知识图谱;语言学术语;学科术语;Neo4j
中图分类号:H083文献标识码:ADOI:10.12339/j.issn.1673-8578.2023.03.003
Abstract:Taking the Chinese Languistic Terms as data source and using the Neo4j graph database, we adopt a topdown graph construction model, and integrate event theory and event evolutionary graph construction methods to generate linguistic terminology knowledge graphs. We hope to visualize the five types of attribute values within linguistic terms and nine types of relationships among term nodes, and provide a more reasonable disciplinary knowledge graph construction model. We also analyze some features of the linguistic terminology knowledge graph, and summarize and outlook the research on linguistic terminology knowledge graph.
Keywords:event evolutionary graph; knowledge graph; linguistic term; subject term; Neo4j
0 引言
知識图谱的定义由Google公司在2012年提出,被界定为用来提升搜索引擎功能的辅助知识库。知识图谱是用图模型来表述人类认识并构建与世界万物之间关系的技术方式,实质上是表述实体与实体之间关系的一个语义网,其基本构成单元为“实体-关系-实体”的三元组[1],包括实体及其关联属性值对,实体之间通过关系互相连接,从而形成网状知识结构。
知识图谱作为知识管理的重要手段,以通用直观的方式来检索和分类数据,通常服务于网络大数据分析工作,Google、Bing和Yahoo等搜索引擎均已引入知识图谱。同时,知识图谱对于梳理某一专业领域的发展脉络也具有重要意义。国家层面也提出“构建涵盖数十亿实体规模的多源、多学科和多数据类型的跨媒体知识图谱”[2]。在近期研究中,也出现了一些对特定知识领域的知识图谱研究,如董晓晓等[3]完成的融合知识组织与教育教学原理和规律来定义实体类型、实体属性和实体关系的教育领域知识图谱模式构建方法;王松等[4]对知识图谱的概念、关键技术及中医药知识图谱研究现状进行了综述,并对中医药知识图谱研究的发展趋势进行了展望;肖飞龙等[5]基于Neo4j图数据库构建了疾病预防与控制措施知识图谱,探索疾病预防控制机构的数量、人员等防控措施现状,为防控体系的完善提出建议。在语言学领域,有学者基于CiteSpace等文献分析图谱进行综述性研究,如陈风华等[6]使用CiteSpace对国内核心期刊与国际核心期刊历年发表的多模态话语研究文献做了知识图谱演化分析;刘霞等[7]使用CiteSpace对1998年至2013年发表于CSSCI刊物的语料库相关文献进行了量化分析和可视化呈现。此类研究的数据来源为期刊网站的文献数据,一般只限于某一微观研究领域,其研究目的主要是分析某一研究热点并撰写综述性文章,并不涉及语言学术语体系图谱的建立。通过查询中国知网、万方等期刊数据,笔者发现国内暂无研究人员采取图数据库的方式储存并展现整个语言学术语的发展脉络。“术语是对已知事物的命名,是通向未知的基础,往往成为一个学科乃至整个知识体系建构的重要节点和衍生点。就此而言,一个学科领域的关键术语犹如该学科的基因,具有学术繁衍力。”[8]语言学发展到今天,已经具备较为庞大的知识体系,可以说,语言学术语的知识图谱构建具有重要意义。
基于前述研究现状,本研究在系统梳理和分析语言学术语发展脉络与发展特征的基础上,采用领域知识图谱常用的自顶向下构建模式,以《语言学名词》[9]作为结构化数据源,将传统知识图谱的节点和边的关系进行重构和梳理,基于事件理论加以事理逻辑类型,构建事理知识图谱。事理知识图谱的本质为一种以事件为节点的知识库,是知识图谱研究下的一种延伸与演化,其发展源头可追溯至20世纪 70 年代的专家系统[10]。本文的语言学术语知识图谱是以“术语事件”为核心节点和动力枢纽,以“术语事件属性值”为次核心节点和关联单元,以“术语事件关系”为演化框架和延伸路线,以“术语事件属性值关系(属性)”为结构内容和分布网络的新形态知识图谱,由此构筑语言学术语空间的演化逻辑链条,搭建术语知识的内容分布模型。基于Neo4j图数据库构建语言学术语知识图谱,梳理语言学发展现状,并总结语言学知识图谱的主要特征,从而深入地探究语言学术语知识图谱模式构建方法,以期推动语言学术语知识图谱的应用发展,并尝试为学科术语知识图谱提供一种构建范式。
1 相关理论及技术
1.1 知识图谱构建
知识图谱主要可分为两类:通用知识图谱和领域知识图谱,划分的主要标准是知识数据的领域范围和图谱构建方法的差别。通用知识图谱注重知识广度,数据一般来源于采用大规模爬虫所收集的互联网资源,通过命名实体识别及属性抽取等算法构建知识图谱,一般采用自底向上的构建模式。领域知识图谱又称为垂直知识图谱或行业知识图谱,它的知识广度限制在某一特定领域,基于该领域的专业知识进行构造,具有数据冗余量少、结构化程度高等特征,一般采用自顶向下的构建模式,更具专业性和精确性[11]。
本文所研究的语言学术语知识图谱属于领域知识图谱,其自顶向下的构建方法要求从顶层概念出发,首先是对领域知识的本体构建,在概念层先给出一个清晰合理的结构,后续的知识图谱构建再将实例和数据进行对应。本体的构建十分重要,决定了最后的知识图谱是否反映出该领域知识的广度及精度,是否可以正确体现出该领域的特点和领域间不同概念之间的关系。
大多数知识图谱在视觉上呈现为互相连接的节点和边,对应着节点、关系、属性三大要素。节点(Node)即实体对象,分为起始节点和终止节点,两个节点通过关系进行连接,节点相对于传统数据库中的ER图(Entity Relationship Diagram)中的实体,主要通过实体的标签信息进行区别,可以包含或不包含属性信息(属性信息是描述实体的信息)。关系(Relationship)在图数据库中的呈现形式即连接节点的“边”,用于表示实体与实体间的联系。属性(Property)通过KeyValue(键值对)表示,包含节点或者关系内部的某些特征信息。
1.2 图数据库Neo4j与Pyneo2
图数据库是一种NoSQL数据库,基于图形理论,表现客观世界中的实体与实体之间、实体各属性之间的关系[12]。在遍历图进行本地读取这方面,图形数据库的表现非常出色,同时还能使用各种数据图形模型及其数据扩展[13]。语义关系复杂、数据体量较大的数据常使用这种方式。相比于传统的关系型数据库,图数据库更适合作为知识图谱的存储媒介,用于图数据库处理的Cypher图形查询语言,可实现关联查询和图算法,更有利于支持查询和价值挖掘[14]。主要的图数据存储系统包括RDF图模型和属性图模型。前者以RDF(Resource Description Framework)三元组为存储对象。RDF由节点和边组成,节点表示实体/资源或者属性,边表示实体和实体之间的关系以及实体和属性的关系。RDF图模型具有较成熟的标准体系和标准查询语言SparQL,常见的数据库有Jena和Virtuoso等。属性图是目前主流图数据库选择的数据模型,更确切地说是带标签的属性图(LabeledProperty Graph),它的节点和边都可以定义属性[15]。常见的图数据库有Neo4j、FlockDB、GraphDB等类型,其中,开源的Neo4j以其高性能、高稳定性、可扩展性强等优点成为当前应用最为广泛的原生图数据库之一[16]。Neo4j采用原生图存储和处理数据,反映了关系网络中实体联系的本质,在查询中能以快捷的路径返回关联数据,表现出高效的查询性能;支持非结构化数据的存储与大规模数据的增长,能很好地适应需求的变化,具有很大灵活性。此外,它还可以对实体间复杂的关系进行分析与推理,支持逻辑语言分析与面向约束的推理。Neo4j拥有自己的查询语言——Cypher语言,它是一种面向图分析、声明式、表达能力强的描述性图形查询语言[17],对用户十分友好,操作简便,主要使用的关键字有create(主要用于创建图形节点、关系及属性)、match(在已有图形数据库中匹配目标信息)、where(是match功能的条件)、return(完成匹配后,返回指定值),基于这些查询语句实现对图形数据的分析与推理。Neo4j以美观清晰的图结构形式存储知识数据,具有节点和关系两种基本类型,每个节点表示一个实体,一个节点可以存在多个关系、属性,并由此与其他节点产生关联。关系指两个节点之间的关系,用户可根据顶层要求自主设计关系类型[12]。
Py2neo是一个客户端库和工具包,Python应用程序与命令行能够使用该库与Neo4j建立连接。Py2neo封装了官方驱动程序,添加了对 HTTP的支持、更高级别的API、OGM、管理工具、交互式控制台,用于Pygments 的CypherLexer 以及许多其他功能。Py2neo包提供了一系列的Neo4j解析和存储功能,利用Py2neo包,可以在计算机内存中建立与存储Neo4j的模型。通过生成节点与关系、过滤重复的数据,最终可生成Neo4j图形数据库[18]。本研究使用Py2neo构建Neo4j模型,并进行Neo4j数据库的增删查改等操作。
2 构建语言学术语知识图谱
2.1 构建思路
语言学术语多为名词性质,但是其中隐藏的事件名词具有动词性质,是推动术语之间关系动态化、术语图式化的核心驱动,应该重点和突出刻画。首先,以语言学学科的[理论/学说/方法]为核心节点和动力枢纽,架构起术语知识图谱的网络框架和演化模型。这样更符合语言学术语的思维习惯和认知规律。其次,以[理论/学说/方法]的存续时间、存续地域、代表人物、关键词(高频/基础/核心术语)、观点为其逻辑主体和主要内容,编制成術语知识图谱的关联网络和关联节点。最后,以[理论/学说/方法]的关键词及它们之间的关系所构成的观点(三元组:关键词术语-关系-关键词术语)为逻辑单元和关键信息,构成术语知识图谱的内容实体和知识链条。上述三点,和事件理论中的“事件”“事件关系”“事件和事件元素关系”“事件元素”“事件元素关系”存在逻辑顺应和功能对应。
基于上述思路,语言学术语知识图谱中的三元组主要包含以下三个要素:
(1)术语事件:本研究中特指语言学术语中蕴含的理论/学说/方法。它们的产生和存续行为及核心凝聚力和“事件”近似,因此称之为“(语言学)术语事件”,在知识图谱中体现为众多节点;
(2)关系:各个理论/学说/方法之间的演化模式和事件链条,在知识图谱中体现为连接节点的边;
(3)属性值:各个理论/学说/方法的存续时间、存续地域、代表人物、关键词、观点等的具体取值。
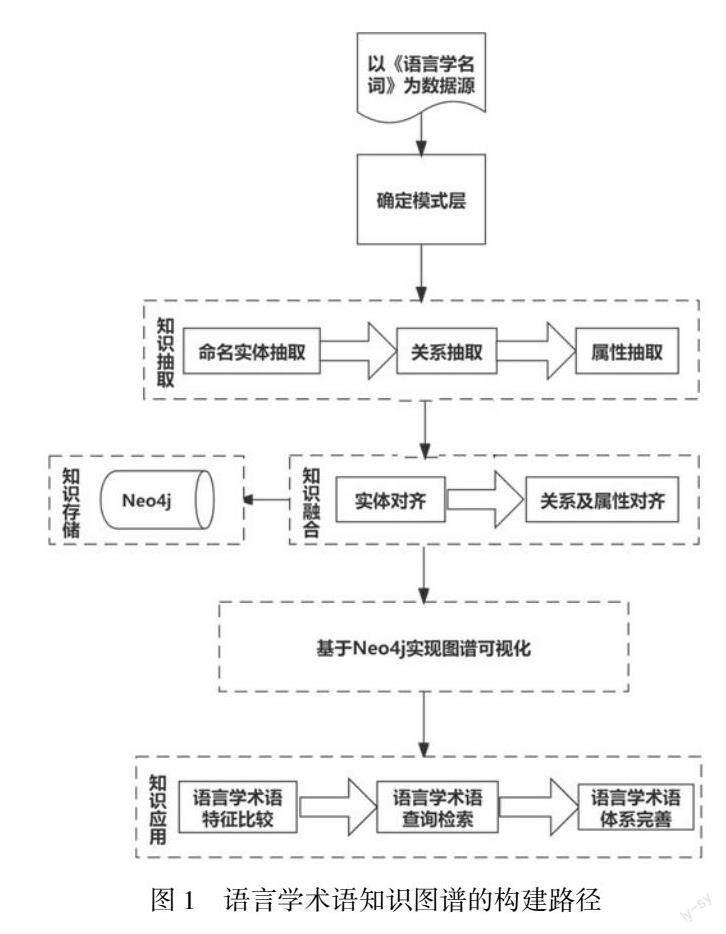
图1展示了本研究中語言学术语知识图谱的构建流程:对《语言学名词》中的知识数据进行命名实体、关系、属性的知识抽取工作后,对相关内容进行对齐,实现知识融合,之后基于Neo4j实现图谱可视化,进行知识图谱特征分析等知识应用工作。
2.2 知识来源
本研究中知识图谱的结构化数据来源于《语言学名词》。《语言学名词》是一部结构严谨的术语词典,内容是由全国科学技术名词审定委员会审定公布的语言学名词,包括理论语言学、文字学、语音学、语法学、语义词汇学、辞书学、方言学、修辞学、音韵学、训诂学、计算语言学、社会语言学、民族语言学共13部分,收词2939条[19],正文按中文名所属学科相关的概念体系和知识系统排列,定义给出其基本内涵,注释则简明扼要阐释其内涵,中文名后列出对应的英文名。本研究将其中的术语条目作为主要实体,并从术语条目的解释内容中提取出术语关系及属性值关系。
2.3 实体抽取与对齐
本研究基于《语言学名词》中的2939条术语条目,去除部分非典型术语条目,如“匹配”等,以术语条目作为知识图谱主节点,以术语事件为中心,构建语言学术语知识体系。在得到节点之后,需要进行实体对齐,即解决“名异实同”问题,检查知识图谱中的节点是否采用不同词汇指称同一概念,解决图谱数据中的实体混淆、实体歧义等问题。例如“转换生成学派”又称“生成语法学派”,如果不进行消歧去重,那么在检索过程中会产生冗余和遗漏现象,故实体对齐是知识图谱构建过程中必不可少的环节之一。因《语言学名词》是一部术语词典,词典性质本身已基本避免术语重复的情况,数据冗余量小,对于存在的少量“名异实同”的术语及阐释,本研究利用人工校对的方式将近似表达统一为相同实体。
2.4 关系及属性值抽取与对齐
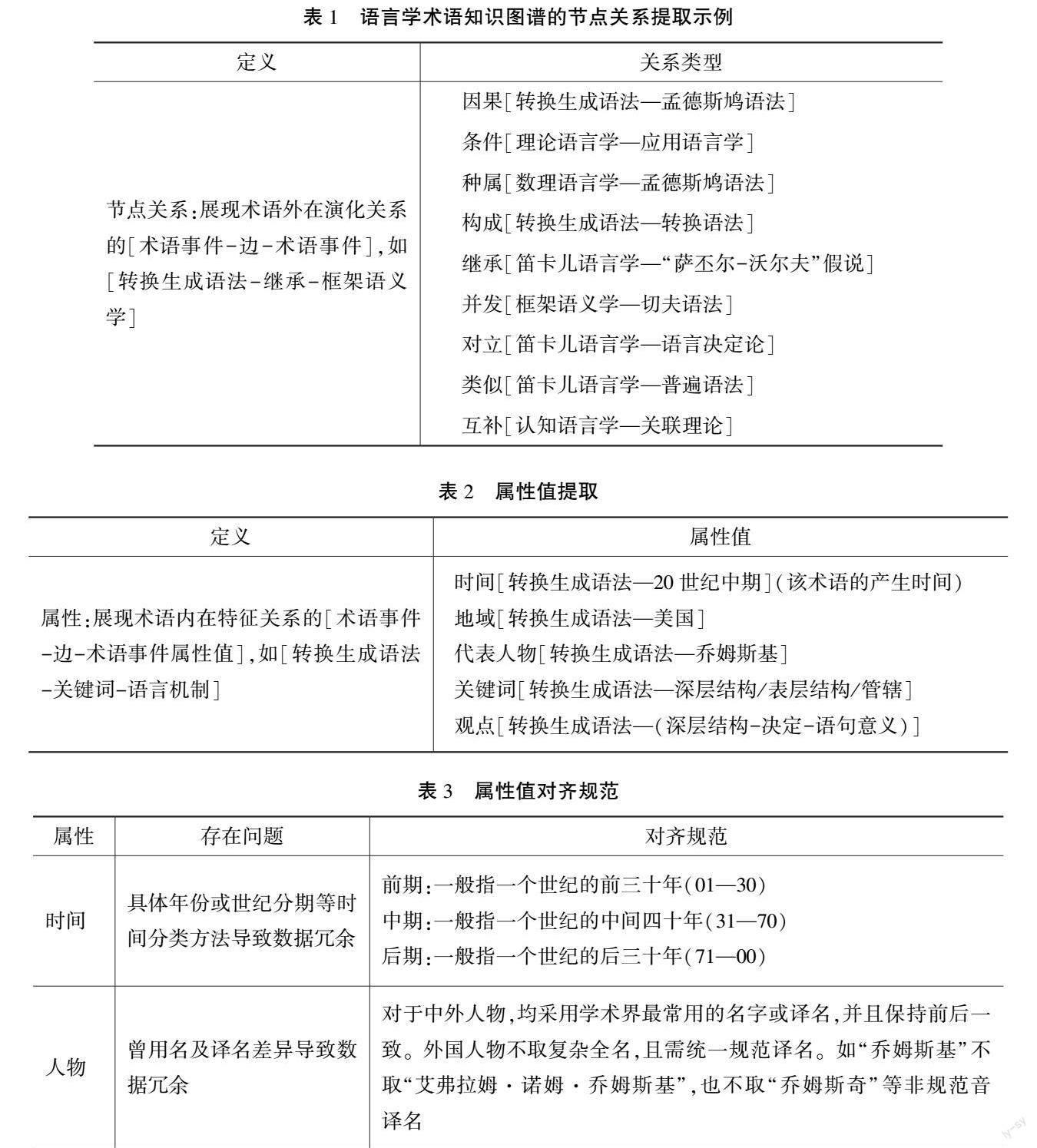
知识图谱的本质是语义网络,节点与节点之间需要用“关系”来连接。关系是使知识图谱形成网络的关键所在,本研究在语言学术语知识图谱的构建过程中,采用了事理逻辑类型来定义节点关系。事理图谱是由Yang等[20]最先提出的,是一个描述事件之间演化规律和模式的事理逻辑知识库。在层次结构上,事理知识图谱是一个有向图,其中节点代表事件,有向边代表事件之间的逻辑关系[21]。语言学术语具备清晰的发展逻辑,适合于事理图谱的构建,并可以展示语言学术语的发展变化。本研究归纳了语言学术语之间的九类实体关系:因果、条件、种属、构成、继承、并发、对立、类似、互补,能够揭示语言学术语的演化规律与逻辑,如表1所示。
上述九类关系是从术语外部出发的关系。术语从内部看,由众多属性构成,属性是术语内部的构成要素,语言学术语发生于一定的时空范围内,对于某一个术语事件,其实体本身大多数具备时间、地域、代表人物、关键词、观点等属性值,本研究根据语言学术语所包含的重要知识特征,定义了五个属性值,用以从术语事件内部发掘术语内在特征之间的规律,如表2所示。
属性值对齐指针对同一属性的属性值存在多种表达形式的问题,设置统一的标注规则,减少数据冗余,提高知识表达能力。如时间属性中“20世纪中期”与“20世纪50年代”的属性值表述不同,但所指概念基本相同,此类问题为属性值冗余问题。就本次研究而言,属性值冗余问题主要存在于时间和人物属性,采取统一的格式规则对这两种属性进行对齐,如表3所示。
2.5 知识存储及可视化实现
本研究采用自顶向下的构建模式,对节点、属性、关系的相关类别进行顶层设计和格式规范后,进行《语言学名词》术语收集和三元组构建工作。最终汇总得到6211条三元组,两端的实体(属性)由中间的关系连接,如表4所示。
利用Py2neo及Cypher语法将csv文件导入Neo4j数据库中,并进行可视化图谱展示,因图谱体量庞大,故节选部分节点关系作为示例,如图2所示。在Neo4j中,以“共时语言学”父节点为例,其“人物”关系的属性值为“索绪尔”,“地点”关系的属性值为“瑞士”。 同时该节点以“历史比较语言学节点”为“条件”关系,与“历时语言学”为“对立”关系。通过 Neo4j 中层次化的图结构可以将语言学术语中的关系与属性直观地展示出来。
知识图谱具有丰富的检索功能,基于此知识图谱,可以从多种角度梳理语言学术语的发展脉络,更清晰地了解语言学的发展历史及现状。本研究也在后文以某些宏观特征进行简单分析。
3 语言学术语知识图谱内容分析与讨论
3.1 整体特征分析
(1)数量庞大,涵盖面广。语言学是一门历史悠久的学科,其术语涉及的知识范围也很庞大,本次研究共生成6263组三元组,上至传统的小学,下至新兴的交叉学科,跨度广,知识精细程度高,是一个较为系统全面的领域知识图谱。该图谱的构建也有助于后期拓展语言学术语研究的深度和广度。
(2)层次清晰,结构性强。本次研究的数据源《语言学名词》将语言学术语划分为理论语言学、文字学、语音学等13个部分,每一部分再拆分为小分支,如第二部分“文字学”所辖分支有总论、汉字的起源和发展、汉字的结构、汉字的形体、汉字系统内部关系、汉字政策、应用研究等。每一部分的小分支数量不固定,但条目大约控制在300条之内,是知识图谱构建过程中可以直接使用的结构性数据。
(3)规范性强。语言学术语本身作为学术研究的产物,具有准确严谨的特点。如“深层结构”“表层结构”“层次分析法”等在理论诞生之初就已经定义完备,具备不可更改和不可替换的特质。在《语言学名词》的术语条目阐释中,往往先给出其上位概念,后指出其含义,最后说明其影响。这种较为固定的术语阐释模式也为节点、关系和属性的提取提供了便利,具有较强的规范性。
3.2 局部特征分析
基于Neo4j的Cypher语法,可以根据检索需求筛选需要的知识数据,从而发现语言学术语的某些发展规律,本研究仅以地点属性为例简要说明检索过程。如对于术语地点属性值进行全图检索,输入Cypher命令:MATCHp=()[r:′地點′]>()RETURNpLIMIT300,可以得到地点属性的部分节点,其中比对图表可得“美国”在术语地点属性值中占有最高的频次,如图3所示。可见在语言学的发展中,美国具有最多的术语产出。
3.3 语言学术语事理动态关系探讨
语言学术语知识图谱的组织和架构,既不能与通用知识图谱一样,偏重[实体-关系-实体]和[实体-属性-属性值],忽略宏观的、大颗粒的知识演化框架,也不能与事理图谱一样,偏重[事件-关系-事件],忽略微观、细颗粒的知识关联形态。应充分融合静态知识图谱和动态事理图谱的构造特征和存在模式,构建基于“静态-动态”融合特征的语言学术语知识图谱。虽然术语多是名词性质的,但是其中隐藏的事件名词具有动态性质,它们是推动术语之间关系动态化、术语图式化的核心驱动,应该重点和突出刻画。人类的命题记忆是以“事件”为存储单位的,存储的是组成事件的概念及其之间的关系以及事件与其之间的关系[22]。以事件作为知识的基本单元更能反映知识,特别是知识的动态性,从认知科学的角度来看,事件更符合人类的理解与思维习惯。
本文正是采用事理逻辑的类型来构建节点间的关系,并且逻辑类型所构成的三元组又恰好成为术语事件的“观点”属性值,如图4所示,转换生成学派的“观点”属性指向“深层结构-决定-表层结构”三元组。某一观点内部已构成三元组,同时以一个整体作为更高层级三元组的构成要素,这显示了语言学术语发展的动态关系和事理逻辑,较小层级的节点关系层层嵌套,推进大节点关系的构成与发展,并最终推动语言学术语的发展。
4 结语
本文展现了语言学术语知识图谱的构建过程,并最终实现了知识图谱的呈现,所构建的较为完备的语言学术语知识图谱,填补了学界对语言学知识图谱的研究空白,可以使用此图谱查询数据以发现语言学术语的演变规律。其次本文提供了一种“动态-静态”的术语图谱构建模式,该构建模式适用于大多数学科术语图谱模式的构建,具备一定的可迁移性。该方法也有助于构建一种从词典的单向封闭主义转向“词典-用户”的双向融合互动的融媒体辞书[23]。此外基于Neo4j的功能,该图谱可以外接至网站接口,实现面向用户的前端图谱网页。
本次知识图谱构建中,还存在不足。首先,参考有限。由于目前还没有中国学者对语言学术语知识图谱进行构建和研究,本文只能参考与本项研究的目的相类似的知识图谱研究,总体来说技术上还不成熟。虽然获得了相对完整的语言学术语知识图谱体系,但在关系准确率方面还存在问题,一些孤立节点缺乏与其他术语的联系,需要在后期研究中进一步挖掘术语之间的深度关系。其次,数据来源较为单一。本文的语言学术语知识渠道依赖于《语言学名词》,所以知识数量具有局限性,抽取的知识数量不够,图谱精度还有待提高,在后期研究中将会补充其他语言学百科类书籍及相关文献作为数据源。再次,数据更新能力较差。本研究的数据源《语言学名词》是2011年出版的,此后新出现的语言学术语未被纳入,数据具有滞后性。针对此问题,后期将会加入爬虫框架从各种语言学学术网、会议网、语言学者博客、百度百科、维基百科等提取最新语料,并基于相关模型进行命名实体识别和自动特征学习。
参考文献
[1] 刘峤, 李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600.
[2] 国务院关于印发新一代人工智能发展规划的通知[A]. 中华人民共和国国务院公报, 2017(22): 7-21.
[3] 董晓晓, 周东岱, 黄雪娇, 等. 学科核心素养发展导向下教育领域知识图谱模式构建方法研究[J]. 电化教育研究, 2022, 43(5): 76-83.
[4] 王松, 李正钧, 杨涛, 等. 中医药知识图谱研究现状及发展趋势[J]. 南京中医药大学学报, 2022, 38(3): 272-278.
[5] 肖飞龙, 张爽, 胡志凌. 基于Neo4j的疾病预防与控制知识图谱研究[J]. 电子技术与软件工程, 2021(22): 180-182.
[6] 陈风华, 弗朗西斯科·维勒索. 多模态话语研究的知识图谱演化分析:基于国内外核心期刊的研究[J]. 华侨大学学报(哲学社会科学版), 2017(6): 154-166.
[7] 刘霞, 许家金, 刘磊. 基于CiteSpace的国内语料库语言学研究概述(1998—2013)[J]. 语料库语言学, 2014, 1(1): 69-77,112.
[8] 赵世举, 郑蒙. 术语与科技话语能力建设:法国的实践及启示[J]. 语言战略研究, 2022, 7(5): 58-68.
[9] 全国科学技术名词审定委员会. 语言学名词[M]. 北京: 商务印书馆, 2011.
[10] 白璐. 面向政治领域的事理演化图谱构建[D]. 北京:国际关系学院, 2020:19.
[11] 付雷杰, 曹岩, 白瑀, 等. 国内垂直领域知识图谱发展现状与展望[J]. 计算机应用研究, 2021, 38(11): 3201-3214.
[12] 孙敏敏, 毛雪岷. 基于Neo4j的肺部疾病知识图谱构建[C]//第十五届(2020)中国管理学年会论文集. 中国管理现代化研究会,复旦管理学奖励基金会, 2020: 25-30.
[13] POKORN J. Functional querying in graph databases[J]. Vietnam Journal of Computer Science, 2018, 5(2): 95-105.
[14] JOUILI S, VANSTEENBERGHE V. An Empirical Comparison of Graph Databases[C]//2013 International Conference on Social Computing. Alexandria, VA, USA: IEEE, 2013: 708-715.
[15] 王力, 韩红旗, 高雄, 等. 关系数据库向Neo4j图数据库转化的应用研究:以工程科技词系统为例[J]. 中国科技资源导刊, 2021, 53(5): 55-65.
[16] FLEMING J, LEVY S, NAG P, et al. Graph database system and method for facilitating financial and corporate relationship analysis[P]. United States Patent 8674993,2014-03-18.
[17] 张维冲, 王芳, 黄毅. 基于图数据库的贵州省大数据政策知识建模研究[J]. 数字图书馆论坛, 2020(4): 30-38.
[18] 苏翔. 基于知识图谱的“数据结构”教学资源平台的构建研究[D]. 北京:北京林业大学, 2019:17.
[19] 《语言学名词》出版[J]. 语文研究, 2012,122(1): 45.
[20] YANG C C, SHI X. Discovering event evolution graphs from newswires[C]//Proceedings of the 15th international conference on World Wide WebWWW06. Edinburgh, Scotland: ACM Press, 2006: 945.
[21] 朱福勇, 刘雅迪, 高帆, 等. 基于图谱融合的人工智能司法数据库构建研究[J]. 扬州大学学报(人文社会科学版), 2019, 23(6): 89-96.
[22] 仲兆满, 刘宗田, 李存华. 事件本体模型及事件类排序[J]. 北京大学学报(自然科学版), 2013, 49(2): 234-240.
[23] 王兴隆, 亢世勇. 新时代融媒體汉语学习词典的融合特征及其优化路径:以《当代汉语学习词典》为例[J]. 语言文字应用, 2021(4): 132-141.
作者简介:王浩学(2000—),男,广西大学文学院硕士研究生,研究方向为实验语音学、计算语言学,主持国家级大学生创新项目1项、广西研究生创新项目1项、山东省语言资源开发与应用重点实验室开放课题1项,发表CSSCI论文1篇。通信方式:wanghx@st.gxu.edu.cn。
王兴隆(1982—),男,鲁东大学文学院副教授,国家语委汉语辞书研究中心、山东省语言资源开发与应用重点实验室专职研究员。主要研究方向为二语学习、词汇学与词典学。主持各类科研项目11项,包括国家语言文字工作委员会重点项目、全国科学技术名词审定委员会项目、教育部语言合作中心项目、山东省社会科学规划项目等。在《外语教学与研究》《语言文字应用》等期刊(包括CSSCI期刊)、论文集发表论文20余篇。获山东省高校人文社科优秀成果一等奖1项,主编论文集2部。通信方式:wangxinglong100@163.com。
猜你喜欢
现代情报(2016年11期)2016-12-21 23:54:23
现代情报(2016年11期)2016-12-21 23:53:46
现代情报(2016年10期)2016-12-15 12:32:46
现代情报(2016年10期)2016-12-15 12:27:57
新教育时代·教师版(2016年33期)2016-12-02 22:26:31
智富时代(2016年12期)2016-12-01 16:28:41
中国远程教育(2016年9期)2016-11-19 12:21:26
商场现代化(2016年23期)2016-11-17 19:31:01
中国教育信息化·基础教育(2016年9期)2016-10-18 02:29:50
电脑知识与技术(2016年7期)2016-05-19 13:54:36
