
融合动态卷积注意力的机器阅读理解研究
2023-07-21 07:50:22吴春燕黄鹏程刘知贵张小乾
计算机技术与发展 2023年7期
吴春燕,李 理,黄鹏程,刘知贵,,张小乾
(1.西南科技大学 计算机科学与技术学院,四川 绵阳 621000;2.西南科技大学 信息工程学院,四川 绵阳 621000)
0 引 言
机器阅读理解(Machine Reading Comprehension,MRC)要求机器阅读并理解人类自然语言文本,在此基础上,回答跟文本信息相关的问题[1]。该任务通常被用来衡量机器理解自然语言的能力,可以帮助人类从大量文本中快速聚焦相关信息,降低人工获取信息的成本。作为自然语言处理(Natural Language Processing,NLP)的研究方向之一,机器阅读理解近年来已受到工业界和学术界广泛的关注。
机器阅读理解模型的研究历史可以追溯到20世纪70年代[2],当时的研究人员已经意识到机器阅读理解可以作为测试计算机语言理解能力的一种方法。其中最具代表性的是1977年Lehnert提出的QUALM问答程序[3],该程序专注于实用主义,为机器阅读理解提供了发展的远景。然而由于其规模小、领域特殊等限制,使得该系统无法推广到更广泛的领域。受限于当时数据集和技术的发展,这一领域的研究进展缓慢。直到二十世纪初,随着社会的发展和进步,一些用于阅读理解的大规模数据集相继被提出,如Mctest[4]、Stanford Question Answering Dataset(SQuAD)[5]、RACE[6]等,这些数据集使得研究者们能够用深层神经网络结构模型解决阅读理解任务[7]。
目前机器阅读理解主要采用的深度学习技术包括卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)和注意力机制。其中CNN擅长提取局部特征;注意力机制旨在关注全局结构特征;RNN则在序列建模中表现优异。然而,目前的工作仅聚焦在使用RNN和注意力机制对文本进行全局建模,忽略了对文本局部结构的捕获,导致模型对文本理解不足,回答问题不准确。针对这一问题,该文提出了一个融合动态卷积注意力的机器阅读理解模型。主要工作内容如下:
(1)采用改进的长短期记忆网络(Long Short-Term Memory,LSTM)——Mogrifier作为编码器,让输入与前一个状态进行多次交互,防止上下文信息流失。
(2)将动态卷积和注意力机制结合同时提取文章局部和全局结构特征,增强基线模型文本建模的能力,提高模型性能。并在公共数据集SQuAD上进行实验,分析实验结果和模型结构对模型性能的影响。
1 相关工作
1.1 任务定义
机器阅读理解任务通常被定义为[8]:给定长度为m的文章P,即P={p1,p2,…,pm},长度为n的问题Q={q1,q2,…,qn},模型需要通过学习函数F使F(P,Q)→A,从中提取连续子序列A={ai,…,ai+k}(其中1≤i≤i+k≤m)作为问题Q的正确答案。训练数据为文章、问题、答案组成的三元组
1.2 基于深度学习的机器阅读理解相关研究
为了捕获文章和问题的语言特征,注意力机制、循环神经网络及其变体长短期记忆网络和门控循环单元(Gated Recurrent Unit,GRU)和卷积神经网络在模型中表现出优异的性能。早期的模型中采用简单的注意力机制,如Hermann等人[9]提出的Attentive Reader,通过计算问题和文章之间的注意权重得到它们的交互信息,Kadlec等[10]提出的Attention Sum Reader和Chen等[11]提出的The Stanford Attentive Reader模型在一定程度上提升了文本相似度的计算能力。然而,这些模型中的注意力无法理解文本的深层含义。
针对这一问题,研究者们开始对深层注意力进行研究。Seo等[12]提出的BiDAF模型同时计算文章到问题和问题到文章两个方向的注意力权重,以获得它们之间更深层的交互信息,达到增强模型的语义表示能力的目的。Chen等[13]通过将词性等语法特征融入词嵌入层,丰富词的向量表示,经过模型处理得到答案。Wang等[14]提出R-Net模型,使用门控的基于注意力的循环网络来计算文章和问题的相似度,以获得问题感知的文章表示,之后通过自匹配的注意力机制改善文章表示,实现整个文章的有效编码。Huang等[15]提出了Fusion- Net模型,通过单词级注意力、句子级注意力等不同层次的特征注意融合作为输入,同时使用所有层的表示,达到更好的文本理解。Yu等[16]提出了一个不含RNN网络的架构,仅由注意力和卷积组成的机器阅读理解模型QANet,虽然带来了训练和推理速度的提升,但无法表示出句子深层次的含义。
以上提出的模型往往采用注意力机制、RNN(LSTM、GRU)和卷积三者中的部分组合对上下文和问题进行交互建模,虽然注意力可以解决长距离的依赖关系,但深层次的注意往往过度集中在单个标记上,而忽略局部信息的利用,难以表示长序列;RNN由于其顺序特性,不能并行处理,使得模型在训练和推理方面都很耗时;卷积由于其窗口滑动的特性,只能捕捉文章和问题的局部特征。因此,如何利用它们的优点以构建更有效的语言特征提取模型是当前研究的重点任务。
2 DCAM模型结构设计
针对片段抽取型机器阅读理解目前存在的语义信息提取不足等问题,提出一种融合动态卷积注意力的机器阅读理解模型(hybriding Dynamic Convolution Attention mechanisms machine reading comprehension Model,DCAM),经过编码层获得文本的序列表示,再通过问题对文章的注意权重得到融合问题特征的文章表示,采用结合动态卷积的注意力机制捕获问题感知的文章表示中的局部和全局关系,利用自注意力机制进一步挖掘文本之间的联系,经过两层双向LSTM建模后传入输出层,得到预测答案的起始位置。该模型一共包含词嵌入层、编码器层、多注意力层以及答案输出层四个部分,其整体结构如图1所示。

图1 融合动态卷积注意力的机器阅读理解结构
2.1 词嵌入层
该层旨在将文章P和问题Q中的词表示特征映射到高维空间,获取词嵌入的一种典型技术是将单词嵌入与其他特征嵌入连接起来作为最终的词向量表示。单词嵌入使用预训练的300维GloVe向量[17]来表示Q和P,其中文章P中的每个单词pi额外使用三种特征嵌入和问题增强嵌入,特征嵌入分别为9维词性标签嵌入、8维命名实体识别嵌入和3维二进制精确匹配特征嵌入;问题增强嵌入由问题表示经过一个280维的单层神经网络得到。
在词嵌入层,文章中的每个标记pi表示为一个600维向量,问题中的每个标记qj表示为一个300维向量。为了解决维度不匹配的问题,采用两层独立的全连接位置前馈网络,将段落和问题词汇编码映射到相同数量的维度。
FFN(x)=W2ReLU(W1x+b1)+b2
(1)
其中,x为段落和问题的词汇编码,W1、W2、b1、b2为需要学习的参数。
通过词嵌入层输出得到P中每个标记最终的词汇矩阵Ep∈Rd×m和Q中每个标记最终的词汇嵌入矩阵Eq∈Rd×n,其中d表示全连接神经网络隐藏层的大小,m表示文章P的长度,n表示问题Q的长度。将文章和问题的词汇矩阵作为下一个模块的输入。
2.2 编码器层
由于原始LSTM中输入x和之前的状态hprev是完全独立的,可能导致上下文信息的流失。该模型在编码层采用Melis等[18]提出的Mogrifier替代传统的LSTM,将输入x与之前的状态hprev进行多次交互,再输入到各个门里进行运算。其结构如图2所示。

图2 Mogrifier结构
在普通的LSTM计算之前,交替地让x与hprev交互,即:
(2)


for oddi∈[1,2,…,r]
(3)

for eveni∈[1,2,…,r]
(4)
其中,⊙表示哈达玛积,Qi和Ri为随机初始化矩阵,r是交互轮数,若r=0,则为普通的LSTM。
文章和问题都使用一个两层的Mogrifier将词汇嵌入投射到上下文嵌入,再拼接一个预训练的600维上下文CoVe向量[19]Cp、Cq,作为上下文编码层的最终输入,并将第一个上下文编码层的输出作为第二个编码层的输入。为了减少参数大小,在每个Mogrifier层上使用一个maxout层[20]来缩小矩阵的维度。通过连接两个Mogrifier层的输出,得到文章P的最终表示Hp∈R2d×m和问题Q的最终表示Hq∈R2d×n,其中d为Mogrifier的隐藏层大小。
Hp=BiMogrifier(Ep;Cp)
(5)
Hq=BiMogrifier(Eq;Cq)
(6)
其中,;表示向量/矩阵串联运算符。
2.3 多注意力层
注意力机制作为一种权重分配机制,可以对重要的语义信息分配较多的注意力。在阅读理解任务中,文章和问题中不同的词对问题的回答的影响是不同的,因此在模型中采用多注意力机制来识别文章和问题中哪些词与答案最相关,该层是模型的核心部分。
2.3.1 互注意力机制
将Mogrifier的输出作为该层的输入,首先利用点积注意力计算Q和P中词汇标记的对齐矩阵,并使用该矩阵得到问题感知的段落表示。
(7)

2.3.2 动态卷积注意力机制
由于单独的注意力机制会受到分散权重的影响,不适合长序列表征学习。而结合卷积的注意力机制[21]混合了逐点变换、卷积和自注意力机制,可以并行学习文本的多角度多层次序列表示。因此,在基线模型中加入结合动态卷积的注意力机制(Dynamic Convolution Attention,DCA),该注意力机制包含三个主要部分:捕获全局特征的自注意力机制,捕获局部特征的动态深度可分离卷积,以及用于捕获标记特征的位置前馈网络。该模块获取前一层的输出矩阵M作为输入,并以融合的方式生成输出表示:
C=M+Att(M)+Conv(M)+Pointwise(M)
(8)
其中,Att表示自注意力机制,Conv表示动态卷积,Pointwise表示位置前馈网络。图3表示了该注意力的详细结构。

图3 动态卷积注意力机制结构
自注意力机制负责学习全局语境的表征。对于前一层的输入序列M,它首先将M进行线性变换产生键K、查询Q和值V,然后使用自注意力机制来获得输出表示:
Att(M)=σ(QWQ,KWK,VWV)WO
(9)
其中,Q=Linear1(M),K=Linear2(M),V=Linear3(M),WO、WQ、WK和WV为权重矩阵,σ是键、查询和值对之间的点积生成,见公式(10):
(10)
为了和自注意力在相同的映射空间中学习上下文序列表示,选取深度方向卷积[22]的变体—动态卷积[23]进行卷积运算。每个卷积子模块包含多个内核大小不同的单元,用于捕捉不同范围的特征。卷积核大小为k的卷积单元的输出为:
Convk(M)=Depth_convk(V2)Wout
(11)
V2=MWV
(12)
其中,W、V和Wout是参数,WV是逐点映射变换矩阵。
含有多个卷积核的卷积运算如公式(13)所示:
(13)
为了学习单词级表示,卷积注意力在每一层连接一个自注意力网络和一个位置前馈网络。
Pointwise(M)=max(0,MW3+b3)W4+b4
(14)
其中,W3、b3、W4和b4是映射参数。
2.3.3 自注意力机制
通过上下文信息表征Hp和通过卷积注意得到的问题感知表示Hq·C的简单连接来表示从文章中提取的所有信息。
Up=concat(Hp,HqC)∈R4d×n
(15)
通常一篇文章可能包含数百个单词,很难完全捕获长距离依赖关系。于是采用一个独立的自注意力层进一步捕获文章中的远距离依赖关系。
(16)
最后根据多注意力层收集到的所有信息,使用BiLSTM生成历史记忆,作为答案预测模块的输入。
(17)
其中,;表示向量/矩阵串联运算符。
2.4 答案输出层
利用记忆网络输出答案。将记忆网络的初始状态向量初始化为:
(18)
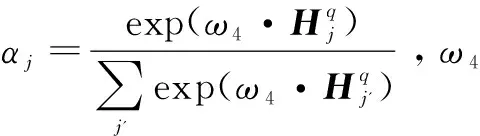
在时间步{0,1,…,T-1}的范围内,第t步的状态定义为:
st=GRU(st-1,xt)
(19)
其中,xt由前一个状态st-1和历史记忆M计算而来。
(20)
βj=softmax(st-1W5M)
(21)
其中,W5为要学习的权重矩阵。
最后使用双线性函数来查找每个推理步骤t∈{0,1,…,T-1}的答案范围的起点和终点。
(22)
(23)
其中,W6、W7为权重矩阵,;表示向量/矩阵串联运算符。
根据答案预测模块输出的一对起点和终点,可以从文章中提取答案片段。该模型通过利用所有T步输出的平均值作为最终的预测答案起始点,使得答案的输出不依赖于具体某一步起始点的产生。
(24)
(25)
为了防止各个模块之间信息的丢失以及模型过拟合的发生,在所有模块的最后一层添加一个随机丢弃层,丢弃率设置为0.4,使模型不依赖于特定的步骤或模块来预测答案。
3 实 验
3.1 实验数据
实验数据采用斯坦福大学发布的SQuAD数据集,该数据集用于片段抽取型阅读理解任务,共包含107.7 K个(文章,问题,答案)三元组。其中87.5 K个问答对作为训练集,10.1 K个问答对作为验证集,10.1 K个问答对作为测试集。表1为SQuAD数据集的样例。

表1 SQuAD数据集样例展示
3.2 实验设置
实验代码基于Python语言及其第三方库,深度学习环境采用Pytorch框架。并在具有两个1 660 Super的GPU上进行训练,单模型训练时占用显存约12 GB,通常训练10个epoch至收敛,整个模型完成训练约需12个小时。模型训练过程中,使用的部分参数设置如表2所示。

表2 参数设置
3.3 评价指标
将提出的模型在SQuAD数据集上进行评估。斯坦福大学官方给定了两个度量准则用以评估模型的性能。
(1)精确匹配(Exact Match,EM)。如果预测答案等于真实答案,EM值为1,否则为0。
(2)F1 Score。预测答案和真实答案之间精确率(precision)和召回率(recall)的调和平均值。
即:
3.4 实验结果及分析
3.4.1 对比实验
为了评估模型的效果,将提出的模型与以下几个模型进行实验对比:
DCN+模型[24]采用双向LSTM对文章和问题进行编码,利用堆叠的自注意力机制和互注意力机制捕获结构特征。
R-Net模型[14]使用双向LSTM作为编码器,并在注意力机制中加入门控机制来筛选出对回答问题相关性强的语义信息部分。
FusionNet[15]采用双向LSTM对文章和问题编码,融合多层注意力来理解文章和问题浅层和深层含义。
QANet[16]采用自注意力机制和深度可分离卷积对文章和问题进行编码,同时使用互注意力机制计算文章和问题的相似度来确定与回答最相关的信息。
SAN模型[25]为选取的基线模型,采用双向LSTM作为编码器,并使用互注意力机制和自注意力机制捕获文章的结构,通过记忆网络来预测答案的起止位置。
选择的对比模型与提出模型的结构及采用的注意力机制对比如表3、表4所示。

表3 模型结构对比
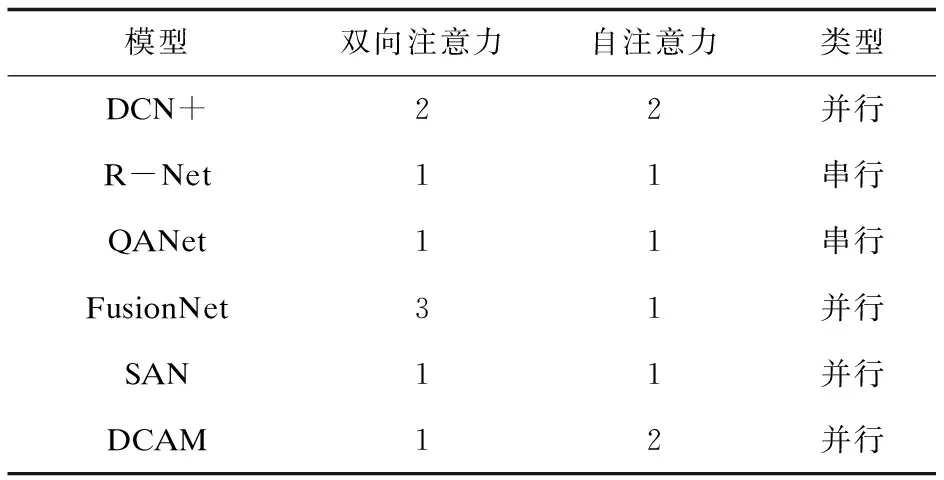
表4 各模型结构中的注意力机制比较
以上可以看出所提模型与其他模型的不同之处,即所提模型在不影响训练速度的情况下,将RNN、CNN和注意力机制融为一体,特别是采用了动态卷积代替普通卷积,并与注意力机制结合,从多层次和多角度提取文本特征,这样可以更好地利用它们的优势,提高文本之间的交互程度。
对比模型与DCAM的实验结果如表5所示。

表5 对比实验结果 %
从表5可以看出,所提模型由于在编码层采用的结构增强了文章和问题在低层语义表示的交互;此外,添加的卷积结构也加深了机器对文章局部结构的理解,弥补注意力机制只能捕获全局结构的不足。在SQuAD数据集上的EM值和F1值分别达到了76.74%、84.30%,相比基线模型SAN其EM值和F1值分别提高了0.81百分点和0.56百分点。同时在SQuAD数据集上的表现也均优于其他对比模型,这得益于DCAM将三种结构的优势相结合。实验结果表明该模型在阅读理解任务上的有效性。
3.4.2 消融实验
DCAM模型是在SAN上进行的改进。为了验证改进模块对模型性能的影响,设计消融实验比较改进模块之后模型的EM值和F1值大小。其实验对比结果如表6所示。

表6 消融实验结果 %
从表6可以看出,使用结合卷积的注意力机制在EM值和F1值上分别提升了0.41百分点和0.26百分点,采用改进的LSTM作为编码器在EM值和F1值上分别提升了0.48百分点和0.41百分点,同时改进则获得0.81百分点的EM值提升和0.56百分点的F1值提升。结果表明改进的两个模块均能够加深模型对文章和问题的理解,提高模型回答问题的准确率。
3.4.3 卷积注意力大小对模型性能的影响
一般来说,卷积核越小,所需的参数量和计算量越小。卷积核越大,其感受野越大,相应的参数量和计算量也越大。但多层小卷积核堆叠不仅可以减少计算量,还能达到大卷积核一样的感受野。这里采用实验里常用的卷积核大小1、3、5来探索不同卷积核大小对模型性能的影响,结果如表7所示。

表7 卷积核大小 %
从表7的结果可以看出,卷积核越大,模型的EM值和F1值越低;卷积核越多,模型的EM值和F1值越高。当只采用单个卷积核时,卷积核大小为3的卷积比卷积核大小为5的卷积对模型的EM值和F1值提升较大,分别高出0.39百分点和0.40百分点;当采用多个卷积核组合时,不同的卷积组合对模型性能均有提升,但1、3、5的卷积组合对模型的EM值和F1值提升更高,相较于3、5的卷积组合分别提升了0.30百分点和0.20百分点。因此,在实验过程中选择卷积核大小为1、3、5的组合。
4 结束语
为解决语义表示能力差、信息冗余、信息丢失等问题,提出了一种融合动态卷积注意力的机器阅读理解模型。该模型利用Mogrifier加强相关文本之间的特征表示,借助注意力机制捕获文章和问题中的相关信息,结合动态卷积注意力进一步捕获文章的局部和全局结构。在SQuAD阅读理解数据集上进行了实验验证,结果表明引入动态卷积和多注意力机制的模型能够有效提高机器阅读理解的准确性,具有一定的应用价值。在未来的研究工作中,可以考虑与大规模的预训练模型(如BERT、RoBERTa等)相结合,进一步提升机器阅读理解模型的性能。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
环球时报(2022-03-14)2022-03-14 18:19:44
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电影(2018年8期)2018-09-21 08:00:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
