
基于攻击上下文分析的多阶段攻击趋势预测
2023-07-21 07:50:18朱光明卢梓杰冯家伟张向东张锋军牛作元
计算机技术与发展 2023年7期
朱光明,卢梓杰,冯家伟,张向东,张锋军,牛作元,张 亮
(1.西安电子科技大学 计算机科学与技术学院,陕西 西安 710071;2.西安电子科技大学 通信工程学院,陕西 西安 710071;3.中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引 言
与以影响或瘫痪目标系统为目标的网络攻击不同,高级可持续威胁(Advanced Persistent Threat,APT)攻击具有非常强的隐蔽性和持续性[1],一般是由专业组织发起,长期综合运用多种攻击手段对特定目标进行渗透,主要目的是获取目标的关键信息[2]。根据网络杀伤链模型(Cyber Kill Chain,CKC),APT多阶段网络攻击可分为7个步骤:侦察、武器化、投递、漏洞利用、安装、指挥和控制、目标行动[3]。对标CKC模型,MITRE ATT&CK[4]模型根据真实的观察数据来描述和分类对抗行为,总结出了常用的14种战术和200多种技术。传统的攻击防御系统,如入侵检测系统(Intrusion Detection System,IDS)、入侵防御系统(Intrusion Prevention System,IPS)、高级安全设备(Advanced Security Appliances,ASA)等[5-6],无法有效发现隐蔽的APT攻击,难以对后续的攻击做出预测及防御。网络流和系统日志虽然可以记录APT攻击过程,但是APT攻击的隐蔽性和持续性决定了无法依靠单步攻击检测来发现整个攻击过程。随着网络规模的日益增长,网络流和系统日志数量也与日俱增,迫切需要把机器学习方法运用到网络安全领域,实现对网络攻击过程的自动检测。
基于机器学习的网络攻击检测算法研究需要相应的数据集来支撑。在网络流数据集方面,相继有UNSW-NB15[7]、NSL-KDD[8]、CICIDS2017[9]、CICIDS2018[10]、DAPT2020[11]等数据集被提出并开源。目前基于网络流量的异常检测主要聚焦于单步攻击检测,无法捕获多阶段攻击的长期行为。刘景美等人[12]提出了基于自适应分箱特征选择的快速网络入侵检测算法,主要解决传统入侵检测系统查全率较低以及基于深度学习的入侵检测的训练用时过长的问题,在NSL-KDD数据集上进行了验证。Myneni等人[11]在DAPT2020数据集上使用编码-解码模型训练重建良性网络流数据,重建误差过大的数据被判定为异常数据。这种方法单独对每个网络流包进行检测,忽略了多阶段攻击的上下文关系,导致异常的准确率和查全率低。Allard[13]在DAPT2020论文模型方法的基础上引入了有效载荷,但还是无法有效解决这个弊端,在横向移动阶段检测性能依旧较差。针对当前研究对APT攻击多阶段流量特征的多样性感知不足的问题,谢丽霞等人[14]提出一种基于样本特征强化的APT攻击多阶段检测方法,引入多阶段感知注意力机制,提高了APT攻击多阶段检测的精度。
与网络流相比,系统日志可以更加详尽地记录APT攻击在主机上的执行过程。在基于系统日志分析的攻击检测方面,通过系统日志数据构建抽象表达能力强的溯源图并分析因果关系,可以有效表达威胁事件的起因、攻击路径和攻击影响,为威胁发现和取证分析提供更高的检测效率和性能[15]。自然语言处理技术在系统日志文本分析方面也发挥重要作用[16-17]。ATLAS[18]是一种用于重建攻击故事的框架,利用自然语言处理技术和基于序列的模型学习技术从审计日志中恢复攻击步骤。LogAnomaly[19]是一个数据驱动的深度学习框架,用于非结构化日志流的异常检测,日志解析中用到了Word2Vec[20]方法来构成日志序列,利用LSTM(Long Short-Term Memory)模型来预测日志是否异常。LogBERT[21]是一种基于BERT(Bidirectional Encoder Representation from Transformers)[22]的日志异常检测方法,通过两个自监督训练任务学习正常日志序列的模式,能够检测出底层模式偏离正常日志序列的异常。DeepLog[23]是一种基于LSTM的深度神经网络模型,把日志信息建模成自然语言序列来处理,自动提炼正常的日志序列进行训练;当日志序列偏离训练的模型时,可以检测出异常。Li 等人[24]提出了DeepAG,能够同时检测APT序列和利用日志语义向量和索引来定位序列中的攻击阶段,并根据上述日志索引构建攻击图。
上述方法都利用了日志的语义向量序列,并基于深度学习框架进行攻击检测;可以定位日志序列中的异常点,但并没有提出如何预测攻击者下一步的攻击行为。尽管这些方法能做到实时监测日志,但是它们不能从现有攻击序列对后续一步或多步的可能的攻击进行预测。APT攻击的检测与预测不是独立的两个方向,它们是高度联系、相辅相成的。该文结合上述日志分析中因果溯源图和自然语言处理的方法,在ATLAS日志数据集上构建因果图,根据恶意标签的节点提取完整的攻击序列,提出基于攻击上下文分析的多阶段攻击预测算法。该文的贡献可以概括为以下几点:
(1)提出了对攻击者行为进行多阶段预测的概念,挖掘攻击序列之间的非线性依赖关系;
(2)通过构建因果图来提取具有上下文关系的异常日志序列,避免了正常日志对预测结果的影响;
(3)利用Transformer模型,将日志分析并进行攻击预测的任务转化成文本分类的处理方式,并在开源数据集上进行了验证。
1 算法流程
1.1 算法基本框架
基于攻击上下文分析的多阶段攻击预测算法的基本框架如图1所示,包含五个主要阶段:

图1 多阶段攻击预测算法流程框架
阶段1:利用日志数据构建因果图;
阶段2:以已知恶意节点为线索,提取异常日志序列;
阶段3:将提取的异常日志序列进行抽象化文本表示,进一步解析成日志索引;
阶段4:用Transformer模型训练日志向量数据;
阶段5:用训练好的模型进行多阶段攻击预测。
1.2 因果图构建
因果图[25-26](Causal Graph)常用于溯源追踪,表征数据之间的因果关系或者依赖关系。该文从系统日志中提取数据来构建因果图,表征了主体(例如进程)和对象(例如文件或连接)之间的因果关系。在因果图中,以主体和对象作为图中的节点,以主体对对象的动作(例如读、写)来生成有向边。
因果图中的节点代表从系统日志中提取的具有唯一ID的系统主体或对象,比如进程名、文件名、IP地址、域名和会话等。边从主体指向对象,连接两个节点,表示主体对对象执行的动作。因果中每两个节点和边的组合对应了一个日志项。将日志中的数据按照上述原则生成节点和边,可以构建一个复杂的因果图。图2展示了一个因果图示例,其中灰色节点表示一个已知的攻击节点。

图2 因果图示例
1.3 异常日志序列提取
在ATLAS数据集中,异常的节点都被打上了恶意标签。该文围绕这些恶意节点提取出异常日志序列,具体分为三个步骤:
第一步:提取邻域图。在因果图中,通过边相连的两个节点称为邻居。提取一个或多个节点的邻域图,只需把它们所有的邻居和相连的边提取出来。
第二步:从邻域图中分离出事件。一个事件被组织成一个四元组<源节点,目的节点,动作,时间戳>。比如cmd.exe在时间t打开了文件flag.txt,事件表示为四元组
第三步,按时间戳对事件进行排序。以已知的单个或多个恶意节点的组合作为中心,提取邻域图,再从邻域图中提取出事件,最后把事件按照时间戳进行排序,得到的序列称之为异常日志序列。如图3所示,已知节点C为恶意节点,那么所有与它有关的日志项都被判定为异常,并且按照时间排序后,形成的日志序列也是异常的日志序列。通过这种方式,可以把所有与恶意节点有关的日志项提取出来,形成按时间排序的、具有明确上下文关系的异常序列,排除了在预测任务中正常行为日志项对预测的影响。文中的实验数据就是在这些异常日志序列的基础上构建的。

图3 提取异常日志序列流程
1.4 抽象文本表示
为了能将提取出来的异常日志序列用于模型训练,需要将词汇抽象化,把日志序列转化成能用于语义解释的通用模板。在ATLAS词汇抽象的基础上做了进一步的词汇组合抽象,构成句子抽象。下面将详细介绍具体流程。
如表1所示,在ATLAS中根据日志中词的细粒度语义将词分为四种不同的类型:进程、文件、网络连接和动作。四种类型中总共包含30个抽象词汇,将原本日志项中带有具体ID的实体映射到对应类型的相关抽象词汇,就可以将日志项抽象成统一的三元组模板。例如,“c:/windows/system32/taskhost.exe_1416 read c:/windows/inf/tapisrv/0409”转化为

表1 抽象词汇集合
对于基于异常日志的APT攻击预测任务来说,一个三元组代表一条日志项的抽象程度还不够,需要将日志项抽象到日志类型。经过分析抽象为三元组的异常日志后,三元组的组合方式的数量是有限且理想的,一般有< user_process,process,programs_process >read
表2展示了部分三元组日志和它们对应的日志类型索引,完整三元组数据一共有54种组合方式,于是设置了对应数目的日志类型索引。可以将异常日志序列映射为日志类型索引的序列,经过词嵌入Embedding[22]后,每个日志索引都转化成词向量,按照索引构成序列的顺序,词向量构成了传入Transformer模型的词向量矩阵,如图4所示。

表2 三元组日志对应的日志类型索引

图4 日志序列处理流程
1.5 模型训练
该文提出基于Transformer模型[4]的多阶段攻击预测算法LogTransformer。为了训练用于预测多阶段攻击的Transformer模型,以日志索引序列对应的词向量序列作为输入,以该索引序列的下一个或者多个索引作为输出。即由若干长度的异常日志序列,推测出下一步或多步可能产生的异常日志,以此来预测攻击者接下来的攻击意图。这种做法比较类似于文本分类等多分类模型的算法,接下来将详细介绍LogTransformer模型如何进行预测工作。
Transformer模型是自然语言处理方面极为先进的模型,它放弃了传统的卷积神经网络和循环神经网络,整个网络结构完全是由注意力(Attention)机制组成,主要包括编码器和解码器两个部件。不同于循环神经网络只能从左向右或者从右向左依次计算,Transformer可以并行处理向量,从而充分利用GPU资源,减少了处理语义向量等高维数据的运行时间。考虑到模型最终的输出只需要概率的向量表示,LogTransformer模型只采用了Transformer的编码器(Encoder)对日志序列进行编码,然后预测。
如图5所示,LogTransformer主体部分由4个Transformer编码器组成,每个编码器包含一个5头注意力层和一个前馈全连接层。在日志向量输入到注意力层之前,需要与位置编码(Position Encoding)做相加,这是因为Transformer没有循环神经网络中的顺序结构,因此需要加入词的位置信息来显式地表明词的上下文关系。该文利用公式(1)和公式(2)来进行位置嵌入:
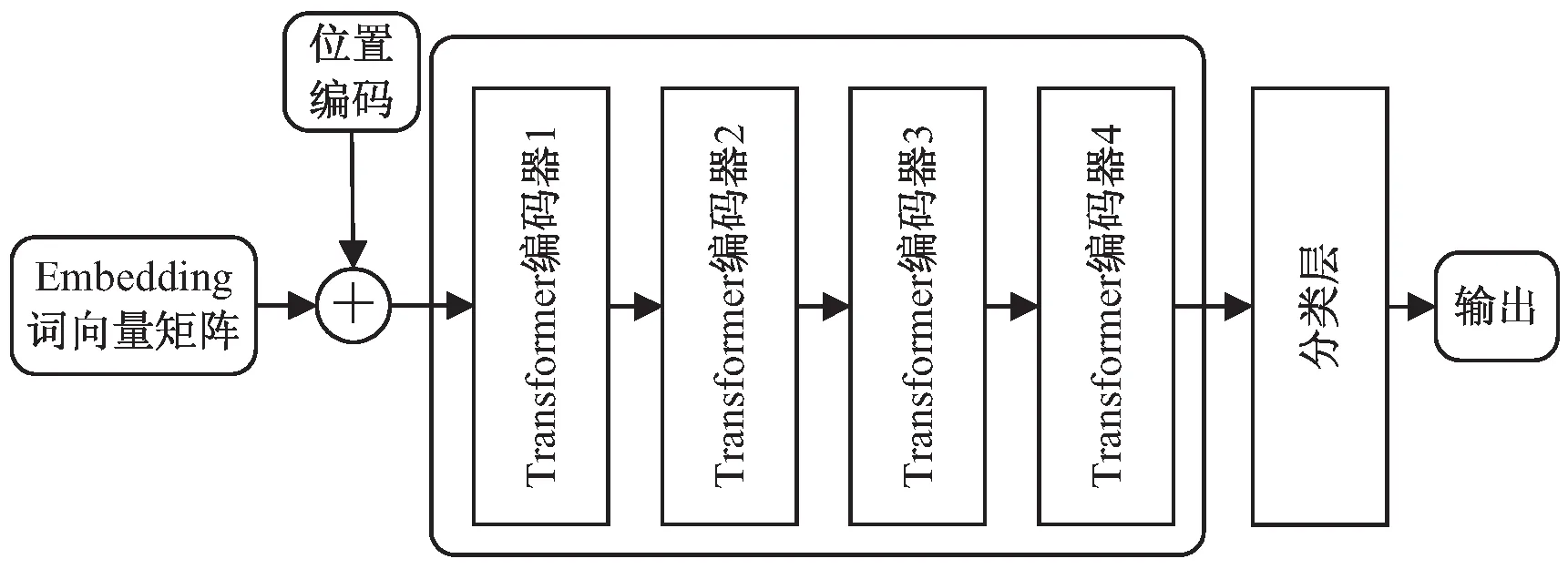
图5 LogTransformer模型框架
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(1)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(2)
其中,PE是一个“序列长度×词向量维度”形状的二维矩阵,pos是词在序列中的位置,dmodel表示词嵌入的维度,i表示词向量的位置。
1.6 攻击预测
经过多个LogTransformer的多个编码块的数据处理后,再连接一个分类层将高维数据映射为低维数据,最后将将二维张量变形成三维,输出的数据是(B,S,C)格式的矩阵。B为每次批处理的序列数量;S表示最终预测的步长,即如输入异常序列之后,预测接下来的S动作;C的大小是54,对应54个日志类型索引。图6说明了数据变换的过程。
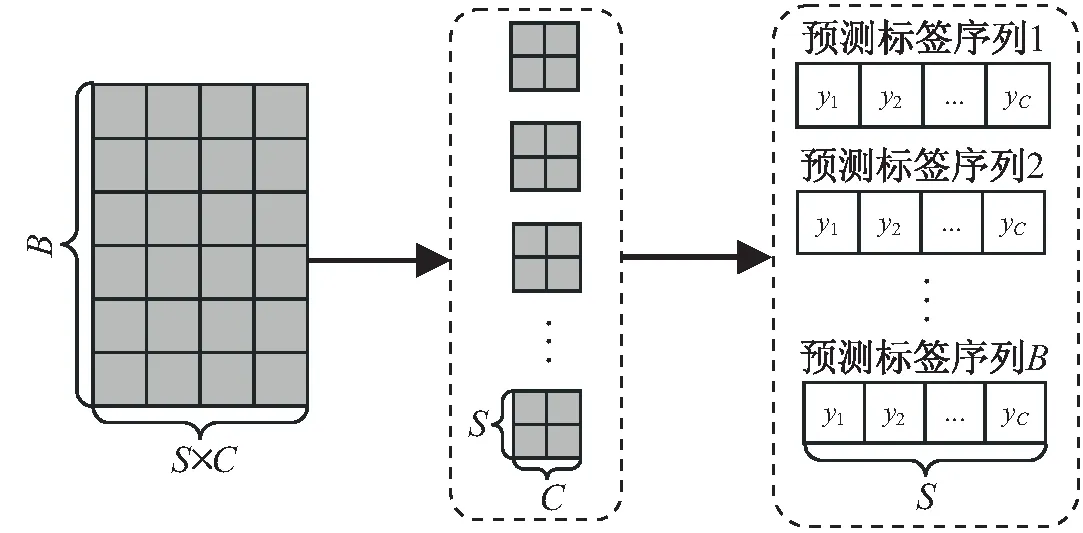
图6 输出数据到标签预测的转换
2 实验设计
2.1 数据集构建
2.1.1 ATLAS数据集
ATLAS数据集包含三种日志,分别是DNS日志、浏览器日志、审计日志。DNS日志记录了域名解析活动,浏览器日志记录了Web请求,审计日志记录了进程、IP及文件等系统活动。ATLAS日志数据集分为两个部分,一个是记录单主机受APT攻击的日志,表示为ATLAS-s;另一个是记录多主机环境下受APT攻击的日志,表示为ATLAS-m。由于多主机情况下会出现横向移动,为了避免这种情况给实验带来的影响,该文将实验数据分为单主机和多主机两个部分。同时,还设置了另一个公开数据集HDFS[27-28]作为对比。与ATLAS数据集不同的是,HDFS日志序列中既包含了异常日志也包含了正常日志,而且没有明确的上下文关系。设置这个实验的目的是体现通过构建因果图提取异常日志序列的优势。
2.1.2 实验数据集构建
经过1.4节对异常日志序列进行文本表示以及索引化之后,得到了许多序列。在这些长序列上,设置长度为10的滑动窗口,移动步长为1。依次在所有原始不定长序列的基础上,构建出等长度方便用于模型训练的序列数据。例如,假设长序列数据集中有一段数据为:{39, 37, 1, 11, 10, 6, 4, 34, 34, 29, 35, 34, 28, 28, 34}。滑动窗口大小为10,输出标签长度为1,则提取出来的训练数据为:{39, 37, 1, 11, 10, 6, 4, 34, 34, 29 → 35},{37, 1, 11, 10, 6, 4, 34, 34, 29, 35 → 34}。同样,如果设置输出预测步长为2,则训练数据为:{39, 37, 1, 11, 10, 6, 4, 34, 34, 29 → 35, 34},{37, 1, 11, 10, 6, 4, 34, 34, 29, 35 → 34, 28}。
表3是ATLAS和HDFS数据集统计数据对比。ATLAS-s graph和ATLAS-m graph是经过因果图提取攻击上下文后的ATLAS数据集。ATLAS-s seq和ATLAS-m seq是仅对日志进行时间排序处理的ATLAS数据集,其中有大量的正常数据,也有更多的日志类型。为了排除日志种类过多对预测结果产生影响,把异常日志序列中没有的日志类型都归于一种正常日志类型。HDFS seq是按时间排序的日志HDFS数据集。

表3 ATLAS和HDFS数据集对比
2.2 实验设置
2.2.1 实验参数
在实验中,输入序列的长度设置为10,Embedding词向量和Transformer编码器输入的维度dmodel=200,Transformer前馈网络层中神经元个数是1 024。
2.2.2 对比算法
为了体现算法LogTransformer的有效性,引入了另外两个算法DeepLog[23]和DeepAG[24]进行对比。DeepLog算法模型的主体部分采用传统的单向LSTM模型;DeepAG算法模型的主体部分采用了双向LSTM模型。三种算法都基于章节1.2、1.3、1.4所描述流程处理后的数据,只是在预测模型上有差异。另外,也设置使用和不使用章节1.2、1.3、1.4所描述流程情况下的对比实验,以此验证通过因果图构建攻击序列进行多阶段攻击预测的有效性。
2.2.3 评估指标
在单步预测中,计算了每个数据集以及不同算法的预测结果的精确率(Precision)、召回率(Recall)和F1分数(F1-score)。在多步长的预测中,精确率、召回率和F1分数等评价指标变得难以计算。因为多步预测中,模型输出的预测值序列需要与实际的标签序列完全一致,才会判定它预测正确。比如设置预测标签长度为5,那么预测值的5个索引值要与实际标签的5个索引值都分别对应相等。在这种情况下,上述三个评估指标极难计算,而且不再适用。因此,在多步预测中,只采用准确率(Accuracy)作为唯一的评估指标。
2.3 实验结果
把实验结果分为单步预测和多步预测两种情况,记录了不同算法在ATLAS数据集中的表现,并对实验结果进行了分析。
2.3.1 单步预测算法性能对比
表4分别显示了基于不同数据集的不同算法的精确率、召回率和F1分数。分析其中的数据,可以发现无论是在ATLAS的单主机日志数据集(ATLAS-s graph)上,还是在多主机日志数据集(ATLAS-m graph)上,三个算法模型中,LogTransformer的性能最高,其中在ATLAS的单主机数据集和多主机数据集上的精确率分别为92.42%和90.92%,召回率分别为93.67%和90.43%,F1分数分别为93.04%和90.67%,都是三个算法模型中最高的性能表现。

表4 单步预测性能对比 %
2.3.2 多步预测算法性能对比
分析表5和表6可以发现,在多步预测的情况下,DeepAG和LogTransformer在ATLAS单主机数据集上的准确率对比互有胜负;而在多主机数据集上,LogTransformer则具有优势,在准确率上比DeepAG 平均领先0.7%。DeepLog在ATLAS的两个数据集上的表现都是最差的,步长从2到5都是准确率最低的,说明传统单向LSTM模型优势不足。
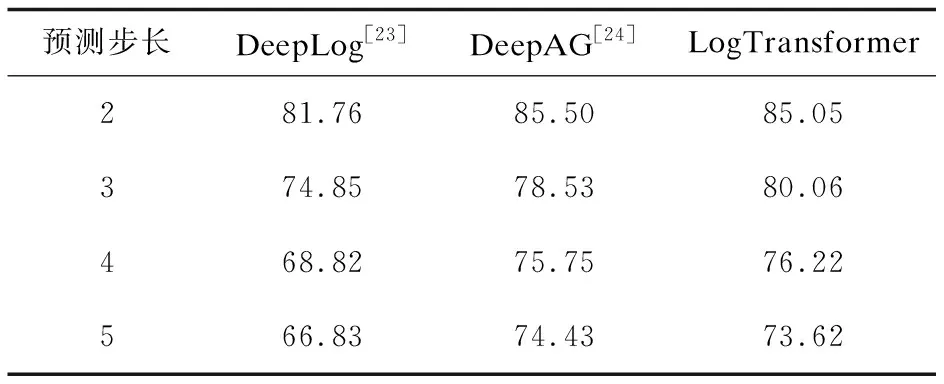
表5 在ATLAS-s graph数据集上多步预测准确率对比 %

表6 在ATLAS-m graph数据集上多步预测准确率对比 %
2.3.3 LogTransformer多步预测分析
为了比较LogTransformer在经过因果图提取算法的日志数据和未经过处理的日志数据上性能的差别,设置了因果图提取后的ATLAS数据集(ATLAS-s graph和ATLAS-m graph)、原始ATLAS数据集(ATLAS-s seq和ATLAS-m seq)和HDFS数据集(HDFS seq)的对照实验。图7统计了LogTransformer在五种数据集上预测步长从1到5的准确率的变化趋势。

图7 LogTransformer在五种数据集上的性能对比
从整体上看,随着预测步长的增加,LogTransformer算法的准确率也在下降。在因果图提取后的ATLAS数据集(ATLAS-s graph和ATLAS-m graph)上,即使预测步长达到了5,LogTransformer的准确率依然能保持在74%左右。在原始ATLAS单主机数据集(ATLAS-s seq)上,不同预测步长的准确率整体上都比因果图提取后的ATLAS-s graph数据集低20%左右。在原始ATLAS多主机数据集(ATLAS-m seq)上,不同的预测步长的准确率平均比因果图提取后的ATLAS-m graph数据集低12%。在HDFS seq数据集上,下降幅度比较大,到三步预测准确率已经下降到53%了,五步预测的准确率已经下降到了35%。这说明未经提取上下文关系的日志数据在用于预测的时候稳定性较差。
这是因为原始ATLAS数据集和HDFS数据集提取的日志序列并不是按照因果图来提取的,异常的日志中夹杂了很多正常操作的日志数据,所以序列里的日志项之间并没有明确的攻击上下文关系。对比分析HDFS数据集和ATLAS数据集的规模,ATLAS数据集的数据量比HDFS少很多,而ATLAS的日志类型数目是HDFS的将近2倍。LogTransformer在经因果图处理后的ATLAS数据集上获得了更佳的性能,这也证明了通过构建因果图来提取异常日志序列进行多阶段攻击趋势预测的有效性和先进性。
3 结束语
通过构建因果图来提取具有攻击上下文关系的异常日志序列,提出了一个基于攻击上下文分析的多阶段攻击预测算法。先通过因果图构建、异常日志序列提取、抽象文本表示等步骤实现对已有攻击上下文的分析;然后基于已经检测到的攻击序列,利用Transformer模型对后续攻击趋势进行预测。经过实验验证,所提算法在多阶段攻击预测上取得了良好的性能。但该算法依然存在一个缺陷,就是攻击趋势预测只能预测已经存在的54种日志类型,如果出现未知的攻击日志类型,算法并不能做出预测的更新。所以,接下来,会在这方面做出努力,完善未知攻击的实时更新处理,提高算法的拓展能力。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
华人时刊(2021年13期)2021-11-27 09:19:02
国际眼科杂志(2021年9期)2021-09-15 03:24:42
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
装备制造技术(2020年2期)2020-12-14 03:09:16
心声歌刊(2020年4期)2020-09-07 06:37:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
