
基于姿态注意力的特定角度人脸正面化网络
2023-07-21 07:50:12解奕鹏秦品乐曾建潮闫寒梅赵鹏程
计算机技术与发展 2023年7期
解奕鹏,秦品乐,曾建潮,闫寒梅,柴 锐,赵鹏程
(1.中北大学 大数据学院,山西 太原 030051;2.山西省医学影像与数据分析工程研究中心(中北大学),山西 太原 030051;3.山西警察学院 刑事科学技术系,山西 太原 030401)
0 引 言
近年来,随着深度学习的快速发展,人脸识别性能得到了很大提升,但它们局限于接近正面的人脸识别(Near-Frontal Face Recognition,NFFR)。多项研究表明,NFFR算法对大姿态的人脸识别效果不佳[1],因此姿态鲁棒性人脸识别(Pose-Invariant Face Recognition,PIFR)成为近年来的研究热点。
目前解决PIFR问题的方法主要分两大类:一类是学习对姿态变化鲁棒的特征,另一类即人脸正面化。第一类方法[2]依赖大量姿态分布均匀的训练数据,而现有数据大多呈现长尾分布,很难学习到对姿态鲁棒的人脸特征[3]。第二类方法[4]可以在不重新训练现有人脸识别模型的基础上,通过生成对应的正面图像进行人脸识别,提高准确率。
现有的人脸正面化方法按照合成域分为基于2D的方法和基于3D的方法。基于3D的方法[5-6]通常对较小姿态的人脸正面化效果比较好,而对较大姿态的人脸纹理细节损失严重,同时三维拟合时严重依赖面部关键点检测的准确性,渲染时计算量大,都使得这类方法难以在实际中应用[1]。
而生成对抗网络[7]的提出极大改善了二维图像合成的视觉效果,所以越来越多的研究人员采用基于2D的方法解决人脸正面化问题。例如,Huang等人提出一种双通道生成对抗网络TP-GAN[8],融合两通道的特征生成正面人脸图像,并用实验结果说明了GAN网络生成的正面人脸可以提高人脸识别的精度;Yin等人提出DA-GAN[9],他们为解码器添加了自注意力机制,增强了纹理细节,却忽略了编码时鲁棒的特征提取也一样重要;Hu等人提出了CAPG-GAN[10],使用5个人脸关键点作为结构先验;类似的,Tu等人提出了MDFR[11]框架,他们使用18个关键点作为结构先验。然而无论是CAPG-GAN还是MDFR,他们都直接将图像与姿态图直接拼接,无法保证在网络深层依旧起作用,也没有指出不同数量关键点的姿态图对网络性能的影响;更进一步,Hao等人提出DGPR[12]网络,他们使用人像草图作为人脸的先验知识,但使用侧面的人像草图生成正面的人像草图时,会引入一些不必要的误差;最后,Li等人提出Sym-GAN[3],他们关注了偏转及俯仰角同时存在的人脸正面化工作,但该方法在非同源的测试数据上视觉效果不理想。
总体来说,上述方法除Sym-GAN以外,均忽略了俯角对正面化工作带来的影响,而现实生活中监控摄像头拍摄的图像大多是俯视并且具有一定的偏转,导致这些方法生成效果不理想。另一方面,上述方法将所有角度的人脸数据混合训练,导致模型对特定角度人脸生成效果不突出。因此,该文聚焦于特定偏转和俯角的人脸正面化问题,结合注意力机制,引导网络生成逼真的正面图像。
主要工作如下:
(1)以类Pix2Pix[13]网络为骨干,提出基于姿态图引导的特定角度人脸正面化网络PS-GAN;并将多个PS-GAN网络进行组合,用于人脸正面化。
(2)提出姿态注意模块,引入人脸结构先验的同时约束模型关注感兴趣区域。使用特征可视化技术展示模型的感兴趣区域。
(3)在本实验室自主采集的多角度人脸监控数据集[14](Multi-Angle Surveillance Face Dataset,MASFD)以及CAS-PEAL-R1[15]数据集上进行了充分的定性和定量实验,验证各模块结构设计的合理性;实验结果表明该方法可以有效提高人脸正面化效果,并在非同源数据上平均人脸相似度达到67.24%。
1 相关工作
1.1 生成对抗网络
生成对抗网络[7](Generative Adversarial Networks,GAN)最初由Goodfellow等人提出。GAN由生成网络和判别网络组成,两者相互博弈:生成网络用于生成与原数据集分布接近的实例,欺骗判别网络;判别网络用来鉴别输入数据是真实数据还是由生成器伪造的。
GAN网络的提出显著提高了二维图像生成的视觉效果。如Yin等人提出的DA-GAN,在解码器部分添加了两个自注意模块,同时使用多个鉴别器,除了生成图像直接与标签进行判别外,引入了三种人脸掩膜,分别关注正面人脸的不同部位。其对抗损失表示如下:
(1)
Lj(Dj,G)=minGjmaxD{Ex∈If[log(D(x))]+
Ez∈Ip[log(1-D(Gj(z)))]}
(2)
其中,j∈{f,s,k,h}表示整幅图像、面部、五官及头发部分。
1.2 注意力机制
注意力机制分为空间注意力机制与通道注意力机制。空间注意力机制计算图像中感兴趣区域并加强。例如,Jaderberg等人提出空间转换网络STN[16],可以对特征图在空间中进行转换并自动搜索重要区域。
通道注意力机制关注图像在通道维度上的重要性,为不同通道的特征图分配权重。Hu等人提出SENet[17],分为压缩和激励两部分,压缩部分对全局信息进行压缩,在通道维度学习各通道的重要性,激励部分为各通道分配权重。
最后,Woo等人提出CBAM[18]模块,将通道注意力与空间注意力组合,提高图像生成质量。
但是,上述注意力机制只关注特征图本身,没有足够的先验知识做引导。
2 人脸正面化网络PS-GAN
图1给出PS-GAN网络的主体框架及各模块结构。仅由卷积、池化等操作组成的网络往往无法准确地关注感兴趣区域,因此将姿态图与空间注意力机制相结合,提出姿态注意模块(Pose Attention Module,PAM),引入人脸结构先验的同时使网络关注感兴趣区域。其次,为将编码器提取到的侧脸高维特征转换为目标特征并去除通道冗余,提出特征转换模块(Feature Transform Module,FTM)。

图1 PS-GAN网络结构及PAM、FTM模块结构
2.1 整体结构设计
PS-GAN网络由生成器和鉴别器组成,生成器由编码器、姿态注意模块PAM、特征转换模块FTM以及解码器四部分组成,编码器由四个卷积块组成,每个卷积块之后都添加了带有侧脸姿态的注意模块,解码器由四个反卷积块及两个卷积核为1×1的卷积层组成,仅在解码器的前三层添加带有平均正脸姿态的注意模块。
其次,将多个PS-GAN模型组合,对于任意姿态的人脸输入,首先使用人脸角度估计网络[19]计算人脸角度,再选择与该角度最接近的PS-GAN模型进行人脸矫正,得到最终生成结果。利用这种组合方法,解决任意角度人脸输入的问题。
2.2 姿态注意模块
2.2.1 姿态图的设计
人脸的关键点包含丰富的人脸结构信息,该文使用3DDFA[20](3D Dense Face Alignment)获取输入图像的68或8个关键点坐标,并将其保存在灰度图中,作为姿态图。
对于侧面的人脸图像,直接使用3DDFA获取到的坐标信息作为侧脸姿态图;而对于正面人脸,虽然每个人的正面关键点都不相同,但五官及人脸轮廓的大致位置都有迹可循,因此使用3DDFA计算训练集内所有正面人脸图像平均坐标,作为平均正脸姿态图。平均正面人脸关键点的计算方法如下:
(3)

2.2.2 姿态图与空间注意力的结合
之前的空间注意力机制使用两种池化操作获取图像的高频细节,却无法保证这些细节的准确性。因此,将空间注意力机制[18]与姿态图相结合,提出姿态注意模块,其网络结构如图1所示。
对输入特征,首先在通道维度上进行最大池化与平均池化,各得到与输入特征大小相同、通道数为1的特征图,再与其对应的姿态图进行拼接,得到特征块,最后经过卷积、Sigmoid激活函数后得到空间注意力权重图,再对权重图与输入特征进行点积得到更新后的特征图。
2.3 特征转换模块
输入图像经过编码器得到侧脸的高维特征,再使用特征转换模块FTM对侧脸特征进行转换[21], FTM模块结构如图1所示。
其中SpectralNorm表示光谱归一化[22];使用斜率为0.1的LeakyReLu作为激活函数。侧脸特征首先经过四层残差块进行特征变换,再使用通道注意模块为每个通道赋予权重,去除冗余通道的同时增强感兴趣通道。在通道注意中,该特征首先在长、宽两个维度上进行平均池化以及最大池化,然后将这两个特征向量输入全连接层,再将两特征向量的对应元素相加,得到通道注意力权重图,最后将该权重图与转换后的特征在通道维度进行点积得到新的特征图。
2.4 网络结构分析
在PS-GAN生成器的基础上去除姿态注意模块、通道注意模块后,记为Backbone网络。该文使用特征可视化技术[23]分析Backbone网络编码器与解码器的感兴趣区域,如图2所示,其中深色的区域为模型关注区域。

图2 Backbone网络特征可视化
由图2第一行可知,编码器在第一、二层关注了人脸区域,而从第三层开始关注头发、背景等非必要区域。因此,对于编码器,不需要添加更多的卷积层辅助提取侧脸特征,但为使编码器在各尺度都关注人脸区域,所以给编码器的每个尺度都添加带有侧脸的姿态注意模块。
由图2第二行可知,Backbone的解码器的前三层恢复正面人脸的大致轮廓,即人脸共有的属性,共性信息;第四层反卷积将特征恢复到原来大小,后两层1×1卷积辅助交替恢复人脸的全局与局部属性,即个性信息。而平均正脸姿态图仅包含人脸共性信息,因此仅为解码器的前三层添加带有平均正脸姿态图的姿态注意模块,辅助网络快速生成人脸共性信息的同时不影响人脸个性信息的恢复。
2.5 损失函数
本节将介绍用到的损失函数。为了使损失函数关注人脸区域,使用人脸分析方法将图像的背景区域扣除[24]:
L=Ladv+λpixelLpixel+λlpipsLlpips+λipLip+λtvLtv
(4)
其中,Ladv表示对抗损失,Lpixel表示多尺度像素损失,Llpips表示感知损失,Lip表示身份保持损失,Ltv表示全变分正则化项,λ*表示不同损失的权重。
2.5.1 对抗损失
GAN网络由生成器与鉴别器组成,两者的对弈过程表示如下:
Ladv=minGmaxD{Ex∈If[log(D(x))]+
Ez∈Ip[log(1-D(G(z)))]}
(5)
其中,E表示求期望;x∈If表示x来自真实的正脸图像集;D(x)表示鉴别器;z∈Ip表示z来自真实的侧脸图像集;G(z)表示生成器。
2.5.2 多尺度像素损失
在正面化结果IG上使用多尺度像素损失[3]来约束生成内容一致性:
(6)
其中,S表示尺度数,取S=3,Igt为正脸标签。
2.5.3 感知损失
使用感知相似性损失[25]保持图像的结构信息。具体的,使用Conv3-64、Conv3-128、Conv3-256、Conv3-512及最后一层全连接计算损失:

‖wl(Vggl(IG)-Vggl(Igt))‖1
(7)
其中,Vggl表示网络提取的第l层的特征图,wl表示对第l层赋予的权重。
2.5.4 身份保持损失
使用LightCNN-29V2[26]提取身份特征。具体的,使用该网络的最后一个池化层及最终的网络输出共同作为人脸高维特征[3,24],具体公式如式(8):
Lip=‖φpool(IG)-φpool(Igt)‖1+
浙江力普自创建以来,独辟蹊径,借力国家重点支持的新材料、新能源等战略性新兴产业领域,专致纳米碳酸钙、石墨球化粉碎、精制棉粉碎制备纤维素醚三大市场领域,进行产业细化深耕,持续科技创新,对于粉体加工中的各种疑难问题拥有独特的技术优势,成为上市公司、世界500强等高端客户的长期战略合作伙伴。“力普高科”牌粉碎设备获评绍兴名牌产品,跻身我国粉碎设备行业屈指可数的名牌产品行列。公司现已成为我国知名的专业生产各类超细粉碎、精细分级成套设备的国家高新技术企业、浙江省优秀创新型企业,中国无机盐工业协会碳酸钙行业分会第五届理事会理事单位(2017—2022年)。
‖φoutput(IG)-φoutput(Igt)‖1
(8)
其中,φpool(·)表示网络在最后一个池化层提取的特征,φoutput(·)表示网络的最终输出结果。
2.5.5 全变分正则化项
GAN网络生成的图像往往会存在大量人工伪影,因此添加全变分正则化项以减少伪影[9]:
(9)
其中,W和H分别表示图像的高和宽。
3 实验与结果分析
3.1 数据集
使用MASFD以及CAS-PEAL-R1数据集进行实验。MASFD数据集由本实验室自主采集,共包含了4 253人的23种角度组合。CAS-PEAL-R1数据集为CAS-PEAL数据集的共享版本,包含1 040位志愿者的30 900张人脸图像,该文使用其姿态子库21 840幅图像验证人脸正面化效果。姿态子库包含三种俯仰变化(抬头、平视、低头)和每种俯仰姿态下七种水平深度旋转姿态变化。另外为了验证PS-GAN网络的泛化性,又拍摄了80张数据集外的侧脸图像,用于验证其在非同源数据上的视觉效果。
对于MASFD数据集,在4 253人中随机选择850人作为测试集,其余3 403人作为训练集,共训练20个单角度模型;对于CAS-PEAL-R1数据集,随机选择831人作为训练集,209人作为测试集,共训练13个单角度模型。
3.2 对比实验
3.2.1 定性比较
由图3可知,文中方法相比其他方法有更少的人工伪影,文中方法只针对特定角度进行训练,网络关注较小范围的姿态变化,与其他方法相比,文中方法在整体结构和局部细节上均与标签更加相似。
其次,展示了PS-GAN与Sym-GAN在不同俯仰角上的正面化效果,如图4所示。
此外,在非同源的数据上进行测试,生成结果如图5所示。其中,第一行为输入,第二行为输出。

图5 文中方法在非同源数据上的生成效果
最后,展示了PS-GAN在两数据集在各角度下的生成结果,如图6所示。其中,第一列为基准图像,奇数行为网络输入,偶数行为网络输出。

图6 文中方法在不同数据集上各个角度的生成效果
3.2.2 定量比较
该文使用Rank-1指标在两数据集上对PS-GAN及上述方法进行定量实验,其定量结果如表1与表2所示。由于CAS-PEAL-R1数据集未给出具体的俯仰角度,因此,使用俯视、平视、仰视三种视角进行标注。其中第一行为俯仰角,第二行为偏转角。由表1和表2可知,文中方法在较大角度下依旧表现良好,说明用单个角度数据对模型进行训练是有效的。
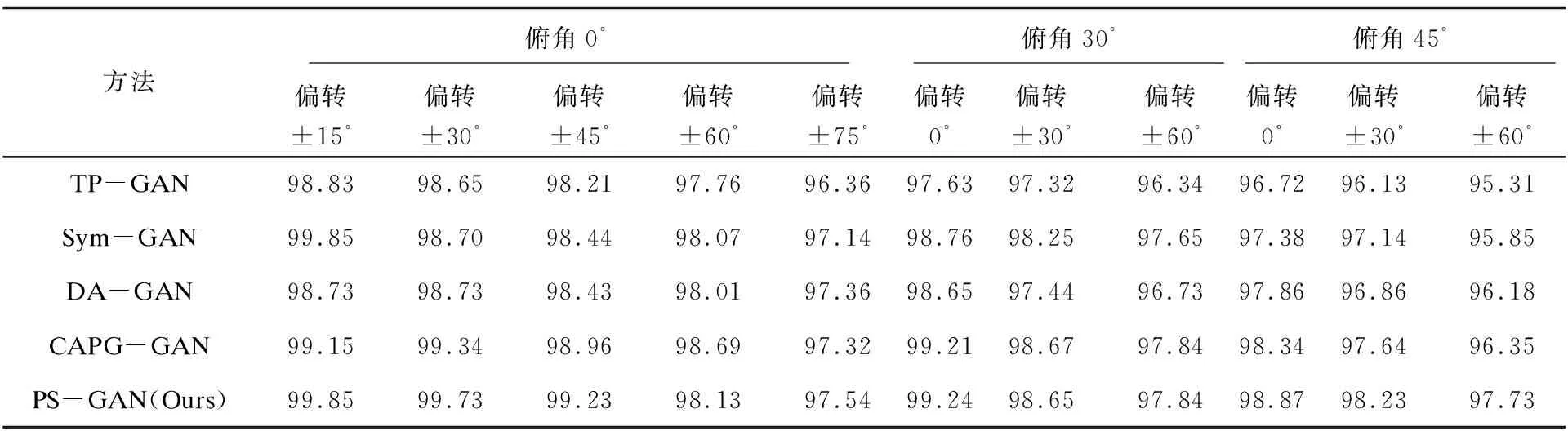
表1 不同方法在MASFD数据集上的Rank-1识别率 %

表2 不同方法在CAS-PEAL-R1数据集上的Rank-1识别率 %
但是Rank-1指标无法体现模型生成人脸与真实人脸的相似程度,因此又使用人脸识别方法计算平均人脸相似度得分(Average Similarity Score,ASS)与方差(Variance),计算方法如下所示:
(10)
100%-ASS)2
(11)
其中,IG为生成图像,Igt为真实标签,FR(·)为计算IG与Igt之间距离的函数。不同数据集的平均人脸相似度与方差计算结果如表3所示。

表3 不同方法及消融实验在MASFD数据集与非同源数据中的平均人脸相似度及其方差
由表3可知,PS-GAN方法在同源测试集和非同源数据上的平均人脸相似度均较高,方差较小,模型稳定性较好。
3.3 消融实验
由于Rank-n指标在消融实验中最终结果较接近,无法体现模型的真实性能,因此使用人脸相似度与方差作为消融实验(+30_30角为例)指标。
实验设置一:为了验证特征转换模块的有效性及结构设计的合理性,在Backbone的基础上分别添加2、3、4、5、6个残差块进行实验。
实验设置二:由图2可知,网络在解码器最后交替恢复人脸局部与全局信息,为了说明解码器后卷积层的数量是否会对生成结果有影响,分别为Backbone添加了1、2、3、4个1×1卷积进行实验。
实验设置三:在Backbone的基础上,首先将不同关键点数量的姿态图直接与输入图像在通道维度拼接,说明不同关键点姿态图对网络生成效果的影响。然后将姿态图与注意力结合,验证文中姿态引导方式的优越性。
3.3.1 不同数量残差块对生成效果的影响
本节分别为特征转换模块PTM添加2、3、4、5、6个残差块,分析不同数量残差块对生成效果的影响,实验结果如表3中Resblock所示。
由表3可知,在同源测试集上,添加四层残差块时平均人脸相似度最高,添加五层残差块时方差最低。在非同源数据上,随着残差块的数量增加,平均人脸相似度有所提升,且总体方差明显减小,即添加残差块可以减小生成效果的波动性。为了使网络结构精简,同时保证模型对非同源数据的泛化能力,为PTM模块添加四层残差块。
3.3.2 不同数量的1×1卷积对生成效果的影响
本节为Backbone添加1、2、3、4个1×1卷积,分析解码器后卷积层的数量对生成效果的影响,实验结果如表3中Conv所示。
由表可知,对同源测试集添加三层卷积层时平均人脸相似度最高,添加两层卷积层时方差最低,波动性最小;对非同源数据,在解码器之后添加两层卷积时相比Backbone的人脸相似度提高较明显,稳定性更好。因此,为解码器添加两层1×1卷积。
3.3.3 姿态注意模块的有效性
首先,在Backbone的基础上,比较不同姿态图对生成效果的影响。共进行了三组实验,分别是不加姿态引导(Backbone)、添加8关键点姿态引导(8pose)、添加68关键点姿态引导(68pose)的网络。每组实验均将原图与姿态图直接拼接,实验结果如表3所示。由表3可知,不论是测试集数据还是非同源数据,关键点越多的姿态图,其生成的图像平均人脸相似度越高,波动性越低。
其次,又展示了三种模型编码器与解码器的感兴趣区域,如图7所示。
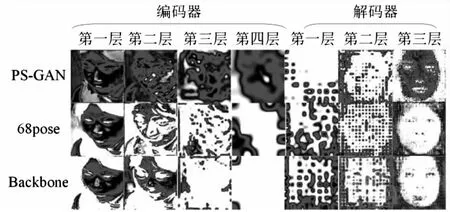
图7 Backbone、68pose及PS-GAN方法特征可视化对比
由图7可知,Backbone网络在编码器第三层已经不再关注人脸区域,而68pose的网络在第三层时依旧关注人脸区域。这一方面反映了姿态引导的有效性,另一方面也说明这种直接与原图进行拼接的姿态引导方式很难在网络深处起作用。
因此,将68关键点的姿态图与注意力机制结合,即文中方法。为了验证文中方法的有效性,对68pose和PS-GAN进行定性对比,结果如表3所示。由表3可知,PS-GAN网络在两类数据上相对其他实验方法平均人脸相似度最高、波动性最低。最后,如图7所示,PS-GAN模型的编码器各层在姿态注意模块的辅助下准确的关注感兴趣区域,解码器的前三层在姿态注意模块的辅助下快速捕捉人脸共性信息,证明了网络结构设计的合理性。
4 结束语
针对特定角度人脸正面化问题,通过实验验证网络的有效性与结构设计的合理性。结合注意力机制,提出PS-GAN网络,并使用特定角度人脸数据训练单个模型,将多个角度模型进行组合,一定程度上缓解各角度生成效果不突出的问题,但这种方法对于数据集中不存在的角度人脸生成效果一般。在后续的工作中,应当考虑如何使用数据集内有限的特定角度,在任意角度都能生成较好的结果。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
学生天地(2020年3期)2020-08-25 09:04:16
家庭影院技术(2019年8期)2019-12-04 14:43:19
动漫星空(2018年9期)2018-10-26 01:17:14
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
发明与创新(2015年33期)2015-02-27 10:40:09
