
上市公司信息披露分类监管研究
2023-07-21 12:02:32谭章禄苏嘉莉
统计与决策 2023年13期
徐 静,谭章禄,苏嘉莉
(1.北京联合大学 管理学院,北京100101;2.中国矿业大学(北京)管理学院,北京 100083)
0 引言
根据近年来中国证监会及各派出机构所做出的行政处罚决定,虚假记载、误导性陈述、重大遗漏、不正当披露等信息披露违规仍是上市公司违法违规的重灾区。为解决监管实践中的突出问题,进一步规范上市公司及其他信息披露义务人的信息披露行为,证监会重新修订并于2021 年3 月印发了新的《上市公司信息披露管理办法》。实务中,证监会坚决落实“零容忍”要求,大力推进分类监管制度,以进一步提升监管效能。对此,深交所、上交所先后发布了《上市公司风险分类管理办法》《上市公司自律监管规则适用指引第3号——信息披露分类监管》等。分类监管是增强监管专业性、精准度和有效性的重要途径,其核心内涵是区分情况、分类施策,即“管少管精才能管好”。那么,如何对上市公司进行科学分类?不同类别上市公司有何特征?如何精准锁定重点监管对象?这些是实施信息披露分类监管亟待解决的问题。在当前的大数据时代背景下,上市公司数据呈爆炸式增长态势,现场检查、抽样审阅等传统手段难以实现差异化和精准监管。而随着监管科技的快速发展,基于数据挖掘技术分析上市公司信息披露行为,根据大数据中蕴含的内在规律确定分类监管方案,成为创新信息披露监管方式的重要途径。
围绕信息披露违规的动因,学者们进行了理论层面的分析。陈西婵和刘星(2021)[1]基于信息披露权衡理论分析,认为在强制性信息披露的环境下,合规披露成本和违规披露后果是上市公司披露行为的决策变量;王通平和钱松军(2016)[2]基于理性投资者理论,针对证券市场信息披露误导性陈述的特征、表现和构成要件进行了分析。实证研究方面,学者们对影响上市公司信息披露的因素进行了研究,主要包括流动比率、资产负债率、净资产收益率、经营活动现金流量等财务压力因素[3,4],机构持股[5]、高管特质[6]、薪酬激励[7]、董事会治理[8,9]等公司治理因素,以及监管处罚[6]、资本市场开放[10]等外部监管因素。
从监管角度而言,信息披露不实等违法违规行为有其内在动因和演化路径,这为分类监管提供了依据[11]。分类监管作为一种差异化监管理念,广泛应用于银行业、证券公司等领域。所谓分类监管,是指根据上市公司信息披露质量、规范运作水平、风险严重程度等情况,在对上市公司风险等级进行评估的基础上,区分重点公司、重点事项开展监管工作。为贯彻分类监管理念,葛其明和徐冬根(2019)[12]在分析差异化信息披露概念与特性的基础上,研究了多层次资本市场环境下的差异化信息披露制度;谢贵春(2021)[13]借鉴国外的做法,探讨了将发行审核效率与发行人信息披露质量挂钩的IPO 分类审核机制;崔笛等(2019)[14]从竞争情报分析和应用的视角出发,开展了基于分类体系的上市公司年报信息披露质量研究。
相较于统一监管模式,分类监管模式更注重监管的实质公平,是有效监管的典范[15]。关于分类监管的内涵及其合理性,学者们主要从经济学角度进行了理论解释。曾小龙(2009)[16]通过效用理论,证明了分类监管最有利于提高上市公司监管效率,主张对不同风险类别的上市公司采取差异化监管政策;王龑等(2014)[17]认为,监管标准会面临着无效区间的影响,产生约束松弛现象,导致监管不能取得预期的效果,分类监管可以在一定程度上解决这个问题。关于分类监管的具体应用,葛其明和徐冬根(2019)[12]认为,我国多层次资本市场的建设需要强化差异化信息披露制度的构建,差异性的制度构建原则孕育差异化的监管理念;高莺和史晋川(2003)[18]针对企业信息披露问题,提出按照不同的行业来制定信息披露监管标准,从经济学角度对分行业监管改善企业整体福利水平的机理进行了研究。关于上市公司分类监管模式,分辖区监管、分行业监管是可操作性较强,也是实务中采用较多的方法。林钟高和李文灿(2021)[19]通过实证研究发现,相对于辖区监管模式,分行业监管模式能显著提升会计信息可比性,而且在受到重点监管和发布信息披露指引的行业内公司效果更好。
此外,随着监管科技的发展及应用,监管部门应注重监管效能及针对性的提升,避免采取简单粗暴的“一刀切”模式,丰富监管政策及手段体系[20]。监管科技的发展促使监管机构不断调整监管方法,一种具有前瞻性、大数据驱动的监管模式正在形成[21,22]。大数据技术使现代监管的方式和速度发生了根本性的变化,机器学习[23]、人工智能[24]等得到越来越多的应用,在很大程度上提高了风险监测和处置的前瞻性、有效性[22]。如美国证券会倡导数据驱动的调查方式,强调借助数据分析工具来识别违反《证券法》的行为[25]。
海量大数据中蕴含着上市公司业务交易的一般规律和内在逻辑,大数据技术为现代监管理论和方法注入了新的内容,为完善分类监管模式提供了新的思路和方法。本文按照大数据分析的全体性、混杂性和相关关系思维,首先基于全体数据对涉及信息披露违规的所有上市公司进行细分和评级,然后综合财务指标、公司治理、外部监管等多维数据提取不同类别上市公司的特征,最后运用决策规则挖掘方法探讨其中的相关关系。
1 研究设计
1.1 变量定义
面向分类监管,以“信息披露违规与否”和“信息披露违规风险”为目标变量。根据上市公司信息披露违规动因,设计用于违规识别检测的输入变量,主要包括财务指标、公司治理、年报审计和被关注度等。变量定义如下页表1所示。
1.2 模型构建
上市公司信息披露违规背后的逻辑可能隐含在大数据中。本文构建基于C&R 树(Classification and Regression Tree)的信息披露违规分类预测模型,借助于数据挖掘方法探究其中的相关关系。
C&R 树即分类与回归树,是一种基于树的分类和预测方法,其原理是使用Gini 系数作为判定决策树是否仍须进行分支的依据,并建立二元的决策树。由于“信息披露违规与否”和“信息披露违规风险”为分类变量,因此选择使用Gini 系数来确认最佳变量和分割点。Gini 系数反映的是目标变量组间差异程度,系数越小,组间差异越大。Gini系数计算公式如下:
其中,T为总记录数,t1,t2,t3,tn,…为输出变量每个类别的记录数。
C&R 树采用Gini 系数的减少量来测量异质性下降,即:
其中,n1为左节点的记录数,n2为右节点的记录数,N为根节点的记录数。
对于信息披露违规分类预测,C&R 树算法通过检查上市公司各项财务指标、公司治理、年报审计等输入变量来查找最佳分割,以分割所引起的杂质指标下降情况进行测量。分割可定义两个子组,其中每个子组随后又被分割为两个子组,依此类推,直到触发其中一个停止标准为止。在整个C&R树生长中,越往下生长,ΔG(t)越小。
1.3 样本选择与数据来源
以因信息披露违规受罚的我国沪深两市A 股上市公司为研究对象,样本期间自2012年1月1日我国内部控制基本规范及配套指引在上海证券交易所和深圳证券交易所主板上市公司施行以来至2021年12月31日,考虑到行业差异和数据的可对比性,选取违规处罚最多的计算机、通信和其他电子设备制造业为样本。违规处罚及相关数据来自国泰安(CSMAR)数据库,将虚构利润、虚列资产、虚假记载、推迟披露、重大遗漏、披露不实、一般会计处理不当等违规类型界定为信息披露违规处罚,剔除其他经营违法违规处罚数据。
2 研究发现
2.1 样本分类
分类监管的前提是对信息披露义务人进行合理分类,以及对其风险等级进行科学评估。根据违规处罚公告,2012—2014 年因信息披露违规受罚的计算机、通信和其他电子设备制造业上市公司数量有所下降,2014 年之后整体上呈增加趋势,且2019—2021 年的增量较大。再根据受罚上市公司的具体违规年份整理数据,获得信息披露违规样本1230 条,同时基于全行业数据获得不涉及信息披露违规的样本3674条,共4904条。如图1和下页图2所示。

图1 受罚公司数量
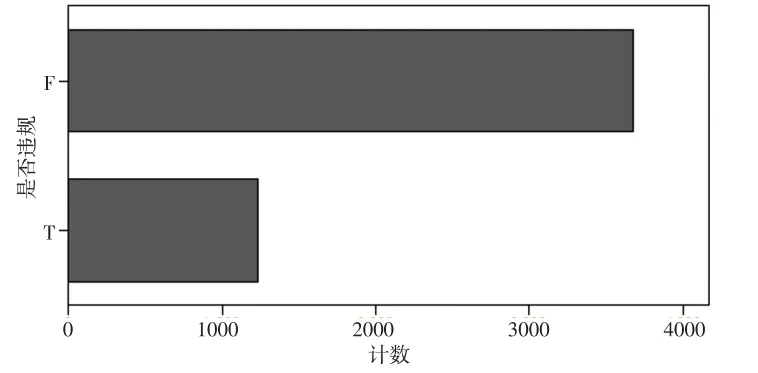
图2 违规样本分布
针对信息披露违规的计算机、通信和其他电子设备制造业上市公司,引入RFM(Recency, Frequency, Monetary)模型进行违规风险评价,进一步细分类别。RFM 模型通过近因、频率和货币三个要素进行主体行为评价,广泛应用于细分用户并衡量其价值。基于上市公司信息披露违规处罚数据,利用上次处罚时间、处罚频率、处罚金额三个指标,可以计算出RFM分值,该值反映上市公司信息披露违规的严重程度和受监管关注度。RFM 分值越大,则违规风险越大,反之亦然。在此基础上,按照违规风险指数可以把涉及信息披露违规的上市公司划分为不同类别,包括低风险类(I)、中风险类(II)、高风险类(III)。运用RFM 模型,对我国计算机、通信和其他电子设备制造业上市公司违规风险评分和评级的结果如下页图3、图4所示。

图3 RFM评分计数
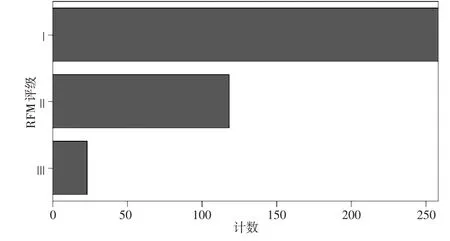
图4 RFM评级分布
根据RFM 评分,评分值介于1 和2 之间的样本数量最多,评分值介于2 和3 之间的样本数量次之,评分值大于3 的样本数量最少。剔除数据缺失的样本后,2012—2021 年计算机、通信和其他电子设备制造业上市公司信息披露违规样本共399条,低风险类(I)、中风险类(II)、高风险类(III)样本数量分别为258条、118条和23条。
2.2 特征提取
表征上市公司信息披露违规的数据具有混杂性,可能包含多个维度的特征指标。运用特征选择算法来识别、筛选对某给定分析最为重要的字段,即对预测“信息披露违规与否”和“信息披露违规风险”重要的指标。特征选择的结果如下页表2所示。
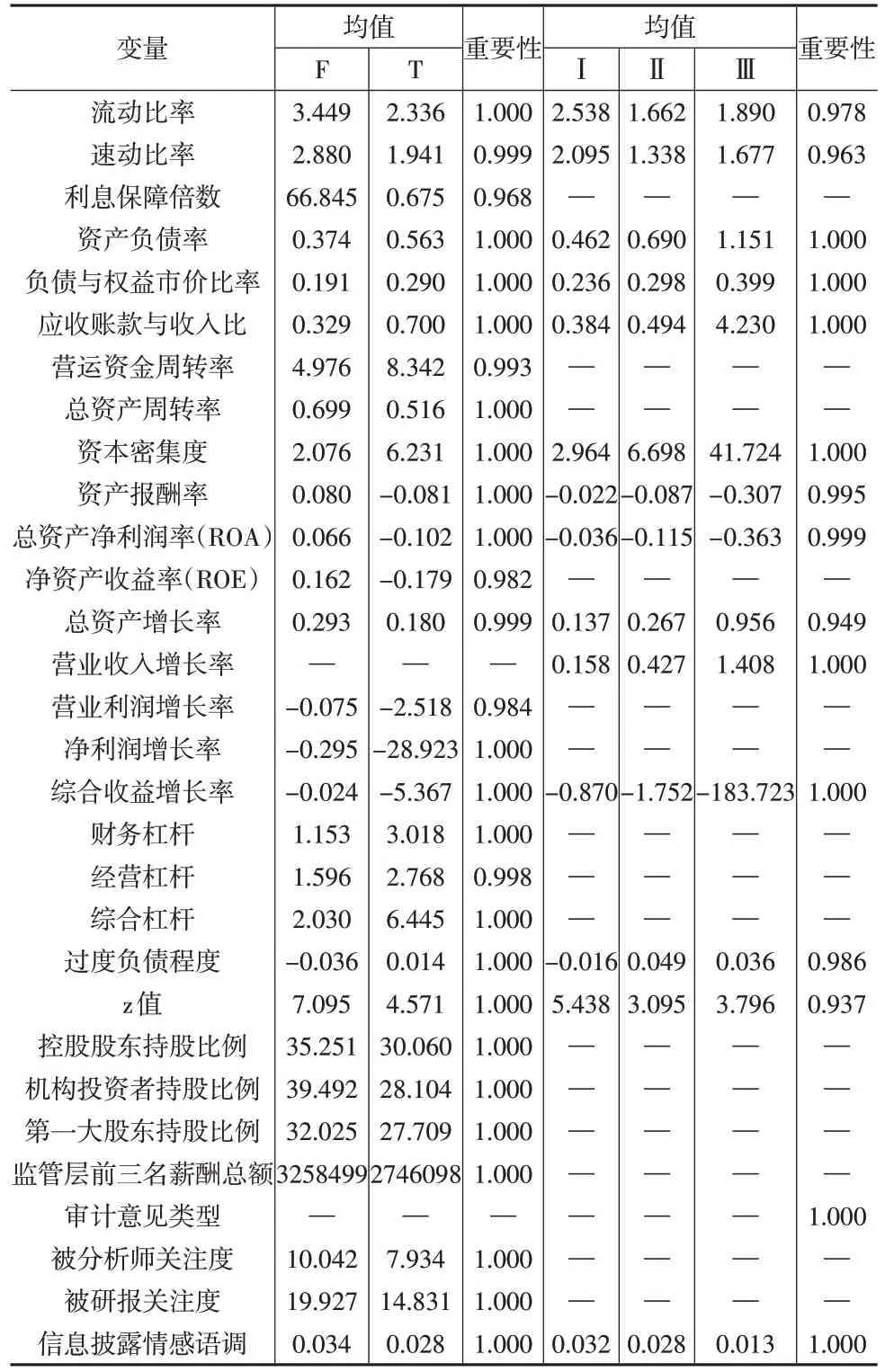
表2 变量重要性
2.3 相关关系
将提取出的各项特征指标作为输入变量,分别以“信息披露违规与否”和“信息披露违规风险”作为目标变量,运行C&R 树模型,挖掘其中最相关的决策规则。
(1)信息披露违规与否
对于“信息披露违规与否”的分类预测,共获得实例数较多和置信度较高的3条规则,其中2条适用于不存在信息披露违规,1条适用于存在信息披露违规,如表3所示。

表3 决策规则(信息披露违规与否)
就计算机、通信和其他电子设备制造业上市公司而言:如果总资产净利润率(ROA)>0.030,则在87.40%的置信度上表明没有信息披露违规;如果总资产净利润率(ROA)≤0.030,净利润增长率>-1.546,且机构投资者持股比例>34.795,则在79.30%的置信度上表明没有信息披露违规;如果总资产净利润率(ROA)≤0.030,净利润增长率≤-1.546,且z值≤-0.034,则在81.70%的置信度上表明存在信息披露违规。可见,较低的总资产净利润率(ROA)、净利润增长率和z值,意味着公司面临着业绩压力和财务风险,从而导致公司发生违规行为,而机构投资者持股有助于提高信息披露质量,在一定程度上抑制公司违规。
(2)信息披露违规风险
对于“信息披露违规风险”的分类预测,过滤掉置信度较低的规则后,保留2条适用于信息披露违规风险为低的规则和1条适用于信息披露违规风险为中等的规则,由于高风险类样本数量少,未挖掘出此类风险等级的有效规则,如表4所示。
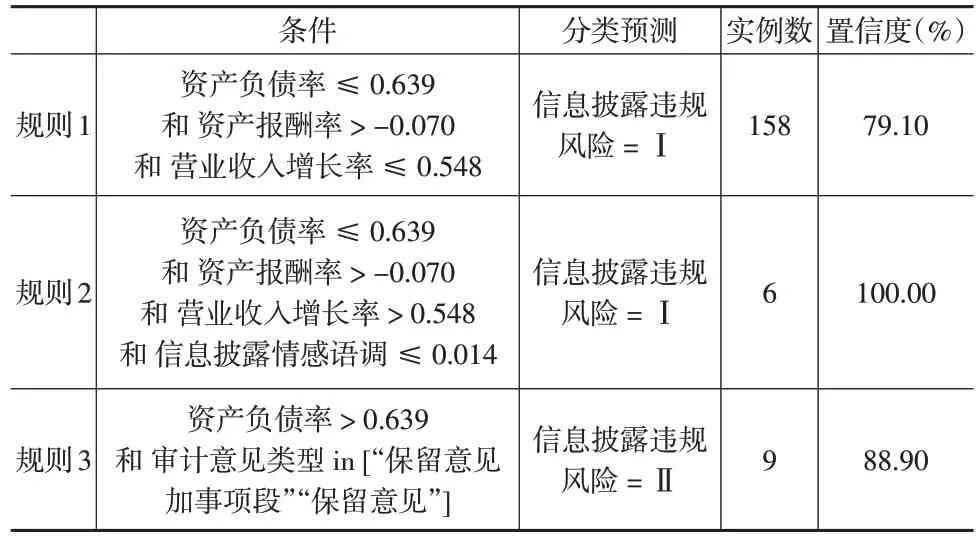
表4 决策规则(信息披露违规风险)
就计算机、通信和其他电子设备制造业上市公司而言:如果资产负债率≤0.639,资产报酬率>-0.070,且营业收入增长率≤0.548,则在79.10%的置信度上表明信息披露违规风险为低水平;如果资产负债率≤0.639,资产报酬率>-0.070,营业收入增长率>0.548,且情感语调≤0.014,则信息披露违规风险均为低水平;如果资产负债率>0.639,且审计意见类型in[“保留意见加事项段”“保留意见”],则信息披露违规风险为中等水平的置信度为88.90%。可见,较高的资产负债率可能加大信息披露违规风险,上市公司被出具保留意见意味着财务报表存在错报以及更高的信息披露违规风险。
3 结论
分类监管是落实上市公司监管要求的基本方法和有效途径。本文在大数据赋能证券监管的时代背景下,按照大数据分析的全体性、混杂性和相关关系思维,应用数据挖掘技术分析上市公司信息披露行为,最终得到如下研究结论:(1)因信息披露违规受罚的计算机、通信和其他电子设备制造业上市公司数量近年来呈增长趋势,相比未发生信息披露违规的上市公司,违规公司在总资产净利润率(ROA)、净利润增长率、z值等指标上取值更低,面临着更大的业绩压力和财务风险,由此可能引发信息披露违规行为。(2)上市公司信息披露违规的时间、频次和受罚金额反映了其违规的严重程度、受监管关注度,相较低违规风险类的上市公司,中高违规风险类公司表现出更高的资产负债率、更低的资产报酬率、更消极的信息披露情感语调等特点,因而偿债能力恶化、盈利能力不足等因素可能带来更大的信息披露违规风险。(3)应用C&R 树模型挖掘出“信息披露违规与否”和“信息披露违规风险”的有效规则各3 条,符合上市公司发生信息披露违规的内在逻辑,能够为监管机构实施分类监管提供决策参考,据此向重点监管领域配置监管资源。
猜你喜欢
廉政瞭望·下半月(2022年4期)2022-05-12 01:09:10
中国石油石化(2021年9期)2021-07-17 09:24:14
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
劳动保护(2018年5期)2018-06-05 02:12:09
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
数学学习与研究(2017年3期)2017-03-09 18:12:42
