
基于ST-SlowFast的电力生产环境违规行为检测
2023-07-17 07:20:52黎亦凡司恒斌任晓龙林平远张志宏
智慧电力 2023年6期
杨 乐,黎亦凡,陈 曦,司恒斌,任晓龙,林平远,张志宏
(1.国网陕西省电力公司信息通信公司,陕西西安 710065;2.厦门大学信息学院,福建厦门 361005)
0 引言
随着国家电网基础设施的快速发展,电力生产中如何保证施工人员的安全性成为电力事业建设的关注重点之一。由于电力作业的特殊性,再小的安全隐患都会导致很严重的后果[1]。因此,除了施工人员需严格按照操作手册进行操作外,还专门设立了安监部门及现场安全员以提供安全保障。采用安全员在场监督的管理方法,虽然在一定程度上能够督促施工人员遵守安全性防护规则,但其不仅耗时耗力,也无法保证24 h 全天候安全监管。
近年来,由于高清监控的全面化普及以及深度学习技术的快速发展,以高清摄像头作为媒介的计算机视觉技术为电力作业场景下的实时检测应用提供了广泛的解决方案[2-13]。
电力作业环境下的违规行为检测一直是实现智能化安全监管的重大难题之一,虽然其本质上同属于行为检测,但与传统行为检测的不同在于,电力生产环境中的违规行为检测存在着一定的数据瓶颈且多属于长时动作,有别于拍手、击掌等原子动作以及跳跃等短时动作,长时动作往往需要更多的上下文信息及时空间信息间的交互。目前基于深度学习的行为检测方法主要分为2 种:(1)基于双流卷积的方式[14-15],将空间信息和时间信息分别进行建模,虽然针对一些简单的原子动作能够取得较好的结果,但在短时和长时动作的检测中准确率较低;(2)利用三维卷积直接进行特征提取,可直接在2 个维度上进行特征的提取从而加强特征之间的关联性,但提取特征粒度较粗,难以达到令人满意的准确率。这2 种方法虽然能够实现行为识别,但难以应用于电力生产环境下的违规行为检测。
本文针对目前电力生产场景中存在的违规行为进行调研,以跨越围栏场景作为应用背景制作相关数据集用于实验结果的验证,并提出了一种新颖的行为识别模型ST-SlowFast(Spatio-Temporal SlowFast)。该模型同时结合时间及空间维度信息以增强视频行为识别鲁棒性。
本文的主要贡献如下:(1)以跨越围栏作为典型样例并制作了用于验证模型性能的数据集;(2)在双流模型的基础上构建了基于注意力机制的第三条特征融合通道,同时补足了时空间信息以及长上下文信息之间的交互。
1 行为检测概述
1.1 双流行为检测
Simonyan 提出的双流卷积网络(Two-stream Convolution Neural Network,Two-stream CNN)[16]首次利用密集光流信息捕捉时间上的运动特征,并设计了双流卷积网络架构,通过对不同维度的信息建模完成最后的行为分类。时间分段网络(Temporal Segment Network,TSN)[17]针对双特征提取网络的庞大计算量做出优化,采用随机时间片分割的方式对视频信息进行输入处理,在降低了计算量的同时,补全了双流网络对长时间建模能力不足的问题。时间关系网络(Temporal Relation Network,TRN)[18]则致力于探索时间信息的关系,它使用ResNet[19]网络对特征进行提取,并设计了新的时间片融合方式获取长时信息,利用多尺度特征融合提高模型的鲁棒性。文献[16-18]的方法虽然在一定程度上解决了二维卷积无法处理时间维度的问题,但其模型的复杂性以及仅沿着单一维度特征提取的局限性导致其难以广泛应用,双流行为检测通过最直接方式对不同维度的信息进行建模,但在提取特征时两者的关联性较低,因此在短时和长时行为检测中难以达到令人满意的性能。
1.2 基于三维卷积的行为检测
对于视频流数据而言,二维卷积网络通常只能够对其中的一帧图像进行处理,通过双流卷积网络虽然能够完成视频流行为检测,但模型参数量以及实时性仍然难以令人满意。三维卷积由Ji 等[20]提出,作为二维卷积的延申,三维卷积处理视频特征时可很好地保留时间维度信息,所取得的特征也具有更强的关联性。三维卷积虽然在特征提取上契合视频流数据,但在检测结果上相较于双流卷积提升不够明显。因此在结合了双流结构以及三维卷积的基础上,He 等人提出了SlowFast[15],它通过模拟生物视觉机制构建不同帧率的通道以提取视频数据特征,并且与此前传统的仅采用双流结构或是三维卷积的方法相比在精确率上有了较大的提升。考虑到当前行为检测模型的性能主要依赖于帧级检测以及三维卷积的长时建模,为了更好地区分相似的对象,Sun 等人提出了一种融合环境特征的行为检测模型(Actor-centric Relation Network,ACRN)[21],提高了模型的判别性,通过三维卷积直接进行特征抽取的方式涵盖了过多的背景噪声,容易对长时动作检测产生影响。
2 基于时空间信息注意力机制的神经网络
2.1 SlowFast概述
SlowFast 提出了一种不同于双流行为检测的双通道架构,其灵感来自灵长类视觉系统中2 种不同视网膜神经节细胞的功能,文中分别将他们称为慢速(Slow)和快速(Fast)通道;这2 条通道通过简单的拼接完成时空特征之间的交互,最后由一个全连接层来完成分类。
Slow 通道和Fast 通道作为特征提取网络,可以采用如ResNet,MobileNet[22]等结构,他们之间主要区别在于输入的帧采样率。相较于Fast 通道而言,Slow 通道是一个低帧率输入通道,对于输入的视频数据,它用一个大的时间步长(一般设置为16 来进行采样),这意味着每秒30 帧视频经过采样后只有2 个关键帧,其目的在于获取时间片内的语义信息;Fast 通道通常选用和Slow 通道一样的网络结构,其主要差别在于参数量大小,为了获得连贯的动作细节特征,Fast 通路以高采样率对输入视频进行采样(时间步长表示为t/a,t 代表原始视频的帧率,a 表示下采样大小,通常设置为4)。由于采样率较高,Fast 路径相对于Slow 路径将通道维度的值设置得较低,以减少浮点计算量。
SlowFast 通过巧妙的方式提出了一种双通道的结构以同时捕捉语义特征及动作特征,但在SlowFast 论文中实验部分在针对Fast 通道进行消融时发现仅保留Slow 通道的结果与双通道结果差异不大。这是因为双通道之间的信息融合机制过于简单(主要采用三维卷积对时间维度进行下采样以达到相同的维度),这种形式虽然简单有效,但是并没有充分利用Fast 通道当中的连续动作特征。本文针对SlowFast 的双通道融合机制进行优化,额外设计了一条时空间注意力机制通道用于重分配不同尺度下语义及动作特征权重,以更好地对双通道特征进行融合,并整合不同感受野下的上下文特征,从而增强了时空间以及长上下文信息的交互,提升长时行为检测的准确性。
2.2 ST-SlowFast
ST-SlowFast 的网络细节结构及模型框架结构分别如图1、图2 所示。

图1 ST-SlowFast模型细节结构图Fig.1 Detail structure of ST-SlowFast model
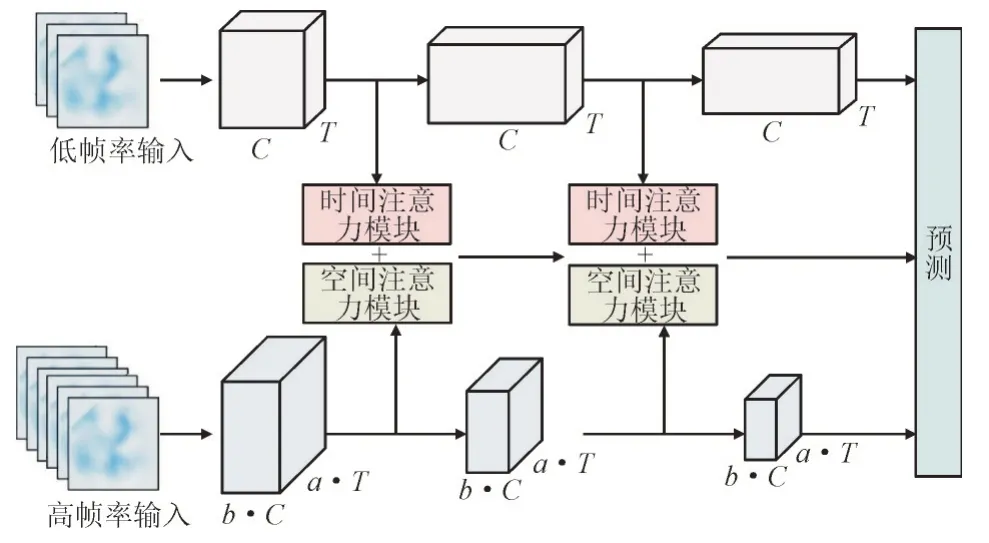
图2 ST-SlowFast框架结构图Fig.2 Framework structure of ST-SlowFast
网络模块的输入包括5 个维度分别为B,C,T,W,H,分别代表训练批量数、通道维度数、采样帧数、图像宽度值和图像高度值。图2 中第1 条低帧率图片输入通道为Slow 通道,第3 条高帧率图片输入通道为Fast 通道,其中b和a为超参数,b用于调整Fast 通道中像素通道维度数,文中设置为0.125;a用于调整采样帧率,文中设置为4,中间进行特征融合的通道为本文所添加的ST-Pathway(Spatio-Temporal Pathway),图1 中展示了图2 各个模块的实现细节。
由图1 可知,ST-SlowFast 中Slow,Fast 及ST 通道采用的网络结构均为ResNet-101[19],包含输入层、输出层及33 个ResNet 模块,其中的m和n分别表示中间特征层的数量以及每一个特征层对应的残差连接模块数,时空间注意力模块被用于每一个中间特征输出层。
2.3 时空间注意力模块
Transformer[23]是一个端到端的注意力机制模块,最早应用于自然语言处理(Natural Language Processing,NLP)领域中,以解决RNN 网络的长时依赖局限性以及推理速度慢等问题[24-25],其通过全局注意力机制计算的方式为细粒度特征分配权重,从而解决了长时依赖问题。在图像分类领域中,视觉Transformer(Vision Transformer,VIT)[26]首 次 以Transformer 完全替代卷积神经网络(Convolutional Neural Network,CNN)模块,将输入图片划分为块的方式减少注意力计算复杂度,并且通过添加可学习参数保证块与块之间的相对位置。本文基于此,针对视频流的三维输入提出了2 个处理时空间特征的Transformer 结构:空间注意力模块(Spatio Transformer)和时间注意力模块(Temporal Transformer),并将两者融入ST-SlowFast 以解决SlowFast 语义动作特征间的自适应融合。
Spatio Transformer 的结构如图3 所示,Slow 和Fast 通道此时的输入维度分别为(B,C,T,W,H)及(B,b∙C,a∙T,W,H)。从结构组成来看,Spatio Transformer 包含多头交叉注意力层(Multi-head Cross Attention,MCA)、标 准 化 层(Layer Norm,LN)、多层感知机层(Multi-Layer Perceptron,MLP)及残差连接层,同时在训练时加入随机失活层(Dropout)以防止过拟合。

图3 Spatio Transformer模块Fig.3 Module of Spatio Transformer.
对于输入的不同维度特征,Spatio Transformer首先通过三维卷积对通道维度和时间维度进行变换,使两者统一;然后为了对阶段输出特征与双通道模块间的注意力分布图进行计算,采用维度变换方式把时间维度整合到通道维度中,同时将像素点整合成一维向量的形式。同时为了保证模型推理的速度,采用了分块计算(文中块大小设置为14×14),并加入线性层(Linear Layer)学习1 组参数用于记录像素块的位置信息,整体过程如下所示:
式中:Ofast为快通道的阶段输出特征;RS 为维度变换操作,变换形式如式(3);Oslow为慢通道的阶段输出特征;out为局部网络模块的输出;outmlp为经过MLP 层的输出;MCA 为Transformer 中的关键模块,其计算过程如下:
式中:Wq,Wk,Wv为对Oslow和Ofast进行线性变换的权重参数,Q,K,V分别为注意力机制计算时的Query,Key 及Value;d为特征向量嵌入维度,1/缩放操作用于解决点乘操作可能导致的梯度消失。
式(7)—式(10)说明了注意力图的运算过程,多头注意力机制通过多个参数矩阵对输入特征进行注意力计算,其中每一个注意力头headi可表示为:
式中:headi为第i个注意力头的输出结果。
由多个注意力头进行聚合的结果OMCA表示如下:
式中:⊕为连接操作;Wo为输出层的权重;l为注意力头的总数。
Spatio Transformer 通过注意力机制对Slow 和Fast 通道所生成的语义特征和空间特征在像素区域进行聚合,从而捕捉Slow 通道中的重点动作变化区域。
Temporal Transformer 的结构如图4 所示,从结构组成上Temporal Transformer 与Spatio Transformer相近,但为了从时间维度上捕捉Fast 通道帧序列中的重点帧,在进行MCA 前需要重新对维度变化进行设计。Temporal Transformer 并不对时间维度进行变化以保留时间特征,而是将图像像素点转化为一维向量,同时以注意力机制捕捉像素点变换剧烈的时间帧;其整体过程类似于Spatio Transformer,但是在RS 操作上有所变换,变换细节如式(13)所示:

图4 Temporal Transformer模块Fig.4 Module of Temporal Transformer
Spatio-temporal Transformer 结构在双通道特征间搭建了一个基于注意力机制的桥梁,在保留了CNN归纳偏置特性的同时增加了全局注意力权重分配。
3 实验验证
3.1 数据集
本文制作了一个基于AVA[27]格式的跨栏违规行为检测数据集,共包含132 个视频剪辑片段。根据原子动作进行分解,数据集中的标签包含站立、行走和跨越3 个类别。数据预处理过程如下:(1)将视频以每秒30 帧的形式进行分割;(2)从每秒中挑选1 帧作为关键帧并进行数据标注;(3)使用目标跟踪方法为关键帧添加身份标签。经过数据预处理,共有11 513 帧图像,其中397 帧为进行动作标注的关键帧。将数据集中的80%作为训练集,其余部分作为测试集。
3.2 实验设置
实现ST-SlowFast 所采用的pytorch 版本为1.12.1,并且在NVIDIA TITAN XP 上完成训练。模型在训练的过程中使用Adam 优化器进行梯度更新,学习率设置为0.000 2,β1和β2分别设置为0.9和0.999,权重衰减系数设置为0.000 1,迭代轮次为500;使用ResNet-101 作为特征提取主干模型,选取在Kinetics-400 上进行训练的预训练的权重作为快慢通道的初始权重,对ST 通道的权重进行训练。
3.3 评估指标
本文采用平均精确度均值(mean Average Precision,mAP)作为实验指标。该值需要对数据集中的每一个类计算精确度均值(Average Precision,AP)值,该值同时与精确率Vpre和召回率Vrec这2 项指标相关:
式中:TP,FP,FN分别为真阳、真阴及假阴的样本个数。
由于Vpre和Vrec是一对矛盾的值,因此采用AP来对结果进行评估更加直观,其计算方式为统计不同Vpre和Vrec值曲线下的面积VAP:
式中:P和R分别为准确率和召回率。
真实场景应用中通常涉及到多个类别下的模型性能评估,因此mAP 的使用频次更高,其是多个类别AP 的均值,可采用OmAP表示为:
式中:OAPj为第j个类别的值;N为类别总数。
3.4 对比实验
为了更好地评估ST-SlowFast 在跨栏行为检测上的性能,本文选取SlowFast,SlowOnly 及ACRN[21]作为对比方法。实验结果如表1 所示,其中OmAP在计算时所采用的重叠面积阈值设置为0.5。由表1 可知,本文所提出的ST-SlowFast 相较于其他方法在mAP 值上都有较大的提升。对比基线模型SlowFast,本文所提出的模型在性能上提高了约22%。由此可知,第3 条特征通道添加让模型能够捕捉到抬脚等细微动作的变化。STSlowFast 可视化结果如图5 所示,其中绿色检测框表示检测所得结果。从图5 可以看出,在室内外环境中ST-SlowFast 对跨栏违规行为均有较好的检测结果。
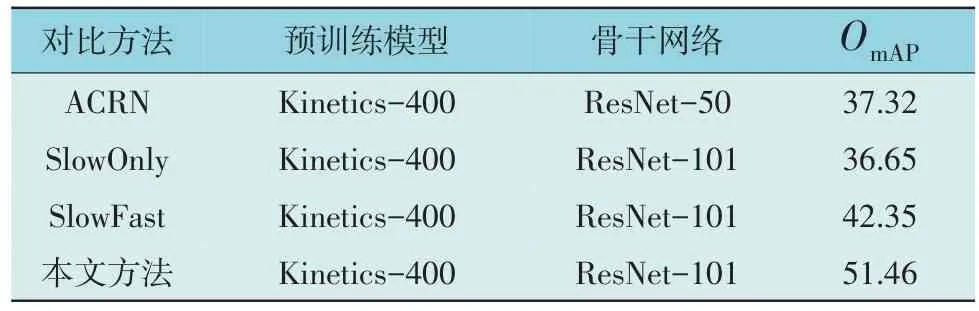
表1 跨栏检测数据集上不同物体检测器的比较Table 1 Comparison of different object detectors on hurdle detection dataset

图5 可视化结果Fig.5 Visualization results
3.5 消融实验
消融实验将分别仅保留Spatio Transformer 和Temporal Transformer 模块,以验证每个模块的作用。消融实验结果如表2 所示,其中√代表使用该模块,×代表不使用该模块。
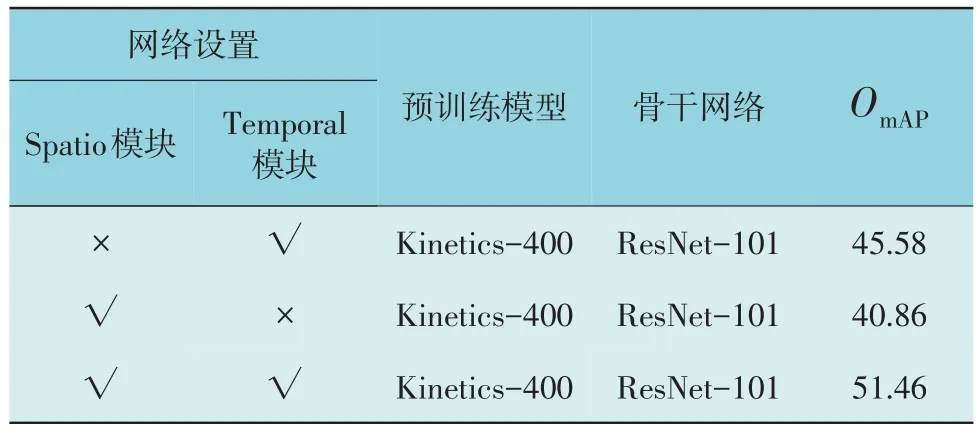
表2 消融实验结果Table 2 Ablation experiment results
由表2 可知,融合两个模块的ST-SlowFast 的实验结果相较于单独加入Spatio 模块及Temporal模块所得到的结果获得了更高的mAP 值,说明本文所提出的2 个模块均能够有效地提升模型的性能。
4 结语
本文针对传统行为检测方法存在的缺陷提出了一种时空间信息融合网络ST-SlowFast,利用时空间注意力通道将不同尺度的双通道特征进行细粒度融合,能在低帧率空间语义和高帧率时间语义间捕获更多细节信息。在跨越围栏违规行为检测背景下,ST-SlowFast 在检测准确率上有着显著提升,能够有效地降低安全监管的人力成本。
猜你喜欢
中小学校长(2022年7期)2022-08-19 01:36:36
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
昆明医科大学学报(2021年4期)2021-07-23 01:21:56
冶金设备(2020年2期)2020-12-28 00:15:22
高原山地气象研究(2020年3期)2020-07-16 07:53:58
中小学校长(2019年10期)2019-11-07 04:56:38
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电子设计工程(2015年16期)2015-02-27 12:07:56
教育与职业(2014年31期)2014-01-19 01:48:18
