
基于扩张因果卷积模型的冷库商品销售量预测
2023-07-17 03:25:37王天润蒋洪伟
物流科技 2023年15期
关键词:深度学习
王天润 蒋洪伟


摘 要:疫情环境下,供应链受到不良影响,库存及市场投入量关乎着社会以及民生的稳定。但是供给与需求无法达到完全一致的现象普遍存在,这使存储管理上面临两方面难题:要么库存过剩增加成本,要么库存不足造成供给短缺。在这种情况下,对商品销售量预测进行深入的研究是一件非常重要的事情。传统的一维卷积神经网络(CNN)在销售量预测上存在信息泄露的问题,且其结构难以获取较长的记忆。文中提出扩张因果卷积神经网络(Dilated Causal Convolution)来优化模型解决问题,其中扩张卷积可以增加卷积模型的感受野大小,获取序列的长时记忆;同时引入因果卷积来解决信息泄露问题。实验结果表明文中提出的扩张因果卷积在销售量预测方面有着较好的预测效果。
关键词:销售量预测;空洞卷积模型;因果卷积模型;深度学习
中图分类号:F253 文献标志码:A DOI:10.13714/j.cnki.1002-3100.2023.15.017
Abstract: Under the epidemic situation, the supply chain is adversely affected. Inventory and market input are related to the stability of society and people's livelihood. However, the phenomenon that supply and demand cannot be completely consistent is widespread, which makes storage management face two problems: Either excess inventory increases costs, or insufficient inventory causes supply shortage. In this case, it is very important to make an in-depth study on the forecast of commodity sales. The traditional one-dimensional convolutional neural network(CNN)has the problem of information leakage in sales forecasting, and its structure is difficult to obtain a long memory. In this paper, a modified causal convolution neural network is proposed to optimize the model to solve the problem. The expanded convolution can increase the receptive field size of the convolution model and obtain the long-term memory of the sequence; at the same time, causal convolution is introduced to solve the problem of information leakage. The experimental results show that the extended causal convolution proposed in this paper has a good prediction effect in sales volume prediction.
Key words: sales volume forecast; void convolution model; causal convolution model; deep learning
0 引 言
疫情以來,我国各地相继采取隔离措施,与此同时,居民的吃饭问题成为了民生保障的重中之重。其中不少副食品常温不易保存,但是冷库仓储空间有限。目前国内企业在运营中很多时候是根据平日的经验和简单辅助工具来进行销售量预测[1],根据专家经验的预测会造成部分商品缺货的同时部分商品存在积压等问题。所以建立有效准确的销售量预测模型能够有效维持冷库货品的出入库平衡,增加存储空间利用率。因此,销售量预测作为冷库供应链管理的一个环节显得格外重要。
销售量预测作为物流领域一个非常基础的研究方向,很多学者都进行了相关研究。从时间维度来看,销售量预测问题就是经典的时间序列预测问题,时间序列预测问题的重点是从过去的信息中挖掘寻找出随时间不断变化的一种趋势,从而对未来的数据进行预测。近几十年来学者对时间序列预测算法进行了大量研究,在许多方面取得良好成绩。目前主要的研究方法分类有两种,一种是基于统计学的方法,一种是基于机器学习的方法。
传统时间序列预测模型,通常指用于时间序列分析/预测的统计学模型,比如常用的有均值回归、ARIMA、指数平滑预测法等,优点是复杂度低、计算速度快,但是有其局限性。通过实验,发现由于真实应用场景的复杂多样性(现实世界的时间序列往往受到各种不同因素的限制与影响,而难以预测),比如受到营销计划、自然灾害等影响,传统的单一统计学模型的准确率相对来说会比机器学习差,而机器学习模型相对更复杂,其集成模型会有更好的效果。
在机器学习的预测方法中,相对于传统的树模型需要人工构建相关模型特征,神经网络模型通常需要输入大量的数据来进行训练,因此如果同类时序的数据量够多(有够多的彼此间相关性较强的时序),那么训练一个通用型的端对端的神经网络预测会有不错的效果。
深度学习是机器学习的一个分支,它利用深层体系学习数据的特征[2-3],非常善于发现高维数据中的复杂结构[4-5],它的兴起以及预测模型的组合带来了许多新的预测思路。
例如Aburto、Weber结合神经网络和SARIMA模型组合来预测食品销售[6];Zhang在研究中认为,当数据的时间序列被反季节性和反趋势化时,神经网络的预测性能有了大幅提高[7]。Kou等人尝试将遗传算法与神经网络模型相结合,来预测某次某便利店的奶制品销量,发现将不同的模型组合优化后的模型在预测上的表现优于传统统计方法以及单一的神经网络预测模型[8]。
近年来,研究人员对销售量预测模型进行了更深入的研究,为了解决人工提取特征时主观性强且既费时又费力的问题,尝试用卷积神经网络让模型自动提取特征,并验证了该方法是可行的[9]。
因果卷积(Causal Convolution)是一种重要的卷积网络,早在1989年该结构便已经出现[10]。近来,这一模型在声音处理、自然语言处理、机器视觉等领域都有了比较好的应用。因果卷积结构能够保证计算时仅涉及之前时刻的信息,非常适于解决预测问题[11]。
1 扩张因果卷积模型
1.1 因果卷积。信息泄露是指针对带有时间序列信息的数据处理时的问题,需要确保模型可以按顺序使用数据,即在模型预测t时刻时,不会用到t+1,t+2等未来时刻数据。而传统的CNN模型中,每层神经元的连接是全连接(fully connected)的形式,不难发现,全连接恰恰违背了时间先后的基本约束,因为输出的靠前的(前一时刻)神经元与输入靠后的(后一时刻)神经元相互产生了连接,这应该是不被允许的,因此做销售量预测需要使用因果卷积模型。因果卷积解决的是时序预测中的信息泄露(leakage)问题,因果卷积的原理如图1所示[12]。
从上面结构可以看出,与传统的CNN相比,因果卷积只能使用过去的数据,而不会使用到未来的数据,所以很好地解决了信息泄露问题。一维因果卷积在pytorch中一般通过Padding实现,序列前端填充相应位数的零,而序列末端不进行填充。因为因果卷积是单向结构的,所以它不能看到未来的数据,也就是只能从前面的数据来预测后面的数据,是一种严格的时间约束模型。模型在t时刻输出的预测不会依赖任何一个未来时刻的数据,只依赖于下一层t时刻及其之前的值。
但是由于每一层的输出都是由前一层对应位置的输入及其前一个位置的输入共同得到,并且如果输出层和输入层之前有很多的隐藏层,那么一个输出对应的所有输入就越多,如果每层的卷积核大小一定,空洞率一定,那么为了提高感受野,就要大幅增加网络的深度。这样会增加卷积的层数,而卷积层数的增加就带来诸如梯度消失,训练复杂,模型过拟合等问题。
1.2 扩张卷积。针对商品销售量预测等序列任务,需要对之前一段时间内的商品销售量数据进行统计建模,不能仅仅依靠前一天的商品销售量来预测第二天的出货量。而传统全连接神经网络的连接结构丢弃了数据的时间序列、时间的先后关系等基于顺序的信息。卷积神经网络可以通过卷积计算获取数据序列关系,形成“记忆”,感受野的大小反映了使用多少数据生成“记忆”。在时间序列预测任务上使用卷积神经网络最大的问题是如何有效的提取长时间的记忆信息。
在卷积神经网络中,感受野指的是每一层输出的特征图(Feature Map)上的节点在原始输入图片上映射区域的大小。为了更好地获取长时记忆,关键就是扩大感受野。当卷积层数为l,每层卷积核大小为k时,感受野大小为k-1×l+1。卷积神经网络的感受野大小与卷积核大小、卷积层数呈线性关系。因此,增加卷积层或者增大卷积核均能扩大感受野。但更深的卷积层数以及更大的卷积核,将会使网络过于庞大,难以完成训练[13]。
在卷积神经网络中,较大的卷积核对运算的算力要求增加而且模型训练变慢,这是由于卷积核每增大一点,网络的参数都会急剧增加。所以通常使用小的卷积核。另外一种较好的获取长时记忆的方法就是使用扩张卷积,与传统的卷积相比,扩张卷积除了卷积核大小外,还有一个参数是用来表示扩张大小的扩张系数(Dilation Rate)。
扩张卷积(Dilated Convolution)也被称为空洞卷积或者膨胀卷积,是在标准的卷积核中注入空洞,以此来增加模型的感受野(Reception Field)。相比原来的正常卷积操作,扩张卷积多了一个参数:Dilation Rate,指的是卷积核的点的间隔数量。扩张卷积主要作用是可以指数倍扩大视野,通过在每一层乘法来实现层深和感受野大小间的指数关系。可以看到随着扩展系数(Dilated)扩大,视野距也在扩大,其原理如图2所示。
对于一维输入的X, X∈R,滤波器f:0,…,k-1→R扩张卷积的计算F定义公式为:
Fs=X*dfs=∑fiX (1)
式中:d表示扩张系数,k表示卷积核大小,s-d*i表示上一层的感受野。当d为1 时,扩张卷积退化为普通卷积,通过控制d的大小,可以在计算量不变的前提下拓宽感受野。
一般的扩张卷积,随着网络深度的增加,扩张系数呈指数增大,这样可以保证越深的卷积核能获取到的历史信息越长。
1.3 扩张因果卷积。将因果卷积与扩张卷积思想结合,得到扩张因果卷积(Dilated Causal Convolution),原理如图3所示。扩张因果卷积的扩张系数分别为1、2、4。扩张系数呈指数增长,使得感受野大小也呈指數增长,这样在卷积层数不高的情况下,也能获得很好的感受野,同时少的卷积层数还保证了模型的计算效率。
1.4 扩张因果卷积模型结构。本文模型由一组残差单元构成,如图4所示。每个残差单元是一个具有残差连接的小型神经网络,通过残差连接可以加快深层网络反馈以及收敛,解决因为网络层次的增加而造成的模型退化。
每一个残差单元包括两个卷积单元和一个1*1cov。卷积单元通过扩张系数的调整来实现更大的感受野,从而让网络能够记忆足够长的信息,且只对需要预测时刻t前的输入数据进行卷积得到t时刻的输出,确保不会发生信息泄露;然后对权重进行归一化处理,使用ReLU函数为激活函数;最后用Dropout操作来随即丢弃一些神经元,来加速模型训练并防止过拟合。1*1cov的作用是在残差单元的输入和输出具有不同的维度时,对高维数据进行降维。
2 实验与结果分析
2.1 环境设置。为了验证本文所提扩张因果卷积模型的性能,利用Pytorch软件进行算法编译,仿真环境为处理器i7-10875H CPU 4.5GHz RAM16GB Win10操作系统的笔记本电脑。
2.2 数据的选取与划分。本文选用了某企业2020年7月1日到2021年1月31日共6个月的每日冷库货品销售量作为实验数据集,选取其中畜肉类商品,计算出每日销售量作为实验数据,部分数据如表1所示。
训练数据从2020年7月1日到2021年1月31日六个月数据,预处理后共131 112条完整样本。其中20%作为验证集,验证集大小为26 222,测试集从2021年1月1日到2021年1月31日,总样本量为21 452。
2.3 实验设计
(1)首先将冷库产品销售量数据进行处理,去除掉个别差错数据,然后将每天的销售量计算出来,以时间步为16天来对数据进行滑窗化处理,以便根据每一天的产品销售量来预测下一天的产品销售量;(2)数据进行预处理并划分训练集与测试集;(3)将训练集输入扩张因果卷积模型进行训练,模型输入序列长度为16,卷积层数为4;(4)利用训练好的模型预测测试集冷库出货量并计算误差。
本文使用模型进行了两种情况的预测实验。
为了检验扩张因果卷积对销售量预测准确度,本文采用了平均绝对百分比误差MAPE为指标来评价模型的拟合精度。MAPE的计算公式如公式(2)所示:
MAPE=∑×100% (2)
式中:xk为预测值,k为实际值;ek=xk-k, k=1,2,3,…,n。
MAPE的评价标准如表2所示。
实验一:使用32天的数据,对接下来一天的销售量进行预测,得到结果后与实际销售量进行对比并计算MAPE。
实验二:使用32天数据,对接下来七天的销售量进行预测,
由于预测接下来一天的销售量时输入数据将模型训练之后进行预测,网络输出的最后一个数字就是对接下来一天的销售量预测,所以在连续预测多天时,可以首先按照预测一天的流程预测,将得到的结果拼接到输入数据中并在输入数据中去掉第一位来预测接下来一天。如此循环至预测满需要预测的七天这个时间段。
2.4 实验结果及分析
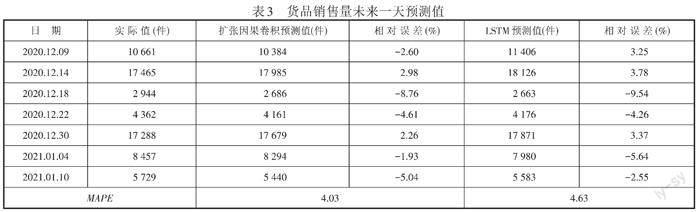
2.4.1 实验一。本文应用的扩张因果卷积模型,随机抽取日期,根据过去32天的销售量预测未来一天的货品销售量,实验结果如表3所示。
2.4.2 实验二。应用扩张因果卷积。抽取了2021.01.09日为起始日期,以之前32天的销售量来预测接下来一周的销售量,得到数据如表4所示。
从表3中数据可以看出利用扩张因果卷积模型得到的销售量预测模型的MAPE值为4.03,说明其精度更高。
从表4中数据可看出利用扩张因果卷积模型通过过去30天来预测,接下来七天得到的冷库畜肉出货量预测MAPE为5.01%,说明其预测精准度依然較高。根据表2中评价标准及对比实验一可知,扩张因果卷积模型在预测未来七天的销售量数据时,虽然精确度没有预测未来一天的时候高,但其拟合精度仍为优。
3 结 论
本文针对销售量的预测有天然时空依赖性,构建扩张因果卷积模型,使用扩张卷积来增加感受野大小,从而获取序列的长时记忆;同时引入因果卷积来确保数据的时序性解决信息泄露问题。设计了预测一天和预测七天两个实验。通过对比MAPE指标,验证了模型具有良好的精确性。
过去十几年,神经网络在图像识别、顺序处理等方面都展现了良好的性能,在预测方向,神经网络模型也得到了更多的应用,相信随着研究的深入,基于卷积的神经网络模型也可以推动冷库商品销售量预测的进一步发展。
参考文献:
[1] 蒋文武. 基于WaveNet-LSTM网络的商品销量预测研究[D]. 广州:广东工业大学,2019.
[2] CHEN X W, LIN X. Big data deep learning: Challenges and perspectives[J]. Quality Control Transactions, 2014,2(2):514-525.
[3] GUO Y, LIU Y, OERLEMANS A, et al. Deep learning for visual understanding: A review[J]. Neurocomputing, 2016,187(26):27-48.
[4] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015,521:436-444.
[5] LITJENS G, KOOI T, BEJNORDI B E, et al. A survey on deep learning in medical image analysis[J]. Medical Image Analysis, 2017,42(9):60-88.
[6] ABURTO L, WEBER R. Improved supply chain management based on hybrid demand forecasts[J]. Applied Soft Computing, 2007,7(1):136-144.
[7] ZHANG G P, QI M. Neural netw ork forecasting for seasonal and trend time series[J]. European Journal of Operational Research, 2005,160(2):501-514.
[8] KUO R J. A sales forecasting system based on fuzzy neural network with initial weights generated by genetic algorithm[J]. European Joumal of Operational Research, 2001,129(3):496-517.
[9] 釗魁. 基于卷积神经网络的电商数据深度挖掘[D]. 杭州:浙江大学,,2017.
[10] WAIBEL A, HANAZAWA T, HINTON G, et al. Phoneme recognition using time-delay neural networks[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1989,37(3):328-339.
[11] 刘宇杰. 基于因果卷积的预测算法研究[D]. 哈尔滨:哈尔滨工程大学,2020.
[12] 翟剑锋. 基于TCN的时序数据研究[J]. 电子技术与软件工程,2021(2):196-198.
[13] 袁华,陈泽濠. 基于时间卷积神经网络的短时交通流预测算法[J]. 华南理工大学学报(自然科学版),2020,48(11):107-113,122.
收稿日期:2022-11-23
作者简介:王天润(1998—),男,辽宁沈阳人,北京信息科技大学信息管理学院硕士研究生,研究方向:大数据与智慧物流;蒋洪伟(1972—),本文通信作者,男,辽宁沈阳人,北京信息科技大学信息管理学院,副教授,研究方向:数据分析与数据挖掘。
引文格式:王天润,蒋洪伟. 基于扩张因果卷积模型的冷库商品销售量预测[J]. 物流科技,2023,46(15):72-75.
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
