
基于改进轻量化YOLOv4 模型的虾只肉壳辨识方法
2023-07-14 14:28:28陈学深吴昌鹏党佩娜刘善健
农业工程学报 2023年9期
陈学深,吴昌鹏,党佩娜,梁 俊,刘善健,武 涛
(华南农业大学工程学院,广州 510642)
0 引言
中国虾产量位居世界第一,近年来增长迅速,年产量涨幅为12.5%[1-2]。机械剥壳是虾只生产加工的重要环节,由于现有技术和装备不够完善,脱壳后裸肉虾中混杂的带壳虾需要进一步人工清选,存在劳动强度大、生产成本高、分选效率低等问题[3-4]。因此,准确辨识裸肉虾与带壳虾实现虾只自动分选十分必要。
国内外学者主要采用机器视觉技术进行了相关研究,分为传统图像处理和机器学习两种方法。LEE 等[5]基于大津法(OTSU)提取了虾只轮廓,结合快速曲线相似度评价方法,在蓝色背景下实现了虾只识别。罗艳[6]基于Zhang-Suen 细化算法有效去除多余分支,并提取了虾只主骨架线,实现了虾只识别。上述方法主要通过设定形状、姿态阈值实现虾只识别,识别方法对虾只光照和背景有一定要求,抗干扰能力较差。
为提高虾只肉壳辨识的抗干扰能力,更多学者采用机器学习方法,主要包括人工特征选择的机器学习和自动特征提取的深度学习两种方法。HU 等[7]优选了虾只颜色、形状、纹理特征,构建了虾识别模型。洪辰等[8]基于灰度差异法提取了虾只骨架线,融合虾只体长、头胸甲长、头胸甲宽等特征,构建了虾只识别模型。上述机器学习方法识别精度高度依赖特征提取的有效性,但不同品种、不同剥壳方式的虾只特征存在差异,基于选择特征的机器学习方法泛化能力不理想。
深度学习在图像识别领域取得了巨大成功,能够不依赖特定特征,自动学习原始图像像素数据的特征表达,可获得比原始数据表达能力更好的特征描述[9-10]。深度学习识别方法可分为两类,一类基于区域推荐的目标检测方法[11]。龚瑞[12]采用此检测方法基于Faster R-CNN模型实现虾只自动识别,准确率为85%。另一类是基于回归的目标检测方法,该方法可实现端到端的网络结构,具有较高的识别精度,目前应用最为广泛[13-14]。其中,YOLO[15-16]系列最典型。刘雄[17]采用Darknet 作为YOLOv4模型特征提取网络,对虾只剥壳效果进行检测,准确率达90%以上。王淑青等[18]采用CIoU 作为YOLOv4 模型的损失函数,有效提高了预测框回归效果,同时引入CBAM 注意力机制增强模型特征抓取能力,模型检测准确率为97.8%。虽然改进YOLOv4 模型在识别精度方面获得了较好的效果,但仍存在网络结构复杂、资源占用多等问题。为此,许多学者针对YOLOv4 主干特征提取网络进行轻量化处理[19-22],目前较成熟的轻量级网络有Google 的MobilenetV3 系列[23]和Efficientnet Lite 系列[24],旷世的Shufflenet 系列[25],华为的GhostNet[26]等,上述轻量级网络在一定程度上提高了模型的检测效率。
本文根据虾只肉壳辨识要求,在YOLOv4 模型基础上,通过替换主干特征提取网络、引入轻量级注意力机制、替换损失函数等改进方法,构建了裸肉虾与带壳虾的辨识模型实现虾只自动分选。
1 数据集与预处理
1.1 图像采集
模型样本为经过去头处理的中国明对虾,经夹尾、开背、去肠、脱壳等机械剥壳处理,单只对虾落料在传送带上,由虾只肉壳辨识试验台进行裸肉虾与带壳虾辨识分选。图像采集于华南农业大学工程学院虾只肉壳辨识试验台,如图1 所示。试验台尺寸为190 cm×30 cm×90 cm,传送带输送速度为0.1 m/s。图像采集设备为HIKVISION 工业相机,有效像素为1 800 万。样本采集时天气晴朗,分为白天和晚上2 个时段,其中晚上采用人工光源。采集时相机镜头与水平方向分别以30°、45°、75°、90°夹角拍摄,图像分辨率为2 928×3 904(像素),原图像保存为jpg 格式,总计拍摄1 400 张图像,人工筛选出质量高、画质清晰的1 321 张作为图像数据集。

图1 虾只肉壳辨识试验台Fig.1 Shrimp meat and shell identification test bench
1.2 图像预处理
为提高训练效果、增强模型泛化能力,对采集图像进行预处理。运用OpenCV 改变原始图像亮度和对比度以模拟不同光照亮度下的环境状况;引入高斯噪声与椒盐噪声,扰乱图像可观测信息,提升模型对目标的捕捉能力;进行图像旋转,增加检测目标的姿态。通过图像预处理增加了裸肉虾图像622 张,带壳虾图像699 张,图像数据集增强效果如图2 所示。为降低信息泄露,更准确反映模型效能,保证模型分辨准确率,将训练集和测试集按9:1 进行划分,训练集为2 387 张,验证集为264 张。同时使用Labelimg 对处理的虾只图像进行标注,生成与图片名称相对应的XML 文件。

图2 虾只图像数据集增强Fig.2 Shrimp image dataset enhancement
2 YOLOv4 网络模型改进
2.1 幻象模块(Ghost Module)引入
YOLOv4 模型由许多基本结构块组成,但由于大量卷积模块计算得到的中间特征图存在高度冗余,导致模型计算量增加[27-29]。本文引入幻象模块(Ghost Module)使YOLOv4 模型更加紧凑,通过减少冗余特征图,提升主干特征提取网络的运算速度。采用幻象模块对输入图像进行处理,流程如图3 所示,具体实现步骤为:1)输入图像经标准卷积运算生成原始特征图;2)原始特征图经低成本深度卷积得特征图φ;3)特征图经标准卷积运算输出叠加特征图。

图3 幻象模块示意图Fig.3 Ghost module diagram
模型引入幻象模块后,可代替YOLOv4 模型的普通卷积,为主干特征提取网络替换提供了基础。
2.2 主干特征提取网络替换
构建特征金字塔时,YOLOv4 主干特征提取网络CSPDarknet53 会将3 个有效特征层分别传入到加强特征提取网络SPP 和PANet 中[30-31],由于此过程需要进行大量卷积计算,降低了网络运算速率。幻象瓶颈结构通过对图像特征层“可分离卷积—深度可分离卷积和普通卷积—可分离卷积”处理,实现特征层宽高压缩,使模型更轻量化。
为减少卷积计算量,在改进YOLOv4 网络中利用Ghost Module 代替CSPDarknet53 中的普通卷积获得幻象瓶颈结构(Ghost bottleneck),如图4 所示。
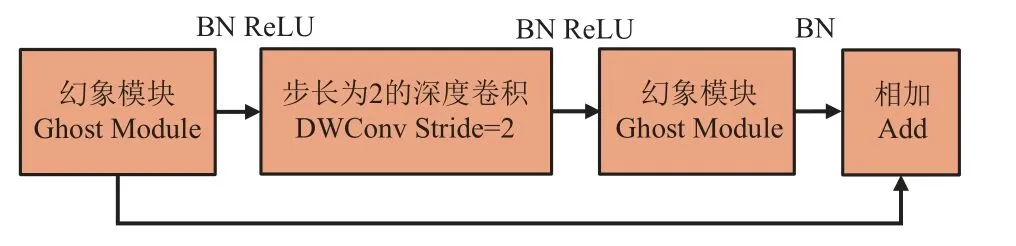
图4 幻象瓶颈结构Fig.4 Ghost bottleneck structure
本文将输入层的图像大小调整为416×416×3,并使用Ghost Module 代替普通卷积,组成轻量化神经网络GhostNet,得到第一有效特征层(尺寸为52×52×40)、第二有效特征层(尺寸为26×26×112)、第三有效特征层(尺寸为13×13×160)3 个有效特征层,模型经过改进后减少了储存容量,改进前和改进后有效特征层尺寸大小如表1 所示。由表1 可知,GhostNet 主干特征提取网络比原CSPDarknet53 主干特征提取网络的有效特征层更为轻量化,进而提高了模型的检测效率。

表1 有效特征层尺寸大小对比Table 1 Comparison of effective feature layer size
2.3 注意力机制嵌入
注意力机制模仿人类大脑视觉注意力机制,通过浏览全局图像对输入信息进行注意力分配,确定重点关注区域,从而快速获取关键信息[32-34]。为提高改进YOLOv4模型虾只肉壳辨识准确率,在预测端嵌入典型SE 注意力机制模块,拟合目标通道相关特征信息,提高模型抗干扰和特征提取能力。SE 注意力机制处理流程如图5 所示,具体实现步骤为:
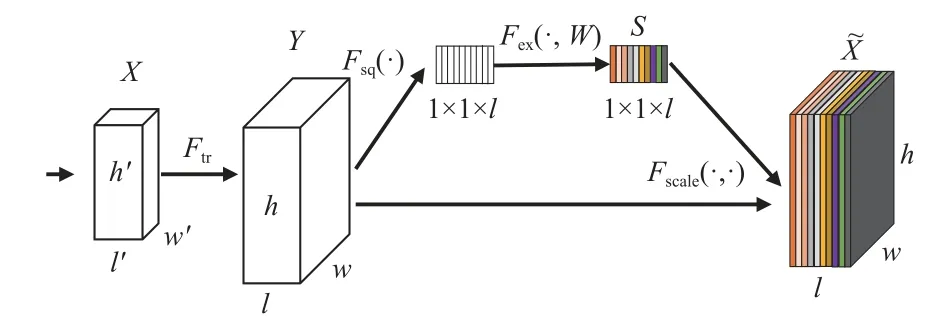
图5 SE 注意力机制流程图Fig.5 SE attention mechanism flowchart
1)对输入特征图X(h’×w’×l’)进行转换,生成长为h、宽为w、通道为l的通道特征图像Y;
2)SE 模块对输入特征图X做全局平均池化,将通道特征图像的长宽求和再取平均值生成空间注意力特征,有效提升对图像的关注能力;
3)通过挤压(Squeeze)操作将h×w×l的特征图压缩为1×1×l特征图,压缩层操作算法如式(1)所示;
4)通过激励(Excitation)操作使用两层全连接自适应学习生成权重S,激励操作算法如式(2)所示;
5)将通道注意力的权重S(1×1×l)、原始输入特征图Y(h×w×l),进行逐通道乘以权重系数,输出具有通道注意力的特征图(h×w×l)。
式中u(i,j)为特征图上的单个特征值,Z为通道特征图的平均特征值,H为特征图的高度,W为特征图的宽度。
式中w1、w2分别为两个全连接层的权值,δ为连接层的ReLU 激活函数,σ为Sigmoid 函数。Sigmoid 函数归一化操作构建各个注意力特征通道之间的关系,把每个通道的数值限制在0~1 之间,抑制无用特征通道信息,激活重点关注区域特征通道。
2.4 CIoU 损失函数设计
合理选择损失函数可以使检测框更适合虾只尺寸,有助于提高模型收敛速度。YOLOv4 模型中采用GIoU损失函数作为位置回归损失的评价指标,计算如式(3)所示。
式中A为预测框,B为真实框,C为包含A和B的最小凸集。
GIoU 损失函数原理如图6a 所示,针对检测框位置或大小不同时,增加了相交尺度的衡量方式,但GIoU 损失函数无法区分相对位置关系,例如检测框面积相同且在标注框内部不同位置时,检测框和标注框差集D相同,导致模型目标检测误差增大。相比较,ZHENG 等[35]提出的CIoU 损失函数可有效区分相对位置关系,减小目标检测误差,原理如图6b 所示,计算式如(4)~(7)所示。
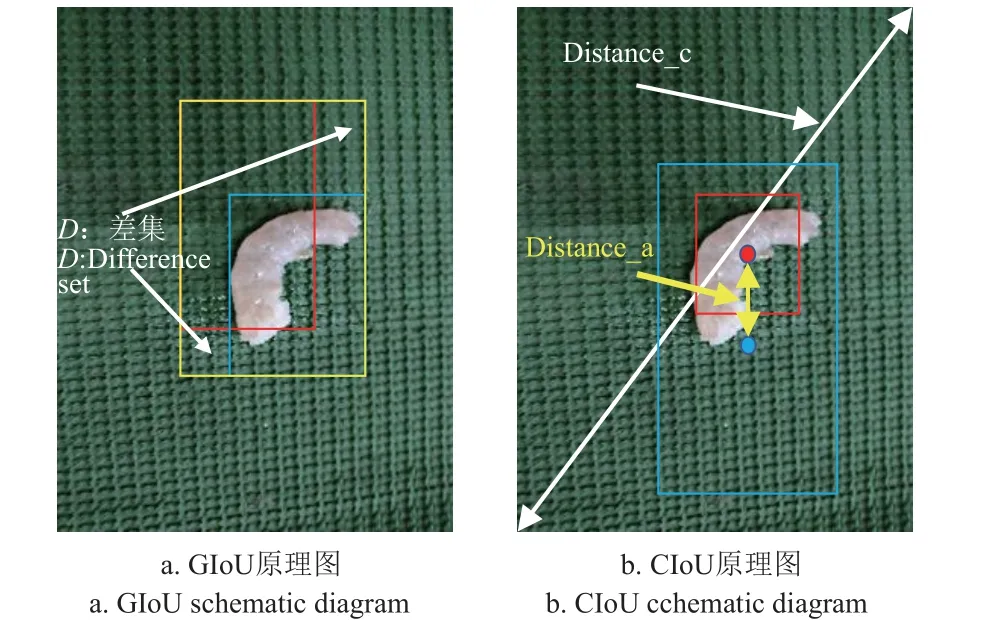
图6 GIoU 和CIoU 原理图Fig.6 GIoU and CIoU schematic diagram
式中 ρ2(b,bgt)为预测框和真实框中心点的欧式距离,IoU为交并比,α 为权衡参数,v为宽高比度量函数,w、h和wgt、hgt分别为预测框高宽和真实框高宽,c为能够同时包含预测框和真实框最小闭包区域的对角线距离,CIoU为CIoU Loss 函数。
与GIoU 损失函数相比,CIoU 损失函数考虑重叠面积、中心点距离和宽高比,可以直接最小化检测框和标注框中心点之间距离,使非极大值抑制得到的结果更为合理有效,模型预测框更为准确。GIoU 和CIoU 损失函数的框选效果如图7 所示,由图7 可知GIoU 损失函数预测框未能将虾只完整框选,而CIoU 损失函数预测框则完整框选了虾只。

图7 不同损失函数的框选效果Fig.7 Effects of frame selection with different loss functions
2.5 改进后的YOLOv4 网络模型
YOLOv4 模型经过主干特征提取网络替换、SE 注意力机制嵌入、CIoU 损失函数设计,构建的改进YOLOv4网络模型(GhostNet-YOLOv4)结构如图8 所示,模型经过改进减少了运算量、增强了特征通道间的关注度、提高了预测框的回归效果,可有效提升模型检测准确率和实时性。
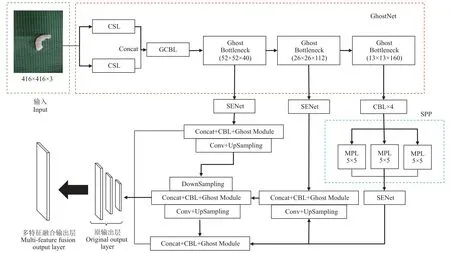
图8 改进YOLOv4 网络结构图Fig.8 Improved YOLOv4 network architecture diagram
2.6 评价指标
采用召回率(recall,R,%)、准确率(precision,P,%)、AP值(average precision,AP,%)和mAP(mean average precision,%)4 个指标对模型进行性能评估,计算如式(8)~(11)所示。
式中TP和FP分别表示真实的正样本和虚假的正样本,FN为虚假的负样本,M为检测目标的类别总数,AP(k)为第k类AP值。
3 结果与分析
3.1 不同模型轻量化对比
为检验模型改进效果,选择YOLOv7、EfficientNet Lite3-YOLOv4、ShuffleNetV2-YOLOv4、MobilenetV3-YOLOv4 模型,以及改进YOLOv4 模型进行轻量化对比验证,结果如表2 所示,由表2 可知,改进YOLOv4 模型参数量最少、计算量最小、轻量化程度最高。

表2 不同目标识别模型比较Table 2 Comparison of different target recognition models
3.2 试验平台与模型训练结果
试验训练集包含裸肉虾图像为1 064 张,带壳虾图像为1 109 张,两者共存214 张。采用Pytorch-GPU1.2 深度学习框架,运行的深度学习处理器为Intel Core-i5-12 400,3.20 GHz,显卡为GeForce RTX 3 080,操作系统为Windows 10,NVIDIA 461.37 驱动,CUDA11 版本,CUDNN神经网络加速库版本为7.6.5。基于试验平台硬件运行性能设置迭代训练样本数为8,根据拟合效果选择迭代次数为500 次。为提高模型稳定性避免训练后期震荡设置动量因子为0.973,衰减系数为0.005,初始学习率为0.001,优化器选择sgd,使用Mosaic 数据增强与余弦退火算法。训练完成后根据后台日志信息记录绘制模型训练损失值变化趋势图,如图9 所示。由图9 可知,模型随迭代次数增加,损失值逐渐减少。GhostNet-YOLOv4模型经历20 次迭代后,模型损失值收敛到2.5 以下,至350 次迭代后损失值趋于平稳,趋于稳定后GhostNet-YOLOv4 模型损失值为1.2,相比YOLOv4 模型损失值减少了1.2,比YOLOv3 模型损失值减少了1.8,比MobilenetV3-YOLOv4 模型损失值减少了0.2,验证了GhostNet-YOLOv4 模型识别准确性较优。
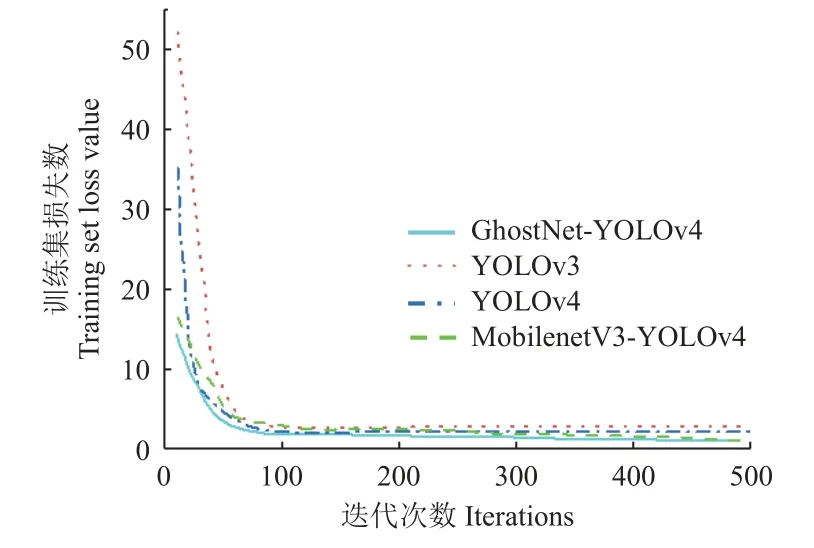
图9 模型训练损失值变化趋势图Fig.9 Model training loss value change trend diagram
3.3 虾只肉壳辨识模型消融试验
为验证主干特征提取网络GhostNet 替换、SE 注意力机制嵌入和CIoU 损失函数设计的改进效果,采用平均精度均值(mAP)、参数量、权重作为模型性能评价指标进行消融试验,结果如表3 所示,由表3 可知,模型经过GhostNet 替换后mAP 提升了2.9 个百分点,加入SE 注意力机制后mAP 提升了1.8 个百分点,CIoU 损失函数设计后mAP 提升了1.4 个百分点。改进YOLOv4模型的平均精度均值为92.8%,而YOLOv4 模型平均精度均值为86.7%,提高了6.1 个百分点。模型改进后参数量和权重明显减少。

表3 消融试验结果对比Table 3 Comparison of ablation test results
3.4 虾只肉壳辨识效果
为验证GhostNet-YOLOv4 模型在不同环境虾只肉壳辨识的有效性,选择阴天及晴天傍晚等光照不足时段,以及在传送带速度为0.1 m/s 输送状态下进行辨识效果试验。本文以相同训练集、不同模型进行训练与测试,基于YOLOv3、YOLOv4、MobilenetV3-YOLOv4 和GhostNet-YOLOv4 模型在相同测试集上进行测试,虾只肉壳辨识测试集共1 000 张照片,部分结果如图10 所示。

图10 不同条件下各模型虾只肉壳检测效果Fig.10 The detection effect of shrimp in different models under different conditions
光照充足时,各模型均可完成虾只肉壳辨识。然而,光照不足时,YOLOv4 和MobilenetV3-YOLOv4 检测准确率明显下降,YOLOv3 模型甚至无法辨识或辨识错误。与其他模型比较,虾只输送时,GhostNet-YOLOv4 的检测准确率与置信度最高。
GhostNet-YOLOv4、YOLOv3、YOLOv4 和Mobilenet V3-YOLOv4 模型的裸肉虾和带壳虾辨识准确率P、召回率R曲线如图11 所示,由图11 可知,GhostNet-YOLOv4的P-R曲线包络面积最大,说明虾只肉壳辨识准确率最高。

图11 准确率-召回率曲线图Fig.11 Precision-recall curve diagram
不同模型的裸肉虾和带壳虾辨识结果如表4 所示,与YOLOv3、YOLOv4、MobilenetV3-YOLOv4 模型相比,GhostNet-YOLOv4 模型裸肉虾识别准确率分别提高了6.9、3.5、1.1 个百分点,带壳虾识别准确率分别提高了9.2、3.8、2.7 个百分点,模型总体识别准确率分别提高了8.1、3.7、1.9 个百分点。与其他模型相比,GhostNet-YO LOv4 模型检测速度最高,为25 帧/s,模型综合性能最优。

表4 不同模型虾只肉壳检测结果Table 4 Results of shrimp meat and shell detection with different training models
3.5 不同剥壳方式虾只肉壳辨识效果
为验证不同剥壳方式虾只肉壳辨识的实际效果,根据图12 所示的虾只不同剥壳方式,进行去尾虾、深切虾、带尾虾、蝴蝶虾的辨识性能试验,测试集共1 815 张图片,其中去尾虾422 张、深切虾464 张、带尾虾519 张、蝴蝶虾410 张。结果如表5 所示。
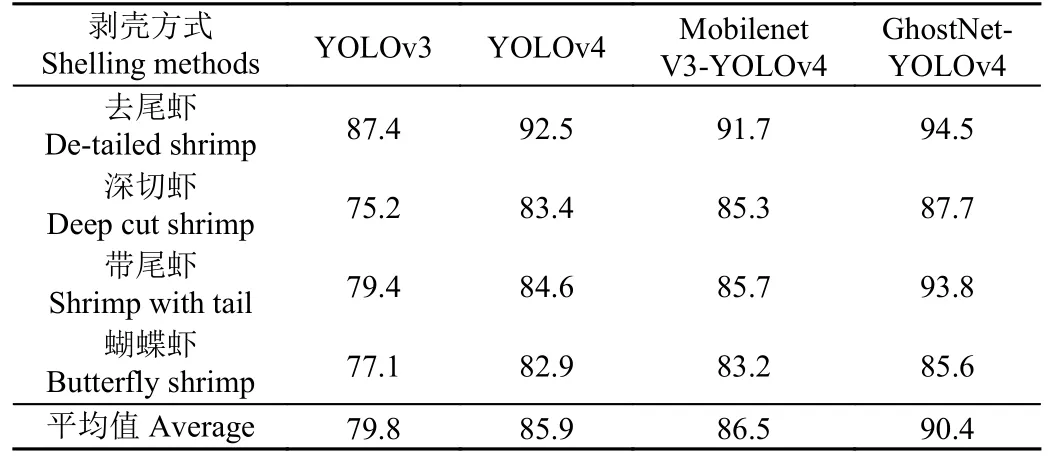
表5 不同剥壳方式虾只肉壳辨识准确率Table 5 Precision of shrimp meat and shell recognition for different shelling methods %

图12 不同剥壳方式的虾只Fig.12 Shrimps with different shelling methods
由表5 可知,GhostNet-YOLOv4 模型辨识准确率平均值为90.4%,与YOLOv3、YOLOv4、MobilenetV3-YOLOv4 模型相比,辨识准确率平均值分别提高了10.6、4.5、3.9 个百分点。但受剥壳方式影响,深切虾和蝴蝶虾由于虾体面积大,易造成肉壳相互遮叠,模型辨识准确率较无遮挡的去尾虾和带尾虾略低,但与其他模型相比,GhostNet-YOLOv4 模型辨识准确率降幅最小。
3.6 不同品种虾只肉壳辨识效果
为验证虾只肉壳辨识模型对不同品种虾的适应性,选择图13 所示的黑虎虾、罗氏虾、日本对虾3 种常见虾只进行辨识性能试验,测试集共1 432 张图片,其中罗氏虾437 张、黑虎虾477 张、日本对虾518 张。结果如表6所示。

表6 不同品种虾只肉壳辨识准确率Table 6 Precision of shrimp meat and shell recognition for different species %

图13 不同品种的虾只Fig.13 Shrimps of different species
由表6 可知,GhostNet-YOLOv4 模型的虾只肉壳辨识准确率最高,平均值为87.2 %,与YOLOv3、YOLOv4、MobilenetV3-YOLOv4 模型相比,准确率平均值分别提高了22.1、12、8 个百分点。受虾只品种影响,上述3个品种的虾只没有经过样本训练,但与其他模型相比,GhostNet-YOLOv4 模型辨识准确率降幅最小。
4 结论
1)构建了改进轻量化YOLOv4 模型,与YOLOv7、EfficientNet Lite3-YOLOv4、ShuffleNetV2-YOLOv4、MobilenetV3-YOLOv4 模型对比,改进的模型参数量最少、计算量最小。消融试验表明改进的模型平均精度均值为92.8%,比原YOLOv4 模型提升了6.1 个百分点。
2)本文通过GhostNet 主干特征提取网络替换、SE注意力机制引入、CIoU 损失函数设计对YOLOv4 网络模型进行改进,有效提高了虾只肉壳辨识性能,构建的GhostNet-YOLOv4 模型总体平均识别准确率为95.9%,检测速度为25.0 帧/s。
3)对构建的GhostNet-YOLOv4 模型进行性能试验。结果表明,不同剥壳方式虾只肉壳辨识准确率平均值为90.4%,不同品种虾只肉壳辨识准确率平均值为87.2%。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
理论与创新(2021年3期)2021-06-24 04:38:31
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年19期)2018-11-14 02:37:08
农村百事通(2017年18期)2017-10-13 06:44:04
自动化学报(2017年11期)2017-04-04 02:52:58
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
小猕猴学习画刊(2015年7期)2015-08-07 23:34:19
中国粮油学报(2015年5期)2015-02-06 01:47:26
