
一种用于遥感图像变化检测的级联跨尺度网络
2023-07-13 09:12刘双泽薛明亮
大连民族大学学报 2023年3期
刘双泽,薛明亮
(大连民族大学 计算机科学与工程学院,辽宁 大连 116650)
变化检测[1]作为遥感领域的重要组成部分,是从同一位置不同时刻获取的两幅遥感图像之间,通过一系列的方法提取出自然或人工变化区域的过程。变化检测在众多领域都有着重要的应用,例如在城市规划[2]、土地调查[3]、灾害评估[4]和生态环境监测[5]等方面。随着越来越多的高分卫星发射到太空,使得具有更高分辨率的遥感图像获取变得更加容易,因此具有高分辨率遥感图像数据集。在这种情况下,寻求新的方法以解决上述问题受到了越来越多研究者的关注,并取得了许多令人瞩目的成果。由于深度学习模型强大的图像处理能力,许多学者将深度学习方法引入遥感图像变化检测领域。因此,近年来涌现了许多基于深度学习的变化检测方法。Song等人[6]设计了一种结合3D全卷积网络和卷积短时长记忆的优点的变化检测方法,名为循环3D全卷积网络。Liu等人[7]提出了一个新的损失函数来实现由语义分割数据集到变化检测数据集之间的迁移学习。这种方法可以缓解变化检测数据集中带注释的训练样本不足的问题。Chen等人[8]提出了一种基于transformer的变化检测模型,它可以通过对时空域内的上下文进行建模,来关联时空中的远程概念。该方法可以有效避免因物体外观相似而导致的误检测,并能很好地处理因季节差异或土地覆被变化引起的无关变化。然而,目前在处理变化检测中伪变化现象仍存在一些问题。一方面,目前的方法大多没有充分利用不同尺度提取的特征,忽略了不同层特征之间的语义差距,这可能会由于特征的冗余和模糊性而导致伪变化问题。其次,由于成像角度、天气状况、季节变化以及外观非常混乱的物体等原因造成的伪变化仍然难以区分。为此本文设计了一种级联跨尺度网络(Cascaded Cross-Scale Network,CCSNet)来提高模型对伪变化的鲁棒性。本文设计了一种级联连接结构来融合不同尺度的特征,缩小了语义差距。本文提出了一种注意力模块,跨尺度注意模块,来提高特征的辨别能力。CCSNet通过将多尺度特征融合起来,然后使用注意力机制来增强与变化相关语义信息一致的区域,并抑制各种因素引起的虚假变化和噪声,从而达到减少由各种因素而导致的伪变化。
1 CCSNet网络算法
CCSNet网络使用的是编码器和解码器结构,整体流程如图1。在编码阶段,将双时态图像输入到卷积池化层中,对图像进行缩放,减少计算内存。然后输入到4层的编码器中进行降采样。通过权值共享的孪生编码器编码,得到5个不同阶段的输出特征图。在解码阶段,首先把同一阶段的两个特征图进行差分操作来得到差分特征图。其次把编码器4的差值特征图和编码器3的差值特征图使用级联连接一起输入到解码器4中进行解码,之后重复上一步的操作。经过层层解码,最后把解码器1的输出特征图传递给最终块,得到最终的变化检测图。
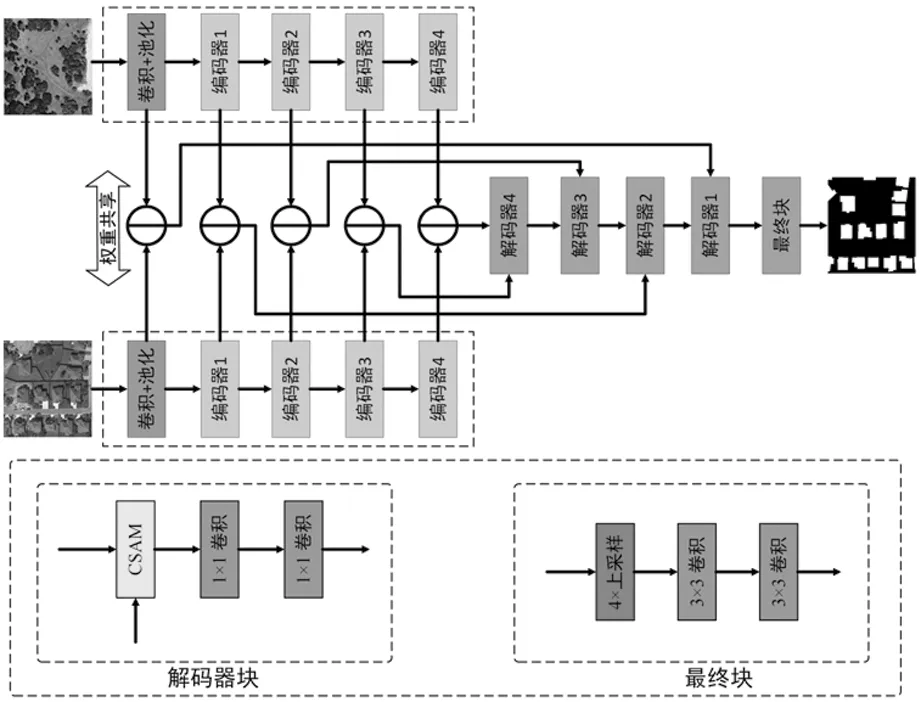
图1 CCSNet网络整体架构
1.1 编码器
卷积神经网络因其强大的特征提取能力而被广泛应用于遥感图像分析。在编码阶段,使用ResNet-34来构建编码器网络。由于变化检测的输入通常是双时相图像,所以编码器网络采用孪生网络结构。具体来说,编码器网络由两个共享可学习权值的编码分支组成。由于ResNet最初是为了解决图像分类问题而提出的,其整体结构可以分为一个卷积池化层、四个降采样卷积层和一个全连接层。但是,最终的变化映射必须恢复到与原始图像完全相同的大小。因此,省略了全连接层。
1.2 解码器
在解码阶段,所提出的结构由四个解码器和一个最终块组成,它们对应于四个编码器和卷积池化层。具体来说,四个解码器具有相同的结构,如图2。该解码器包含一个跨尺度注意模块(Cross-Scale Attention Module,CSAM)和两个1×1卷积层。所提出的解码体系结构有不同的实现方式。具体来说,将两个不同尺度的连接特征图使用级联连接输入给一个解码器。例如,将编码器4(深特征)和编码器3(浅特征)提取的特征输入到解码器4中进行进一步学习。这种方式可以更好地融合浅层特征的空间信息和深度特征的语义信息,以补偿特征编码过程中衰落的几何信息,这是检测变化区域的关键。此外,还可以缩小语义差异,并关注与变化信息相关的特征映射区域。因此,得到的最终特征图可以整合不同尺度的特征。解码阶段的最后一部分是最终块。跨尺度注意力模块的整体结构如图2。它由一个4倍的上采样层和两个3×3的卷积层组成。它的功能是最终的变化图恢复到与原图像完全相同的大小。

图2 跨尺度注意力模块的整体结构
1.3 跨尺度注意力模块
将不同编码层获得的浅层与深层特征图融合,有助于恢复在级联特征编码过程中逐渐消失的空间信息。然而,由于多尺度特征之间存在语义差距,不适当的融合可能会引入冗余信息或噪声。它可能会导致过度的分割和意外的模糊表示,这可能会分散模型来区分由于成像角度、天气条件、季节变化和外观非常混乱的物体而引起的伪变化。为了缩小多尺度特征之间的语义差异,使模型对伪变化更具鲁棒性,设计了一个级联跨尺度注意力模块(Cross-Scale Attention Module,CSAM)如图3。CSAM通过通道注意力和空间注意力来融合多尺度特征图。通道注意力可以有效地学习与不同尺度的特征图之间的变化相关的通道,而空间注意力则可以帮助学习已经发生变化的区域。由通道和空间注意力模块学习到的特征图然后被自注意力模块融合,以捕获不同像素之间的依赖关系。CSAM可以更好地融合浅层和深层特征图与变化信息相关的信息,抑制由各种因素而导致的伪变化信息。

(a)图像T1;(b)图像T2;(c)Ground truth; (d) FC-EF; (e) FC-Siam-Diff; (f) FC-Siam-Conc;(g) DTCDSCN;(h) STANet;(i)BIT;(j) CCSNet。图3 LEVIR-CD数据集上的检测结果可视化
通常来说,特征图中的每个通道的重要程度是相同。但是,对于特定任务来说不同通道的重要性是有所不同的,往往需要对每个通道的重要性进行建模来达到增强或抑制一些通道。在本文中,通道注意力模块(Channel Attention Module,CAM)所采用的是SENet[9]。它首先使用压缩模块对特征图进行全局信息嵌入,然后使用激励模块进行通道关系加权。在变化检测任务中,通道注意力增强与地面特征变化相关的通道,抑制其他不相关的通道。因此,首先使用通道注意力减少浅层特征图和深层特征图之间的语义差距,增强它们之间与变化相关的语义信息。
在计算机视觉任务中,图像像素点的识别需要考虑它所在的空间位置。换句话说,不同的像素位置的重要程度是有所区别的。考虑到遥感图像中像素位置的重要程度不同,所以引入空间注意力模块(Spatial Attention Module,SAM)[10]。因为变化检测的输入为双时态图像,所以为了确认双时态图像的那些像素位置与变化相关,那些像素位置与变化无关,这是十分有意义的。而空间注意力可以增加变化像素和不变像素之间的距离差,从而选择对变化信息更敏感的像素位置。
与通道和空间注意力模块不同,自注意力模块(Self-Attention Module,Self-AM)旨在捕获特征图任意两个位置之间的空间依赖关系。它通过对特征图之间的任意两点之间的关系进行建模,来选择性地聚合每个位置的特征。为了更好地识别那两个像素之间位置关系对变化信息更重要,采纳Chen等人提出的位置注意模块[11]。
2 实 验
为了评估本模型对伪变化的有效性,本文在LEVIR-CD数据集进行了对比实验,并使用精度(Precision)、召回率(Recall)、F1值(F1)、交并比(IoU)和总准确率(OA)作为评估模型的指标。本文将所提出的网络与现有先进的变化检测进行对比实验,并进行了可视化比较,从而进一步验证模型对伪变化的性能。
2.1 数据集及实验环境
LEVIR-CD[12]是一个被广泛使用的建筑物变化检测数据集。总有637对分辨率为0.5 m遥感图像。其中每张图像的大小为1 024×1 024像素。该数据集中的双时间图像是使用谷歌Earth API在2002年至2018年期间从美国德克萨斯州18个州的20个不同地点收集的。它主要关注小而密集的建筑增加和建筑拆除。考虑到GPU内存有限和模型训练速度等因素,把1 024×1 024的图像对裁剪为256×256的没有重叠图像对。最终,LEVIR-CD数据集的训练集、验证集、测试集大小分别为 7 120、1 024、2 048。
模型搭建和网络训练都是用PyTorch实现的,并使用单个 48GB 内存 NVIDIA RTX A6000 GPU 进行训练。由于原图像的分辨率太大和显卡内存有限,将所有输入图像对都被裁剪成256×256不重叠的补丁。使用随机翻转、随机旋转、随机裁剪和高斯模糊等数据增强方式来丰富数据集和防止模型过拟合。所使用的优化器为动量随机梯度下降(SGD),并将动量设置为 0.9,权重衰减设置为 0.000 5。初始学习率设置为 0.01,batch size 设置为 8,训练总轮数设置为 200。
2.2 实验结果分析
2.2.1 对比实验
为了评估整体性能,将本文的CCSNet与其他先进的方法,例如FC-EF[13]、FC-Siam-Diff[13]、FC-Siam-Conc[13]、DTCDSCN[14]、STANet[12]和BIT[8],在LEVIR-CD数据集上进行了对比实验。实验结果的定性和定量结果见表1和图3。
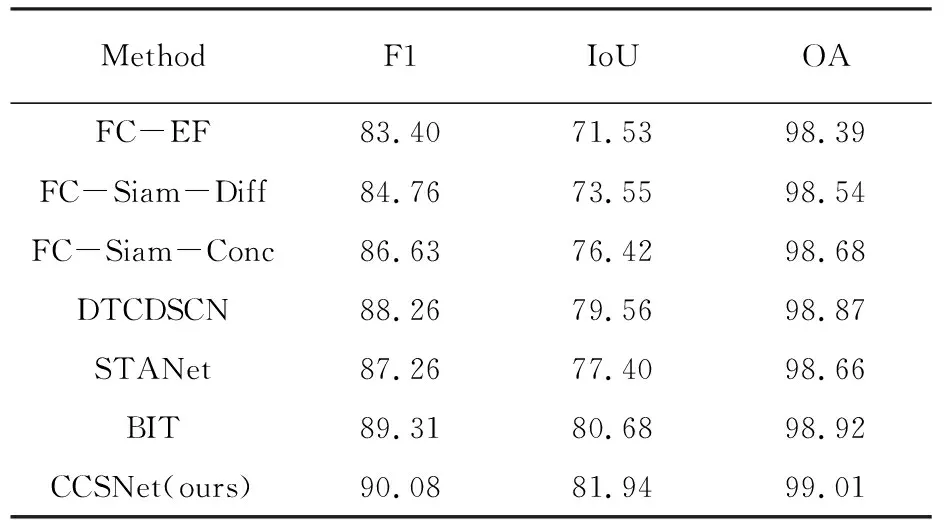
表1 LEVIR-CD数据集上的变化检测性能比较 %
从表1的定量分析表明,根据F1、IoU和OA等指标,CCSNet的表现优于其他CD方法。在LEVIR-CD数据集上,CCSNet在精度、F1、IoU和OA四个指标中都达到了最优的结果。与最新的方法BIT相比,CCSNet的F1值、IoU和OA分别提高了 0.77%、1.26%、0.09%。
图3展示了CCSNet与其他模型在LECIR-CD数据集上的可视化结果。从图中可以更加直观地比较本文的模型与其他模型的性能。为了更好地分析模型的性能,在生成的变化图中使用白色表示正确预测的变化像素(TP),黑色表示正确预测的不变像素(TN),红色表示错误预测的不变像素(FP),绿色表示真实变化像素的漏检(FN)。从图中可以观察到,CCSNet在LEVIR-CD数据集上都取得了令人满意的结果。
如图3的第一行图像所示,它是不同模型在小而稀疏的建筑情况下所得到的结果。从中可以观测到,FC系列的模型都将游泳池区域错误分类为建筑更改。而CCSNet以及DTCDSCN、STANet和BIT都能正确识别。这是因为所提出的跨尺度注意力模块可以很好地整合浅层特征图中与深层特征图一致的区域,并抑制不必要的特征表达和噪声。如图3的第二行图像所示,它是比较了在大型建筑的情况。从中可以看出其他模型未能很好地检测出右上角细长的条形建筑物,且主要建筑物的检测结果存在孔洞或边界不完整。尽管STANet可以检测到它们,但它们要么在其他地方进行错误检测(FP),要么漏检(FN),导致建筑物边界不完整。本文的模型是唯一一个不仅检测出了右上角的长条形建筑物,而且获得了主体建筑物完整边界的模型。从图3的第三行图像看出,是模型在小目标变化的情况。其他模型要么未能检测到左下角的建筑物,要么错误地检测到树木的树冠引起的变化。相反,本文的模型成功地避免了这两个问题,这说明本文的模型能够区分由树木覆盖引起的伪变化。从图3的最后一行图像看出,模型在小而密集的建筑群下的检测结果。许多模型在处理密集分布的小型建筑物时都出现了不同程度漏检情况,而本文的模型和BIT的检测相对完整。
2.2.2 消融实验
为了验证CSAM的有效性,在设计的CSAM中对不同组合结构进行了消融实验,并在LEVIR-CD数据集上进行了对比分析。BASE 模型是 CCSNet的变体,是由一个基于 ResNet的孪生编码器和一个去掉了 CSAM解码器组成。消融实验在LEVIR-CD 数据集上的具体量化结果见表2。从表中可以清楚地观察到 BASE模型的测试结果是最低的。这是因为 BASE模型是最简单的,并且没有包含 CSAM。将CAM、 SAM或Self-AM分别插入到 BASE中,可以显著提高检测性能,取得的F1值、 IoU和OA均表明了这一点。其中,“BASE + CAM”模型在F1值、IOU和OA指标上取得了最好的成绩,在 LEVIR-CD数据集上分别提升了7.47%、 1.46% 和 0.82%。此外,为了进一步验证CSAM 中所使用结构的有效性,还对任意两个注意力模块的组合情况进行了实验。从表2可以看出,“BASE +CAM + Self-AM”组合的性能最好,其中F1值、 IOU 和OA分别达到89.83%、 81.54% 和98.98%。“BASE + CAM + SAM”的性能次之。通过将 CAM、SAM和Self-AM与 BASE模型集成,得到的CSAM模型获得了最好的变化检测结果,在LEVIR-CD数据集上的F1值提高了8.13%,IOU提高了12.53%,OA提高了0.88%。从表2的量化结果可以看出,CSAM 中CAM、 SAM和Self-AM 的每个注意力模块都对变化特征学习有贡献。本文提出的CSAM通过融合他们来处理不同类型的噪声可能导致的伪变化,进一步提高了检测性能。

表2 不同注意力模块组合在LEVIR-CD数据集上的消融结果
3 结 语
提出了一个用于高分辨率遥感图像的变化检的级联跨尺度网络。设计了一种级联连接结构,将不同层的浅层和深度特征映射一起输入解码器。此外,将编码器提取的浅层特征图连续输入解码器,以缩小浅层特征和深层特征之间的语义差距。CSAM使网络能够在通道维度、空间位置和不同像素之间的依赖性三个角度优化浅层特征,从而增强与深层特征映射的一致性语义信息,抑制其他不必要的特征表达和噪声。当在LEVIR-CD数据集上进行评估时,所提出的CCSNet优于其他最先进的方法。实验结果表明:所提出的CSAM可以很好地保持不同尺度下特征映射之间的语义一致性,提高了模型对伪变化的鲁棒性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
河北地质(2021年1期)2021-07-21
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
中国生物医学工程学报(2019年5期)2019-07-16
成都信息工程大学学报(2018年3期)2018-08-29
中南林业科技大学学报(2017年12期)2017-12-19
电子设计工程(2017年20期)2017-02-10
太空探索(2016年5期)2016-07-12
电子器件(2015年5期)2015-12-29
时代英语·高三(2014年5期)2014-08-26
