
新水文地理数据集的研究与应用
——以洞庭湖水系为例
2023-07-04 01:39:36黄泽群廖春花陈玉贵陈唯天赵恩榕罗红梅谢睿恒
灌溉排水学报 2023年6期
黄泽群,廖春花*,陈玉贵,陈唯天,赵恩榕,罗红梅,谢睿恒
(1.湖南省气象服务中心,长沙 410118;2.气象防灾减灾湖南省重点实验室,长沙 410118;3.中山大学 大气科学学院,广东 珠海 519082;4.广东省气候变化与自然灾害研究重点实验室,广州 510275;5.湖南省气象台,长沙 410118)
0 引 言1
在全球变暖的大背景下,随着人类活动的日益影响,暴雨和洪涝等自然灾害的频率逐渐增多[1-3],这些自然灾害给社会经济发展带来很大的不确定性和风险[4]。【研究意义】水文地理参数(流向、河网和流域面积等)在许多水文气象领域的研究与应用方面起着重要作用,如水文模型的建模,地形地貌的分类,水库电站的调度,防灾减灾系统的构架等。其中水文模型对流域的汇流参数具有很强的敏感性[5-8]。同一研究区域中使用不同质量的水文参数得出的水文学基本规律和理论可能具有很大的差异性。然而,大多数高分辨率的水文参数数据集不能通过直接测量获得,必须通过高分辨率的数字高程模型(DEM,Digital Elevation Model)来提取[9]。【切入点】通过DEM 分析提取地表水流方向,可以描绘出许多水文参数,例如集水区边界、流域面积、水流距离和河道宽度等。【研究进展】目前全球主流的DEM 数据主要有SRTM3(Shuttle Radar Topography Mission 3 DEM)[10]、TanDEM-X DEM(TerraSAR-X add-on for Digital Elevation Measurements )[11]、ASTER GDEM(Advanced Spaceborne Thermal Emission and Reflection Radiometer-Global DEM)[12]和 AW3D(Advanced Land Observing Satellite World 3D DEM)[13]等。【拟解决的关键问题】这些DEM 在全球不同的区域范围内存在着观测误差(特别是垂直方向上),会极大地干扰地形的坡度计算和流向的分配,进而影响整个水文地理参数集的质量。
迄今为止,基于SRTM3 开发的HydroSHEDS是使用范围最广,用户人数最多的水文地理参数数据集[14]。但HydroSHEDS 也存在以下几个缺点:①在森林地区,中小河流的位置在HydroSHEDS 中没有很好地表示,这是因为DEM 高程中存在树高误差。②HydroSHEDS 中大型水体的流向分配存在错误,特别在内陆河流和湖泊中表现较为明显。③受到SRTM3 DEM 的范围限制,HydroSHEDS 的覆盖范围被限制在60°N 以下,未实现高纬度地区的覆盖[15-16]。④HydroSHEDS 数据集的发布时间距今已超过10 a以上,受自然环境和人类活动影响,部分水文参数可能已经发生改变,如河流改道,河水干枯断流和地形地貌发生变化等。为此,Yamazaki 等[14]于2017 年发布了的1 套高精度(约90 m 分辨率)的全球范围的数字高程模型(MERIT DEM,Multi-Error-Removed Improved-Terrain DEM),该DEM 通过一系列的拼接和过滤技术,消除了复合误差,能够较好的反应研究区域的高程信息。本研究以MERIT DEM 为基础,通过GIS 信息系统软件和python 程序的自动校正等手段,生产了1 套覆盖洞庭湖水系的水文地理参数集(流向、汇流累积量、河网、流域面积、河长等),通过数据的对比分析和模型验证的方法来说明新数据集的质量,为之后的洪水模拟和预报工作提供有力的数据支撑。
1 研究区域、数据及方法
1.1 研究区域概况
洞庭湖水系位于长江中游南岸,是洞庭湖和入湖的湘江、资水、沅江、澧水(简称“四水”)和汨罗江等水系的总称。洞庭湖水系河网密布,水资源丰富,流域总面积约为26.28 万km2,占湖南省国土面积的95%以上。地形上,洞庭湖水系三面环山,北部以平原、湖泊为主,中部丘陵山地起伏,呈西高东低、南高北低的地势[17]。
1.2 研究数据
MERIT DEM 是一套高精度(3″,约90 m 分辨率)的全球范围(85°N—60°S)DEM。该DEM 以SRTM3 DEM、AW3D DEM 和VFP-DEM 为基础,通过一系列的误差过滤技术消除了条纹噪声、斑点噪声、绝对偏差和植被高度偏差[14],能够有效降低后期生产的水文参数(如流向、坡度等)的不确定性,最大限度地保护河网的整体结构。
HydroSHEDS 是在SRTM DEM 的基础上,进行了算法的改进而得到1 套高精度(3″,约90 m 分辨率)的全球范围(60°N—56°S)DEM。该DEM 经过用户多年的使用和检验,已成为目前全球使用最广泛的数字高程模型之一。尽管在一些陡峭的山脉和水体之间存在着测量误差,并且在森林区域存在树高误差,但是在全球大部分地区能够较好的保证河流的整体结构。
1.3 研究方法
本文以90 m 分辨率的MERIT DEM 为基础,通过地理信息系统软件(ArcGIS)和Python 程序的自动校正等手段,得到了一系列的水文汇流参数(流向、汇流累积量、河网、流域面积、河长和流域分区等)。数据评估方面,先是对比了 2 套数据的数据源(MERIT DEM 和HydroSHEDS DEM)以及提取的流向占比,之后通过河网整体结构的视觉评估,流域面积和河长的对比分析等方法验证了新水文地理数据集(MERIT)的质量。评估的指标为相对误差(Relative Error)、平均相对误差(Mean Relative Error)和均方根误差(Root Mean Squared Error),计算式为:
式中:Mi表示由MERIT 得到的参数值;Hi表示由HydroSHEDS 得到的参数值;N表示对比的参数值个数。
本研究使用的模型(DRIVE, Dominant River Tracing-Routing Integrated with VIC Environment Model)是陆面过程与水文过程耦合的分布式水文模型[16],其中产流模型选用的是分布式大尺度水文模型VIC (Variable Infiltration Capacity Macroscale Hydrologic Model)模型,汇流模型是DRTR(Dominant River Tracing based Routing Model)模型。可变下渗容量大尺度水文模型(VIC)是一个开源的,基于水量热量平衡、物理动力机理的概念型大尺度分布式水文模型。该模型最初是由华盛顿大学、加利福尼亚大学伯克利分校和普林斯顿大学的研究人员基于Liang等[5]的思想共同研制出来的水文模型。DRTR 模型,全称Dominant River Tracing based Routing Model,水文网络自动升尺度化汇流模型,是基于Wu 等[6]提出的升尺度化算法(DRT)发展而来。相关计算式为:
式中:t表示时间(s);x为纵向流动距离(m);A指的是水面下河道的横截面积(m2);P为截面的周长(m);Sf为摩擦斜率,主要影响因素包括重力、摩擦力、惯性力等。如果地形很陡峭,重力将占主导地位,Sf可以近似为河道底部斜率S0,这是汇流方法中运动波方程的基本假设。n为曼宁粗糙度系数,其不能够通过直接测量获得,但主要由表面粗糙度,底部材料的类型和河道的弯曲度决定。Q为流量(m3/s),qL为横向流量(m3/s)。
模型的试验范围为整个洞庭湖水系流域(共26.28 万km2)。模型运行的时间段为2000 年1 月1日0 时到2020 年1 月1 日0 时,共20 a,时间步长为3 h。由于水文站点的观测数据限制,模型的评估阶段为2017 年1 月1 日0 时—2020 年1 月1 日0 时,共4 a。模型的输入数据除比较的2 套数据集(MERIT和HydroSHEDS)不同外,其他的输入参数均为同1 套数据。其中降水数据均为IMERG(Integrated Multi-satellitE Retrievals for GPM),温度和风速来自于 NASA (National Aeronautics and Space Administration)的MERRA(Modern-Era Retrospective analysis for Research and Applications)数据。土壤和植被参数则由美国普林斯顿大学的贾斯汀·谢菲尔德提供。模型的评估指标为纳什系数(Nash-Sutcliffe efficiency coefficient, NSE)。NSE越接近1,表示模型的模拟效果越好,可信度越高。
2 结果与分析
2.1 数字高程模型的对比
数字高程模型(DEM)是大部分水文基本参数(如河流流向等)的数据源。为分析MERIT DEM 与HydroSHEDS DEM 的差异,将精度同为90 m 的MERIT DEM 高程值减去HydroSHEDS DEM 的高程值,得到的结果如图1 所示。从图1 可以看出,MERIT DEM 的平均高程要低于HydroSHEDS DEM,主要原因是MERIT DEM 消除了复合误差(特别是植被高度),且在海拔较高的区域(如武陵山脉、雪峰山和南岭山脉等)尤为明显,而在地形平坦的区域(如洞庭湖区域)差距较小。2 套DEM 高程的平均相对误差(MRE)为3.57 m,均方根误差(RMSE)为9.12 m。本研究还分析了高程差(d)的绝对值在不同阈值范围的占比情况(图2),阈值分别为5、10、15 m和20 m。从图2 可以看出,高程差的绝对值主要集中在0~5 m 的范围内,占总数的72.29%,其次是5~10 m 的区间,占比为26.24%,而高程差大于20 m 的栅格数量仅为0.39%。这说明2 套DEM 数据还是存在着一定的差别,特别是在部分地势较高的地区有着显著的差异。这些差异会影响后续河流流向、河网和流域面积等参数的提取。
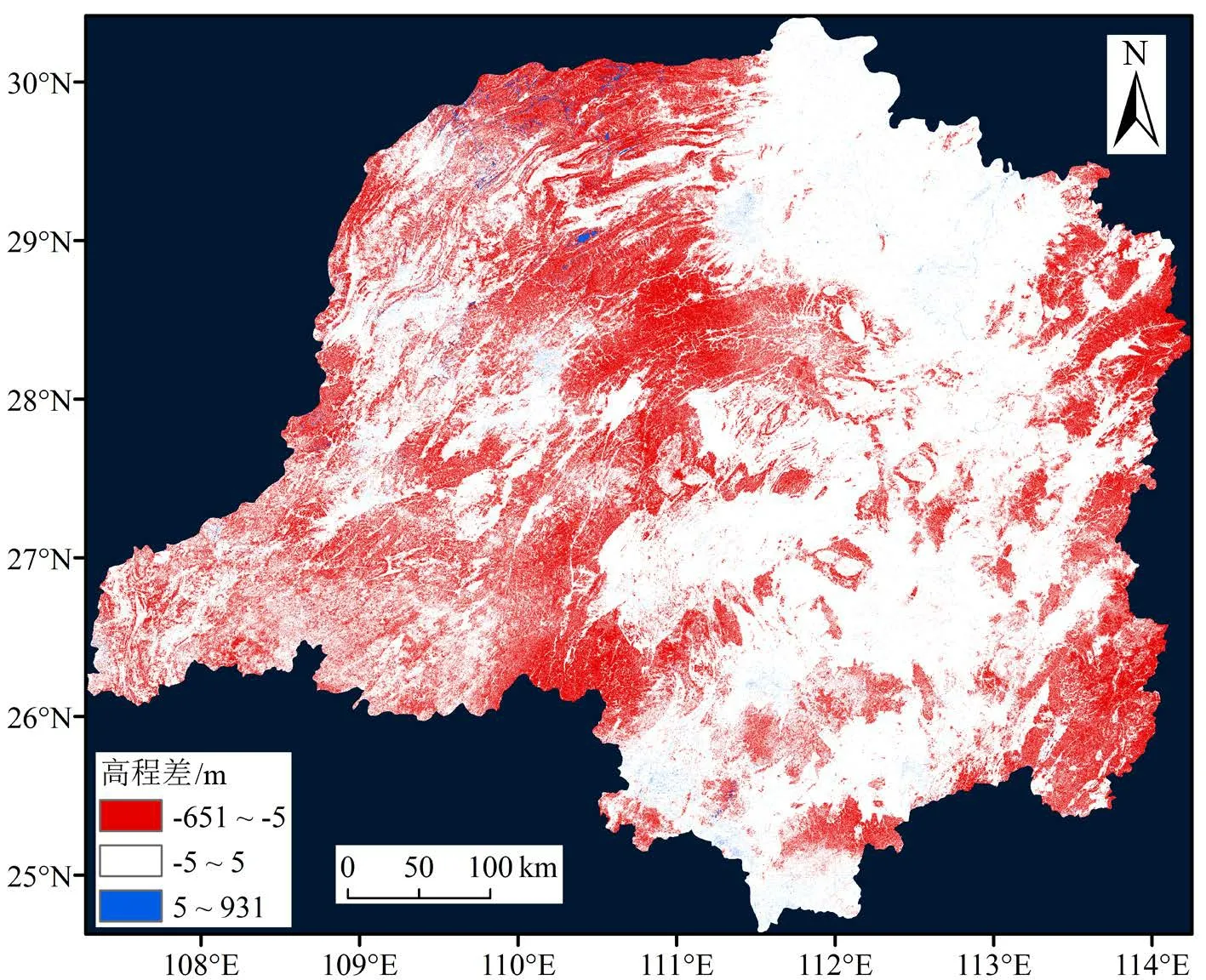
图1 MERIT DEM 和HydroSHEDS DEM 的高程差Fig.1 Differences between MERIT and HydroSHEDS DEM
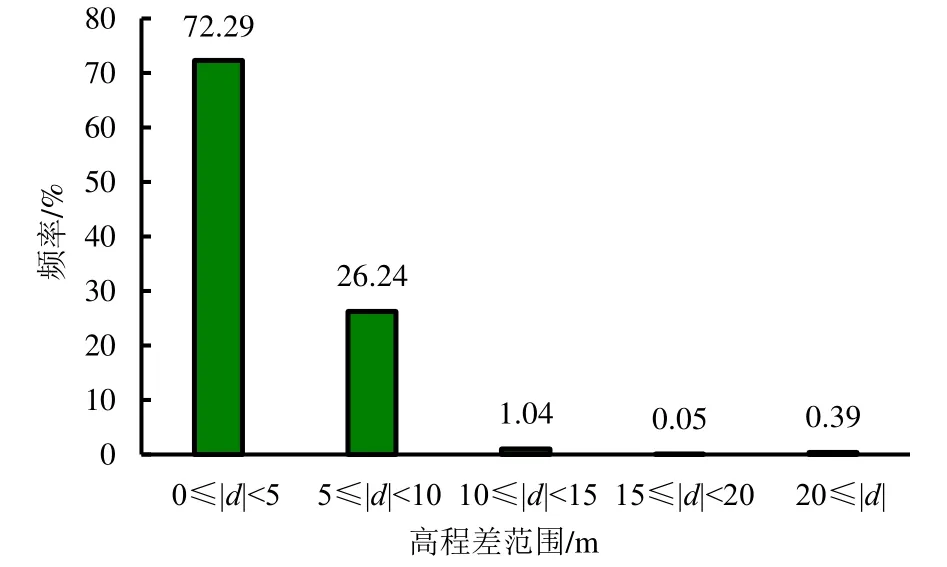
图2 高程差直方图Fig.2 Average errors between MERIT and HydroSHEDS DEM
2.2 流向的评估
流向是指河道中的水流从当前栅格流向下一个栅格的方向[18],是生成许多水文汇流参数的基础(如汇流累积量和河网等)。本研究采用的是D8 算法,对比了基于不同的DEM 生成的2 套流向数据(图3)。结果显示HydroSHEDS 的流向中,东、南、西、北4个方向偏多一些,其中正南方向的栅格数量最多,占总栅格数的15.7%,而MERIT 的流向则是东北、东南、西南和西北4 个方向多一些,其中东南方向的栅格数量最多,占总栅格数的19.8%。造成这种差异的原因主要是:不同数据源的卫星产品(DEM)存在着差异,且在流向分布上的表现会更为明显。流向的这些差异必然会影响到河网数据的提取。
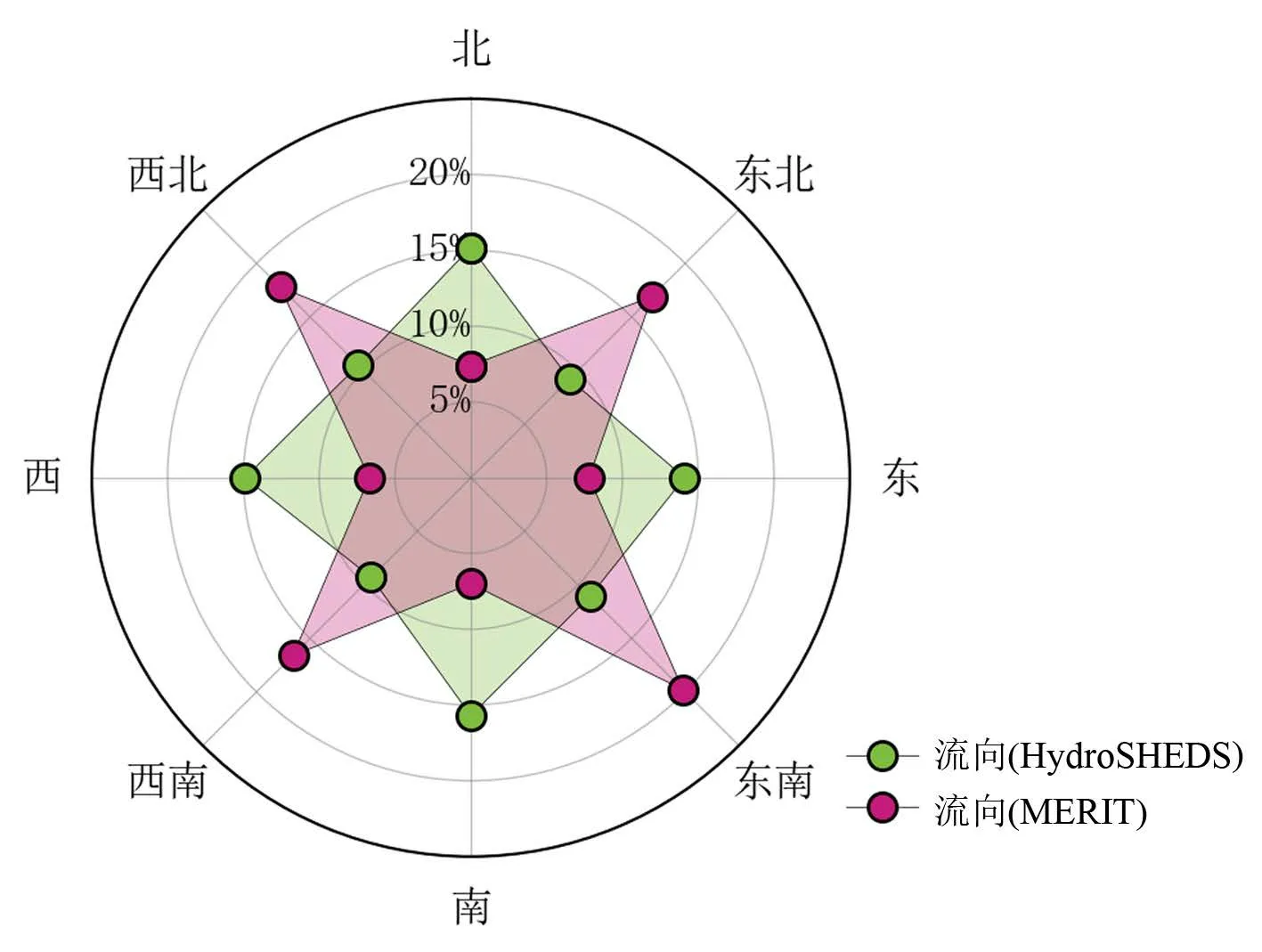
图3 不同的流向占比Fig.3 Proportion of different flow direction
2.3 河网的可视化评估
河网的可视化分析是一种最直接的评估方法。图4 展示了2 套数据的河网在洞庭湖水系范围内的整体结构,河网的提取阈值均为50 km2。从图4 可以看出,2 套河网数据在大部分地区基本重合,但在少数区域(如洞庭湖区)存在着较大的差异,这是因为该区域湖泊众多,地势平坦,D8 算法在湖泊等特殊地理区域的流向提取方面存在着一定的局限性。本研究选取了3 个区域进行放大(即图4 中的a、b、c),用来和谷歌高清卫星影像进行对比,结果如图5 所示。图5中红色的河网(MERIT)在河道的蜿蜒曲折部分(虚线框内)更加贴近于真实的河道,说明MERIT 生成的河网在一定程度上要好于HydroSHEDS 的河网。
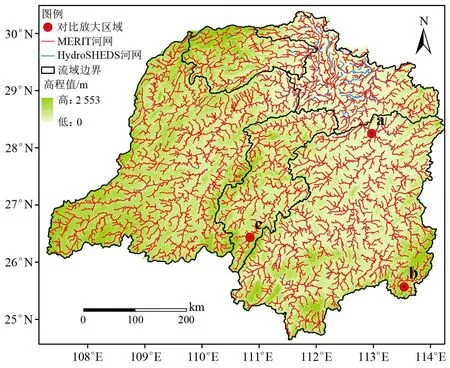
图4 MERIT 和HydroSHEDS 的河网对比Fig.4 Comparison of MERIT and HydroSHEDS’river network map
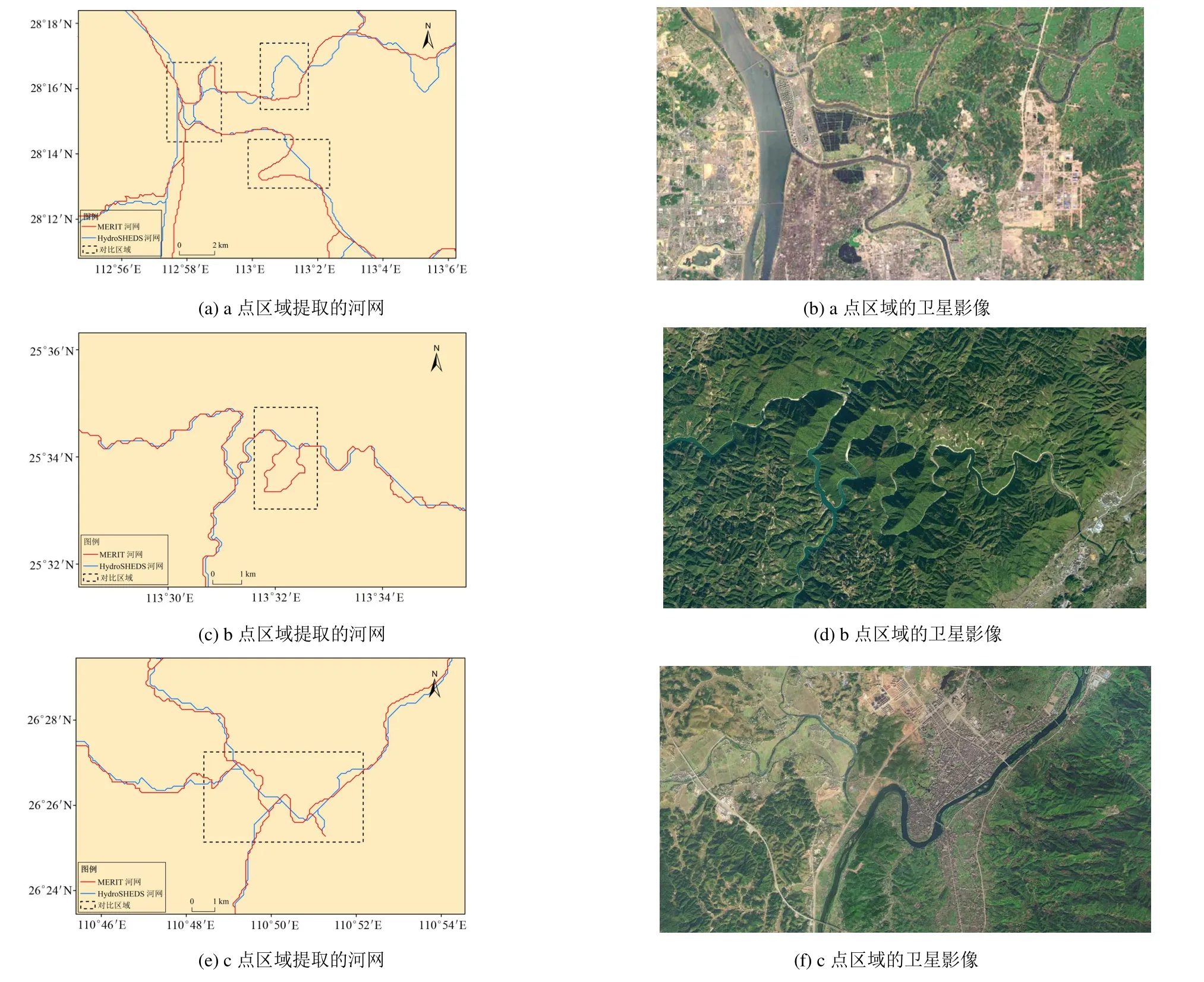
图5 2 套数据的河网与谷歌影像中的河道对比Fig.5 Differences between two datasets and Google map in river networks
2.4 流域面积和河流长度的对比分析
流域面积和河流长度是评估河网整体结构的重要汇流参数[19]。本研究评估了2 套数据在洞庭湖水系及“四水”(湘江、资水、沅江和澧水)的流域面积。由表1 可知,MERIT 和HydroSHEDS 在湘江和资水的流域面积差异较小,其中资水流域的面积差约为0.24 km2,相对误差不足0.01%。“四水”中相对误差最大出现在澧水流域,面积差约为409.52 km2,相对误差为2.2%。所有流域的相对误差都小于3%,说明MERIT 和HydroSHEDS 的2 套数据在流域面积方面差异较小。河流长度评估方面,将洞庭湖水系的所有河流都设定长度阈值,分别为10、25、50、75 km 和100 km。由表2 可得,MERIT 提取的河流条数由44到526 条不等,HydroSHEDS 提取的河流条数由35~492 条不等,说明从MERIT 中提取的河流数量要大于HydroSHEDS。
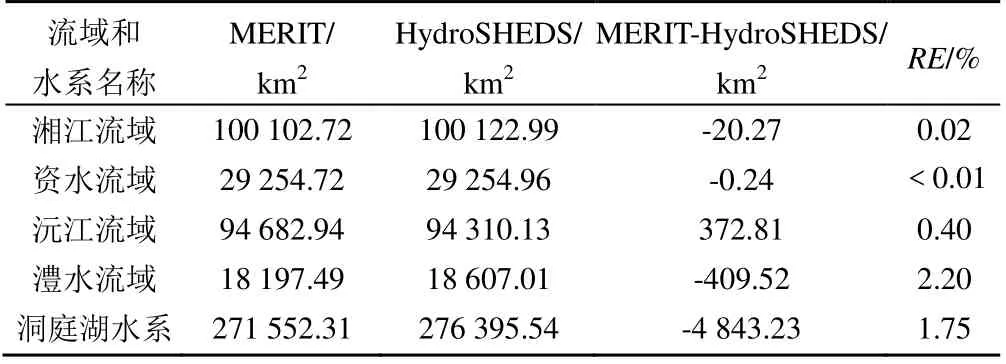
表1 流域面积的评估结果Table 1 Assessment results of derived basin area

表2 河流长度的评估结果Table 2 Assessment results of derived flow distance
2.5 水文模型的验证
为了更好地比较2 套数据的质量,本研究验证了不同数据集在DRIVE 模型径流量模拟方面的效果。结果显示,使用MERIT 为输入数据的平均日纳什系数为0.41,月纳什系数为0.52,而使用HydroSHEDS的日纳什系数为0.37,月纳什系数为0.5,说明MERIT数据集的整体质量要好于HydroSHEDS。各站点的日纳什系数的空间分布如图6 所示,其中红色圆点(共 30 个站点)代表MERIT 日纳什系数高于HydroSHEDS 的站点,绿色圆点(共15 个站点)代表HydroSHEDS 日纳什系数高于MERIT 的站点。
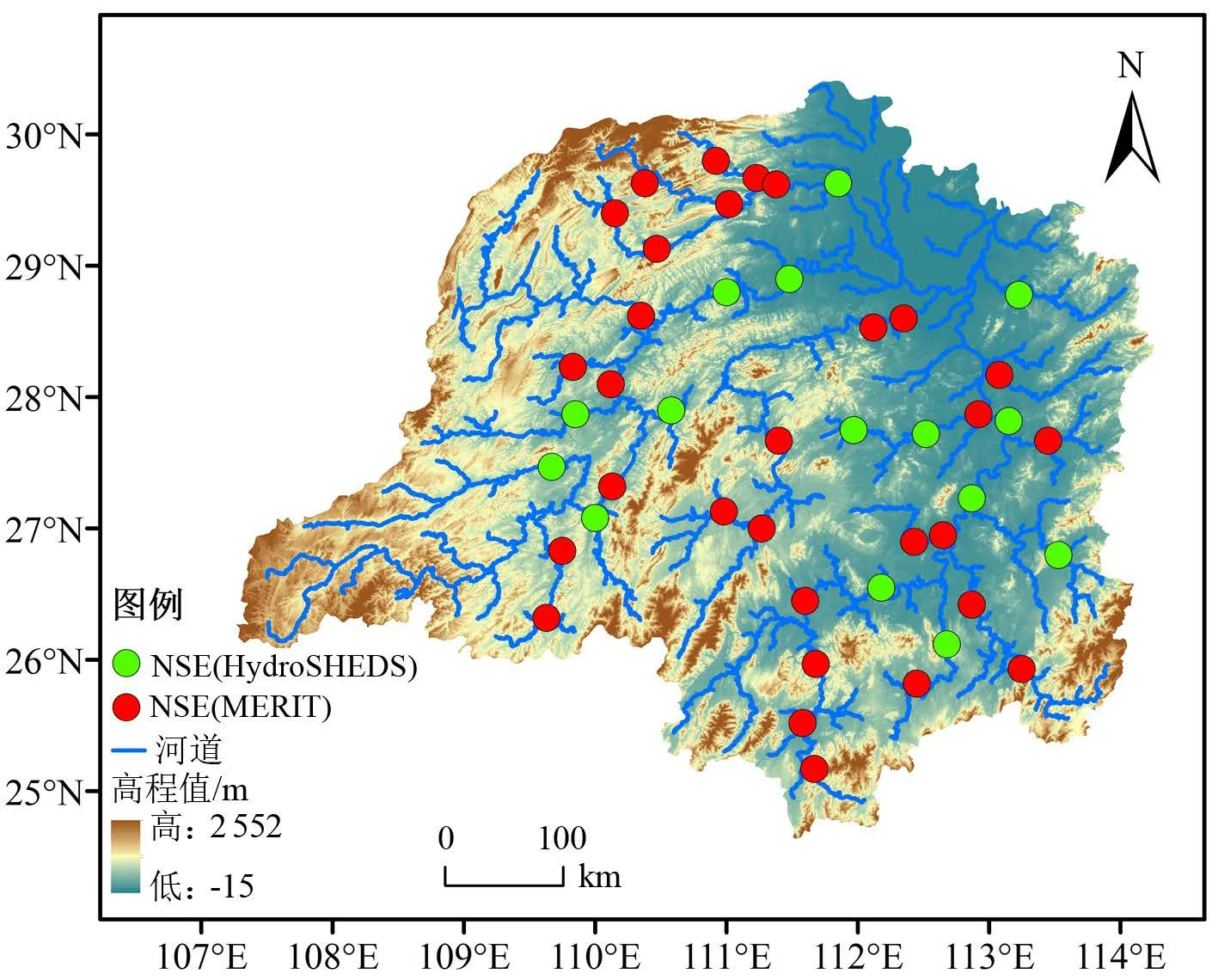
图6 日纳什系数值在洞庭湖水系上的空间分布Fig.6 Spatial distribution of Nash coefficient values in Dongting river basin
造成上述差异的主要原因是MERIT 能更好地反映河道的弯曲程度,更加贴近实际的河流情况,而HydroSHEDS 在部分地区(特别是中小河流)的河道更加笔直,这样会造成河流长度小于MEIRT,从而导致模型计算的径流量和流速的偏大。同时实验显示纳什系数较好的站点主要集中在河道的上游区域,这主要是因为上游的径流受水库大坝的调控影响较小,更符合原始自然地貌的流域景观。
2.6 基于MERIT 数据集的流域划分
流域分区在水文模拟、水旱灾害防御调度和水资源评估等方面起着重要作用。因为基于MERIT 提取的河网数据集比HydroSHEDS 的更加精准,所以以MERIT 数据集为基础,将整个洞庭湖水系划分为4个等级(图7):Ⅰ级为5 个子流域,Ⅱ级为22 个子流域,Ⅲ级为58 个子流域,Ⅳ级为3 383 个子流域。所有子流域都采用字母加编号的方式命名(表3),字母代表所属的Ⅰ级流域(如湘江的Ⅰ到Ⅳ级流域字母均为X,资水的Ⅰ到Ⅳ级流域字母均为Z),数字代表子流域编号,数字的位数代表Ⅰ到Ⅳ级,湘江流域Ⅰ级为X1,Ⅱ级为X01 到X06,Ⅲ级为X001 到X016,Ⅳ级为X0001 到X1390。

表3 洞庭湖水系流域分区命名Table 3 Name for division of Dongting basin
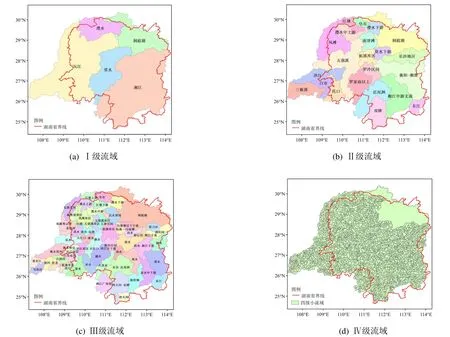
图7 洞庭湖水系的流域划分Fig.7 Division of Dongting basin
3 讨 论
尽管新生成的水文地理数据集能够满足水文气象行业服务的基本需求,降低水文模拟的参数不确定性,但仍然存在着一些缺陷和不足。
在算法方面,新数据集基于单流向算法(D8),对流向的数据质量要求较高,需要一定量的手动校正才能有效地避免在地势较为平坦的区域产生“平行伪河道”,但这在大范围的研究区域下难以实现,时间成本较高。同时,单流向算法无法准确描绘出三角洲处河流分叉的现象,进而影响洪水预报和风险评估的成果。多流向法算法(Multi-Flow Directions)中的Dinf(D infinity)算法是在3×3 的栅格中,中心栅格与其周围8 个栅格形成8 个平面三角形,分别计算出每一个三角形的坡度,然后以最大三角形坡度作为中心栅格的坡度,该三角形的坡向即为中心栅格的流向,最大坡度的三角形所确定的2 个下游栅格作为流量的分配单元。该算法虽然能够解决三角洲处河流分叉的问题,但是因为其算法较为复杂,且运算时间成本较高,无法适应分辨率较高的科学研究和实践应用。在评估方面,本研究也存在几点不足:①局限于单一水文模型的评估,今后可以尝试不同的水文模型,如LISFLOOD 和CaMa-Flood 模型等,因为不同的水文模型可能会对同一套水文地理数据集产生模拟的差异性。②还应该进行参数率定工作,找到参数的最优解,提高模拟结果的质量。③一些大型的分布式水文模型,输入数据还包括河宽和湖泊等参数,目前的数据集还无法满足这些要求。④受人类活动的影响,新数据集无法体现出人工开凿的河道,需要基于最新的遥感影像资料进行一定量的手动校正,才能保证其结构的合理性。这些缺陷和不足都迫使新水文地理数据集还需进一步的更新和升级。
4 结 论
基于MEIRT DEM 提取的新水文地理数据虽然在流域面积部分和HydroSHEDS 数据结果相差不大,但在DEM 高程、流向的分布方面存在着较大的差异,MERIT 更好地保证了河网的整体结构(特别是河道的蜿蜒曲折部分),从而保证了河流长度等其他参数计算的准确性。在水文模型评估方面,MERIT 数据集的日纳什系数为0.41,月纳什系数为0.52,均优于HydroSHEDS 数据集。同时,基于新数据集将洞庭湖水系按流域划分为4 个等级,其中Ⅰ级为5 个子流域,Ⅱ级为22 个子流域,Ⅲ级为58 个子流域,Ⅳ级为3 383 个子流域。新数据集有助于提升分布式水文模型的模拟结果,促进相关领域的科学研究,推进中高端专业水文气象服务的发展。
(作者声明本文无实际或潜在的利益冲突)
猜你喜欢
水科学进展(2023年4期)2023-10-07 11:23:44
小学生学习指导(低年级)(2021年10期)2021-11-01 08:22:58
井冈教育(2020年6期)2020-12-14 03:04:42
金桥(2020年8期)2020-05-22 06:22:54
华东师范大学学报(自然科学版)(2019年3期)2019-06-24 05:29:09
水利科技与经济(2017年5期)2017-04-22 02:39:28
股市动态分析(2016年3期)2016-09-27 16:31:48
音乐天地(音乐创作版)(2016年4期)2016-07-28 09:39:37
水利科技与经济(2016年9期)2016-04-22 01:07:22
林业与生态(2016年3期)2016-02-27 14:24:22
