
基于改进Tiny YOLOv3的交通标志检测方法
2023-07-03 08:23郑海波宋爽刘同海
天津农学院学报 2023年2期
郑海波,宋爽,刘同海
基于改进Tiny YOLOv3的交通标志检测方法
郑海波,宋爽,刘同海通信作者
(天津农学院 计算机与信息工程学院,天津 300392)
针对智能驾驶场景下的小尺寸交通标志检测准确率不高的问题,提出一种基于Tiny YOLOv3网络的交通标志检测算法。通过使用深度可分离卷积重构特征提取网络和增加浅层与深层特征层之间的特征融合,提高模型对小目标的注意力;同时修改anchor boxes尺寸,提升预测框的准确度。在TT100K交通标志数据集上的试验结果表明,提出算法的平均精度均值()较Tiny YOLOv3提高了19.3%,对小尺寸交通标志检测具有更强的鲁棒性。
交通标志检测;深度可分离卷积;特征融合;Tiny YOLOv3
交通标志检测与识别是智能驾驶的核心技术之一,在行车安全中发挥着至关重要的作用。虽然不同形状的交通标志具有不同的作用,常见的有三角形、矩形和圆形等特殊形状,但自然环境下的交通标志检测会受到很多不确定性因素影响,如光照变化、恶劣的天气、遮挡等。另外,在实际的驾驶场景中,交通标志占据每幅图像的比例很小[1],与一般目标相比更难检测。过去,交通标志检测方法通常以颜色[2]、形状[3]等特征以及多种特征相结合[4]来提取图像中的感兴趣区域,具有较强的针对性,但缺乏鲁棒性。如今,基于卷积神经网络的目标检测算法在准确性和泛化性上都远超传统图像处理方法,例如以Faster R-CNN[5]等为代表的两阶段算法和以YOLO[6-8]等为代表的一阶段算法。研究人员基于Faster R-CNN网络构建了交通标志检测模型,检测准确率和推理速度较原始网络有所提升[9-10]。ZHANG等[11]在YOLOv3网络中引入多尺度空间金字塔池化模块,提高了小尺寸交通标志检测性能。该算法在中国交通标志检测基准TT100K[1](Tsinghua-Tencent 100K)上的达到86.3%,但是检测速度仅为23.81 FPS。总体来看,基于卷积神经网络的目标检测算法更具普适性,但在小目标检测和检测速度方面未能取得令人满意的结果。Tiny YOLOv3是对YOLOv3检测算法的简化,拥有更快速度,但检测精度低。因此,本文以Tiny YOLOv3检测算法为基础,提出了一种结合深度可分离卷积和多尺度预测思想的交通标志检测方法。试验结果表明,所提方法有效提高了小尺寸交通标志的检测性能。
1 Tiny YOLOv3算法简介
YOLO检测模型将输入的图像划分为×的网格,每个格子都预测B个边界框,并且每个预测框包含5个预测值(,,,,),其中,,,为预测框的中心坐标和归一化后的长宽值,为该预测框的置信度。置信度的计算如公式(1)所示。
Tiny YOLOv3算法是一个轻量级卷积神经网络,主干特征提取网络由7个卷积层和6个池化层组成。同时,在特征融合网络中使用两个尺度对目标进行预测,通过融合浅层和深层特征加强特征提取能力。首先,将13×13的特征图进行卷积和上采样操作,然后与26×26的特征图通过通道串联形成新的26×26特征图,最终网络输出 13×13和26×26共两个特征图,进行检测框回归和分类。Tiny YOLOv3的网络结构如图1所示。

图1 Tiny YOLOv3网络结构图
2 改进的Tiny YOLOv3算法
2.1 改进主干特征提取网络
Tiny YOLOv3模型的主干网络层次较浅,难以提取出交通标志的高层次语义特征,并且使用池化层会损失较大采样信息,检测精度较低。深度可分离卷积(Depthwise Separable Convolution,DSC)具有较少的网络参数量和更低的运算成本。深度可分离卷积与标准卷积的计算复杂度比值如公式(2)所示。

式中,为卷积核的尺寸;M、N分别为输入通道和输出通道;H和W为输出特征图的长宽。若卷积核尺寸=3,深度可分离卷积的计算量约为标准卷积的1/9。深度可分离卷积的本质是将标准卷积拆分为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution),其原理如图2所示。深度卷积对输入的特征图,使用M个3×3卷积核,一个卷积核对一个通道进行特征提取。经过深度卷积后,特征图的通道数不变。接下来是N个卷积核大小为1×1的逐点卷积对通道数进行调整。
因此,本文提出一种基于深度可分离卷积的Tiny YOLOv3主干特征提取网络,如表1所示。
表1 改进的Tiny YOLOv3主干特征提取网络
类型滤波器数卷积核尺寸输出 Convolutional163×3/1416×416×16 DSC163×3/2208×208×16 Convolutional321×1/1208×208×32 DSC323×3/1208×208×32 Convolutional641×1/1208×208×64 DSC643×3/2104×104×64 Convolutional1281×1/1104×104×128 3×DSC1283×3/1 Convolutional1281×1/1 Residual 104×104×128 DSC1283×3/252×52×128 Convolutional2561×1/152×52×256 3×DSC2563×3/1 Convolutional2561×1/1 Residual 52×52×256 DSC2563×3/226×26×256 Convolutional5121×1/126×26×512 3×DSC5123×3/1 Convolutional5121×1/1 Residual 26×26×512 DSC5123×3/213×13×512 Convolutional1 0241×1/113×13×1 024
在特征提取网络中,使用深度可分离卷积代替3×3卷积核的标准卷积,步长为2的深度可分离卷积代替最大池化层,中间层引入1×1卷积核进行跨通道信息交互,提升网络表达能力。在4倍下采样、8倍下采样和16倍下采样后设置更多层次,并添加残差结构(Residual),避免因卷积层数增加而出现梯度消失的问题。通过增加网络层次加强了语义特征提取,并有效降低模型大小和计算量。
2.2 增强特征融合
Tiny YOLOv3通过特征金字塔融合16倍下采样和32倍下采样的特征层,输出26×26和13×13特征图,以416×416大小的输入图像举例,当图像经过下采样形成26×26的特征图时,输入图像中16 pixel×16 pixel的目标被压缩到一个像素,若输入图像中的交通标志尺寸小于16 pixel×16 pixel,该目标就无法被网络检测到。为提高网络对中小尺寸交通标志的检测能力,本文通过利用网络中浅层特征信息,增强模型对小目标的注意力,改进后的网络结构如图3所示。首先在网络中增加8倍和4倍下采样的特征融合,输出52×52和104×104特征图,收集8 pixel×8 pixel和4 pixel×4 pixel尺度的特征,实现对中小尺寸交通标志检测性能提升。另外,在卷积神经网络中的低层特征中含有大量的位置信息,高层特征中含有丰富的语义信息。从高层到低层的特征融合操作仅实现了语义信息传递,因此继续对104×104特征图进行下采样,与52×52特征图融合,提高对小目标检测和位置信息判断。

图3 改进的Tiny YOLOv3网络结构图
对于实时交通标志检测,其重点是对中远距离交通标志检测,并且远景图片分辨率较高,故删除原网络中尺度为13×13和26×26的预测层,减少计算量。此外,为获得不同尺度的局部特征信息,弥补删除13×13和26×26预测层后近距离交通标志感受野不足的问题,本文在主干网络后使用RFB[12]模块增加浅层特征层的感受野,进而提升网络检测精度。使用416×416的输入图像,改进的Tiny YOLOv3得到52×52和104×104输出特征尺度,提高了交通标志检测的准确性。
2.3 K-means聚类
Tiny YOLOv3网络的初始锚点框(anchor boxes)与交通标志的尺寸差异较大,容易影响目标检测的精度。因此,本文使用函数作为K-means算法的距离度量标准,生成更适合交通标志的anchor boxes,距离函数如式(3)所示。

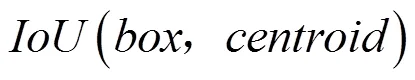
3 试验基本概况
本文进行两个试验,一是选取CCTSDB数据集中不同场景下相似度低、差异性大、分辨率为641 pixel×936 pixel和1 024 pixel×768 pixel的 2 484张图像作为训练集,621张图像作为测试集进行消融试验,验证前文所述方法的提升效果;二是通过迁移学习的方法,利用CCTSDB数据集上训练好的权重,在交通标志尺寸更小、图像分辨率为2 048 pixel×2 048 pixel的TT100K交通标志数据集上与其他目标检测算法对比,验证改进Tiny YOLOv3算法整体结构的优势,其中TT100K的训练集和测试集图像各包含6 105张和3 071张。在目标检测中,小目标、中等目标和大目标在图片中的像素面积分别介于(0,32²)、[32²,96²)和[96²,∞)[14]。然而在TT100K数据集中,41.6%的交通标志的像素小于32 pixel×32 pixel,49.1%的交通标志小于96 pixel×96 pixel,存在大量的中小尺寸交通标志,因此检测难度更大。本文根据交通标志的作用将两个数据集的类别标签都标注为指示标志(Mandatory)、禁止标志(Prohibitory)和警告标志(Warning)。
本文试验在Ubuntu 18.04系统下进行,采用PyTorch 1.5深度学习框架,硬件配置为NVIDIA GeForce GTX 1 080 Ti,11 GB显存。训练过程中参数设置如下:输入大小416×416,采用SGD优化器,初始学习率0.001,动量大小0.937,权重衰减系数0.000 5,学习率用余弦退火衰减策略,通过翻转、平移变换、Mosaic等方法对数据集进行数据增强,批量大小16,最大迭代次数为2 000个epoch,训练至损失收敛则停止训练。
本文通过平均准确率(mean Average Precision,),即各个类别(Average Precision)的平均值和每秒帧率(Frames Per Second,)来评价算法的性能。
4 结果分析
4.1 消融试验
为了验证前文方法的有效性,明确各个改进对于网络性能的影响,本文在CCTSDB数据集上采用不同方法改进Tiny YOLOv3的检测结果如表2所示。
表2 在CCTSDB数据集上的消融试验
基础网络改进主干网络K-means聚类特征融合网络mAP/%模型大小 MB Tiny YOLOv3×××86.533.1 √××89.219.1 ×√×87.933.1 ××√89.151.7 √√×89.319.1 √√√89.936.3
从表中可知,改进的3部分对算法的精度都有所提升。其中,改进主干网络后的模型参数量下降为Tiny YOLOv3的57.7%,且提高了2.7%,可见改进的主干网络更加轻量高效;增强特征融合后的提高了2.6%,但模型的参数量明显增加。K-means聚类anchor boxes之后,在不增加参数量的情况下提升了检测精度。Tiny YOLOv3应用全部改进方案后实现了最佳检测性能,达到了89.9%。综上所述,改进后的Tiny YOLOv3算法性能较原算法有明显提升,说明这些改进策略有利于交通标志检测。
4.2 与其他目标检测算法对比
为了进一步验证改进算法对小尺寸交通标志的检测效果,将改进的Tiny YOLOv3算法与YOLOv3、Tiny YOLOv3、Faster R-CNN[15]、RetinaNet[15]算法在TT100K数据集上的试验结果进行对比。5种算法的检测精度、检测速度和模型大小整体性能对比结果如表3所示。对表中的数据分析可知,改进Tiny YOLOv3算法达到89.18%,相较于YOLOv3、Tiny YOLOv3、Faster R-CNN、RetinaNet分别提升2.95%、19.30%、25.18%、23.02%,并且3种类别交通标志的平均精度分别为89.39%、89.40%和88.76%,均优于其他模型的检测结果。从检测速度上看,改进后的Tiny YOLOv3模型的下降明显,由于特征融合网络改进增加了计算量,导致指标下降,但是仍然能够达到32.6,满足实时检测的要求。
表3 TT100K数据集上与其他检测算法对比
方法类别AP/%mAP/%FPSGPU模型大小/MB Faster R-CNNProhibitory66.7964.007.4TITAN Xp334.0 Mandatory64.83 Warning60.37 RetinaNetProhibitory64.6666.1622.0TITAN Xp245.0 Mandatory63.29 Warning67.49 YOLOv3Prohibitory82.1086.2331.5GTX 1080 Ti235.0 Mandatory88.73 Warning68.98 Tiny YOLOv3Prohibitory70.5169.8890.2GTX 1080 Ti33.1 Mandatory70.15 Warning87.86 本文方法Prohibitory89.3989.1832.6GTX 1080 Ti36.3 Mandatory89.40 Warning88.76
图4为YOLOv3、Tiny YOLOv3和改进Tiny YOLOv3在3类交通标志上的P-R曲线对比图,改进网络的精确率和召回率均优于其他模型。同时,本文对比了3种算法在不同尺寸的交通标志上的检测结果,如表4所示。从表中可以看出,改进后的Tiny YOLOv3对小尺寸和中等尺寸交通标志的检测效果最好,特别是在小尺寸交通标志检测上,相较于Tiny YOLOv3和YOLOv3分别提升了28.5%和9.0%。由此可见,改进后的Tiny YOLOv3模型能够更好地检测中远距离的交通标志。

图4 3种检测网络的P-R曲线分析
表4 TT100K数据集上不同尺寸交通标志的检测结果%
方法AP Small(0,32²)Medium[32²,96²)Large[96²,∞) Tiny YOLOv315.848.573.6 YOLOv335.365.077.7 本文方法44.366.075.8
图5对比了3种算法在高分辨率图像中的交通标志检测效果,改进Tiny YOLOv3算法比其他两种算法对目标框的定位更精确,并且解决了YOLOv3和Tiny YOLOv3算法在远距离、遮挡和阴暗环境下存在的漏检、误检问题。

图5 三种算法的检测效果对比图
5 结论
为解决高分辨率图像中的小尺寸交通标志检测精度低的问题,本文提出了一种基于Tiny YOLOv3的改进算法。其中,引入深度可分离卷积和残差结构加深主干特征提取网络的层次,加强语义特征提取;通过增加浅层与深层特征层之间的特征融合,重构特征融合网络,提高了对小目标的检测性能。试验结果表明,本文提出的算法在TT100K交通标志数据集上的相较于Tiny YOLOv3提升了19.3%,且对小尺寸交通标志检测更具鲁棒性。如何在保证高精度的前提下考虑更多的交通标志类别以及进一步加快网络推理速度,将会是下一步研究的重点。
[1] ZHU Z,LIANG D,ZHANG S,et al. Traffic-sign detection and classification in the wild[C]//IEEE. 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas:IEEE,2016:2110-2118.
[2] LILLO-CASTELLANO J M,MORA-JIMÉNEZ I,FIGUERA-POZUELO C,et al. Traffic sign segmentation and classification using statistical learning methods[J]. Neurocomputing,2015,153:286-299.
[3] XU Z,REN J,BAO C. A Traffic signs' detection method of contour approximation based on concave removal[C]// IEEE. 2016 Chinese Control and Decision Conference. Yinchuan:IEEE,2016:5199-5204.
[4] XU X,JIN J,ZHANG S,et al. Smart data driven traffic sign detection method based on adaptive color threshold and shape symmetry[J]. Future Generation Computer Systems,2019,94:381-391.
[5] REN S,HE K,GIRSHICK R,et al. Faster R-CNN:Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[6] REDMON J,DIVVALA S,GIRSHICK R, et al. You only look once:Unified,real-time object detection[C]//IEEE. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos:IEEE,2016:779-788.
[7] REDMON J,FARHADI A. YOLO9000:better,faster,stronger[C]//IEEE. 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu:IEEE,2017:6517-6525.
[8] REDMON J,FARHADI A. YOLOv3:An incremental improvement[EB/OL].(2018-04-08)[2022-02-07]. https:// arxiv.org/abs/1804.02767.
[9] YANG T,LONG X,SANGAIAH A K,et al. Deep detection network for real-life traffic sign in vehicular networks[J]. Computer Networks,2018,136:95-104.
[10] LI J,WANG Z. Real-time traffic sign recognition based on efficient CNNs in the wild[J]. IEEE Transactions on Intelligent Transportation Systems,2019,20(3):975- 984.
[11] ZHANG H,QIN L,LI J,et al. Real-time detection method for small traffic signs based on Yolov3[J]. IEEE Access,2020,8:64145-64156.
[12] LIU S,HUANG D. Receptive field block net for accurate and fast object detection[C]//European Conference on Computer Vision. Proceedings of the European Conference on Computer Vision. Berlin:Springer,2018:404-419.
[13] ZHANG J,HUANG M,JIN X,et al. A real-time Chinese traffic sign detection algorithm based on modified YOLOv2[J]. Algorithms,2017,10(4):127.
[14] KISANTAL M,WOJNA Z,MURAWSKI J,et al. Augmentation for small object detection[J]. arXiv preprint arXiv,2019,21:47.
[15] 刘胜,马社祥,孟鑫,等. 基于U-Net定位优化的交通标志识别网络[J]. 重庆理工大学学报(自然科学版),2020,34(11):147-155.
Traffic sign detection method based on improved Tiny YOLOv3
Zheng Haibo, Song Shuang, Liu TonghaiCorresponding Author
(College of Computer and Information Engineering, Tianjin Agricultural University, Tianjin 300392, China)
Aiming at the problem of low accuracy of small-size traffic sign detection in intelligent driving scenarios, a traffic sign detection algorithm based on Tiny YOLOv3 network was proposed. By using the depth separable convolutional reconstruction feature extraction network and increasing the feature fusion between the shallow and deep feature layers, the model's attention to small targets could be improved; at the same time, the accuracy of the prediction box was also improved by modifying the size of anchor boxes. The test results on the TT100K traffic sign data set showed that the mean average precision()of the proposed algorithm was 19.3% higher than that of Tiny YOLOv3, and it is more robust to the detection of small-size traffic signs.
traffic sign detection; depth separable convolution; feature fusion; Tiny YOLOv3
1008-5394(2023)02-0062-07
10.19640/j.cnki.jtau.2023.02.013
TP391.41
A
2022-03-07
天津市研究生科研创新项目人工智能专项(2020YJSZXS11);天津市重点研发计划科技支撑重点项目(20YFZCSN00220);中央引导地方科技发展专项(21ZYCGSN00590);内蒙古自治区科学技术厅项目(2020GG0068)
郑海波(1996—),男,硕士在读,主要从事基于深度学习的目标检测和智慧农业方面研究。E-mail:2009028125@stu.tjau.edu.cn。
刘同海(1977—),男,教授,博士,主要从事农业人工智能方面研究。E-mail:tonghai_1227@126.com。
责任编辑:张爱婷
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
小天使·一年级语数英综合(2016年8期)2016-05-14
噪声与振动控制(2015年4期)2015-01-01
小天使·一年级语数英综合(2014年7期)2014-06-26
电视技术(2014年19期)2014-03-11
