
基于YOLOv5手榴弹检测算法的轻量化研究
2023-07-03 02:34沈芸亦吴中红
兵器装备工程学报 2023年6期
邱 锦,刘 健,沈芸亦,吴中红
(海军工程大学兵器工程学院, 武汉 430033)
0 引言
随着人工智能、深度学习等技术的发展,采用就地爆破去清理哑弹(未爆手榴弹)的方法逐渐走向智能化、无人化,排爆机器人、哑弹清理机器人等概念相继被学者们提出,其中,目标检测是利用无人平台实现排爆的基础任务也是关键任务[1]。
目标检测算法的核心是输出物体的类别以及其在图像中的位置,这2个过程也称为分类与回归[2]。基于深度学习的目标检测算法按检测步骤分为单阶段算法和双阶段算法[3]两类。经典的双阶段检测算法有R-CNN[4]、SPP-Net[5],算法的基础流程是先提取图像中可能存在目标的区域生成候选区,然后在候选区域上学习目标特征,即通过2种不同的学习网络将目标分类和回归过程分成两阶段实现,因此,双阶段网络模型参数大,占用存储空间大,具有检测精度高但实时性差的特点。单阶段检测算法在给定一张图像作为输入时,可以端到端输出与输入尺寸相同的检测结果,其使用唯一的主干网络直接生成目标的分类和回归,加快了检测速度但牺牲了部分精度,YOLO算法是经典的单阶段检测算法之一,常常用在实时性要求高的检测任务中,如自动驾驶领域、无人搜救领域。
常用于排爆的无人平台有无人车、无人机、机器人[6-7]等,这些无人工具都需要具有可移动、高移速的特点,在进行完全自主的爆破任务时,要求其嵌入的检测算法在模型大小上尽量轻,同时需要足够好的性能,去满足复杂环境下实时并高精准的获取目标信息,保证无人平台安全、顺利的完成后续任务。
综合分析,本文中选用YOLO算法为基础算法,为实现机器人、无人车等排爆无人平台在复杂环境下(即背景杂乱或存在弹体密集分布、弹体互相遮挡等检测环境)的落地应用,对基于YOLOv5的手榴弹检测算法轻量化改进展开研究。
1 YOLOv5算法基本结构
YOLOv5目前已经更新到6.0版本,官方给出算法在COCO数据集上实验时,其与旧版本算法的性能对比数据如表1所示。相较于上一版本算法,其具体的改动如下:更新了超参数,使用等效的普通卷积取代了Backbone中Focus层,减少了模型参数。沿用了5.0中C3模块,将起到增大感受野作用的SPP模块更新为SPPF(快速空间金字塔池化模块),在未损失性能的前提下,整体减小了模型参数,提高了模型推理速度。结合表1数据可得,6.0版本算法在推理速度上有明显提升。
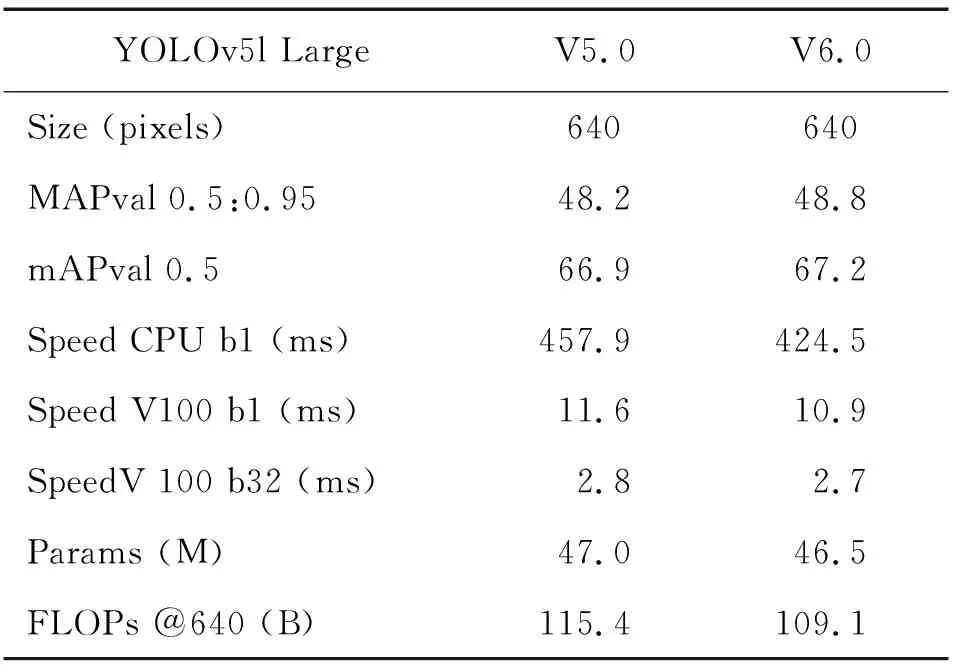
表1 5.0与6.0算法性能对比Table 1 Performance comparison between the 5.0 version algorithm and the 6.0 version algorithm
综上分析,YOLOv5算法虽然已经更新到6.0版本,但相较于5.0版本,其总体结构没有大幅的改进,本文中使用6.0版本中较为轻量的YOLOv5s作为基础检测框架,算法可按实现功能划分为Input、Backbone、Neck、Output四部分,模型完整构架如图1所示。
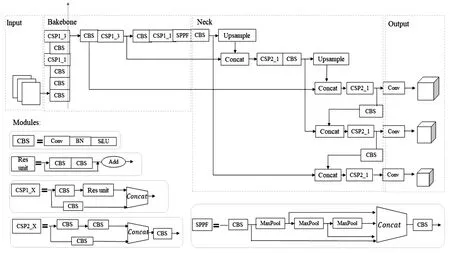
图1 YOLOv5 6.0 的完整网络结构Fig.1 The complete network structure of YOLOv5 6.0
1.1 Input输入端
图片输送到特征提取网络前需要在算法的输入端进行数据增强、统一图片尺寸、自适应锚框计算等三大预处理操作。
YOLO算法在YOLOv4以后一直沿用Mosaic数据增强算法,其核心思想是随机抓取训练集中四张图片,对抓取的图片随机剪裁、随机翻转、随机缩放后拼接得到大图,对拼接后的大图resize、缩放等操作,得到固定尺寸的增强后数据,增强了算法单批处理数据的能力,提高了模型的训练速度,同时丰富了实验训练集、提高了模型的鲁棒性。
YOLO是经典的基于锚框匹配的检测算法,在训练阶段,网络需要在其针对不同数据集,设定特定尺寸(矩形框的长、宽)的初始锚点框的基础上,生成预测框,通过不断计算预测框与真实框的位置、尺寸差距,反向更新其参数去缩小差距,以保证其网络的检测准确率。自适应锚框生成算法即根据输入的数据集,计算与数据集目标尺寸更为匹配的初始锚框,使得网络在初始阶段,能得到更贴合真实检测框大小的预测框,提高训练速度。YOLOv5算法预设的自适应锚框算法为k-means聚类算法以及遗传算法,首先聚类得到锚点框、再通过遗传算法生成变异锚点框,自适应获取更适应数据集的预设锚框。
1.2 Backbone主干网络
网络的Backbone部分通常采用连续下采样操作,自适应学习目标特征信息。YOLOv5中沿用CSPNet(跨阶段局部网络)的思想,搭建以CSPDarknet53为主要结构的特征提取模型,将网络梯度信息的变化反映到特征图中,降低特征图计算的冗余性,同时保证网络获取到丰富的梯度信息,提高了算法的运行效率。
1.3 Neck瓶颈层
图片经过输入端完成预处理后进入到主干网络中提取特征,随后在网络的Neck层完成特征多尺度融合,常用的融合方式如Concat、Add等。YOLO算法中为了能更充分的利用主干网络提取到的特征,在其Backbone和Neck之间插入了SPPF层,增大层间感受野,在其瓶颈层采用经典的FPN+PAN[8]复合结构,实现了特征图的跨层融合,丰富了特征的多样性。
1.4 Output输出端
YOLO的输出层,包含 Bounding box损失计算、NMS非极大值抑制值两大部分,损失函数沿用YOLOv4中的CIOU_Loss,在对生成的目标框筛选时,采用DIOU_nms,在不增加计算成本的前提下,增加了网络的遮挡目标的检测能力。最后用到3个不同尺度的检测头完成对目标的识别与定位,有效的缓解了多尺度检测问题。
2 算法改进原理
经实验表明:6.0版本的YOLOv5s应用在本文手榴弹数据集检测中,算法检测的平均精度达到99.5%,在准确率上已经满足实际需求,但距离嵌入移动设备中使用,其参数量仍有待降低。
从轻量化出发,分两阶段改进算法:第一阶段调整时,使用Ghost模块做轻量化调整,即保留其等效Focus层的普通卷积层,用Ghost卷积模块替换剩余普通卷积、采用Ghost bottleneck替换C3模块中Bottleneck得到C3Ghost模块,大幅降低模型参数。第二阶段调整时,使用Coordinate注意力机制模块(简称为CoordAtt或CA),应用到上一阶段中得到的轻量化网络中,提升其检测效果,保证模型检测准确率。
2.1 Ghost模块
Ghost卷积(GhostConv)是在GhostNet[9]中提出的一种分阶段卷积模块,其主要思想是将传统一步非线性卷积(非线性卷积=卷积+批归一化+非线性激活函数)替换为两步卷积去获得同样数量特征图的模块(数量设为N张),即第一步使用少量卷积核对输入图片进行非线性卷积,输出m个Intrinsic feature maps,在其基础上使用线性卷积(只有卷积操作,这里常用分组卷积或深度可分离卷积),生成N-m张特征图,又称为ghost feature maps,分步卷积的操作充分利用了特征间相关性,降低了网络对冗余(相关)特征的关注成本,减少了模型参数与计算量,使得算法能在小幅度牺牲精度的同时,达到提高运行速度的效果,其二者结构对比图,如图2所示。

图2 传统卷积与ghost卷积结构对比图Fig.2 Comparison of traditional convolution and ghost convolution structures
Ghost Bottleneck是GhostNet中提出的一类即插即用模块,可以用来减小传统瓶颈层的计算量、轻量化网络构架。Ghost Bottleneck按功能划分为扩张层和缩放层2部分,前者由步长为1 的Ghost模块残差连接构成,其目的为增加模块输出通道数;后者由步长为2的残差块构成,用来减小输出通道数,保证了层间输入、输出通道数的一致性,提高了模型学习特征的速度,模块结构图如图3所示。
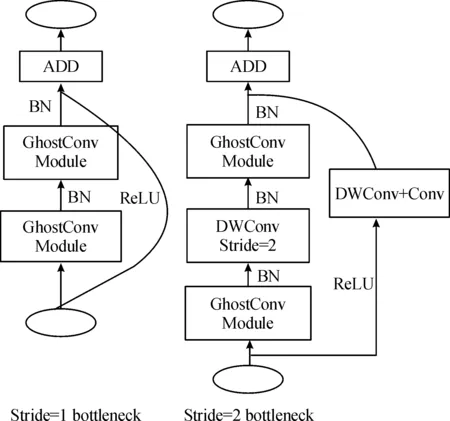
图3 ghost bottleneck模块结构图Fig.3 Structure diagram of ghost bottleneck module
2.2 CA注意力机制模块
在Ghost卷积模块中,算法执行减少非线性卷积操作时,容易丢失图像的局部信息,导致网络的精度下降。因此,本文中提出:在基于Ghost模块轻量化改进后的网络中添加注意力机制,保证网络轻量性的同时,改善模型性能,提高算法识别精度。
注意力机制是一种通过自学习对输入信息逐区域加权的模块,其目的是让模型更多的关注图像中的目标信息(增大其学习权重),降低算法对无关信息的关注程度,从而学习到更多目标的细节信息。在图像领域中常用到的注意力机制按其加权位置分为通道注意力机制(如SENet[10]、SKNet[11])、空间注意力机制(如CA[12])以及同时对通道、空间信息加权的混合注意力机制(如BAM[13]、CBAM[14])。
CA是将目标的全局位置信息嵌入通道注意力的空间注意力模块[15],其结构图如图4。

图4 CA模块结构图Fig.4 Structure diagram of CA module
如图4所示,给定一个输入时,CA模块用到尺寸为(H,1)、(1,W)的2种池化核分别沿特征图的H、W两个不同方向(图中表示为X、Y方向)进行池化得到2个特征图,替代了传统通道注意力机制,如SENet中的一步全局池化操作,将位置信息嵌入了特征图中。随后将得到的2个特征图沿空间维度方向拼接融合,分离融合特征图后得到2个特征图,从而得到2组不同方向的注意力加权向量,这一步解决了传统空间注意力机制,如CBAM中,位置注意力部分未构建空间信息间长程依赖性问题。
综上分析,为了抑制复杂环境下背景对目标的影响,选用CA注意力机制提升轻量化网络的性能,考虑到SKNet中提出的观点:注意力机制加在中浅层时,对网络学习能力的影响更显著。因此,本文中在轻量化模型的SPPF层前插入CA层。
2.3 改进后的YOLOv5-GA算法结构
为方便记录实验结果,将本文中基于Ghost模块、CA模块两阶段改进后的算法命名为YOLOv5-GA,其具体改进措施如上文中所描述,模型的具体结构图如图5所示(G-CONV为ghostconv模块缩写,G-C3对应C3ghost模块的缩写)。

图5 YOLOv5-GA完整结构图Fig.5 The complete network structure of YOLOv5-GA
对应的改进后算法网络模型架构及模块参数如表2所示,其中,C3Ghost为C3模块中传统的瓶颈模块更换为Ghost Bottleneck模块形成的模块;from表示输入来自哪一层;n表示层间模块叠加次数;arguments表示模块基本参数,如:模块输入、输出通道数,卷积核大小、步长等参数。
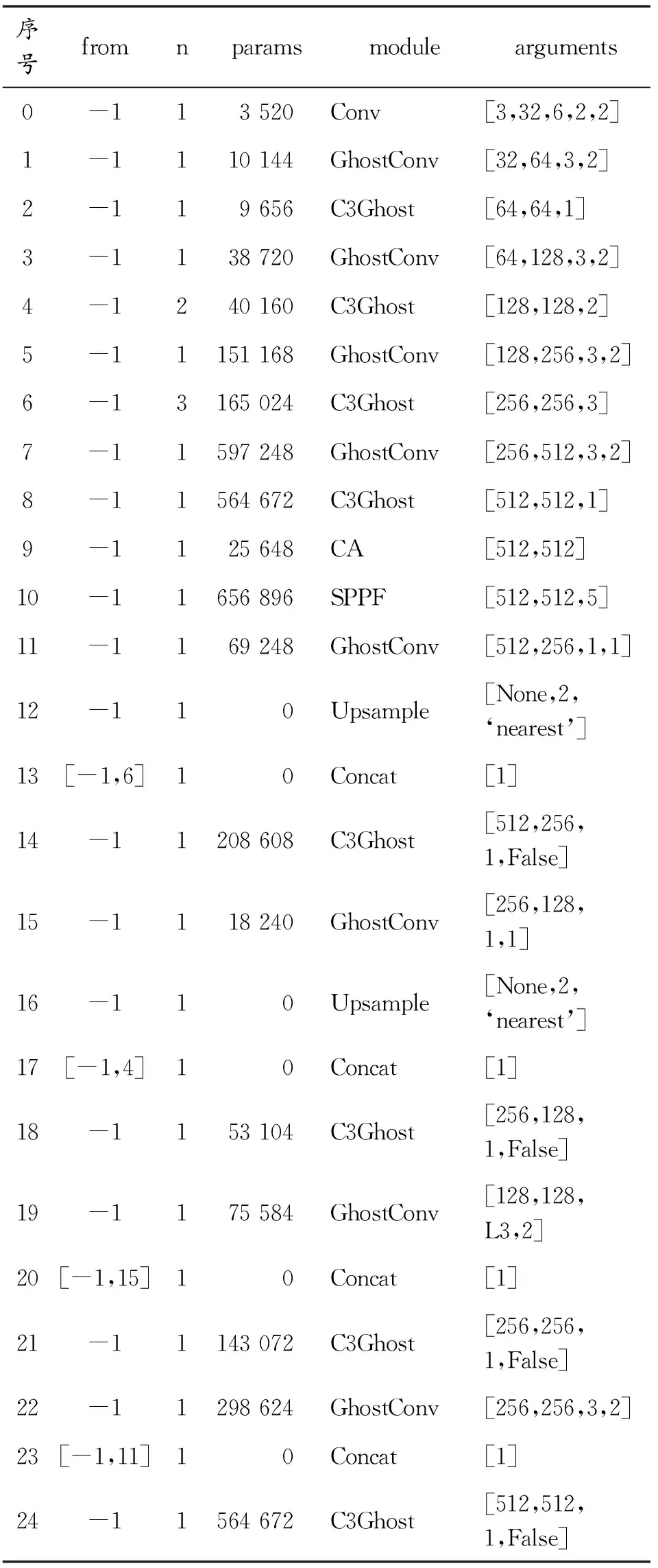
表2 YOLOv5-GA算法架构Table 2 YOLOv5-GA algorithm architecture
3 实验准备及评估标准
3.1 实验环境
实验软硬件平台如表3所示。

表3 实验环境配置Table 3 Experimental environment configuration
3.2 数据集及参数设置
本文中,采用相机实拍的方式制作手榴弹数据集,单张图片单样本,共采集图片884张,用LabelImg软件进行手工标注,按8∶2比例将数据集划分为训练集和验证集。
训练时在输入端固定输入图片的尺寸为640*640,单批处理图像数量(Batch size)设为32,默认训练300个epochs,训练参数如表4所示。使用YOLOv5自带的K-means聚类算法生成3组锚框尺寸分别为:[64,64,90,110,139,128],[115,188,187,203,245,165],[167,275,230,329,318,254]。

表4 实验参数设置Table 4 Experimental parameter settings
3.3 实验模型评估标准
目标检测领域常用精度、召回率以及平均精度来综合衡量算法的检测效果。YOLOv5在训练后会自动生成记录曲线,对于单类别的手榴弹检测,其主要模型评估曲线有精度曲线(P曲线)、召回率曲线(R曲线)、P-R曲线以及AP@0.5曲线,其对应含义,如表5所示。

表5 模型评估指标Table 5 Evaluation metrics for the model
由于精确率与召回率在计算时两者互相影响,单独应用时,无法直接衡量出模型优劣程度。因此,本文中采用AP@0.5(平均精度)评估模型的查全率和查准率[16],AP越高,模型的检测精度越高。采用模型生成权重大小以及模型参数大小反应模型所占内存大小,用模型处理单帧图片的推理时间(inference),即图像经过预处理后输入模型中到模型输出检测结果的时间,衡量模型运行速度。
4 仿真实验及结果分析
4.1 仿真实验
为了验证模型改进后的性能,在本文的数据集上使用YOLOv5s、基于Ghost模块改进的YOLOv5-G算法以及基于Ghost以及CA两种模块综合改进的YOLOv5-GA算法做改进前后模块消融实验,在损失函数达到收敛,训练保存的tensorboard日志AP曲线对比图如图6所示。

图6 AP@0.5曲线对比图Fig.6 Comparison chart of AP@0.5 curve
为更好的展示改进后算法性能,增设YOLOv3算法实验对比,归纳以上实验中算法的部分参数、性能如表6所示。

表6 算法性能对比Table 6 Comparison of algorithms performance
4.2 实验结果分析
4.2.1模块改进效果分析
结合上节中表6和图6分析,对于文中提出的两阶段改进算法,分阶段得出以下结论:
1) 一阶段YOLOv5-G算法:参数量下降到原算法(YOLOv5s)的1/2,模型权重减小一半,虽然实现了轻量化,但算法AP值下降幅度较大,由图6可知,其AP曲线一直位于YOLOv5s算法及YOLOv5-G算法的AP曲线下方,结果表明,其精度比起原算法下降了5%,但模型推理速度加快了4.1 ms,算法精度有待进一步提高。
2) 二阶段YOLOv5-GA算法:为了保证轻量化网络的检测精度,提出将CA模块加入轻量化网络的YOLOv5-GA算法,对比YOLOv5-G算法,在增加不到1%参数的前提下,其AP曲线在稳定时一直位于YOLOv5s-G算法的AP曲线上方,AP值提高了4%,模型推理速度虽减缓1 ms,算法检测精度达到98.4%。
4.2.2改进后检测效果分析
在复杂环境下的各算法模型的检测效果如图7、图8所示。分析检测效果图可知:加入注意力机制模块的YOLOv5-GA算法,比起其他算法,相同环境下其检测框上输出的置信度分数更高,对手榴弹的识别更精确,由图8中对比可得,注意力机制的添加对遮挡目标的识别效果也有所改善,但对遮挡目标的识别准确度有待进一步提升。

图7 杂乱背景下检测效果对比图Fig.7 Comparison of detection effects of various algorithms under cluttered background

图8 部分遮挡下检测效果对比Fig.8 Comparison of detection effects of various algorithm under occlusion
5 结论
由仿真实验数据分析可得,YOLOv5-GA算法在自制手榴弹数据集上达到了高精度、轻量化的效果:
1) 对比YOLOv3算法:算法参数量及权重大小仅占YOLOv3算法的2%,模型推理速度加快了21.1 ms,但精度与该算法相差不到1%。
2) 对比YOLOv5s算法:YOLOv5-GA参数量及权重大小均下降到YOLOv5s算法的1/2左右,检测速度提高了3 ms,保证了算法的高实时性,降低了模型嵌入移动端时所需要的设备要求,减少了计算成本,提高了检测效率。
综上所述,文中针对算法在复杂环境下识别效率不高、不够轻量化的问题,改进了YOLOv5算法,提出了YOLOv5-GA算法,在自制数据集上检测效果良好,模型在复杂环境下识别目标的能力有所提高,同时,参数量大幅度降低,实现了检测算法在高精度下的轻量化,识别效率不高的问题,对YOLOv5算法做出了轻量化改进,提出了YOLOv5-GA算法,在自制数据集上检测能满足更多嵌入式设备的需求。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
专用汽车(2016年1期)2016-03-01
