
基于混合模型和Stacking框架的循环水出口温度预测
2023-07-03 08:19白英君
计算机仿真 2023年5期
张 悦,田 庆,白英君
(1. 华北电力大学控制与计算机工程学院,河北 保定 071000;2. 华北电力大学河北省发电过程仿真与优化控制工程技术研究中心,河北 保定 071000)
1 引言
大多数的工业过程,比如过程控制系统、化学工程、电子电路系统等,其结构清晰,系统运行机理明确,可根据能量平衡方程、化学反应定律及电路基本定律建立白箱模型[1],然而实际的工业过程是非线性的、耦合的,建立机理模型的时候会根据边界条件做出适当的假设,这就造成了机理模型存在较大的且不可调节的误差。随着大数据与人工智能的问世,数据驱动模型迅速发展起来,在能源电力行业的可再生能源预测、负荷预测、故障诊断、电网数据可视化等方面获得了广泛的应用[2]。虽然数据驱动模型可挖掘数据的深层次特征,但当数据集对应的环境条件发生变化时,需要重新构建模型并训练,模型精度过于依赖数据的准确性,只能获得有限的精度和预测效果。
为了提高机理模型的精度,很多学者进行了大量研究,不仅仅单纯的建立凝汽器的模型,而是将相关的汽轮机排汽阻力、锅炉补给水、不凝气体、变速泵等因素考虑到模型之中[3-5],文献[6,7]中建立了非设计条件下的机理模型,并优化变工况的特性。机理模型一定程度上能反应模型的特征,但由于实际电厂的测点信息复杂,不能很准确的得到各种参数,因此存在较大的限制。钟震等[8]将改进的多种群果蝇优化算法(MFOA)用于优化GRNN的超参数集,建立了汽轮机热耗率预测模型,还有很多类似的数据驱动模型优化方法,比如最小二乘支持向量机和人工蚁群算法组合模型;通用自回归神经网络模型(GSTAR-SUR-NN);ARIMA与自适应滤波方法组合模型;小波变换(WT)和粒子群(PSO)优化与极限学习机组合模型,广泛用于气象、医疗、工业生产过程等的预测[9-13]。此类模型往往采用单一的数据驱动模型,使用优化算法对模型中的参数进行优化,但仍避免不了数据驱动模型陷入局部极小点的问题,而且还可能出现由于随机性导致模型泛化能力不佳的状况。针对此问题,文献[14,15]中提出了多种数据驱动模型融合的方法,充分发挥不同机器学习算法的优势,实验证明了融合模型预测的可行性与有效性。该方法归根结底依旧是数据驱动模型,对历史数据依赖程度很大,对实际过程的机理涉及甚少,因此很多学者提出了机理模型与数据模型结合的混合模型,将数据驱动模型作为误差补偿器对机理模型进行修正,实验证明该混合模型的精度均高于单纯的机理模型与数据驱动模型[16-18]。毫无疑问,机理模型与多个数据驱动模型的混合模型在处理复杂的系统时,与单个系统相比,能有效的提高预测的准确性[19]。
本文将支持向量机算法(Support vector machines,SVM)、自适应提升算法(Adaboost, Adaptive Boosting)、梯度提升树算法( Gradient Boost Decision Tree,GBDT)及广义回归神经网络算法(General Regression Neural Network,GRNN)与集成学习方式有效的结合起来,提出了一种基于混合模型和Stacking框架的循环水出口温度预测方法。在组合多个数据驱动模型的基础上,将机理模型以误差补偿的形式并联到数据驱动模型中,构建了混合模型。既考虑了多种算法的差异性,深层次挖掘隐含在时间序列数据中的特征,又结合了实际生产过程中的物质流传递机理,使混合模型的参数具有明确的物理意义,更好的反应研究对象的动态特性。
2 凝汽器管侧机理模型
凝汽器是发电机组的一个重要辅助设备,主要作用是在汽轮机排汽口形成较高真空,提高热循环效率。其运行的优劣直接影响电厂运行的经济性、安全性,建立一个准确度高、精度高的机理模型来研究凝汽器的工作状态很有必要性。本文以某1000MW电厂的表面式凝汽器为研究对象(如图1),建立其管侧(或称冷却水侧)机理模型[20],模型求解的中间变量为冷却水管壁的金属温度,输出变量为循环水出口温度。
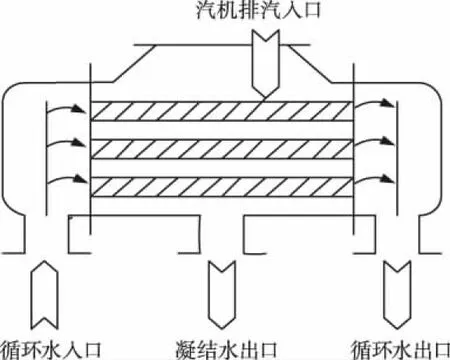
图1 表面式凝汽器

图2 广义回归神经网络结构图
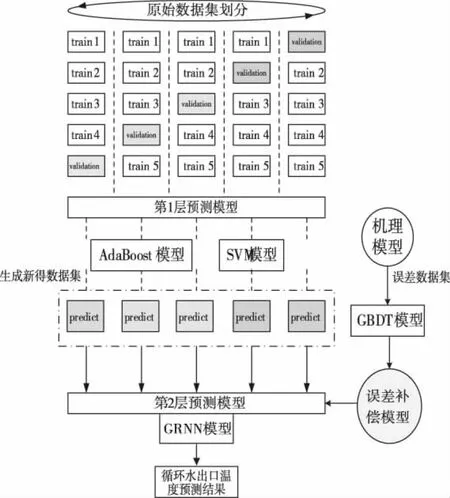
图3 流程图
根据传热学理论,假设凝汽器与外界大气不存在换热,得到冷却水管壁的金属温度Tm
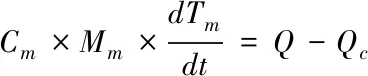
(1)
其中,蒸汽区的换热量Q由热平衡方程得

(2)
式(2)中K为总传热系数,按照美国传热学会颁布的HEI公式得
K=ξcβtβmK0
(3)

(4)
式(3)中K0为基本传热系数,ξc为清洁系数,本文取0.85,βt为循环水入口水温修正系数,βm为冷却管材料和壁厚的修正系数,均与Tc1有关,式(4)中C为计算系数,与冷却管外径有关。
冷却水的吸热量由热平衡方程得

(5)
式中αc为对流换热系数,按照经验公式得
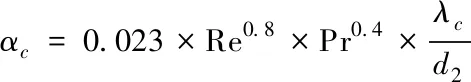
(6)
式(6)中Re为雷诺数,Pr为普朗特常数。根据冷却水的吸热过程,利用能量平衡原理得
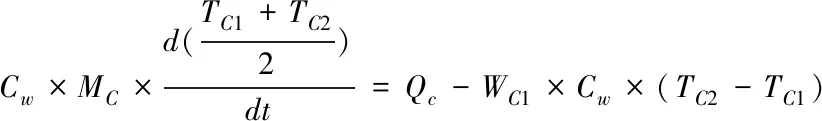
(7)
本文以某1000MW电厂的凝汽器管侧数据为参考,根据式(1)~式(7)建立凝汽器管侧的机理模型,输入输出主要性能参数如表1所示。
表1中f(t)代表变量是时间序列数据。
3 混合建模方法
3.1 基于误差补偿的机理模型
循坏水在管道中的流动过程涉及的因素较多,在建立机理模型时进行了一系列简化,比如将管侧的所有并联铜管等效为一根传热管;冷却水管壁上的温度、比热容等相关参数分布一致等,因此对机理模型的计算结果造成一定误差。
GBDT算法是一种基于残差学习的回归树模型,每一颗树会对之前所有树结论和的残差进行迭代学习,直至残差为0得到最终的预测值。在上述第1节中建立的机理模型中,因做了多种简化,实际值与机理模型输出值之间必然存在较大的误差,直接以此误差作为GBDT的衡量标准,有利于寻得全局最优方向,在迭代过程中快速找到决策树,让样本的损失量尽可能变小。
3.2 数据驱动模型
数据驱动模型依赖于大量的历史数据,且相关特征较复杂,预测最终结果是循环水出口温度,涉及的数据有循环水进口温度、汽轮机的排汽温度、凝汽器的立管温度、凝汽器壳侧温度、凝结水入口温度及凝结水出口温度等,SVM算法是一种经典的统计学方法,在回归问题上具有明显的优势,尤其是涉及高维度及非线性的问题。在多变量输入的预测模型中有较高的准确率。凝汽器模型除了温度变量对循环水出口温度有直接影响,还有压力变量的间接影响,将代表不同含义的特征变量进行组合学习,有利于提高模型的预测准确率。AdaBoost算法利用前一轮迭代弱学习器的误差率来更新权重,对每次分错的样本升高权重,加强了压力与温度之间的对应关系,在训练过程中具有很高的精度。
GRNN是美国学者SPECHT[21]等人在1991年提出的一种前馈神经网络,主要采用非线性回归分析的方法求解回归问题。相对于其它的网络,其可以处理不稳定数据,容错能力强,泛化能力好,可调节参数少,并且有很强的非线性映射能力和学习速度。GRNN的结构主要有四部分,分别为输入层、模式层、输出层及求和层。
1)输入层神经元的数目等于样本中输入向量的维数,各神经元直接将输入变量传递给模式层。
2)模式层神经元的数目等于学习样本数目,该层神经元传递函数为:
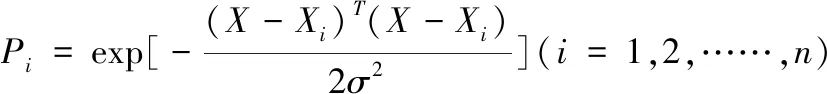
(8)
式(8)中X为输入变量; Xi为相应神经元对应的学习样本;σ为光滑因子
3)求和层使用两种类型的传递函数进行求和。
a. 各神经元与模式层的连接权值为1

(9)
b. 模式层中第i个神经元与求和层中第j个神经元的连接权值为输出样本中第j个元素值

(10)
4)输出层神经元的数目等于样本中输出向量的维数,将求和层中的两类求和神经元相除结果作为预测值。
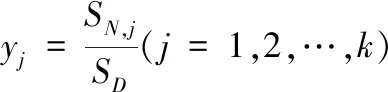
(11)
3.3 基于Stacking框架下的混合模型
Stacking学习方式是将多个预测模型进行融合的模型集成技术,它可以将不同的机器学习算法通过不同的方式结合在一起,以此获得比单一算法更优越的性能。本文在stacking模型第一层选择了预测性能较为优异的AdaBoost算法与SVM算法作为初级训练器,有助于提升模型整体的预测性能。次级训练器选择GRNN算法提高泛化能力,对多个学习算法的训练偏置情况进行优化。另一方面,为了获得最优的预测效果,在stacking模型的第二层中选择了机理误差模型作为补偿输入。这是考虑到机理模型参数明确、适应性强的特点,同时结合数据模型的优势,较好的挖掘时序序列数据的深层次特征,优势互补,更好的反应研究对象的规律与特性,提高整体预测效果。
Stacking框架下混合模型的预测方法训练流程如下:
1)根据人工经验将数据集分为温度数据集和压力数据集,选择差异较大的AdaBoost算法与SVM算法作为第一层预测模型。划分原始数据集,使用5折交叉验证的方式,完成特征提取并优化各模型的参数。
2)使用划分后的数据集对Stacking中的第1层预测算法分别进行训练,并输出预测结果,生成新的数据集。
3)选择机理模型的仿真值与真实值作为GDBT算法的输入,并训练误差模型,得到混合模型的补偿输入。
4)使用第2)步生成的新数据集与第3)步生成的误差输出,对Stacking中的第2层算法进行训练,整体算法训练完毕,得到混合模型的输出。
4 仿真及分析
本文算法及Stacking框架下的学习模型在Python环境下实现,数据集来源是某1000MW机组的凝汽器数据,训练数据的采样周期为5min,初级训练器的训练集4000个数据,验证集1000个数据,测试集1000个数据,次级训练器的训练集5000个数据,测试集1000个数据。预测时段的目标为未来三天的循环水出口温度。预测评价指标采用均方误差MSE(meansquareerror)、最大误差Emax及判定系数R2,MSE和Emax越小、R2越接近1,表示预测效果越准确,如下所示

(12)
Emax=[x(i)-y(i)]
(13)

(14)
式中:x(i)与y(i)分别表示i时刻的实际值和预测值,n为样本数量。
4.1 基于机理模型的误差补偿模型
根据本文第1节所建立的机理模型进行仿真,得到真实值与仿真值的曲线,以误差为GBDT算法的输入,对机理模型的仿真值进行补偿,得到最终的模型预测输出。
由图4可以看出,机理模型仿真的结果与真实值存在较大差异,但其误差的变化在一定的可控范围内,通过基于GBDT算法的补偿,能够的到比较准确的预测结果。
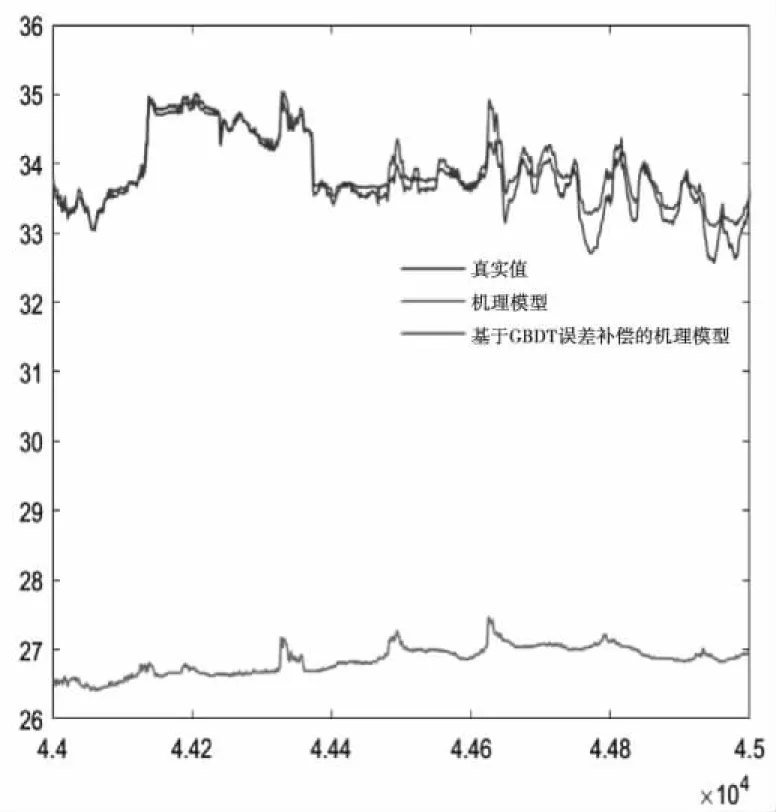
图4 基于机理模型的误差补偿预测
4.2 数据驱动模型
本文以6月份的某三天数据为例,将汽轮机排汽的压力与温度、凝结水的压力与温度、循环水入口温度、凝汽器压力、汽机侧立管温度及壳侧温度作为输入变量,循环水出口温度作为输出变量,在单一数据驱动模型上测试模型的预测准确率,各算法模型的预测结果如图5所示。
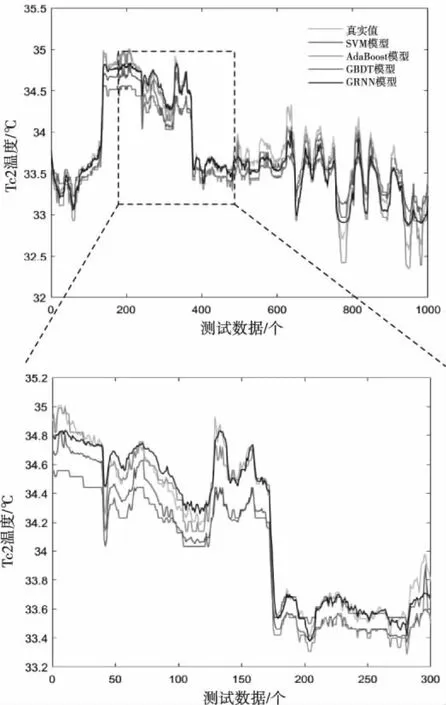
图5 单一数据驱动模型的温度预测结果
结合仿真结果图5及表2的预测指标可知,在单一的数据驱动模型中,SVM模型整体表现略差一点,而GRNN模型的均方误差均低于其它模型,虽然最大误差比AdaBoost模型的高了0.12,但判定系数比AdaBoost模型的提高了2.14%。相对于其它的模型,GRNN模型具有好的控制效果,因此在后续的对比实验中,单一数据驱动模型以GRNN模型为主。
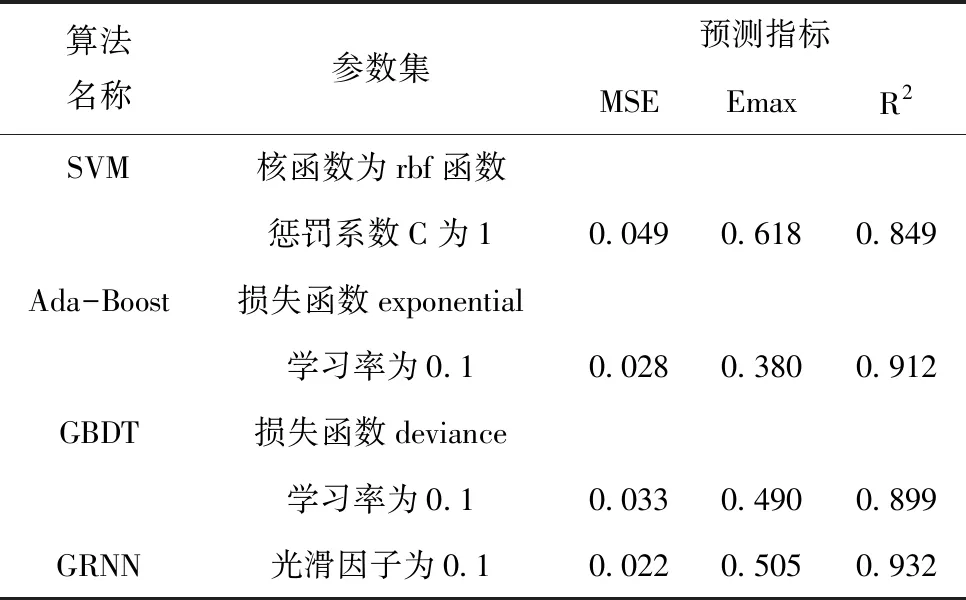
表2 数据驱动模型下的预测指标
4.3 Stacking框架下混合模型预测性能分析
4.3.1 数据驱动组合(SVM-AdaBoost-GRNN)模型
为了凸显基于机理模型的误差补偿模型的优越性,首先对数据驱动模型在Stacking框架下进行组合学习。将数据集按照温度与压力的特征分为两部分,SVM算法训练温度模型,输出中间变量壳侧温度,AdaBoost算法训练压力模型,输出中间变量排汽压力,以中间变量作为GRNN模型的输入,最终训练组合模型得到循坏水出口的温度。
4.3.2 Stacking框架下的混合模型
为了验证Stacking框架下的混合模型的预测性能,在数据驱动组合模型的训练基础上,将3.1节中由GBDT算法训练得到的误差补偿模型作为GRNN模型的第三个输入变量,同时选择6月份的数据,将此模型与单一数据驱动模型(选择GRNN)、数据驱动组合模型预测效果分别进行对比分析,验证算法可行性。
为了更直观的展现Stacking混合模型与其它模型的准确性,计算上述三种模型的MSE、Emax及R2,如表3所示。
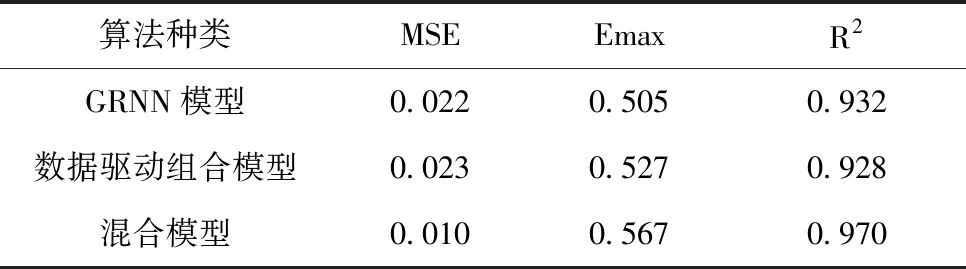
表3 不同模型组合下的预测指标
参考3.1节机理模型仿真结果图4,可以明显比较出机理模型的仿真效果是最差的。同时结合三种不同模型下的预测结果图6及表3可以看到单一数据驱动模型与数据驱动组合模型预测性能相当,但采用Stacking框架下混合模型的预测效果均优于其它的数据驱动模型。混合模型的均方误差比GRNN模型降低了0.012,判定系数相比于数据驱动组合模型提高了4.53%。
5 结论
1)本文提出了一种基于混合模型和Stacking框架的参数预测方法,在机理模型的基础上,充分发挥不同算法(SVM、AdaBoost、GBDT、GRNN)从不同角度对数据空间与结构进行观测,有利于提高凝汽器参数预测的准确度,对实际电厂凝汽器的安全运行、经济运行有着重大的意义。
2)本文将提出的模型应用在凝汽器循环水出口温度的预测中,划分数据集并进行算法训练,仿真结果表明,基于Stacking框架下混合模型的MSE比GRNN模型降低了0.012,R2相比于数据驱动组合模型提高了4.53%,具有更高的预测准确率与拟合度,可以将该方法改进并尝试应用在实际电厂除凝汽器管侧模型之外的参数预测问题中。
猜你喜欢
设备管理与维修(2022年21期)2022-12-28
水泵技术(2022年2期)2022-06-16
汽车实用技术(2022年7期)2022-04-20
建材发展导向(2021年14期)2021-08-23
房地产导刊(2020年11期)2020-12-28
铁道通信信号(2019年4期)2019-10-10
中国煤层气(2019年2期)2019-08-27
环境与可持续发展(2017年2期)2017-04-06
电站辅机(2016年3期)2016-05-17
通信电源技术(2016年1期)2016-04-16
