
一种基于CUDA与FAST的机场全景监视方法
2023-07-03 08:49吴岳洲张先浩
计算机仿真 2023年5期
吴岳洲,傅 强,郭 康,张先浩
(中国民用航空飞行学院计算机学院,四川 德阳 618307)
1 引言
基于多摄像机视频的机场场面监视中,全景图像生成是最为关键的技术,基于该方法可以将多路不同点位不同朝向的视频整合成一个用户感兴趣的大场景视图,既保留了原始图像的细节信息,又具有较好的整体场景态势感知体验。全景生成常用的图像配准方法包括:基于变换域的图像配准法,如对数-极坐标变换、傅里叶变换等[1-3];基于时域的图像配准法,如基于纹理特征、角点特征、像素值等的图像配准方法。机场场面全景监视目前主要应用于远程塔台领域[4-6],多视点全景有利于空中交通管制中心同时观察多个远程中小机场场面运行态势,为其提供管制服务。国内外基于多路摄像机视频的远程塔台全景监视系统一般在180度的环幕上进行显示,对监视中小安装环境要求较高,且前端采集摄像机位置多集中安装于一个点位,没有考虑多点位全景整合生成问题。文献[5,6]对远程虚拟塔台中的全景监视技术功能进行了扩充,加入了视频图像增强和目标提取功能,但是并没有解决多路摄像机视频间亮度不一致和高清实时全景生成问题。
本文在已有报道文献的基础上,引入光照一致化、动态规划拼接缝、GPU统一计算设备架构(Compute unified device architecture,CUDA)并行加速等技术,设计并实现一套实时、高清的机场场面全景监视方法。全景拼接前,首先对每一路视频图像进行光照一致化处理,然后提取图像的FAST特征[6],利用随机抽样一致算法(Random sample consensus,RANSAC)[7,8]进行相邻摄像机图像间变换模型的鲁棒估计。为实现相邻摄像机图像的平滑过渡,采用基于动态规划缝合线的相邻图像缝合。由于拼接过程中的图像变换、图像插值与图像融合具有数据结构相似、大规模、高并发的特点,本文设计了一套基于CUDA并行加速的全景图生成方法,充分利用CUDA的单指令多线程(Single instruction multiple thread,SIMT)特性,满足实时性要求。
2 光照一致化
全景拼接前,需要校正各通道摄像机由于曝光差异、环境光和朝向不同导致的图像亮度不一致。通常在图像配准后即可确定两图像的重叠部分,分别计算两图像在重叠区域光照强度的平均值或方差等统计量,对各通道图像间进行比较,计算它们的差异,然后将光照强度较强的图像亮度降低,将光照强度较弱的图像亮度增强,达到均衡光差的效果。但是该方法对于图像通道数超过3时校正效果并不理想,很难保证多通道图像的亮度一致化,且无法保持原图像亮度的对比度,容易出现矫正后图像过亮或过暗的现象[9]。考虑到HSV色彩空间中各分量相对独立,本文选择其中亮度分量作为光照一致化的参考变量,与同时校正RGB三个通道的分量的方法相比,在减小计算复杂度的同时,该方法有效防止了因为某通道图像过亮或过暗而导致全景图过亮或过暗的影响[10]。
各路视频图像亮度进行全局一致化校正时,定义一个基于相邻图像重叠区域像素亮度值的全局优化函数,均衡调整各通道图像亮度。
+(1-gi)2β)
(1)
其中

(2)
式中,gi,gj是图像的整体亮度校正值,Nij=|R(i,j)|表示图像i与图像j的重叠区域R(i,j)的像素个数,α是保持多路图像光照一致的权重,β是图像保持原来亮度值的权重。


(3)
3 全景生成
3.1 基于FAST特征的图像配准
光照一致化后,提取特征点进行变换模型参数的估计。常用的图像特征有SIFT、SURF和FAST等,具有128维描述向量的SIFT特征计算复杂度高,FAST描述子与SURF都具有较高的匹配精度,但是FAST特征的提取速度更快,更适用于实时性要求高的应用,因此本文采用FAST特征。为提高相邻图像特征检测效率、降低误匹配率,本文根据相邻摄像机Ii和Ii+1的方位、场景等先验知识,预设粗匹配区域Ri和Ri+1,再提取粗匹配区域的FAST特征。本文采用八参数投影变换模型,变换前像素坐标X=(x,y,1)与变换后像素坐标X′=(x′,y′,1)的关系见式(4)

(4)
其中,h11,h12,h21,h22为缩放、旋转因子,h13,h23分别是水平平移因子、垂直平移因子,h31,h32是仿射变换因子。
特征点p周围一圈的像素要满足以下要求才能作为FAST特征点:
1)候选点圆邻域内有足够比率的像素点(3/4左右)与该候选点的灰度值差别足够大;

(5)
其中,I(p)表示圆心p的灰度值,circle(p)表示p点的周围一圈,I(x)表示circle(p)上任意点x的灰度值,εd为阈值。
2)候选点某圆邻域内满足(5)式的像素点构成的最大弧度值θ大于等于阀值θt。
提取FAST-16特征,然后进行m×m(m≥3)邻域的非极值抑制,特征点赋值规则如式(6)

(6)
本文中,基于RANSAC算法的FAST特征匹配流程如下:
步骤1:基于FANN方法[11],对感兴趣区域Ri内的FAST特征进行粗匹配,得到n(n>4)对匹配点对。
步骤2:随机抽取粗匹配点对中m(m≥4)个匹配点对,任意三点不共线。
步骤3:利用抽取的m(m≥4)匹配点对建立线性方程组,求解模型M。
M=[h11,h12,…,h32]T
(7)
步骤4:定义欧式距离dis与距离阀值th,dis≤th时,匹配点对为内点,同时更新内点数目num。

(8)

步骤5:重复步骤2到步骤4直达最大采样次数MAX或者num足够大。MAX通过式(9)确定

(9)
其中,β表示任一对匹配点对是内点的概率,p表示采样的m对匹配点对中内点的概率。
步骤6:利用获得的内点实现精匹配,用最小二乘法计算各变换模型参数。
特征提取的结果和匹配点对见图1。

图1 FAST特粗匹配与精匹配结果
3.2 基于动态规划缝合线的图像缝合
求得变换模型参数后,需要进行图像缝合。由于摄像机安装位置和环境光不同等因素,虽然摄像机型号相同,但各摄像机图像颜色或亮度等方面会存在差异,如果对相邻图像直接进行融合,在重叠区域将会出现明显的融合带现象[12]。因此,本文设计一种动态规划缝合线方法,采用相邻摄像机图像重叠区域内HSV色彩分量作为缝合准则,动态规划缝合线示意图见图2中相邻两图重叠区域的虚线部分。

图2 动态规划拼接缝
本文定义的相邻摄像机图像缝合线准则是:缝合线两边r邻域内(r=9)的梯度差最小,图像梯度分量通过Sobel算子得到;缝合线像素点的色差最小,色差用HSV色彩空间中反映色彩本质特性的色度和饱和度的和进行分析计量。每条缝合线上缝合点个数为mi。
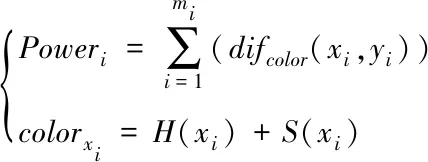
(10)
其中H(·)、S(·)分别为某点的色度值、饱和度值,最佳缝合线即为Powermin所对应的缝合线:
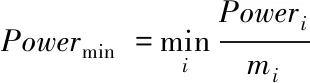
(11)
图3是3路视频全景拼接后的效果图,其中图a为没有进行光照一致化的缝合图像,图b是经过光照一致化后的缝合图像。

图3 全景图缝合
为使相邻图像实现重叠区域内平滑过渡,采用符合人眼视觉感知的分段三角函数加权融合方法,融合函数见式(12),融合区域为基于缝合线向两边邻域扩展得到的区域。
f(i)(x)=θ(x)f(i)(x)
(12)
其中,f(i)(x)(i=1,2,3)表示图像在X方向坐标值x处的R,G,B分量值,θ表示基于分段三角函数的权值。设xmin,xmax为缝合线X方向r邻域内(r=9)坐标值的最小值和最大值,θ取值规则见式(13-15)。
当xmin≤x (13) 当xmin+(xmax-xmin)/4≤x≤3/4(xmax-xmin)时 (14) 当xmin+3/4(xmax-xmin) (15) 由于全景拼接对各通道视频数据的访问是相互独立的,充分利用CUDA的SIMT特性进行高性能并行处理,基于GPU CUDA加速的系统架构示意图见图4。 图4 系统架构 由于CUDA中二维结构线程划分正好与二维图像空间对应,该设计便于在并行平台中产生与图像像素数目相等的线程数量,可做到每个独立线程实现一个像素点相关处理。因此,CUDA内核函数执行时GPU线程分配采用二维分配方式。假设有48×32像素大小的图像数据块(如图5),考虑CUDA内线程调度单位是以32个线程构成的线程束(warp),线程块(Block)规模一般设计为16×16,因此就有3×2个线程块处理对应的该图像数据块。 图5 CUDA线程划分 设备端(GPU)实时生成全景监视图像前,主机端(CPU)和设备端需进行以下操作:通过CPU端同步采集多通道视频帧到主机端内存,并动态更新上载到CUDA全局存储器;加载图像配准变换模型对应的反向插值映射矩阵到CUDA全局存储器;加载动态规划图像缝合矩阵到CUDA全局存储器;间歇式动态更新光照一致化参数到CUDA常数存储器(相对于全局存储器访问速度更快)。 CPU端启动GPU端全景实时生成的CUDA内核函数(Kernel function),进行以下操作:对动态加载的多通道同步视频帧进行光照一致化校正;实现基于预加载图像变换模型的反向插值映射;实现动态规划缝合和基于式(12)对应的分段三角函数加权融合。以上步骤动态循环执行,实时生成高分辨率全景监视图像。CUDA加速算法流程如图6所示。 图6 CUDA加速算法流程图 机场场面全景监视对实时性、分辨率等要求较高,项目采用的服务器配置为:英特尔至强处理器E5-2650CPU,英伟达GTX Titan显卡。前端两个全景监视点位分别架设了3个和2个1920×1080像素高清网络摄像机。摄像机布局与成像示意图如图7。 图7 摄像机布局及多路视频效果 最终两个全景监视点位的全景图合并到一起,根据需要真实监视场景需求,修剪为4537×1724的高分辨率全景图像,系统在机场塔台的实景图见图8,全景监视效果见图9。 图8 塔台全景监视系统 图9 全景监视效果图 实际摄像机环境无法获取各摄像机通道间的真实配准模型参数,本文采用均方根误差(Root mean square error,RMSE)作为配准精度计量指标[13],利用参与配准模型计算的匹配点对进行计算,计算方法见式(16)。 (16) 其中,M为图像I1,I2间的变换矩阵,x1,i,x2,i是相邻图像重叠区域内匹配点对的坐标,m为重叠区域内匹配点对的个数。通过对视频任意抽取10帧同步数据,经过特征提取、匹配和计算分析,RMSE=0.822,配准几何误差范围小,满足全景质量要求。主机端(CPU)的图像配准算法用时对比分析见表1。 表1 配准算法用时对比 实验表明,如果只依靠主机端(CPU)完成如图6所示的视频帧光照一致化、视频帧反向插值映射和动态规划图像缝合,基于5帧1920×1080像素图像生成1帧全景监视图像,耗时约为2000~2300毫秒(ms)。通过算法移植设备端(GPU),通过CUDA并行加速,相同视频场景下,耗时约为65~70毫秒(ms),在不影响全景生成质量的前提下,性能得到大幅度提升。 本文提出的全景监视方法中,各摄像机视频间的变换模型参数实现基于RANSAC与FAST的全自动计算,无需进行摄像机标定、现场测量等,只需在安装时保证相邻摄像机图像间有一定重合区域即可。通过加入基于HSV色彩空间与全局优化函数的动态光照一致化,实现多路摄像机视频亮度间全局自动校正。通过动态规划缝合线实现高质量全景生成。通过对图像变换、图像缝合等关键步骤的GPU CUDA并行加速,实现全景实时生成。通过在某机场的应用示范,验证了本文提出方法的科学合理性和工程实用性。在未来的工作中,将开展基于大尺度机场场面监视的目标行为建模、事件挖掘分析等工作。


3.3 基于CUDA加速的全景视频生成



4 实验



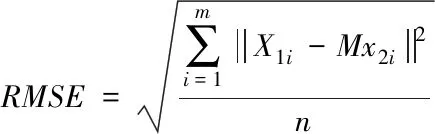

5 结论
猜你喜欢
东华大学学报(自然科学版)(2023年2期)2023-05-16纺织学报(2021年5期)2021-05-27家庭影院技术(2020年11期)2020-12-28英美文学研究论丛(2018年1期)2018-08-16环球市场(2017年36期)2017-03-09家庭影院技术(2017年12期)2017-02-06特别文摘(2016年21期)2016-12-05地下水(2014年2期)2014-06-07计算机工程与科学(2013年2期)2013-06-07吉林建筑大学学报(2012年3期)2012-08-15
