
基于多表征融合的函数级代码漏洞检测方法
2023-07-01 06:36田振洲吕佳俊王凡凡
西安邮电大学学报 2023年1期
田振洲,吕佳俊,王凡凡
(西安邮电大学 计算机学院,陕西 西安 710121)
近年来,网络攻击事件频发,木马、蠕虫和勒索软件等层出不穷,对网络安全构成了严重威胁。例如,2017年的Apache Struts漏洞导致1.43亿消费者的金融数据被泄露,造成不可估量的经济损失[1-2]。网络攻击得以实施的根源在于软件漏洞的普遍存在。截至目前,通用漏洞披露(Common Vulnerabilities &Exposures,CVE)网站上已收录的漏洞高达17余万条[3],且漏洞数量依然呈爆发式增长态势。
现有漏洞检测方法主要分为基于代码相似性的漏洞检测[4-6]、基于规则的漏洞检测[7]和基于机器学习的漏洞检测[8-9]。基于代码相似性进行漏洞检测的核心思想是,相似的代码中很可能包含相同的漏洞,但用其检测并非由代码复制引入的漏洞时,存在较高的漏报率。基于规则的漏洞检测方法定义的漏洞规则具有很强的主观性,难以全面考虑各种区分有漏洞和无漏洞的情况,导致方法往往存在较高的漏报率和误报率。基于机器学习的漏洞检测方法,按照是否需要专家定义特征,又分为基于传统机器学习和基于深度学习的方法两类。基于传统机器学习的漏洞检测方法不依赖定义的漏洞规则,但依然需要人为地结合专业的领域知识,利用特征工程筛选出对于刻画漏洞至关重要的代码特征,然后利用机器学习算法实现漏洞检测。
深度学习在程序语言建模[10]和情感分析[11]等诸多领域有着广泛应用,近年来也逐渐被应用于程序漏洞检测中。Xu等[12]利用神经网络模型在函数级上进行基于代码相似性的二进制漏洞检测。Russell等[13]针对C/C++源代码,利用卷积神经网络(Convolutional Neural Network,CNN)处理函数Token序列,实现漏洞检测。基于深度学习的漏洞检测方法不需要手工定义特征,而是借助深度神经网络强大的特征学习能力,自动抽取漏洞模式或漏洞相关的指示性特征。但是,仅利用代码的某一特定的表征结构进行漏洞检测,导致深度学习模型难以充分学习代码中蕴含的深层语义信息,不利于深层漏洞的检测。
针对上述问题,拟提出一种基于多表征融合的代码漏洞检测(Sequence and Structure Fusion based Vulnerability Dectection,S2FVD)方法。对不同的代码表征使用适配的深度神经网络模型,提取深层语义特征并进行有机融合,以期充分学习代码中蕴含的语义信息,实现代码漏洞的精准检测。
1 S2FVD方法整体结构
S2FVD方法为保证漏洞检测的粒度,先选取函数而非整个程序作为基本分析单元,通过对函数的词法和语法解析,从中构建Token序列和属性控制流图(Attributed Control Flow Graph,ACFG),作为函数的两种不同的原始表征结构。其次,对Token序列中的Token、属性控制流图中的节点进行词嵌入,得到初始向量表示,并在嵌入的基础上,对属性控制流图中的节点属性使用TextCNN模型提取节点初始特征。然后,分别使用针对序列的神经网络TextCNN和图卷积神经网络[14](Graph Con-volutional Nueral Network,GCN ),从中抽取深层次的代码语义特征。最后,考虑到Token序列和ACFG是从不同角度(序列和结构)对同一函数的语义进行的互补性描述,因此通过直观的向量拼接操作,将从二者中抽取的特征向量进行有机融合,并送入分类层,实现函数级漏洞的精准检测。S2FVD方法的整体结构示意图如图1所示。

图1 S2FVD方法的整体结构示意图
2 原始代码表征提取
为了充分学习代码所承载的语义信息,检测出C/C++代码中的漏洞,需要先提取每个函数的Token序列和属性控制流图,作为每个函数的原始代码表征。
2.1 Token序列提取
Token序列相当于按自然语言处理的方式处理代码,体现了源代码的自然顺序,一定程度上反映了源代码所体现的编程逻辑。提取Token序列时,先删除代码中的注释,因为其与漏洞无关。然后,对代码进行标准化处理,筛选出自定义的变量名和函数名,对其进行统一替换,以去除一些语义无关的信息。将同一函数中出现的不同变量和不同函数名按出现的次序映射为对应的符号名,如“VAR1”“VAR2”表示同一函数中的不同变量,“FUN1”“FUN2”表示同一函数中的不同函数名。最后,通过词法分析,将符号表示中的函数划分为一系列标记,包括标识符、关键字、操作符和符号。函数转化为Token序列的过程如图2所示。

图2 函数转化为Token序列的过程
2.2 属性控制流图提取
控制流图(Control Flow Graph,CFG)是程序分析领域广泛使用的一种代码表示结构,其蕴含了程序代码间的控制依赖等语义信息。进一步地,除考虑控制流节点的依赖关系外,对控制流节点内的程序语句进行抽象以赋予节点属性信息,从而构建属性控制流图作为函数的另一种原始代码表征结构。
属性控制流图是一个有向图,定义为G=(V,E,A),其中:V和E分别为顶点和边的集合;A为顶点包含的信息的集合。在代码漏洞检测场景中,每个顶点是控制流图中的节点,每条边代表代码的控制流,节点所包含的信息作为节点的属性。节点属性包含节点的类型和节点所对应的程序语句。每个节点都有一个类型,为节点所代表的程序语句的类型。如图3所示,类型为METHOD的节点表示方法名,类型为METHOD_RETURN的节点表示返回值类型,类型为

图3 属性控制流图
3 基于多表征融合的漏洞检测
3.1 基于TextCNN的代码序列特征提取
对于函数的Token序列,采用嵌入的方式将单个Token转化为向量表示,再使用TextCNN模型进行代码序列特征的提取。
1)嵌入。标准化后的Token序列必须转换为数值向量,以便能够作为深度学习模型的输入。对此,利用Word2Vec词嵌入算法,将每个独特的Token映射成一个高维的数值向量。具体地,将标准化后的每条Token序列视为一条句子,将序列中的每个Token视为一个单词。利用gensim库中提供的skip-gram模型[16],迭代地通过中心词推断上下文窗口内的其他词,从而为每个独特的Token学习一个d维向量。向量维度过高会导致表示空间稀疏,并增加后续神经网络模型训练的时空开销,维度过低,则可能导致含义不同的Token难以准确区分。利用Word2Vec进行词嵌入的源代码分析任务中,50、100和200为最常见的取值。采取gensim中skip-gram模型的默认参数设置,即向量维度d和上下文窗口的值分别设置为100和5,同时,模型迭代训练100次。
2)TextCNN模型。在Token嵌入的基础上,将每个Token序列转换为原始特征矩阵A∈l×d,即
A=[e1,e2,…,ei,…,el]T
(1)
式中:l为Token序列的长度,Token的实际数量因函数而异,为方便批量训练,采取补零或截断的方式,将Token序列长度统一调整为l;ei∈d是序列中Token相应的嵌入。
使用卷积核进行特征提取,与图像处理的卷积核不同的是,经过词向量表达的Token序列为一维数据,因此,在TextCNN中用一维卷积。在卷积层,采用结构为n×d的m个卷积滤波器对原始特征矩阵A进行卷积运算,得到特征矩阵A∈(l-n+1)×m,其中,n表示卷积核的大小。为了提取特征模式的不同视图,使用大小分别为2、3和4的不同卷积核对A进行卷积。不同高度的卷积核得到的特征图(feature map)大小不一样,使用汇聚函数使其维度相同,这里使用1D-maxpooling提取出最大值。最后,拼接起来得到特征向量VToken。基于TextCNN的模型结构如图4所示。

图4 基于TextCNN的Token序列特征抽取模型
3.2 基于GCN的代码结构特征提取
带属性的控制流图是图结构,因此可以选择使用GCN进行表示学习。GCN的核心思想为学习一个函数映射,通过该映射图中的节点聚合其自己特征与其邻居节点特征,从而生成节点的新表示。
1)节点初始特征提取。首先,将控制流图中节点的属性通过词法分析解析成Token序列。其次,采取gensim中的skip-gram模型,为每个独特的Token学习一个w维向量,向量维度设置为100。将每个节点的属性对应的Token序列转换为原始特征矩阵N∈Rk×w,其中k是Token序列的长度,设置为30。然后,使用大小分别为2、3和4的卷积核进行特征提取。不同大小的卷积核得到的特征图大小不一样,使用汇聚函数,使其维度相同。最后,将生成的表示进行连接,经过全连接层转化为输出特征,作为图中节点的初始特征。
2)GCN模型。基于GCN的模型结构如图5所示。

图5 基于GCN的ACFG结构特征抽取模型
将节点的初始特征组成一个n×m维的矩阵X,每个节点之间的关系也会形成一个n×n维的矩阵A,称为邻接矩阵(adjacency matrix)。其中,n为节点的个数,m为节点初始特征的维度,X和A是GCN模型的输入,则GCN模型可用公式表示为
X(l+1)=f(X(l),A)
(2)
式中,X(l)为第l层节点的特征。
每个节点与邻节点关系为
(3)

由式(3)可知,每经过一层图卷积,利用节点与节点之间的联系和节点自身的特征进行聚合,可生成新的节点表示。在读出(Readout)操作中,采用均值汇聚的方式,将图中新的节点表示的均值作为图的表示,即
(4)
式中:N为图中的所有节点;xv是节点v的特征表示。xg对应的特征向量为VCFG。
3.3 融合
融合的方式很多种,常见的有逐点相加和向量拼接两种方式[18]。逐点相加的数学表达为,现有特征向量v1∈n和v2∈n,为了融合v1和v2,进行对应位置元素的相加,即v={xi|xi=v1[i]+v2[i],i=1,2,…,n}。进行此操作的前提是这两个向量的维度相同。
向量拼接是一个更为通用的特征融合方法,其数学表达为,现有特征向量v1∈n和v2∈n,则有融合特征向量v=[v1∶v2]∈m+1。对于融合机制的设计,考虑到提取的代码表征分别是从序列和结构的角度对函数进行的互补性描述,因此选择向量拼接融合的方式,将不同代码表征学习到的特征向量拼接成一个单一的特征向量。
源码分析工具Joern无法对所有的函数进行正确解析,导致生成的属性控制流图数量略微少于数据集中的函数数量。因此,先进行数据处理,将Token序列和属性控制流图进行一一对应。然后,将前面提取出来的特征向量VToken和VCFG直接拼接,得到特征向量Vs=[VToken∶VCFG],维度是384。最后,将特征向量Vs送入全连接层,并利用sigmoid实现二分类,得到标签的值,其中,0代表目标函数无漏洞,1代表目标函数有漏洞。
4 实验
4.1 实验环境与数据集
实验在RTX 2080Ti GPU的硬件条件与python 3.7的软件环境上运行,网络模型部分基于PyTorch框架和深度图谱库(Deep Graph Library,DGL)框架构建。使用VDISC(Vulnerability Detection in Source Code)漏洞数据集[13],该数据集共计包含127万余个C/C++函数。利用Clang[19]、Cppcheck[20]和Flawfinder[21]等静态漏洞分析工具扫描源代码得到每个函数标记,即是否存在漏洞以及漏洞对应的CWE(Common Vulnerabilities &Exposures)类型。处理生成的语料库中函数Token序列长度的分布情况如图6所示。可以看到,接近95%的Token序列的长度在400以下,约99%的Token序列长度不超过500。考虑到模型学习效率和函数语义覆盖的完整程度,S2FVD选取400作为默认的Token序列截断或补全的长度。

图6 Token序列长度分布情况
4.2 实验与结果分析
随机选取80%的函数作为训练集,20%的函数作为测试集。将PR(Precision-Recall)曲线、ROC(Receiver Operating Characteristic)曲线、马修斯相关系数(Matthews Correlation Coefficient,MCC)和F1值作为性能评估指标,对S2FVD的检测性能进行评估,并与文献[13]漏洞检测方法进行对比。S2FVD方法的PR和ROC曲线分别如图7和图8所示,两种方法的检测结果如表1所示。

表1 两种方法的检测结果
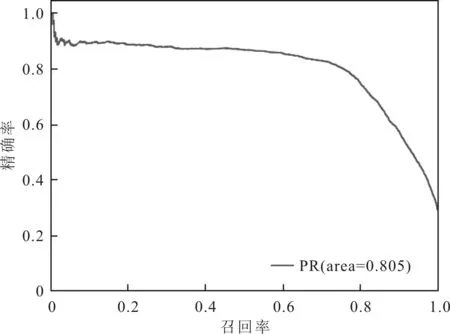
图7 S2FVD方法的PR曲线评估结果

图8 S2FVD的ROC曲线评估结果
由表1可以看到,S2FVD 方法的4种性能评估指标均优于文献[13]漏洞检测方法。其中,PR和ROC曲线下的面积(Area Under Curve,AUC)分别提高了28.7%和1%。特别地,F1值提高了21.7%。F1值综合考虑了精确率和召回率的计算结果,较全面地评价了分类器的性能,其值越大说明检测效果越理想。由此得出,S2FVD方法在漏洞检测方面优于文献[13]漏洞检测方法。这是因为S2FVD综合了Token序列和属性控制流图两种不同的代码表征形式,分别利用适配的表示学习模型学习函数语义的不同侧面并进行融合,使得抽取到的函数语义特征更加全面。
为了验证多表征融合对代码漏洞的检测效果好于单一表征,下面进行消融实验,对采取单一表征训练好的模型的检测效果进行评估。将Token序列通过TextCNN模型学习得到特征向量VToken,并送入分类层进行二分类训练,记为S2FVDToken方法。将属性控制流图通过GCN模型学习得到特征向量VCFG,且独立地送入分类层进行二分类训练,记为S2FVDACFG方法。将S2FVDToken和S2FVDACFG两种方法的检测结果分别与S2FVD方法对比,如表2所示。

表2 多表征融合方式与单一表征的检测结果对比
由表2可以看出,基于多表征融合进行漏洞检测的各项评估指标,均优于采用单一表征的情形。说明采用单一表征进行训练时,模型确实不容易充分学习代码所承载的语义信息,导致产生相对较差的检测效果。同时也可以推断出,从Token序列和属性控制流图中抽取的特征,会有一定程度的语义上的重叠,但这些特征不相交的部分,进一步提升了融合模型的漏洞检测能力。
S2FVD默认采取Word2Vec进行Token嵌入。考虑到FastText是另一种常用的词嵌入模型,这里对比采取不同Token嵌入模型时,S2FVD的漏洞检测结果。同时,考虑到Token序列长度是影响模型检测能力的关键参数之一,其决定了检测模型能够看到的函数语义的范围。对此,对比分析Token序列长度l在不同取值(300、400和500)时,S2FVD的漏洞检测结果。S2FVD采取不同嵌入方式和取不同l值时的检测结果如表3所示。

表3 采取不同嵌入方式和取不同l值时的检测结果
如表3所示,S2FVD在不同嵌入方式下的检测结果差异并不显著,表明Word2Vec或FastText均能充分学习Token的共现关系,生成品质区别不大的预训练嵌入向量。类似地,采取不同Token长度时,模型的检测性能也并未表现出明显变化。主要原因在于,S2FVD融合了TextCNN从序列中抽取的语义特征,以及GCN从ACFG中抽取的语义特征实现漏洞检测,而序列长度主要影响了TextCNN从Token序列中提取的部分漏洞相关的特征,表明多表征融合有助于降低模型对参数设置的敏感性。同时,采取Word2Vec进行Token嵌入,且Token序列长度l取值为400时,S2FVD模型表现出最优的漏洞检测性能。
5 结语
S2FVD方法基于函数中提取的Token序列和属性控制流图两种原始的代码表征结构,分别适配TextCNN和GCN神经网络模型进行语义特征抽取,并通过语义特征向量的拼接融合,提高了漏洞检测能力。在公共数据集上开展的实验结果表明,S2FVD相比文献[13]方法表现出更优秀的漏洞检测能力。消融实验结果表明,对多种代码表征结构进行融合学习是有必要的,检测性能优于仅使用单一表征结构的情况。
猜你喜欢
今日农业(2022年13期)2022-09-15
数字技术与应用(2021年5期)2021-06-29
电子科技(2021年2期)2021-01-08
计算机工程与设计(2020年11期)2020-11-17
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
中国卫生(2016年5期)2016-11-12
儿童时代(2016年6期)2016-09-14
