
基于大数据技术的铁路工务检测数据平台方案研究
2023-06-25 23:37:59许丹亚欧阳慎齐晨虹朱志尹文志
电脑知识与技术 2023年13期
许丹亚 欧阳慎 齐晨虹 朱志 尹文志

摘要:当前,普速铁路故障点检测手段多样,各种检测数据的类型多样,数据量大,查询分析逻辑复杂。不同于以往基于关系型数据库的数据处理,方案基于Hadoop大数据集群,采用低代码的形式和多种数据处理工具,设计实现工务数据同步、存储、查询、共享流程,降低了数据存储成本,提高了数据查询效率。同时,有助于后续其他业务系统的海量数据开发流程优化,为铁路各项业务提供稳定、高效数据处理方案。
关键词:大数据;Phoenix;DataX;铁路;Hadoop
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)13-0076-03
开放科学(资源服务)标识码(OSID)
1 引言
我国铁路系统正在进入大数据的时代,每天多个业务系统将产生海量数据,且数据量逐年增加[1-3]。近年来,中国铁路郑州局集团公司普速铁路故障点检测手段多样,包括晃车仪、轨检小车、人工添乘等。工务各种监测数据体量庞大,数据类型复杂,业务查询频繁,对后续海量数据的深度挖掘带来了一定困难。特别是,晃车仪数据主要依靠人工分析,郑州局全局192台晃车仪设备,每天产生几万条数据。因此,急需建立工务数据平台,优化工务各种检测监测数据的存储、分析、共享流程。
当前,有不少学者对铁路业务的大数据应用进行研究。卫铮铮等人,研究了客运大数据平台的铁路客流预测系统,集成了各类客流预测算法模型,为各类客运业务分析人员提供定制化客流预测数据[4]。王沛然等人,研究了铁路数据服务平台存储架构设计与应用[5]。王万齐等人,研究了京张高铁运营安全大数据平台设计及关键技术,对京张高铁安全数据共享共用、安全管理和安全预警能力提升,具有参考意义[6]。廉小亲等人,研究了面向建设期铁路大数据的分级存储方法,有效地对铁路建设期大数据进行存储级别判定,实现了面向建设期铁路大数据的分级存储[7]。
面对工务检测数据的数据量大、数据接入复杂、数据查询分析复杂等问题,常用的数据流程设计方案通常以软件代码开发的形式接入数据,采用关系型数据库实现对多种数据的存储和查询。但这种方案在应对超过千万级数据量时,往往会出现查询效率低下、存储成本高等问题。因此,本文以低代码的形式,基于Hadoop大数据集群和多种数据同步工具,设计并实现了工务大数据平台,打通数据同步与清洗、数据存储与查询、数据共享等数据处理流程,优化了数据处理手段,降低了数据存储成本,提高了数据查询效率。
2 总体方案设计
当前工务车载分析系统可接入的数据源,种类多、总量大、查询需求复杂,具体数据如下:
1) 数据种类多,同步情况不同
工务检测数据种类多,当前可接入的数据包括,晃车数据、轨检超限大值、便携添乘、轨检小车、人工添乘主表、人工添乘从表等。晃车数据,即晃车仪产生的数据,目前以每月几十万条的速度增加,同步频率为每半小时。轨检超限大值、便携添乘、轨检小车、人工添乘主表、人工添乘从表等其他检测监测数据,同步频率为每天,每天增量从几十到几百不等。
2) 数据查询需求复杂
针对各种检测监测数据,当前查询内容主要以检测时间、线别、行别、里程范围、垂直加速度、水平加速度等为主。在查询的形式上,大多是针对单一数据内容查询,也有少许联表查询的需求,这些联表查询往往业务逻辑复杂。
3) 数据量大
晃车数据的数据量为千万级别,其他数据的总量在几万到几百万之间。随着时间增加,各监测数据量在不断增大,也增加了服务器存储压力。
根據以上数据特征,按照数据的处理流程,本文设计和实现了基于大数据技术的铁路工务检测数据平台,主要包括数据同步、数据存储与查询、数据共享三部分,如图1所示。
3 数据同步与清洗
通过DataX、Sqoop等数据同步工具,从物理和逻辑层次上,把各种监测数据集中汇聚,完成数据同步与清洗,为后续大数据应用开发提供数据支持。由于数据内容中单位名称、线路名、里程值等存在不规范的现象,所以需要额外的数据清洗工作,规范数据内容。
首先,定时从远端Oracle服务器采集监测数据。之后,根据数据的种类、同步频率和查询需求,将采集后的数据分为晃车仪数据和其他检测数据。
对于轨检超限大值、便携添乘、人工添乘主表、人工添乘从表、轨检小车等数据,数据总量最大约为百万级,增量数据较小。采用现有数据同步工具DataX,将远端Oracle数据库同步到本地MySQL中,并设置定时增量数据导入任务[8]。DataX是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,可实现包括MySQL、Oracle、HDFS、Hive等各种异构数据源之间高效的数据同步功能。同时可集成插件,对同步的数据进行定制化开发,完成数据清洗功能。
对于晃车仪数据,总量较大,为千万级,且随时在增加。所以,数据同步分为全量同步和增量同步。全量同步,是将过去五年内所有数据一次性导入。这种操作较为耗时,且校验数据完整性复杂。增量同步是随着时间变化,将新增数据同步到本地数据服务器中。同时,需要做到实时同步,频率较高,而远端数据库中新增数据的时间和数量不固定。另外,数据内容中存在单位名称、线路名称等不规范情况,需要在接入时进行数据清洗操作。
根据晃车数据的数据量大和查询复杂的特点,方便设计后续存储和查询方案,即将晃车数据存储至Hadoop大数据平台,使用HBase上层查询引擎Phoenix提升查询速度。故,在接入全量晃车数据时,使用Phoenix组件自带lib库的现有数据导入工具CsvBulkLoadTool,底层执行分布式MapReduce任务并行导入,并同时对Phoenix二级索引进行更新。经测试,Phoenix MR方式导入一千七百万数据耗时10min左右,可快速导入大量数据,并保证数据的完整性。对于增量的晃车数据导入,采用数据同步工具DataX,定时获取某个时间段内增量数据插入到大数据集群中,并且在插入到集群之前,集成数据清洗插件Transformer,定制化转换数据内容。
4 数据存储与查询
对于轨检超限大值、便携添乘、人工添乘主表、人工添乘从表、轨检小车等检测数据,数据本身总量约为百万级,增量数据较小,采用MySQL存储,提供查询服务。
对于晃车数据,总量为千万级,增量相对较大。传统的关系型数据库MySQL难以支持数据的存储,后期维护也越来越复杂,急需能够存储大量数据且查询速度快的数据库。因此,适合采用分布式大数据集群存储。HBase底层应用分布式文件系统,在处理庞大表上十分有优势。由于HBase是分布式存储,为了优化存储性能和后续查询性能,防止数据倾斜问题,本文采用预分区HexStringSplit算法,根据Rowkey编码,HBase也会通过算法将其分到不同的Region,实现均匀分布,避免热点问题。
HBase本身是列存储,仅能查询单个字段值,不能满足业务系统对一条数据所有字段的详细查询需求,而Phoenix可将多列数据聚合为行,同时查询出多个字段值,使用体验上和关系型数据库类似。Phoenix是一个开源的HBase SQL层,支持二级索引、事务以及多种SQL层优化。二级索引可大幅度提升数据查询速度。
在创建索引时,根据业务查询需求,将常用的查询字段,包括检测时间、线编号、行别等,加入索引列中。同时,需要使用include语法,将其他未在索引中的字段包含[9]。之后,在查询过程中即可包含所有字段,满足对详细数据的查询需求。随着Phoenix表中数据持续增加,创建新的索引往往耗费大量时间。索引的底层原理仍是通过HBase特性,建立数据表,表的key由多个索引字段构成,value是对应数据的rowkey。因此,随着数据量的增加,索引的存储量也会增加。如果创建索引的时间超过Phoenix客户端的固定时间,将出现创建超时的问题。在后续使用中,如果需要创建其他业务相关的索引时,可以通过Phoenix的lib库中IndexTool工具,执行Mapreduce任务,创建异步索引。另外,在使用Phoenix提高查询效率时,需要注意时间类型的时区问题。Phoenix的数据类型默认时区是UTC,而日常多用GMT+8时区。在具体使用时,需要进行时区的转换操作。
为了进一步提升查询性能,根据HBase运行原理,进行修改HBase部分配置。对于HBase的Master,最大内存设置为当前机器内存的60%左右,最小设置为2G即可满足运行需求。对于HBase的RegionServer,内存设置为服务器内存的50%~70%。对于HBase的HFile,设置hfile.block.cache.size为0.5甚至0.6。同时参考hbase.regionserver.global.memstore.upperlimit,如果两值加起来超过80%~90%,会有内存溢出的风险。
5 数据共享
对于轨检超限大值、便携添乘、人工添乘主表、人工添乘从表、轨检小车等检测数据,数据存储在MySQL中,直接通过MySQL查询,使用JDBC连接共享至下游工务车载数据分析业务系统即可。
对于晃车数据,存储于大数据集群中,并通过HBase上层组件Phoenix优化查询。在数据共享时,虽然Phoenix提供通过JDBC连接的形式访问数据,但是,这种方式功能不够全面,多个系统之间集成交互困难,也不具备权限验证功能。因此,采用HTTP接口形式,可以较好地解决不同系统之间的交互需求。在传输数据时,采用POST方法而不是GET方法,对传输数据内容的大小更宽容。
由于查询条件不固定,如果根据不同的查询请求开发不同的接口,接口不具有灵活性,开发周期长,后续扩展性差。所以,参考常用持久层框架MyBatis,将通用查询功能总结为三种,查询所有详细信息list、查询分页信息page、和查询数据总量count,并将这三种功能开放为3个访问接口。
在传递查询参数上,本文封装了查询参数。查询参数内部包括查询属性和分页属性。查询属性中可包含多个查询条件。每个查询条件包括查询字段、查询关系、查询数值。分页属性包括页面大小和页码。因此,根据查询参数,即可组合多种查询条件,满足不同需求。
针对具有复杂业务逻辑的联表查询,需要额外的设计方式。虽然Phoenix本身提供联表查询功能,但是,在实际使用时发现Phoenix在联表查询时的一些缺陷。比如,联表查询的联查条件不能为大于或者小于,只能是等于。随着联表查询的复杂度增加,查询效率也会随之下降。因此,结合Phoenix索引查询效率高的优点和Java内存处理快的优点,本方案根据实际业务逻辑,先从大数据集群中,通过索引,以毫秒级速度获取单一表结构数据到内存中,然后,以代码的形式,根据联查条件,从内存中使用stream流筛选合适的数据。
6 应用结果分析
传统的业务系统存储数据时常用关系型数据库,例如MySQL、Oracle等。为了提高查询效率和缓解存储压力,本方案通过Phoenix组件,数据进行存储、查询、共享等流程。本章从存储压力和查询性能两个方面,对MySQL和Phoenix方式进行对比。
在存储层面上,对于存储相同数据量的晃车数据,使用MySQL存储容量为10.35GB,包含数据6.7GB,索引3.65GB。使用HBase存储容量为10.2GB,包含数据5.4GB,索引4.79GB。其中,HBase中的数据存储在HDFS中,副本为3。对于相同的数据,采用HBase存储容量略小于MySQL存储容量;采用HBase存储数据三重备份,容灾性更强。
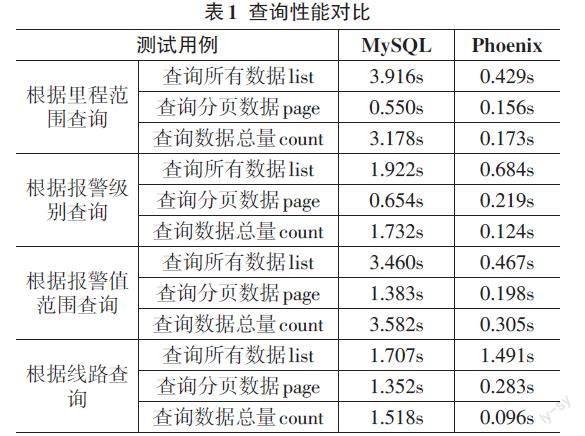
在查询性能上,使用4个测试用例,即根据里程范围查询、根据报警级别查询、根据报警值范围查询、根据线路查询,分别测试查询所有明細数据list、查询分页数据page、查询数据总量count的时间,如表1所示。对于MySQL,各个测试用例的查询时间范围在0到5秒。对于Phoenix二级索引,大部分测试用例的查询时间在500毫秒内,可做到秒级响应。
另外,随着数据量的增长,在MySQL中查询数据的时间将逐渐增加,而在HBase中存储的数据,借助Phoenix二级索引分布式查询,查询速度随着数据量的增加仍然保持恒定。
可得出结论,相比MySQL,使用HBase分布式数据库更适合存储晃车数据,使用相同的存储容量,HBase可存储更多数据,同时三重备份,提高了数据容灾性;使用Phoenix二级索引比MySQL索引平均提升查询效率为5倍,最高提升18倍,最低提升1.14倍。
7 总结与展望
本文提出一种针对工务监测数据的数据同步与清洗、数据存储与查询、数据共享各流程的技术方案。在数据同步与清洗方面,采用数据集成工具DataX,将多种监测数据汇聚接入。对于轨检超限大值、便携添乘、人工添乘主表、人工添乘从表、轨检小车表,使用关系型数据库MySQL进行数据存储和数据查询。对于晃车数据,使用分布式存储HDFS和HBase,使用Phoenix优化查询效率,并针对查询特点,设置数据共享HTTP接口。本文方案统一管理多种数据接入,降低了存储压力,提高了查询效率。方案经验证和试运行,使用便捷、性能出色,具有一定的应用和参考价值。
参考文献:
[1] 何欣玲,刘宇,赵天,等.铁路数据中心基础设施管理系统的研究[J].铁路计算机应用,2020,29(10):21-25.
[2] 马小宁,李平,史天运.铁路大数据应用体系架构研究[J].铁路计算机应用,2016,25(9):7-13.
[3] 宋一凡,张玉福.铁路运输清算系统运行实践研究[J].铁道运输与经济,2013,35(9):38-42.
[4] 卫铮铮,单杏花,王洪业,等. 基于客运大数据平台的铁路客流预测系统[J]. 铁路计算机应用,2022,31(1):37-42.
[5] 王沛然,马小宁,王喆,等. 铁路数据服务平台存储架构设计与应用[J]. 铁路计算机应用, 2021,30(5):5.
[6] 王万齐,刘军,李平,等.京张高铁运营安全大数据平台设计及关键技术[J].铁路計算机应用,2021,30(7):61-65.
[7] 廉小亲,杨凯,程智博,等.面向建设期铁路大数据的分级存储方法研究[J].铁路计算机应用,2022,31(2):17-22.
[8] 陈宇收.基于Datax的数据同步方案研究[J].电脑编程技巧与维护,2018(9):97-98,13.
[9] 刘文东. 基于Phoenix平台的空间数据索引与查询技术研究[D].西安电子科技大学,2018.
【通联编辑:王力】
猜你喜欢
云南画报(2021年12期)2021-03-08 00:50:54
铁道通信信号(2018年7期)2018-08-29 01:17:04
科技视界(2016年20期)2016-09-29 10:53:22
通信电源技术(2016年4期)2016-04-04 02:58:04
工程建设与设计(2016年3期)2016-02-27 10:50:46
