
基于LDA主题模型对电子商务专业岗位特征的挖掘
2023-06-25 23:37唐勇
电脑知识与技术 2023年13期
唐勇
摘要:文章使用Python语言基于LDA模型对电子商务专业的岗位特征进行挖掘。首先使用Selenium库对人才招聘网站的求职信息进行采集,分析整理了电子商务专业岗位的主要职位名称;然后对每个职位的岗位内容进行采集;使用skLearn机器学习库对岗位内容进行LDA建模,分析出电子商务岗位的五大主题即:管理能力、服务能力、设计能力、直播能力和薪酬待遇,并计算了每个岗位主题下的主要特征词汇,最后对这些主题进行了可视化处理,分析了各个主题的区别度和相关性。
关键词:主题模型;LDA模型;电子商务岗位
中图分类号:TP311.52 文献标识码:A
文章编号:1009-3044(2023)13-0069-04
开放科学(资源服务)标识码(OSID)
0 引言
人工智能、大数据及区块链等新兴技术正有力地推动着电子商务行业的新发展。例如网络商品的展示已经从早期的图片和文字转变为以短视频和直播为主要形式;商品的网络推广也从关键词推广转变为以人工智能和大数据为主要技术手段的智能推荐;售前和售后的客户服务环节则出现了智能客服机器人和智能语音应答等人工智能技术;在网店的运营数据分析方面人工智能算法和大数据处理技术也被应用起来。
电子商务行业的这些新变化引发了电子商务相关岗位技能的新变化,也对电子商务专业的人才培养提出了新的挑战。然而,不同的电子商务企业对电子商务岗位技能的要求不尽相同,本文使用采用LDA主题模型对招聘网站中的电子商务专业岗位进行数据分析,发现电子商务专业岗位技能的主题和特征词,从而为电子商务专业的人才培養提供借鉴。
1 LDA主题模型介绍
LDA(Latent Dirichlet Allocation) 是潜在迪利克雷分配的英文简写,属于无监督机器学习的一种算法,主要用于从大量文本数据中挖掘出潜在的主题信息。该算法认为每篇文档是由主题的多项式分布表示,称为文档主题分布;而每个主题是由单词的多项式分布表示,称为主题单词分布。文档的生成过程是对文档中每一个位置先由文档主题分布随机生成一个主题,然后由该主题单词分布随机生成该位置的单词[1]。
尽管PLSA(概率潜在语义分析)模型也采用了文档的主题分布和主题的单词分布,但是与PLSA模型的不同之处在于:LDA模型假定文档的主题分布和主题的单词分布都具有先验分布,并且这两个分布的参数都服从迪利克雷分布,而PLSA模型并没有使用先验分布。使用迪利克雷分布作为先验分布的好处是:一方面可以避免在参数学习过程中产生过拟合问题;另一方面是由于文档主题分布和主题单词分布都是多项式分布,而多项式分布的共轭分布是迪利克雷分布,因此可以直接推断出其后验分布也服从迪利克雷分布,从而方便了相关参数计算。
LDA模型算法中主题数K、文档的主题分布概率参数α及主题的单词分布概率参数β均为算法的超参数,需要预先设定。一般情况下,α和β的初始值可以设置为1/k,那么模型的主题数K就非常重要了。在自然语言处理中困惑度是评价语言模型的重要指标,效果越好的语言模型在测试数据集上的困惑度越小。通过计算不同主题数下困惑度的变化可以找出主题数K,当困惑度曲线出现拐点时的主题数K通常是较好的主题数。
2 LDA模型的语料库
网经社电子商务研究中心2022年发布的电子商务人才状况调查报告显示,企业对于电子商务类人才的需求主要有:运营类、视频直播类、客户服务类及网络营销类[2]。刘亚宁、侯海涛等人基于招聘网站的人才需求将电子商务的岗位类型分为商务类、管理类和技术类[3];曾奕棠采用岗位群的视角将电子商务岗位分为技术类岗位群、商务类岗位群及综合管理类岗位群,其中技术类岗位群包括了页面设计、网店美工、信息编辑等岗位,商务类岗位群包括了网络营销、网络策划与推广、客户服务等岗位;综合岗位类岗位群包括了客户服务经理、网店运营管理等岗位[4]。程丹和詹增荣基于胜任力模型并结合企业和相关院校的调研数据,将电子商务专业的岗位分为技术型和营销型,其中技术型人才核心岗位包括了网店美工、淘宝店长、网络运维和页面设计,营销型人才核心岗位包括了运营专员、推广专员和网络客户[5]。从上述企业和学者的研究结论可以看出:电子商务岗位主要集中于网店运营、网店美工、直播营销、客户服务等岗位。
招聘网站中汇集了大量的企业人才需求信息,能够真实反映企业的岗位技能要求。本文选取前程无忧作为LDA主题模型的数据来源。前程无忧网站是国内较有影响的人才招聘网站,该网站中的求职信息能够真实反映企业对电子商务专业的岗位技能要求。本文采用Python语言的Selenium工具包从前程无忧网站中获取总计2 000余条电子商务专业的岗位招聘信息。
Selenium是Web应用程序的自动化测试工具包,可以用代替人来模拟Web浏览器访问Web页面。由于Selenium是间接地调用浏览器并通过浏览器向目标网站发送访问指令,因此与真实用户访问Web页面没有本质的差异。通过对前程无忧网站的招聘列表页面进行解析,成功采集到电子商务相关岗位的名称及岗位对应的详情页网址,共计两千条数据。
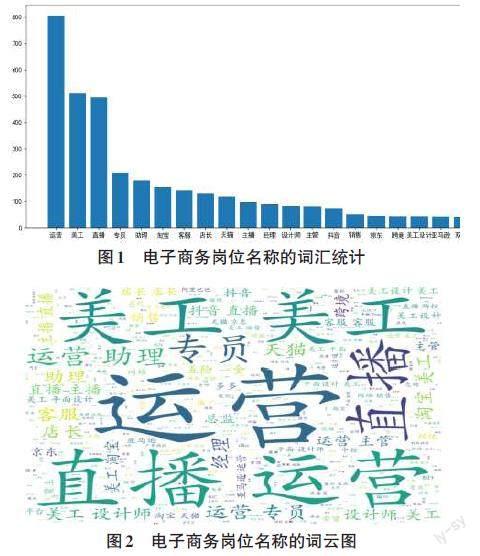
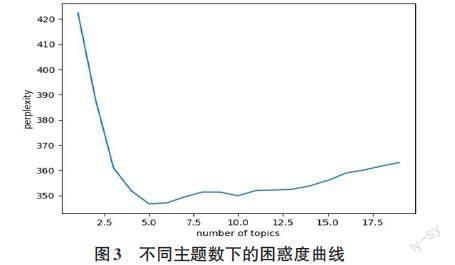
对于数据中的岗位名称信息,本文使用Jieba分词工具对齐进行中文分词处理,接着基于百度停用词表,过滤掉岗位名称中的一些常规词汇、停用词和长度小于两个字符的单字词汇;然后使用Panadas数据分析工具和Matplotlib绘图工具统计出岗位名称中的高频词,如图1所示;最后使用wordcloud工具包将上述词汇统计数据转换成词云图,如图2所示。可以看出在电子商务专业的岗位名称中运营、美工、直播等词汇出现的频率最高,其次是专员、助理、淘宝和店长等词汇。通过对岗位名称的词汇统计可以发现目前企业招聘电子商务专业人才的主要需求。
3 LDA模型的构建
对岗位名称的词汇统计仅能浅层次的分析电子商务岗位的主要聚集方向,但是对于深层次的电子商务岗位特征信息还需要采集每个岗位的详情页内容,挖掘每个岗位的职责和任职要求。本文使用Selenium工具包分批次采集了上述岗位详情页列表。使用Jieba分词工具对每个详情页文本进行了中文分词处理、过滤了常用停用词和长度小于两个字符的单字词汇,形成了电子商务岗位信息文档共计2 000篇,构成了LDA主题模型的文档集合。
LDA主题模型可以使用Python语言的gensim工具包或者sklearn库来实现。LDA模型的主题数K需要人为选定,通常是依据计算不同主题数K值下困惑度P的变化情况来确定主题数。但是gensim工具包并没有提供困惑度的计算,因此本文采用sklearn库实现LDA模型。sklearn库的decomposition模块含有各种数据降维的算法接口,其中LatentDirichletAllocation接口就是LDA主题模型的线性变分算法实现接口。LatentDirichletAllocation接口要求输入数据必须是特定格式的词频矩阵,矩阵中的每个元素表示为:(文档序号,单词编号,词频数),这里的文档序号将文档集合中的第1篇文档编号为0,依次编号;文档集合中的所有词汇集合构成一个词语列表,每个词从1开始依次编号;例如:词频矩阵元素(1923,1217,3) 表示的是第1924篇文档中编号为1217的词汇在该文档中总共出现了3次。使用sklearn的CountVectorizer类可以将之前使用Jieba分词工具得到的文档词汇列表转变文档词频矩阵。具体代码如下所示。
wordlist= [w for w in [" ".join(words) for words in wordlist]]
tf_vectorizer = CountVectorizer( max_features=1500, max_df =0.95, min_df =2)
tf = tf_vectorizer.fit_transform(wordlist)
上述代码中wordlist就是文档的词汇列表;CountVectorizer类的参数max_features=1500表示选取词汇表中词频数在前1500的词放入词频矩阵;参数max_df=0.95表示当某个词在所有文档中出现频率大于95%时该词不放入词频矩阵;参数min_df=2表示当某个词在所有文档中出现的频数小于2时,该词汇不纳入词频矩阵。max_df的设定实质上过滤了在所有文档中都使用的常用词,min_df则过滤了所有文档都极少使用的词汇。CountVectorizer类的fit_transform方法完成了将文档词汇列表转换为词频矩阵的过程。如果使用print方法打印fit_transform方法的返回值tf,可以查看到词频矩阵的每个元素。
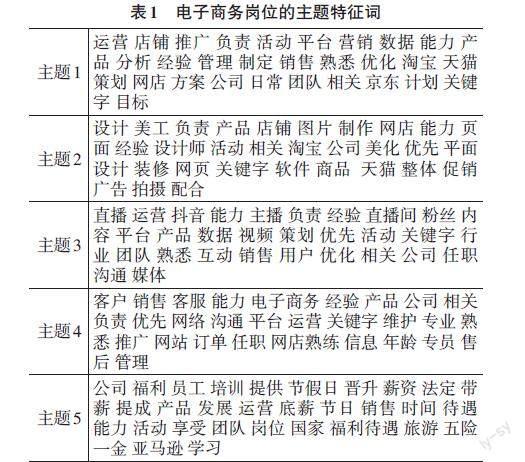
在计算出词频矩阵tf后就可以将其作为数据源,输入到LatentDirichletAllocation接口中训练LDA模型,但是LDA模型需要预设主题数K。根据前述电子商务岗位的名称词汇统计信息,本文将主题数K的范围设定在1到20的范围内,并计算不同主题数下模型困惑的数值,并使用matplotlib绘制出主题数与困惑度的曲线,如图3所示。可以看出当主题数K的值为5时,困惑度曲线出现了明显的拐点,因此,选择LDA模型的主题数K的值为5较为合适。
在设定了主题数K的值之后就可以将LDA模型中的文档的主题分布概率参数及主题的单词分布概率参数的值设置为1/K。构建LDA主题模型的主要代码如下所示。
lda = LatentDirichletAllocation(n_components=n_topics, max_iter=50, learning_method='batch', learning_offset=50, doc_topic_prior=1/ k, topic_word_prior=1/k, random_state=666)
lda.fit(tf)
在上述代碼中,LatentDirichletAllocation方法的参数doc_topic_prior代表的是文档的主题分布概率参数,而topic_word_prior代表的是主题的单词分布概率参数,它们的初始值都被设置为1/K,max_iter表示算法的迭代次数,其值为50,表示模型将应用线性变分算法迭代50次后计算出模型参数和的值。最后使用fit方法对词频矩阵tf进行数据拟合,完成了LDA主题模型的训练。
4 电子商务岗位的主题特征分析
经过训练LDA主题模型中包含有词汇表所有词汇在各个主题下的评分信息,可以通过lda变量的_component属性获取各个主题及对应的特征词汇评分。结合之前训练得到的文档词汇矩阵tf_vectorizer变量就可以得到每个主题下评分最高的特征词汇。计算每个主题下评分较高的特征词汇程序代码如下所示。
feature_names=tf_vectorizer. get_feature_names_out()
n_top_words=30
for topic_index, topic in enumerate(lda.components_):
topic_words= " ".join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]])
pprint(topic_ words)
tf_vectorizer变量的get_feature_names_out方法可以获取到语料库中的所有词汇。本文选择n_top_words=30表示在每个主题下选取评分最高的前30个词汇。获取的主题特征词汇见表1。
从获取的主题特征词汇表中可以看出,每个主题的特征词汇有明显的区别,部分词汇是各个主题都包含的。主题1可以概括为管理能力,其岗位的特征包括店铺的运营推广、平台的营销、数据分析能力、计划制定和管理能力及主流的电商平台(淘宝、京东和天猫)的运营经验;主题2可以概括为设计能力,其岗位特征包括产品和店铺的图片制作、美化和装修能力,促销、拍摄和配合能力等;主题3可以概括为直播能力,其岗位特征包括抖音的直播运营能力、有责任心和经验,熟悉直播间、粉丝、内容、产品、视频等直播元素,能够与用户互动、懂得沟通;主题4可以概括为服务能力,其岗位特征主要是客服能力、销售能力和经验、责任心和沟通能力,关键字维护和推广,对网店的熟悉、订单和售后的管理等;主题5是崗位的薪酬特征,包括岗位的福利待遇、职业发展空间、员工薪酬工资等方面。除了主题5之外其他主题都与电子商务专业的岗位技能要求有关,可以作为岗位的特征信息。
基于模型获取的主题和主题的特征词汇,本文使用pyLDAvis库对LDA主题模型进一步展开可视化分析。pyLDAvis库是可视化交互式的主题模型展示工具。pyLDAvis库的lda_model类接收参数包括:已训练完的lda模型、词频矩阵tf及文档词汇矩阵tf_ vectorizer,并调用show方法完成LDA模型的可视化展示。最终的LDA模型可视化效果如图4所示。图中左侧的五个圆分别表示五个主题;选择每个主题可以得出该主题下评分较高的前30个主题词;图中深色水平条块表示该词汇在此主题下的频数,而浅色条块表示该词汇在全部文档的频数。
可视化分析的结果可以看出主题2(设计能力)和主题5(薪酬特征)与其他主题有明显的区别度,这是由于设计能力和薪酬特征的相关词汇较为专业,与其他主题没有太多的相关性;而主题1(管理能力)、主题3(直播能力)和主题4(服务能力)具有一定的重合度。尤其是主题1和主题4有较大的重合,这也表明了电子商务的运营、推广和客户服务、售后服务具有较大的相关性,而直播能力相对较为专业和独立。
5 总结
本文通过LDA模型分析电子商务专业岗位的潜在特征,基于特征词汇的评分概括为五个主题,即:管理能力、服务能力、直播能力、设计能力和薪酬特征,其中,管理能力和服务能力具有较多的重叠特征词汇,而直播能力和管理能力具有较小的重叠特征词汇,但是直播能力、服务能力和设计能力彼此具有相对对立的特征词汇,这为电子商务专业的人才培养方向提供了一定的借鉴。在后续研究中需要扩大并优化模型的数据源,以期进一步分析主题间的重叠特征词汇,发现新的特征,另一方面对LDA模型自身的局限性要结合其他模型进行优化,以期提升主题划分的精确性。
参考文献:
[1] 李航.统计学习方法[M].2版.北京:清华大学出版社,2019:391-393.
[2] 网经社中国电子商务研究中心.2021年度中国电子商务人才状况调查报告[EB/OL].(2022-05-22)[2022-10-19].http://www.100ec.cn/detail--6611176.html.
[3] 刘亚宁,侯海涛,孙东阳,等.基于招聘网站的电子商务岗位能力要求研究[J].现代商业,2022(10):65-67.
[4] 曾奕棠.基于岗位群的电子商务专业大学生就业能力研究[J].电子商务,2018(1):70-71.
[5] 程丹,詹增荣.基于胜任力模型下高职电子商务人才职业岗位能力及素质研究[J].电子商务,2018(6):67-69.
【通联编辑:谢媛媛】
