
基于K-means算法的RFM模型的客户细分研究
2023-06-25 23:37:59魏建兵
电脑知识与技术 2023年13期
关键词:数据挖掘
魏建兵

摘要:客户决定着企业存在的价值,能否满足客户需求是公司商业运作成功与否的关键所在。在复杂多变的市场情形中,只有那些了解客户,把握市场变化,学习使用现阶段先进的管理理论,将信息技术与数量分析方法相结合,对现有市场情况进行数据分析與决策的企业才可能成为市场的赢家。因此,愈来愈多的企业将关注的重点从以产品为中心的商业模式向以客户为中心的新型商业模式转移。该文通过结合RFM理论,运用数据挖掘,进行聚类分析并提取出相关规则,证明基于RFM模型的组合数据挖掘技术进行客户细分及规则挖掘是有效的。
关键词:K-means;RFM;客户细分;数据挖掘
中图分类号:TP391.9 文献标识码:A
文章编号:1009-3044(2023)13-0073-03
开放科学(资源服务)标识码(OSID)
0 引言
H公司其主要产品是各类型电流稳压器,是国家稳压器定点生产厂家之一,具备全系列交流稳压器的生产经验。H公司同众多企业一样,迫切需要解决的一个问题也是其业务过程中累积的大量数据需要分析处理。H公司在数据分析处理中进行了三次数据处理:第一次为数据报表的统计阶段,业务人员利用一些常用的计算机相关的统计软件,对企业相关的静态数据进行分类统计,这些数据将成为企业领导进行最终决策的重要依据;第二次是联机事务处理或联机分析处理阶段,这个阶段对统计报表进行优化,会进行一些多维分析及原因分析,如分析调查今年以来哪些产品是最有利润的?最有利润产品是不是和去年一样?同时,进行一些简单的预测功能,如销售量的预测等;第三次是数据挖掘技术的应用,公司对经营运行过程汇总产生的数据,利用数据挖掘工具建立数学模型,如聚类模型、分类与预测、K-means[1],快速聚类,系统聚类等。
1 数据的分析过程及方法
文章利用衡量客户价值和客户创造利益能力的RFM模型[2],对相应客户进行分析工作。第一步,预处理相关的数据集;第二步,利用RFM模型,利用聚类分析方法,输入近度、频度、值度,输出客户价值;第三步,利用数据挖掘相关算法,对每个类别的规则特征进行分析提取;第四步,客户信息的结果描述,输出按照类型分类的客户规则,客户数据库为最近购买时间、购买频率和总购买金额等。
1.1 数据预处理
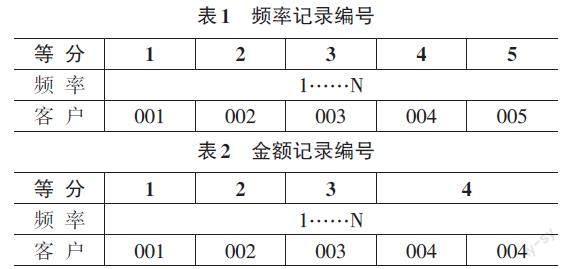
排序处理对消费金额(值度)、购买频率(频度)分别进行排序,见表1和表2。
1.2 市场细分
温德尔·史密斯(Wendell R·Smith) 在其 1958 年发表的《市场营销策略中的产品差异化与客户细分》一文中指出:市场细分是指企业按照客户属性将客户群体分为若干个子客户群体,细分后客户群体之间的差异最大化,每个客户群体尽可能相似[3]。
为进一步有效地挖掘不同类别客户,利用聚类分析对客户数据进行有效分析,输出不同类别客户所隐藏的信息。针对不同客户,企业利用这些信息可以采取不同的营销策略,根据企业贡献度的高低,优选相应的客户类别,并在持续做好贡献度高的客户的同时,将贡献度较低类的客户通过优化策略发展成为贡献度高的客户[4]。
基于RFM的聚类分析可以按以下步骤进行:
第一步:确定聚类算法[5],将数据集D划分为若干个类C={C1,C2,...,Cp}。其中,D=C1∪C2∪...∪p;
第二步:选取:近度R(Re-cency)、频度F(Frequency)和值度M(Monetary Value)。
第三步:对每一个Ci,i=1,2,...,p,归纳出能描述其特征的一条或几条规则。
1.3 规则的挖掘
数据挖掘最关键的步骤就是挖掘数据库中的潜在规则。可以利用数据挖掘工具完成,这也是数据分析过程的关键所在。
2 建模仿真
本案例采用TipDM 数据挖掘在线建模平台中的k-Means聚类分析[4]和Apriori关联规则挖掘等算法进行模型构建。
2.1 数据预处理
在C-company业务数据表中共收集了2019年到2022年的客户交易记录,删除冗余。转变成合适的格式,保存规范的业务记录,业务记录表包括最近购买时间、购买频次和总购预买金额等。对原始数据进行预处理得到合适的格式,详细步骤如下:
1) 定义RFM的取值范围[6],如划分为5等份,分别为5至1等。对于R-Recency值,如最近合同时间是2022年定为5,2021年定义为4,依此类推。对F-Frequency、M-Monetary也分别类似处理。
2) 对客户数据表中的每一条客户记录量化以后,得到RFM 量化结果,包括客户ID、R-Recency、F-Frequency、M-Monetary。
3) 分别评估R(近度)、F(频度)、M(值度)的权重,事实上它们的权重应该是相同的。
2.2 K-means聚类分析
预处理后产生的RFM数值,利用聚类方法对各大区的x个客户分5类得到的初始聚类中心值为:C1(3.21, 1.38, 1.76) C2(1.84, 1.24, 1.70)
C3(1.95, 1.27, 1.11) C4(2.29, 2.13, 3.78)
C5(1.89, 1.22, 1.08)
然后,运用K-均值聚类算法[3],完成数据集的聚类分析,这样,我们就得到了每一个客户所属的聚类类别,通过聚类方法找到了对企业具有重要价值的客户[7]。
2.3 特征规则提取
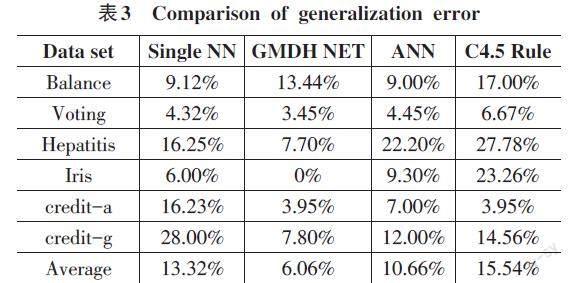
选取UCI数据集中balance scale ,congressional voting records, hepatitis, iris plant , statlogaustralian credit approval及 statlog german credit共六个数据集作为实验数据集,分别应用Single NN(single neural network)方法、GMDH网络方法(Knowledgeminer) 、神经网络方法(Clementine) 、C4.5决策树方法(weka)进行对比分析。将每一个数据集分成5部分,以每一个为检测集,其他四个为学习集,五次运行后的平均结果为最终结果。
对于balance-scale数据集,按顺序选取500个样本构成学习集,125个样本构成检测集,运用GMDH网络分类得到的结果是:学习集中47个错误,错误率9.4%;在检测集中8个错误,错误率6.4%。再分别任选一部分作检测集,其余四部分作为学习集重复运行五次,对检测集中分类错误平均,得到检测集中平均错误率为13.44%(5次共84个错误)。
提取的 L 类特征规则是:
IF NOT - A1& C1 OR NOT - B1&D1
THEN L
如果左、右两边重量都不是1,或者左、右两边距离都不为1,则属于L类。
对于其他数据集,使用不同方法同样处理,得到分类错误率如表3所示。同样,对于连续型属性,将某个连续属性的取值分成若干个区间,将连续属性离散化,再建立规则输入输出模型。
上面列出一些错误情况对比,可用Friedman统计检验方法对各算法之间是否有显著差异进行判断。设[rji]是第j个算法在第i个数据集上的排序,Firedman检验比较各种算法的平均排序[Rj=1Nirji]。Firedman检验的零假设是各算法表现是一样的,即它们的平均排序相同。
Firedman检验:
[x2F=12Nk(k+1)jR2j-k(k+1)24],服从自由度为k?1的卡方分布。在此基础上,Iman 和 Davenport指出Firedman过于保守,他们提出了另一种更好的统计检验:[FF=(N-1)x2FN(k-1)-x2F]服从自由度为k?1和(k?1)(N?1)的F分布。
引入秩后表后,GMDH网络方法要好于其他三种方法,因GMDH的平均秩为最大,所以可用Holm方法對算法进行进一步的检验。Holm检验从最显著的p1值开始,如果p1<α/(k?1),拒绝相应的零假设,同时进一步比较p2和α/(k?2),如果第2个假设被拒绝,则继续第3个比较,直至被接受为止。令[z=(Ri-Rj)k(k+1)6N],z值用于从正态分布表中查找相应的概率值([p(x≥z)=2*(1-p(x≤z))]) ,然后将概率值与相应的α(0.05)进行比较。
从Holm检验可以看到,0.004<0.017,显然, C4.5 Rule要劣于GMDH方法。但由于0.072>0.025,0.116>0.05,因此,在95%的置信度下不能拒绝零假设,即神经网络方法劣于GMDH方法并不明显。
通过实验,GMDH网络方法具备较好的特征提取能力,由于需要预先知道样本的类型,所以在企业面对众多客户的情况下,结合聚类和GMDH网络进行特征规则挖掘是一种有效而实用的方法。在本例中,通过TIPDM完成对客户进行聚类分析后,我们就知道了每个客户分别属于哪类客户(客户价值),然后在此基础上运用GMDH网络方法提取出一些规则特征。这样,聚类后通过提取规则,就从客户关系数据库中得到了一些描述规则,这些规则概括了数据集中不同概念的特征,从而使公司的营销活动更有针对性。有了这些特征规则,决策者可以作出一个正确的销售和广告宣传决策[6]。
2.4 Apriori算法产生强关联规则
2.4.1 算法过程
通过Apriori算法,对数据库的多次扫描来发现所有的频繁项目集,在每一次扫描中只考虑具有同一长度(即项目集中所含项目的个数)的所有项目集,在第一次扫描中计算所有单个项目的支持度,生成所有长度为1的频繁项目集。在后续的每一次扫描中,首先以K-1次扫描所生成的所有频繁项目集为基础产生新的候选项目集。然后,扫描数据库,计算这些候选项目集的支持度,删除其支持度低于用户给定的最小支持的项目集。最后,生成所有长度为K的频繁项目集。重复过程,直至再也找不到新的频繁项目集为止[8]。产品项目表如表4所示。
这样,就得到一个频繁 3 项集{SBW?30,SBW?50,SBW?100},它的所有非空真子集有:{SBW?30},{SBW?50},{SBW?100},{SBW?30,SBW?50},{SBW?30,SBW?100},{SBW?50,SBW?100},设最小置信度为50%,则可以输出强关联规则如:SBW?50?SBW?30∧SBW?100,置信度(2/3=67%) ,支持度(2/3=67%) 。
2.4.2 TIPDM挖掘关联规则
通过TIPDM对 Apriori算法的实现,就可以从销售数据库中挖掘出关联规则了。如计算得到的{SBW?30 SBW?50 SBW?100}及{SBW?100 SBW?180 SBW?400},均为支持度大于2的频繁3项集,同样可以计算出各个产品间的置信度。例:SBW?100?SBW?180∧SBW?400,因SBW?100的支持度计数为38,而SBW?180∧SBW?400的支持度计数为2,即SBW?100?SBW?180∧SBW?400的置信度(2/38=5.26%) ,购买SBW100的5.26%的客户,可能性会同时购买SBW180和SBW400,但由SBW?180?SBW?400置信度(10/18=55.56%),即购买了SBW180的客户很可能(55.56%的可能性)会同时购买SBW400。这样,企业就可以据此采取相应的促销措施,开展交叉销售活动,从而促进更多产品的销售,更好地满足客户需求。
3 结论
随着世界经济一体化进程的加速,企业可利用数据挖掘技术进行客户特征规则提取及关联规则挖掘。利用RFM模型,聚类方法,通过对神经网络方法、C4.5方法及GMDH网络方法在六个UCI数据集上的比较实验,确认几种算法之间是有差异的,并指出结合聚类(客户细分)与GMDH网络方法建立模型,从而提取出特征规则是比较理想与可行的一种方法。
综上,文章通过运用组合数据挖掘技术,将改进的K-means方法用于客户细分,结合聚类与GMDH网络提取客户特征规则及Apriori挖掘出产品的关联规则,证明进行客户细分和规则挖掘是有效的。
参考文献:
[1] 李明倩,王苗,刘芳.改进k-means的电网控制自动化系统数据聚类方法[J].机械与电子,2023,41(3): 34-38.
[2] 程汝娇,徐鸿雁.基于RFM模型的半监督聚类算法[J].计算机系统应用,2017,26(11):170-175.
[3] 李明杨.基于无监督K-means聚类方法的移动公司客户细分研究[J].通讯世界,2019,26(2):8-10.
[4] 谢鹏寿,张宽,范宏进,等.汽车4S店TFM客户细分模型及其方法研究[J].小型微型计算机系统,2019,40(10):2165-2169.
[5] 才东阳.基于K-means聚类的计算机网络信息安全风险评估方法[J].网络安全技术与应用,2022(11):30-31.
[6] 赵伟.基于RFM模型X公司客户关系管理研究[D].北京:北京化工大学,2018.
[7] 白燕燕.基于客户细分的潜在高价值客户挖掘实证研究[D].兰州:兰州财经大学, 2017.
[8] 杨一男.基于数据挖掘技术的B2C企业客户关系管理研究[D].沈阳:沈阳工业大学,2016.
【通联编辑:代影】
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
中国交通信息化(2020年1期)2020-07-27 02:50:04
电力与能源(2017年6期)2017-05-14 06:19:37
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
信息通信技术(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
河南科技(2014年19期)2014-02-27 14:15:26
电子设计工程(2014年18期)2014-02-27 12:00:13
电子设计工程(2014年18期)2014-02-27 12:00:12
智能系统学报(2013年1期)2013-01-28 10:16:55
