
基于动态数据集重发布的隐私保护研究
2023-06-25 15:43陈虹云姬娇娜倪杰史雨轩梅香香
现代信息科技 2023年8期
关键词:隐私保护
陈虹云 姬娇娜 倪杰 史雨轩 梅香香

摘 要:近年来,随着大数据技术和网络信息技术的迅猛发展,越来越多的信息在网络中传播和分享。在数据挖掘与分析技术的不断进步下,人们可以快速且有效地从海量的信息数据中提取出潜在的、有价值的信息。但是,从发布的数据中依旧可以挖掘出大量的隐私信息,这些信息一旦被有目的地利用和关联,就会造成隐私信息的泄露,后果将不堪设想。在现实生活中,真实的数据集都是动态的数据。因此,对于在数据发布中隐私保护技术的研究具有极其重要的意义。
关键词:动态数据集;隐私保护;重发布
中图分类号:TP393 文献标识码:A 文章编号:2096-4706(2023)08-0111-03
Abstract: In recent years, with the rapid development of big data technology and network information technology, more and more information is disseminated and shared in the network. With the continuous progress of data mining and analysis technology, people can quickly and effectively extract potential and valuable information from massive information data. However, a large amount of private information can still be mined from the published data. Once such information is purposefully used and associated, it will cause the disclosure of private information, and the consequences will be unimaginable. In real life, real datasets are dynamic data. Therefore, the research on privacy protection technology in data publication is of great significance.
Keywords: dynamic dataset; privacy protection; republication
0 引 言
目前,在数据库的应用领域中存在着大量与个人隐私相关的信息即原始数据。有些保险公司可能会因为被保人状态的不断变化而需要定期更新数据库。但是,假设在变化后不进行一定的操作和处理,直接发布和分享一些信息,就会导致个人隐私信息的泄露,甚至不可预计的后果。而社会上有很多研究机构需要通过这些数据进行科学研究,从而发現一些社会问题并及时处理。例如,保险公司需要定期检查保险记录,这可能涉及到个人隐私信息。因此,数据隐私保护技术在现实中起着重要的作用和意义。其中,动态数据集重发布中的隐私保护在现实中得到了越来越广泛的应用,相应的隐私保护模型的研究也得到了进一步的发展。然而,现有的动态数据集重发布隐私保护模型在动态数据集的重发布过程中大多存在一些不足和缺陷。
1 国内外研究现状
近些年来,经过专家学者的研究和改进,匿名化技术得到了迅猛的发展。Wong等人经研究后提出了(α,k)-匿名模型,它为每个等价类的敏感值设置了统一的频率约束,要求每个等价类的任意一个敏感属性值出现的频率不大于α。王晓耘等人经改进后提出(α,k)-MDAV模型,该模型是通过在大小可变的等价类上增加频率约束的方法来实现敏感值个性化保护的目的。史丽燕等人通过微聚类技术对个人背景数据进行分类处理,可以为个人信息的隐私保护提供精确的数据基础。杨晓春等人也随之提出多约束的k-anonymity匿名模型—Classfly+,其中包括朴素算法、完全IndepCSet和部分IndepCSet这三种算法。但以上匿名模型都不能满足动态数据匿名发布的需求。静态数据匿名发布方面的研究已经日趋完善。但是,在现实生活中数据是瞬息万变的,不断有数据需要进行多样发布、系列发布和连续性发布。因此,对于动态数据匿名发布的研究得到了越来越广泛的关注,成为了隐私保护研究的热门话题。
2 隐私保护模型的设计
匿名重发布的其中一个基本原则是保持数据的及时性。如果匿名重发布存在延时发布或者是不发布,那么很有可能就会因为这些原因导致有些机构根据其研究的成果造成偏差,从而导致很严重的后果。匿名重发布的另一个基本原则就是尽可能提高数据的可用性。如果匿名重发布之后的数据完全无可用性,那么将会失去匿名重发布的意义了。综上几点,匿名重发布的基本原则是安全性、及时性和可用性。
本文的动态数据集重发布模型为每个等价类的敏感值设置了统一的频率约束,满足了数据多样性的要求。本模型包括三部分:新增、删除和修改。
2.1 新增模块设计
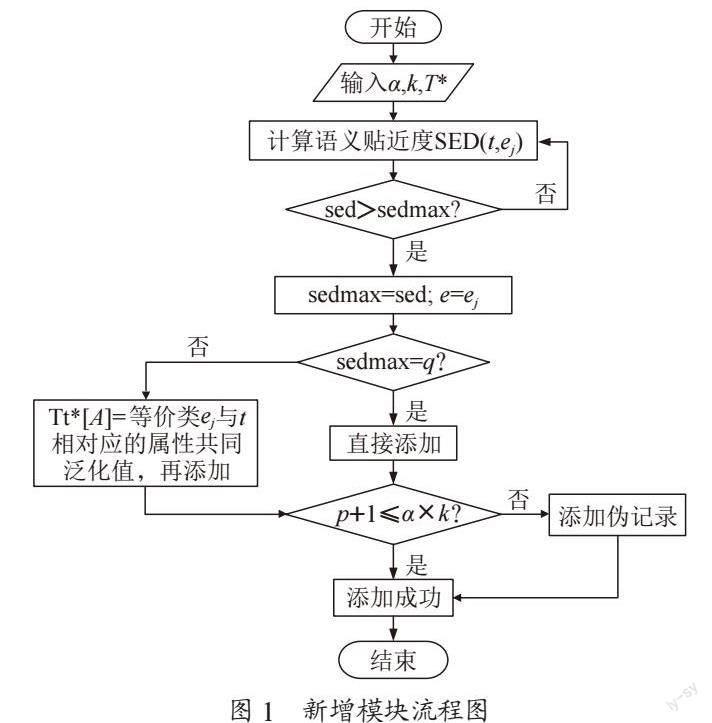
新增模块的主要功能是向已发布的数据集T*中新增数据集T。第一步设置阈值;第二步计算元组t与其等价类的语义贴近度;第三步根据计算结果选择语义贴近度值最大的等价类;第四步判断语义贴近度最大值跟准标识符属性个数q是否一致,再决定是否新增数据;第五步判断匿名数据集是否满足匿名约束。如果满足约束条件,那么新增成功;如果不满足约束条件,那么需要加入伪记录来满足约束条件。图1为新增模块的具体流程图。
2.2 删除模块设计
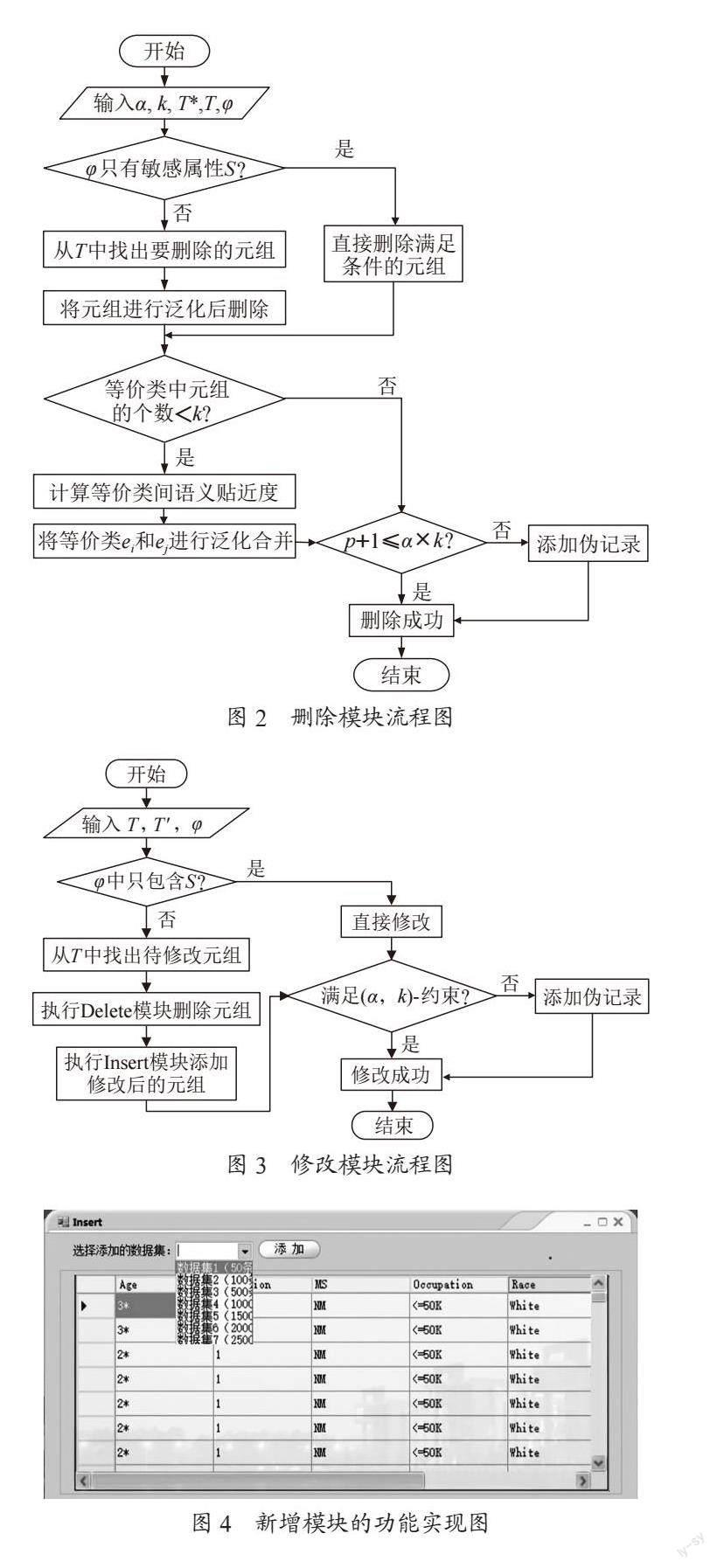
删除模块的主要功能是从已发布的匿名数据集T*中删除数据。第一步设置阈值;第二步通过删除条件φ以及元组和泛化元组的映射关系,确定对删除的元组进行定位;第三步删除数据;第五步进行等价类个数的判断。如果等价类个数小于k,那么跟语义贴近度最大的等价类进行合并。第六步判断是否满足匿名约束,如果不满足,再进行调整。图2为删除模块的具体流程图。
2.3 修改模块设计
修改模块的功能是根据实际需要对原始匿名数据集中的数据进行对应的修改。修改模块的功能是从已发布数据集中修改数据。第一步如果修改条件中只包含敏感属性,那么根据删除条件和元组的映射关系来对所需修改数据所在的等价类进行定位再直接进行修改;第二步当修改条件中包含准标识符属性,将修改操作拆分为删除操作和插入操作。先进行删除模块删除元组,再进行新增模块添加修改后的元组;第三步判断是否满足约束条件,如果满足条件,那么修改成功;如果不满足,那么加入伪数据直至满足匿名條件。修改模块的主要流程如图3所示。
3 隐私保护模型的实现
3.1 新增模块实现
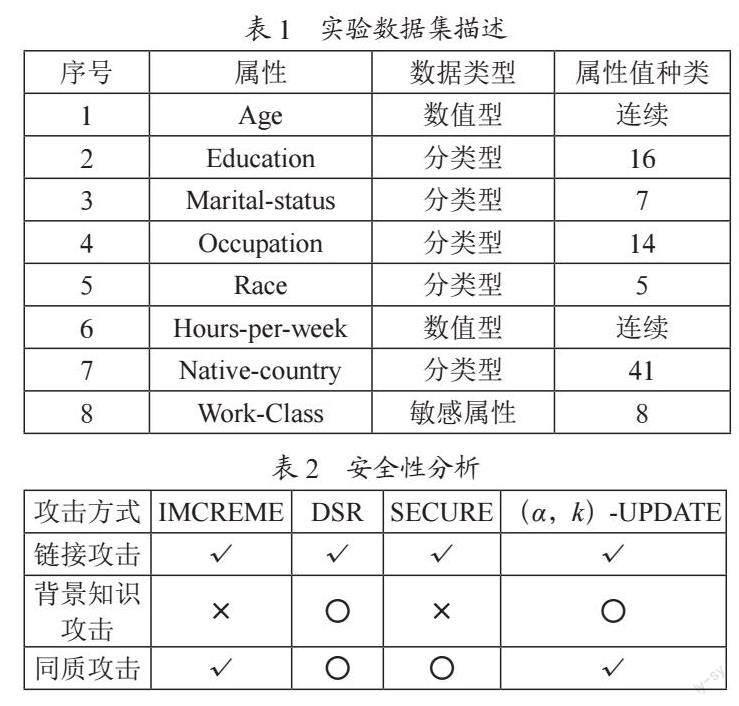
用户在“发布”功能中预先设定好k值、阈值α和需更新的数据集后,点击主菜单中的“添加新数据”,就会弹出新增模块的操作界面,如图4所示。在操作界面中,用户可以选择不同的数据集作为待添加数据集进行添加操作。为了后期实验数据分析本系统预先设定了7种数据集来进行实验。
3.2 删除模块实现
用户在主界面中选择“删除数据”来执行删除模块,如图5所示。用户需要在8个文本框当中填写删除数据的条件,删除模块根据用户输入的删除的条件进行整合,取交集来执行删除命令。用户在文本框中输入删除命令的时候,系统会检查用户的输入值的合法性。在点击“删除”按钮后,如果任何文本框中的值都不符合输入规则,系统会提示用户重新输入。
3.3 修改模块实现
修改模块的功能是根据实际需要对原始匿名数据集中的数据进行对应的修改。如图6所示,表示修改模块的功能实现图。用户可以将修改条件填入功能界面的文本框当中。
4 隐私保护技术性能评估
4.1 实验数据来源
实验数据采用UCI的人口统计实际数据集中的Adult数据集,实际数据集来自http://kdd.ics.uci.edu。实验采用
“Adult”数据集来模拟实际生活中不断更新的医疗数据集。将收集到的数据经过过滤,去除空值处理之后,导入到EXCEL中,其中一共包含48 842条数据记录,14个敏感属性数据值。
4.2 实验数据设置
Adult标准数据集共有48 842条数据记录,在经过预处理之后为45 222条数据。本次试验取其中的8个不同的属性:{Age,Education,Marital-status,Occupation,Race,Hours-per-week,Native-country,Work-Class},其中“Work-Class”作为敏感属性,其余7种属性作为准标识符属性,如表1所示。
4.3 实验安全性分析
将从几种常见的攻击方式方面来对本文的匿名模型进行安全性分析,如表2所示(“√”代表抵抗效果好,“○”代表抵抗效果一般,“×”代表抵抗效果较差)。
实验结果表明,本文提出的面向动态数据集发布的匿名模型以及根据其相应的更新设计与实现的动态数据集匿名发布系统,对于数据规模较大、数据增减量相对较小、数据更新频繁的动态数据集,在能够保证动态数据的同步性和真实性方面有着明显优势,尤其是对于更新数量较少的动态数据集,能够在保证其数据精度的同时,有效地保护隐私信息安全。
5 结 论
随着信息共享技术和数据挖掘技术的不断发展,在网络中传播和共享的数据也在逐渐递增。其中的数据中往往会包含大量个人和企业的隐私信息,这些信息一旦被有目的地利用和关联,就会造成隐私信息的泄露,后果将不堪设想。本文主要研究在动态数据发布中的隐私保护的相关技术,提出了一种动态数据发布的匿名模型,并且提供了一个完整的动态数据发布的模型及实现。但是,本文提出的模型还存在着不足,今后还需要进一步地研究和提高。
参考文献:
[1] 白雨靓,李晓会,陈潮阳,等.面向轨迹数据发布的优化抑制差分隐私保护研究 [J].小型微型计算机系统,2021,42(8):1787-1792.
[2] 王明月,张兴,李万杰,等.面向数据发布的隐私保护技术研究综述 [J].小型微型计算机系统,2020,41(12):2657-2667.
[3] 梁文娟,陈红,吴云乘,等.持续监控下差分隐私保护 [J].软件学报,2020,31(6):1761-1785.
[4] 杨旭东,高岭,王海,等.一种面向直方图发布的均衡差分隐私保护方法 [J].计算机学报,2020,43(8):1414-1432.
[5] JIN Y. Disclosure and protection of personal privacy data in the era of big data [J].Journal of Tongji University ( Social Science Edition),2020,31(3):18-29.
作者简介:陈虹云(1993—),女,汉族,江苏南通人,讲师,硕士,研究方向:信息安全、计算机技术。
猜你喜欢
现代营销·学苑版(2016年12期)2017-01-23
计算机应用(2016年12期)2017-01-13
无线互联科技(2016年13期)2017-01-10
软件导刊(2016年11期)2016-12-22
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
新闻界(2016年15期)2016-12-20
企业导报(2016年20期)2016-11-05
电脑知识与技术(2016年21期)2016-10-18
