
基于特征提取和随机森林的接口服务异常值检测
2023-06-22 06:02:37左金虎肖忠良陈理华
现代信息科技 2023年5期
关键词:随机森林
左金虎 肖忠良 陈理华

摘 要:文章提出了一种提取一维统计学中的特征作为属性,通过随机森林进行训练的有监督学习的异常检测方法。作为属性的特征有标准分异常值、格拉布斯异常值、中位数方差异常值和平均偏离值等。现阶段一般采用无监督模型和集成学习的方法来检测异常值。文章提出的方法就是基于现阶段方法做的一个升级版本,能检测出大部分跨区换卡、套餐变更和个人开机的中国移动业务接口服务异常值。
关键词:随机森林;一维特征提取;有监督学习;业务接口服务异常值
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)05-0163-04
Detection of Interface Service Outlier Based on Feature Extraction and Random Forest
ZUO Jinhu, XIAO Zhongliang, CHEN Lihua
(China Mobile Information Technology Co., Ltd., Beijing 102200, China)
Abstract: This paper proposes a outlier detection method with supervised learning that extracts features in one-dimensional statistics as attributes and trains through Random Forest. The features as attributes include standard score outliers, Grubbs outliers, median variance outliers, and mean deviation values. At this stage, unsupervised models and ensemble learning methods are generally used to detect outliers. The method proposed in this paper is an upgraded version based on the method at current stage, which can detect most of the outliers of China Mobile business interface services such as cross-regional card replacement, package change and personal boot.
Keywords: Random Forest; one-dimensional feature extraction; supervised learning; business interface service outlier
0 引 言
在运维监控的领域中,时序数据一般有三种类型:周期型、阶梯型和无规律型。一般涉及具体业务的,比如在线用户数量,业务量等有较为明显的,以日、周、月、节假日为周期的规律。 以磁盘使用率为代表的时序数据一般为阶梯增长,而CPU使用率、内存使用率则大多为无规律型。目前针对这些时序数据的检测算法一般可分为三类:
第一类是基于经验阈值的检测方法,这过于依赖专家知识,需要专家在部署监控程序时指定阈值,指标数值超过阈值时则为异常。
第二类是基于有监督的方法,比如xgboost、logistic回归、随机森林、神经网络等方法。这类有监督学习依赖于有标注的数据集。
第三类是基于无监督的方法,这种一般采用线性回归,ARIMA,移动平均,Holt-Winter,聚类等方法。
当前场景下,在计算机采集的关键指标数据上进行异常检测存在两方面问题:(1)指标数量多,无标注,且历史记录的异常非常少,缺乏已标注的异常数据。(2)类型多。时间序列一般可分为周期性、阶梯形和无规律型。但同样是CPU利用率,可能有周期性,也可能是无规律,并且可能因為业务变更导致该指标从一种类型(比如无规律型)变换为另一种(比如周期型)。
现有方案中,经验阈值依赖专家经验,面临指标数量多,业务调整频繁等问题;有监督算法依赖于有标注数据,但系统和应用异常在日常生活中属于极小概率事件,能积累的异常数据非常少,这就导致了哪怕能提供标注数据,其正负样本也极度不均衡,并且只能检测数据集中出现过的故障;而单一的无监督算法则面临时间序列类型多样,难以使用一个算法应对全部类型的问题。
目前,中国移动的业务支撑系统大部分均采用的分布式服务器,所以一套系统中包含了多个子系统,子系统经常会存在互相调用的情况,有时候服务器处理完请求返回结果的时候进程就会挂掉。此时用户发现自己的请求没有返回结果,就会多次请求业务,这时就容易出现异常值,表示出现业务上的故障。现阶段的处理方法是:运维人员接到服务器发出的告警之后,人眼观察此时间段是否出现异常值,然后再处理告警看是否需要升级告警或者处理故障。此时如果是出现故障的话,已经发生了一段时间了,这种方法的弊端是不能及时发现故障和需要有经验的运维人员判断是否发生了故障。或者是用多种无监督学习的方法来判断当前时间点是否为业务上的异常点,然后再经过集成学习投票的方法来最终决定该点是否为异常点[1]。这种方法虽然发现异常的速度快而且不需要人为判断而且召回率高,但是它的准确率不是特别理想。
本文就提出一种提取特征的方法,将标准分异常值、格拉布斯异常值、中位数方差异常值和平均偏离值等特征提取出来。从以前的一维特征转变为多维特征的维度复杂化操作。这相当于每个时间戳上都含有该时间戳附近时间点的信息。然后再把它们喂给随机森林模型进行训练,最后由若干个决策树来判断该时间点是否为异常点。这个方法能检测出大部分跨区换卡、套餐变更和个人开机的中国移动业务接口服务异常值。
综上,我们提出时间序列集成检测算法(Bagging Detection on Time-Series, BDTS),从统计学习出发,以学习数据的统计分布为目的,将数据中不符合统计分布的小概率数据视为异常点,并采用集成学习bagging的策略,在算法上集成3sigma、Quantile、 ESMA、IForrest等算法,在時间上提取不同粒度的统计特征,集成多类型、多时间粒度层次的无监督学习算法,并通过自行设计的6个评价指标监控模型性能,并在交叉验证中自动调整子模型权重,使得模型自动适配周期型,阶梯型和无规律型时间序列的异常检测任务,检测时序上的离群点、不一致点和突变点。
1 接口服务异常值检测算法
1.1 特征提取的方法
在采集后的数据集中只有两个特征,一个是时间戳,另一个是数值。特征提取的方法就是将数据按照时间戳进行排序再固定一个有意义的时间窗口,然后根据相应的统计学方法计算该时间戳在整个时间窗口中具有统计意义的另外一个值。一个值就对应着该时间戳上的一个特征,从而达到将简单的一维数据复杂成多维数组。这种复杂化操作,既能降低单一时间戳上预测异常值的随机性,让预测的异常值更可信,还能让只有一个属性的数组多出几个具有上下时间戳信息的属性出来。本文选取了四个统计学的方法提取特征,分别是标准分异常值、格拉布斯异常值、中位数方差异常值、平均偏离值和波形的判断。
标准分异常值是指以标准差为单位算每个样本到集合中均值的距离,相当于样本到均值的平均偏离水平。算法的大致流程:(1)排除最后一个值。(2)求剩余样本值的平均值;(3)所有样本减去这个平均值。(4)求剩余样本的标准差。(5)(中间三个数的平均值-全序列的均值)/全序列的标准差。
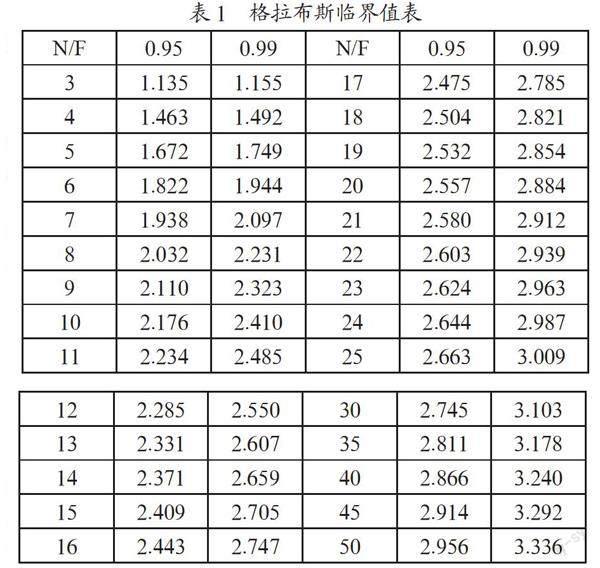
格拉布斯异常值是一种从时间窗口的样本中找异常点的方法,样本中偏离平均值过远的数据有可能是极端情况下的正常数据,也有可能是测量数据时候的异常数值。假设样本是符合正太分布的,然后选定一个临界值就可以用Grubbs进行检测,格拉布斯临界值表如表1所示。
格拉布斯异常值检测大致流程:(1)将时间窗内样本从大到小进行排序。(2)求时间窗内样本的均值和标准偏差。(3)计算最大值和最小值和均值的差,哪个差值大哪个更加可疑。(4)求可疑值的标准分异常值,如果大于格拉布斯中选取的临界值,它就是异常值。(5)不断更新格拉布斯临界值中的检出水平∝和样本数量n,排除异常值并重复1~5步骤。
中位数方差异常值和标准分异常值是十分相似的,前者是以均值为评判数据的进奏或者分散程度,后者则是用集合中的中位数为标准。如果集合的元素是偶数,则取中间两个数的平均值。这个特征就是先算滑动窗口中的中位数,然后每个元素减去这个中位数的值作为新的特征[2]。
平均偏离值的特征值类似3-sigma准则。简单的算法流程:(1)去除滑动窗口中的最后一个值,求剩余值的均值。
(2)滑动窗口中的每一个值减去这个均值,再求标准差。(3)然后再求滑动窗口中间值和第二步中减去均值后的那个值的绝对值,将得到的值作为新的特征。
波形的判断是用来判断滑动窗口中的数据的规律类型,总共分为4中类别:周期型、阶梯型、平缓型和无规律型,然后用0、1、2、3位滑动窗口内的数据类型进行分类。
1.2 随机森林的生成
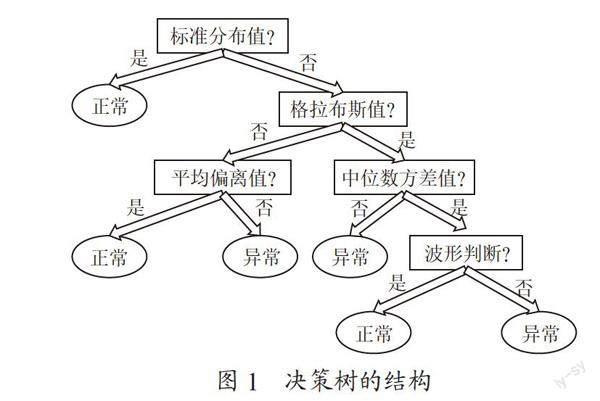
通过之前的维度复杂化的操作,一个时间戳下从以前的只有一个值变换成了有六个属性的复杂特征矩阵。这时本文选择用随机森林的方法来进行类别的判断,判断该时间戳上是否为异常点,1为异常,0为正常。随机森林是由若干个决策树组合而成的,其是一个二叉树,是一个预测模型,它是根据属性递归进行判断是否是异常点,直到属性用完或者得到下一分支的结果就会停止递归,决策树的结构如图1所示。
在这个决策树中,每个内部节点代表一个样本中的其中一个属性,每个分支代表一个测试输出,每个叶节点代表一种类别。然后通过无放回的方法,把所有可能的情况全部枚举出来组成一个由若干个决策树组成的随机森林。每颗决策树都要输出这个样本是否是异常点,每颗决策树都是独立的,由若干个弱分类器来组成这个强分类的森林[4]。
2 模型算法实验
2.1 数据预处理
通过集中化BOMC系统采集数据,原数据集分为四列:接口服务ID、时间戳、value值和标签。接口服务ID是区别每个服务器不同的唯一ID。时间戳是指在该接口服务上的时间戳。value值是类似系统健康度一样一个综合的评分,每过5秒钟产生一次。标签只有0和1,0代表正常,1代表异常。然后把数据集按照8:1:1的比例分为训练集、验证机和测试集。并且对value值作归一化的处理,减少数据的扰动。
接着就需要根据这个value值进行特征维度的扩充,选择20个数据作为滑动的时间窗口,每一行的数据扩充特征维度的时候都是以该行数据为中心上下依次选取10行数据。然后算标准分布值、格拉布斯值、平均偏离值、中位数方差值和波形的判断,作为每一行数据新增的属性,标签不变。
2.2 模型的训练
本文选用机器学习中的随机森林模型进行训练。以标准分布值、格拉布斯值、平均偏离值、中位数方差值、波形的判断和value值作为模型的输入特征属性。Batch Size的大小是数据总量-滑动窗口大小/2。在参数的设定方面,本文选择120个决策树和10的深度。一般来说森林的规模越大,集成的方差越小,模型泛化能力越强,但是算力开销也会越大;同时,决策树深度越深,模型拟合偏差越小,但是也容易模型过拟合和算力开销大。RF树的数量与F1得分的关系如图3所示,RF树的深度与F1得分的关系如图4所示。
训练采用不放回的训练策略,并且支持决策树之间交叉验证。在job的选择中选择了1,减少每次迭代训练之间的影响,并行提高性能。
数据预处理主要分两部分,有时候因为采集Agent的重启或者流程重复等因素,采集的数据存在时间戳重复和缺失的情况。一般处理重复时间戳可以考虑直接去除,或者是合并的方式。具体采用哪种跟指标类型有关。一般填补缺失时间戳指标值的方式可以使用統计值,比如均值和中位数来填充,具体统计的时间粒度根据需求而定。
2.3 特征工程
特征工程的内容包括:提取不同类型和不同时间粒度的统计特征。类型包括均值、标准差、分位数等,时间粒度上,一般默认7种,不分组的、日、周、月、工作日/周末、月初/月中/月末、节假日/非节假日。此外还可以根据业务指定一些特定的周期。采集的统计值可视化结果为:
(1)时间粒度:不分组,从全部的数据中提取全局均值、标准差、分位数等。
(2)时间粒度:日,将每天中的8:00分为一组,并提取前后各5分钟的数据填充,则按分钟采样的数据集可以分为24×60=1 440组,从每一组中提取局部均值、标准差、分位数等。
(3)时间粒度:周,将每周三的8:00分为一组,并提取前后各5分钟的数据填充,则按分钟采样的数据集可以分为7×24×60=10 080组,从每一组中提取局部均值、标准差、分位数等。
(4)其他的时间粒度的数据分组和提取统计特征的方式依次类推。
2.4 模型测试集结果分析
测试模型在测试集的表现结果是由F1得分决定的。F1得分是统计学中衡量分类任务模型的一种方法,它由准确率和召回率组成。它的本质是一种模型准确率和召回率的加权平均,最大值为1,最小值为0,值越大越好,计算公式为[5]:
模型在测试集的最终F1得分为0.86。
测试集上对模型的性能进行评估之后,在全部的数据上对BDTS模型进行重新训练。并将模型部署为在线服务。持续从数据平台中接收实时采集的数据流,在实时数据流上进行异常检测,并展现异常检测结果。展示内容包括时序图,检测到的异常点及其异常概率,以及整体异常比例,当异常比例高于5%以上时进行告警,检测结果可视化界面如图5所示。
3 结 论
本文提出了一种基于特征提取和随机森林的接口服务器异常检测的方法,将本身比较简单和单一的异常值扩充成多维度的特征属性,使得模型训练和测试时更加复杂和准确。这种方法帮助了运维系统的人员更加快捷的发现故障,减少系统故障延时发现的频率,提升了系统的稳定性。文章提出了一种提取一维统计学中的特征作为属性,把属性喂给随机森林进行训练的有监督学习的异常检测方法。作为属性的特征有标准分异常值、格拉布斯异常值、中位数方差异常值和平均偏离值等。现阶段一般采用无监督模型和集成学习的方法来检测异常值。本文提出的方法就是基于现阶段方法做的一个升级版本,能检测出大部分跨区换卡、套餐变更和个人开机的中国移动业务接口服务异常值。
参考文献:
[1] BREIMAN L. Bagging predictors [J].Mach Learn,1996,24(2):123-140.
[2] BREIMAN L. Random Forests [J].Machine Language,45(1):5-32.
[3] GILLES L. Understanding Random Forests [D].Liege University of Liège,2015.
[4] BARTLETT P,FREUND Y,LEE W S. Boosting the margin:a new explanation for the effectiveness of voting methods [J].Ann.Statist.,1998,26(5):1651-1686.
[5] KAGGLE. Macro F1-Score Keras [EB/OL].[2022-09-06].https://www.kaggle.com/code/guglielmocamporese/macro-f1-score-keras/notebook.
作者简介:左金虎(1983—),男,汉族,湖北汉川人,应用业务架构师,硕士研究生,研究方向:应用系统架构演进及AIOps;肖忠良(1986—),男,汉族,山西朔州人,高级工程师,硕士研究生,研究方向:AIOps算法;陈理华(1985—),男,汉族,湖南邵阳人,集团专家,硕士研究生,研究方向:AIOps运营。
收稿日期:2022-10-26
猜你喜欢
中国中药杂志(2017年7期)2017-05-26 00:10:21
湖北农业科学(2017年7期)2017-05-13 08:01:24
电脑知识与技术(2017年5期)2017-04-08 13:00:44
时代金融(2017年6期)2017-03-25 22:21:13
安徽农学通报(2017年1期)2017-02-15 17:49:06
软件(2016年7期)2017-02-07 15:54:01
南水北调与水利科技(2016年6期)2017-01-06 13:43:27
电脑知识与技术(2016年23期)2016-11-02 23:25:12
软件(2016年2期)2016-04-08 02:06:21
现代电子技术(2015年15期)2015-08-14 21:28:48
