
基于BERT-BILSTM-CRF的慢性支气管炎中医医案实体识别
2023-06-22 23:25帅亚琦李燕陈月月徐丽娜钟昕妤
现代信息科技 2023年5期
关键词:数据挖掘
帅亚琦 李燕 陈月月 徐丽娜 钟昕妤


摘 要:随着现代信息技术的飞速发展,人类社会开始进入大数据时代,如何高效快捷地从海量的中医医案文本数据中挖掘出我们所需要的信息,从而更好地应用于临床工作,是目前亟待解决的问题。通过实验对慢性支气管炎中医医案进行研究,分析BERT、BILSTM、BILSTM-CRF和BERT-BILSTM-CRF四种模型的实体识别效果,结果表明,相比于其他模型,采用BERT-BILSTM-CRF模型可以更加准确有效地识别出慢性支气管炎中医医案的实体类别,其F1、Precision和Recall均优于其他模型。
关键词:数据挖掘;命名实体识别;中医医案;循环神经网络
中图分类号:TP391.1;R2-03 文献标识码:A 文章编号:2096-4706(2023)05-0145-05
Entity Recognition of Traditional Chinese Medical Cases of Chronic Bronchitis
Based on BERT-BILSTM-CRF
SHUAI Yaqi, LI Yan, CHEN Yueyue, XU Lina, ZHONG Xinyu
(School of Information Engineering, Gansu University of Chinese Medicine, Lanzhou 730000, China)
Abstract: With the rapid development of modern information technology, human society has begun to enter the era of big data. How to efficiently and quickly mine the information we need from the massive text data of traditional Chinese medicalcases, so as to better apply them to clinical work, which is an urgent problem to be solved at present. Based on the experimental study of traditional Chinese medicalcases of chronic bronchitis, the entity recognition effects of four models, BERT, BILSTM, BILSTM-CRF and BERT-BILSTM-CRF, are analyzed. The results show that compared with other models, the BERT-BILSTM-CRF model can more accurately and effectively identify the entity categories of traditional Chinese medicalcases of chronic bronchitis, and its F1, Precision and Recall are all better than that of other models.
Keywords: data mining; named entity recognition; traditional Chinese medical case; cyclic neural network
0 引 言
中醫医案最早起源于周代,在明清时期,个人医案专著大量增加,中医医案的撰写量也达到了顶峰。中医医案的价值和意义不仅仅局限于现代西医药研究方法意义上的科学,它也是祖国医学上临床传承的重要形式。如何从海量的医案信息中快速准确地获取用户感兴趣的知识已经成为亟待解决的问题。本文所使用的技术手段称为命名实体识别技术,命名实体识别一直以来都是信息抽取、自然语言处理等领域中重要的研究任务,本文通过命名实体识别技术识别出慢性支气管炎中医医案中表示实体的成分,并对其进行分类,从而更好地应用于医疗辅助系统、智能诊断系统中,为中医药的数字化临床信息发展提供技术支持。
1 相关研究
近年来,随着数据挖掘技术的日益成熟,将数据挖掘技术应用于中医药领域成了现代数据挖掘技术研究的热点话题,在中医药方面的研究也取得了优异的成果。面对海量的中医医案知识,人的精力和时间是有限的,因此通过自然语言处理技术对医案里的非结构化数据进行数据挖掘,可以更加有效的提取出医案里的隐性知识,并将其应用于知识图谱和知识问答等实际应用中。
早期的实体识别主要是基于规则的方法,人工构建,再从文本中寻找匹配这些规则的字符串以达到实体识别的目的[1]。但是规则的制定是有限的而实体是变换无穷的,所以这样的方法越来越笨重。统计机器学习的方法需要人工选取词性、依存句法依赖等可能对任务结构有影响的特征作为模型的输入[2],所以其命名实体识别效果也有待提高。研究学者们发现神经网络模型可以自动学习句子特征,无需复杂的特征工程,并且可以通过神经网络自动挖掘数据的深层次特征进行预测,所以众多研究学者们开始将最新的深度学习技术应用于NER问题上。Peters[3]等人在2018年首次提出了ELMo(Embeddings from Language Models)模型,但是该模型无法并行计算。在该模型的基础上,Devlin[4]通过BERT模使用掩蔽语言模型实现了基于预训练的深度双向表示,通过使用Transformer架构中的Encoder模块,使得BERT模型拥有了双向编码能力和强大的特征提取能力。而随着目前的实体识别研究已经将CNN、SVM、BERT等模型应用于语言预处理,并在模型中引用注意力机制来提高实体识别准确率[5]。
目前对于中医医案症状识别主要使用的是循环神经网络技术,高佳奕[6]通过LSTM-CRF模型,应用LSTM层结合预训练字向量抽取医案的抽象特征,通过CRF进行序列标注,识别的F1值达到了0.85左右。李明浩[7]通过LSTM-CRF模型识别中医医案症状术语,在小规模训练集上的训练,使得F1值最高达到了0.78。肖瑞[8]基于BILSTM-CRF对中医药文本数据进行挖掘,使得F1值达到了80.92%。本将BERT模型与BILSTM-CRF模型结合,利用两者的优势对慢性支气管炎中医医案进行实体识别。
2 资料与方法
2.1 数据来源
本文研究的数据主要来源于《岳美中医案集》《颜德馨临床经验辑要》《世中联名老中医典型医案》等古今部分名老中医的中医医案著作。其中使用了300多条医案数据。在选定了这些数据后,删除文本中的特殊字符以及无效信息。以句号作为间隔符将原医案文本内容进行切分。
2.2 序列标注
命名实体识别是自然语言处理的一项最基本的任务,其主要目的是从文本中识别出特定命名指向的词汇。在本文中设定了6种实体类型,并将疾病名、症状、证候、治则治法、方药和舌脉信息,依此记为DIS、SYM、SYN、TRE、PRE和DIA,通过BIO标注,将B表示开始,I表示内部,O表示非实体。本文对标签的类别以及特征进行了分类,如表1所示。
在序列标注建模方法和序列标注体系下对于中文文本的命名实体识别模型就是要为序列中的每个变量预测出所属的标签类别[9]。
3 模型结构
本文通过BERT-BILSTM-CRF模型进行命名实体识别,该模型主要包括三个部分,首先是BERT预训练语言模型,慢性支气管炎中医医案的非结构化文本数据转化为向量形式并提取出蕴含在中医医案里的丰富语义特征,再通过BILSTM模型进一步提取出医案中的上下文特征,最后通过CRF添加约束条件,减少错误序列的产生,并输出最终的标记序列。
3.1 BERT预训练语言模型
BERT(Bidirectional Encoder Representation from Transformers)模型是一种语言预训练模型。该模型结构如图1所示。
本文将原始的医案文本数据进行数据筛选与标注后,对标注的文本数据进行切分,然后进行向量表示。Transformer结构是BERT的关键部分,是基于注意力机制的深度网络,通过在同一个句子中计算每个词与其他词之间的关联程度来调整权重稀疏矩阵,从而获得词的特征向量的表达。本文通过Transformer的Encoder层获得具有上下文丰富语义特征的文本序列向量,然后输出向量,,作为命名实体识别模型的Embedding层,输入到BILSTM模型中。
3.2 BILSTM模型
LSTM(Long-Short Time Memory)模型最早由Hochreiter[10]
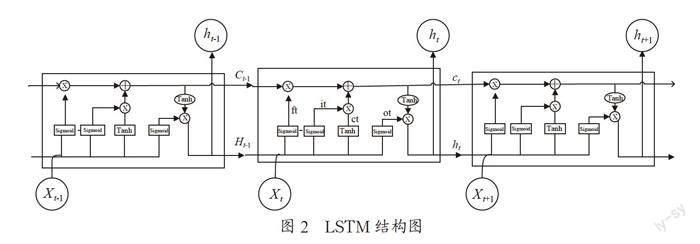
提出,是一种特殊的循环神经网络,该网络结构中隐藏单元的内部结构十分复杂,通过引入记忆单元和门控记忆单元保存历史信息、长期状态,使用门控来控制信息的流动,有效的实现了上下文信息的存储和更新,如图2所示。
每个LSTM单元都通过遗忘门、输入门和输出门三种结构来控制信息状态,LSTM单元内部的计算公式为:
ft =Sigmoid(Wf×[ht-1, xt]+bf) (1)
it =Sigmoid(Wi×[ht-1, xt]+bi) (2)
ot =Sigmoid(Wo×[ht-1, xt]+bo) (3)
Ct =ft*Ct-1+it*tanh(Wc×[ht-1, xt]+bc) (4)
ht =ot*tanh(Ct) (5)
如圖所示,LSTM的输入有三个,当前时刻输入xt、上一时刻LSTM的输出值ht-1以及上一时刻的单元状态Ct-1;输出有两个,当前时刻LSTM的输出值ht和当前时刻的单元状态。LSTM模型通过三个门结构实现了对信息状态的选择性输出。其中,W和b表示权重和偏置项,式(1)为遗忘门状态更新公式,[ht-1, xt]表示把两个向量组成的一个更长的向量。Sigmoid函数的作用是将门的输出值限制在0到1之间,当门输出为0时,任何向量与之相乘都会得到0向量,这就相当于什么都不能通过;输出为1时,任何向量与之相乘都不会有任何改变,这就相当于什么都可以通过[11]。
式(1)决定上一时刻的单元状态Ct-1有多少保留到当前时刻Ct;式(2)为输入门的状态更新公式,决定当前网络的输出xt有多少保存到状态单元Ct。式(3)为当前时刻单元的状态计算公式;式(4)(5)为输出门的计算公式,决定控制单元状态Ct有多少输出到LSTM的当前输出值ht。显然,当前LSTM单元的隐藏状态ht依赖于先前的隐藏状态ht-1,但与下一个隐藏状态ht+1不相关,即信息仅在单向LSTM中向前流动。这使得LSTM模型存在梯度消失或梯度爆炸的现象。
2005年,GRAVES[12]根据LSTM和双向RNN模型,提出了BILSTM模型,该模型可以同时使用时序数据中某个输入的历史和未来的信息,从而增加循环神经网络中可以利用的信息,使得模型具有更加强大的特征提取能力。本文在BERT预训练语言模型的基础上使用了BILSTM模型,通过慢性支气管炎医案数据中的双向语义信息即潜在的语义关系,优化了循环神经网络(RNN)模型的迭代性问题,缓解了梯度消失或梯度爆炸的现象,提高了对序列数据的长期记忆能力。
3.3 CRF模型概述
条件随机场(Conditional Random Fields,CRF)作为一种条件概率分布模型被用于命名实体识别。在命名实体识别领域,其最主要的功能上在多种可能的标注序列中,挑选出一个概率最大的标注序列作为我们对这句话的标注。虽然BILSTM模型能够输出标签取值的概率值,但是直接用BILSTM模型输出的标签有些并不是合理的,原因是未考虑标签与标签之间的关联性,比如实体的头部必不可能是I开头,O标签后的下一个标签必不可能是I,B-Dis标签后面必为I-Dis等,因此在BILSTM模型后面加入CRF层加入约束机制,这样就可以调整输出的标签,使得标签的结果顺序更加的合理,从而提高模型的准确率。在本文任务中,主要应用的是线性链条件随机场,其原理如式(6)为[13]:
(6)
其中,Z(x)表示归一化因子,Z(x)和s(x, y)的计算公式为:
(7)
s(x, y)=∑ i Emit(xi, yi)+Trans( yi-1, yi)(8)
其中,Emit(xi, yi)表示LSTM的输出概率,Trans( yi-1, yi)表示对应的转移概率,也是CRF转移概率对应的数值。
4 实验结果及分析
4.1 评估指标
本次命名实体识别任务通过查准率(Precision,P)、召回率(Recall,R)和F1值作为饰演的评价指标。其计算公式为:
(9)
(10)
(11)
其中,TP为实际为正被预测为正的样本数量,表中FP为实际为负但被预测为正样本数量,FN为实际为正但被预测为负的样本的数量[14]。
4.2 实验方案
本文首先对慢性支气管炎医案数据进行了爬取,然后在众多的医案数据中,筛选出慢性支气管炎中医医案数据,删除掉医案中的数据来源等冗余信息,然后对医案数据进行分词和BIO标注,将标注好的医案数据输入到命名实体识别模型中,进行实体识别。为验证本文所使用模型在慢性支气管炎中医医案的优势,与下列几种模型进行了实验对比。
4.2.1 BERT模型
实验使用的是Googel提供的预训练好的中文BERT模型,获取上下文本中的丰富语义信息,采用Transformers进行预训练,以此生成深层的双向语言表征信息。本文所使用的BERT模型的相关参数设置为:学习率为0.001,12个编码层,12个注意力机制和768个隐藏单元,预先迭代100个epoch测试,然后根据结果调参。
4.2.2 BILSTM模型
将标注好的信息输入到双向的BILSTM模型,然后将前向和后向提取的字特征向量拼接到一起作为最终的字向量特征,最后输入分类层,softmax函数后得到每个标签的分值,其中分值最大的就是该字的标签,用交叉熵作为损失,梯度下降方法更新整个模型参数。本文BILSTM模型的相关参数设置为:输入层的batch_size为300,每个词用128维的向量表示,隐藏层的维度为256,学习率为0.001,也用交叉熵损失。
4.2.3 BILSTM-CRF模型
双向的BILSTM模型可以捕捉正向信息和反向信息,使得模型对文本的利用效果更佳的全面,然后通过CRF层添加约束条件,使得模型的y预测结果更加的精确减少错误序列的出现。本文所使用的BILSTM-CRF模型的相关参数设置为:输入层的单句文本长度为300,每个词用128维的向量表示,隐藏层的维度为256,学习率为0.001,也用交叉熵损失,优化器选择Adam优化算法。
4.3 实验结果對比及分析
本文的所有实验模型都是基于PyTorch框架,使用GPU为GTX1650,为验证模型的效果,本文将BERT-BILSTM-CRF模型与BERT、BILSTM、BILSTM-CRF三种模型进行对比,通过评价指标来验证BERT-BILSTM-CRF模型的效果。实验对比结果如表2所示。
根据表2可以看出,本文所采用的BERT-BILSTM-CRF模型整体效果优于其他模型。表中的所有实验数据是在不同的迭代次数下所取得最优值,通过比较发现,BERT-BILSTM-CRF模型在各个测量指标上都能达到最优值。从表中可以看出,BILSTM-CRF模型的效果比BILSTM模型的识别效果好,这是因为CRF层不同于BILSTM模型,CRF计算序列时计算的是联合概率,考虑的整个句子的局部特征的线性加权组合,优化的是整个序列,而不是仅仅的将每个时刻的最优拼接起来,因此,CRF层的添加使得BILSTM-CRF模型的整体效果优于BILSTM模型。在表中,虽然BERT模型的识别效果不如BILSTM模型,但是BERT模型的动态词向量的获取能力很强,在词向量的表现上优于BILSTM-CRF模型的embedding层,借助BERT预训练模型的优点,使得BERT-BILSTM-CRF模型的识别效果整体优于BILSTM-CRF模型。BERT-BILSTM-CRF模型的评价指标变化趋势如图3所示。
从图中可以看出,该模型在迭代了100次后,三种评价指标在一定范围内上下波动,开始出现震荡,表明该模型训练趋于稳定,不会出现大幅度波动。该模型的训练集损失函数和验证集损失函数如图4所示。
从图中可以看出,该模型在从0个Epoch开始,Loss开始大幅度下降,当到达100个Epoch后,开始趋于稳定状态,也验证了图三的评价指标变化趋势是在100个Epoch后模型的评价指标开始在一定范围内上下波动,评价指标没有出现大幅度上升或下降。从图四中可以看出,在150个Epoch后,随着Epoch的增加,Dev_loss开始有上升趋势,在图三的同一Epoch上,评价也同时上升,这说明开始出现过拟合现象。在模型训练过程中,模型的状态变化为从最开始的不拟合状态,进入优化拟合状态,当随着Epoch的增加,当到达一定程度时,神经网络开始出现过拟合现象。所以该模型的Epoch应该设置为100~150次左右。
5 结 论
本文基于BERT-BILSTM-CRF模型对慢性支气管炎中医医案进行命名实体识别,通过该模型,实现了对慢性支气管炎中医医案的实体识别并获得了良好的效果。首先通过BERT预训练模型抽取出了丰富的文本特征,然后通过BILSTM模型提取出实体所需要的特征信息,最后通过CRF层计算出最优的序列标注,并输识别结果。然后将该模型与BERT、BILSTM和BILSTM-CRF进行对比实验,通过对比我们发现BERT-BILSTM-CRF模型对慢性支气管炎中医医案上的实体识别效果最好,其F1值、P值和R值相比于其他模型的都高。命名实体识别模型较多,但用于中医药相关命名实体识别模型数量微乎其微,构建中医药相关命名实体识别模型,将更加有效地推动中医药文本挖掘发展。本文提出的方法解决了慢性支气管炎中医医案实体识别效率一般的问题,也为深度挖掘慢性支气管炎中医医案里的隐性知识提供了技术支撑。
参考文献:
[1] 吴信东,李娇,周鹏,等.碎片化家谱数据的融合技术[J].软件学报,2021,32(9):2816-2836.
[2] 钟华帅.基于深度学习的实体和关系联合抽取模型研究与应用[D].广州:华南理工大学,2020.
[3] PETERS M E,NEUMANN M,IYYER M,etal. Deep Contextualized Word Representations[J/OL].arXiv:1802.05365[cs.CL].[2022-10-03].https://arxiv.org/abs/1802.05365v1.
[4] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers forLanguage Understanding[J/OL].arXiv:1810.04805 [cs.CL].[2022-10-03].https://arxiv.org/abs/1810.04805.
[5] GAJENDRAN S,MANJULA D,SUGUMARAN V. Character level and word level embedding with bidirectional LSTM–Dynamic recurrent neural network for biomedical named entity recognition from literature[J/OL].Journal of Biomedical Informatics,2020,112[2022-10-02].https://linkinghub.elsevier.com/retrieve/pii/S1532046420302367.
[6] 高佳奕,楊涛,董海艳,等.基于LSTM-CRF的中医医案症状命名实体抽取研究[J].中国中医药信息杂志,2021,28(5):20-24.
[7] 李明浩,刘忠,姚远哲.基于LSTM-CRF的中医医案症状术语识别[J].计算机应用,2018,38(S2):42-46.
[8] 肖瑞,胡冯菊,裴卫.基于BiLSTM-CRF的中医文本命名实体识别[J].世界科学技术-中医药现代化,2020,22(7):2504-2510.
[9] 顾溢.基于BiLSTM-CRF的复杂中文命名实体识别研究[D].南京:南京大学,2019.
[10] HOCHREITER S,SCHMIDHUBER J. Long Short-Term Memory [J].Neural computation,1997,9(8):1735-1780.
[11] 山梦娜.基于深度学习的遥测数据异常检测[D].西安:西安工业大学,2020.
[12] GRAVES A,SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures [J].Neural Networks,2005,18(5-6):602-610.
[13] 杨云,宋清漪,云馨雨,等.基于BiLSTM-CRF的玻璃文物知识点抽取研究[J].陕西科技大学学报,2022,40(3):179-184.
[14] 高经纬,马超,姚杰,等.基于机器学习的人体步态检测智能识别算法研究[J].电子测量与仪器学报,2021,35(3):49-55.
作者简介:帅亚琦(1998—),男,汉族,山东潍坊人,硕士研究生在读,主要研究方向:知识图谱;通讯作者:李燕(1976—),女,汉族,甘肃兰州人,教授,硕士研究生,主要研究方向:中医药数据挖掘、中医药知识图谱;陈月月(1997—),女,汉族,山东滨州人,硕士研究生在读,主要研究方向:知识图谱;徐丽娜(1996—),女,汉族,甘肃定西人,硕士研究生在读,主要研究方向:数据挖掘;钟昕妤(1996—)女,汉族,浙江嘉兴人,硕士研究生在读,主要研究方向:数据挖掘。
收稿日期:2022-10-26
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
电力与能源(2017年6期)2017-05-14
中国中医药信息杂志(2016年7期)2016-12-01
现代电子技术(2016年15期)2016-12-01
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
河南科技(2014年19期)2014-02-27
电子设计工程(2014年18期)2014-02-27
电子设计工程(2014年18期)2014-02-27
