
基于多级滤波思想的人脸去手势遮挡恢复方法研究
2023-06-21 09:28:16欧静文志诚
现代信息科技 2023年9期
关键词:深度学习
欧静 文志诚



摘 要:针对当下大面积人脸图像修复过程中广泛存在的色彩差异及生成内容丢失主要面部辨识特征等问题,文章提出一种端到端的三分支修复网络结构——TreeNet。单阶段的生成网络结构简单清晰且参数量较少,其中,逐像素滤波操作有益于减少色彩误差,促进生成图像的细节表达,记忆转化模块促使网络在结构记忆存储器中搜寻相关结构信息以重建缺失纹理信息。测试结果表明,TreeNet可以生成五官结构更加清晰自然、细节色彩更加逼近原图的人脸信息。
关键词:深度学习;生成对抗网络;人脸修复;像素滤波
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)09-0094-05
Abstract: To solve the problems of color difference and loss of main facial recognition features in the process of large-scale face inpainting, this paper proposes an end-to-end three branch repair network structure TreeNet. The single stage generation network has a simple and clear structure with fewer parameters. Among them, pixel by pixel filtering operation is beneficial for reducing color errors and promoting the detailed expression of generated images. The memory conversion module enables the network to search for relevant structural information in the structural memory storage to reconstruct missing texture information. The test results show that TreeNet can generate facial information with clearer and more natural facial features and more detailed colors that approximate the original image.
Keywords: deep learning; generative adversarial network; face restoration; pixel filtering
0 引 言
人脸图像去遮挡及修复是图像修复领域的重要研究课题,而今,在实际应用场景中,人脸图像修复常被用于消除因人为遮挡(口罩、帽子、手势遮挡等)和损毁造成的人脸识别失败等情况。因此,人脸修复方法始终面临两大挑战:一是如何生成准确度更高,更贴合原文的图像结构;二是在待处理图像丢失主要面部结构信息时,如何使网络对图像的处理更具有针对性。
针对以上问题本文提出一种新的网络结构——TreeNet,即基于多级交互滤波思想的多尺度特征融合神经网络。TreeNet摈弃了繁复冗余的多阶段深度神经生成网络,试图构建一种单阶段可实现端到端训练和生成的图像修复网络。因此我们遵循传统的对抗生成网络结构思想,并在此基础上引入滤波核处理思想[1]。其次,为应对大面积连续缺失带来的人脸面部结构信息丢失的状况,网络增加了记忆力模块分支。该分支使经过特征提取后的特征图谱在记忆存储器中搜寻与之匹配度最高的图像信息,从而提升网络在生成人脸面部结构信息时的合理性能力。
整体而言,TreeNet生成网络是一个由三个重要的生成分支组成的端到端生成网络,三分支主要包括:1)主生成网络,其中包含用于融合不同尺度感受野的多扩张卷积块。2)用于生成适应不同图像状态的滤波核预测网络。3)用于完善大量结构信息重建的记忆转化模块。为了进一步激活该人脸图像修复网络对大面积连续缺损图像的处理能力,试验中采用一种新的数据集处理方式,即使用CelebA-HQ人脸图像[2]和11K Hands数据集[3]生成相对应的手势遮挡。经过试验训练,TreeNet在实现手势遮挡方面取得了最优的效果,且具有训练便捷、收敛速度快等优势。
1 近期相关工作
1.1 传统修复方法
现存的修复方法主要包括传统修复方法和基于深度网络的自我学习推理方法。前者以基于偏微分方程的數学推理为基本思想,Bertalmio等人[4]提出使有效像素按等光线方向逐步向缺损区域内部延伸以计算得出目标像素信息,同时,研究者也尝试基于变分思想,采用曲率驱动扩散等方式对算法进行改进。为合成大面积图像信息,基于补丁匹配思想的修复方法通过提取图像中与缺失像素相似像素周围的局部扩展纹理进行填充,或通过外部数据驱动的方式经过大量搜索计算匹配到相似的补丁进行修补[5]。这种方式往往由于缺乏对图像深层语义结构的理解而产生重复,形成不真实且不符合感官逻辑的像素内容,尤其是在处理人脸图像此类结构明显的数据时,其弊端更加明显。
1.2 基于深度神经网络的图像修复方法
相较于传统的修复方法,基于生成对抗网络而生的变体结构通过设计一系列损失函数对生成器和鉴别器采用min-max的方式进行联合训练,使生成器可以改写噪声分布并使其可以无限接近于目标分布。因此基于生成对抗网络的方法相较于编码器而言可以生成更加清晰的图像,该类方法也是当下应用范围最广的方法。Nazeri等人[6]提出EdgeConnect,意在使用边缘信息指导图像修复;Ren等人[7]则提出利用结构信息指导修复。除此之外,还有利用多种指导知识相互结合指导的变体网络结构。因此,此类网络结构多为二阶段甚至三阶段网络,存在网络结构复杂及参数量庞大且难以训练的特点。此外人们也尝试使用各种注意力机制聚焦图像中的重要特征信息,以促进生成结果与原始信息间的结构一致性,如Yu等人[8]提出的上下文注意力等,但在训练时对显存的占用量较大,计算成本较高。
2 提出方法
2.1 网络整体结构
本文提出一种三分支的单阶段修复网络。整体网络结构由复合生成器G(·)和鉴别器G(·)组成,复合生成器中包括主信息生成分支G1(·)、滤波核预测分支Gkpn(·)以及一个结构记忆转化分支Gmem(·)。具体而言,主信息分支由一层图像预处理层、两层下采样、八层序列排放的多扩张卷积块以及包含三层上采样层的解码器构成。其中的多扩张卷积块由四个并行具有不同扩张率的扩张卷积组成,根据Zeng等人[9]的工作经验,其扩张率分别设置为1、2、4、8时可以使卷积更好地聚合上下文变化进而增强其对上下文的推理。滤波核预测分支Gkpn(·)与主生成分支中的特征信息相结合可以在语义级和像素层级上根据输入的图像信息生成适合的滤波核,使得图像生成在细节上更加逼真,还原真实图像情况的元素信息,同时还可以有效减少色彩误差。记忆转化分支Gmem(·)的主要任务是避免连续大面积结构缺失情况的产生,记忆转化分支中包括特征提取、逐像素记忆搜寻和推理以及结构记忆存储器。在鉴别器的设计上我们沿用了经典的谱归一化马尔可夫判别器结构,判别器通过鉴别生成图像中尺寸大小为70×70的图像块与真实图像信息的接近程度来反馈参数,进一步促进网络训练,优化内部参数。整体网络结构流程图如图1所示。
2.2 滤波核预测网络
使用滤波核依次对图像中的每一个像素进行处理,原本常用于图像去噪、去雨等退化修复型任务。其具体实现思想为,假设输入的退化后失真图像大小为H×W。由于现实中图像的状态和特征均不同,网络在处理每一个像素时都有与之一一对应的滤波核,因此,可设Kp为图像I中坐标为p的像素所对应的滤波核。与此同时,所有像素对应的滤波核集合可表示为:,K2表示滤波核大小。逐像素滤波操作过程如式(1)所示:
其中, 表示经过滤波后图像 中的像素p,q是p的相邻元素,t的取值范围为 到 。由式(1)可以看出,滤波修复思想可表述为通过建立目标像素与邻近像素之间的线性关系达到像素信息重建的效果,在修复缺损信息边缘时可以在有效减少生成像素与有效像素之间的色彩误差的同时保持局部信息的一致性。
滤波核以不同的模式来展现其重构丢失像素的能力。因此,模型使用深度神经网络对输入的失真图像进行特征提取和理解,生成图像所需的所有滤波核。使用图像级滤波核可以根据像素周围的信息准确地重建丢失像素,但仅靠循环过滤并不能使修复性能有所提升。由于特征图像中高度展现了图像的语义信息,那么将滤波思想扩展到图像的语义结构层,对包含语义信息的深层特征进行过滤可以实现对图像语义信息的深刻理解。假设FL为图像I在编码器中第L层的特征图像,对其的重建过程如式(2)所示,其中,q∈Np表示包含原像素p及其所有相邻元素在内的K2个元素信息。由此,语义过滤可以实现在具有低空间分辨率的深层特征图上修复所丢失语义信息的效果。
2.3 记忆转化模块
如图2所示,结构记忆存储器Mem是一个可训练的大小为N×C维实值向量矩阵,符号表示为 ,其中C的维数与输入特征图的通道位数相同,N设置为训练超参数,表示结构记忆存储器N的最大容量。我们将记忆存储器Mem的行向量标记为mi, 表示记忆实值向量矩阵的第i行,即结构记忆存储器的一个存储项。像素在检索记忆项时均需要一个大小为1×C的寻址向量,可用符号 表示。由此,特征圖谱逐像素记忆搜寻的过程可用式(3)表示,即:
综上所述,稀疏寻址机制使网络模型可以使用更少且更相关的记忆项来表示人脸图像中的结构特征,从而促使网络在处理大面积损毁的图像时依然能够生成合理的人脸五官信息。
2.4 损失函数设置
人脸图像修复及优化目标是保证修复图像在人眼视觉下达到结构完整且符合逻辑,纹理清晰减少伪影和模糊,达到一定的视觉逼真度,并且要求人眼观测之外的逐像素重建精度。为此,在训练期间,网络严格按照联合损失函数Lcom进行反馈和调整,联合损失函数包括对抗损失Ladv、风格损失Lstyle、感知损失Lperc和L1平均绝对误差损失 。
假定用Ireal表示真实图片,生成器输出图像为Ipred。表达式如式(5)所示:
3 实验细节
3.1 数据集
为了激发网络对于人脸结构的推理能力以及更加符合现实场景下的应用,我们选取了由Voo等人[10]提出的高质量合成人脸遮挡分割数据集,人脸数据信息来自CelebA-HQ,其中包括30 000张高分辨率人脸图像。用于生成合成图像的手势遮挡数据来自11K Hands数据集,其中包含11 076张来自190名不同年龄段受试者的手部图像。为了提高网络模型的泛化能力避免过拟合,实验过程中将每个掩码随机旋转0°、90°、180°或270°,并在垂直或水平方向上随机翻转达到数据增强的目的。所有图像包括相对应的掩码图像在输入网络之前统一将尺寸大小调整为256×256。
3.2 实验过程
我们的实验硬件为12核CPU及一块RTX 3090显卡,搭配cuda版本为11.7。实验环境为:在Ubuntu 18.04.5系统下使用Python 3.8.10搭配pytorch 1.8.1深度学习框架。训练图像及对应mask在输入网络前均被调整为256×256,实验过程中将batch_size设置为4,将learning_rate设置为0.000 1,经过观察可知,网络在迭代300 000个iteration后达到收敛。联合损失函数参数确定为λadv=0.1,=1,λperc=0.1,λstyle=250。
4 结果与分析
4.1 定量分析
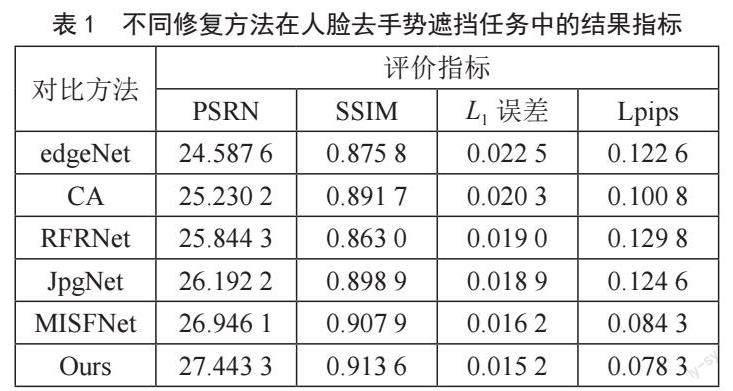
为验证本文使用方法在人脸图像修复效果上的优越性,引入5种对比方法,分别为edge-connect、CA、RFRNet[11]、JpgNet和MISF,且采用普及面最广的PSNR(峰值信噪比)、SSIM(结构相似性指数)、L1误差以及LPIPS(图像感知相似度)对各网络的生成结果进行测试。定量比较结果如表1所示。
从表1中可以看出:模型在峰值信噪比、结构相似度以及L1损失上都获得了较好的数值结果,这说明改进模型在去手势遮挡上的合理性结构生成能力以及像素精度重建上都表现出优异的效果。与MISF相比,修复结果在PSNR指标上平均增加了0.5,在感知相似度指标上降低了0.006,且与其他网络相比表现出更加优异的性能。同时,我们使用不规则掩码数据集对测试图像进行处理,修复结果如图3所示,评价指标如表2所示。与MISF相较,当缺损面积变大时修复结果的峰值信噪比数值增长量更大,即当缺损比达到40%和50%时,PSNR值分别增加0.696和1.012,LPIPS值分别缩小0.213和0.356,这说明模型在扩大感受野以获取相似结构以及生成更符合人类视觉特征的纹理信息上具有明显的优势,且当缺损区域更大时表现得更为明显。
4.2 定性分析
我们在图3中列举了不同网络对人脸手势遮挡修复任务的部分修复结果,可以发现,我们的模型所生成的人脸面部五官的结构信息更加自然、准确、清晰,且符合原图的人脸特征。图4展示了不同修复方法在大面积不规则缺失修复任务中的结果示例,即使面对大规模的有效信息丢失,本文提出网络也可以做到在生成符合人眼逻辑的五官结构纹理的同时尊重原图的颜色信息,使最终呈现效果具有更高的保真度。当修复面积增大且大于40%时,相较于对比模型,本文所提方法依旧可以生成更完整的面部信息结构,在掩码边缘的色彩过渡更为自然和谐,纹理细节更加清晰流畅。
5 结 论
本文针对人脸去除手势遮挡任务提出一种新的基于预测滤波核以及结构记忆搜寻的端到端三分支网络——TreeNet。滤波和预测网络分支可以有效利用深度神经网络生成可以感知空间变化以及进行语义感知的可学习动态滤波核。结构记忆转化分支促使网络在处理大面积损毁的图像时依然能够生成合理的人脸五官信息。经实验验证,TreeNet在人脸去手势遮挡任务中表现优异,生成的人脸图像五官结构清晰,色彩保真度高且不会引入过多的伪影(即纹理模糊)。
参考文献:
[1] GUO Q,SUN J Y,XU J f,et al. Efficientderain: Learning pixel-wise dilation filtering for high-efficiency single-image deraining [J/OL].arXiv:2009.09238 [cs.CV].[2023-02-12].https://arxiv.org/abs/2009.09238v1.
[2] KARRAS T,AILA T,LAINE S,et al. Progressive growing of gans for improved quality, stability, and variation [J/OL].arXiv:1710.10196 [cs.NE].[2023-02-14].https://arxiv.org/abs/1710.10196v2.
[3] AFIFI M. 11K Hands: Gender recognition and biometric identification using a large dataset of hand images [J/OL].arXiv:1711.04322 [cs.CV].[2023-02-18].https://arxiv.org/abs/1711.04322v8.
[4] BERTALMIO M,SAPIRO G,CASELLES V,et al. Image inpainting [EB/OL].[2023-02-06].https://dl.acm.org/doi/pdf/10.1145/344779.344972.
[5] CRIMINISI A,PÉREZ P,TOYAMA K. Region filling and object removal by exemplar-based image inpainting [J].IEEE Transactions on Image Processing,2004,13(9):1200-1212.
[6] NAZERI K,NG E,JOSEPH T,et al. EdgeConnect: generative image inpainting with adversarial edge learning [J/OL].arXiv:1901.00212 [cs.CV].[2023-02-16].https://arxiv.org/abs/1901.00212.
[7] REN Y R,YU X M,ZHANG R N,et al. StructureFlow: image inpainting via structure- aware appearance flow [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul:IEEE,2019:181-190.
[8] YU J H,LIN Z,YANG J M,et al. Generative image inpainting with contextual attention [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE,2018:5505-5514.
[9] ZENG Y H,Fu J L,CHAO H Y,et al. Aggregated contextual transformations for high-resolution image inpainting [J/OL].IEEE Transactions on Visualization and Computer Graphics,2022:[2023-02-09].https://ieeexplore.ieee.org/abstract/document/9729564.
[10] VOO K T R,JIANG L M,LOY C C. Delving into high-quality synthetic face occlusion segmentation datasets [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).New Orleans:IEEE,2022:4710-4719.
[11] LI J Y,WANG N,ZHANG L F,et al. Recurrent feature reasoning for image inpainting [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:7757-7765.
作者簡介:欧静(1997—),女,汉族,陕西汉中人,硕士研究生在读,研究方向:计算机视觉、图像生成与分析;通讯作者:文志诚(1972—),男,汉族,湖南东安人,教授,硕士研究生导师,博士研究生,研究方向:计算机视觉、数字图像处理、模式识别。
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
