
基于作物生长模型与机器学习算法的区域冬小麦估产
2023-06-20 04:40:30马战林周颖杰鲁春阳薛华柱李长春
农业机械学报 2023年6期
马战林 文 枫 周颖杰 鲁春阳 薛华柱 李长春
(1.河南城建学院测绘与城市空间信息学院, 平顶山 467001; 2.河南城建学院管理学院, 平顶山 467001;3.河南理工大学测绘与国土信息工程学院, 焦作 454003)
0 引言
河南省为中国小麦主产地之一,冬小麦产量约占全国小麦产量的25%。精准、高效、实时的区域冬小麦产量预测,不仅能够为河南省各级政府、相关部门制定农业农村政策提供技术支持,同时对保障中国粮食安全、农业可持续发展、种植结构优化和数字农业建设也有重要意义[1]。
当前,作物估产常用的方法有人工区域调查法、作物生长模型及机器学习算法3类。人工区域调查方法工作量大且成本较高,难以实现大范围、高频的区域尺度作物估产,但其优势是获取的点源信息准确度高。作物生长模型虽融入光、温、水、土壤等条件为环境驱动变量,对作物生长的全过程、产量形成机理具有较好的科学解释性,但仅在单点尺度上建立和实现作物生长发育动态模拟。遥感对地观测的优势在于提供大空间、面元尺度的作物物候、生长冠层信息。实现遥感信息与作物生长模型的耦合,则能够利用空间上连续、时间上动态变化的卫星观测数据得到模型中较难获取的区域级尺度参数,以校正、优化作物生长模型与产量形成过程的相关参数,使模拟的产量结果更为准确[2]。结合遥感数据与作物生长模型实现区域估产的方法主要包含驱动法和同化法。相比于驱动法,同化法已成为近年来的研究热点。
同化法以改进或调整作物生长模型中与作物生长总生物量、粮食产量形成密切相关的输入参数或初始条件,从而缩小作物生长模型模拟的和遥感数据反演的状态变量间的差距,达到准确估测作物生长模型参数和提高作物估产精度的目的。针对作物模型敏感性参数分析,常用的敏感度分析方法主要有Morris、FAST、Sobol、EFAST等方法[3]。对于同化方法,当前同化法主要有扩展卡尔曼滤波(Extended Kalman filter,EKF)、粒子滤波(Particle filter,PF)、集合卡尔曼滤波(Ensemble Kalman filter,EnKF)等顺序同化算法和基于最优控制的全局拟合法,如四维变分(4DVAR)[4]、三维变分(3DVAR)及VW-4DenSRF[5](Variable time window and four-dimensional extension)等方法。其中,EnKF、4DVAR同化法最为常用。相关研究表明,EnKF在相对较小的研究区域上能够取得较高的产量模拟精度[6]。如谢毅等[7]对比4DVAR和EnKF不同同化算法模拟关中平原冬小麦产量精度,结果表明EnKF算法在同化LAI时的产量估算精度较高。另外,同化变量的选择同样会影响参数的调整,最终影响作物产量预报精度[2]。当前常用的同化变量主要是LAI,其次为土壤含水率、生物量等。
当然,数据同化是一种将外部观测数据纳入动态力学模型的方法,同化单元尺寸的选择不仅取决于遥感数据反演的同化参数分辨率,同样也取决于气象要素、作物、土壤及田间管理的分辨率。更细的同化单元则伴随着巨大的计算力,需要研发更高效的同化策略及适用于高性能计算的组织架构与模式。近年来机器学习方法已与遥感信息进行融合,被广泛应用于作物估产研究[8]。机器学习算法具有很强的非线性拟合能力和高计算效率,但其是一种数据驱动的模型,大量的样本才能使得该模型涵盖尽可能的分布,从而提升其适用性。受作物育种技术、品种特性的影响,作物长势监测和估产模型构建所需的样本数据一般是近5年的数据,造成作为训练样本的数据量有限且具有很强的时效性[8]。且使用机器学习实现区域作物估产,样本采集会耗费大量人力物力。
从提升区域估产精度与效率的角度出发,本文以河南省鹤壁市石桥村为研究区,基于PROSAIL辐射传输模型反演多时相Sentinel-2光学遥感影像的时序LAI,利用EnKF算法同化时序LAI到作物生长模型中,提供不同长势的一定数量单点产量训练数据,利用建立的机器学习模型反演区域冬小麦产量,以期实现作物生长模型与机器学习算法的耦合,为准确、实时、高效地实现区域作物估产提供新的模式与技术。
1 材料与方法
1.1 研究区域
鹤壁市是河南省重要的冬小麦种植区,稳定的气候环境和少发的极端气候为建立和验证作物估产模型提供良好的气候条件。为验证建立的耦合作物生长模型与机器学习算法实现区域估产的有效性,该研究在鹤壁市中部地区淇县桥盟乡石桥村建立村级区域级别的试验与算法验证基地。该基地是鹤壁市重要的冬小麦种植区和高标准农田建设示范基地,地势平整、连片。试验区占地309.23 hm2,是河南省农业大数据中心的规模化管理种植区。研究区具体位置如图1所示。
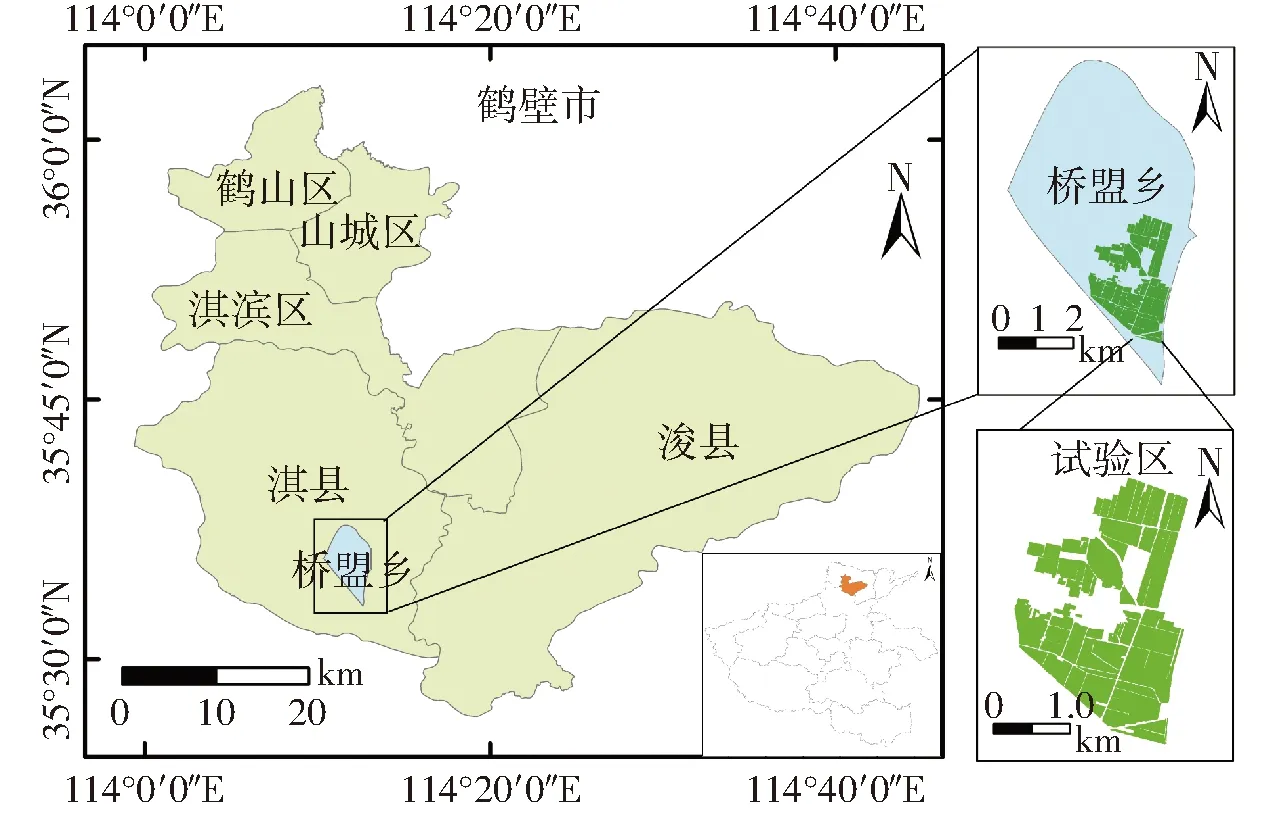
图1 研究区地理位置Fig.1 Geographical location of study area
试验区属暖温带半湿润型季风气候,四季分明,光照充足,年平均气温14.2~15.5℃,年降水量349.2~970.1 mm;年日照时数1 787.2~2 566.7 h。试验区土壤类型以粘土为主, 灌溉条件良好, 主要种植模式为冬小麦和夏玉米轮作。冬小麦播种时间通常情况下在10月上、中旬,出苗期在播种后5~6 d。根据当地气候情况,11月下旬到次年2月下旬,冬小麦处于越冬期;2月底到3月上旬进入返青期,随着气温升高,冬小麦随后开始快速、旺盛生长;3月中、下旬冬小麦开始起身,4月中旬到5月上旬为拔节孕穗期,随后中旬进入灌浆期,中、下旬为乳熟期,并在6月上旬完成收获。
1.2 PyWOFOST作物生长模型及其所需数据
WOFOST作物生长模型以光拦截和CO2为驱动因素,应用一系列参数模拟和控制不同类型、不同品种作物受环境条件影响时的呼吸、蒸腾、物候、干物质积累及其分配等生长发育过程。其对作物生长发育控制的过程主要分为出苗、开花和成熟3个生育期,可估计特定作物类型每天的LAI、地上生物量和存储器官总干质量(TWSO,即粮食产量)等。另外,该模型可以在潜在模式(无水和养分胁迫引起的限制)、水分限制模式(土壤水分胁迫)或营养限制模式下运行。PyWOFOST模型是WOFOST模型的Python版本,其驱动数据包含气象数据[9]、作物参数数据、土壤数据及田间管理数据。
1.2.1气象数据
PyWOFOST模型需最低与最高温度、太阳辐射、降雨量、风速等气象数据。研究使用田间建立的小型气象观测站数据,如图2所示。该气象站点数据包含的逐日气象要素包含平均气温、最高与最低气温、风速、降雨、日照时数、水汽压和辐射等。考虑到试验区范围、平坦的地形因素及仅有的单个气象站数据,估产过程中应用气象站数据时未进行反距离插值的面域处理。

图2 气象站位置及其实物图Fig.2 Weather station location and weather station
1.2.2作物生长参数
冬小麦作物生长参数是PyWOFOST模型中的最重要参数[10],也是不确定性最大的参数,描述小麦的遗传特性、发育性状和产量性状等,控制着冬小麦的生长发育过程,与植株形态的发展和籽粒产量的形成直接相关。该参数包含不同发育阶段所需要的积温、光周影响因子、不同生育期的最大光合速率、不同生育期的比叶面积、干物质分配系数、干物质和叶片的死亡率等。在应用PyWOFOST模型前,需要对冬小麦的作物参数数据进行设置和标定,以实现模型的本地化应用。作物生长参数[10-12]见表1。

表1 PyWOFOST模型冬小麦主要作物参数Tab.1 Main crop parameters in PyWOFOST model
1.2.3土壤数据
土壤是作物生长的基础,土壤参数的准确性直接影响作物模型的模拟精度。土壤质地和结构是土壤的基本物理特性。在冬小麦播种前,对土壤样品进行实地采样并进行理化性质分析。测定0~10 cm、10~20 cm、20~50 cm、50~80 cm、80~120 cm、120~160 cm的6个土壤剖面参数。土壤参数主要包含土壤质量含水率、土壤相对湿度、土壤容重、田间持水量、凋萎湿度等PyWOFOST模型需要输入的土壤参数。参数如表2所示。

表2 PyWOFOST模型土壤参数Tab.2 Main soil parameters in PyWOFOST model
1.2.4田间管理数据
在冬小麦播种期前,实地调查土壤墒情,在10月22日开始播种,播种品种为郑麦-119,播种量为210~270 kg/hm2。PyWOFOST模型的田间管理数据需要输入灌溉时间,施肥元素、时间及设定利用效率。管理数据必须输入作物种植时间、开始生长时间和收获时间,以便和气象数据进行时间上的匹配。表3为田间管理和冬小麦实地考察的生育期。
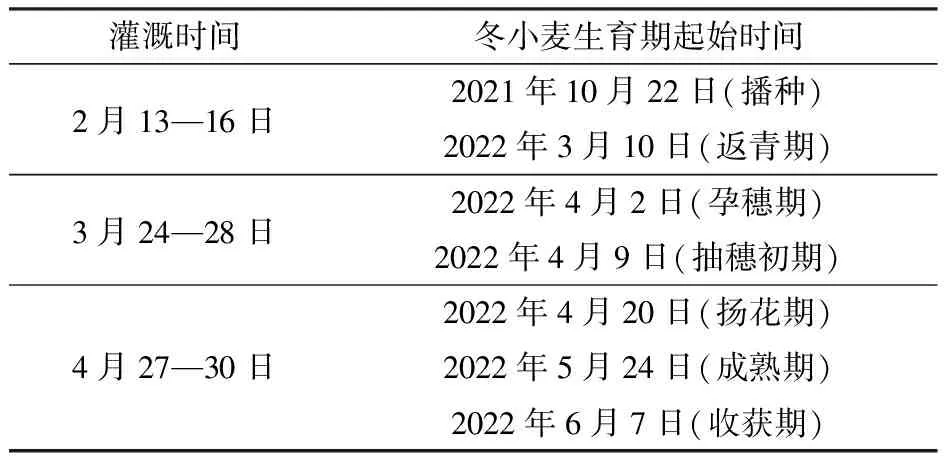
表3 PyWOFOST模型田间管理和主要生育期参数Tab.3 PyWOFOST model management and primary reproductive period parameter
1.3 遥感数据与观测数据
研究应用GEE遥感数据平台获取Sentinel-2多光谱遥感数据,该数据的具体介绍及获取方式见文献[13]。
结合冬小麦关键生育期、长势状况和卫星过境时间确定叶面积指数、土壤含水率、地上生物量、叶片叶绿素含量、冠层光谱等采集工作。地面点数据采集时间为2022年3月4日、3月10日、4月2日、4月9日、4月19日、4月29日、5月23日、5月27日。冬小麦叶面积指数的单点获取主要应用LI-COR公司的LAI-2200型植被冠层分析仪,具体操作参照文献[14]。采集点坐标使用中海达V30型GPS仪器获取,与遥感数据统一为WGS-84坐标系。
对于产量数据的获取,在冬小麦成熟期,依据不同长势分布选取74个点作为样方。在1 m×1 m的样方范围内,人工数出实际株数和有效麦穗数,并对样方范围内的小麦进行收割。收割后对样品进行干燥、人工脱粒和称量,并计算各样方点产量。在种植过程中将地块分为10个管理区,为验证区域产量估测的精度,在冬小麦收获过程中,对每个区的产量进行区域级别的统计。采样样方设计、采样点位置和管理区分布情况如图3所示。
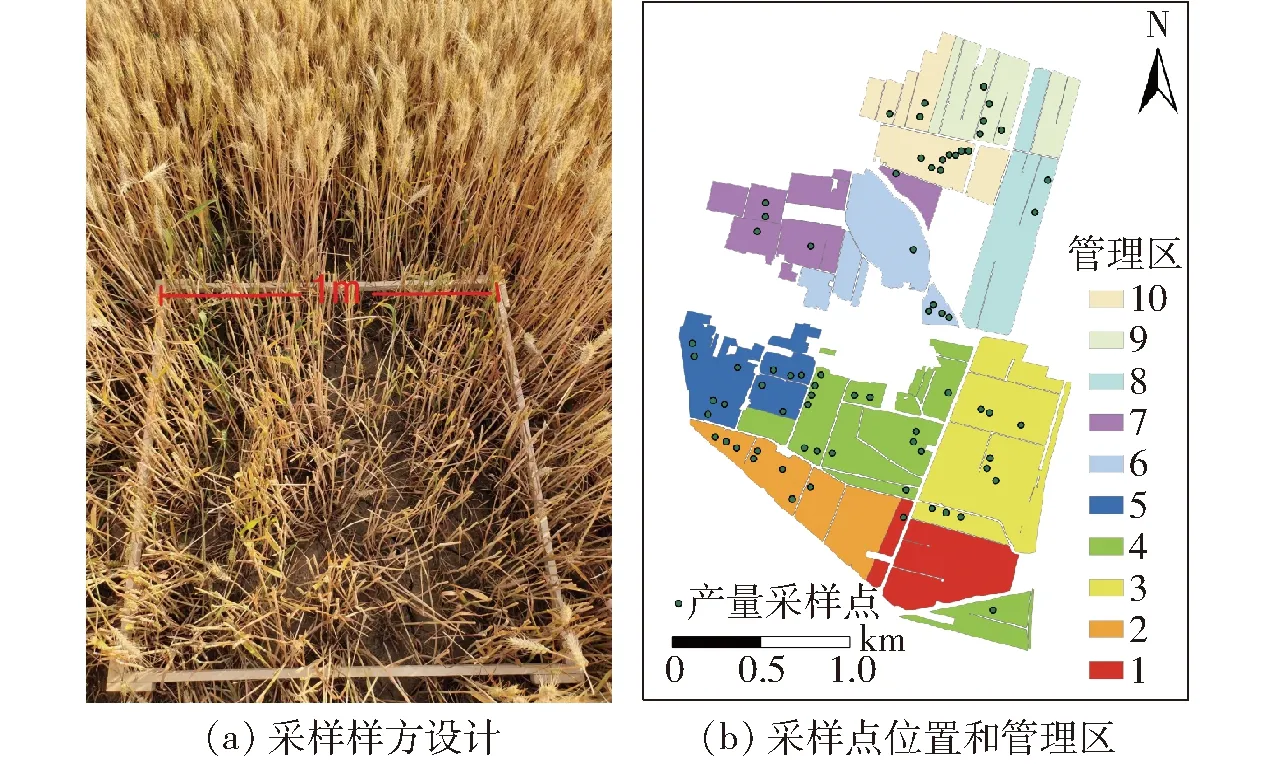
图3 采样样方设计、采样点位置和管理区分布Fig.3 Winter wheat sampling design, sampling point location and management area distribution
1.4 研究方法
1.4.1叶面积指数反演算法
不同物候期的LAI能够反映当时作物群体的长势状况及特征、光合作用、生物量和产量形成等诸多理化进程[15]。研究应用PROSAIL辐射传输模型反演不同时期的叶面积指数。具体PROSAIL辐射传输模型的参数敏感性分析、优化参数选择参照文献[16],参数优化方法选择计算效率优于查找表法[17]的SUBPLEX算法[18]。
1.4.2EnKF同化算法
EnKF的核心思想是利用集合预报的方式,基于统计得到的背景误差协方差进行状态变量的最优估计,实现对误差协方差的更新。EnKF在处理各种数据不确定性时比较灵活,算法易于实现和操作,因此被广泛应用于地表数据同化研究中。EnKF具体算法及流程参照文献[19]。
1.4.3RFR算法
应用PyWOFOST作物生长模型反演单点产量作为机器学习算法训练数据时,该模型反演的产量误差会对建立的机器学习模型产生影响。为减弱后续建立的机器学习模型再次产生的误差传递而影响面域估产精度,研究选择训练速度快、防过度拟合、抗噪性和模型泛化能力强等特点的RFR算法[20]。
1.4.4精度评价
采用决定系数R2、均方根误差(Root mean square error,RMSE)、平均绝对误差(Mean absolute error,MAE)、偏差(Bias)对反演的LAI与单点产量进行反演精度评价。对于区域产量精度评价,计算公式为
P=1-|Rpredict-Rstatics|/Rstatics
(1)
式中P——区域产量监测精度
Rpredict——区域产量反演结果
Rstatics——区域产量统计结果
2 结果与分析
2.1 PROSAIL辐射传输模型反演叶面积指数
基于Sentinel-2光学数据的B2、B3、B4、B8波段,应用SUBPLEX算法和PROSAIL辐射传输模型实现单点尺度LAI的反演。实地LAI单点采样时间和光学数据的对应时间如表4所示。图4为研究区不同时期的遥感影像,其时间与实地采样时间存在差异。实地考察中,冬小麦在4月20日进入扬花期,叶片发育开始减缓,4月28日进行全域灌溉,造成4月29日采集样本较少(仅7个),因此5月2日影像反演的LAI采用4月19日和29日的合并采集数据进行验证。研究基于单点LAI的采样坐标,应用SNAP软件的“Raster→Export→Extract pixel values”操作步骤提取单点Sentinel-2影像的不同波段光谱数据。

表4 Sentinel-2卫星影像日期和地面单点LAI采样日期Tab.4 Sentinel-2 satellite image date and LAI collection samples date
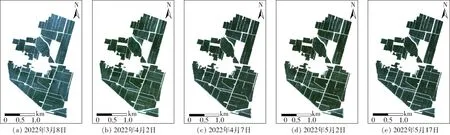
图4 研究区不同时期遥感影像Fig.4 Study area remote sensing images at different periods
每期光学影像数据单点尺度的叶面积指数反演结果与精度如图5和表5所示。从图5与表5可以看出,针对单幅影像LAI的反演情况,4月2日的R2最高,达到0.744 5。其原因是卫星当天过境,地面点LAI当天采集,两者数据时间匹配良好。5月2日的R2相对3月8日、4月2日和4月7日3期的R2较低,为0.608 1;造成该日R2较低的原因是地面点采集时间与遥感影像时间差距过大。5月13—25日,冬小麦生育期从灌浆期步入成熟期,冬小麦叶片及穗的逐日特征变化迅速、明显,造成5月17日测量与反演LAI的R2非常小,仅为0.055 1,并存在明显的低估现象,同时RMSE、MAE、Bias也达到最大,分别为0.910 3 m2/m2、0.780 0 m2/m2、0.524 6。就整体LAI反演情况而言,该反演方法存在一定的低估现象,但整体反演LAI的R2、RMSE较好,达到0.863 2、0.719 3 m2/m2,特别是Bias达到0.090 8,高于苏伟等[16]在参数标定前应用PROSAIL模型反演LAI的精度(R2=0.73,RMSE为0.79 m2/m2)。RMSE和MAE也低于4月7日、5月2日和5月17日,达到0.719 3 m2/m2和0.574 7 m2/m2。因此,该方法反演LAI的可靠性良好。

表5 单点叶面积指数反演精度评价Tab.5 Evaluation of retrieval accuracy of single-point LAI
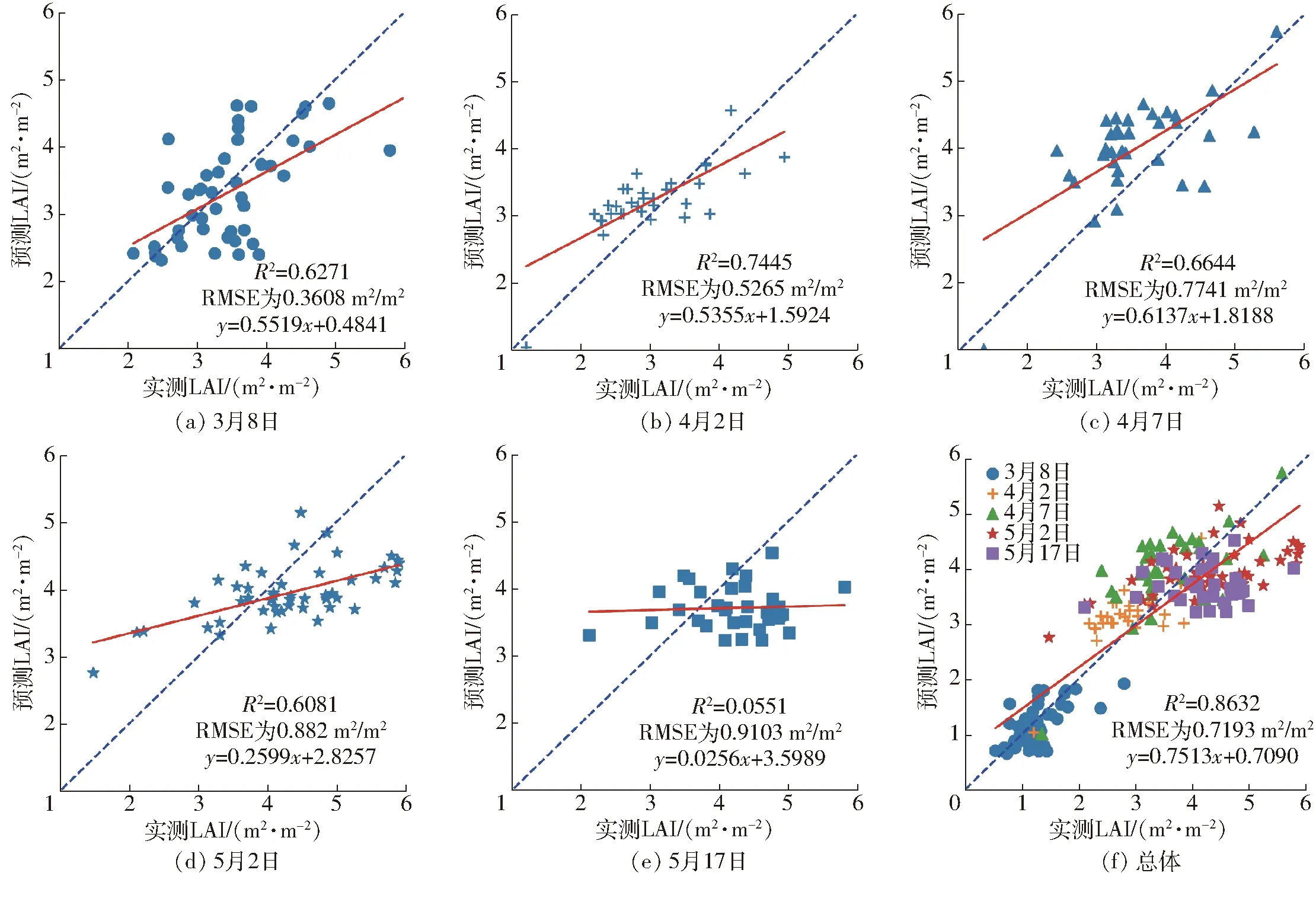
图5 SUBPLEX+PROSAIL算法单点叶面积指数反演Fig.5 SUBPLEX+PROSAIL algorithm retrieval single-points LAI
应用上述方法进行区域LAI反演,同样以B2、B3、B4、B8波段作为输入,逐像元进行区域LAI反演,不同时期反演LAI的值域分布结果如图6所示。有研究表明,NDVI与LAI有较强的相关性[21],为探究区域LAI反演分布的可靠性,引入区域NDVI图像进行分析。区域NDVI分布情况如图7所示。从图7看出,NDVI在4月2日前期能够反映作物的长势信息,但在4月2日到5月2日内趋于饱和,反映作物长势信息能力相比LAI较差,且NDVI在达到饱和后,LAI和NDVI的相关性较弱。但在5月17日,冬小麦趋于成熟期,NDVI值降低,LAI同样能够反映冬小麦长势分布及情况。
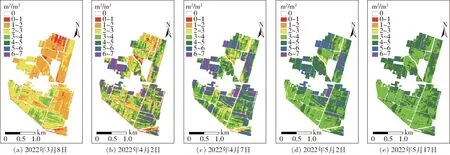
图6 PROSAIL+SUBPLEX算法反演LAI值域分布Fig.6 LAI value domain distribution map by PROSAIL + SUBPLEX algorithm retrieval
2.2 基于EnKF算法的同化策略与估产实现
2.2.1PyWOFOST作物生长模型参数敏感性分析
PyWOFOST模型参数众多,为对每个参数或参数间相互作用影响输出结果的程度进行定量评价,需对不同参数及参数间耦合作用进行全局敏感性分析。少数模型参数通常是模型输出的大部分可变性的原因,而大多数其他参数可能只有很小的影响。为集中精力校准一定生物学意义的少数敏感性参数和保证模型模拟效果,又适当减少计算量,参照文献[22],对表1中27个PyWOFOST模型主要参数及大部分研究中未加入蒸散速率修正因子(CFET)和土壤水分消耗作物群数量(DEPNR)参数进行敏感性分析[11]。
研究利用Sobol全局敏感性分析算法[3]对目标变量TWSO进行参数敏感性分析。Sobol法的参数样本数设置为2 000×29。研究主要应用PyWOFOST作物生长模型的潜在模式,基于2021—2022年冬小麦生长期间的站点气象数据实现参数的敏感性分析,结果如图8所示。潜在模式下对TWSO敏感的前4个主要参数有AMAXTB1、TDWI、TSUMEM和CVO。

图8 对TWSO相关的参数敏感性分析Fig.8 Parameters sensitivity analysis about TWSO
2.2.2同化变量选取与参数标定方案建立
作物生长模型是一个基于过程的模型,LAI能够描述作物在不同生长阶段的特性,常作为作物模型与遥感数据耦合的同化变量[18]。故研究同化变量主要选择LAI,在校准LAI时需综合考虑当地的生产条件及与LAI相关参数的敏感特性。
参考许伟等[19]参数标定方法及为提高单点估产精度,研究同样选取作物生育期最大叶面积指数(LAImax)作为分析对象,结合2021—2022年气象站提供的气象数据,分析PyWOFOST作物模型与LAI相关的14个重要输入参数(TBASEM、RGRLAI、SPAN、TBASE、TDWI、Q10、RMR、RMS、RML、RMO、 CVL、CVR、CVS、 CVO)敏感性,分析结果如图9所示。本文选取TDWI、TBASE、CVS、CVL作为对LAImax敏感的待优化参数。
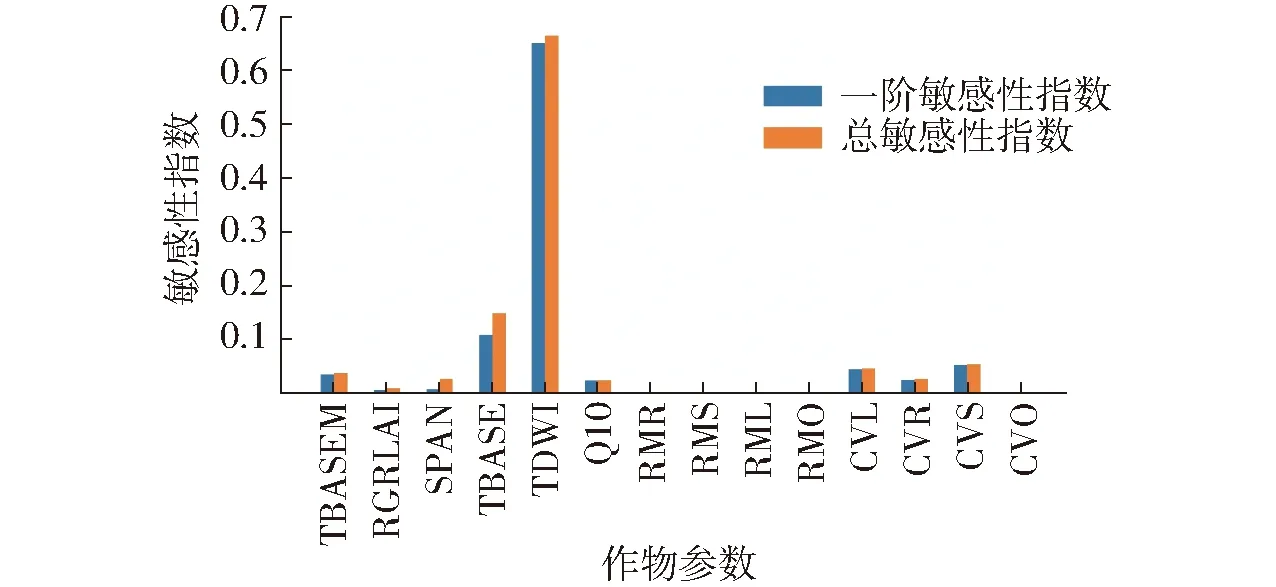
图9 对LAImax相关的参数敏感性分析Fig.9 Parameters sensitivity analysis about LAImax
对于参数标定方法,本文利用反演的多时相LAI和粒子群优化算法[23](Particle swarm optimization,PSO)优化与LAImax相关的4个敏感参数,并将优化后的值输入到同化LAI的EnKF+PyWOFOST估产系统中,以实现单点产量的估算。同化运行过程中PyWOFOST模型应用潜在模式,且集合的成员数(N)对同化速率和结果有重要的影响,相关研究表明N≥30时就能表现出更高的同化精度[12]。同化变量LAI反演精度的标准差设为本值的10%,以对LAI进行扰动设置[2],生成LAI的集合N=200。基于实测单点产量进行验证分析,结果如表6和图10所示。预测的单点产量与实测产量的R2、RMSE、MAE、Bias分别为0.866 5、468.64 kg/hm2、385.70 kg/hm2和103.08。相对于黄健熙等[12]、谢毅等[7]早前的估产精度,该方法具备较好的单点估测精度。

表6 单点尺度同化估产精度评价Tab.6 Single points yield accuracy estimation
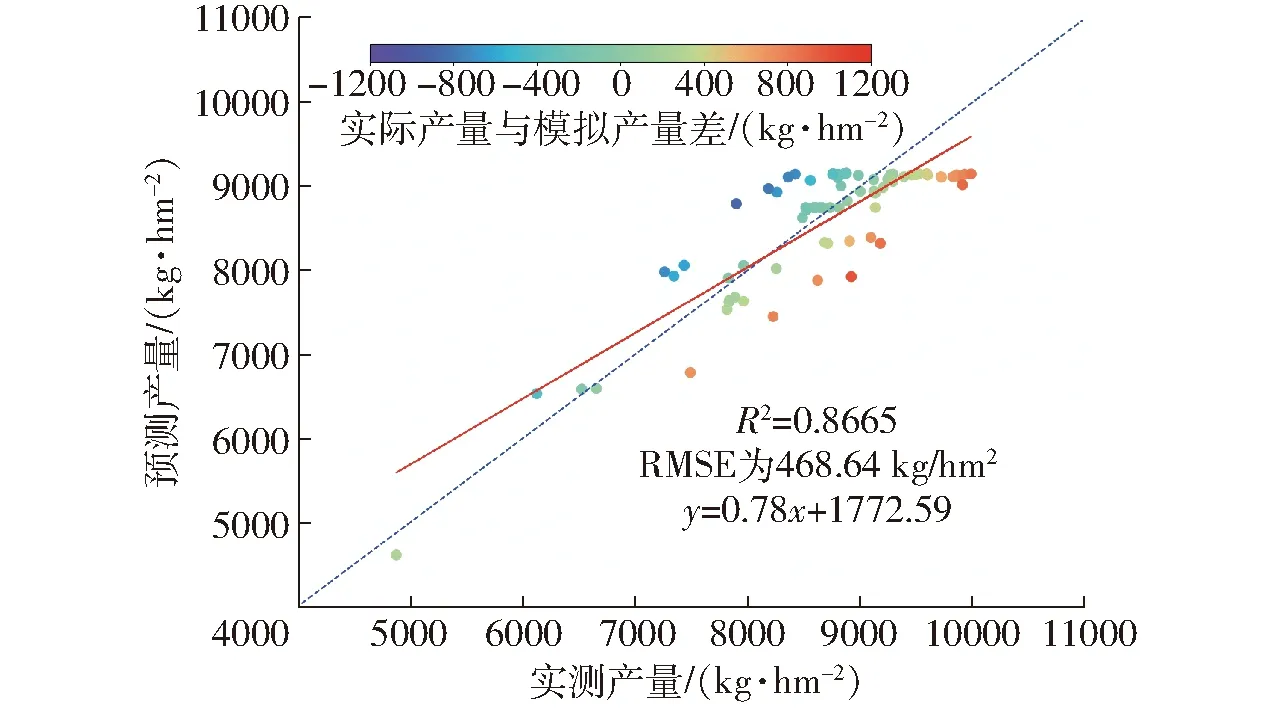
图10 同化多时相LAI实现单点尺度估产Fig.10 Assimilation multi-temporal LAI to realize single points yield estimation
2.2.3区域产量估算模型构建与分析
研究基于本文的参数标定方法和同化多期LAI到EnKF+PyWOFOST估产系统中,逐像元计算试验区每个像元的产量模拟值,其产量分布结果如表7和图11a所示。研究区(309.23 hm2),仅同化LAI过程得到区域产量结果花费时间接近144 h,即每公顷算法运行用时约0.47 h。从表7发现,应用同化方法的区域整体估产精度为89.01%,其中管理区最低、最高区域估产精度分别为第5管理区的76.37%和第7管理区的95.53%。结合图3管理区分布和图6中反演LAI的分布情况,发现区域LAI分布越均匀,估产精度越高。此原因是LAI表达作物的群体特征,应用空间分辨率10 m的遥感数据,对冬小麦长势分布的表达能力有限。若提升长势分布复杂的区域估产精度,建议采用更高分辨率的无人机数据。

表7 区域统计产量与模拟产量Tab.7 Regional statistical yields and simulated yields
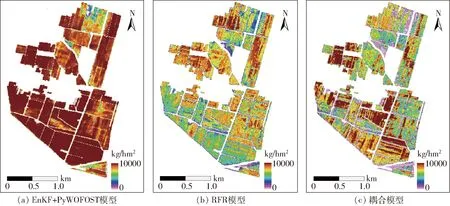
图11 不同模型冬小麦区域估产图Fig.11 Regional yield estimation map of winter wheat based on different models
应用机器学习算法实现作物估产的依据是作物生长因素受多种因素的影响,且其生长过程是一个非常复杂的生物生理过程,但作物生长状况、产量可以用一些与其生长过程密切相关的参数进行表征。
因此机器学习方法是一种与作物生长模型不同的估产方法。由于冬小麦产量形成的非线性和非平稳性,在应用机器学习进行冬小麦产量建模时,需结合多个生育期的关键影响因子综合建模,才能有望提升冬小麦产量预测的精度。刘新杰等[24]利用冬小麦抽穗期和乳熟期的累积NDVI值可实现冬小麦产量的精确估算,黄健熙等[25]建议使用多时序的NDVI值进行估产研究。研究参照上述研究结论,应用多时相NDVI和其NDVI累计值作为RFR算法预测产量的变量。其反演区域产量结果如表8和图11b所示。此过程花费时间为8 min,平均每公顷算法运行用时约1.55 s。从表8发现,区域整体估产精度虽达到99.44%,不同管理区的估产精度仍存在较大差异,如管理区5和管理区7的估产精度与物理模型区域估产精度表现一致。

表8 基于机器学习的冬小麦区域估产统计Tab.8 Statistics of winter wheat regional yield estimation based on machine learning
为更快地实现区域估产及避免现场产量采集工作,将上述两类算法进行耦合以实现区域冬小麦估产研究。研究使用PyWOFOST物理模型反演采集点的单点产量,结合5期遥感数据的NDVI和NDVI累计值作为训练数据,输入RFR模型中建立估产模型,得出区域尺度的产量,结果如表9和图11c所示。此过程花费时间44.25 min,平均每公顷用时约8.85 s,其中利用EnKF+PyWOFOST模型花费时长约36 min,占总时长约81.35%。耦合模型的区域估产精度高于物理模型6.57个百分点,低于机器学习模型3.86个百分点,且在各管理区域的估产精度分布上,与上述两者表现出较强的一致性,说明耦合模型具有较强的适用性。

表9 耦合PyWOFOST作物生长模型与机器学习的冬小麦区域估产统计Tab.9 Regional winter wheat yield estimation coupled PyWOFOST crop growth model with machine learning
3 讨论
研究使用PROSAIL辐射传输模型结合Sentinel-2光学数据反演不同时期的LAI,相对于应用机理性弱的机器学习方法反演LAI,该方法具有普适性[26]。PROSAIL模型参数众多,特别是采用查找表法计算参数时,容易造成病态反演问题,导致反演LAI的可靠性减弱。后续研究将利用该模型结合MCMC[27]、VMG[26]等参数优化方法反演LAI,检验SUBPLEX+PROSAIL算法组合反演LAI的可靠性和抗噪能力。
同化多期Sentinel-2光学数据反演的变量时,光学成像时间基本固定,易造成同化时影像数据时间过于集中、分散或关键物候期缺乏[28]的情况,对物理模型估算单点产量精度造成一定影响,近而影响耦合模型的区域估产精度。后期研究中使用不受天气影响Sentinel-1 SAR数据反演同化所需的变量[21]或利用更加丰富的多源遥感数据增加同化过程中的数据量,以提高估产精度[29]。当然,过多的数据量会降低计算效率,后续研究需确定合适同化数据量、同化变量的时间与同化步长,在同化数据量和估产精度方面做均衡评估。
耦合作物生长模型和机器学习模型存在误差传递问题,即基于作物生长模型估产的单点产量本身存在一定的误差和机器学习是高度依赖训练样本的算法,单点产量用于机器学习建模中,会导致误差的传递,而如何解决和描述误差传递的过程和不确定性分析是本文存在的缺陷和难题。研究中仅使用PyWOFOST作物生长模型。作物生长过程是一个非常复杂的非线性系统,具备高度的空间异质性,单一的作物模型无法完全表达和模拟作物生长过程中的所有动态变量,因此需建立多作物模型估产系统进行产量评估,如DSSAT[30]、APSIM-Wheat[31]等模型,依据一定的权重实现多模型联合产量估算。
当前的研究多基于MLR、RFR或SVR方法来探究多时相NDVI、LAI与作物产量的关系[9]。虽然使用上述几种方法能够产生更好的产量估算,但其算法本身不能处理卫星的时间序列数据,致使作物某阶段的生长状态变量会影响最终产量上体现较弱。相关研究表明,LSTM模型能够从时间序列中学习历史特征[32],比从静态角度处理输入数据的方法(如RFR方法)具有更大的潜力,若将CNN算法[33]与LSTM模型进行融合[34],则模型可从卫星的时间序列上提取空间和时间特征,从而提升冬小麦的估产精度。
4 结论
(1)基于观测的时序LAI,应用PSO优化算法逐像元优化与LAImax相关的敏感性参数(TDWI、TBASE、CVS、CVL),将优化参数输入到PyWOFOST作物生长模型中,再使用EnKF算法同化时序LAI到PyWOFOST作物生长模型,以调整对TWSO敏感的4个参数(AMAXTB1、TDWI、TSUMEM、CVO),得到的单点模拟产量具有较高精度,其R2、RMSE分别达到0.866 5和468.64 kg/hm2,优于相关研究。
(2)为解决同化遥感信息与作物生长模型在区域估产中计算低效的问题,应用EnKF算法同化PROSAIL模型反演的多期LAI到PyWOTOST作物生长模型中,估测一定数量冬小麦不同长势采样点的产量,将模拟的多个单点产量和该点的多时相NDVI数据建立RFR机器学习算法模型,并利用面域多时相NDVI和建立的RFR模型实现区域冬小麦估产。结果表明,耦合模型区域产量模拟精度在试验区的小区域范围内估产精度最低为81.28%,在试验区总体估产精度达到95.58%,有效避免机器学习所需的人工实地采样和减弱利用同化方法实现区域估产面临的巨大算力需求,为快速、准确实现区域作物估产提供新的思路。
猜你喜欢
山西农业科学(2021年2期)2021-02-24 05:19:20
电脑知识与技术(2020年21期)2020-08-21 17:21:37
中国惯性技术学报(2020年2期)2020-07-24 08:41:02
山东冶金(2019年5期)2019-11-16 09:09:10
植物保护(2017年1期)2017-02-13 06:44:34
山东工业技术(2016年15期)2016-12-01 05:31:14
信息记录材料(2016年4期)2016-03-11 15:22:33
江苏农业科学(2015年11期)2016-01-27 09:44:15
中学生(2015年4期)2015-08-31 02:53:50
江苏农业科学(2015年2期)2015-03-12 17:54:58
