
基于等距拆分和随机森林算法的皖北小麦始花期气象预报
2023-06-20 00:51乐章燕陈文涛史锡军马嘉炜邱虎森
麦类作物学报 2023年6期
李 德,乐章燕,陈文涛,史锡军,马嘉炜,陈 伟,孙 朋,邱虎森
(1.安徽省宿州市气象局,安徽宿州 234000;2.河北省廊坊市气象局,河北廊坊 0650002;3.宿州学院环境与测绘工程学院,安徽宿州 234000)
小麦赤霉病是世界范围内广泛流行的小麦病害,具有暴发性强、抗病育种难度大、防治适期时效性强、危害损失重等特点[1-3]。随着全球气候变暖和耕作方式的改变,小麦赤霉病的发生危害面积和频次不断增加。在中国小麦主产区的黄淮麦区,赤霉病也已成为常发病害[2-4]。“见花打药,统防统控”是当前赤霉病防控工作的黄金法则[3-6],其关键是提前对小麦开花日期进行准确预报,从而为药剂药械、人力调度等提供决策依据。
目前,诸如小麦开花期、成熟期等作物物候预报问题一直受到学者的关注。统计模型、过程机理模型和理论模型[7-8]是物候预报的传统方法,但均存在不足,如统计模型未考虑影响因子之间的非线性关系[7,9]、过程机理模型的机理研究不清且参数多[10-11]、以遥感数据驱动的理论模型[7-8]在研判阈值上存在不确定性[12-16]等。机器学习算法由于在理解和预测生物系统和非生物系统间复杂的相互作用方面具有优势,且不要求样本数据具有特定的分布形式,能智能分析数据规律并利用其进行预测[7-9,17],特别是随机森林算法(RF,random forest),近年来已在玉米物候识别[18]与叶绿素浓度估算[19]、梨树花期[9]、天气类型与气象要素[20-24]、森林火灾[19]、空气质量[26]、小麦产量[27]和赤霉病病穗率预测[28]等许多领域得到应用并取得较好预测效果。然而,目前这方面的研究在训练模型时,多采用从基础数据集中随机抽取样本[9,19-21,25],或将全部样本[22-23,26]作为训练集,或直接采用Bootstrap法[24,27-28]训练模型,并未对样本不均衡引起的过拟合问题进行关注[29-31]。同时,应用RF算法进行作物物候预测的研究相对较少。本研究依据前人先验知识,筛选影响皖北地区小麦始花期早迟的关键气象因子作为特征变量,以小麦始花期为目标变量,采取有序等距离抽样的拆分方法,构造训练集与测试集,再根据不同起报时间,由RF算法训练构建皖北地区小麦始花期气象预报模型并实现始花期逐日预报,以期通过解决样本不平衡问题,提升始花期预报精度,为小麦赤霉病精准防控提供技术支撑。
1 材料与方法
1.1 研究地概况
冬小麦是安徽省主要粮食作物之一,其中皖北地区常年种植面积140 万 hm2以上,约占全省种植面积的70%,年总产量占全国总产量的8%左右[6,32]。皖北平原属黄淮冬麦区[33],冬小麦适宜播种期间日平均气温15~18 ℃,越冬期间年平均气温0 ℃上下,极端最低气温不低于-20 ℃,越冬期冻害几率低。冬小麦生育期间多年平均降水量为300 mm左右,≥0 ℃积温2 300 ℃·d,日照时数约1 300 h。
1.2 数据来源
1980-2019年,皖北地区亳州、砀山、蒙城、宿州、阜阳、寿县和五河7个农业气象观测站的冬小麦始花期原位观测地段的物候观测数据和气象监测逐日实况数据,均来自安徽省气象信息中心,其中寿县站和亳州站冬小麦始花期观测分别开始于1983年和1985年,7个观测站累计有小麦始花期样本271个。观测站点的冬小麦物候观测地段与观测植株选择标准以及开花始期观测方法,均按照《农业气象观测规范(下卷)》[34]执行。7个观测站的冬小麦物候观测期间对应的逐日气象监测实况数据包括平均气温、最高气温、最低气温、降水量、日照时数等。
1.3 研究方法
1.3.1 等距拆分和RF算法的小麦始花期气象预报模型构建技术路线
依据影响冬小麦开花始期早迟的相关知识和研究成果,搜集基本气象数据和小麦始花期数据。通过Pearson相关分析,筛选与小麦始花期相关程度较高的关键气象因子作为特征变量并形成基本数据集。有序等距离抽样拆分出测试集与训练集方法,即先把皖北地区7个观测站点的冬小麦逐年始花期数据,逐一按照由早到迟的顺序进行排列,然后根据各站点的样本量和所需要抽取用于测试的样本量大小,确定抽取距离。例如40个样本,抽取5个用于测试集,则抽取距离为8个间距,样本点分别为8、16、24、32、40号位上的样本,并由抽取的这5个样本年份的小麦始花期数据及其对应年份筛选出来的特征变量构成测试集,剩下的始花期样本及其对应年份的特征变量则构成训练集。按照不同的开始预报日期,基于RF算法,由训练集进行模型训练,并经测试集进行预报模型精度评估。最后,利用评估后的预报模型开展小麦始花期气象预报(具体技术路线见图1)。

图1 基于等距拆分和RF算法构建小麦始花期气象预报模型技术路线Fig.1 Technical route of meteorological forecast model of wheat initial flowering based on isometric sampling split method and random forest algorithm

图2 不同界限温度的积温及累积日数与始花期之间相关系数Fig.2 Correlation coefficients between accumulated temperature,accumulated days and initial flowering at different threshold temperatures
1.3.2 随机森林预报模型构建
(1)特征变量与目标变量构造:研究表明,小麦开花受到春化作用、光合周期反应、热效应等环境因素和基本早熟性等生物因素的相互作用,且环境因素对物候影响更显著,其中气温、日照时数等气象要素是环境因素中最重要、最活跃的影响因子,尤其是每个物候期的开始日期与其前2~3个月的气温有显著的相关关系[10,33,35-39]。本研究依据冬小麦的生物学特性[33,39],结合环境气候特点和生产服务经验及相关研究成果[3,7-8,10,35-39],按照不遗漏可能影响开花的前期气象因子,并兼顾所选预报因子距离实际开花始期有一定的提前量,以提升预报结果的实际应用价值为原则,选取的气象因子的终止日期为较常年始花期早10 d的4月15日,以选取更多的气象因子。依据Pearson相关系数,筛选出通过0.01信度水平检验的气象因子,作为基本特征因子。同时,按照冬小麦越冬期、越冬至返青、返青至起身和起身至始花前4个时段进行特征因子筛选。
首先,筛选冬小麦越冬开始期(1月1日)至开始现花之前(4月10日)逐旬及其跨旬的日平均气温、日照时数、降水量等气象要素,以反映小麦始花前气象条件整体变化对生育进程的影响。同时,重点普查起身后至开花前(3月上旬-4月10日)逐旬及其跨旬的日平均气温、日平均最高气温和日照时数与始花期之间的相关程度,以反映气象要素之间的叠加效应。
其次,为反映气候过渡带冬小麦越冬期间热量累积对生育进程的影响[32-33,39],普查了越冬期间(1月1-31日)逐日平均气温≥0 ℃积温与始花期之间的相关程度。
再者,为反映返青到起身之间热量效应对生育进程的影响,普查了2月1日-3月10日逐日平均气温≥0 ℃活动积温和≥3.0 ℃与≥5.0 ℃活动及有效积温与始花期间的相关程度。
最后,为反映起身后温度效应对发育进程的影响,选取起身后日平均气温、日平均高温等气象要素超过小麦生理适宜温度的累积量及其日数等指标,即自每年3月11日开始累积到4月10日、4月11日……4月15日的逐日平均气温≥5.0 ℃和≥11.5 ℃活动积温、有效积温及累积日数和逐日平均最高气温≥15.0 ℃活动积温与累积日数,计8个指标,每个特征指标自4月10日为一组,向后每增1 d特征变量增加一组,至4月15日为止,共计8×6组变量并与始花期进行相关系数计算。
目标变量为皖北地区亳州、砀山、蒙城、宿州、阜阳、寿县和五河7个观测站点的小麦始花期原位观测数据,累计271个样本。采用日序法转换法,将皖北地区7个站点的冬小麦逐年始花期的日期型数据,转换为数值型数据,作为目标变量集,即1月1日、1月2日、1月3日……1月31日,分别为1、2、3……31,其余类推。
(2)逐日滚动气象预报模型构建:以4月10日为开始预报日期、4月15日为终止预报日期,自4月10日开始至4月15日,期间每向后延1 d,分别选取不同的特征变量进入数量集进行模型训练,累计训练6个预报模型,以实现始花期逐日滚动气象预报。
(3)预报模型构建过程:随机森林回归是由多棵分类回归树(classification and regression tree, CART)构成的组合分类模型[40-41],以选定的特征变量作为特征数据并与始花期数据进行集成,构成随机森林的样本数据集。
本研究对皖北地区7个观测站点各等距离抽取5个样本(表1),计35个样本用于测试集,占总样本量的13%。剩余的236个样本作为训练集,占总样本量的87%。

表1 等距离抽样法抽取的各站点测试样本(年份)Table 1 Samples of each site extracted by isometric sampling split method(year)
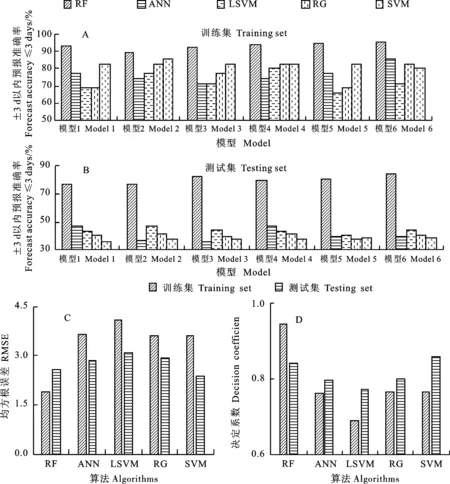
然后,通过自助法(bootstrap)从训练集采样得到构建N棵树所需的N个子集,每次未被抽到的数据称为袋外数据(out-of-bag,OOB),用来进行内部误差估计和变量重要性评价。生成每棵树时,从规模为M的特征变量集中随机选择m个变量(m (1) 式中,y为各原位监测点历年小麦始花期数据;N为决策树数量;Qn为独立同分布随机向量。 本研究在逐日始花期气象预报模型的 RF 算法训练中,最大节点数、最大树深度、最小子节点数、模型数量分别取1 000、10、5、100,并利用 R 语言 Random Forest包来实现随机森林模型构建和各特征变量重要性计算。 1.3.3 模型精度评估与应用 采用决定系数(r2)、均方根误差(RMSE)和预报准确率(Nd)3个指标进行模型优劣评价。 (2) (3) Nd=Nr/Nf×100% (4) 同时,利用等距离抽样法拆分出训练集和测试集,比较了基于随机森林(RF)算法与类神经网络算法(ANN)、线性支撑向量机(LSVM)、多元回归(RG)和支持向量机(SVM)4种算法训练出的预报模型的优劣。 另外,2020年和2021年,利用皖北地区亳州、砀山、蒙城、宿州、阜阳、寿县和五河7个观测站点气象监测实况数据,驱动训练的6个始花期气象智能预报模型,进行了小麦始花期预报应用检验。 《普通高中英语课程标准:2017年版》指出英语课程承担着发展学生思维能力的任务。思维品质体现英语学科核心素养的心智特征,是学生发展的重要内容。提问作为英语教学的重要教学技能,是培养学生思维品质的重要手段。然而,为了满足应试需求,英语教师普遍关注语用能力的培养,提问侧重于阅读文本的词句、段落大意的理解,较少涉及学生对文本内涵的理解和评判,在促进学生思维发展方面存在不足。在英语学科核心素养的背景下,阅读教学中学生思维品质的培养已成为重要教学目标。 依据Pearson相关系数,筛选出通过0.01水平检验的旬尺度及跨旬尺度的气象要素即特征变量共有28个(表2)。在这28个特征变量中,有27个特征变量与小麦始花期的相关程度均达到了0.001显著性水平,其中相关程度最高的特征变量为3月-4月上旬平均气温,与始花期之间的相关系数为-0.658 1;剩余的1个变量(3月上旬-中旬日照时数)与始花期的相关程度最低,相关系数为-0.180 8。入选的特征变量由平均气温、最高气温、日照时数三类因素构成,而降水量、降水日数、最低气温等因素未入选,表明本研究区域内,在旬和跨旬尺度水平上,降水因素与小麦始花期早迟相关性不强。 表2 旬及跨旬尺度气象要素与小麦始花期相关系数Table 2 Correlation coefficients between meteorological elements and initial flowering dates of wheat at ten-day scale and inter-ten-day scale 入选的不同界限温度的活动积温、有效积温及其累积日数变量共有12个(表3),而1月逐日平均气温≥0 ℃累积日数,2月1日-3月10日日平均气温≥3.0 ℃、≥5.0 ℃有效积温及其累积日数,3月11日-4月15日逐日平均气温≥5.0 ℃的累积日数,与小麦始花期之间的相关程度均未通过0.01显著性水平检验。12个特征变量中,ΣT0、ΣT6和ΣTn3i与小麦始花期之间的相关系数绝对值均小于 0.5,其他特征变量与小麦始花期之间的相关系数绝对值均大于0.5,其中ΣT7i和ΣT8i与小麦始花期相关性最大。 表3 筛选的积温效应特征变量Table 3 Selected characteristic variable of accumulated temperature effect 根据上述确定的逐日预报模型构建原则,以4月10日为开始预报日进行始花期预报,以后每增加1 d训练1个气象预报模型,到4月15日最后1个预报日,累计训练6个预报模型。其中,4月10日、4月11日、4月12日、4月13日和4月14日入选的特征变量均为40个,4月15日入选的特征变量为39个(表4)。 表4 不同日期预报模型入选的特征变量Table 4 Selected characteristic variables of different date prediction models 从6个预报日预报模型入选的特征变量重要性看,从大到小排序前5位的特征变量(表5)中,排在第1位的特征变量均为ΣT0,即越冬期间1月1日-31日>0 ℃的积温量。这可能与皖北地区地处气候过渡带,在本研究时段内冬季无明显越冬期[32,39],越冬期间的积温多少对小麦生育进程有正向促进作用。排在第2位的6个特征变量中,ΣT3占3个,分别属于预报模型1、模型4和模型6;ΣT6占2个,分别属于预报模型2和模型3;余下的Tav5属于预报模型5。排在第3和4位的特征变量只有1个相同,即Sav8,其余5个特征变量均不相同。排在第5位的特征变量在6个预报模型中均不一样。这表明即使距离花期有1 d变化,影响花期早迟的气象因子也存在差异。 表5 不同预报模型中重要性排在前5位的特征变量Table 5 Top 5 important characteristic variables in different forecast models 2.4.1 等距抽样和随机抽样法拆分构建预报模型的误差 采用等距抽样和随机抽样法拆分训练集,再基于RF算法构建不同预报日期的预报模型。在训练集和测试集上,基于等距拆分法构建的预报模型预报误差在±3 d以内的准确率均高于传统的随机抽样法,且随着预报日期逐渐向终止预报日接近,训练集和测试集的准确率均呈现增加的趋势(图3)。采用随机抽样法拆分数据,训练的预报模型准确率在训练集和测试集上的稳定性都弱于等距离拆分法。 图3 不同模型在训练集和测试集上的预报准确率Fig.3 Prediction accuracy of training set and test set 从预报模型的RMSE和决定系数(r2)(图4和图5)看,在训练集上,等距抽样和随机抽样法的RMSE 和r2均相近,RMSE在2.0左右,r2在0.93以上;在测试集上,随机抽样法的RMSE和r2分别显著高于和低于等距离拆分法,其中随机抽样法的RMSE普遍高于4.0,r2普遍在0.85以上,而等距离拆分法RMSE则多在2.0~3.0之间,r2多在0.65~0.75之间。 图4 不同预报模型的均方根误差(RMSE)Fig.4 Root mean square error(RMSE) of different prediction models 图5 不同预报模型的决定系数(r2)Fig.5 Determination coefficients of different prediction models(r2) 2.4.2 基于等距抽样拆分法构建不同机器学习算法的气象预报模型评估 基于利用等距离抽样拆分法建立的训练集和测试集,分别用类神经网络算法(ANN)、线性支撑向量机(LSVM)、多元回归(RG)和支持向量机(SVM)构建预报模型,其在训练集和测试集上的准确率均低于RF算法模型,RMSE和r2分别均大于和小于RF算法(图6)。 图6 4种机器学习算法构建预报模型评估Fig.6 Evaluation of prediction model constructed by four machine learning algorithms 分别利用2020年和2021年皖北地区亳州、砀山、蒙城、宿州、阜阳、寿县和五河7个气象观测站的气象监测数据,以等距离抽样拆分法和RF算法构建的不同预报日期的小麦始花期气象预报模型,得到7个站点2020年、2021年小麦始花期(图7)。与实际监测的小麦始花期相比,2020年和2021年除4月12日有2个站(阜阳站误差3.7 d、宿州站误差3.5 d)预报误差超过3 d外,4月12日之后即4月13-15日的预报误差均在3 d之内,尤其是最终的预报日,即4月15日,2个年度的预报模型5(即4月15日)的预报误差均在2 d以内,取得了较高的预报精度。 图7 2020年和2021年不同预报日期的预报误差Fig.7 Forecast errors of different forecast dates in 2020 and 2021 利用气象数据准确预报皖北地区冬小麦始花期,可为小麦赤霉病防控决策部署提供技术支撑。本研究以4月10日为起报日、4月15日为终报日,以始花期为目标变量及与花期早迟密切相关的前期气象条件为特征变量,以决定系数、均方根误差(RMSE)和准确率为判定训练模型优劣指标,采用有序等距离抽样的方法,拆分出训练集和测试集,基于随机森林算法(RF),每日训练1个模型,形成6个模型,建立了冬小麦始花期的逐日滚动气象智能预报技术。同时,基于RF算法训练的预报模型的3项检验指标均优于类神经网络算法(ANN)、线性支撑向量机(LSVM)、多元回归(RG)和支持向量机(SVM)4种算法训练的预报模型。经2020年、2021年利用气象监测实况数据检验,6个RF算法预报模型均表现出较高的预报能力,提前7~9 d准确预报出当年小麦始花期,基本满足小麦赤霉病防控决策部署的气象服务需求,为开展相关作物花期预报技术研究提供了样例。 随着机器学习技术的兴起,多种应用场景都采用了机器学习算法构建模型进行预测研究,尤其是能较好解决特征变量间非线性问题的RF已成为应用热点并取得一定成效[9,17-28]。然而,这些工作并未较好解决RF算法中的类不平衡问题[29-30]。本研究采用先把目标变量样本进行有序排列,再采用等距离抽样法拆分出训练集和测试集,并与随机抽样拆分法训练的预报模型进行比较。经检验,在训练集上,等距离抽样法训练的6个预报模型的各项指标均优于随机抽样拆分法。在测试集上,等距离拆分法的6个预报模型的决定系数均高于0.85、而随机抽样法多在0.65~0.75之间。采用有序等距离法拆分出训练集和测试集,为解决RF算法用于日期类物候预报中的类不平衡问题提供了一种方案。 特征变量筛选[9,19-24,28,42]是利用机器学习算法进行不同应用场景预测工作的基础。本研究依据相关研究成果、生产服务经验和冬小麦生物学特性及环境气候特点,在尽可能多地筛选出影响花期早迟的前期气象条件的基础上,以相关程度高为原则,确定不同时间段的特征变量,进行预报模型训练。这在目前对决定小麦始花期早迟的气象因子影响机制尚不清晰的情况下,为最大限度地筛选出影响花期早迟的特征变量提供了思路和方法,也是本研究基于RF算法构建气象预报模型特征变量的特色,为开展小麦等作物物候气象预报提供了一种思路。 在随机森林算法训练出的6个预报模型中,在入选的特征变量重要性排序中,排在前5位的特征变量并不一致,表明本研究区域内影响小麦花期进程的气象因子即使有一日之差,对花期早迟的影响也不一样。由此表明,小麦花期早迟受气象因子影响的复杂性、非线性特征,尤其是在驱动植物物候变化的各种因素是同时作用或是有序进行至今尚不清晰的当下[7],在难以掌握驱动因素与物候之间的复杂关系时,采用机器学习技术,通过大规模数据挖掘其规律,利用现有气象数据对小麦等作物物候进行预测是有效技术之一。 不同机器学习任务中数据集的规模和质量是限制机器学习系统性能的重要问题[7-8,17]。作物生育速度的快慢,与作物本身的生物学特性、气象条件、土壤肥力及耕作栽培技术措施等密切相关[7,35]。对于某一地区来说,土壤条件和耕作技术是相对稳定,作物的生育速度主要取决于作物本身的生物学特性和环境气象条件的变化[7,38,43]。本研究入选的关键气象因子为温度和日照时数,且温度类占入选因子的80%以上,这与学术界公认的温度是植物物候变化的主要驱动因子[7,43-45]的结论一致。未来随着监测数据的丰富,引入诸如土壤温度、冠层温度[7]等数据作为特征变量,会进一步提升模型的预测精度,这是未来本研究需要改进之处。 (1)采用有序等距离抽样拆分出训练集和测试集,基于RF算法,从4月10日到4月15日,逐日训练1个小麦始花期气象预报模型,计6个预报模型,实现了逐日滚动气象预报。2020年和2021年应用模型进行预报,提前7~9 d准确预报出当年始花期,基本满足了气象服务需求。 (2)构建的6个逐日气象预报模型的预报精度均较高,训练集与测试集误差在±3 d以内的平均正确率分别为93.3%、80.4%,平均均方根误差(RMSE)分别为1.860~1.960和2.510~2.709,平均决定系数(r2)分别为0.944和0.841,且6个预报模型的r2均随着预报日期向始花期的临近逐渐增大。 (3)以“筛选特征变量+有序等距离抽样拆分+RF算法训练模型+模型评估+模型应用”为技术流程,构建的皖北地区冬小麦开花期气象智能预报技术,可为开展其他作物开花期等关键物候的客观预报技术研究提供了新的思路。
2 结果与分析
2.1 旬尺度气象要素与小麦始花期的相关性

2.2 不同界限温度的积温及其累积日数与始花期相关性

2.3 不同预报日期气象预报模型入选的特征变量及其重要性分析


2.4 逐日气象预报模型的误差比较



2.5 2020年和2021年小麦始花期气象预报应用检验

3 讨 论
4 结论
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
黑龙江气象(2022年1期)2022-05-18
今日农业(2021年15期)2021-10-14
内蒙古气象(2021年2期)2021-07-01
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
新闻传播(2016年1期)2016-07-12
产业与科技论坛(2015年14期)2015-03-19
传奇故事(破茧成蝶)(2015年8期)2015-02-28
