
计算人文视阈下的计算语言学:现状和范式
2023-06-18 06:15:42柏晓鹏
图书与情报 2023年1期

摘 要:文章讨论计算人文视阈下计算语言学的定位问题,主要涉及三个问题:计算人文视阈下计算语言学的定位、研究范式,以及它与其他计算人文研究方向的关系。“计算人文”这一术语明确了数字人文的研究以计算技术解决人文学科的研究问题这一研究范式。我们认为,当前计算语言学的工作显示出明显的工程特征,将语言作为数据进行处理,很少有回答语言学研究问题的工作。尽管很多学者认为计算语言学是语言学的研究方向之一,但目前并无很多利用计算技术来进行语言学研究的案例。因此,以文本可读性工作为例,提出一个利用计算技术进行语言学研究的计算语言学研究范式。研究认为,计算语言学在工作方式上与其他计算人文研究方向并无二致,应在统一的研究范式下工作;作为研究工具的计算语言学,则需要在有效性和可解释性间获得平衡,推动数字人文各分支领域的发展,这是计算语言学在“以人文为核心,以计算为工具”这一研究框架中的准确定位。
关键词:计算语言学;计算人文;数字人文;语言学;自然语言处理
中图分类号:H085.2 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2023002
Abstract In this article, we discuss the positioning of computational linguistics in the context of computational humanities. We focus on three main issues: the position of computational linguistics in the context of computational humanities, the research paradigm, and its relationship with other research fields in computational humanities. The term "computational humanities" clarifies the research paradigm in which the study of digital humanities solves research problems in the humanities with computational technologies. We find that current work in computational linguistics shows distinctly engineering character, treating language as data, with little work answering the research questions of linguistics. Although many scholars consider computational linguistics as one of the research directions in linguistics, we do not see many cases of using computational technology for linguistic (especially for Chinese language) research at present. Therefore, this paper proposes a computational linguistics research paradigm that uses computational techniques for linguistic research, using text readability work as an example. We believe that computational linguistics is no different from other research fields in computational humanities and should work under a unified research paradigm. Computational linguistics as a research method requires a balance between validity and interpretability. This is the positioning of computational linguistics in the framework of "humanities as the core and computation as the tool".
Key words computational linguistics; computational humanities; computational humanities; linguistics; natural language processing
1 从数字人文到计算人文
数字人文将人文研究的成果用数字化手段呈现出来,如可视化的数据检索在地图上表示。随着近年来计算技术作为研究工具应用到学术研究的各个领域,人文研究也逐渐接受并尝试使用这些工具来更新研究方法、拓展研究视野乃至提出新的研究问题。“计算人文”这一术语强调将计算技术运用成研究工具,改变现有的研究范式。简单来说,是将基于数据(data based)和数据驱动(data driven)这两种方法运用到传统上依赖研究者个人经验的人文研究中。
在数字人文提出之前,较有影响力的术语是人文计算。人文计算源于罗伯特·布萨对于著作索引的研究[1],早期的人文计算的研究也主要围绕着词语索引的构建,借助计算机对词语进行计量,以此完成索引资源的建构[2]。人文学科在研究过程中引入了计算技术,开拓新的研究视角[3]。黄水清认为,人文计算的核心框架与数字人文没有本质区別[4]。通过文本编码、数据库、计量分析等技术将人文内容以及研究成果以数字化的形式呈现。数据可视化为人文研究提供了全局图景,得以进行“远读”研究[5]。
“计算人文”术语的提出,体现了计算技术作为研究方法融入人文科学的趋势,“人文”是研究问题和研究对象,通过计算技术的方法发现、回应人文学科的研究问题。一方面,计算技术作为人文科学的研究方法,在各人文子领域中应该拥有统一的研究范式、系统的研究流程。黄水清在针对人文计算的困窘以及规范化的研究中提出了问题定义、数据集构建、技术实现、问题求解、结果评价及呈现的五阶段范式[6];另一方面,科学研究不仅是对材料进行计量统计,得到统计数据,更重要的是利用数据,对其中的研究问题进行解释,通过计算技术在人文学科研究中发现问题,解释问题,甚至对已有结论进行再论证。
本文讨论计算语言学与计算人文的关系。首先,介绍计算语言学的概况、发展历程以及主流研究范式;其次,介绍计算语言学中一些典型的语言学问题。目前计算语言学的主要研究问题不是语言学研究问题,其主流方法与计算人文提出的研究框架并不兼容;第三,展示一项文本可读性的研究,提出计算人文框架下计算语言学的研究范式;最后,讨论计算语言学作为计算人文的研究工具的问题。
2 计算语言学的发展
2.1 计算语言学的定义
计算语言学致力于自动化处理自然语言,如语音与文字的相互转换、专有名词的识别、文本分类、回答问题、文本摘要的生成、翻译等。其研究成果的运用使数字人文研究的重点逐渐转向了对文本知识的挖掘。如刘浏等通过对《春秋》三传中的女性人物知识以及诸侯国联姻关系进行量化分析,为《春秋》三传中的女性人物的解读提供了新的角度[7]。于纯良等利用机器学习算法对稷下学重要文献资料中的知识信息进行自动识别、细粒度的语义知识深度标引以及知识单元提取,以支持文献资源的知识挖掘[8]。
计算语言学至少在语言学和计算机科学两个领域得到系统性关注,与之并列,还有“自然语言处理”这一常见术语。关于这两个术语,我们列举学界一些有代表性的说法:
计算语言学是利用电子数字计算机进行的语言分析[9]。
计算语言学是通过建立形式化的计算模型来分析、理解和处理语言的学科[9]。
计算语言学,也称自然语言处理或自然语言理解,是一门以计算为手段对自然语言进行研究和处理的学科[10]。
自然语言处理就是利用计算机为工具对人类特有的书面形式和口头形式的语言进行各种类型处理和加工的技术[11]。
(计算语言学是)语言学的一个分支,用计算技术和概念来阐述语言学和语音学问题[12]。
自然语言处理要研制表示语言能力和语言应用的模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术[13]。
计算语言学包括以语音为主要研究对象的语音学基础及其语音处理技术研究和以词汇、句子、话语或语篇及其词法、句法、语义和语用等相关信息为主要研究对象的处理技术研究[14]。
从上述定义和描述可以看出,“计算语言学”强调使用计算技术对语言进行研究,“自然语言处理”则关注语言处理技术,但二者的定义在很大程度上是重合的,难以做出泾渭分明的区分。目前学界对计算语言学的认识是:其研究对象是人类语言,研究手段是计算技术,研究目的是对语言进行自动化处理,其研究过程涉及对语言的建模和对模型的评价。
2.2 计算语言学方法论的变迁
计算语言学研究的方法论经历了三个阶段:基于规则的方法、基于统计机器学习的经验主义方法和基于深度神经网络的方法。
2.2.1 基于规则的方法
基于规则的方法是理性主义(rationalism)方法,基于乔姆斯基关于语言是人脑内在功能(faculty)的假设。它主张用人工整理和定义的语法规则,通过推理程序,对自然语言进行自动处理。根据规则构造出来的语言处理系统解释力很强,因为规则来自于语言学家对语言的观察和总结。然而,在多数情况下,系统中的规则并不能覆盖所有语言现象。当某条规则在计算过程中碰到例外,需要对这条规则做出修正。
以词性标注(POS tagging)为例,假设一个词性标注系统由一百条语法规则组成,对其中任何一条规则进行变动,都可能会带来其他规则变化的连锁反应。语法学研究显示,自然语言是复杂系统,几乎没有一套规则可以涵盖所有可能的语言现象。基于规则的方法需要不断地对规则系统做出调整,随着所要处理的语言现象增多,规则系统面临崩溃。
2.2.2 基于统计机器学习的方法
基于统计机器学习的方法是经验主义(empiricism)方法。它与认知语言学的假设一致,认为语言能力的获取是语言输入的结果。人们通过已有的语言数据对统计模型进行训练(training),将语言现象在语料库中的分布转化为统计模型的参数,然后用带有参数的统计模型去处理新的语言现象。相较于基于规则的方法,该方法更加健壮(robust),具有较好的预测性。从应用的角度说,基于统计的方法比基于规则的方法更加简单,适应性更强。基于统计的方法需要将自然语言转换为恰当的表示(representation),并根据具体任务抽取特征(features),所以,特征工程(feature engineering)是非常重要的工作。
2.2.3 基于深度神经网络的方法
基于统计机器学习的方法结果的好坏很大程度上取决于数据的规模和标注质量。语料库的规模、标注深度、标注质量、标注内容等问题都会对机器学习模型的结果产生影响。进入21世纪,互联网上积累了海量数据,这为深度神经网络(deep neural network)算法的实现提供了数据基础。深度神经网络的输入端和输出端之间有n层神经网络,每层神经网络上有若干个节点(node,又称为神经元),每个节点是一个参数,数据进入网络后经过计算(如激活函数、求导等操作)进行逐层的向前/向后傳播,最终得到输出值,在此期间,网络中的节点(参数)不断更新,以优化输出值。深度神经网络方法又称为深度学习(deep learning)。
深度神经网络技术在语言处理中代表性的算法主要有词嵌入(Word Embedding)、长短时记忆(Long-Short Term Memory)和预训练语言模型(Pre-trained Language Models)。词嵌入是文本表示方法,与统计机器学习算法常用的独热表示(One-hot Representation)相比,词嵌入表示将高维空间的词汇向量投射到低维空间,得到低维高稠密的词汇向量。LSTM是一种循环神经网络(Recurrent Neural Network),RNN是一类处理序列数据的神经网络,适用于语言,LSTM通过门结构(Gate)的设计弥补了RNN无法处理长距离依存信息的问题,成为处理语言数据的典型算法。预训练模型提供“预训练+微调”的模式,研究者使用开源预训练模型,用自己的数据对模型进行微调后,即可开展研究工作。深度神经网络方法已成为计算语言学的主流方法,其在各项NLP任务上的表现均优于基于统计的机器学习方法。
2.3 计算语言学的主流研究范式
从20世纪40年代机器翻译工作开始,计算语言学逐渐形成了一个主流的研究范式获取数据、训练模型、评测模型。这三个部分是目前进行计算语言学研究工作的必要环节。
2.3.1 获取数据
数据是用来训练模型的。对于不同的方法,获取数据的方式和难度是不同的。对于基于统计的机器学习方法来说,需要从语料库中获取信息,对模型进行训练。而标注是必要的工作,如分词、词性标注、句法剖析、语义角色标注等。不同任务需要标注的类型和深度是不一样的。
对于深度神经网络的方法,数据主要来自互联网语料,包含了很多信息。如果使用预训练模型,研究者只需要准备少量的、简单标注的数据对预训练模型进行微调即可将模型转移(transfer)到自己的工作上。
2.3.2 训练模型
本质上,模型是(一些)数学公式,訓练模型就是利用语料库将公式中的参数估计出来的过程。如最简单的一元线性回归模型y=a+bx,训练模型的过程就是利用语料库中(x,y)信息对参数a、b进行估计。对于预训练模型来说,训练模型是对网络上的参数进行估计。在实际工作中,模型参数的规模可能非常庞大,当前的大语言模型(Large Language Models)参数规模往往超过亿个,如Bert、GPT-1的参数规模是1亿多,GPT-2的参数规模是15亿,Google的PaLm参数规模5400亿,ChatGPT(GPT-3.5)参数规模1750亿,而GPT-4达到百万亿的参数规模。
2.3.3 评测模型
模型训练完成后需要对其表现进行检测,以判断其是否有效,称为评测(evaluation)。一般来说,用于评测模型的数据是训练语料中的一部分,在实际工作中,研究者会按一定的比例将语料库分为训练数据和测试数据,也就是说,测试数据是模型在训练阶段没有“见过”的,这个比例往往是7:3或者8:2,取决于语料库规模。
用于评测模型的指标对不同的任务是不同的。如准确率(accuracy)、召回率(recall)和调和平均值(f-score)适合用于分类、序列标注等模型的评测,而BLEU、标注一致性等指标适用于机器翻译、自动文摘模型的评测。
在这个研究范式中,研究目标是最大程度优化模型算法在语言处理任务中的表现,研究问题则是通过模型改进、开发新的数据集以在特定任务上达到最佳的评测结果。
3 计算语言学与语言学的关系
通过引入其他学科的研究方法,当代语言学衍生出相应的研究方向。如认知语言学使用认知科学中的“象似性”原理解释语法化过程中某些语法现象的演变,心理语言学使用眼动仪和行为实验记录人眼对语言材料的“刺激-反应”数据,从而对多义词义项选择进行解释。同样,学者们认为计算语言学是当代语言学的研究方向之一。但仔细观察计算语言学的发展及其研究范式,我们并不认为计算语言学与认知语言学、心理语言学一样,是典型的语言学研究方向。本节罗列一些曾在计算语言学中被关注的语言问题,藉此来讨论计算语言学与语言学的关系。
3.1 分词(Segmentation)
汉语书面语没有词边界,相较于英语这类语言,计算机处理汉语首先要识别词边界,词边界隔开的单位被称为分词单位。在具体研究中,分词单位的定义往往不是语言学意义上的词。如果我们要从语料库中统计常用词,那么分词单位应当是语言学意义上的词,即“独立运用的最小音义结合体”,所以,“中华人民共和国”就应该被切分为三个分词单位“中华”“人民”和“共和国”。如果要做一个搜索系统,那么分词单位应当是表达一个完整概念的单位,“中华人民共和国”就应该被视为一个分词单位。用于进行分词的方法有三种:基于词典的规则方法、基于统计模型的方法和基于分类模型的方法。
3.2 词性标注(Part-of-speech Tagging)
句子中的每个词都有其语法类别,称为词性,词性标注就是在句子中确定每个词词性的任务。相较于印欧语系形态屈折变化丰富的语言,对汉语进行词性标注存在一些困难[15]:无法从词形推断词性;词的语法兼类现象普遍;词性标注标准不统一。进行词性标注的方法主要有基于统计的方法、基于规则的方法和统计与规则相结合的方法。
3.3 句法分析(Parsing)
句子是层次性结构,所以句子中的词不总是与相邻的词有直接句法关系,句法分析就是自动识别句子中词与词之间的句法关系并进一步确定句法结构的任务。
句法分析主要分为短语结构分析(constituent parsing)和依存分析(dependency parsing)两种路径。前者以宾州树库(Penn Treebank)为代表,后者以哈工大依存树库(dependency treebank)为代表。这两种路径反映了不同的语法理论,对于计算语言学来说,这是两种不同的句子表示方法。
句法分析是计算语言学中一项基础工作,曾被认为是机器翻译必经之路。用于句法分析的训练语料库开发成本非常大,而且不同学者对同一个句法现象该如何标注也会有争议。
3.4 语义分析
常见的语义分析工作有词义消歧和语义角色标注。
3.4.1 词义消歧(Word Sense Disambiguation)
一词多义是词汇语义中最常见的现象,词汇学往往会区别多义词和汉语中的同音同形词,但对计算机而言,这两个现象是一回事,都是一个词形对应多个义项。如“吃”在“我吃饺子”和“吃俺老孙一棒”中是不同的意思,词义消歧的目标就是把“吃”在不同句子中的义项标注出来。
3.4.2 语义角色标注(Semantic Role Labeling)
语义角色描述了句法上所说“论元”与谓语中心的语义关系,来源于Fillmore(1968)提出的格语法。如“我吃了一碗饭”,谓语中心是“吃”,它辖制两个论元:“我”和“一碗饭”。论元“我”的语义角色是谓语中心的“施事(agent)”,而“一碗饭”则是谓语中心的“受事(patient)”。SRL就是要在“论元-谓语中心”的框架中将论元的语义角色自动识别出来。
3.5 计算语言学和语言学的关系
上述问题并不能算是语言学的研究问题,换言之,计算语言学的相关研究没有回答相关的词汇学、句法学和语义学的问题。上述问题只是在特定任务中计算语言学需要解决的障碍。如计算语言学需要识别汉语文本的词边界,因为统计模型需要使用词分布的数据进行训练。对于语言学,分词问题的本质是回答“汉语中什么是词”的问题,而词性标注的本质则是“对于缺乏屈折形态变化的汉语,如何对词划分句法类别”的问题。可以看到,计算语言学在分詞、词性标注方面的工作并没有推动解决相关语言学问题。
从评价的角度来看,评价一个计算语言学工作优劣的标准是某个机器学习模型在标准数据集上是否能够取得评测指标的提升。如预训练语言模型能够比支撑向量机模型在同一个汉语分词数据集上取得更好的调和平均值,那使用预训练语言模型进行分词的工作就是更好的。但是,预训练语言模型依然没有能够回答语言学问题。
总体而言,在目前主流计算语言学的研究范式中,研究目的不是对语言现象进行研究解释,而是解决具体的工程问题。计算语言学还没有发展出一套以解决语言学研究问题为中心的研究范式。以句法为例,计算语言学所说的句法研究与语言学所说的句法研究不是一回事,计算语言学的句法研究工作是在现有句法分析体系(一般是短语结构文法或依存句法)框架下,探讨如何将线性的句子自动解析为层次性的树状结构,语言学的句法研究工作则是构建句法规则体系,并且用句法体系来解释句法现象。现有的计算语言学研究范式与“人文为问题,计算为方法”的框架不兼容。计算语言学研究应当有一个以“语言/语言学研究”为核心,回应语言和语言学研究问题的研究范式。
4 计算人文视阈下计算语言学研究范式:以文本可读性计算为例
计算语言学应形成一个以语言学问题为中心的研究范式,在这个范式中对语言学问题进行讨论。这里我们以一项文本可读性计算(text readability assessment)的工作为例,来演示我们如何通过计算语言学中的自动分类技术,对比评价各项语言学特征对文本可读性的影响[16],并尝试提出一套以语言问题为核心研究范式。
4.1 文本可读性计算(Text Readability Assessment)
文本可读性指文本易于阅读和理解的程度,是对文本的难易程度进行评估的核心指标,是分级阅读研究关心的核心问题之一。前人研究将文本可读性计算看作分类问题,使用基于统计的自动分类模型为研究方法。
4.2 研究问题
研究者在文本可读性计算这个问题上,主要关心两方面的问题:一是哪些计算模型和方法可以用来解决这个问题;二哪些因素影响了文本的可读性。前一个问题是关于如何构造文本可读性计算系统,以达到自动判断的目的。后一个问题是文本中有哪些特征影响了可读性,这是关于文本可读性的理论问题。显然后一个问题是语言学的研究问题,在计算人文的框架中,应以此为研究问题。文本可以分解为若干语言学特征:词汇、句法、篇章。这些特征如何影响文本的可读性,从而可以指导应用语言学的相关工作,如语言教学。所以,研究问题具体为:词汇、句法和篇章这三种语言特征对文本可读性的影响如何。
4.3 构建语料库和获取语言学特征
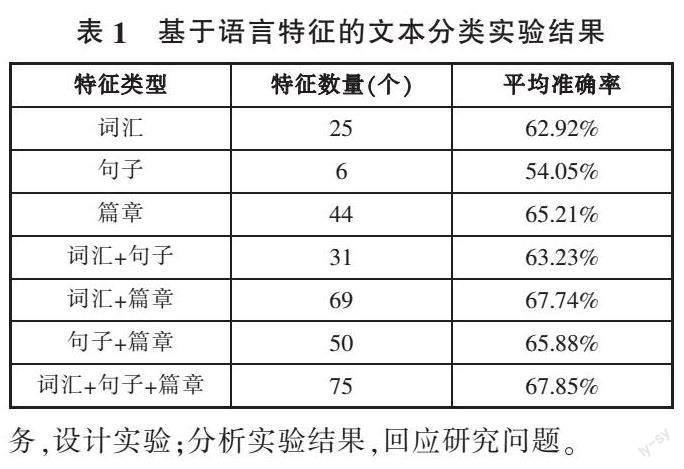
语料库是此项研究的材料,选取了“统编版语文教材语料库”[17]共计31.5万字(不包括标点)。由于语料整体规模较小,语料库以学段为分级单位,根据教育部颁布的《义务教育语文课程标准》(2022版)对学段的划分将四个学段的课文对应为四个可读性级别,作为类别标签。然后,对语料库标注了三个层面的语言学特征:词法(25种)、句法(6种)和篇章(44种)。
4.4 自动分类实验
工程研究不同,本文不以提高分类器的分类结果为目标,而是把分类器作为工具,用来测试文本语言特征对可读性的影响。以文本在教材中所处的学段作为可读性类别标签,以语言特征作为参数,实现特征与类别的关联,最后利用该模型判定该文本的所属类别。对文本可读性级别影响较大的特征,当它出现的时候,分类模型的结果必然比它不出现的时候更好。我们可以通过观察某类特征是否出现对于分类结果的影响,来评估该特征对文本可读性的影响。
4.5 实验结果
实验结果显示了不同种类的语言特征对文本可读性的影响(见表1)。使用支撑向量机分类器,我们可以对“语言特征对文本可读性的影响”这一问题进行量化分析。在单一特征模型中,篇章特征模型的分级准确率为65.21%,优于词汇模型和句法模型,句法特征模型的准确率最差。所以,篇章特征对文本可读性的影响最大,词汇特征次之,句法特征最次。
4.6 计算人文视阈下计算语言学的研究范式
以语言和语言学问题为核心,计算技术为研究手段,通过上述文本可读性的工作,可以总结出一个计算人文视阈下计算语言学的研究范式。它包含四个部分:提出语言学研究问题;与研究问题相关的语言学特征的获取;将研究问题转换为计算语言学任务,设计实验;分析实验结果,回应研究问题。
5 作为研究工具的计算语言学
语言是人类文明的重要载体,人类文明大多以语言形式(语音和文字)保留下来。人文学科(如文学、历史、文献学等)大部分的研究对象(如档案、文献等)以文本形式呈现,所以文本是必不可少的研究材料。在研究中,不仅要对个体材料有精深的理解和把握,也需要对大规模材料有整体上的认识,这在依赖研究者个体经验的情况下是难以实现的。计算语言学的快速发展为处理大规模文本数据,以及在文本中进行知识发现等研究活动提供了工具。我们认为,计算语言学作为研究工具,有三方面的工作可为相关研究所用:语言资源建设、文本分析技术、基于深层神经网络和预训练模型的技术。
5.1 语言资源建设
语言资源分为语料库和语言知识库。
语料库是对真实语言材料进行各类标注的结果,它为统计模型提供数据。语料库可以做如下分类:根据语料库的用途可分为通用语料库(如人民日报语料库、BCC语料库、台湾中研院语料库)和专用语料库(如口语语料库、中介语语料库);根据所搜集语料的时间跨度可分为共时语料库(如LIVAC语料库、人民日报语料库)和历时语料库(如古代汉语语料库);根据语料库的加工类型和深度可分为词法标注语料库(如人民日报语料库、国家语委平衡语料库)、句法树库(如宾州树库、清华树库)、句法依存树库(如哈工大汉语依存树库)、命题库(如宾州命题树库)、篇章树库(宾州篇章树库)、抽象语义表示库。语料规模、采集范围、标注规范,这些问题决定了语料库的质量并进一步影响后续的研究,相关研究催生了一个专门的研究方向:语料库语言学。
语言知识库是确定的语言知识的集合,它往往以词典和数据库的形式出现。语言知识库的建立依赖专家知识,是语言处理系统的基础设施。根据语言知识库的基本元素,可分为概念知识库(如WordNet、FrameNet、HowNet、同义词词林)、词汇知识库(如北大语法信息词典)。
语言资源相关的工作对于计算人文依然具有重大的意义和价值,一方面现有的语言资源可以直接用于计算人文的研究,另一方面其方法论可以指导未来语料库和数据库的开发和建设。
5.2 文本分析技术
计算语言学在文本分析方面的成果可以运用在从词到篇各层面的数据挖掘。文本分析产生的数据,如词汇、语法关系等,对于文学、语言学、历史学等人文社会科学研究领域是非常有用的材料。目前研究者可以通过开源的形式获得大部分的文本分析工具。这里简单介绍一些可以对汉语文本进行分析的开源工具。
5.2.1 词法分析工具
词法分析是对文本进行挖掘和处理的第一步,目前大多数面向现代汉语的词法分析工具可以达到高于90%的调和平均值(f-score),即使不能直接用于研究,也可以极大地简化相应的工作负担。古文分词的工具比较少见,这主要是因为古代汉语的时间跨度很大,不同时代、文体、题材的文本都称为古代汉语文本,其内部的词法分布规律非常不均衡,故打造一个通用的古文分词工具难度很大。古汉语分词与词性标注国际评测是专门面向该问题的工作[18]。
詞法分析主要包括:分词、词性标注、各类命名实体识别等。命名实体识别可以看作是一类特殊的词性标注,目前大部分的词法分析工具都把这三个部分集成在一起(一些开源词法分析工具见表2)。
5.2.2 句法分析工具
句法分析工具将句子中词的关系进行显性标注一般有短语结构分析和依存分析两种。短语结构分析将句子表示为一个树状结构,依存分析将句子表示为一个有向图的结构。尽管这两种分析方法基于不同的句法学理念,但是二者间在技术上是可以相互转换的。本文仅对部分开源句法分析工具简单列举(见表3)。
5.2.3 语义分析工具
语义分析主要是对句中词的语义角色关系进行显性标注。语义分析需要在句法分析的基础上进行,非常依赖句法分析的结果。目前主要是LTP和suPar提供语义角色标注和语义依存分析。需要指出的是,suPar是一款若干句法分析工具的集成,很难看作是原创性的工作。
以上列举的各项文本分析工具,大多以语言处理平台的方式出现,专门针对某一语言单项的分析工具(除了结巴分词)不多。从效果上来看,从高到低依次排序为:分词、句法分析、语义分析。分词和句法分析工具的结果基本上可以直接使用,但是需要根据具体研究做一些适应性改造。而语义分析的结果较差,如suPar报告的语义依存分析结果的调和平均值最高为71%。
就计算语言学本身而言,对文本内容进行挖掘是其工作流程中的中间环节,如果下游的任务不再需要某种文本数据,那么对这种数据的挖掘就不再重要,如上文所提及的句法分析工作。所以计算人文领域需要在句法语义等“传统的”文本处理分析工具方面投入研究。
5.3 基于深层神经网络和预训练模型的技术
深层神经网络和预训练模型技术是目前计算语言学的主流技术,已经应用在各个研究方向上。深层神经网络技术又称为端到端(end-to-end)的技术,即研究者只需选择模型、调整参数、输入数据即可,而不再需要从头开发。而这种端到端的模式也使得很多任务,如机器翻译、人机对话等,不再依赖对文本的词汇、结构、语义等分析的结果,所以上面提到的各种文本分析技术不再是(计算机科学视阈下)计算语言学研究的重点①。学界和工业界相继开源了一批深层神经网络学习框架,如PyTorch[28]、TensorFlow[29]等,这些框架的核心是各种预训练模型,预训练模型是在深层神经网络框架中使用大规模数据训练得到的神经语言模型,这些框架和预训练模型使得研究者可以训练自己的预训练模型。目前开源的中文预训练模型如中文BERT[30-31]、ELECTRA(现代汉语)、SiKuBert[32](古代汉语)等,还有Hugging Face[33]这样的模型框架。
开源的深层神经网络框架和预训练模型极大简化了研究者对深层神经网络技术的使用,研究者不必从头去开发极为复杂的模型,甚至不用去准备大量数据,而是直接调用开源工具,结合小规模数据对预训练语言模型进行微调。当然,目前开源的预训练模型大多是通用性的,人文研究还需要结合具体研究,开发特定用途的预训练模型,如史学模型、文学模型、文献模型等。
5.4 技术的有效性和可解释性
相比统计机器学习模型,基于深层神经网络的预训练模型能够更好地完成语言处理的各项任务。但也带来一个问题,预训练模型的解释力不及统计机器学习模型,尽管学术界提出“可解释的深度学习”,但是预训练模型为何能够取得很好的结果,哪些因素对模型产生了积极影响。对于人文研究来说,需要在技术的有效性和可解释性间达到平衡,在计算机科学无法使得预训练模型更加“透明”的情况下,研究者可以将预训练模型作为在研究的中间层,而不是直接输出最终结果,这样可以做到一定程度的平衡。如在文本可读性的研究中,我们使用基于预训练模型的句法分析器输出了高质量的句法分析结果,然后用统计机器学习模型构造文本可读性分类器,以评估不同语言学特征对文本可读性的影响。
6 结论
本文首先介绍了计算人文的概念,提出这一术语是数字人文进一步发展、对研究方法的认识进一步明确的结果。随后讨论了计算语言学在计算人文中的定位,介绍了计算语言学的发展,计算语言学与语言学的关系,以及计算语言学作为研究工具在计算人文领域中的作用。认为当前计算语言学的研究范式属于计算机科学。计算人文视阈下的计算语言学研究范式与计算机科学的研究范式应有所不同。由此展示了一项文本可读性计算的工作,利用自动分类实验考查不同的语言学特征对文本可读性的影响,借此提出了一个与计算机科学研究范式不同的、以语言和语言学研究问题为核心的计算人文研究范式,这个范式与计算人文所提出的研究框架是契合的。
在新一代互联网技术爆发的背景下,计算语言学研究应顺势而上,把握好国家建设“新文科”的机遇,在计算人文这一大的框架下,将本体研究与计算技术充分结合,开辟出具有中国特色的学科体系、学术话語。在以深层神经网络为代表的新一代计算语言学技术蓬勃发展的今天,利用开源框架和模型,人文研究已经完全可以将计算技术融入自己的研究,使用基于数据和数据驱动的方法推动人文研究的进一步发展。
计算语言学今后的发展,一方面需要以语言和语言学研究为核心,利用计算技术推动语言学研究;另一方面,应在文本分析、预训练模型等方面深入研究,以人文学科的问题为研究问题,为计算人文领域其他研究方向提供研究工具。计算语言学应找准定位,推动计算人文的进一步发展,助力“新文科”发展战略。
参考文献:
[1] Busa R.The Annals of Humanities Computing:The Index Thomisticus[J].Computer and the Humanities,1980,14(2):83-90.
[2] 黄水清,刘浏,王东波.计算人文的发展及展望[J].科技情报研究,2021,3(4):1-12.
[3] 黄水清,刘浏,王东波.国内外数字人文研究进展[J].情报学进展,2022,14(0):50-84.
[4] 黄水清.回归人文:从人文计算到计算人文[N].社会科学报,2021-09-09(5).
[5] 王军.从人文计算到可视化——数字人文的发展脉络梳理[J].文艺理论与批评,2020(2):18-23.
[6] 黄水清.人文计算与数字人文:概念、问题、范式及关键环节[J].图书馆建设,2019(5):68-78.
[7] 刘浏,黄水清,孟凯,等.《春秋》三传女性人物的人文计算研究[J].图书情报工作,2020,64(23):109-123.
[8] 于纯良,吴一平,白如江,等.数字人文视域下稷下学语义计算平台建设研究[J].图书馆建设,2022(2):141-149.
[9] 翁富良、王野翊.计算语言学导论[M].北京:中国社会科学出版社,2015.
[10] 刘颖.计算语言学[M].北京:清华大学出版社,2014.
[11] 冯志伟.自然语言的计算机处理[M].上海:上海外语教育出版社,1996.
[12] (英)戴维·克里斯特尔.沈家煊,译.现代语言学词典[M].北京:商务印书馆,2002.
[13] Manaris B.Natural Language Processing:A Human-computer Interaction Perspective[J].Advaced in Computers,1999,47:1-66.
[14] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2016.
[15] 刘开瑛.中文文本自动分词和标注[M].北京:商务印书馆,2000.
[16] 柏晓鹏,吉伶俐.篇章结构特征对文本可读性的影响[J].语言文字应用,2022(3):62-72.
[17] 柏晓鹏,吉伶俐.部编版小学语文教材语料库建设:目的和原则[J].新疆教育学院学报 ,2020,36 (1):11-17.
[18] Devlin J,Chang M W,Lee K,et al.Bert:Pre-training of deep bidirectional transformers for language understanding[J].arXiv preprint arXiv:1810.04805,2018.
[19] HanLP官网[EB/OL].[2023-01-14].https://www.hanlp.com/index.html.
[20] JUNYI S.jieba[CP/OL].[2023-01-14].https://github.com/fxsjy/jieba.
[21] 语言技术平台(Language Technology Plantform | LTP )[EB/OL].[2023-01-14].http://ltp.ai/.
[22] THULAC:一个高效的中文词法分析工具包[EB/OL].[2023-01-14].http://thulac.thunlp.org/.
[23] YAN J.甲言Jiayan[CP/OL].[2023-01-14].https://github.com/jiaeyan/Jiayan.
[24] stanfordnlp/stanza[CP].Stanford NLP,2023.
[25] supar·PyPI[EB/OL].[2023-01-14].https://pypi.org/project/supar/.
[26] DDParser[CP].Baidu,2023.
[27] Overview[EB/OL].[2023-01-14].https://stanfordnlp.github.io/CoreNLP/.
[28] PyTorch[EB/OL].[2023-01-14].https://www.pytorch.org.
[29] ABADI M,AGARWAL A,BARHAM P,et al.TensorFlow,Large-scale machine learning on heterogeneous systems[EB/OL].[2023-01-14].https://github.com/tensorflow/tensorflow.
[30] BERT[EB/OL].[2023-01-14].https://github.com/google-research/bert.
[31] Li B,Yuan Y,Lu J,et al.The First International Ancient Chinese Word Segmentation and POS Tagging Bakeoff:Overview of the EvaHan 2022 Evaluation Campaign[C].Proceedings of the Second Workshop on Language Technologies for Historical and Ancient Languages,2022:135-140.
[32] 王东波,刘畅,朱子赫,等.SikuBERT与SikuRoBERTa:面向數字人文的《四库全书》预训练模型构建及应用研究[J].图书馆论坛,2022,42(6):31-43.
[33] Hugging Face-The AI community building the future[EB/OL].[2023-01-14].https://huggingface.co/.
作者简介:柏晓鹏,华东师范大学中文系副教授,研究方向:计算语言学、语言数字资源、词汇学、汉语语言学。
猜你喜欢
大学图书馆学报(2017年1期)2017-03-25 17:34:17
大学图书馆学报(2016年5期)2017-02-18 20:37:24
大学图书馆学报(2016年5期)2017-02-18 17:14:49
海外华文教育(2016年1期)2017-01-20 08:21:56
计算机应用(2016年12期)2017-01-13 01:24:36
大学图书馆学报(2016年3期)2016-12-29 19:16:31
电脑知识与技术(2016年10期)2016-06-16 21:16:32
电脑知识与技术(2016年5期)2016-04-14 11:12:38
科技视界(2016年5期)2016-02-22 11:41:39
当代修辞学(2011年2期)2011-01-23 06:39:12
