
机械设备多模态声源分离方法研究
2023-06-15 09:27:16肖晓萍李自胜
计算机技术与发展 2023年6期
简 斌,肖晓萍,李自胜,张 楷,袁 昊
(1.西南科技大学 制造科学与工程学院,四川 绵阳 621010;2.西南科技大学 工程技术中心,四川 绵阳 621010;3.西南交通大学 机械工程学院,四川 成都 610031)
0 引 言
机械设备声源分离是噪声故障监测与识别的前提条件,目前,机械设备混合音频信号分离通常采用盲源分离方法,即在源信号及传输特征未知的情况下,仅依靠接收到的混合信号恢复各个独立源信号[1]。毕凤荣等人[2]通过集合经验模态分解与独立分量分析相结合的方法,对装载机室内噪声信号进行盲源分离。侯一民等人[3]运用集合经验模态分解与快速独立分量分析相结合的方法,对三台异步电动机噪声信号进行盲源分离。孙玉伟等人[4]运用快速独立分量分析方法,对断路器合闸期间的音频信号进行盲源分离。此外,不同于盲源分离方法,Wang等人[5]通过Vold-Kalman滤波和循环维纳滤波的级联滤波方法,对直升机主、尾旋翼气动噪声进行分离。严青等人[6]提出一种多元线性拟合的多源噪声分离方法。上述声源分离方法均能根据机械设备混合信号恢复源信号,但盲源分离方法由于分离结果存在两个不确定性[7],从而造成分离后声源信号与机械设备对应关系不确定。
近年来,随着深度学习的发展,多模态特征融合相关研究逐渐成为热点,音视频特征融合的多模态声源分离方法可以依赖不同模态特征间存在的潜在联系,解决单模态混合音频信号分离方法存在的声源分离效果不佳、分离后声源与目标对应关系无法确定等问题。Zhao等人[8]提出一种融合视觉特征与音频特征的乐器声源分离方法;Gan等人[9]提出一种融合身体关键点特征、手指运动特征、视觉特征和音频特征的乐器声源分离方法;Gao等人[10]提出采用预训练Faster R-CNN检测视频中乐器目标,再将目标视觉特征与音频特征融合的乐器声源分离方法;Zhu等人[11]提出一种融合乐器类别信息、单帧视觉特征与音频特征的乐器声源分离方法;Xu等人[12]提出一种融合音视频特征的循环递归声源分离方法;马硕[13]提出一种在初分离的基础上再进行细粒度分离的乐器声源分离方法。上述多模态声源分离方法均能根据视觉特征分离对应声源信号且能够取得较好的声源分离效果。
鉴于多模态特征融合在声源分离方面存在的优势与潜力,首次将该方法应用于机械设备声源分离研究,针对机械设备外观与声源特点,该文提出一种多模态特征融合的机械设备声源分离网络模型,以解决单模态机械设备混合音频信号分离方法存在的声源对应关系不确定问题。
1 文中方法
1.1 网络模型整体结构
提出的机械设备多模态声源分离网络模型受PixelPlayer[8]算法启发改进而得。PixelPlayer是一种针对乐器声源分离提出的网络模型,该模型属于双流结构,以乐器视频流和乐器混合音频流作为网络输入,整个模型由视频特征提取网络、音频特征提取网络、音视特征融合网络三部分组成,其中,混合音频信号由两个视频的独立音频信号叠加而成,因此,模型实现无监督的声源分离。针对机械设备外观与声源的特点,对PixelPlayer模型的音视频特征提取主干网络进行改进,以提升对机械设备音视频特征提取能力,提高声源分离质量,所提网络模型整体结构如图1所示。

图1 网络模型整体结构
1.2 音频特征提取网络
UNet网络设计之初是为了解决在医学图像分割中存在的问题[14],其通过引入编码器、解码器、融合浅层特征与深层特征等方式有效恢复图像的边界和空间信息,随后被广泛应用于图像分割领域,UNet网络结构如图2所示。
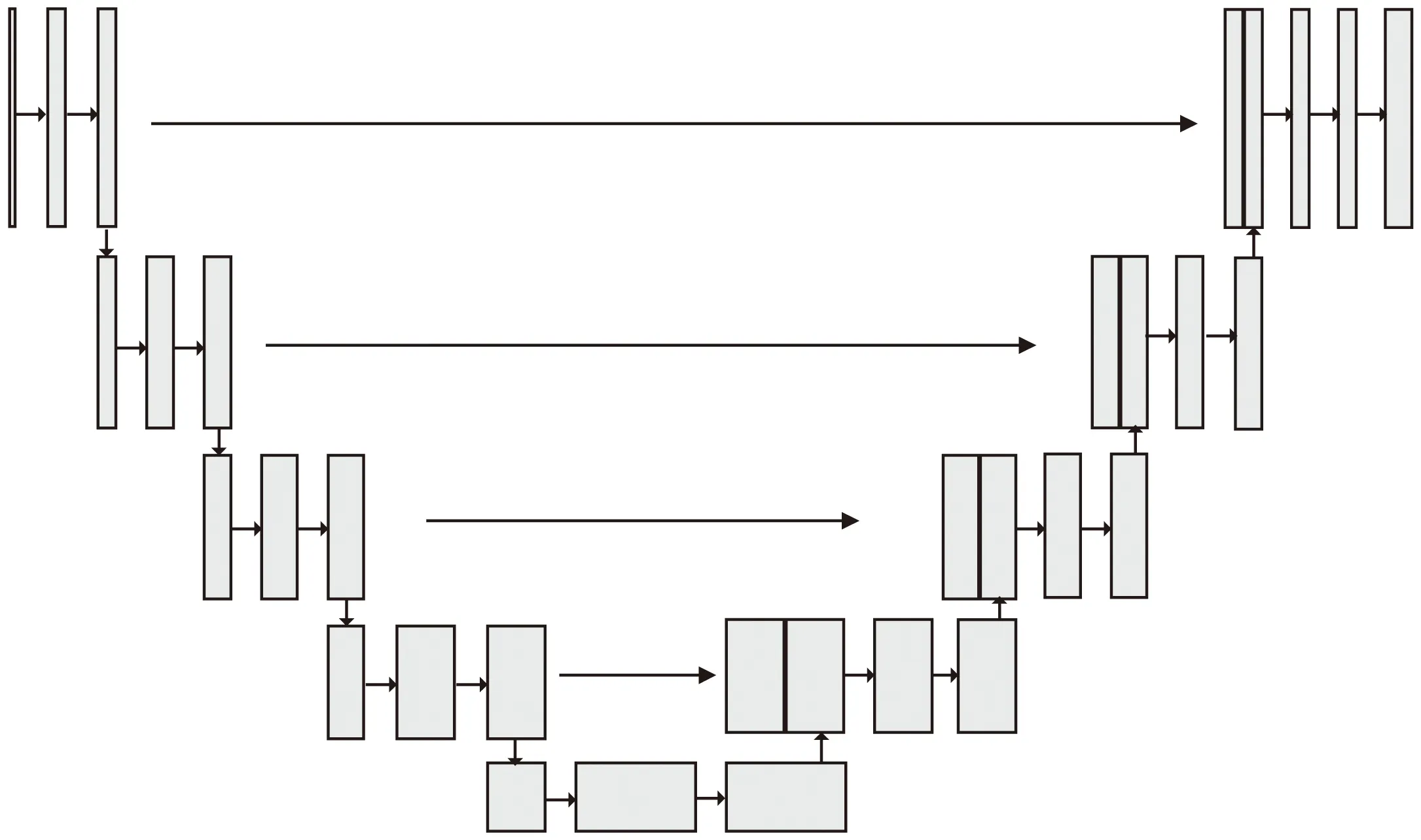
图2 UNet网络结构
UNet网络由左侧的编码器和右侧的编码器组成,两者是对称结构,编码器对图像进行4次下采样,通过卷积层提取不同深度图像语义特征并获取图像上下文信息。解码器对特征图进行4次上采样,将图像上下文信息传递给高分辨率层并恢复图像尺寸,再通过跳跃连接与相应浅层特征图拼接,将浅层特征中更多的空间信息与深层特征中更多的语义信息融合,使网络学习更多不同类型特征,提高网络对特征的学习与表达能力。
针对不同机械设备声源相似度高,在混合声谱图中不同机械设备声谱特征表现差异小,如果直接连接编码器的输出特征与解码器上采样之后的特征,由于浅层特征与深层特征语义差异较大,未消除初级噪声干扰会对模型最后的输出结果产生影响,降低声源分离效果。因此,该文提出在UNet网络中引入坐标注意力机制模块(Coordinate Attention,CA)[15]用以替换编码器与解码器之间的直接跳跃连接,增强编码器中不同特征的空间位置信息表达,抑制干扰噪声,缩小编码器与解码器之间的语义特征差异。将融入CA模块的UNet网络称为CA-UNet,CA-UNet结构如图3所示。
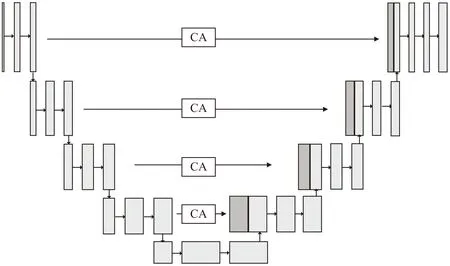
图3 CA-UNet网络结构
其中,CA模块是一个可以用来增强信息表达能力的计算单元,它可以将任意特征X=[x1,x2,…,xc]∈C×H×W作为输入,并输出一个有着增强表达能力的同尺寸输出特征Y=[y1,y2,…,yc]∈RC×H×W。该模块通过精准的位置信息对通道关系和远距离依赖关系进行编码,具体步骤可分为坐标信息嵌入和坐标注意力生成,CA模块结构如图4所示。

图4 CA模块结构
对于坐标信息嵌入,全局池化方法通常用于通道注意力机制编码全局的空间信息,但它将全局空间信息压缩到一个通道维度中,难以保存特征中存在的位置信息,而位置信息对于提取特征图中的空间结构特征至关重要。为了提高注意力模块提取具有精准位置信息的空间结构特征,CA模块将全局池化分解为两个一维特征编码过程,分别沿水平X和垂直Y两个空间方向压缩特征。对于特征图F∈RC×H×W,在每个通道上使用尺寸为(H,1)和(1,W)的平均池化核分别沿着水平坐标X方向和垂直坐标Y方向进行编码,其计算如式(1)(2)所示。
(1)
(2)
通过这种编码方式,返回一对方向感知注意力图,它们在一个空间方向捕获远距离依赖关系,同时在另一个空间方向保留精确的特征位置信息。这有助于网络更准确地定位当前更感兴趣的区域。
对于坐标注意力生成,将上述坐标信息嵌入得到的注意力图进行拼接,再对其进行卷积操作,其计算如式(3)所示。
f=σ(F1([Zh,Zw]))
(3)
式中,σ为ReLU激活函数,F1为1×1的卷积运算,[·,·]是将特征沿通道进行拼接,为降低网络复杂度,通常采用下采样比例r来压缩特征图f通道数,文中r=32,则f∈RC/r×(H+W)是在水平方向和垂直方向上编码空间信息的中间特征映射,将特征f按通道维度划分为两个张量fw∈RC/r×W和fh∈RC/r×H,再分别进行卷积操作,使其恢复到输入特征的通道数目,其计算如式(4)(5)所示。
gh=σ(Fh(fh))
(4)
gw=σ(Fw(fw))
(5)
式中:σ为Sigmoid激活函数,Fh和Fw为1×1卷积运算,gh和gw为坐标注意力机制矩阵,则通过坐标注意力机制的输出特征yc可以用公式(6)表示。
(6)
1.3 视频特征提取网络
ResNet[16]是一种将残差模块的相同拓扑结构以跳跃连接的方式进行堆叠而构建的深度网络结构,该结构的提出有效解决了随着网络深度的增加而导致的梯度消失和爆炸等问题。ResNet18虽然能有效解决梯度消失和爆炸的问题,但应用于机械设备视觉特征提取场景时,存在特征提取尺度单一、语义特征不够丰富等不足。因此,该文提出将ResNet18网络中的残差模块改进为Res2Net[17]中的多尺度特征提取结构,该结构利用特征分组的思想,在残差块内以多组卷积替换原来单一卷积,并以层级残差方式连接,通过构建的多组不同尺度卷积层结构增加输出特征感受野,提高网络对机械设备细粒度视觉特征提取,改进前后的残差块结构如图5所示。

图5 残差模块结构
图5(a)是ResNet18网络中的残差块结构,包含两个3×3卷积层;图5(b)是改进后的残差块结构,将ResNet18残差块中的第二个3×3卷积替换成多组不同尺度的3×3卷积,达到多尺度特征提取的目的。其中引入的超参数s,将经过3×3卷积层输出的特征图F∈RC×H×W按通道划分为S组,即每一组特征xi的形状为F∈RC/s×H×W,其中i∈{1,2,…,s},在保持空间特征不变的同时,对经过3×3卷积输出的操作记为Ki()。第1组特征x1不经过卷积操作直接输出y1=x1,第2组特征x2,经过3×3卷积层输出y2=K2(x2),第3组特征x3和y2做特征融合后再通过3×3卷积层后输出y3=K3(x3+y2),计算推导如式(7)所示。
(7)
将具有多尺度特征提取结构的ResNet18网络称为Res2Net18,采用超参数s=4的Res2Net18作为视觉特征提取主干网络,网络结构参数见表1。
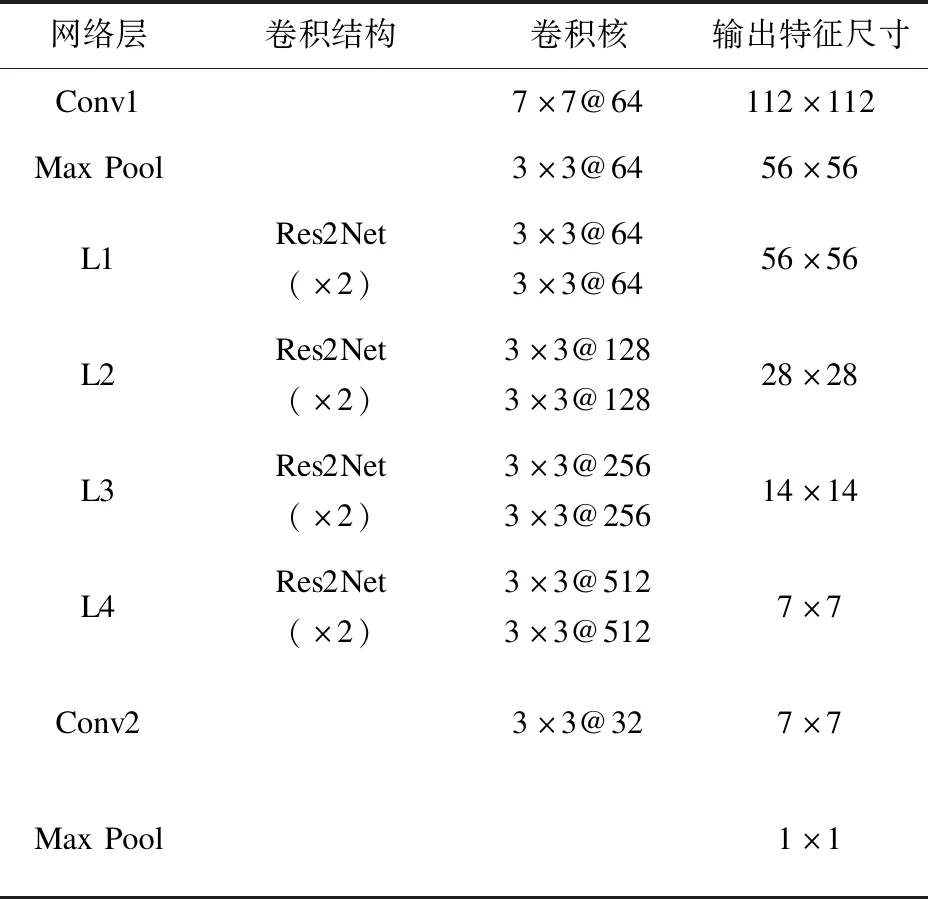
表1 Res2Net18网络结构
1.4 音视频特征融合网络
音视频特征融合阶段将提取到的机械设备视频特征融入音频特征中,视频特征ik的形状F∈k×1×1,混合音频特征sk的形状F∈k×256×256,k是音视频特征通道数。在特征融合时,按特征通道将视觉特征ik与音频特征ik(x,y)每一个特征元素相乘,再按特征通道将对应特征元素相加,则生成视觉特征对应的声源掩码Μ,掩码Μ的形状F∈1×256×256,再将掩码与混合音频频谱结合即可得到视觉特征对应的独立声源频谱,音视频特征融合计算如公式(8)所示。
(8)
式中,αk和β0是一组能够自适应学习的权重系数,在训练时自动调整以加快模型的收敛速度。
2 实验与分析
2.1 实验环境
本次实验采用的深度学习框架是PyTorch1.10.0,编程语言为Python3.6.2,在此基础上搭建实验运行环境。电脑硬件方面,操作系统为Windows10专业版,CPU为i5-10400F,16G内存,并使用NVIDIA GeForce RTX3060显卡12G显存的GPU对网络训练进行加速。
2.2 数据集及预处理
数据集来源于网络和仿真模拟拍摄,共计5种机械设备,包括齿轮箱、电机、剪切机、机床和工业风扇,每种机械设备有40条视频数据,总计200条,每条视频中仅含有一种机械设备与相应音频信号,视频时长由10秒到3分钟不等,训练集与验证集按8∶2随机划分。
随机裁剪两段不同类型的机械设备音频信号,将两段音频信号混合模拟混合音频信号。以11 025 Hz的采样频率对混合音频采样,共计65 536个采样点用于训练,取每1 022个采样点为一帧,帧移为256个采样点,窗函数为汉明窗的短时傅里叶变换将音频信号由时域转为频域,生成幅度谱和相位谱,再选择幅度谱作为音频特征提取网络的输入,输入网络前通过下采样将幅度谱尺寸调整为256×256。
视频特征提取网络输入机械设备视频帧图像,随机选择音频段内相应的视频帧图像,如果将该音频段内全部图像送入网络,会造成信息冗余,不利于网络训练。因此,对于每个视频选择3帧图像,输入视频特征提取网络前采用双线性插值方法将图像尺寸调整为224×224。
2.3 评价指标
实验采用的评价指标为BSSEVAL[18],BSSEVAL通常用来评估模型的分离性能。根据BSSEVAL,声源分离性能评估使用3个定量值表示,分别是信噪失真比(Source to Distortion Ratio,SDR)、信噪干扰比(Source to Interference Ratio,SIR)和信噪伪影比(Source to Artifact Ratio,SAR)。这3个评价指标的核心思想是将预测信号y分解为目标信号starget、干扰信号einterf、噪声信号enoise和误差信号eartif,其计算如式(9)所示。
y=starget+einterf+enoise+eartif
(9)
则SDR、SIR和SAR的计算如式(10)(11)和(12)所示。
(10)
(11)
(12)
其中,SDR反映声源分离的总体效果,SIR反映分离算法对干扰信号的抑制能力,SAR反映分离算法对引入噪声的抑制能力。因此,评估指标SDR、SIR和SAR的值越高表明分离算法性能越好,实验采用基于Python的开源声音评估库mir_eval[19]对SDR、SIR和SAR的值进行计算。
2.4 训练参数及目标
模型训练选择随机梯度下降法,动量值为0.9,视觉特征网络学习率为0.000 1,音频特征网络学习率为0.001,特征融合网络学习率为0.001,设置训练迭代为100个epoch,批次大小为8,音视频特征通道数K=32。
声源分离的目标是获取理想比值掩码(Ideal Ratio Mask,IRM),通过计算单一音频与混合音频幅值比获得,计算如式(13)所示。
(13)
式中,(t,f)代表声谱图的时间与频率坐标,Sn和Smix是单一音频和混合音频的幅度谱,由此,可以计算每一种音频在混合音频中的真实比值掩码M,在实验中,将真实比值掩码M作为训练目标。
2.5 结果与分析
实验在两种不同类型机械设备音频信号混合的情况下,模拟文中方法对声源分离的效果。为了对比网络模型改进效果,也使用相同数据集在PixelPlayer模型上进行训练与评估,两次训练与评估相关超参数保持一致,实验结果见表2。
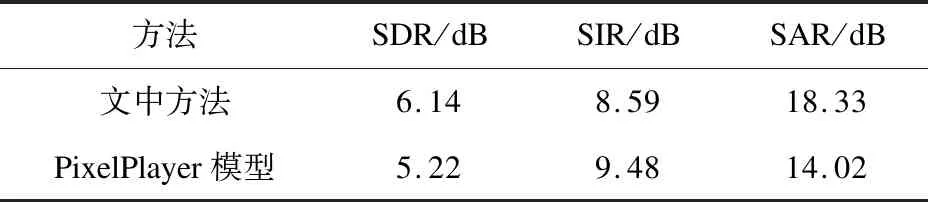
表2 模型改进前后对比实验
从表2可知,通过对音频特征提取的UNet网络中添加CA模块,对视觉特征提取的ResNet18网络中添加多组不同尺度的卷积结构,改进后的模型与PixelPlayer模型相比在SDR和SAR上分别有0.92 dB和4.31 dB的提高。从而可以看出,提出的两种特征提取主干网络能够提高对机械设备的音视频特征提取能力,提升模型对机械设备的声源分离效果。
为了可视化对比文中方法和PixelPlayer模型对声源分离效果的差异,选择剪切机和电机混合音频分离前后声谱图像作为对比,分离效果如图6所示。

图6 模型改进前后分离效果对比
图6中,Mixture是混合声谱图,Ground Truth为混合前单一声源的声谱图像,上侧为剪切机下侧为电机。对于分离后剪切机的声谱图,文中方法更加接近真实的声谱图,而PixelPlayer模型中还残留少量电机的声谱能量。对于分离后电机的声谱图,文中方法表现也更加优异,分离后的整体声谱变化更加接近真实的声谱图,而PixelPlayer模型分离后的电机声谱图还残留大量剪切机的能量,声谱图整体变化趋势也相差较大,说明PixelPlayer模型并不能较好地分离机械设备声源信号。
为了对比文中使用的多尺度特征提取结构与CA模块对声源分离的影响,设计了对比消融实验。通过搭配不同的特征提取网络,探究其不同模块对声源分离的影响程度,音频特征提取网络和视频特征提取网络分别为CA-UNet+Res2Net18、CA-UNet+ResNet18、UNet+Res2Net18和UNet+ResNet18,实验结果见表3。

表3 消融实验
从表3可知,含有多尺度特征提取结构和CA模块的音视频特征组合网络,获得了最好的分离效果,在SDR和SAR上表现最优。说明多尺度特征提取结构和CA模块均能够提高网络对机械设备音视频特征的提取能力,提高对机械设备声源的分离效果。当音频特征提取网络相同时,具有多尺度特征提取结构的Res2Net18网络对声源分离的总体效果SDR上有0.38 dB和0.39 dB的提高。当视频特征提取网络相同时,具有坐标注意力模块的CA-Unet网络对声源分离的总体效果SDR上有0.53 dB和0.54 dB的提高,可以看出,音频特征提取网络的改进对声源分离总体效果影响更大。
为了进一步验证所提多模态声源分离方法在机械设备声源分离任务的先进性,将所提模型与文献[11-12]所提多模态声源分离模型进行对比。文献[11-12]所提模型与PixelPlayer模型结构类似,特征提取主干网络均为ResNet18和UNet,不同之处在于文献[11]所提模型的视觉特征提取网络输入为单帧图像且在声源分离过程中融入声源物体的类别信息。而文献[12]所提模型按循环递归方式进行声源分离,并在分离时通过残差UNet对分离频谱进行修正。使用相同数据集对上述两种模型进行训练与评估,训练与评估相关超参数均保持一致,实验结果见表4。

表4 不同模型对比实验
从表4可知,所提模型在SDR和SAR上均取得最优结果,SIR略低。与文献[11-12]所提模型的主要不同在于,文中模型对特征提取主干网络进行改进,以提高对机械设备音视频特征提取能力,而文献[11]模型中融入声源类别信息对声源分离效果的提升并不明显,而文献[12]模型在分离时使用残差UNet对分离频谱进行修正,与文献[11]模型相比使用残差UNet对分离频谱进行修正有效改善了对机械设备声源分离效果,在SIR上达到最优表现,但在SDR和SAR上略低于文中所提模型。
3 结束语
针对单模态混合信号分离方法存在的无法确定机械设备与声源对应关系问题,提出一种多模态特征融合的机械设备声源分离方法。与单模态分离方法仅依靠音频信号进行分离不同,该文将机械设备视觉特征融入音频特征中,通过融合机械设备音视频特征生成视觉特征对应声源掩码,将声源掩码与混合音频频谱结合得到独立声源频谱,从而实现根据视觉特征分离对应声源信号。实验结果表明,所提机械设备多模态声源分离方法,能够有效对两种不同类型的机械设备混合音频信号进行分离,通过改进的Res2Net18和CA-UNet网络提高对机械设备音视频特征提取能力。与现有三种多模态声源分离模型相比,所提模型在机械设备声源分离任务上具有明显优势,为机械设备混合音频信号分离提供了新的解决方法。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15 07:54:30
电子制作(2019年23期)2019-02-23 13:21:12
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
电子制作(2017年9期)2017-04-17 03:00:46
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2016年5期)2016-11-09 09:09:47
人间(2015年8期)2016-01-09 13:12:42
舰船科学技术(2015年8期)2015-02-27 15:38:48
噪声与振动控制(2015年4期)2015-01-01 07:08:21
