
基于机器学习的围绝经期综合征中医智能辨证模型构建研究
2023-06-13 02:08姚帅君闫敬来杜彩凤温岩刘铭杨继红
中国中医药信息杂志 2023年6期
姚帅君,闫敬来,杜彩凤,温岩,刘铭,杨继红
山西中医药大学,山西 晋中 030619
围绝经期综合征(perimenopausal syndrome,PPS)指妇女在绝经前后时期卵巢的功能逐步衰退,从而引起体内雌性激素水平降低,以及自主神经功能紊乱和代谢障碍为主的一组症候群。本病多发生于45~55岁,是妇女绝经相关最常见的疾病,涉及人体多个器官、系统。目前多数学者认为本病与卵巢功能减退引起的内分泌紊乱密切相关,同时也与社会、心理因素有关[1]。激素治疗是现代医学治疗PPS最主要的方法,但不良反应较大,存在潜在风险。历代中医医籍对本病并无专题论述,按照辨证论治及症状表现将其归属于“年老血崩”“脏燥”等范畴。中医疗法可有效缓解患者的临床症状,且不良反应较少,但目前尚存在缺乏统一的疗效评价体系和缺乏大样本临床研究等局限[2]。
辨证论治是中医的特色和精髓,但中医辨证受个人主观因素的影响,不确定性强,存在客观化、标准化等方面的不足。目前,中医数字化辨证是人工智能在中医领域研究的热点课题[3-6]。统一规范的中医辨证模式是中医辨证智能化的基础,同时也是中医药现代化的重要内容之一[7]。本研究基于逻辑回归、支持向量机、K近邻、随机森林、XGBoost、BP神经网络6种机器学习算法,及公开发表的文献医案数据建立PPS中医辨证模型,旨在为PPS的辅助诊断提供参考,并为中医辨证智能化和客观化提供借鉴。
1 资料与方法
1.1 数据来源与检索策略
本研究医案数据来源于两部分:一部分为数据库,包括中国知识资源总库(CNKI)、中文科技期刊数据库(VIP)、万方数据知识服务平台(Wanfang Data)、中国生物医学文献数据库(CBM)建库至2022年5月发表的中医治疗PPS的临床文献;另一部分为古今医案云平台2.3.5收录的PPS相关中医病案。
数据库采用高级检索,先以“围绝经期综合征”与“医案”“经验”“验案”“病案”为检索词两两组合进行检索,然后以“更年期综合征”与“医案”“经验”“验案”“病案”为检索词两两组合进行检索,再以“经断前后诸证”与“医案”“经验”“验案”“病案”为检索词两两组合进行检索。在古今医案云平台分别以“围绝经期综合征”“更年期综合征”“经断前后诸证”为主题词进行一框式检索。
1.2 证型标准
参考《中西医结合内分泌代谢疾病诊治学》[8]、《妇产科中西医结合诊疗技巧》[9]、《中医妇科学》[10]、《中医病证诊断疗效标准》[11]中有关PPS或经断前后诸证辨证分型的论述,将本病证候确定为肾阴虚、肾阳虚、肾阴阳两虚、肾虚肝旺、肝郁化火、肝气郁结、气滞血瘀、心脾两虚共8个证型。
1.3 文献筛选标准
纳入标准:①符合上述证型标准的中医治疗PPS的医案文献;②文献中四诊信息记录完整的中医医案及临床观察类文献。
排除标准:①学位论文、综述、Meta分析、理论论述类文献;②中西医结合治疗的临床病例;③四诊信息记录不完整(缺少舌象和脉象)的医案;④其他疾病(如乳腺癌、糖尿病等)合并PPS的临床病例。
1.4 数据录入
首先将符合纳入标准的文献题目录入WPS2019,去除重复文献后,以剩余文献题目为检索词在上述数据库中进行一框式检索,提取其中可供录入的医案内容,然后将医案录入(录入内容为患者症状、体征及所对应的证型)。最终获得上述医案样本的数据信息(其中肾阴虚证215例,肾阳虚证61例,肾阴阳两虚证141例,肾虚肝旺证255例,肝郁化火证148例,肝气郁结证79例,气滞血瘀证63例,心脾两虚证59例),以此作为原始数据库(录入格式:医案编号;症状和体征;证型)。
1.5 数据预处理
以患者的临床指标为特征值(包括胸闷、口苦、口干、善太息、盗汗、潮热汗出、失眠多梦、健忘、面红目赤、面色㿠白、面色萎黄、两颧潮红、头晕目眩、两目干涩、耳鸣、心烦、心悸、手足心热、四肢不温、下肢冰冷、畏寒、悲伤欲哭、急躁易怒、情绪低落、胸胁胀痛、乳房胀痛、外阴干涩、外阴瘙痒、腰膝酸软、气短、精神倦怠、乏力、胃脘胀满、纳呆、小便短赤、小便清长、大便溏薄、大便秘结、大便时溏时秘、月经有血块、月经量多、月经量少、月经量时多时少、月经先期、月经后期、月经先后不定期、月经紊乱、闭经、舌红、舌淡红、舌淡白、舌黯红、舌紫黯、胖大舌、齿痕舌、瘀斑瘀点舌、苔白、苔黄、苔薄、苔厚、少苔、无苔、脉弦、脉细、脉滑、脉虚、脉涩、脉沉、脉迟、脉数、脉缓、脉弱共72项),并使用“0-1”编码对各列特征进行赋值,即出现该特征记为“1”,不出现该特征记为“0”。然后以原始数据库中每个样本所对应的证型作为目标值(包括心脾两虚、气滞血瘀、肝气郁结、肝郁化火、肾虚肝旺、肾阳虚、肾阴虚、肾阴阳两虚共8类),建立PPS数据集(数据集格式:患者编号;特征值;目标值)。
通过Scikit-learn中的标签编码(Label Encoding)类对目标值下的中医证型进行处理,将文本信息映射为数值,即转换为0,1,2,3,4,5,6,7 的标签。利用train_test_split 模块将PPS 数据集的70%作为训练集(n=714),30%作为测试集(n=307),通过设置参数stratify=y使训练集和测试集中各证型数据与原PPS数据集保持相同的比例,然后通过设置参数random_state=0保证每次实验都使用相同的训练集和测试集,并增加实验的重现性。
1.6 实验环境与框架
本研究开发环境为PyCharm2021.1,逻辑回归、支持向量机、随机森林、K近邻及XGBoost算法采用的框架为Scikit-learn0.24.2。Scikit-learn是Python第三方提供的机器学习框架,支持分类、聚类、降维、回归四大算法及特征提取、数据处理、模型评估三大模块[12]。BP 神经网络采用的框架为PyTorch1.0.0。PyTorch是以Python优先的深度学习框架,不仅支持自动求导功能,且设计简洁,较其他深度学习框架具有灵活性强、运行速度快等优点[13]。模型解释采用的框架为SHAP0.40.0,它使用SHAP值解释机器学习模型和特征重要性[14]。
1.7 样本类别不平衡处理
PPS 最常见的证型是肾虚肝旺证,而肾阳虚证、气滞血瘀证临床较为少见。因此,本研究使用的数据集为典型的多分类类别不平衡数据集,为使模型的泛化能力不受影响,在实验过程中对逻辑回归、支持向量机、随机森林模型直接在建模时设置参数class_weight=“balanced”平衡样本的权重,对XGBoost模型在拟合模型时手动计算各类别的权重后赋值给sample_weight参数,对BP神经网络同样手动计算各类别的权重后赋值给nn.CrossEntropyLoss 类中的weight参数。
1.8 分类器模型构建
逻辑回归(logistic regression)主要应用于二分类问题,也可应用于多分类问题[15]。逻辑回归假定观察值样本因变量的概率分布呈S形,且通过极大似然估计使因变量观察次数的概率极大化,从而得到自变量参数的最佳估计值[16]。本研究通过调用sklearn 中的LogisticRegression算法实现逻辑回归建模,参数solver(求解器)选择“saga”,其余超参数选择最优组合,然后调用fit函数用训练集拟合模型,通过predict函数输出预测值。
支持向量机(support vector machine)通过在特征空间构造一个距离样本点间隔最大的分离超平面ωTx+b=0将实例分到不同的类[17]。支持向量机是机器学习领域若干技术集大成者,能够较好地解决小样本、非线性、高维数和局部最小等一系列问题[18]。在本研究中通过调用sklearn中的svm.SVM算法实现支持向量机建模,参数kernel(核函数)选择“rbf”,其余超参数选择最优组合,然后调用fit函数用训练集拟合模型,通过predict函数输出预测值。
随机森林(random forest)算法首先在变量和数据的使用上进行随机化,削弱数据间的相关性,构造大量的规则树,通过简单投票判断类别并汇总结果[19]。它能够很好地预测多达几千个解释变量的作用,被誉为当前最好的机器学习算法之一。本研究通过调用sklearn中的RandomForestClassifier算法实现随机森林建模,参数criterion(衡量指标)选择“gini”,其余超参数选择最优组合,然后调用fit函数用训练集拟合模型,通过predict函数输出预测值。
K近邻(K-nearest neighbor)的思想是,如果待测样本与训练集中的k个样本最相似(即在特征空间中最邻近),并且k个样本中的大多数属于某类,则待测样本也属于该类[20]。k值的选择、距离度量、分类决策规则是K 近邻法的3 个基本要素[21]。本研究通过调用sklearn 中的KNeighborsClassifier 算法实现K 近邻建模,参数weights(近邻权)选择“distance”,其余超参数选择最优组合,然后调用fit函数用训练集拟合模型,通过predict函数输出预测值。
XGBoost算法通过对损失函数进行二阶泰勒展开,然后在损失函数之外对正则项求得最优解,它可以充分利用多核CPU并行计算的优势,从而能够更快地进行模型探索[22]。本研究通过调用xgboost库中的sklearn接口XGBClassifier实现XGBoost建模,参数objective(目标函数)选择“multi:softmax”,其余超参数选择最优组合,然后调用fit 函数用训练集拟合模型,通过predict函数输出预测值。
BP 神经网络(backpropagation neural network)的结构包括输入层、隐含层、输出层。该算法的工作流程:先将输入示例提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结果;然后计算输出层的误差,再将误差逆向传播至隐层神经元,最后根据隐层神经元的误差对连接权和阈值进行调整,该迭代过程循环进行,直到达到停止条件为止[23]。本研究通过torch.nn模块层层堆叠的方式搭建神经网络分类器,神经网络中包含1个输入层、2个隐含层和1个输出层。其中输入层与隐含层之间、隐含层与隐含层之间选择Relu 激活函数,输出层选择Softmax函数进行多分类输出,训练迭代周期设定为50,其余超参数选择最优组合。在每一个训练周期(epoch)通过DataLoader 方法循环获得训练batch(批次),对每一批数据使用crossentropy loss(交叉熵损失函数)作为模型的学习策略,优化器选择Adam(自适应矩估计算法),然后通过torch.optim模块完成优化器清零、损失反向传播、优化器更新等训练步骤。
1.9 超参数调优与模型评价
逻辑回归、支持向量机、K 近邻、随机森林、XGBoost 采用GridSearchCV 模块通过参数列表param_grid寻找最优模型的超参数组合,使用分层K(K=5)折交叉验证。BP神经网络在Optuna框架下创建objective(目标函数),objective的评估指标设置为accuracy(准确率),通过study(研究对象)最大化目标函数值进行30次trials(试验),并在试验完成后从study中选择最优的超参数组合。
以上模型均使用准确率(accuracy)、精确率(precision)、召回率(recall)、f1分数(f1 score)、混淆矩阵、受试者工作特征(ROC)曲线及曲线下面积(AUC)评估模型的性能。
2 结果
高级检索得到文献3 519篇,一框式检索得到医案文献559篇。去除重复文献后得到文献963篇,含可供录入的医案1 021则。
2.1 模型评价
2.1.1 逻辑回归
通过逻辑回归建模后输出的各证型ROC 曲线见图1,混淆矩阵见图2。
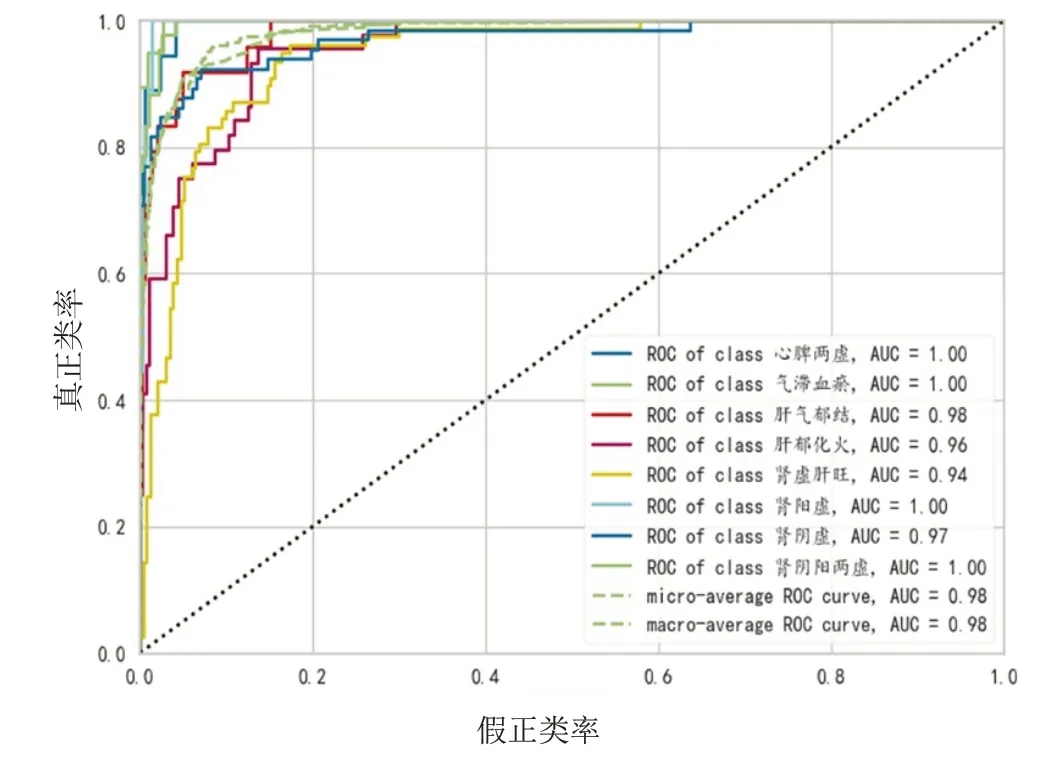
图1 逻辑回归模型ROC曲线
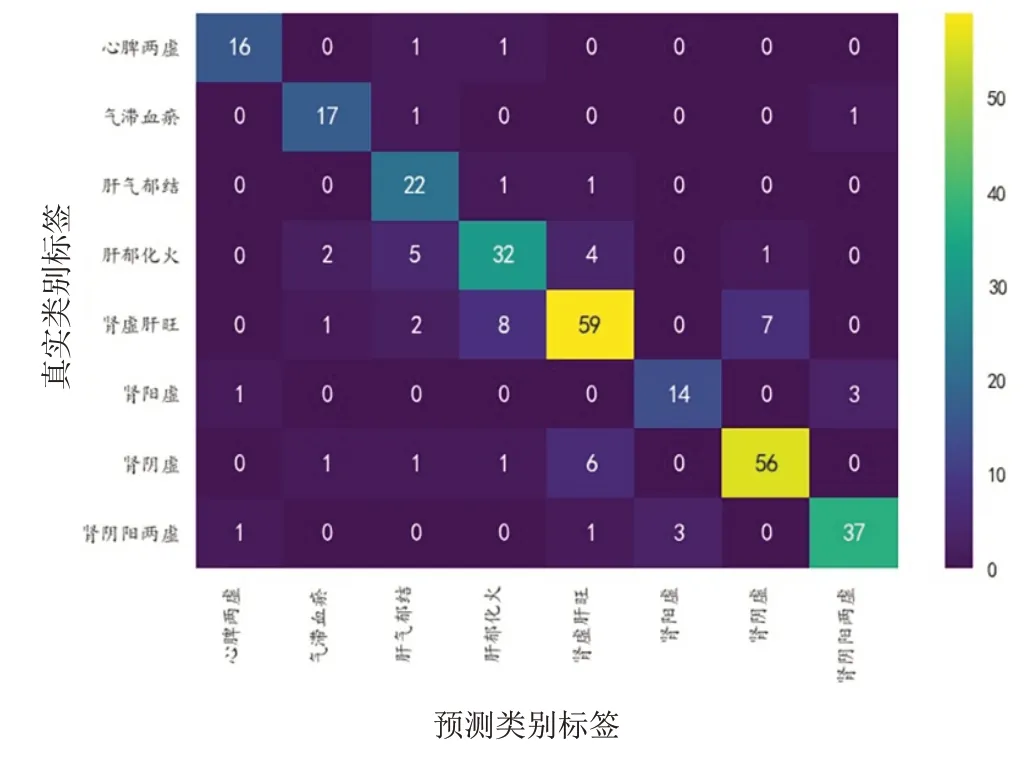
图2 逻辑回归模型混淆矩阵
2.1.2 支持向量机
通过支持向量机建模后输出的各证型ROC曲线见图3,混淆矩阵见图4。

图3 支持向量机模型ROC曲线
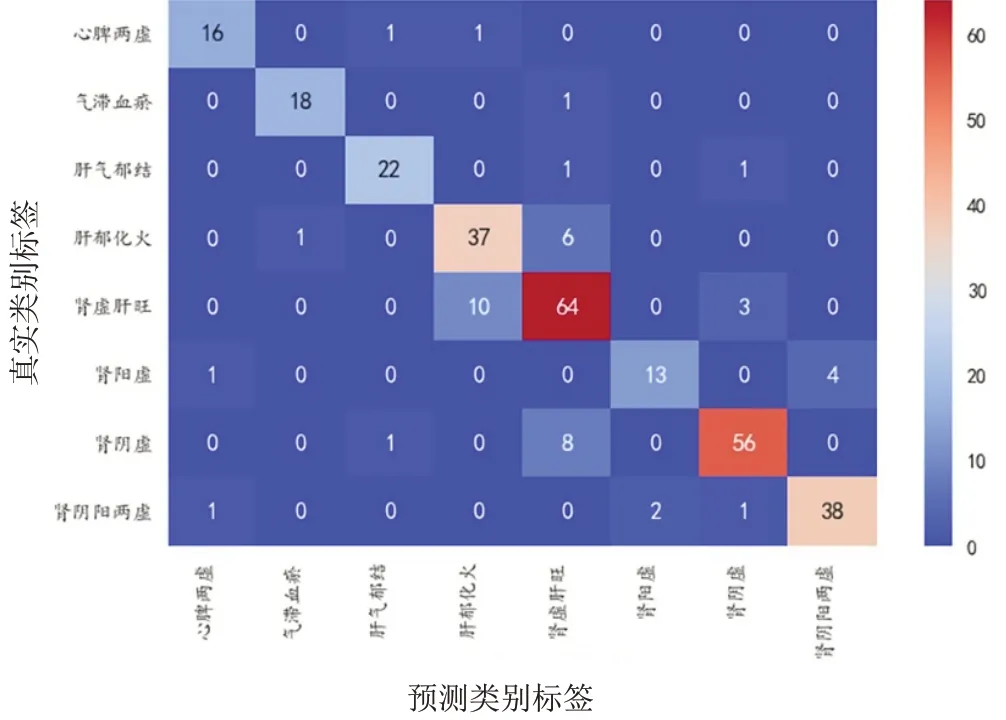
图4 支持向量机模型混淆矩阵
2.1.3 K近邻
通过K 近邻法建模后输出的各证型ROC 曲线见图5,混淆矩阵见图6。
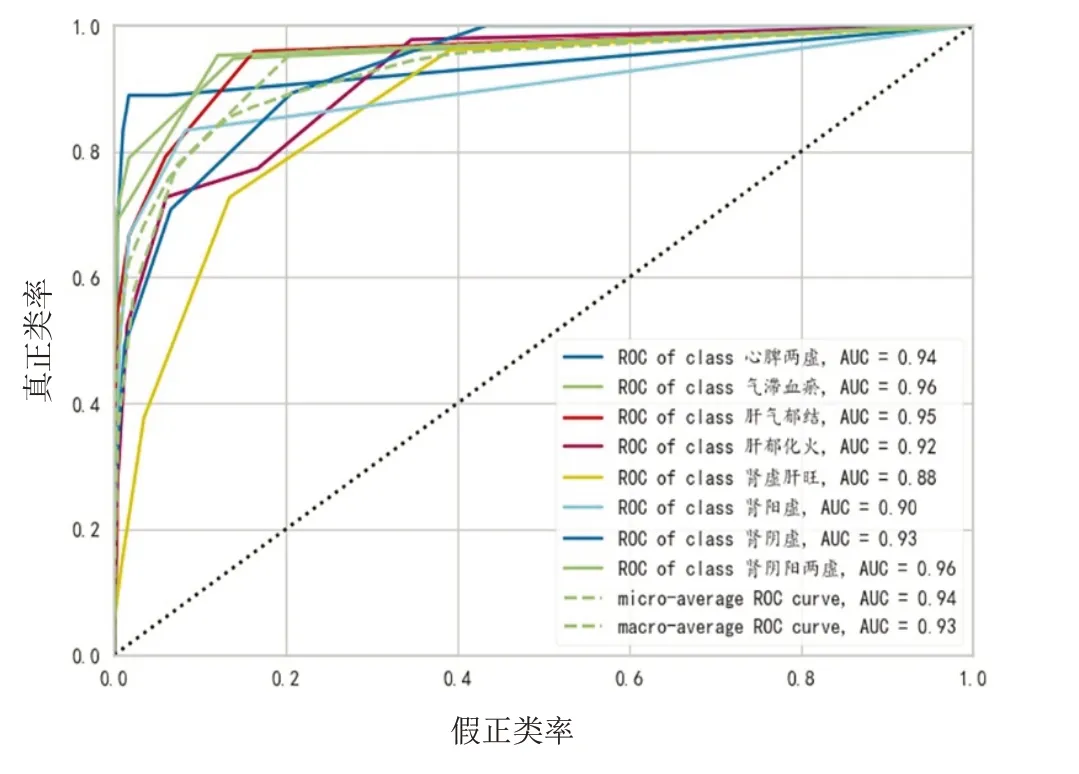
图5 K近邻模型ROC曲线

图6 K近邻模型混淆矩阵
2.1.4 随机森林
通过随机森林建模后输出的各证型ROC 曲线见图7,混淆矩阵见图8。
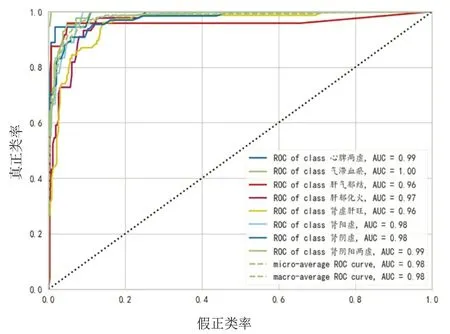
图7 随机森林模型ROC曲线
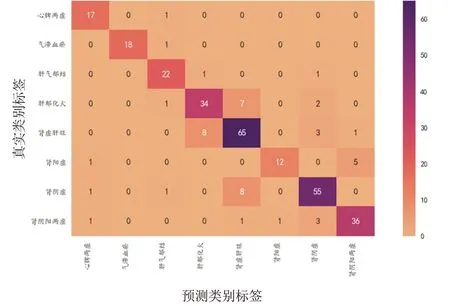
图8 随机森林模型混淆矩阵
2.1.5 XGBoost
通过XGBoost 建模后输出的各证型ROC 曲线见图9,混淆矩阵见图10。
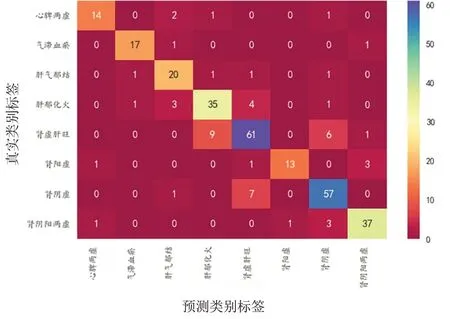
图10 XGBoost模型混淆矩阵
2.1.6 BP神经网络
通过BP神经网络建模的accuracy-loss曲线见图11。x轴代表epoch(训练周期),y轴代表准确率和损失。随着迭代次数增加,accuracy逐渐上升,loss逐渐下降,当epoch在50左右时曲线趋于平缓,达到收敛。神经网络建模输出的各证型ROC曲线见图12,混淆矩阵见图13。
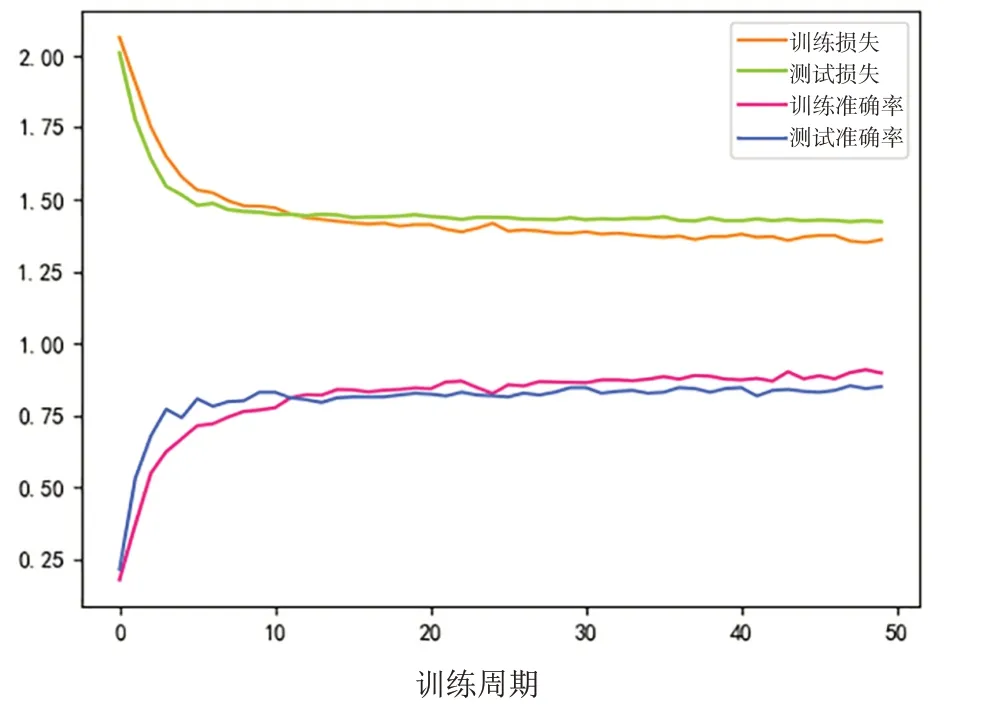
图11 神经网络训练过程accuracy-loss曲线
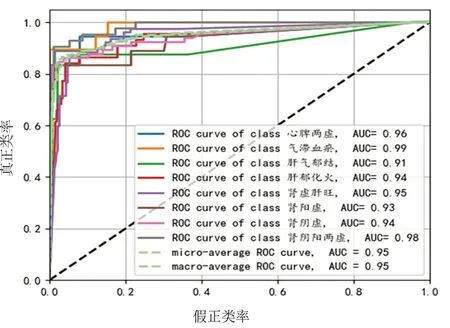
图12 BP神经网络模型ROC曲线
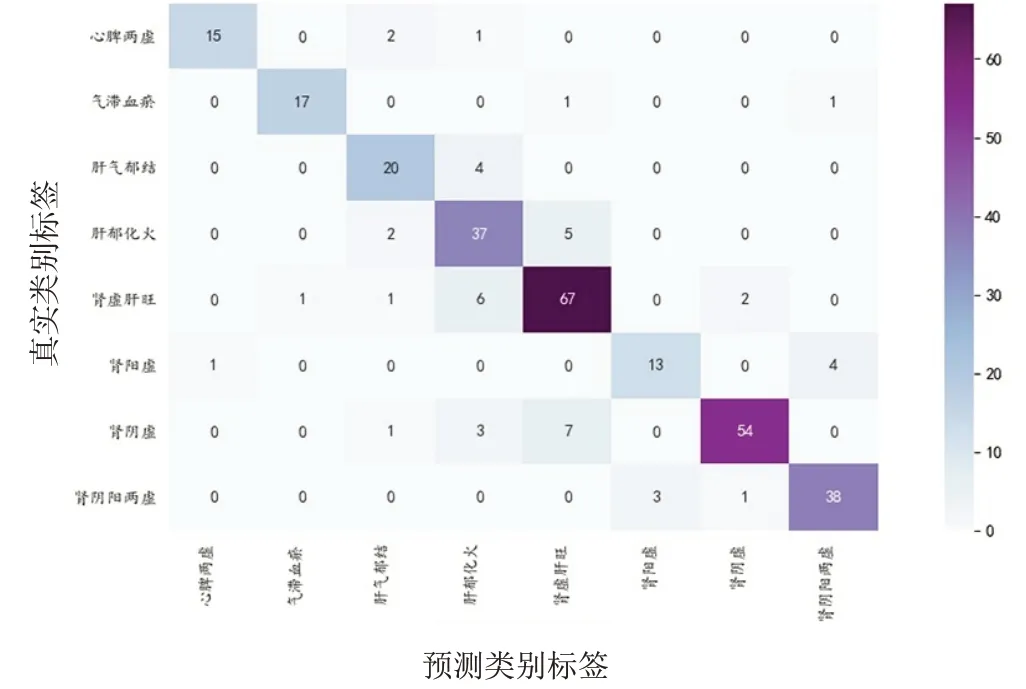
图13 BP神经网络模型混淆矩阵
2.2 模型比较
通过网格搜索和贝叶斯优化后的各辨证模型的最优超参数见表1,其中Optuna超参数自动寻优过程的优化历史曲线见图14。
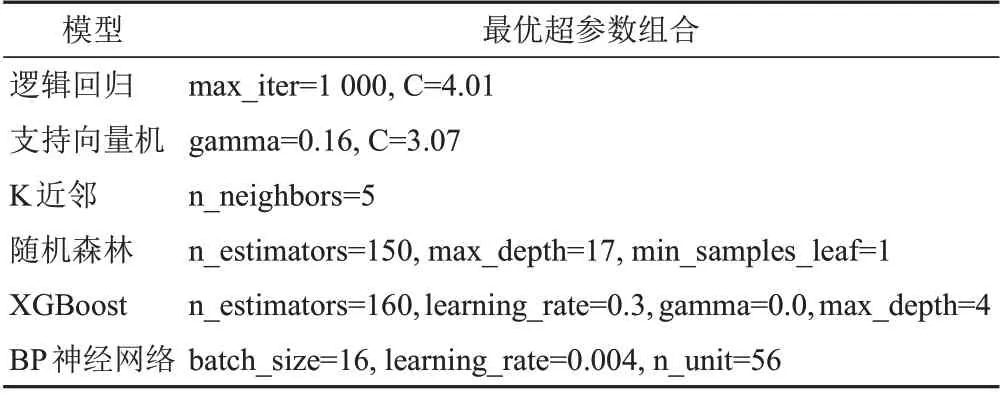
表1 模型最优超参数
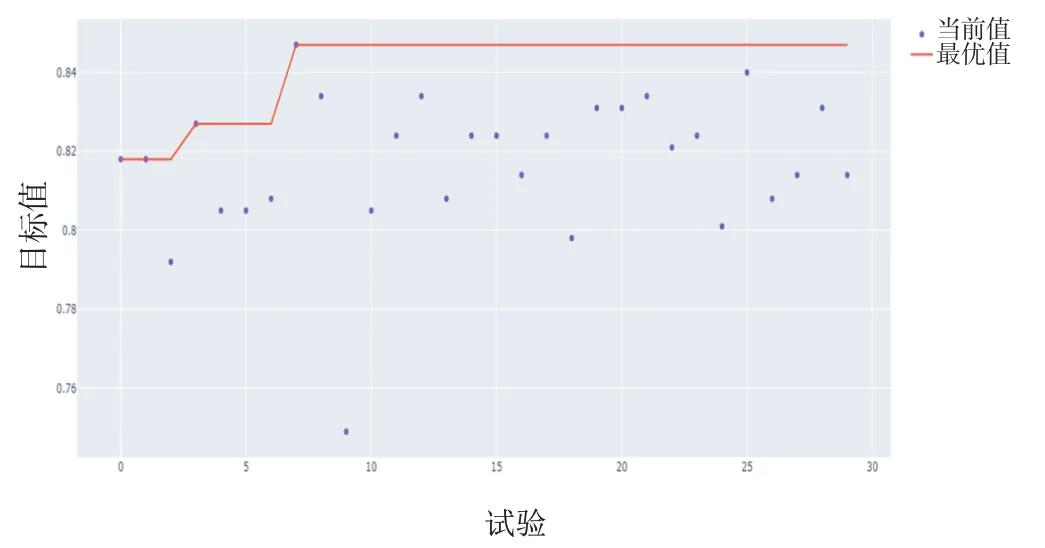
图14 Optuna优化历史曲线
在相同测试集下各分类模型的accuracy、precision、recall、f1 score及AUC值见表2。从表2可知,高斯径向基核函数支持向量机模型的accuracy、precsion、recall、f1 score达0.86,AUC值达0.98,各项评估指标均优于其他分类器模型。
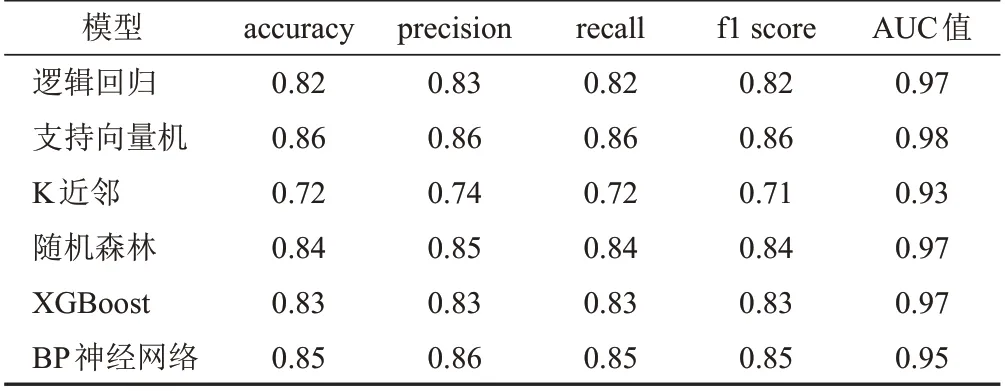
表2 6种算法模型性能评估指标
2.3 模型解释
模型可解释性在医学领域十分重要,医疗辅助决策系统必须是可理解的、可解释的。在理想状态下,模型应向所有相关方解释提供对应决策的完整逻辑,才能得到医生信任[24]。SHAP(SHapley Additive exPlanations)值是由Lundberg 和Lee[25]于2017 年提出的用于解释任何机器学习模型输出的方法。SHAP值源自博弈论中的shaplely value,该方法量化了模型中每个特征对观察结果最终预测的贡献,使用基于所有可能的特征子集组合(包括给定特征)预测模型[26]。本研究按照证型分类求得每个样本特征对应的SHAP值,并使用SHAP值的平均值作为该特征的重要性值,从而得到全局解释,以此阐明模型中贡献度较大的特征。
通过模型性能比较可以看出支持向量机的预测性能优于其他机器学习模型,因此本研究在支持向量机的基础上,调用SHAP 库的Explainer API 降序输出PPS各证型的特征重要性(排名前10位),见图15。由图可知,对心脾两虚证,齿痕舌、大便溏薄、心悸、脉弱、纳差等特征有较高贡献度;对气滞血瘀证,舌黯红、脉涩、瘀斑瘀点舌、心烦、胸闷等特征有较高贡献度;对肝气郁结证,脉弦、心烦、善太息、情绪低落、胸胁胀痛等特征有较高贡献度,对肝郁化火证,急躁易怒、心烦、脉弦、口苦、小便黄赤等特征有较高贡献度;对肾虚肝旺证,脉弦、急躁易怒、口苦、手足心热、乏力等特征有较高贡献度;对肾阳虚证,脉沉、畏寒、四肢不温、面色㿠白、舌淡白等特征有较高贡献度;对肾阴虚证,心烦、盗汗、脉细、手足心热、口干等特征有较高贡献度;对肾阴阳两虚证,脉沉、脉细、腰膝酸软、健忘、畏寒等特征有较高贡献度。
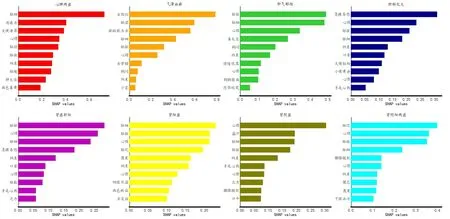
图15 PPS各证型排名前10位的特征贡献度
3 讨论
随着中医药现代化研究不断深入,中医药临床数据量与日俱增,其数据形式和来源更加多样、广泛和复杂。传统的数理统计分析方法和工具已无法满足中医药临床科研的需求,面对更加复杂、海量的医学数据和信息,机器学习算法不仅能为中医辨证提供有力支持[27-28],也能与现代医学实验室指标相结合,提高诊断的准确性。
本研究基于逻辑回归、支持向量机、K近邻、随机森林、XGBoost、BP 神经网络6 种机器学习算法,通过文献中的医案数据对PPS的智能辨证进行分析和探索。研究结果表明,K近邻在6个分类器模型中表现较差,尤其不能较好地区分肾虚肝旺证和肝郁化火证,在75例肾虚肝旺证中,有22例被误分类为肝郁化火证。XGBoost在心脾两虚证的分类上预测能力较弱,18例心脾两虚证仅14例分类正确。随机森林在肾阳虚证的预测方面表现一般,17例肾阳虚证中有5例被预测为肾阴阳两虚证。逻辑回归在各证型的分类任务上表现一般。BP神经网络在肾虚肝旺证的分类上表现最佳,但在其余证型的预测上表现一般。支持向量机在6个分类器中预测性能最佳,各证型的分类正确率都很高,是较为理想的、泛化能力最好的分类器。BP神经网络具有良好的容错性、自组织适应性和学习能力,在疾病的诊断和预后等方面应用广泛。但由于本研究样本量偏小,BP神经网络的分类效果并不十分理想。另外,神经网络算法对于四诊信息的分类方法是随机产生一个分离超平面并移动该超平面,直至属于不同证型的症状和体征刚好位于该超平面的各不同侧面,而支持向量机算法不但能够找到一个满足分类需求的超平面,并使各症状在训练集中的点距离超平面尽可能远,且这样的超平面具有唯一性。因此,神经网络算法仅能使分离超平面将训练集中的数据分开,但各证型的离散度并非最佳;支持向量机算法不仅能使超平面将训练集中的数据分开,还能保证各证型的离散度最大化[29]。可知,支持向量机能很好地解决高维和局部极值的问题,克服神经网络算法中合理结构难以确定和存在局部最优等缺陷[30]。
近年来,支持向量机在中医药领域已经逐渐受到学者的关注。顾天宇等[31]基于支持向量机对中风病中医证候进行分类,模型分类准确率达86%。许明东等[18]基于支持向量机算法建立高血压中医证候诊断模型,总体准确率达90%。陈菊萍[32]运用支持向量机实现了中医证候信息的分类研究,平均训练模型的分类精度达98.8%。但该算法的缺点是面对大样本时矩阵存储和计算将耗费大量内存和时间,其训练速度会变慢,适用性也受到影响[33]。
综上,在中医诊断方面的中小型多分类类别不平衡数据集上,支持向量机模型较其他机器学习算法有更好的表现,对中医临床更有指导意义和参考价值。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
世界科学技术-中医药现代化(2021年8期)2021-12-21
基层中医药(2021年8期)2021-11-02
基层中医药(2021年8期)2021-11-02
世界科学技术-中医药现代化(2021年12期)2021-04-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
基层中医药(2018年4期)2018-08-29
基层中医药(2018年3期)2018-05-31
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
