
Dynamic Unet+: 一种轻量精确的语义分割算法及应用
2023-06-12 05:49陈朗任洋甫杨培刘晓静崔亚超
电脑知识与技术 2023年11期
陈朗 任洋甫 杨培 刘晓静 崔亚超


关键词:深度学习;卷积神经网络;图像语义分割;语义分割算法应用;自动人像抠图
0 引言
图像语义分割是计算机对场景理解的重要环节,由于拍摄图片通常会受到光照、角度、尺度以及拍摄图片分辨率等多种复杂条件的影响,使图像语义分割成了计算机视觉领域具有挑战性的问题。例如像素聚类、阈值分割等传统算法存在难以建立语义层级理解的问题,随着2012年AlexNet在图像分类领域取得的巨大成功,以卷积神经网络为代表的深度学习技术快速发展,同时也深刻影响了包括图像语义分割在内的众多计算机视觉领域的研究。
随着深度学习的引入,模型参数量也成倍增加,巨大的内存消耗和计算开销可能会成为算法应用部署中的一大阻碍。大多数图像语义分割算法具有非常庞大的参数量,例如在实验测试中,基于ResNet101实现的PSPNet[1]有高达70M的参数量,以VGG16为骨干网络的FCN8s[2] 参数量更是超过了130M,以ResNet101 为骨干网络实现的DeepLabv3+也有接近60M的参数量。这些网络在拥有巨大参数量的同时,训练获得原始论文中所报告的精度往往需要大量额外的训练数据以及工程训练技巧,缺乏一定的普适性和实用性。受O Ronneberger等人在医学影像分割领域工作的启发,本文利用轻量的Unet[3]的U形编解码结构和横向越级连接,同时针对Unet对实际场景图像中分割能力表现不足的问题进行多方面的改进,在对多个基准数据集的测试中取得了很好的效果,且需要相对较少的训练技巧和数据量便可获得较好的精度和结果。
本文的主要贡献在以下两个方面:
1) 提出了相对轻量、通用的动态Unet 架构,将ResNet融入Unet中组成动态Unet,提高了模型对复杂场景特征的编码能力,进而提高了模型效果;
2) 替换了反卷积上采样技术,并将像素重组[3]技术应用到模型Dynamic Unet+中,进一步提升了模型解码器的能力并使模型获得了一定的效果增益。
1 Unet 工作回顾和分析
1.1U 形编解码器结构
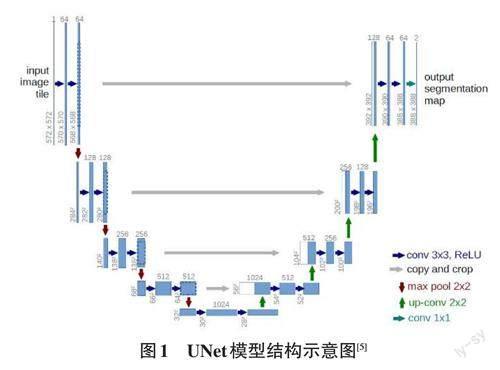
UNet(结构如图1 所示)最早发表在2015 年的MICCAI(医学影像学术顶级会议)上,相比于FCN、PSPNet、DeepLab等发表在计算机视觉领域期刊和会议的工作来说,早期对其重视程度不高。UNet仅有7M左右的参数量,非常适用于应用研究,同时作为一个灵活的语义分割架构,具有很好的越级连接和编解码器的方法。
在Unet基础上也出现了许多UNet的改进版本,例如UNet++[6]和UNet 3+[7]和基于Transformer的Tran?sUNet[8]等,但这些工作主要针对医学影像分割,少有改进工作是针对实际应用场景的复杂图片,且医学影像和现实场景图片在数据分布和复杂度方面存在很大差异,直接使用原始Unet进行语义分割会存在域偏移等问题,导致模型效果较差,这也可能是早期Unet被圈内学者低估的原因之一。
1.2 优缺点分析
Unet相比其他语义分割模型,仅拥有7M左右的参数量,是作为研究的一个很好的基准(Baseline),其中包含的越级连接和编解码器思想使得模型蕴藏着很大的潜力。然而由于医学影像和自然场景图片存在较大的数据分布变化,直接应用会存在域偏移从而导致模型效果差,同时模型结构不足以应对复杂多变的自然图像分割。
为了解决原始UNet在复杂自然图像分割中能力欠缺的问题,如图2所示,通过记录ResNet等CNN系列网络的下采样模块的位置更换了原始Unet的特征提取器,然后与解码器对应位置对齐,进而复用了原始Unet的U形编解码器结构和横向越级连接,得益于原始Unet的结构优点和ResNet在ImageNet的预训练权重,充分利用了迁移学习和微调的思想,使模型在此基础上获得了很好的效果增益。同时为了避免反卷积上采样模块可能存在的计算资源浪费和性能次优等问题,采用像素重组[3]进行替换,增强了模型的解码器能力,使得模型在恢复分割掩模时产生了更好的效果。
2 本文方法
图2中展示了Dynamic Unet+动态编码器语义分割架构。模型输入是一个RGB的待分割图片,模型输出是一个与输入同尺寸的类别注释掩模图,其中C为类别(Class)数量。其中沿用了Unet[5]的U形编解码器结构和横向连接的基本结构。
2.1 动态编码器
为了增强模型对于复杂多变的自然场景图片编解码器的能力和充分利用迁移学习技术(TransferLearning),如图2所示则对原始的Unet的编码器进行了替换。在本文实验中使用ResNet系列网络进行代替,为了保持U形编解码器结构,将ResNet融入Unet的方式:去掉原始Unet的左半部的编码器部分,记录ResNet每一次下采样的位置然后与右侧的编码器对应位置进行对齐。值得注意的是,对原始ResNet的最后的池化层及其池化之后的所有模块进行了截断,因为不需要最后的几个用来做分类的模块,同时为了进一步增强模型恢复分割细节的能力,将原始图像与解码器对应分辨率的特征图进行了连接与合并(Connectand Concat),相比于原始的Unet,还在输入和输出部分直接进行了越级连接,进一步增强恢复分割细节的能力,为了进一步增强特征解码器的表现能力,使用更高的通道维度,例如1024、768等,并且将所有的上采样模块替换成了像素重组(Pixel Shuffle)模块[3]。
2.2 像素重组上采样技术
邻域常用双线性插值和反卷积进行上采样,由于双线性插值通过直接计算得到上采样图,该过程并没有可学习性,无法使用神经网络的强大学习能力进行效果加持,同时反卷积上采样模块虽然有可学习的参数,在一定程度上增强了模型在上采样过程的可学习性,促进了模型的特征解码和分割结果恢复,然而過多的零值填充使得卷积过程存在大量的计算浪费。Wenzhe Shi等人[3]首次提出像素重组技术并成功应用于图像超分辨率生成,取得了很好的效果,本文创新性地将其应用到了图像语义分割,在帮助模型恢复分割细节和解码特征方面,大大提高计算利用效率的同时,该技术表现出更好的特征解码能力和分割效果,图3展示了典型的反卷积和像素重组技术的计算过程示意图。
2.3 损失函数
损失函数度量了模型的预测和真值标签之间的差距。实验中将图像分割看作是像素级别的分类问题,因此本文使用的损失函数基于的多分类交叉熵损失函数:
3 实验
3.1 实验数据集及评价指标
为了验证本文方法的有效性,通过在PASCALVOC 2012和Camvid数据集上进行了测试,报告的测试均是严格基于对应的验证集并采用原始的训练集进行训练。在PASCAL VOC2012数据集中,除了官方标注,还报告了由第三方提供的含有1万余张标注信息的增强版本数据集上的测试结果,数据集详情如表1所示。
评价指标采用平均交并比(MIOU),即对每一类的预测和真值之间的交并比,然后在所有类别上求和取平均,设共有c + 1个类别(包括空类或背景类),则MIOU计算方式如下公式所示:
3.2 实验设置
实验中采用单张GTX1080Ti显卡进行训练,学习率均采用One Cycle策略,使用Adma优化器,并采用大小1e-2的权重衰减,所使用的ResNet骨干特征提取网络均采用其在ImageNet上的预训练权重以充分利用迁移学习技术,并使用多尺度训练的技巧:在PASCAL VOC 2012和Camvid两个数据上,均先使用224×224的图片进行训练,收敛后在此基础上将图片输入增加到448×448再进行训练,然后再增加到512×512尺寸大小。受限于显存等原因没有继续增加输入图像尺寸,报告的结果均是最后基于512×512进行训练的最终结果。
3.3 实验结果
使用包含1万余张的PASCAL VOC2012数据集训练了Dynamic Unet+ ResNet34模型,采用的验证集与原始的验证集保持一致,与其他模型的对比结果如表2所示:
值得注意的是,受限于实验环境和其他因素的影响,仅仅采用了最高ResNet34作为特征编码器,在面对PASACL VOC2012这种相对复杂的分割任务来说可能是使得性能受限的重要原因之一,但仍然达到了81.8%的MIOU。这对于仅仅以ResNet34作为骨干网络的模型来说已经相当可观。
而且Dynamic UNet+在Camvid数据集上取得了非常具有竞争力结果。模型表现以及与SOTA模型的对比如表3 所示。为了平衡模型大小和精度,基于ResNet34骨干网络进行了实现,笔者的模型在Camvid数据集上取得了非常好的效果,在参数量保持较低的水平的情况下仍然保持了较高的分割精度。
3.4 消融实验
本节报告了Dynamic UNet+模型在PASCAL VOC2012数据集上相对于基准模型UNet的精度变化和对比情况,同时探究了不同的编码器嵌入和编码器是否预训练对模型效果的影响,结果如表4所示。
可以看到,相对于基准模型在PASCAL VOC 2012数据集上只取得了16%的MIOU值,本文的DynamicUNet+在将ResNet系列网络嵌入后,模型效果大幅提升,显著增强了模型处理复杂场景的能力,且呈现出随着嵌入的编码器网络深度的增加,模型精度呈上升趋势,同时在使用相同的特征编码器的情况下,使用ImageNet上的预训练权重会显著提升Dynamic UNet+的模型效果,这是本文模型能保持相对较低参数量的情况下仍能获得如此具有竞争力的重要原因之一。
4 实验人像分割应用
4.1 实验设置
为了进一步验证模型的可行性,笔者测试了模型在人像分割方面的应用能力。实验采用AutomaticPortrait Matting[16]和Aisegment 人像分割数据集,分别包含2 000张图片和34 427张统一分辨率的高质量的半身人像图片。为了进一步减少参数量,实验中选用了ResNet18作为特征提取的骨干網络,在保证人像分割效果的同时,进一步降低了模型参数量,模型配置及训练信息如表5所示:
根据Smith L等人的工作,采用One Cycle学习率策略。同时采样与本文3.2节所述相同的参数设置和多尺度训练方法,使用Adma优化器训练仅15个Ep?och模型基本收敛。
4.2 模型效果
为了测试模型的泛化能力,采用更贴近实际应用场景的图片进行测试,笔者从互联网上随机选取了模型从未见过的肖像图片进行分割,分割结果如图4所示,其中最左边是模型输入的原始RGB图片,中间是模型生成的掩模,最右边一列是对掩模图进行后处理制作的背景编辑应用Demo,用于模拟真实的自动证件照制作场景。
可以看到,基于ResNet18实现的Dynamic Unet+在处理简单背景的肖像图几乎达到超越人类水平的结果,在较为复杂的背景下也依然保持较高水平。
5 结束语
UNet作为一个轻量灵活的医学影像分割架构早期并没有受到机器学习圈内学者的过多关注,并且少有工作将Unet迁移到复杂场景图像语义分割。在本文中笔者充分利用的Unet的U形编解码结构和横向越级连接,同时针对Unet在复杂语义和环境场景下表现力欠缺等问题对其进行了多方面的改进,提出了Dynamic Unet+,并举例如何将ResNet嵌入到UNet模型中,该模型非常灵活,几乎支持多种图像分类或其他网络的嵌入,例如使用Efficient Net将进一步减少模型的参数量,提高速度。使用这些带有预训练的模型作为骨干网络,可以充分利用例如迁移学习、微调(Fine Tuning)等技术并从中受益。笔者的DynamicUnet+模型在PSCAL VOC2012、Camvid等数据集上取得了不错的效果,并且拥有相对更低的参数量和更快速度,促进了语义分割在实际应用上的落地。同时,通过对模型在人像分割应用方面的初步测试,以较小的参数量和相当的精度取得了很好的实际应用效果,结果充分验证了本文的Dynamic Unet+算法的可行性和实用性。
猜你喜欢
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
