
上市公司财务预警研究
——基于逐步回归和Logistic 回归
2023-06-11 04:03区梦怡广西经贸职业技术学院广西南宁530000
商业会计 2023年10期
区梦怡(广西经贸职业技术学院 广西南宁 530000)
一、引言
由于市场上的信息无法精确预测,而企业的融资方式多样,经营环境也越来越复杂,因此财务风险贯穿于每个企业发展、成长、成熟到衰退的全过程,企业的经营也总是与财务风险相伴而生。在当前激烈竞争的市场经济环境中,每个企业在其生命周期的不同阶段都会面临着不同的风险,存在着很大的不确定性与可能性。构建财务预警模型可以及时监督与预测企业的经营状况,帮助企业利益相关者做出决策。对于企业内部经营管理者来说,企业财务预警模型的构建能够帮助其及时发现企业所面临的风险并采取相应措施来降低风险因素给企业带来的负面影响,而对于企业外部投资者来说,借助财务预警模型来了解企业的经营状况,能够促进投资者的资金优化配置和资本市场效率的提升。
对企业存在的财务风险问题一定要及时发现,并采取一定的措施来减少财务风险的发生,以降低企业财务危机出现的概率。财务危机具有繁杂性、多样性、可控性及可预测性等特征,企业应实时监测并定期检查其运行情况,以及时发现运行中所面临的风险并制定相应风险管理方案以规避财务危机。财务预警是指企业财务人员通过长时间观察设定对于企业未来经营状况有预测能力的指标变动,并通过数据统计与分析指标变动来科学、合理地评估企业的经营状况。财务预警能够有效地预测企业可能面临的运营情况,并及时发现日常运营中存在的财务风险问题,一旦发现问题,企业经营管理者应及时采取措施,以免财务风险不断恶化从而使企业陷入财务危机之中,以保障企业能够正常、持续地发展下去。企业财务预警通过统计与分析企业的经营数据,构建财务预警模型,可以预测财务危机发生的可能性。财务预警模型是企业能够正常和持续运营的重要工具,对于维护企业的正常运营来说是一个重要保证。
二、文献综述
国外学者Beaver(1966)将财务危机界定为破产、优先股股息拖欠、银行透支、债券无法偿还等问题。Carmichael(1972)将财务危机界定为企业发生严重资产折现现象,而这一现象取决于企业经营方式或者存在形态的改变。Altman(1968)将学术界关于财务危机的定义做了全面阐述,认为财务危机表现为公司经营失败、公司没有偿付能力、公司违约、公司破产。在Ross(2000)看来,财务危机表现为公司在清算之后仍然不能偿付债权人债务、公司或者债权人到法院要求公司破产、公司不能按时履行义务、还本付息以及公司账面净资产为负、资不抵债等。Ohlson(1980)利用对样本数据需求宽松的Logistic 回归方法来预测企业破产概率。Beckmann D.,Menkhoff L.,Sawischlewski K.(2006)进一步改进了Logistic 模型,并通过对模型判断处于财务危机中的公司的研究来推动财务预警有关研究。
国内学者在国外学术界关于财务危机研究的基础上,启动了关于我国上市公司财务危机问题的探讨。我国的财务危机预测研究对象多集中于上市公司,因此通常认定发生财务危机者为财务状况异常且被“特殊处理”的公司。“异常状况”包括“财务状况异常”与“其他状况异常”。其中,由于“其他状况异常”受到特殊处理存在较大不确定性,很难从财务角度做出有效预测,而对于“财务状况异常”的定义与普遍认为企业财务状况不良的结论是一致的,所以国内学者一般将陷入财务危机的企业定义为因财务状况异常而被特别处理。王春峰等(1998)在研究中论证了使用Logistic 模型进行财务预警的结果比通过线性回归进行财务预警的结果准确,樊林堉(2018)改进了Logistic模型,提高了预测精准度。Logistic 模型对假设条件没有苛刻要求,其样本数据不需要服从标准正态分布的假设条件,克服了多元线性判定模型受统计假设约束的局限性,胡胜等(2018)基于Logistic 模型对房地产公司进行了风险研究,陈欣欣和郭洪涛(2022)基于Logistic 回归对农林牧渔业进行了风险与预警研究,贺平等(2021)基于Logistic模型对我国股票市场进行了预测,均取得了较好结果,说明Logistic 模型对上市公司财务预警的准确性较高。因此Logistic 回归在财务预警模型构建中得到了较为广泛的运用。然而,Logistic 模型具有多重共线性敏感性,若所选指标变量间具有多重共线性,将严重影响Logistic 模型在企业分类中的预测效果。
三、研究设计
(一)样本选择与数据来源
本文选取2009—2021 年我国A 股上市公司的数据为初选样本,借鉴已有成果,以ST 公司作为财务危机样本,其他上市公司作为未发生财务危机样本。由于ST 公司样本数量远小于正常经营的公司(非ST 公司)样本数量,故以ST 公司作为样本选择基础,剔除指标披露较少的公司后,真正有效的ST 公司样本量为500 个,同时按照1∶1 的比例匹配资产规模相似的500 个非ST 公司作为匹配样本。分别将ST 公司样本和非ST 公司样本按照7∶3 的比例分为训练集和测试集,训练集共700 个样本,其中ST 公司样本350 个、非ST 公司样本350 个,测试集共300 个样本,其中ST 公司样本150 个、非ST 公司样本150 个。本文所使用的资料均为上市公司公开披露的资料。
(二)指标初步筛选
本文在筛选指标时,通过查阅以往研究文献,选取了每股指标、盈利能力指标、收益质量指标、现金流量指标、资本结构指标、偿债能力指标和营运能力指标等财务指标,并结合企业基本信息、股东持股比例、企业人员的薪资和学历构成、收入成本构成和往来款构成、审计意见类别等企业非财务指标,设置了60 个指标构建了上市公司财务预警指标体系,如表1 所示。
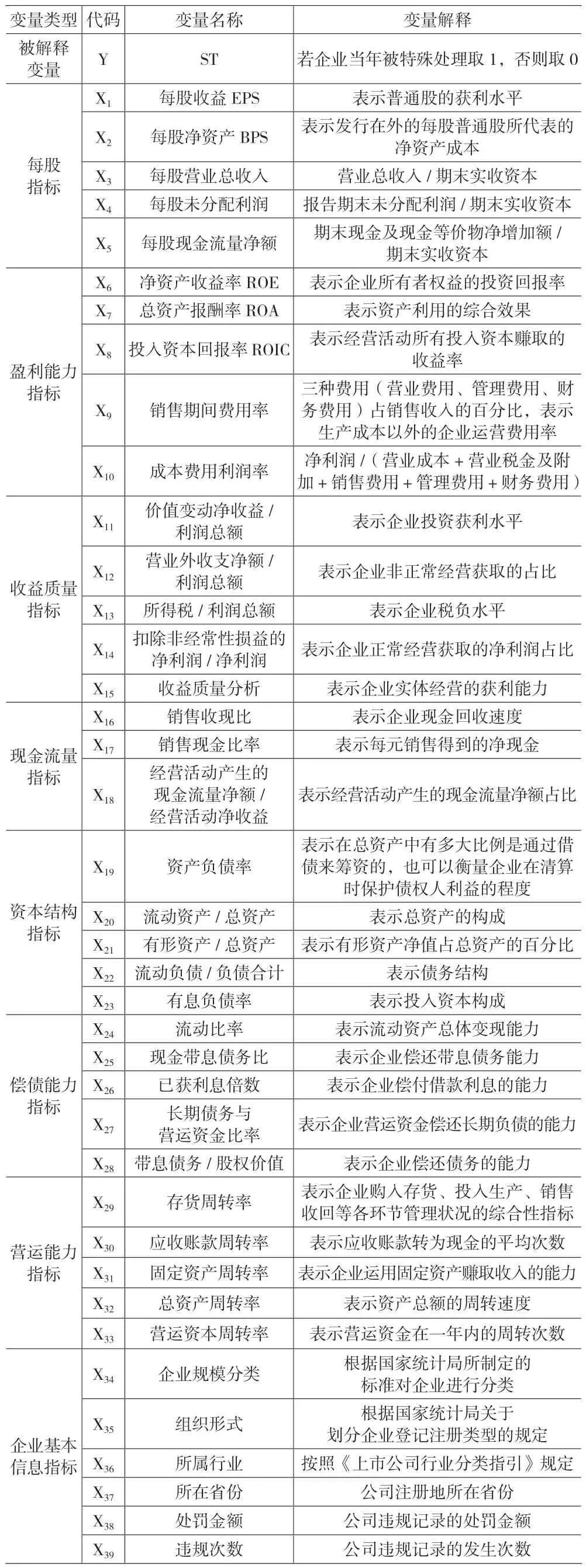
表1 初步预警指标列表
四、实证结果与分析
(一)逐步回归法筛选指标
当学者研究企业是否陷入财务危机时,总要尽可能地搜集有关信息,除了会造成搜集成本的大幅增加外,还会给模型建构带来困难,同时也造成了多重共线性过大,反而使得模型估算失真或者很难精确估算。因此所采集的自变量中什么需要导入模型、什么不该导入模型,以及自变量导入模型后会对预测准确性产生改善或降低预测准确性等问题长期困扰研究人员。尽管人为地筛选自变量可以部分地解决自变量过多的情况,但人为筛选存在一定的主观性,用人为筛选指标来预测,其结论与事实可能不相符。
本文通过逐步回归法筛选指标。第一步是分别对p 个候选自变量(X1,X2,…,XP)拟合它们与因变量Y 的简单线性回归模型,共有p 个,考察其中有统计学意义的k个简单线性回归模型(k ≤p),并首先将p 值最小的模型所对应自变量Xi引入模型;第二步是在已经引入模型的Xi基础上再分别拟合引入模型外的p-1 个自变量的线性回归模型,自变量组合分别为X1,…Xi-1,Xi+1,…,XP等p-1个自变量中p 值最小且有统计学意义的自变量引入Xi模型;第三步是考察第一步引入模型的自变量Xi是否仍具有统计学意义,如果没有则将其剔除,之后再拟合包含第二步引入模型的自变量Xj与除Xi之外的p-2 个自变量的模型,将其中p 值最小且具有统计学意义的自变量引入模型,如果剩余的自变量没有统计学意义,则运算过程结束,如果第一步引入模型的自变量Xi有统计学意义,则进行下一步;第四步是在模型引入Xi和Xj的基础上继续拟合,将其他的p-2 个自变量引入模型,考察其是否具有统计学意义,引入p 值最小且具有统计学意义的自变量,如果剩余变量均无统计学意义,则运算过程结束。如此反复进行,直至模型外的自变量均无统计学意义,而模型内的自变量均有统计学意义。综上,逐步回归法在向模型引入一个新变量后均考察原来在模型中的自变量是否还有统计学意义,是否可以剔除,通过该方法筛选指标不仅能解决指标的多重共线性问题,还能简化模型进行预测分析,提高预测效率。
本文通过SPSS 将经过初筛的60 项财务指标及非财务指标代入逐步回归法筛选自变量,为了辨别ST 公司和非ST 公司,当候选变量中F 值小于或等于0.050 时,引入相关变量。在引入方程的变量中F 值大于或等于0.100 时,则剔除该变量。筛选出在ST 公司和非ST 公司中存在显著性差异的指标,结果如表2 所示。通过逐步回归法筛选出19 个指标,并对筛选出来的19 项自变量进行Logistic 回归,建立上市公司财务预警模型。
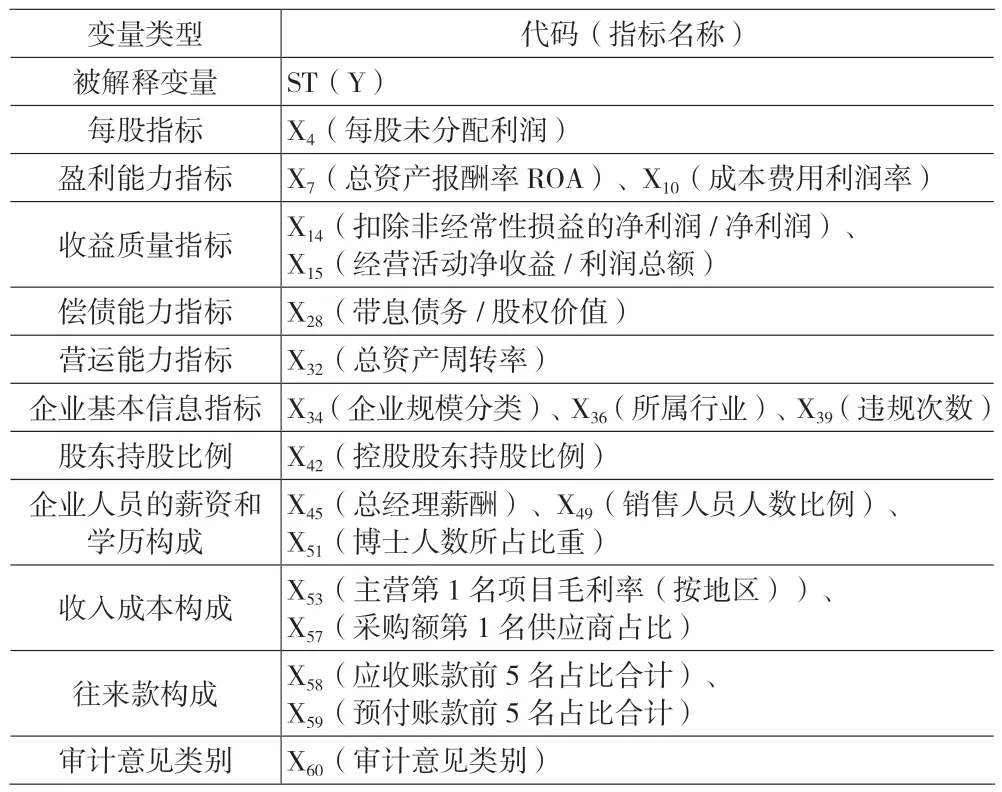
表2 经筛选后的预警指标列表
(二)构建Logistic 回归模型
从数学上讲Logistic 回归系数与多元回归系数的解释没有区别,表示的是自变量X 改变一个单位时LogitP 的平均改变量,但是因为比值的自然对数是Logit 变换的结果,这就使得Logistic 回归中的系数与OR 有着直接的变换关系,使得Logistic 回归系数更接近于实际情况,该模型也得到了更广泛的应用。
Logistic 模型是回归分析的一种应用模型。随着计算机技术的发展,该模型在经济领域中开始得到广泛应用。利用Logistic 模型开展财务风险预警研究的原因在于:第一,Logistic 模型的因变量Y 和自变量X 是线性的;第二,Logistic 模型的自变量X 能够不服从正态分布或两组样本的等协方差,更符合企业各项指标变量的实际情况;第三,Logistic 模型具有更高的预测精确度。因此,通过Logistic 模型能够比较准确地判断出企业出现财务风险的可能性,并对其未来财务状况进行预测,可以表示为P=eb+aX/(1+eb+aX),公式中b 是常数,a 是X 的系数。由于通过Logistic 模型构建的财务预警指标体系中,自变量X 不是一个而是多个,所以Logistic 模型的公式表示为:P=eF(X)/(1+eF(X)),公式中F(X)=b+a1X1+…+anXn(n为自变量的个数)。
Logistic 模型的建立主要解决了在[0,1]上的回归。上市公司有两种状态:一种是财务正常(非ST 样本),另一种是陷入财务危机(ST 样本)。本文以上市公司是否被ST 作为因变量,即:非ST 样本Y=0,ST 样本Y=1。Logistic 模型通过对解释变量进行回归分析,得到企业预测到ST 结果的概率出现比例,再依据出现概率的大小来判断其是否将作为ST 样本进行研究。先将60 个初筛指标引入Logistic 回归,构建财务预警模型,命名为模型1,再将通过逐步回归法筛选出的指标引入Logistic 回归,构建财务预警模型,命名为模型2。只经过初筛构建的财务预警模型和经过逐步回归法筛选后的指标构建的模型检验结果分类如表3 所示。

表3 Logistic 回归财务预警模型检验结果分类
分别计算出模型1 和模型2 对非ST 样本和ST 样本测试集总体样本的预测精度,不同财务预警模型预测精度如表4 所示。
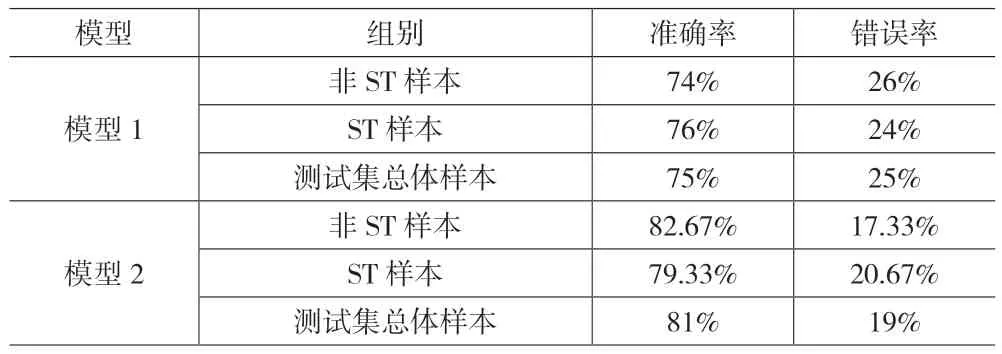
表4 不同财务预警模型预测精度
通过表3 和表4 可以看出模型1 对非ST 样本预测的准确率为74%,对ST 样本预测的准确率为76%,对总体样本预测的准确率为75%;模型2 对非ST 样本预测的准确率为82.67%,对ST 样本预测的准确率为79.33%,对总体样本预测的准确率为81%。可以看出通过逐步回归法对指标进行筛选后,通过同样的模型进行财务预警,对于非ST样本,预测精度提高了8.67%,对于ST 样本,预测精度提高了3.33%,整体提高了6%。通过上述研究可以看出,通过逐步回归法筛选指标后,财务预警模型预测精度更高,预测结果更好。所以通过逐步回归法筛选指标构建的财务预警模型能够更好地对企业的经营状况进行预测,为企业内外部利益相关者提供更好的决策支持。
五、结论
市场经济环境下,企业一般都存在财务风险,财务预警是一种有效的财务风险监测手段,通过建立财务预警模型来正确地预测分类企业的经营状况并提高财务预警精度,无论是从理论研究上还是在实际应用中都有着十分重要的作用。本文选取2009—2021 年我国A 股上市公司的数据共计1 000 个样本作为实证研究对象,联合运用逐步回归法和Logistic 模型构建了上市公司财务预警模型,在每股指标、盈利能力指标、收益质量指标、现金流量指标、资本结构指标、偿债能力指标和营运能力指标等财务指标,企业基本信息、股东持股比例、企业人员的薪资和学历构成、收入成本构成、往来款构成和审计意见类别等非财务指标中选取了60 个指标构建财务预警模型,并采用逐步回归法选取了19 个指标,对上市公司进行财务预警研究。研究结果表明:在没有采用逐步回归法筛选指标之前,通过初筛的60 个指标结合Logistic 回归构建财务预警模型的整体预测精度为75%,而通过逐步回归法选取了19 个指标结合Logistic回归构建财务预警模型整体预测精度为81%,整体预测精度提升了6%。
本文的贡献主要体现在,不仅在初筛指标选择方面对已有财务预警指标体系进行了改进和充实,而且采用逐步回归法对指标进行了进一步甄别,较好地解决了指标的多重共线性问题,提高了财务预警模型的总体预测精度。此外,在财务预警方法上联合运用逐步回归法和Logistic 回归进行财务预警的实证研究,研究内容有所创新。
本文仅采用逐步回归、Logistic 回归等方法来构造财务预警模型,并没有考虑其他财务预警模型对预测结果的影响,在以后的研究中可以将逐步回归法结合到不同的模型中,以提高财务预警模型的总体预测精度。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2019年12期)2019-08-13
安顺学院学报(2019年2期)2019-07-04
知识经济·中国直销(2018年8期)2018-08-23
现代园艺(2017年22期)2018-01-19
商周刊(2017年6期)2017-08-22
统计与决策(2017年2期)2017-03-20
数学学习与研究(2017年3期)2017-03-09
通化师范学院学报(2016年11期)2017-01-15
中国老区建设(2016年1期)2016-02-28
