
一种用于SLAM 的IMU 状态优化加速器设计
2023-06-10 03:21:44刘强刘威壮俞波刘少山
北京航空航天大学学报 2023年5期
刘强,刘威壮,俞波,刘少山
(1.天津大学 微电子学院,天津 300072;2.天津市成像与感知微电子技术重点实验室,天津 300072;3.深圳普思英察科技有限公司,深圳 518000)
同步定 位与建 图(simultaneous localization and mapping,SLAM)是当前实现移动机器人自主定位与环境感知的关键技术[1]。为了感知复杂的环境,SLAM 系统往往需要融合内感受型传感器(如IMU)和外感受型传感器(如相机、GPS)[2]。惯性测量单位(inertial measurement unit,IMU)是加速度计和陀螺仪的组合,可获得物体自身的加速度值和角速度值,从而用来估计移动物体的位置、方向和速度,并且具有不受外界环境影响的特点。SLAM 系统可以在隧道(GPS 信息丢失)和地下黑暗(视觉信息消失)环境中依赖IMU 信息进行定位[3]。
SLAM 系统包括2 个主要组件:前端和后端。前端将传感器数据抽象为适合优化的模型,后端对前端产生的抽象数据进行推理,优化移动的轨迹[4]。后端又分为滤波和非线性优化2 种实现方法。与滤波方法相比,非线性优化方法可以实现更精确的状态估计,已成为目前研究的重点[5]。非线性优化方法使用由系统状态得出的理论值和观测数据之间的误差项来构建成本函数,通过最小化该成本函数的值来优化系统状态,通常使用的算法有高斯牛顿(Gauss-Newton)算法和列文伯格-马夸尔特(Levenberg-Marquardt,LM)算法等。
虽然基于非线性优化的后端方法可以提升系统的定位精度和鲁棒性,但是高计算量和数据复杂性限制了其在功率受限、实时性要求高情况下的应用。现 场 可 编 程 门 阵 列(field programmable gate array,FPGA)具有功耗低、适合大规模并行计算及可重配置的特点。近年来,研究者们提出了多个基于FPGA 的SLAM 后端加速器。2020 年,天津大学在嵌入式FPGA-SoC 上实现了软硬件协同的SLAM后端硬件加速器[6],同时提出了共视优化技术和硬件友好的微分方法。同年,上海交通大学提出了基于FPGA 的全硬件SLAM 后端加速器[7]。佐治亚理工学院提出将SLAM 中稀疏矩阵运算转换为固定大小的密集矩阵运算的方法,并在FPGA 上实现了低功耗的SLAM 后端加速器[8]。然而,这些关于SLAM 后端加速器的研究都仅考虑了视觉信息,没有涉及对IMU 观测信息的加速处理。随着IMU在SLAM 中的应用越来越广泛,研究IMU 信息的加速处理变得很有必要。
本文在FPGA 上设计了用于IMU 状态优化的SLAM 后端加速器。加速器采用LM 算法,为算法中的雅可比矩阵计算、海森矩阵计算和求解线性方程组等步骤定制硬件计算架构,利用算法流程和数据的特点实现复用。同时,充分利用IMU 状态优化问题中特有的稀疏特性,简化矩阵计算和存储。对于计算量最大的求解线性方程组的硬件,采用电路规模可配置的设计,实现电路性能、资源消耗和功耗的折中。
1 算法原理
1.1 优化问题描述
IMU 状态由位姿、速度和偏置3 个参数定义。在 时 刻i,IMU 状 态 可 表 示 为xi=(pi,qi,vi,bai,bgi)。其中,(pi,qi)表 示位置和姿态,pi∈R3为平移向量,表示当前IMU 相对于坐标原点的位置,四元数qi表示IMU 的姿态,即相对于参考坐标系的旋转;vi∈R3为 IMU 三 个 轴 上 的 速 度;bai,bgi∈R3分 别 为IMU 三个轴的加速度偏置和绕三个轴旋转的角速度偏置。
IMU 的测量频率通常为100~3 000 Hz。在基于优化的方法中,如果为每个IMU 测量定义一个新状态,系统将由于计算量过大而无法处理[9]。因此,需要减少系统中优化的状态量。图1 为IMU 积分示意图。通过对一段时间 ∆t内的惯性测量进行积分,得出ti和ti+∆t之间IMU 测量的积分值,即将∆t内的多个惯性测量值合并为一个相对运动约束,从而定义系统在ti和ti+∆t时刻的状态。IMU 测量的积分由SLAM 前端完成,作为后端优化的输入。IMU 测量的积分值通常使用欧拉积分的方法在离散时间上积分得出[10]。
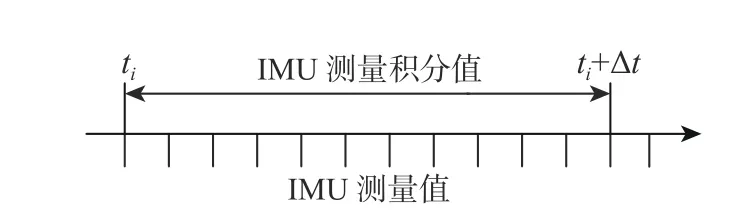
图1 IMU 积分示意图Fig.1 Schematic diagram of IMU integration
将时间段ti~tj上的IMU 测量积分值定义为yi,j,yi,j=(∆p,∆q,∆v)分别表示平移、旋转和速度的积分值。同时,利用IMU 在ti和tj时刻的状态xi和xj,可以计算出积分的理论值yˆi,j。但由于测量噪声的存在,yˆi,j与yi,j之间存在误差,误差的值可表示为ri,j(xi,xj,yi,j)=yˆi,j−yi,j。式(1)展示了IMU 误差的具体计算方法,计算结果是15 维的向量。
式中:“⊗”表示四元数的乘积运算;Ri为四元数qi的旋转矩阵形式;G为重力加速度。

1.2 优化问题求解
式(2)是一个复杂的非线性最小二乘问题,通常采用迭代方法求解该最小二乘问题[11],即通过不断更新优化的变量使F(X)的值下降。由于LM 算法实现容易,收敛快速[12],广泛应用在SLAM 后端中求解该问题。
算法1 描述了LM 算法流程。该算法输入的是待优化的初始状态X0和积分值Y0。算法输出的是使成本函数(2)最小的状态变量X+。在算法描述中,为了书写的简洁,使用r(X,Y0)表示系统中所有的误差项,即N个待优化的状态和N−1 个积分值形成的N−1 个误差项。同样,r′(X,Y0)表示所有误差项对系统整体状态的导数。LM 算法是迭代算法,迭代停止的条件为:①达到最大迭代次数kmax;②算法1 中 第6 行 梯 度g的 无 穷 范 数 //g//∞<ε1;③第9 行中X的更新变化小于 ε2。kmax和 ε1、ε2及初始信任域半径 µ0均是算法的经验参数。

算法首先计算初始状态的误差和误差对状态变量的导数即雅可比矩阵J。在每次的迭代中,根据当前的雅可比矩阵J和误差 ϵ计算海森矩阵H和梯度g。海森矩阵原为误差对状态变量的二阶导数,LM 算法中使用雅可比矩阵的转置JT和J的乘积来近似。然后通过求解线性方程(H+µI)δX=g来计算X的更新步长 δX,该线性方程称为最小二乘的正规方程。利用正规方程的解更新状态得到Xnew,计算Xnew对应的成本函数,并判断是否满足成本函数减小,若不满足则需要扩大信任域半径重新寻找迭代步长 δX,若满足则将状态更新为Xnew,并重新计算对应的误差和雅可比矩阵进行下一次迭代。
求解正规方程是算法中计算复杂度最高的步骤,正规方程中系数矩阵H+µI是对称正定矩阵[13],为了快速稳定地求解该方程,通常使用乔可斯基分解算法进行求解。乔可斯基分解算法将对称正定矩阵S分解成下三角矩阵L和上三角矩阵LT,使得S=LLT,算法2 列出了具体的计算流程。


2 加速器设计和优化
2.1 整体架构
加速器采用全硬件的定制化电路,基于FPGA平台实现。根据算法流程,本文提出了如图2 所示的硬件架构。误差、雅可比和成本计算单元(error,Jacobian and cost calculation unit,EJCC)可工作在误差、雅可比计算(error and Jacobian calculation,EJC)模式和成本计算(cost calculation,CC)模式。EJC 模式计算IMU 误差项和误差对状态的导数J。海森矩 阵 和 梯 度 计 算 单 元(Hessian matrix and gradient calculation unit,HGC)计算海森矩阵JTJ和梯度JTϵ,并将其存储到片上存储中。线性方程组求解单元(linear equation solving unit,LES)使用乔可斯基分解算法求解正规方程,解得状态的增量 δX。EJCC 工作在CC 模式计算更新后的成本F(Xnew)。状态更新和信任域调整单元判断是否满足F(Xnew)小 于F(X):若满足,则将Xnew输入到EJCC 中进行下一次迭代,并缩小 µ;若不满足,则增大 µ并重新求解正规方程。
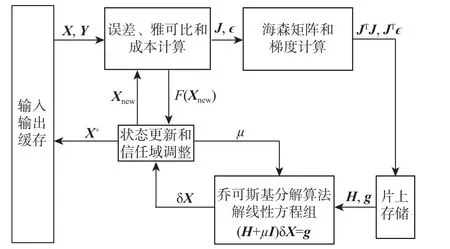
图2 硬件设计架构Fig.2 Hardware design architecture
本文通过分析算法流程和数据的特点进行整体架构、电路实现及存储的优化。
利用算法中的相同计算实现电路和数据复用。电路复用体现在EJC 和CC 运算使用EJCC 电路的不同模式实现,此外在2 种模式下实现流水线的平衡。数据复用体现在使用误差、雅可比通用计算模块计算通用部分,计算结果同时用于误差和雅可比的计算,实现数据的复用,提高加速器的效率。
利用雅可比矩阵和海森矩阵的稀疏性进行计算和存储的优化。HGC 电路利用雅可比矩阵的稀疏性实现JTJ的运算简化,片上存储利用海森矩阵的稀疏特点实现存储的压缩。
线性方程组求解包含矩阵分解和三角线性方程求解等步骤,是电路中延时最长的运算,平均占系统运算总时间的82.4%。本文设计了矩阵分解单元的数量可配置的LES 电路,该配置参数对加速器的性能和资源消耗影响明显,通过调整该参数可实现加速器性能、资源使用和功耗的折中。
2.2 电路和数据的复用
复用体现在EJCC 模块,首先介绍误差和雅可比的计算方法。误差的计算如式(1)所示,对于N个状态,需计算N−1 个误差项,每个误差项ri,j(xi,xj,yi,j)是15 维的IMU 误差向量。雅可比矩阵J是N−1 个误差项对状态变量X的偏导数。对于误差项ri,j,与其相关的优化变量是xi、xj(30 维),因此误差项ri,j对状态X的偏导数是15×30 的雅可比矩阵,记为Ji,j。基于Forster 等[14]提出的求导方法和具体的Ji,j的解析形式,本文根据误差项和状态的物理含义将Ji,j表示成如图3 所示的分块矩阵形式。
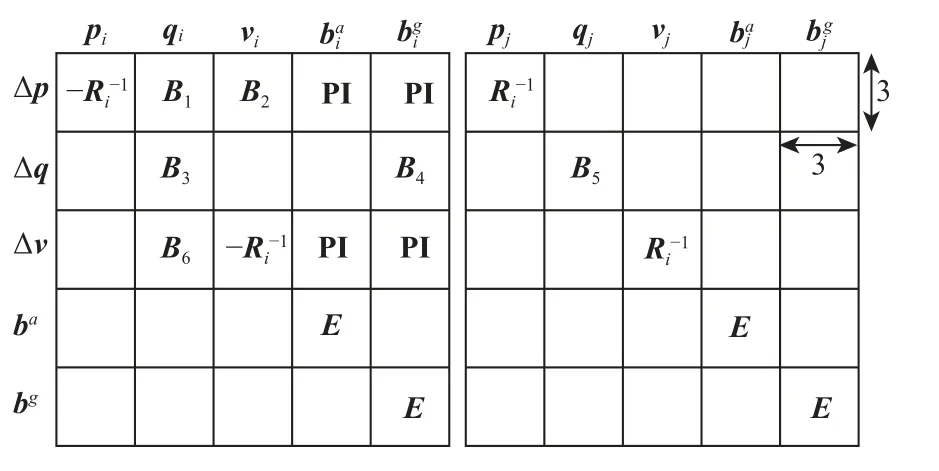
图3 误差函数对状态量的雅可比矩阵Fig.3 Jacobian matrix of error function versus states
图3 中,每个矩阵分块表示对应的误差分量对状态分量的导数,如B1表示误差项中平移误差对旋转状态的导数。PI 由前端提供,E为单位矩阵,Ri为qi的旋转矩阵形式。B1~B6根据导数的解析式计算,空白部分的值是0。
LM 算法迭代过程中,需要先后计算成本F(X)和误差、雅可比,如算法1 的第11 行和13 行。考虑到成本是误差向量的范数平方和,本文利用EJCC的2 种工作模式实现成本和误差雅可比的计算。EJCC 的电路架构如图4 上部所示。该电路分为3 个模块,模块之间的数据交互通过Ping-Pong RAM 实现。EJCC 可工作在如图4 所示的EJC 和CC 这2 种模式。模式1 用于计算误差和雅可比,将成本计算单元关闭,分为2 个流水阶段,阶段1 的2 个电路模块分别完成误差、雅可比通用项的计算和雅可比矩阵分块的计算;阶段2 完成误差项的计算,并将雅可比矩阵写入到片上存储。模式2 无需计算雅可比,因此关闭雅可比计算和雅可比写入模块,开启成本计算模块,分成3 个流水阶段,阶段1 和阶段2 计算误差,阶段3 求误差的平方和得到成本。
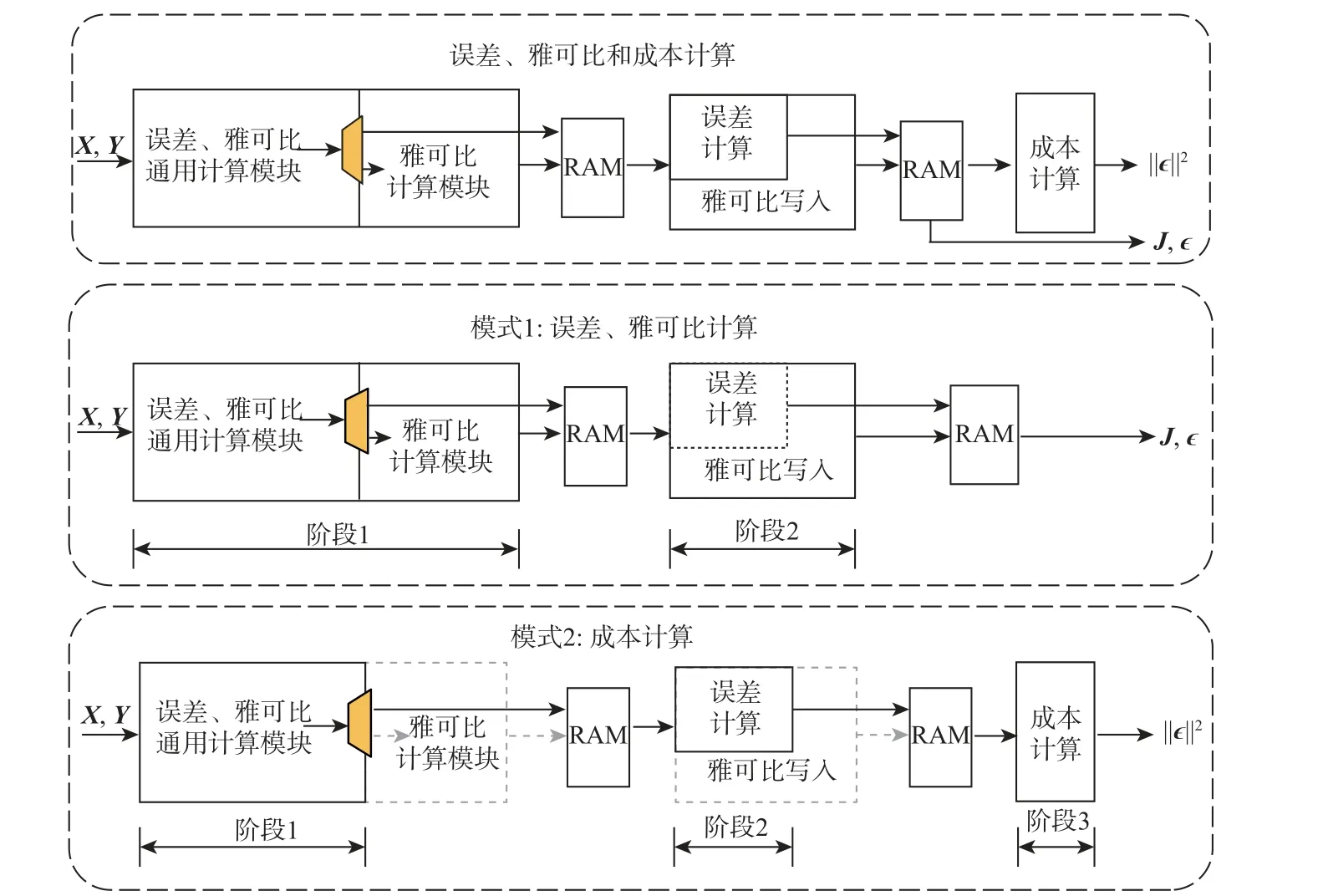
图4 误差、雅可比和成本计算电路及配置模式Fig.4 Error, Jacobian and cost calculation circuit and its configuration modes
EJCC 实现2 种模式下流水线的平衡,使得2 种模式均可以高效运行。雅可比写入模块的延时最长,将其作为一个单独的流水阶段。在EJC 模式中,将误差、雅可比通用计算模块和雅可比计算模块划分为阶段1,使得两阶段的延时近似相等。误差计算延时和误差、雅可比通用计算的延时相等,将误差计算划分到阶段2。这样在关闭了雅可比相关计算模块的CC 模式下,阶段1 和阶段2 延时相同,成本计算模块通过调节乘累加单元的数目与前2 个阶段平衡,CC 模式实现流水线的平衡。
误差和雅可比的计算中存在相同的中间值,本文据此重构了误差、雅可比的计算流程。图5 为EJCC 阶段1 电路,在硬件上实现了误差、雅可比通用计算模块计算共同的中间值,其中QM 表示四元数的乘法运算。EJCC 阶段1 电路分为3 个并行部分,同时计算不同的中间值和图3 中雅可比矩阵的分块。
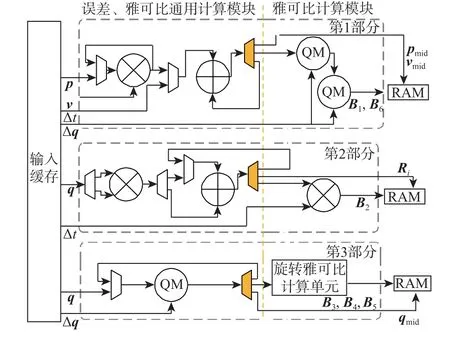
图5 误差、雅可比和成本计算阶段1 电路Fig.5 Stage one of error, Jacobian and cost calculation circuit
第1 部分的电路处理误差、雅可比中与Δp和Δv相关部分,计算平移中间值 (pj−pi−vi∆t+0.5G∆t2)、速度中间值 (vj−vi+G∆t)及雅可比的B1和B6分块;第2 部分电路计算误差和雅可比中都用到的旋转矩阵Ri,同时计算Ri与Δt的乘积即雅可比的B2分块;第3 部分计算与Δq相关的导数和误差,误差、雅可比通用计算模块计算中间值 ∆q⊗(qi⊗qj),旋转雅可比计算单元计算B3~B5分块。中间值不仅直接用于计算雅可比,还保存下来用于下一阶段的误差计算。该电路实现了误差、雅可比的数据复用,避免重复计算,提高了计算的效率。
2.3 利用稀疏性优化计算和存储
HGC 单元计算海森矩阵JTJ,本文利用雅可比矩阵的稀疏结构重新划分矩阵分块来减少计算量。定义图3 矩阵左上角前9 行、前24 列的子矩阵为Λ,通过合并单位矩阵和0 矩阵将Ji,j写成式(3)的分块形式,其中E6表示6 维的单位矩阵。

海森矩阵的维度是15N,包含(15N)2个元素,直接存储需要消耗大量的存储资源。本文利用算法特点、海森矩阵的性质和矩阵块的稀疏性,分3 个步骤压缩海森矩阵的存储,图6 以5 个优化变量为例进行说明。首先,海森矩阵中的值表示状态的约束关系,IMU 误差仅约束相邻的状态,因此不相邻的状态如x1和x3在海森矩阵中的矩阵块是零。其次,海森矩阵是对称矩阵,仅存储下三角矩阵可以减少近一半的存储。最后,利用每一个矩阵分块的细粒度的稀疏特性,去除矩阵结构中固定位置的0 元素的存储。图7 展示了具有20 和80 个优化变量的海森矩阵的压缩效果,经过3 个步骤的存储压缩后,可以分别节约21.1 倍和82.8 倍的存储资源。
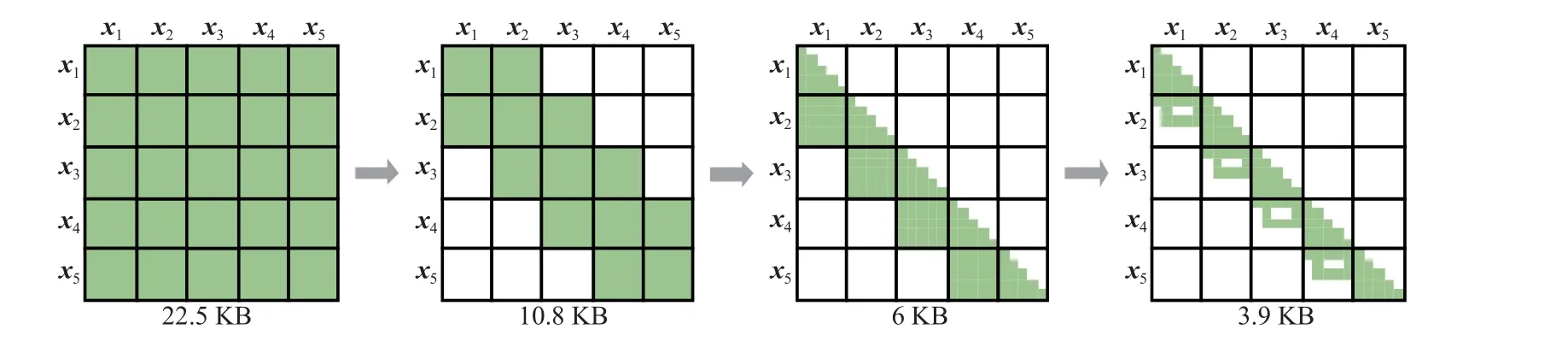
图6 H 矩阵的存储优化Fig.6 Storage optimization of H matrix
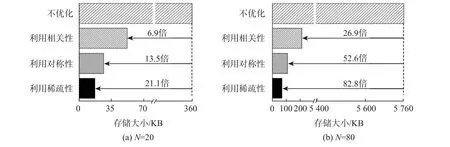
图7 在20 个和80 个优化状态下的存储优化效果Fig.7 Storage optimization results with 20 and 80 optimization states
2.4 适用多场景要求的可配置设计
LES 的电路架构如图8 所示。首先乔可斯基分解模块将系数矩阵分解为下三角矩阵L,然后通过矩阵转置模块得到LT。最后利用三角矩阵线性方程求解单元先后求解Lz=g和LTδX=z来求得原方程的解 δX。
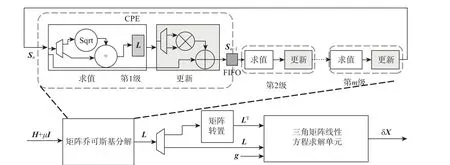
图8 乔可斯基分解算法线性方程组求解电路Fig.8 Cholesky decomposition linear equation solving circuit
乔可斯基分解是求解线性方程组中计算复杂度最高的步骤。该电路采用可配置的设计来实现性能、功耗和资源使用的灵活可变,满足不同的场景约束。本文设计的乔可斯基分解电路如图8 上部所示,其级联了多个乔可斯基分解基本单元(Cholesky process element,CPE)。CPE 包括2 个电路模块:求值和更新。求值模块对应算法2 的第2 行和第4 行,计算下三角矩阵L第i列的值,并存储到求值模块中的片上存储器中。更新模块对应算法2 的第6 行,更新被分解的矩阵S的第i+1~n列,将更新结果存储到FIFO 中提供给下一级的CPE 读取。
图9 以配置4 个CPE 为例,展示了各级CPE 的计算时序。第1 级CPE 的求值模块计算出L的第1 列L1,更新模块更新矩阵S的第2~n列,作为第2 级CPE 的输入。第1 级CPE 更新的结果开始写入到第1 级和第2 级之间的FIFO 中后第2 级CPE即可开始求值运算。同样,第2 级到第4 级CPE 依次计算L的2 到4 列并不断更新S。待第1 级CPE更新完成后,开始第2 轮计算。首先使用第1 级CPE的求值模块得到L的第5 列L5,第1 级输出更新的运算结果后第2 级CPE 求得L的第6 列L6。第3、4 级CPE 在上一级更新开始后计算L7 和L8。每一轮求得L的4 列,直到求得完整的L计算结束。
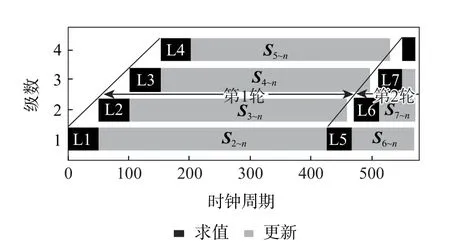
图9 乔可斯基分解基本单元的计算时序Fig.9 Computing schedule of CPEs
由以上分析可知,分解完成一个n维矩阵需要运行的轮数为n/#CPE,其中,#CPE表示CPE 的级数。增加CPE 的级数可以增加轮内的计算并行度,减少运行轮数,缩短计算的时间。随着 #CPE的增加,资源消耗线性增加,由于轮数与 #CPE是反比关系,运行时间不断减小,但减小速度变缓。本文的设计将CPE 的数目参数化,调节该参数实现性能、资源使用和功耗的折中。具体来讲,系统中的状态数目确定后,如果速度无法满足当前场景的需求,则增大参数值来提高运行速度;如果当前场景对功耗和资源占用限制严格,则减小配置参数的值以减小功耗。配置参数的修改需要重新综合新的加速器硬件电路并在FPGA 上进行配置。
3 实验结果和分析
本文使用Xilinx ZC706 平台[15]对硬件设计进行评估,时钟频率为143 MHz。本文设计与SLAM软件VINS-Fusion[16]的后端优化进行对比,该软件使用谷歌公司的开源非线性优化库Ceres[17]进行状态优化。IMU 求导运算和方程求解的数值均需要大的动态范围和高精度[18],为了保证系统的稳定性和定位精度,本文评估的软硬件均使用32 bit 浮点数表示数据。在2 个处理器平台上对软件进行评估:搭 载Intel i5-8250U 处 理 器,主 频1.6 GHz 的x86 平台;搭载四核Arm Cortex-A57 处理器,主频1.9 GHz 的Nvidia Jetson TX1 平 台[19]。为 比 较 软 硬件性能,使用EuRoC 数据集[20]进行测试,该数据集采集自微型飞行器(micro aerial vehicle,MAV)上的视觉惯性传感器单元,其中包含IMU(ADIS16448,200 Hz)的加速度和角速率测量数据。首先使用VINS-Fusion 前端计算IMU 的积分值,后端优化选取20、50、80 个IMU 状态的测试数据,即系统的状态数N为20、50 和80。
调整LES 模块中CPE 的个数对整体的性能、资源消耗和功耗有明显的影响。在状态数目N为50 时,矩阵分解单元的数量设置为最小5 和最大120 的情况下,IMU 状态优化加速器的运行时间分别为171 ms 和8.97 ms。前者的运行时间为后者的19.1 倍;FPGA 资源使用方面,最大参数配置下的加速器中数字信号处理单元和存储资源分别是最小参数配置的6.4 倍和11.4 倍。本文在硬件上实现了3 个不同配置的电路C1、C2、C3,配置的CPE 的个数分别为20、40、80。C1、C2、C3 的硬件并行度依次提高,性能提升的同时资源消耗和功耗也增加。
硬件的资源消耗数据使用Vivado 工具布局布线后报告得出。C1、C2、C3 的资源消耗如表1 所示,3 种配置电路占用了FPGA 芯片中13.3%~27.3%的查找表(look up table,LUT)、6.7%~12.4%的触发器(flip-flop,FF)、15.9%~32.4%的块随机存取存储器RAM(block-RAM,BRAM)和30.9%~70.9%的数字信号处理单元(digital signal processor,DSP)。其中,BRAM 的数量以36 Kbit 块为单位,0.5 表示18 Kbit 块。评估使用的硬件平台中DSP 资源共有900 个,CPE 单元中的更新模块包含浮点乘和浮点加运算,增加一个CPE 单元DSP 的使用增加6 个,占总数的0.67%,CPE 数目的增多使DSP 的资源占用变化最大。每一个CPE 中带有存储矩阵分解结果的片上存储器,BRAM 的资源占用随着CPE 的数目的增多而变高。此外,BRAM 还和硬件能处理的IMU 状态数有关,本文设计能处理的最大的IMU状态数为80。

表1 硬件设计的资源消耗Table 1 Resource utilization of hardware design
对3 种配置的电路在不同测试数据上的性能进行了评估,如表2 所示。测试数据中,随着状态数目N变大,3 种配置电路的执行时间均变长。对IMU 状态数目小,如N=20 的测试数据,FPGA 相比软件取得较大的加速效果,处理时间小于1 ms,相比于x86 可以达到67.2 倍的加速效果,相比于TX1平台可以达到190.3 倍的加速效果。随着测试数据规模变大,FPGA 的加速效果减小,这是由于软件中分配的处理资源如内存等会同时增加,而FPGA 的电路使用的资源没有变化。但通过增加CPE 的数目,速度可以获得较大的提升,如对于N=80 的测试数据,C3 的时间相比于C1 的时间减小62.5%。对于不同测试数据上的平均加速效果,低功耗的C1电路相比于x86 平台和TX1 平台可以达到平均17.4倍和53.7 倍的加速效果,高性能的C3 电路的加速分别为26.7 倍和87 倍。
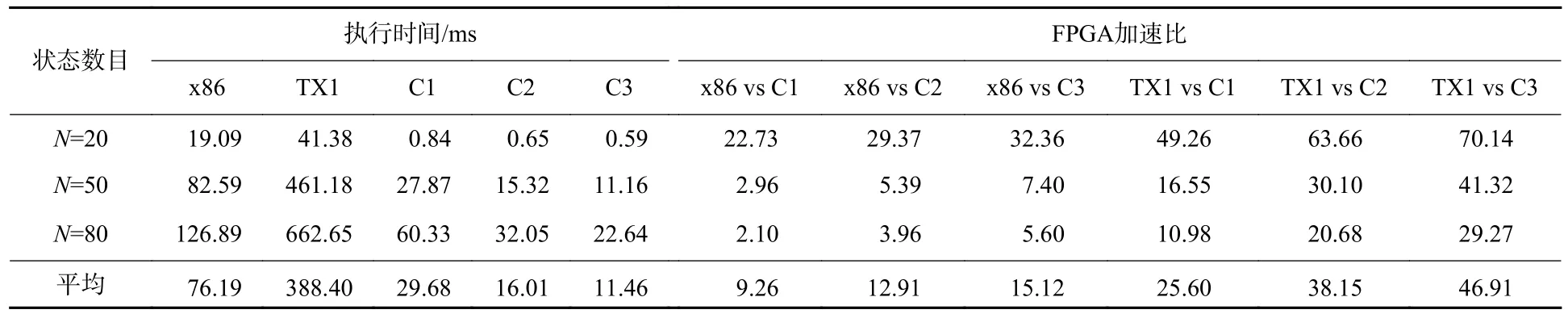
表2 软硬件实现的性能比较Table 2 Performance comparison between hardware and software implementations
此外,本文还对3 个平台上的功耗和能耗进行了评估。FPGA 功耗使用Vivado 的功耗评估器得出,C1、C2、C3 的功耗分别为2.293 W、2.956 W 和3.759 W。Intel CPU 的功耗评估采用其热设计功耗(thermal design power,TDP)15 W,Jetson TX1 使 用板载功耗监视传感器测得功耗为5.02 W。
表3 展示了在3 个测试数据上FPGA 与软件的能耗,在IMU 状态数少,如N=20 的测试中,不同配置的电路能耗相当,C3 由于功耗高能耗最多。状态数目增多,在N=50,80 的测试中,由于C1、C2 和C3 的计算时间差别明显,C3 的能耗最小。本文实现的FPGA 设计相比x86 平台和TX1 平台分别可以节省90%和95%以上的能耗,在高性能的同时也节约了能耗,可以更好地满足功耗受限、实时性要求高的应用要求。
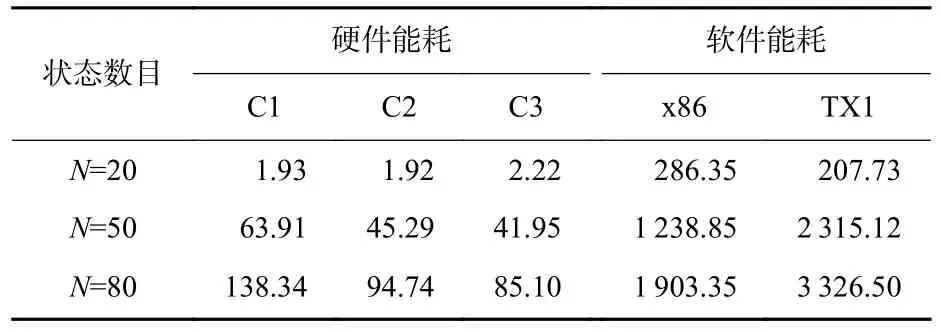
表3 能耗对比Table 3 Comparison of energy consumption mJ
4 结 论
1)提出了基于FPGA 实现的IMU 状态优化加速器设计,利用算法流程和数据的特点实现电路复用、计算简化和存储压缩。
2)解方程模块采用可配置设计,通过改变该模块的配置可使整体加速器在大范围的设计空间中变化,以适用不同的场景约束。
3)实验结果证明,本文设计在性能和功耗方面均大幅优于软件实现。本文提出的加速器设计可以高效地在功耗受限的嵌入式设备上完成IMU 观测信息的优化求解。
猜你喜欢
故事作文·高年级(2024年5期)2024-06-04 23:39:22
高中数理化(2024年8期)2024-04-24 16:58:14
初中生学习指导·中考版(2022年4期)2022-05-12 00:12:51
少先队活动(2021年6期)2021-07-22 08:44:24
中学生数理化·中考版(2019年10期)2019-11-25 09:39:06
电子制作(2019年24期)2019-02-23 13:22:20
电子制作(2018年17期)2018-09-28 01:56:44
个人电脑(2016年12期)2017-02-13 15:24:40
电子制作(2016年19期)2016-08-24 07:49:54
少年博览·小学低年级(2016年5期)2016-05-14 11:59:03
