
基于视图融合和注意力机制的三维小目标识别
2023-06-09 08:57吴佳佳
现代计算机 2023年7期
吴佳佳,李 智
(四川大学电子信息学院,成都 610065)
0 引言
激光雷达系统作为一种高效、快速的感知技术,已广泛应用于目标识别、检测和跟踪任务中[1‑2]。传统方法将视觉传感器采集的二维图像信息作为输入数据源,然而其易受到光照、天气状况以及可视距离等的影响。与视觉传感器相比,激光雷达更利于获得物体的空间结构。同时,由于激光雷达具有精细的角度分辨率,其对小目标的探测非常有效。然而,一方面传感器通过扫描一定场角内物体来获得点云,它来自部分目标而非目标整体,面临点云信息不完整的问题。另一方面受到目标体积和距离的影响,小目标探测面临点云稀疏的问题,这导致了识别的困难。
以往的研究工作表明,基于点云的目标识别工作已经取得了进展[3‑21],然而针对稀疏点云的处理仍未得到充分的探索。一些研究者借用图像处理的思想将点云投影到二维平面[6‑9],然而,这些方法运行速度较慢并且忽视了点云的内在空间结构关系。其它方法将点云转换为三维体积表示并对体素网格应用三维卷积[10−12],由于大多数的体素网格未被占用,因此这种表示方法效率低。文献[13]提出了PointNet 架构,该网络可以直接使用多层感知器处理原始点云,并利用对称函数聚合点云特征。然而,这种方法无法获得局部特征。作为PointNet 的扩展,PointNet++[14]引入了层次化结构将PointNet 架构应用在不同的抽象层中。在每一层中,选取某些点构建局部区域并将剩余的点舍弃,这些操作造成大量的信息损失。近年来,基于图的点云处理方法由于其在拓扑特征提取方面的强大能力得到了广泛的研究[15‑18]。文献[15]提出一种边缘卷积EdgeConv,通过将每个中心点与其k个最近邻连接起来构造图的方式聚合局部上下文信息。文献[17]提出了DDGCN,通过使用方向和距离计算点对之间的相似性矩阵,并在此基础上构建局部区域。最近,注意力机制由于其在二维图像处理中的表现得到研究者的关注,不少研究者将其应用到三维点云处理任务中,它可以对学习到的原始的特征图进行重新加权,并且对输入元素的排列是不变的。
传统的点云识别方法虽然能够有效地提取目标表面的结构特征,但针对小目标的识别,当面临点云数量少的情况时,依然存在鲁棒性差、特征提取少等问题。为此,我们提出了一个基于视图融合和注意力机制的小目标识别网络,它将多个视图的稀疏点云作为输入,并输出物体的类别标签。为此,本文在网络中设计了视图融合模块以及基于注意力机制的局部编码模块,其中视图融合模块通过融合不同视角下的原始点云数据得到描述目标整体的点云特征图,以增强全局点云特征。针对聚合后的全局点云特征提取难的问题,局部编码模块在全局点云特征上采用注意力网络进一步突出关键点特征。实验结果表明,本文提出的方法具有良好的鲁棒性,可以有效地解决点云稀疏时面临的识别精度下降的问题,而且在模型复杂度和识别速度方面也优于其它方法。本文提供了详尽的实验和理论分析,结果显示本文提出的方法在公开数据集ModelNet 以及真实环境采集的Aircraft 数据集上都取得了最先进的性能。即使点云数量下降,识别结果仍优于其它流行算法,这意味着本文的方法显示出稳健的性能。
1 网络原理与实现
点云可被看作是三维空间中的一组点,其数学表达式如公式(1)所示。
其中:M表示一组点云,N是其中点的个数,P代表一个点,可以由其三维空间坐标(x,y,z)表示。
本文采用的激光雷达数据主要有以下几个特点:针对小目标的探测任务中获得的点云数据是稀疏的;单个视角下的点云是由激光雷达在一定场角内扫描得到的,只包含组成全局特征的部分特征;各个点之间存在着关联性,单个模型中各点与其相邻的点有类似的几何结构。
本文提出的基于视图融合和注意力机制的识别网络的完整网络架构如图1所示。网络中包含了两个关键性模块,下文将对各模块进行详细介绍。
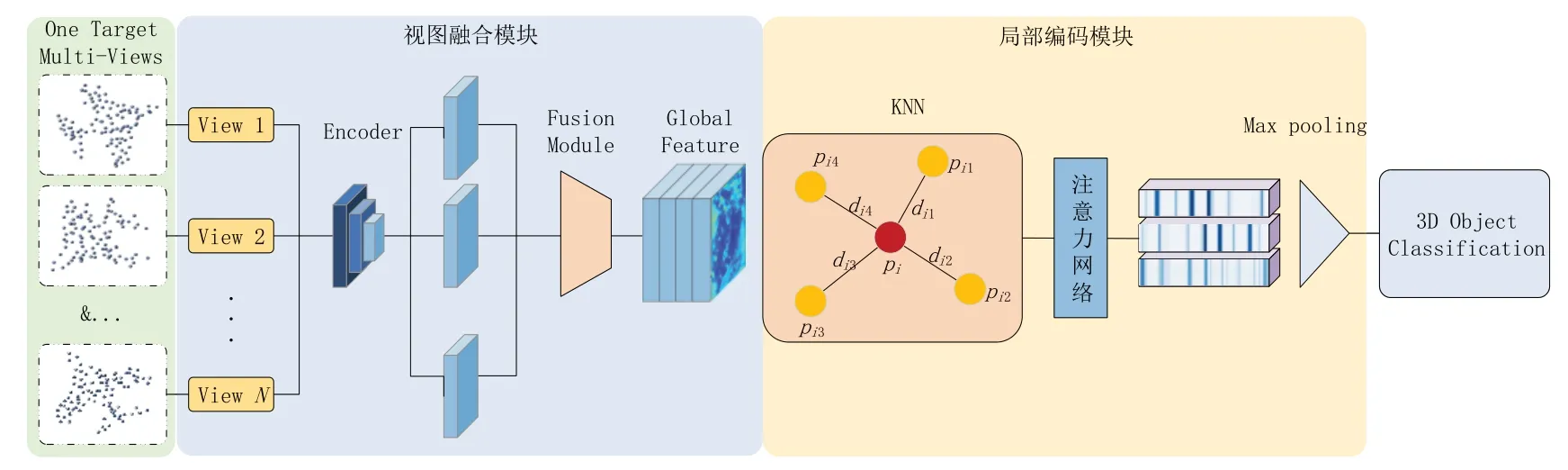
图1 网络结构
1.1 视图融合模块
来自单视图的点云包含了目标局部区域的部分稀疏点特征,缺乏全面性。为了充分表达三维对象,增强物体的全局点云特征,本文通过融合多个视图下的稀疏点云,以解决点云稀疏引发的特征少问题。文献[3]提出在分类器前设计一个类似于微型神经网络的视图融合网络,融合多个视图的深层次特征。Su 等[6]跨视图采用最大化操作,将所有视图的信息合成为单个形状描述符。
本文提出一种直接作用于原始点云的视图融合模块,其网络结构如图2所示。它通过数据融合方式将来自于不同视角下的原始点融合为完整目标的全局点云特征图。该模块包含空间向量映射和融合两个部分。考虑到不同视角下三维物体空间结构的差异性,在对点云进行融合之前,需将多视图下的点云映射至同一个向量空间。
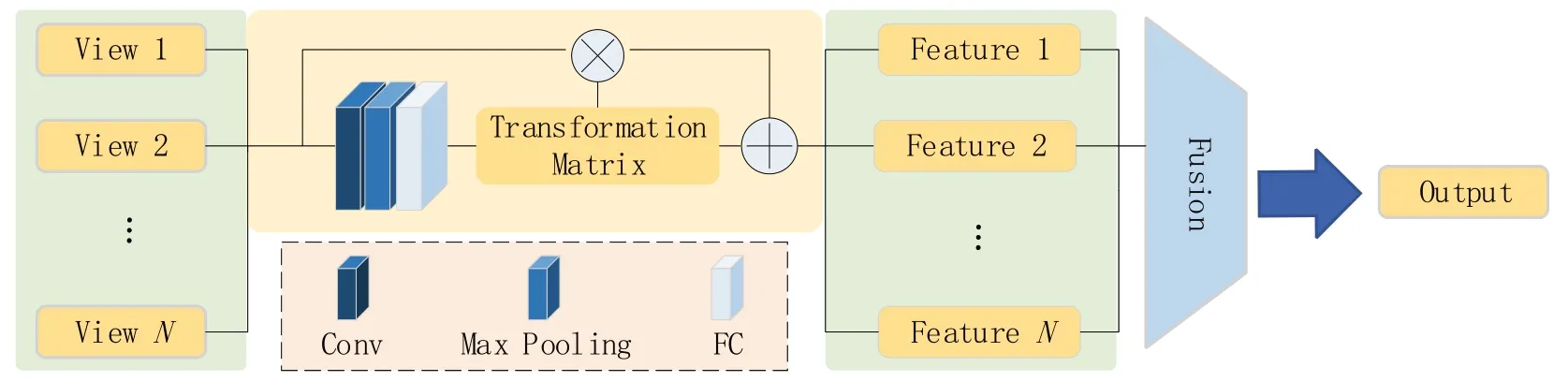
图2 视图融合模块
一般认为,点云在经过一系列刚性变化后语义标记是不变的,因此,我们用一个空间转换方程实现不同视角下点云的映射,它包括一个非奇异线性变换。它的计算公式如式(2)所示。
其中:P为空间变换前的坐标矩阵;P'为空间变换后的坐标矩阵;T为变换矩阵,包括旋转和尺度缩放,A表示一个平移矩阵。
本文采用了一个微型神经网络,通过反向传播算法自适应地学习变换矩阵和平移矩阵。它类似于一个神经网络结构,由卷积层、最大池化层和全连接层等基本模块组成,并在最后将全连接层的输出映射为N阶变换矩阵。最后,将在同一向量空间内的不同视角下点云进行拼接,得到描述目标全局的全局点云特征图。通过这种方法,稀疏点特征进行了增强。
1.2 基于注意力机制的局部编码模块
经过视图融合模块后的点云,包含了目标的全局点特征,为了解决全局点云特征提取困难的问题,引入基于注意力机制的局部编码模块,突出目标的关键局部特征,其网络结构如图3 所示。该模块由四个关键部分组成:采样层、分组层、编码层和聚合层。采样层从输入点中选择一组点作为局部区域的中心。分组层通过寻找中心点的相邻点来构建局部区域。编码层通过注意力网络将局部区域内的点云编码为一个特征向量,聚合层将点云的全局特征与局部特征聚合为一个单一的特征描述符。

图3 Modelnet数据集部分多视角点云图
在这一层中,首先将局部区域内点的三维空间坐标扩展为包含局部特征的四维表达:其中di表示该局部区域内各点与中心点的欧式距离。编码该点集主要采用一个矢量自注意。其表达式如式(3)所示。
其中:Pi表示该局部邻域的中心点;Pj为邻域内其余各点;ψ由线性层表示;γ表示MLP 层;δ为结构位置编码,其表达式如式(4)所示,通过对邻域内点的相对位置关系及相互之间距离进行处理得到关于局部点位置的编码信息,并将其添加至转换后的特征。由于Pj中已包含该局部邻域内所有点的相对位置关系,因此用其生成注意,同时注意力机制保证了输出对输入的顺序不变性。但其只编码局部信息,将形状视为小区域的集合,并失去了全局结构。
因此,在编码层后添加了聚合层,以聚合全局特征与局部编码特征。在最远点采样选择中心点时,只保留了选定的部分点。为了充分获取目标的结构信息,提高三维对象的识别准确率,必须通过融合的方式将有代表性的局部特征与全局特征聚合起来,避免稀疏点云特征的浪费。本文提出在网络最终的分类器前添加聚合层,其类似于一个微型神经网络,本文利用卷积层、最大池化层描述该微型网络。经过聚合层后,局部特征和全局特征被聚合到一个单一的描述符中。
2 实验结果与分析
2.1 数据集
为了评价提出的方法,本文在公开数据集和真实环境下采集的数据集上分别进行了实验。表1为本文实验中使用的数据集的统计数据。

表1 数据集描述
本文使用一款机器视觉处理软件HALCON生成ModelNet10 和ModelNet40 数据集在不同场角下的多视角点云。它首先通过设定虚拟摄像机的分辨率、镜头类型等参数初始化其位置,然后通过旋转三维物体获得不同视角下的点云数据。图3展示了实验中采用的部分多视图点云可视化结果。
为了分析真实环境中网络对小物体的识别效果,我们使用激光雷达传感器采集到目标数据集,并将其命名为Aircraft 数据集。利用小型激光雷达传感器平台Tanway‑Pro 进行扫描,扫描仪位于坐标原点(0,0,0),获得的数据是格式为(x,y,z)的空间坐标值。它包含了固定翼飞机、战斗机、火箭筒、鸟,共四种类别的4448 个训练样本和621个测试样本,如图4所示。
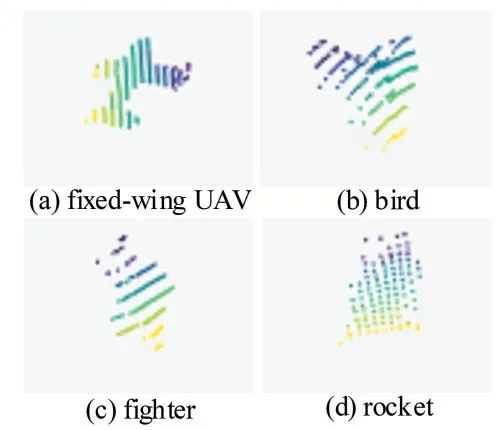
图4 Aircraft数据集点云图
2.2 实验环境
本次实验采用的CPU 为Intel® Xeon(R)CPU E5−1650 v4@3.60 GHz×12,显卡1080Ti。操作系统为Ubuntu16.04,开发环境为Pycharm,并采用Halcon 开发软件实现了多视角点云的提取。实验中编程语言采用Python 3.6,深度学习框架为Pytorch 1.9.0[20]。模型训练的初始学习率为0.01,并采用自适应下降的方式更新,Batch‑size 为16,训练轮数统一设置为120,优化器采用ADAM[21]。
2.3 实验结果分析
表2 显示了不同网络的对比实验结果,实验中均匀的采样10 个点作为网络的输入。结果显示我们的模型在公开数据集ModelNet10 和ModelNet40 及提出的Aircraft 数据集上均取得了最先进的性能。
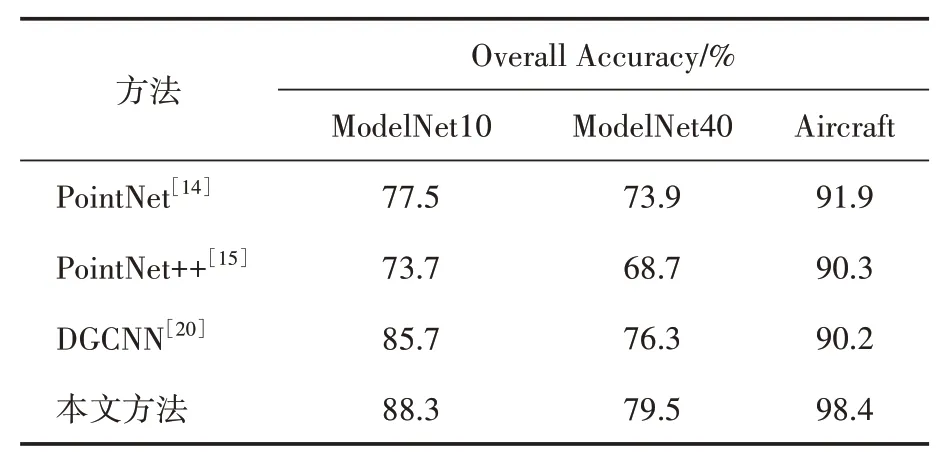
表2 对比实验结果分析
可明显地观察到,本文提出的方法比Point‑Net表现更好。这是因为本文对不同视角下的点云进行了融合,全局点云得到增强,不仅如此,在PointNet 中每个点都是独立地应用卷积算子,这种方法忽视了局部特征。PointNet++采用了一个局部特征聚合函数,将点云划分为小区域,解决了PointNet缺乏局部特征的问题。然而,它在每个采样层之后都会有信息损失。不仅如此,提出的网络添加了注意力机制,突出了局部中的关键特征。图5(a)为ModelNet10 数据集的最佳测试结果产生的混淆矩阵,其中对Monitor 的识别率高达95%以上,Chair、Sofa 和Toilet 等的识别准确率也在90%左右,最大的混淆在Desk和Night_stand 中,其中Desk 容易被归为Sofa,而Night_stand 容易被归为Dresser,这是因为它们具有相似的平面空间结构,且表面特征较不明显,造成了识别的误差。

图5 混淆矩阵
图5(b)是由Aircraft 数据集产生的混淆矩阵,识别任务相对简单。从混淆矩阵可以看出,固定翼飞机、鸟类和火箭的识别准确率都在95% 以上,其中鸟类和火箭的准确率都为100%。最大的混淆是在战斗机上,它很容易被混淆为固定翼无人机。尽管如此,本文提出的方法的识别结果仍然是最佳的。
理论上,获得的点云数量取决于激光雷达本身性能和激光雷达与目标之间的距离。针对同一个激光雷达系统,在短距离上工作的激光雷达比长距离上能获得更多的点。因此,我们在公开数据集ModelNet10 和采集的Aircraft 数据集上进一步分析了网络的健壮性。
对于ModelNet10,我们在其中选择一个飞行样本作为模板,均匀地对点进行采样,并将其归一化为具有100、60、30、10个点的单位球体。图6(a)直观地展示了不同点数的物体结构及点的分布。当点云数量为100点时,存在一定的信息损失,但物体的关键部位仍然可以被识别。当存在30 点时,只剩下基本的形状信息。如果只剩下10 个点,此时形状信息已经难以分辨。图6(b)显示了随着点数量下降精度曲线的变化过程。结果表明,与其它流行算法相比,基于视图融合和注意力机制的识别网络具有更好的鲁棒性。
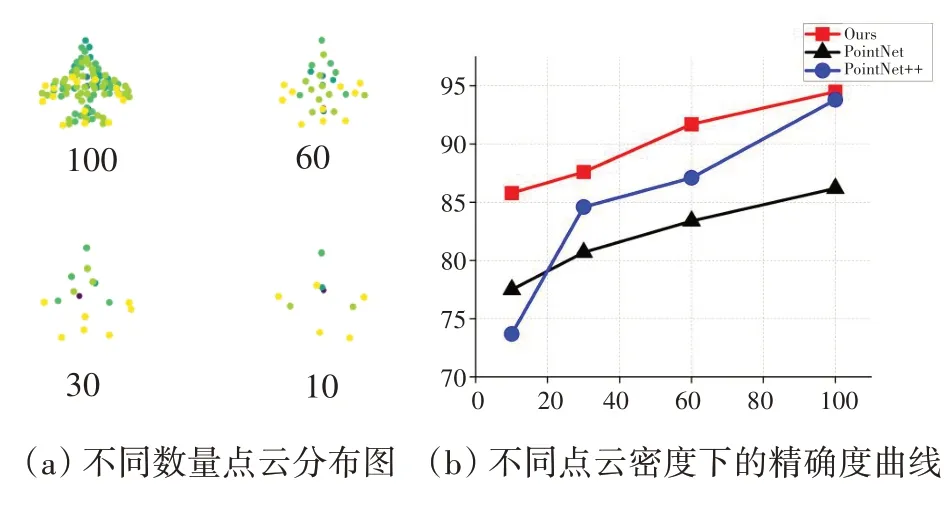
图6 ModelNet鲁棒性分析
对于Aircraft 数据集,分析目标在不同探测距离下网络的稳健性。图7是不同距离下同一视角点云的分布情况以及网络的识别性能。结果表明,随着探测距离的增加,物体表面点云稀疏,识别难度增强。在真实的探测环境下,提出的方法对不同探测距离下的目标有着很好的鲁棒性。从图中可明显看出,本文提出的网络曲线下降趋势与其它曲线相比要慢得多。
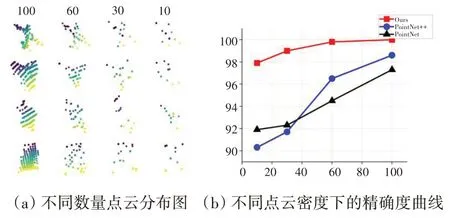
图7 Aircaft鲁棒性分析
此外,本文分析了视图数量对于识别结果的影响,分别对1、3、6 和10 视图的识别效果进行了测试。对于ModelNet10 数据集和Aircraft数据集的结果如表3所示。

表3 输入10个点时不同数量视图的精确度
在所有实验中,均匀地对10个点进行采样。结果表明,视图的数量对网络的识别效果有一定的影响。对于ModelNet10 数据集,当视图减少至6 个时,准确率下降了2.5%;当视图减少至3 个时,准确率只有83.2%。这是因为,各视图中包含着目标的局部点云信息,网络输入的视图数量减少,经过视图融合模块后拼接到的全局点云特征图的数据也会减少,导致部分特征信息丢失,数据的表达能力减弱,识别精度降低。
2.4 消融实验
为了证明网络中视图融合模块和基于注意力机制的局部编码模块的有效性,我们在Model‑Net10 数据集上进行了一系列消融实验,以特征分布的t‑SNE 可视化表征网络的识别效果。图8(a)为该网络的实验结果。首先,为了证明视图融合模块的有效性,在网络中删除视图融合模块(Module 2),以单视角下的稀疏点云作为网络的输入,实验结果如图8(b)所示。其次,为了证明局部编码模块的有效性,在网络中删除局部编码模块(Module 1),实验结果如图8(c)所示。最后,删除网络中视图融合模块和局部编码模块,实验结果如图8(d)所示。结果表明,网络中视图融合模块和局部编码模块都对网络的识别效果有积极影响。
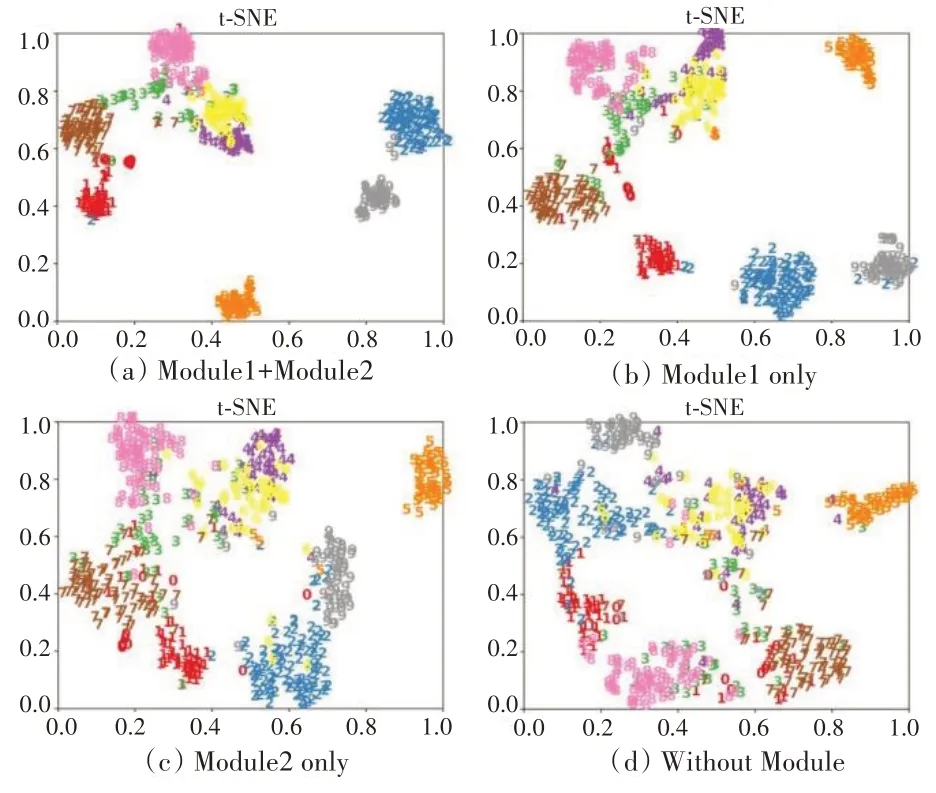
图8 在Modelnet10上特征分布的t⁃SNE可视化
3 结语
激光雷达探测小物体存在点云稀疏的问题,本文提出了一个基于多视图融合和注意力机制的点云识别网络。网络的关键是添加了视图融合模块和基于注意力机制的局部编码模块,它将输入的多视角稀疏点云进行融合,得到了增强后的全局点云特征。针对增强后的全局点云,提出基于注意力的局部编码,编码局部结构关系的同时突出关键点特征。在公开数据集以及Aircraft 数据集上,本文提出的方法显示出比其它最先进的算法更好的性能。因此,本文提出的方法对真实环境中的激光雷达数据也同样适用,可应用于小物体的识别任务中。未来,将探索更有效的特征提取方法以提高网络表征局部特征的能力。我们将专注于提取目标的局部细节,并尝试用尽可能少的点捕捉有效的特征。此外,我们希望利用无人机上的嵌入式平台对物体进行灵活扫描,完成远距离下小目标的识别任务。
猜你喜欢
北京测绘(2022年5期)2022-11-22
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
汽车观察(2021年8期)2021-09-01
中国交通信息化(2019年1期)2019-03-26
电子制作(2018年16期)2018-09-26
金桥(2018年4期)2018-09-26
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
