
基于Stacking集成结构的钓鱼网站识别
2023-06-09 08:57:38段金凤张晓颖
现代计算机 2023年7期
段金凤,张晓颖
(长春大学理学院,吉林 130022)
0 引言
网络钓鱼常常通过创建虚假网站来获取用户隐私信息,且存在更新速度快、周期较短等特点。如何及时高效地对钓鱼网站进行识别是当今面临比较棘手的问题。随着机器学习深度学习算法的发展,国内外研究人员利用其对网络钓鱼网站识别开展了许多研究。Aggarwal 等[1]提出使用Twitter 上特有特征结合UTL 特征来构建钓鱼网站识别模型,达到了92.52%的准确性;Liew 等[2]提出了基于随机森林算法的预警机制,在11个最佳特征上准确率达到了94.75%;胡向东等[3]提出一种结合网页敏感文本和logo图像特征的检测方法,其召回率为97%;周传华等[4]提出了一种过滤式方法和封装式方法混合特征选择模型FSIGR,在特征降维和提高分类精确度方面均有很好的表现;毕青松等[5]提出一种基于最大相关最小冗余和随机森林相结合的特征选择,并利用XGBoost 算法来构建钓鱼网站检测模型,精确度达到90.25%,其AUC值为0.87。
为了能更高效识别钓鱼网站,本文提出一种基于Stacking 模型融合的钓鱼网站识别方法,主要包含以下几个方面:使用XGBoost算法筛选出最优特征子集,在此基础上选取RF、ET、XGBoost、LightGBM 作为Stacking 第一层基分类模型,最后利用GBDT 算法作为Stacking 第二层元分类模型,对钓鱼网站进行识别。该方法构建基模型进行特征学习,提高钓鱼网站识别准确率。
1 基础理论
1.1 XGBoost
XGBoost 是一种集成树模型,是GBDT 的改进boosting 算法,具有训练速度快、预测精度高等优点[6]。其简单目标函数如下:
为了将目标函数化简,将常数项抽离出来,使用泰勒公式进行近似展开,得到如下目标函数:
其中:gi表示对̂(t−1)的一阶导数;hi表示对̂(t −1)的二阶导数。在式(3)中使用函数f(x) 来表示树模型,模型的优化求解本质上是求解参数,为了对模型优化求解,需更进一步对树模型参数进行优化。定义树的复杂度主要从每棵树叶子节点数和叶子节点权重两个方面,可得到Ω(ft)表达如下:
其中:T表示叶子节点数;wj表示第j个叶子节点的权重。将式(4)带入目标函数中,由于常数并不影响参数优化,可得如下:
为了使目标函数最小,令其导数为0,解得每个叶子节点的最优预测权重为
代入式(5)目标函数,解得最小损失为
XGBoost 利用了二阶梯度对节点进行划分,相对于其他GBM 算法精度更高;利用局部近似算法对分裂节点的贪心算法优化;在损失函数中加入L1/L2正则项,控制模型复杂度,提高了模型的鲁棒性,提高并行计算能力。
1.2 LightGBM
LightGBM 是基于决策树模型的Boosting 算法,由于GBDT寻找合适分割点,需要遍历所有数据去计算信息增益,对于大量数据而言,计算复杂度和时间急剧增加。LightGBM 提出针对此问题进行优化,采用了基于梯度单边采样(GOSS)和互斥特征合并(EFB)两种方法[7]。
基于梯度单边采样在梯度小的数据上进行随机采样,保留梯度大的数据,EFB 将许多互斥特征变成低维稠密,减少不必要特征计算,LightGBM 使用这两种方法去平衡准确率和效率,减少了计算和时间成本。
1.3 随机森林
随机森林(random forest, RF)是由很多决策树分类模型组成的组合分类模型,是利用boot‑strap 重抽样方法从原始样本中抽取多个样本,对每个bootstrap 样本进行决策树建模,然后组合多棵决策树预测,通过投票得出最终预测结果。具有比较高的预测准确率,对异常值和噪声有很好的容忍度且不容易出现过拟合。
1.4 极端随机树
极端随机树(extremely randomized tree,ET)中每棵树都使用所有训练样本,随机选择分叉特征。与随机森林算法类似,但是ET 采用随机特征,分裂随机减少了信息增益比或者基尼指数的计算过程,多棵决策树组合在一起,也可以达到比较好的预测效果。
1.5 梯度提升树
梯度提升树(gradient boosting decision tree,GBDT)的基本思想是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加形式结合到现有模型中。采用决策树作为弱分类具有比较好的解释性和鲁棒性,能够自动发现特征间高阶关系,并且不需要对数据进行特殊预处理,既能处理连续值也能处理离散值。
2 Stacking集成学习模型
Stacking 集成算法是由Wolpert[8]在其论文Stacked Generalization 中所提出的,其实际上是一种串行结构的多层学习系统。不同于Bagging和Boosting 集成算法,是分为两层将不同基础学习器组合起来进行模型学习[9]。Stacking 先将原始数据K−折交叉验证法分成不交叉的K份,K−1份作为训练集,一份作为测试集;其次利用多种分类器作为第一层基分类模型,得出每个分类器预测的结果,每个分类器预测结果取K−折交叉验证的平均值“生成”一个新数据集;最后将新数据集作为第二层的输入特征,使用第二层分类器进行预测。Stacking算法如下:
在文本中第一层基分类模型为随机森林(RF)、极端随机树(ET)、XGBoost 和LightGBM 四种分类器,梯度提升决策树(GBDT)作为Stacking 集成结构的第二层,也就是对钓鱼网站识别的最终分类器。
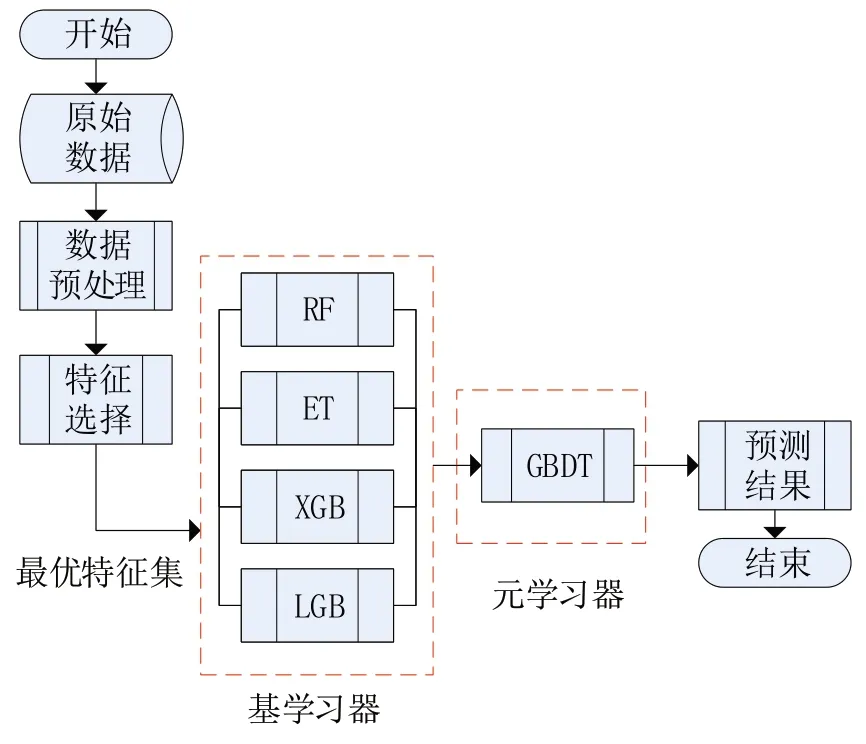
图1 Stacking集成学习框架
3 实验
3.1 实验数据及说明
本文实验数据来自于UCI 数据库中的phish‑ing 数据集,数据集总条数为11055,其中钓鱼网站数据量为4898,占比约为44.4%;非钓鱼网站为6157,占比约为55.6%。总计包含30 个属性特征,包括URL_Length、Shortining_Service、SSLfinal_State、SFH等主要特征。实验环境如下:实验平台为Pycharm;Python 版本为3.8.6;一些常用机器学习库Pandas、Matplotlib、Sklearn等。
3.2 评价指标
对于分类问题,模型评价指标主要有准确率(accuracy)、精准度(precision)、召回率(recall)、F‑score和ROC−AUC曲线。
AUC 是ROC 曲线下的面积,统计意义为从所有正样本中随机抽取一个正样本,从所有负样本中随机抽取一个负样本,当前score 使得正样本排在负样本前面的概率,取值在0.5 到1 之间,越靠近1表示模型性能越好。
3.3 最优特征集选取
本文数据集有30 个属性,将数据80%划分为训练集,20%划分为测试集。特征选取过多或过少都会影响到模型的精确度,使用XGBoost进行特征筛选,图2为精确度随选择特征重要性阈值和特征个数k变化的曲线,可知在特征重要性阈值为0.07,k为24时,模型精确度最高。图3 为24 个重要特征排序结果。所以最终选取SSLfinal_State、URL_of_Anchor、Prefix_Suffix 等24个重要特征进行建模。
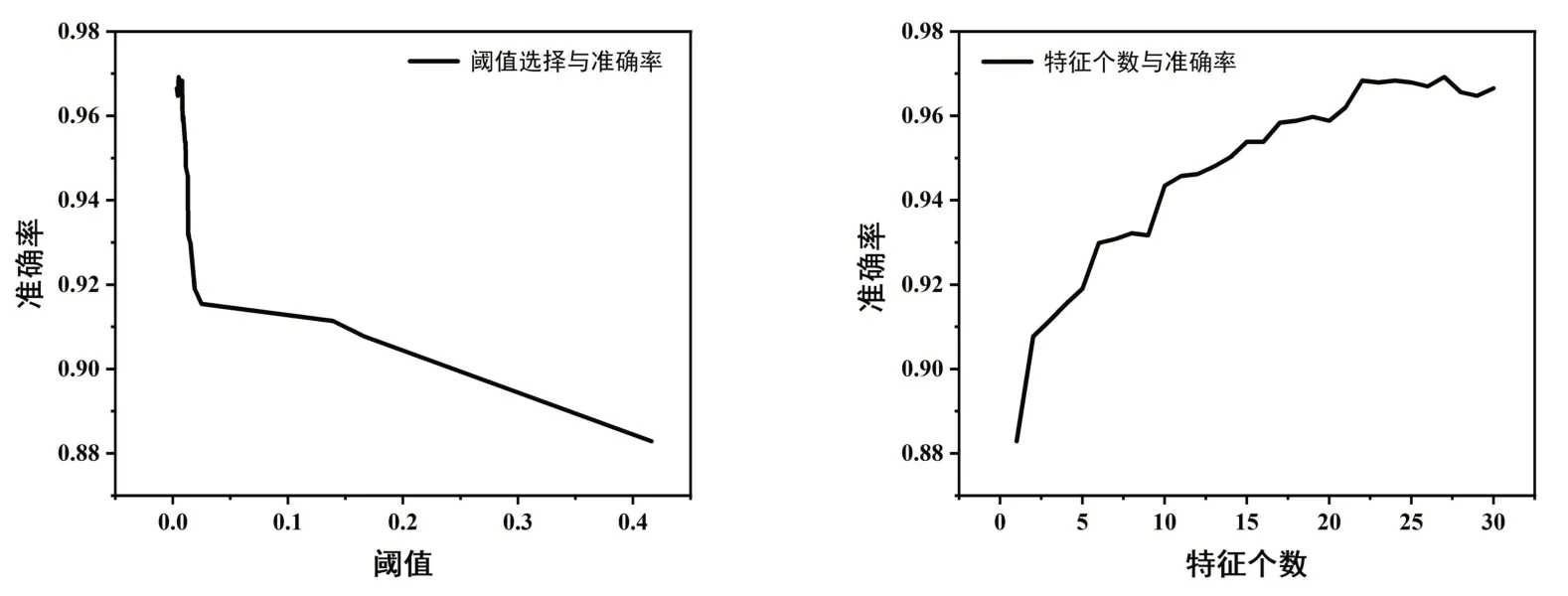
图2 最优特征集选取
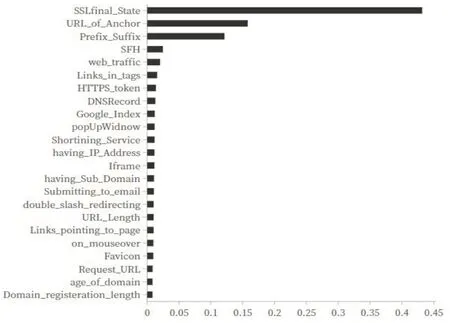
图3 24个重要特征排序
3.4 实验结果与分析
为了检验本文提出的钓鱼网站识别模型是否有效,先利用筛选出的最优特征集使用XG‑Boost、LightGBM 等五种单一学习器对钓鱼网站进行识别预测。为了提高模型的鲁棒性,本文采用Sklearn 库中StratifiedKFold 对训练数据集进行五折分层交叉验证,StratifiedKFold 可以让每一折中都保持着原始数据中各个类别的比例关系,使得验证结果更加可信。同时使用Grid‑SearchCV 对参数进行调节,提高模型预测能力,其网格搜索得到最优参数。
表1是不同分类器模型在最优特征集上对钓鱼网站识别的结果,使用XGBoost的准确率可以达到96.89%,召回率为95.74%,其AUC 的值为0.9651;LightGBM 对钓鱼网站识别的准确率为97.21%,召回率、F1 指标和AUC 的值都比XG‑Boost 模型高;RF 和ET 的召回率都可以达到98%左右,但是F1 指标和AUC 的值相对而言并不高。本文提出的Stacking集成模型准确率达到了97.96%,召回率为96.24%,F1 指标和AUC的值也比其余五个单一分类器高,可见使用Stacking 集成模型对钓鱼网站进行识别是非常有效的,而且综合性能也比RF、ET、XGBoost 等单一学习器高,尽管它们的预测能力已经比较高了。
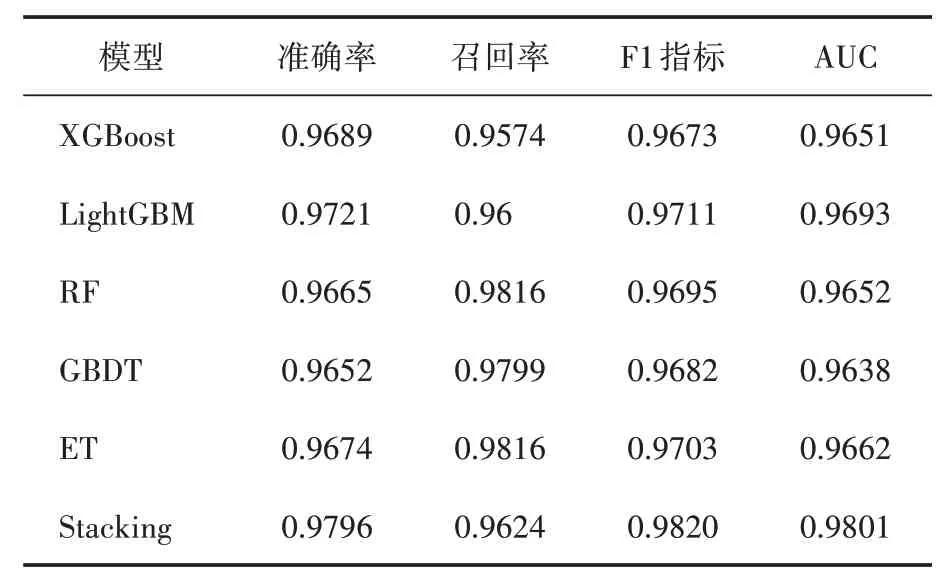
表1 不同分类模型实验结果
为了能更直观展示本文各个钓鱼网站识别模型的预测能力,图4 给出了XGBoost、RF、GBDT 和Stacking 集成模型的ROC 曲线以及AUC值,AUC 的值越靠近1 说明模型预测能力更好,由图4 可知,使用Stacking 集成模型识别钓鱼网站是最好的。
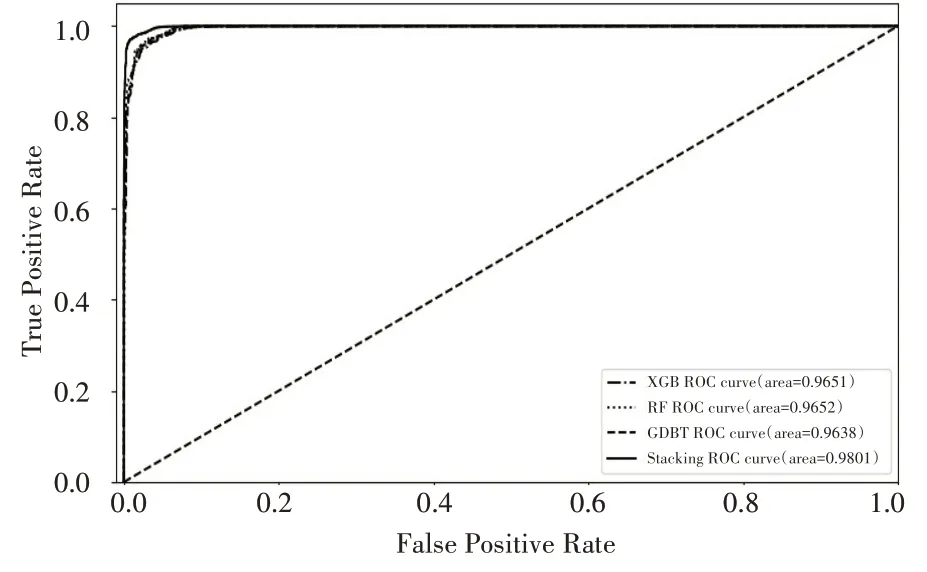
图4 不同分类器的ROC曲线
4 结语
随着互联网的快速发展,快速、有效地识别钓鱼网站是非常有必要的。尽管已有文献已经从不同的角度进行了研究,但大多研究仅是使用单一机器学习方法,且精确度不高。本文提出一种Stacking集成结构的方法,将RF、ET、XGBoost 和LightGBM 四种不同集成决策树模型预测结果进行融合,然后基于GBDT模型进行钓鱼网站识别。此外本文在对钓鱼网站进行识别之前,利用XGBoost进行特征筛选,去掉冗余特征,得到24 个重要特征组成最优特征集。结果表明,Stacking 集成模型F1 指标和AUC 值评价指标都高于XGBoost、LightGBM 等五种单一算法。可见本文提出的Stacking集成模型对于钓鱼网站的识别效果较好,但本文针对Stacking集成模型并没有详细调参,如何筛选最优特征集和参数调节来提高预测准确率是今后研究方向。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
小学生导刊(低年级)(2016年8期)2016-09-24 07:57:23
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
小学科学(2015年6期)2015-07-01 14:28:58
小学科学(2015年6期)2015-07-01 14:28:58
小学科学(2015年5期)2015-06-08 21:33:00
