
面向民航事故报告的异构图摘要模型研究
2023-06-08 08:10何元清
现代计算机 2023年8期
何元清,郑 鑫
(中国民用航空飞行学院计算机学院,广汉 618307)
0 引言
民用航空事故跟踪调查报告记录事故发生全过程,监管者会通篇阅读报告,提炼总结要旨,为本次事故提出原因分析和安全建议,同时指出监管疏漏之处,确定下一步工作重点。事故报告内容繁杂且专业性极强,目前主要依靠民航领域专家人工编写事故发生原因概要,但面对海量且迅速增长的航空事故跟踪调查报告,仅依靠专家不仅面临效率困境还容易出现分析疏漏。如何快速、深入、准确地整理事故原因提炼事件详情是制约事故报告利用率的关键问题。实现民航事故报告自动摘要可极大减轻专家阅读工作量,自主筛选出重点信息,对提升民航专家工作效率,推理事故影响因素,调整民航监管工作重点具有重大意义。
目前文本摘要技术已经广泛应用于新闻、微博用户发言、商业服务评价等领域。Cheng等[1]在CNN/Daily Mail 中检索出大量新闻文章构建出新闻语料库,并为每个句子打上标准标签,以及创建了来自此新闻语料的词汇数据集。Zhou[2]等提出了端到端模型NEUSUM,首次将选择策略融入打分模型中,并在CNN/Daily Mail数据集中达到当时最好效果。Zhong 等[3]细分析数据集对神经网络摘要模型的影响因素,探讨通用领域模型移植到专业领域的可能性,展示了充分挖掘数据集以及增添外部知识对模型的重要性。随后,Zhong 等[4]提出Summary‑level(篇章级)抽取式摘要的思想,即高质量摘要应当整体与原始文档在语义空间上尽可能相似,并在CNN/Daily Mail 数据集上得到验证。研究者尽管在摘要领域取得不断进步,但大多集中在新闻领域。Zhong 等[5]从美国退伍军人受伤后应激障碍诉讼案例中构建了法律领域摘要数据集,采用深度学习的抽取式方法获取摘要,但出现语义缺失的问题;程坤等[6]针对中文新闻文本特点提出增加线索词、标题相似度等因素来改进MMR(maximal marginal relevance)[11]算法;施国梁等[7]提出专利文本领域摘要模型,指出专利文本结构复杂、内容繁多,而当前通用领域下的模型所生成的摘要内容单一重复且不够简洁流畅。以上研究工作主要集中在公共领域,部分研究者开展法律、专利等特殊领域文本摘要,但却难以直接移植模型,须对领域内数据集详细分析。
与上述领域研究相比,民航事故调查报告内容繁杂,包含事故详情,事故原因总结、专家意见等内容,文本中经常出现“飞行器名称、故障名称、零部件名称”等一系列专业词汇,这些内容直接影响摘要生成质量。这些因素导致现有的文本摘要模型在民航事故领域难以取得高质量摘要。因此,面向航空事故跟踪调查报告的自动文本摘要技术成为了切实且紧迫的需求。
针对上述问题,为深度挖掘航空事故跟踪调查报告文中语义关系,融入专业词汇指导摘要生成,提出基于实体要素异构图的抽取式文本摘要模型。基于图神经网络构建实体节点与句子节点多粒度异构图,结合注意力机制构建EHGA(entity heterogeneous graph abstract model)模型。针对EHGA 模型有效性实验所采用的文本数据来自各个国家飞行事故调查局发布的民航事故调查跟踪报告,使用真实事故报告中事故详情部分作为输入。实验结果表明,EHGA模型通过引入实体节点内部信息补充,在进行抽取式摘要时能取得较不错的结果。于ROUGE[8]评分体系下显示出较好的摘要抽取能力,极大减轻摘要的冗余程度,扩大摘要信息覆盖范围,相比传统的序列到序列模型,在ROUGE‑1、ROUGE‑2 和ROUGE‑L 上平均取得6.23%,4.67%和6.01%的性能提升。
1 EHGA 模型介绍
针对民航事故调查跟踪报告文本设计基于实体要素异构图的文本摘要方法,总体架构如图1 所示。模型分为3 个主要部分,分别是实体抽取模块、融合实体要素的异构图注意力模块和句子抽取模块,本节将分别对以上部分进行详细介绍。
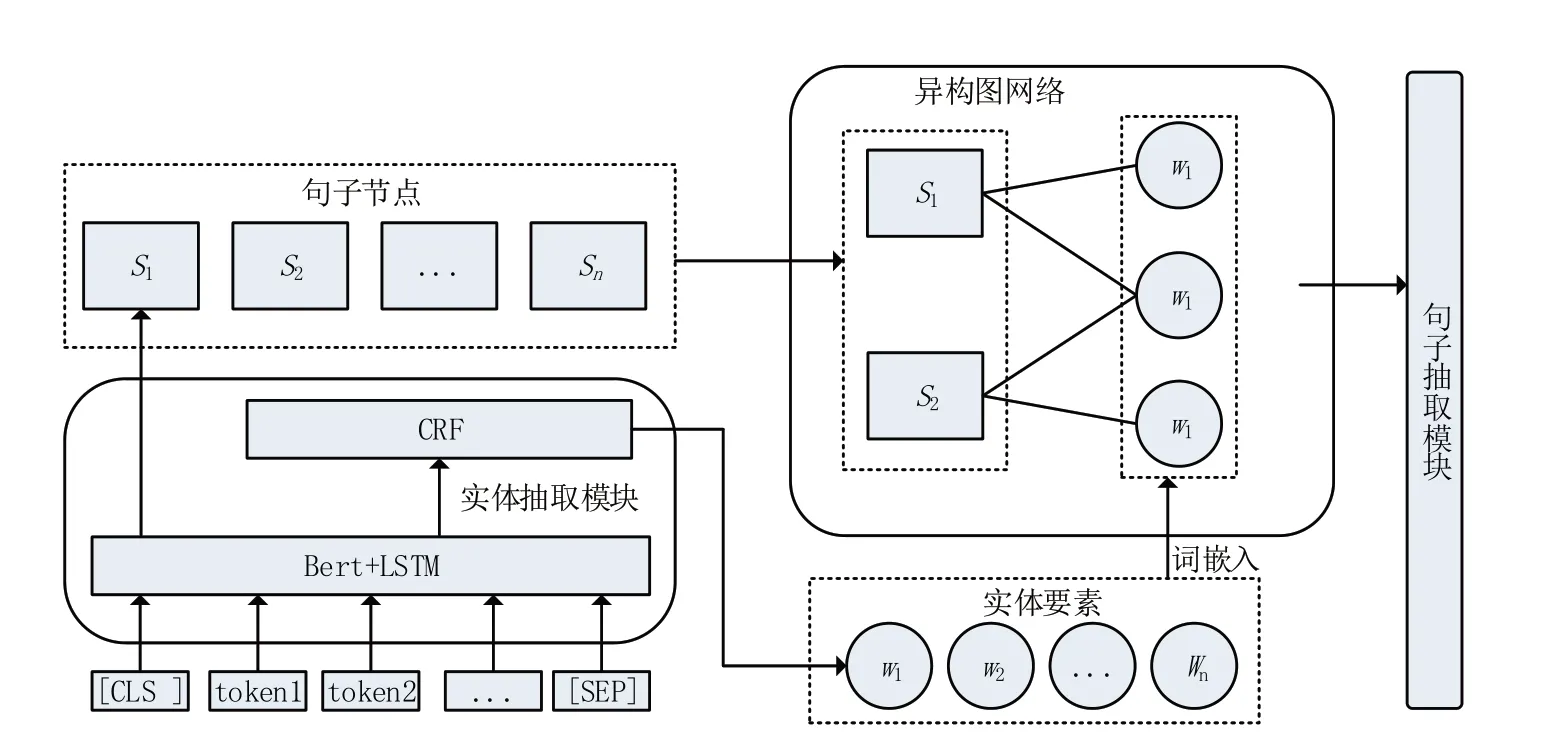
图1 实体要素异构图摘要模型
1.1 实体抽取模块
为使用实体要素来丰富句子之间的关联关系,采用BERT‑BiGRU‑CRF 模型的方法获取民航事故调查跟踪报告中实体元素,其优势在于结合了BERT[9]模型和BiGRU(Bi‑directional gate recurrent unit)模型的优点。BERT 是已经在大型文本语料库中训练过的模型,其基于双向Trans‑former Encoder连接,内部采用多头注意力机制,可以高效获取文本中的语法结构和语义特征;之后利用BiGRU‑CRF[10‑11]模型标注实体,此模型充分考虑文本中上下文语句的连贯信息,从而使抽取的实体不是独立分类。
图2是实体抽取模块的总体架构图,以“泛非航空A332 的黎波里复飞过程中坠毁”为例,输入“泛非航空A332 的黎波里复飞过程中坠毁”在BERT 层映射为token 值,然后在BERT层进行特征抽取获得输出向量,再到BiGRU 层理解上下文语境,经过前后双向传播得到包含双层维度的输出向量,最后经过CRF 层计算路径分数最大值,获得准确度最高的标注序列。
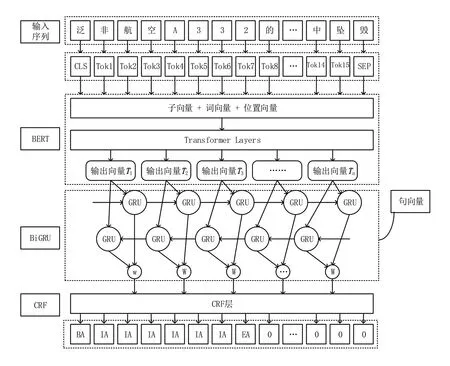
图2 BERT⁃BiGRU⁃CRF模型结构
在获取实体要素的同时,所输入的文本数据被送入预训练模型BERT中生成对应向量,为更加充分地对上下文语义内容进行学习,将预训练获取到的向量送入基于BiGRU 的特征提取层进一步凝合信息,之后便得到图模型所需的句向量。
1.2 异构图构建
传统图模型直接在句子间建立连接,而EHGA 模型构建一个多粒度信息的异构图,以实体要素作为句子间的中介节点,由此形成的异构图拥有更丰富的语义信息。在此图中,有两种基本粒度类型节点:句子和实体,其中实体来自实体抽取模块。实体节点作为基本语义节点,代表词级信息;句子节点对应文档句子,代表全局信息。若实体出现在句子中,则将实体节点与句子节点连接,而句子结点间不直接相连,采用TF‑IDF值作为边的初始值。
因此给定图G={V,E},其中V表示节点集,E表示节点之间的边,则异构图可以被定义为V=Vw∪Vs和E={e11,…,emn}。其中,Vw={w1,…,wm}表示文档中m个唯一实体,Vs={s1,…,sn}对应文档中n个句子。E为边的权重矩阵且eij≠0(i∈{1,…,m} ,j∈{i,…,n}),其含义为第j个句子包含第i个实体。
1.2.1 图节点表示
与其他模型相比,BERT 通过位置编码和MLM(mask language model)得到符合上下文语境的词向量,使其更符合原文含义,因而采用BERT 生成实体向量,句向量则需要充分考虑文本前后文采用BERT+BiGRU 训练。令Xw∈ℝm×dw和Xs∈ℝn×ds表示实体向量和句子向量特征矩阵,dw表示实体向量维度,ds表示句向量维度。经过实体提取模块得到实体向量表示Xz∈ℝp×dz,可以得到由BERT 所学习到的实体语义特征lw,和经过BiGRU 获取句子级全局特征gs,最后经过Average‑polling 层拼接,得到句向量的最终表示,具体如下:
词节点出现的程度可以衡量文档的冗余程度,实体节点可以聚合更多句子的信息来丰富图结构信息。Xz∈ℝq×dz表示实体节点语义特征矩阵,q是实体节点数量,dz是在民航事故调查跟踪报告中抽取实体的特征矩阵维数。
1.2.2 边表示
为进一步概括句子节点之间的关系,定义句子-实体边(如果一个句子包含一个实体)来模拟句子之间存在的丰富联系。句子节点可以通过实体节点建立彼此之间的联系,从全局层面观察全文句子隐含关联,实体与句子构成的边被称为wTs。
由此得到异构图G={V,E},V=Xw∪Xs,E=wTs。
1.3 异构图注意力机制模块
EHGA 模型通过引入图注意力网络(graph attention networks,GAT)[12]来更新语义节点表示,具体表现如图3所示。
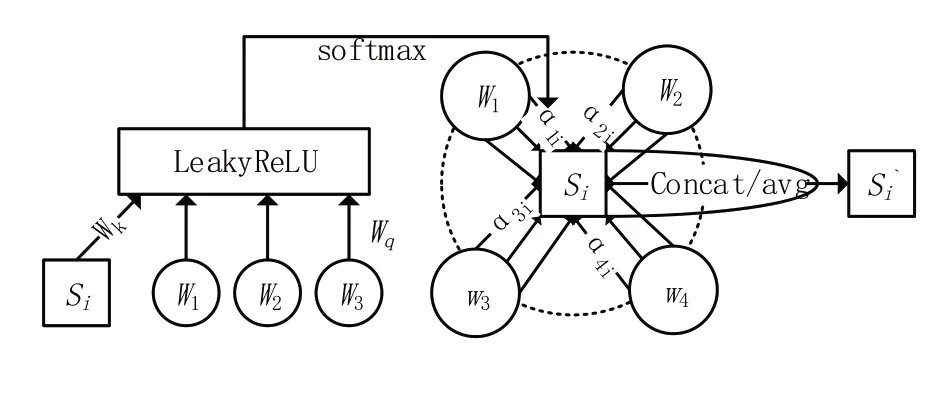
图3 融入实体节点异构图注意力模型
民航事故调查跟踪报告正文作为输入,第i句的向量表示记为hi∈ℝdh(i∈(1,…,n)),hz∈ℝdh(z∈(1,…,m))表示实体节点向量,eiz∈ℝn×m表示实体节点与句子节点的边特征矩阵,则整个图注意力层设计如下:
其中,Wa,Wq,Wk是可训练参数,γiz表示句子节点i与实体节点z之间的注意力权重计算,EHGA 模型对γiz进行归一化操作得到αiz便于不同句子节点的重要性比较,如公式(3)。对于句子节点hi与其他相连的所有实体节点hz进行信息聚合, GAT 层整体运算过程如以下表达式所示:
其中μi是句子节点hi在其所有邻接实体节点上学习到的向量表示,因此也具有特定的语义信息。为了在学习过程中提取更多特征,EHGA模型采用多头注意力机制,如下所示:
考虑到图神经网络常见的过渡平滑以及梯度消失问题,EHGA 模型参考transformers 中残差连接设计,避免因迭代次数过多而引起的梯度消失问题。因此在图注意力网络中句子节点hi的特征向量表示为
在每个图注意力层后,引入一个前馈网络(FFN)层对特征进行进一步压缩,获得最终的句子稠密向量表示,其计算过程如下。
1.4 句子选择模块
在真实句子选择时,往往会出现句子级分数较低但是整体摘要分数较高的情况,为了保证最终摘要结果的可读性和重要信息的覆盖度,EHGA 模型采用Trigram blocking 策略。对所有候选句子依据概率排序,依次选择概率最高的句子,如果被选择的句子与当前摘要存在三元组重叠(trigram overlapping)[13],则认为其冗余,反之则将其加入摘要,并从剩余候选句子中排除此句,反复进行以上操作直到满足摘要所设定的长度阈值。EHGA 模型采用交叉熵作为损失函数衡量真实摘要和预测结果之间的距离,损失函数公式为
其中:yi表示对应句子hi的真实标签,yi= 1 表示第i个句子应该包含在摘要中。
2 实验及结果分析
2.1 数据集及实验环境介绍
2.1.1 数据集构建
本次实验使用来自各个国家飞行事故调查局所发布的民航事故调查跟踪报告数据集,包含由2010—2016 年世界各地民航事故调查跟踪报告共861篇,并对文本进行清洗、标注,构建航空事故报告数据集,有效数据842对,数据集统计结果如表1所示。
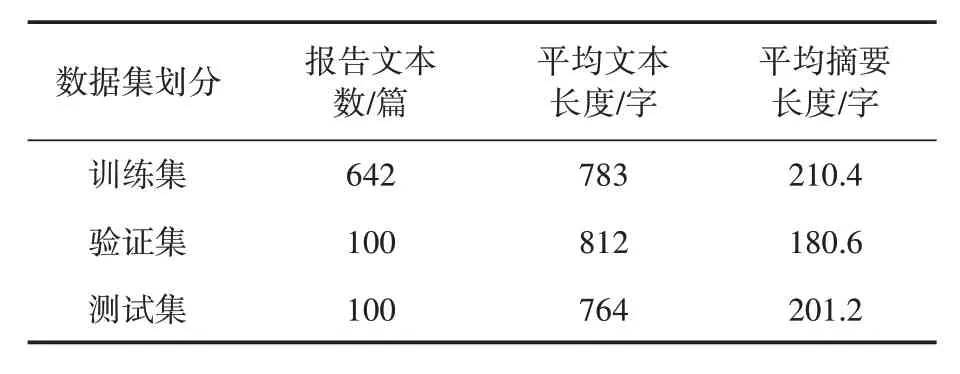
表1 数据集统计
实体数据集则通过民航局颁布的《民用航空器事故征候》《民用航空器征候等级划分办法》《事件样例》《民用航空器事故和飞行事故征候调查规定》《民用航空安全信息管理规定》等规范性文件确定实体名称,包括航空事件、航空事件原因、航空地面事件等类型规范实体名和报告中一些不规范实体名称,因此实体要素对于摘要的生成具有科学性与准确性。
2.1.2 实验环境介绍
本次实验CPU 使用Intel Core I9-10900X,内存96 GB,GPU 为Nvidia GeForce RTX 3090 24 GB 一块。采用深度学习框架PyTorch,实验环境PyCharm,Python 3.8 版本。EHGA 模型使用预训练语言模型BERT 初始化句子节点表示,其词向量的维度是768。对于实体的选择,每个文档选择前10 个关键短语。在异构图注意力模块设置头数K= 8。每个头中句子节点的隐藏向量维度为128,最终连接节点向量的维度为768。采用ROUGE(Recall‑Oriented Un‑derstudy for Gisting Evaluation)中的RG‑1、RG‑2和RG⁃L。
在训练过程中,实验设置训练的批量大小为32,训练轮次24,使用Adam 优化器,设置学习率为5e-4。
2.2 实验结果分析
2.2.1 基准模型
为证明EHGA 模型的有效性,将其与几个优秀的文本摘要模型进行比较。
(1)Lead‑n:选取文中前n个句子作为文章摘要,常用于新闻领域。
(2)TextRank[14]:以句子间相似度构建图模型。
(3)Summer RuNNer[15]:是基于序列分类器的循环神经网络对句子分类训练模型,采用两层双向GRU(gate recurrent unit)和循环神经网络(recurrent neural network,RNN)来对句子进行编码。
(4)BERTSum[16]:采用预训练模型BERT 获取文档中每个句子的句向量编码,通过贪心策略选择最优的top‑n个句子。
2.2.2 模型检测
本实验以ROUGE 评分体系作为文本自动摘要的评价标准,采用ROUGE‑N(N 为N‑gram),ROUGE‑L,ROUGE‑S 等数值作为对当前所得摘要的评价,其计算方式如下:
2.2.3 基线模型结果分析
本组实验是在民航事故调查跟踪报告数据集上进行EHGA 模型与上述4 个模型对比,结果如表2 所示。可以看到,EHGA 模型与其他模型相比ROUGE 指标提升显著,证明EHGA 具有更好的摘要效果。
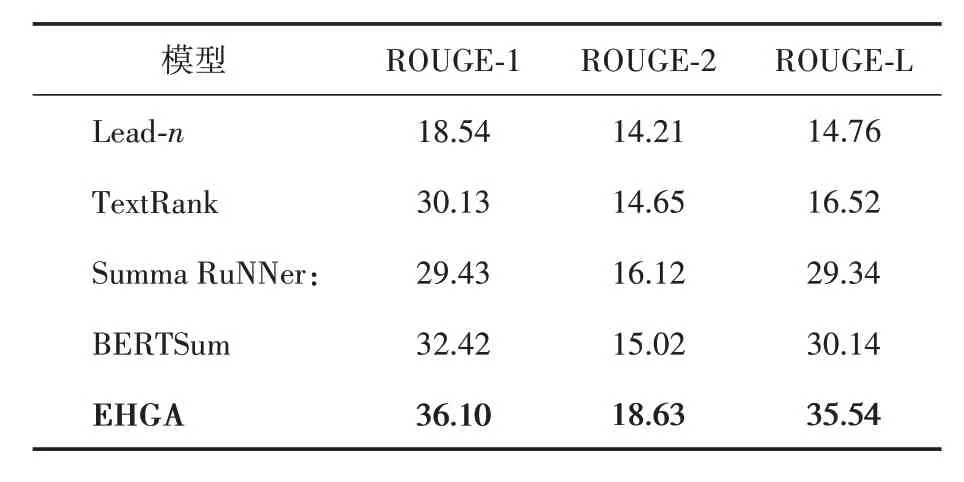
表2 基线模型对比试验
EHGA 模型通过采用异构图来融入内部信息实体节点,可以有效丰富模型的语义信息,提高摘要性能,并且依照实体更贴近原文内容;同时图结构可以跨越简单上下文的关系而获得更远距离的语义信息,对抽取处更贴近原文的句子具有指导作用。与Lead‑n 模型相比,选取前n句作为摘要时更适合有总结句的文本,而航空事故报告是平铺直叙,显然不适合。与Text‑Rank 相比,EHGA 模型以实体要素作为句子关键程度的指标,重点关注的是句子,而TexkRank 更加关注关键词,偏离原文主旨。与SummaRuNNer 相比,EHGA 模型引入实体要素辅助模型理解文本含义,而SummaRuNNer 则只依靠神经网络学习文本特征,使得模型会过分关注某一方面而造成文本冗余。
2.2.4 消融实验
为验证EHGA 模型中各个模块的效果而开展了消融实验,实验结果如表3所示。EHGA 是在图神经网络(GNN)的基础上增加了实体要素节点,效果较GNN 在ROUGE‑1,ROUGE‑2 和ROUGE‑L 3 种评价指标上均有明显提高。说明增加实体要素可以使模型尽可能关注到与实体相关的句子,而达到专有名词指导文本摘要生成效果。其实验结果如表3所示。
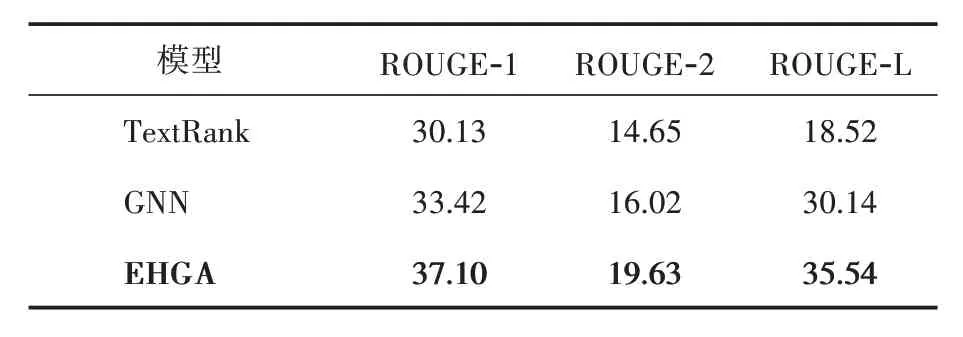
表3 消融实验对比
2.2.5 案例展示
为进一步展示EHGA 模型的实验效果,以“美国航空公司MD-82 飞机圣路易斯发动机起火事故调查报告”为例对输出摘要进行评价分析,具体如表4。

表4 抽取式摘要样例展示
通过表4的样例展示,EHGA 模型依据实体要素能够较为全面地概括报告内容,实体要素的加入能够在图注意力机制中筛选出与事故关联性强的句子,能够扩大信息的覆盖范围,关注不同层次信息,多维度概括文本内容,因此可见实体信息对于文本摘要的生成具有指导意义。
3 结语
EHGA 模型针对民航事故调查跟踪报告,提出基于实体要素异构图注意力机制抽取式摘要模型。把词语、实体和句子构建为异构图,以注意力机制获得句子重要程度,联合评分机制获得最终摘要。实验证明,针对事故报告这一特定领域的摘要任务,融入实体要素能够提升摘要选择覆盖度和准确性,生成高质量摘要。同时也验证了,基于异构图网络进行文本数据分析,更加关注句子间隐含的深层关系。
同样,在研究过程中发现人工摘要存在大量总结式、概括式和推理式词语,这些无法在原文中找到对应,无疑给抽取式摘要带来极大的挑战。因此在下一步研究中,拟继续在异构图中添加更多外部知识,提升摘要性能。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
现代语文(2016年21期)2016-05-25
通信电源技术(2016年6期)2016-04-20
