
奖赏预测误差对项目和联结记忆影响的分离:元记忆的作用*
2023-06-07 01:53龙翼婷姜英杰
心理学报 2023年6期
龙翼婷 姜英杰 崔 璨 岳 阳
奖赏预测误差对项目和联结记忆影响的分离:元记忆的作用*
龙翼婷1姜英杰1崔 璨2岳 阳1
(1东北师范大学心理学院, 长春 130024) (2江苏省脑疾病与生物信息重点实验室, 徐州医科大学生物化学与分子生物学研究中心, 徐州 221004)
选取奖赏预测误差(reward prediction error, RPE)效价和凸显性为自变量, 通过3个实验考察RPE对项目和联结记忆影响的差异及其元记忆机制。被试在对图片的奖赏猜测−奖赏反馈中形成RPE, 且需要同时记忆图片(项目)以及图片−奖赏联结, 最后进行记忆测试。结果表明, (1)联结记忆成绩存在RPE正效价和低凸显性优势, 其信心判断准确性在RPE正效价时更高, 而项目记忆成绩存在RPE负效价和高凸显性优势; (2)在编码过程中, RPE正效价和低凸显性提高了个体的瞳孔变化均值和峰值; RPE低凸显性增加了分值注视时间, 缩短了图片注视时间; (3)增加RPE水平后, RPE对项目和联结记忆成绩的分离影响仍稳定存在。这些结果表明, RPE对项目和联结记忆的影响存在分离: 编码阶段中, 个体以RPE效价和凸显性为线索, 通过元记忆控制对项目和联结记忆加工中的认知资源进行差异性分配; 提取阶段中, RPE正效价提高了对联结记忆提取的元记忆监测水平。
奖赏预测误差, 联结记忆, 眼动, 情景记忆, 元记忆
1 引言
情景记忆(episodic memory)是指个体对亲身经历过的发生在特定时间和地点的事件的记忆(Tulving, 2001)。其中的项目记忆(item memory)是对情景中单个项目的记忆, 而联结记忆(associative memory)需要通过绑定加工(binding)将多个项目或特征进行整合(Murty et al., 2016)。在日常生活中, 认知资源的有限性使个体难以对情景中的全部信息进行加工, 为了使此刻的经验有助于将来的行动, 个体通常会在编码中把认知资源分配给更有价值的信息, 因此同时呈现的项目和联结记忆信息可能会因认知资源竞争被差异性加工。
有研究发现奖赏结果引起了个体对项目和联结记忆的差异性加工。Murty等(2016)使用独裁者范式, 学习阶段的每个试次中, 独裁者拥有$10, 可以分配给自己和被试, 告知被试其中某个独裁者所分配金额将被付现, 且之后还将见到这些独裁者面孔。为获得更多收益, 被试在学习阶段需利用有限的认知资源, 同时对面孔(项目)及其价值信息(项目−奖赏联结)进行记忆, 能够体现奖赏如何影响情景中的不同记忆成分。记忆测试的结果表明, 在独裁者事件中, 项目记忆受奖赏影响不显著, 但低奖赏结果促进了个体联结记忆的提高。
另有研究考察了奖赏预测误差(reward prediction error, RPE)对项目记忆和联结记忆的影响(Ergo et al., 2021; Rouhani et al., 2018; Rouhani et al., 2020)。RPE是奖赏结果减去奖赏预期后的差值, 有效价和凸显性两个属性(Mason et al., 2019)。效价(valance)代表奖赏结果高于还是低于奖赏预期, 正效价代表奖赏结果优于奖赏预期, 负效价代表奖赏结果低于奖赏预期(Ergo et al., 2020)。凸显性(salience)代表奖赏结果和奖赏预期间的偏离程度, 可以用无符号的奖赏预测误差(unsigned RPE, URPE) 表示, URPE越大代表结果与预期的偏离程度越大, 个体的意外程度越高(Rouhani et al., 2018)。RPE的效价和凸显性都会对情景记忆产生影响。
Rouhani等(2018)在学习阶段让被试对图片进行奖赏预期并获得奖赏反馈结果, 习得图片的奖赏规律(其中一类图片出现高奖赏的比率更大), 告知被试在随后的决策阶段中需要在每两张图片中进行选择并获得其奖赏; 决策阶段后对被试进行了记忆测试。以反馈结果与奖赏预期之差作为RPE, 以URPE作为RPE凸显性, 结果表明, RPE对项目记忆(图片再认)影响不显著, 但URPE显著提高了项目记忆成绩, 说明项目记忆只受到了RPE凸显性的影响。之后Rouhani等(2020)将学习阶段换成被动的顺序奖赏任务, 屏幕上会连续呈现若干带有不同分值的图片, 分值的10%被累计到被试收益中, 由分值分布的变化产生RPE, 仍然发现了项目记忆的RPE高凸显性优势。此外, 该研究在实验4中让被试对图片呈现时序进行记忆, 最后的时序联结记忆成绩表现出RPE低凸显性优势。表明RPE凸显性可能引起了对项目和联结记忆的差异性加工。
但在上述研究中, 只有项目记忆能影响决策收益, 因此在编码阶段, 被试将以RPE凸显性为线索,对图片编码优先投入认知资源, 其次才对图片时序进行学习, 这意味着联结记忆成绩可能主要取决于项目记忆对认知资源的占用情况, 而非受到RPE的直接影响。不同的是, 一些研究将联结记忆作为主要任务(外语−母语词对联结:Calderon et al., 2021; 人物−物品联结:Aberg et al., 2017), 结果都发现了联结记忆中的RPE正效价优势, 却并未能验证RPE凸显性的影响。Aberg等(2017)虽然发现预期与结果偏差更小(RPE凸显性更小)的条件下被试的联结记忆成绩更高, 但实验中该条件下得到正性结果的几率也更大(RPE效价更正), 因此难以分辨出联结记忆成绩的提高是否能归因于凸显性的影响。
综上, 已有研究发现奖赏预测误差对项目和联结记忆的影响存在差异, 项目记忆表现出高凸显性优势, 联结记忆表现出正效价优势, 但凸显性是否对联结记忆存在影响还有待考察。人类情景中通常同时涉及项目和联结成分, 它们需要竞争有限的认知资源, 奖赏会改变个体对这些成分的认知资源投入, 因而项目和联结记忆受奖赏的影响表现出差异性(Murty et al., 2016)。但在探究RPE对情景记忆的影响时, 先前研究对项目和联结记忆分开考察, 实验往往只包含单一记忆任务, 难以探讨RPE对项目和联结记忆影响的差异, 更无法进一步揭示该差异产生的原因——即RPE对认知资源分配的影响。因此本研究参考Murty等(2016)的研究, 以图片和图片−奖赏联结分别作为项目和联结记忆指标, 考察个体如何基于RPE同时进行项目记忆和联结记忆加工。
记忆编码中个体对认知资源投入的调节, 是元记忆控制过程的体现, 为揭示奖赏对这一过程的影响, 价值导向元记忆(value-directed metamemory)研究中采用眼动技术追踪被试对特定兴趣区中的刺激的注视时间(fixation duration)作为学习时间分配(study-time allocation)的指标, 发现高价值刺激比低价值刺激获得了更长的学习时间, 表明个体会优先对高价值项目分配认知资源(姜英杰等, 2016)。瞳孔扩张也与认知资源投入有关, 学习者编码信息的心理努力更大时(此时认知资源投入更多), 瞳孔扩张会增大, 记忆效果提高(Ariel & Castel, 2014)。因此本研究采用眼动追踪技术, 通过注视时间和瞳孔直径变化两个指标, 考察RPE影响项目和联结记忆编码的元记忆控制过程, 作为RPE效应产生的认知机制。
因此, 本研究通过3个实验考察RPE的效价和凸显性对同时呈现的项目记忆和联结记忆的影响及其元记忆机制。其中实验1比较了不同RPE水平下项目和联结记忆成绩的差异, 并通过信心判断考察了RPE对提取阶段元记忆监测的影响, 基于Rouhani等(2020)的结果, 实验1假设项目和联结记忆受RPE影响的方向相反, 且RPE能够促进记忆提取中的信心判断准确性。在实验1的基础上, 实验2通过眼动技术考察编码阶段中RPE如何影响元记忆控制过程, 我们预期, 项目编码和联结编码存在认知资源竞争, RPE对二者的影响方向与记忆成绩的结果相符。在实验1和2中, 奖赏结果只有1、4和7三个水平, RPE正负效价分别与7和1两种结果存在较大的重叠, 为减小RPE效价和奖赏结果影响的重叠, 增加结果的可重复性, 补充进行实验3, 在实验1的基础上增加RPE水平, 验证记忆中的RPE效应, 预期其结果会与前两个实验一致。
2 实验1:奖赏预测误差对项目和联结记忆成绩的影响
实验1的目的是考察RPE效价和凸显性如何影响项目和奖赏联结记忆。
2.1 方法
2.1.1 被试
招募被试36人, 剔除了其中2名(项目记忆成绩低于随机水平), 保留被试34人(女性24人), 年龄19~25岁(= 22.11岁,= 1.98岁), 视力或矫正视力正常, 无神经系统和心理疾病病史。所有被试均自愿参加实验, 并签署被试知情同意书。每名被试获得真实现金奖励平均约为21元。
2.1.2 实验材料
刺激材料为120张室内和户外场景图片(Höeltje & Mecklinger, 2020), 整个实验过程中的刺激均呈现在白色背景上。通过E-prime 3.0进行实验编程。
考虑到个体对奖赏加工的差异能够调节RPE效价对记忆的影响(Aberg et al., 2017; Rouhani & Niv, 2019), 在学习和测试的间隔时间内, 让被试填写汉化版的奖惩敏感性量表(sensitivity to punishment and sensitivity to reward questionnaire, SPSRQ)。SPSRQ包括惩罚敏感性(SP)和奖励敏感性(SR)两个分量表, 要求被试做出“是”或“否”的回答。汉化版SPSRQ由郭永香等(2011)进行修订, 共31道题目, 其中SP有19个项目, SR有12个项目。汉化版SPSRQ中SP和SR在本研究中的内部一致性信度分别为0.85和0.70。
2.1.3 实验设计
采用被试内设计, 自变量为RPE效价和凸显性, 因变量为项目和联结记忆成绩。
实验1中奖赏结果包含1、4和7三种分值, 它们在高、低价值图片中的比例分别是2 : 3 : 5和5 : 3 : 2。由奖赏结果和被试的给出的猜测价值之差产生RPE, 共有−6、−3、0、3和6五种分值, 效价为其正负符号, 凸显性为URPE。
2.1.4 实验流程
包含价值学习和记忆测试两个阶段, 总体流程如图1。参考Rouhani等(2018)的实验范式, 价值学习阶段以室内和户外风景图片为学习材料, 其中一类图片出现高分值结果的概率更大。在学习阶段, 让被试对图片进行奖赏预测并获得奖赏结果的反馈, 通过这样的强化学习探索图片分值规律, 所有分值的30%将累计入总分值中; 告知被试之后有在每两张图片中进行决策并获得其价值的机会, 以此产生奖赏动机对记忆的影响, 但实际的程序并不包括决策阶段, 学习阶段后直接对被试进行项目和奖赏联结记忆测试, 并给出对其回忆结果的信心判断(judgements of confidence, JOCs)。
学习阶段。在400~600 ms的注视点后, 屏幕上呈现一张室内或户外场景图片3秒, 这3秒之内不需按键。图片消失后, 进入价值猜测, 电脑询问被试“你猜测这张图片分值为多少?”并给出可选项为1、4或7分(分别对应左、下、右方向键), 要求在3秒内按键作答。随后询问被试对于猜测的信心判断值, 并按Z、X、C或V键进行反应(分别对应“猜的”、“有点确定”、“相当确定”或“完全确定”), 要求在3秒内按键反应。按键之后, 屏幕上再次呈现图片及其价值结果(如“+7”), 呈现3秒。正式实验包括60个试次, 在此之前, 被试需要完成6个练习试次, 以确保完全理解指导语。
学习阶段之后, 要求被试填写汉化版的SPSRQ, 然后进行连续减3的干扰任务, 以填充学习和测试间的5分钟间隔。
最后进入未被提前告知的测试阶段。首先呈现一个400~600 ms的注视点, 随后呈现一张场景图片, 图片下方出现新旧两个选项, 被试需要在5秒内按左右方向键进行反应, 并在之后的3秒内按Z、X、C或V键做出信心判断(猜的、有点确定、相当确定或完全确定)。然后进入价值回忆, 屏幕上再次呈现该场景图片, 图片下方出现1、4和7三个价值选项, 被试需要在5秒内按方向键作答, 并在之后的3秒内给出信心值(猜的、有点确定、相当确定或完全确定)。回忆阶段的正式实验包含60张旧图像和60张新图像, 在此之前, 被试需要完成12个试次的练习。

图1 实验1流程图
2.1.5 数据整理与分析方法
项目记忆成绩为对旧图片的再认结果(正确计分为1, 错误计分为0), 联结记忆成绩为项目再认正确试次中被试对价值反馈的回忆结果(正确计分为1, 错误计分为0), JOCs中猜的、有点确定、相当确定、完全确定分别记分为1、2、3、4。对于SPSRQ分数, 首先将SR分数和SP分数转换为值, 再将二者相减得到奖惩敏感性差值分数。
参考前人的分析方法(Rouhani et al., 2018), 通过R软件的广义混合效应线性模型对行为数据进行分析, 始终将被试作为随机截距项放入所有模型分析。以往多数研究只将RPE作为预测因子, 忽略了奖赏结果本身的影响(Ergo et al., 2020; Jang et al., 2019; Rouhani et al., 2018), 但奖赏结果和RPE两种奖赏成分都可能影响情景记忆, 且RPE正效价往往对应着高奖赏结果, 两种效应存在混淆, 因此本研究将同时对这两种奖赏成分进行分析, 在考察RPE和URPE的影响时, 始终将奖赏结果作为另一预测因子放入模型。若因变量为分类变量(即项目记忆和联结记忆准确性), 使用广义混合效应线性模型(lme4包中的glmer函数)进行分析; 若因变量为连续变量(即项目记忆和联结记忆JOCs), 使用混合效应线性模型(nlme包中的lme函数)进行分析。当对多个因子的影响进行分析时, 报告拟合程度最好(即AIC值最低)的公式中的效应, 如某些情况下, 考虑进因子间显著的交互作用后, AIC值更低, 则同时报告因子的主效应及其交互作用。在线性模型分析结果中, RPE的主效应显著则表明存在RPE效价效应, URPE的主效应显著则表明存在凸显性效应。对于交互作用, 通过将主效应项值乘积的符号与交互作用项值的符号进行对比, 符号相反时的交互作用被描述为负向交互作用, 此时一个变量的增长会削弱另一个变量的效应量; 符号相同时则被描述为正向交互作用, 此时一个变量的增长会增大另一个变量的效应量。
2.2 结果分析
2.2.1 奖赏预测误差对情景记忆成绩的影响
删去学习阶段中被试未做出价值猜测按键的试次后, 不同RPE条件下, 项目和联结记忆击中率的均值和标准差如表1所示, RPE和奖赏结果对记忆成绩的影响如图2所示。
对记忆成绩进行分析(表2)发现, 奖赏结果(= 0.610)和RPE (= 0.217)对项目记忆的影响不显著, URPE (= 0.070)的影响也只达到了边缘显著水平, 表明项目记忆只有随凸显性增大而提高的趋势。对于联结记忆, 奖赏结果(= 0.002)和RPE (< 0.001)主效应均显著, 表明高奖赏结果和RPE正效价都会促进联结记忆成绩的提高, 且两者存在显著的负向交互作用(= 0.001), 表明随着奖赏结果的增大, RPE效价的效应会减弱; URPE的影响也显著(< 0.001), 联结记忆成绩在低凸显性时更高。

表1 实验1项目和联结记忆击中率均值和标准差(n = 34)
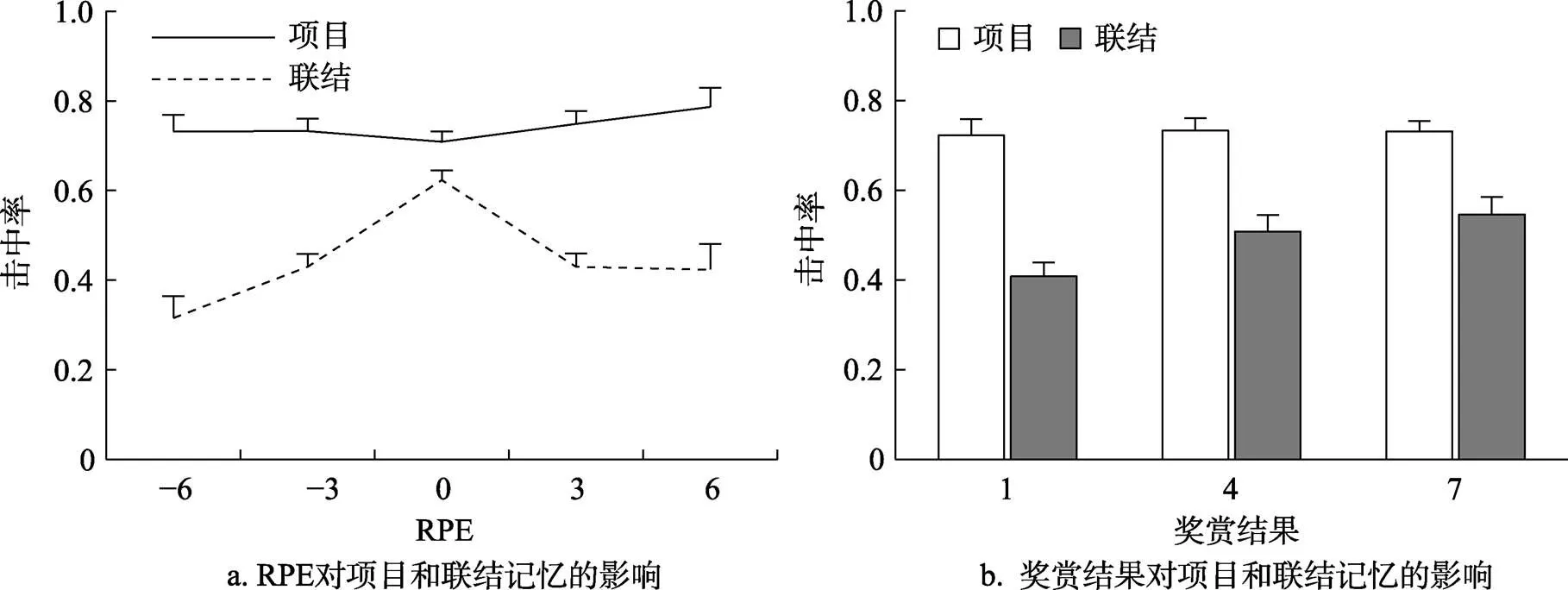
图2 实验1奖赏(a为RPE, b为奖赏结果)对项目和联结记忆击中率的影响(误差线为标准误)
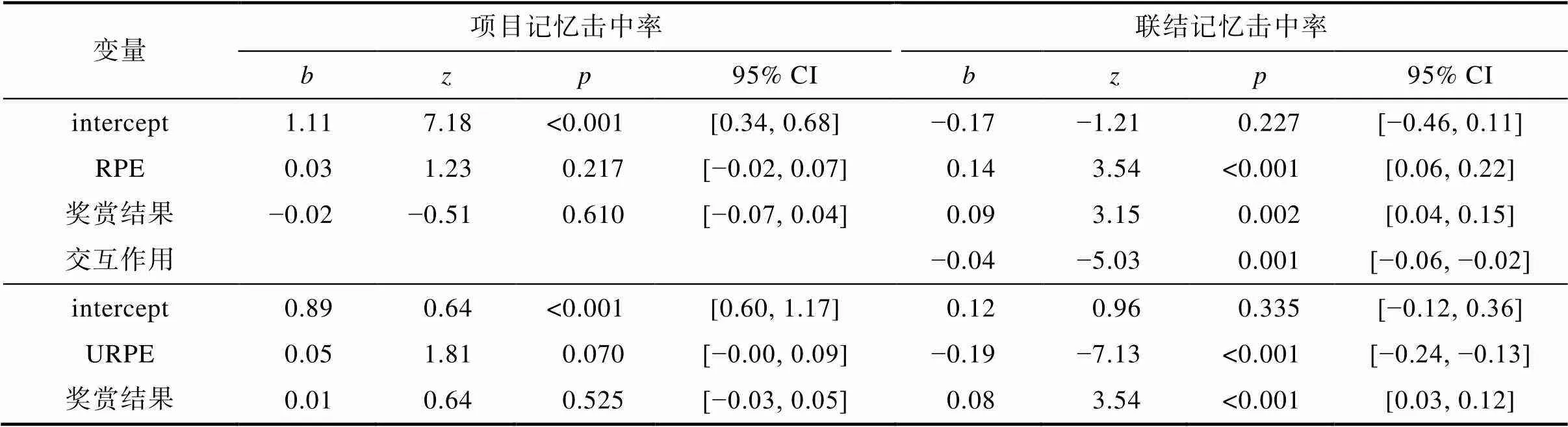
表2 实验1项目和联结记忆击中率广义混合线性模型分析结果
对再认正确试次的反应时进行分析(表3), 结果只发现了奖赏结果的增大对联结记忆提取速度的显著促进作用(= 0.002)。
将正负RPE效价间的项目记忆和联结记忆成绩分别作差, 再将该差值与奖惩敏感性差值进行相关分析。结果发现, 奖惩敏感性差值与项目记忆成绩差值的相关并不显著(= −0.25,= 0.147), 但与联结记忆成绩差值的相关显著(= 0.39,= 0.022), 对奖赏更敏感同时对惩罚更不敏感的被试, 在RPE正效价时的联结记忆成绩会更高于负效价时。
2.2.2 奖赏预测误差对信心判断的影响
删去一名未理解信心判断指导语的被试(全部选择了完全确定选项), 并删去被试在学习阶段没有做出价值预期以及在测试阶段未做出信心判断的试次后, 在不同RPE条件下, 不同记忆结果下中项目记忆和联结记忆JOCs的均值和标准差如表4所示, 错误和正确回忆试次中RPE对JOCs的影响如图3所示。
对于项目记忆JOCs, 首先, 项目记忆结果的影响显著(= 0.76,= 17.48,< 0.001, 95% CI = [0.68, 0.85]), 再认正确时的信心值比再认错误时更高。值得注意的是, 这种记忆结果的主效应体现的是JOCs的准确性, 若其他变量和记忆结果有显著的交互作用, 则表明该变量能够影响JOCs准确性。在将记忆结果作为预测因子的基础上, 分别对RPE和URPE进行混合线性回归分析(表5)。结果发现, 三个奖赏成分与记忆结果的交互作用都不显著(s > 0.100)。
对于联结记忆JOCs, 联结记忆结果的影响同样显著(= 0.26,= 5.47,< 0.001, 95% CI = [0.16, 0.35]), 当联结回忆正确时, 被试的信心判断值更高。在将回忆结果作为预测因子的基础上, 再分别对RPE和URPE的影响进行混合线性回归分析(表5)。结果发现, 奖赏结果(= 0.005)和RPE (= 0.029)分别与记忆结果的正向交互作用显著, 表明奖赏结果和RPE效价对联结记忆JOCs准确性存在显著影响, 奖赏结果升高和RPE正效价都促进了联结JOCs准确性的提高。但URPE与记忆结果交互作用不显著(= 0.817)。
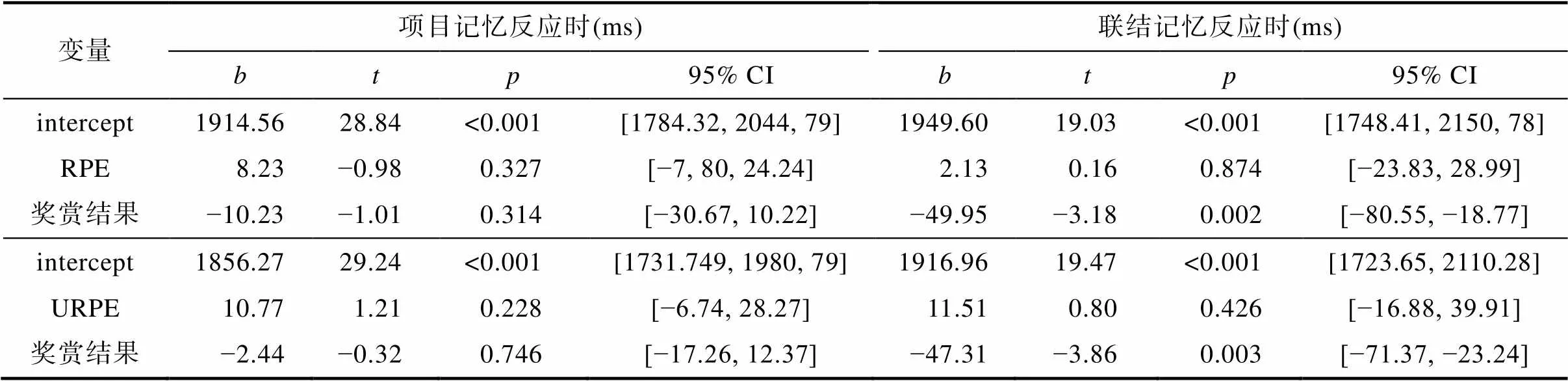
表3 实验1项目和联结记忆反应时广义混合线性模型分析结果
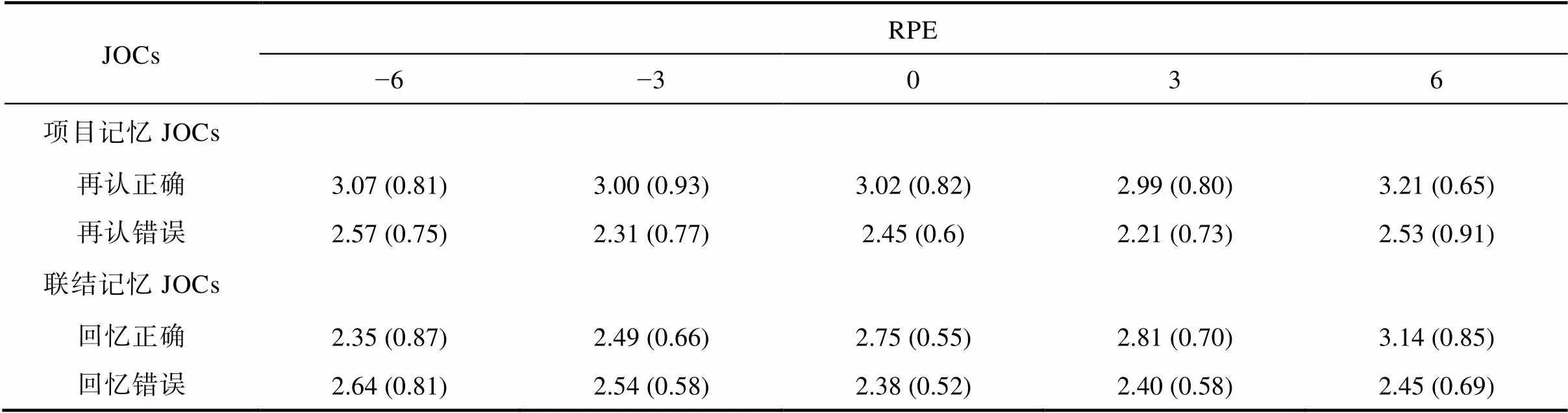
表4 项目和联结记忆JOCs均值和标准差(n = 33)
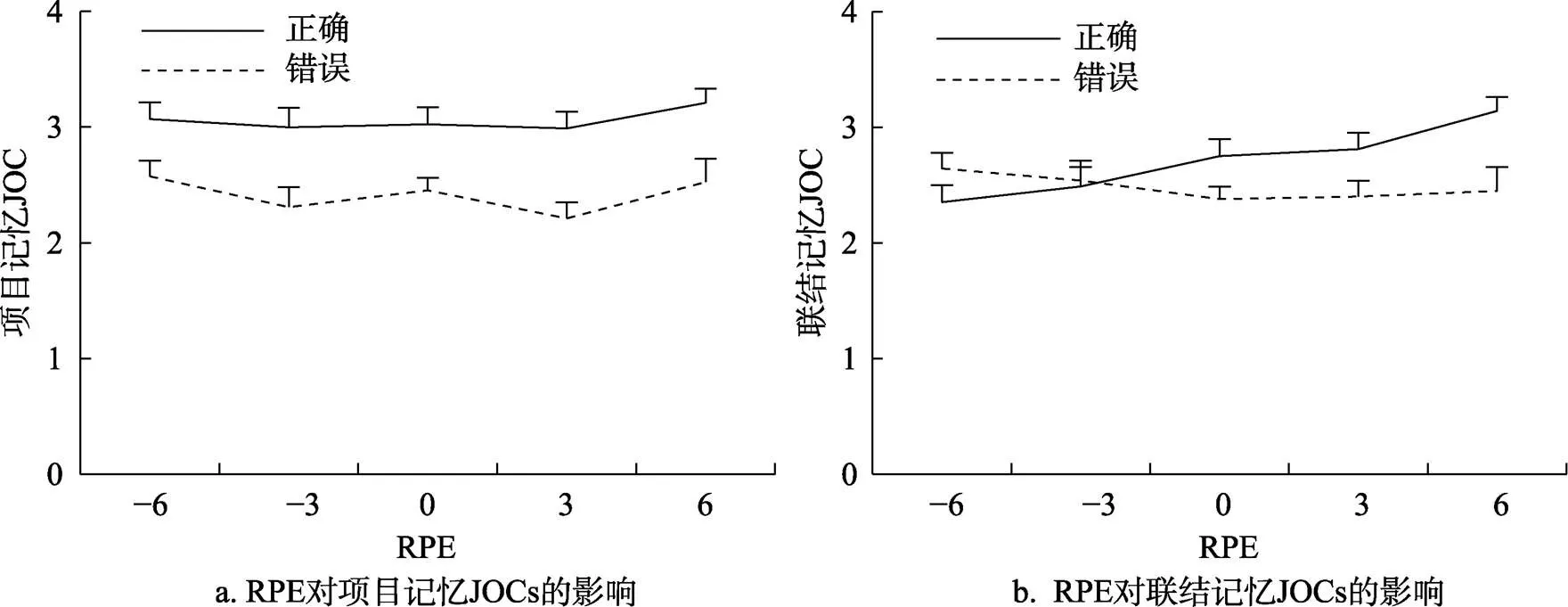
图3 实验1 RPE对项目(图a)和联结记忆(图b)JOCs的影响(误差线为标准误)
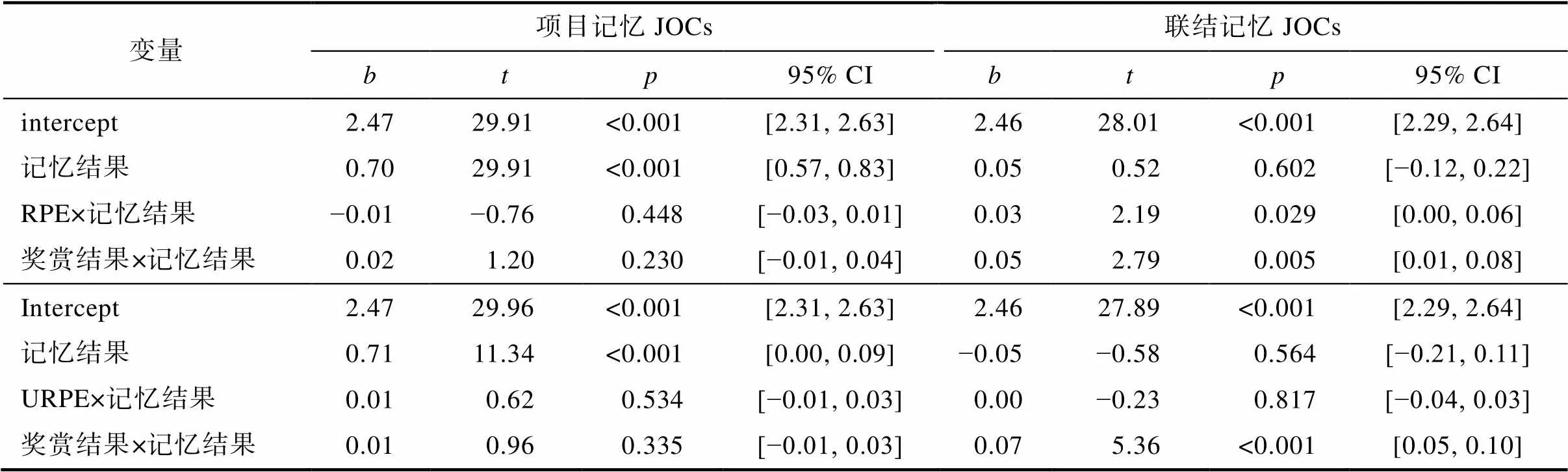
表5 实验1 JOCs混合线性模型分析结果
2.3 讨论
实验1中, 不同奖赏条件下的项目记忆成绩相似, 只存在项目记忆随RPE凸显性升高而增大的趋势。这可能是由于预期阶段时长为3s, 导致被试在预期阶段就已对图片进行了较深编码, 而在反馈阶段更多地编码联结信息, 从而削弱了反馈阶段产生的RPE对项目记忆编码的影响。但前人使用相似程序(Rouhani & Niv, 2021), 却仍发现了URPE对项目记忆的显著影响, 究其原因, 前人研究中分值为1至100间的连续整数列, 而本研究只包含1、4和7三个分值选项, 奖赏信息加工对认知资源的占用更小, 有利于个体更充分对图片进行加工。
不同的是, 考虑了奖赏结果增大对联结记忆成绩的促进效应后, 我们仍发现了联结记忆中明显的RPE正效价和低凸显性优势。此外, 个体特质可能会通过影响奖赏的动机作用而改变记忆成绩(Aberg et al., 2017; Rouhani & Niv, 2019), 奖惩敏感性差值的分析结果表明, 相比于受奖赏动机的激励更弱的人, 受奖赏动机的激励更强的个体在面对RPE正效价时, 联结记忆成绩会更高。
反应时反映了记忆提取的流畅性, JOCs反映了记忆提取中的元记忆监测准确性。奖赏对联结记忆的提取过程有重要影响, 一方面, 奖赏结果的增大提高了联结记忆提取的流畅性, 另一方面, 联结记忆提取中的元记忆监测在高奖赏结果和RPE正效价时更准确, 且RPE正效价时准确性也更高。
3 实验2:奖赏预测误差对项目和联结编码中眼动的影响
在实验1的基础上, 实验2采用眼动技术, 考察RPE效价和凸显性对项目和联结记忆编码过程中元记忆控制的影响。实验1过长的预期阶段导致了项目记忆成绩的阴性结果, 因此实验2中将学习阶段的预期阶段时间由3 s变为2 s, 相应地将反馈阶段时间由3 s延长到4 s, 以增强反馈阶段的奖赏信息对记忆的影响。
3.1 方法
3.1.1 被试
考虑到眼动分析中会剔除部分记录失误的试次, 实验2将学习阶段的试次数由60增加到100, 相应减小了被试量。共招募被试23人, 其中女性17人, 年龄为17~23岁(= 19.79岁,= 1.89岁), 视力或矫正视力正常, 无神经系统和心理疾病病史。所有被试均自愿参加实验, 并签署被试知情同意书。每名被试获得真实现金奖励平均约为28元。
3.1.2 实验材料与仪器
刺激材料和量表与实验1中相同。采用Eyelink1000Plus塔式眼动仪, 采样率为1000 Hz。屏幕刷新率为60 Hz, 分辨率为1920×1080像素, 被试眼睛与屏幕间距离为76 cm, 所有刺激都呈现在深灰色背景上, 图片大小为600×400像素, 记录右眼的眼动轨迹。
3.1.3 实验流程
实验流程(图4)和指导语与实验1相似。不同的是, 调整学习阶段各屏的呈现时间, 预期阶段图片仅呈现2秒, 而反馈阶段图片呈现时长改为4秒, 且除了每个试次开始时的注视点外, 每两屏间都还有一个600~800 ms的注视点空屏, 试次结束后还有一个800~1200 ms的注视点空屏。学习阶段包括100试次, 测试阶段包括200试次。完成练习试次后, 先进行九点模式校准, 要求平均误差低于0.5°, 成功校准后, 实验开始。
在学习阶段的价值反馈屏收集眼动数据。一方面, 以图片和分值区域为兴趣区, 分别收集被试的注视时间; 另一方面, 记录该屏内被试的瞳孔直径。
3.2 结果分析
3.2.1 奖赏预测误差对情景记忆成绩的影响
删去学习阶段被试没有做出价值猜测的试次后, 不同RPE条件下, 项目和联结记忆击中率的均值和标准差如表6所示, RPE和奖赏结果对记忆击中率的影响如图5所示。
对记忆成绩进行分析(表7)。对于项目记忆, 首先, 奖赏结果(< 0.001)和RPE (< 0.001)主效应均显著, 且两者存在显著的负向交互作用(= 0.002), 高奖赏结果和RPE负效价都促进了项目记忆的提高, 但效价效应会随着奖赏结果的增大而被削弱。其次, URPE的影响也显著(< 0.001), 项目记忆成绩随RPE凸显性增高而提高。联结记忆成绩的结果与实验1相同, 奖赏结果(< 0.001)、RPE (= 0.002)和URPE (< 0.001)的影响均显著, 且RPE与奖赏结果的负向交互作用显著(< 0.001), 联结记忆成绩受到高奖赏结果的促进, 且存在RPE正效价和低凸显性优势, 其中效价效应会受高奖赏结果的削弱。
对再认正确试次的反应时进行分析(表8), 只发现了URPE对联结记忆反应时的显著影响(= 0.011), RPE凸显性的减小促进了联结记忆提取速度的提高。
奖惩敏感性差值与正负效价间项目记忆成绩差值(= −0.05,= 0.840)和联结记忆成绩差值(= −0.11,= 0.630) 的相关都不显著。
3.2.2 奖赏预测误差对编码阶段眼动的影响
删去眼动数据收录过程中校准失败的3名被试, 对于剩余20名的被试, 删去眨眼过多或对分值注视时间小于50 ms的试次, 描述统计结果如表9所示。对图片和分值注视时间以及瞳孔直径变化的混合线性模型分析结果如下(见表10)。

图4 实验2流程图(在价值反馈屏收集眼动指标, 流程图中以绿色框标出)

表6 实验2项目和联结记忆击中率均值和标准差(n = 23)
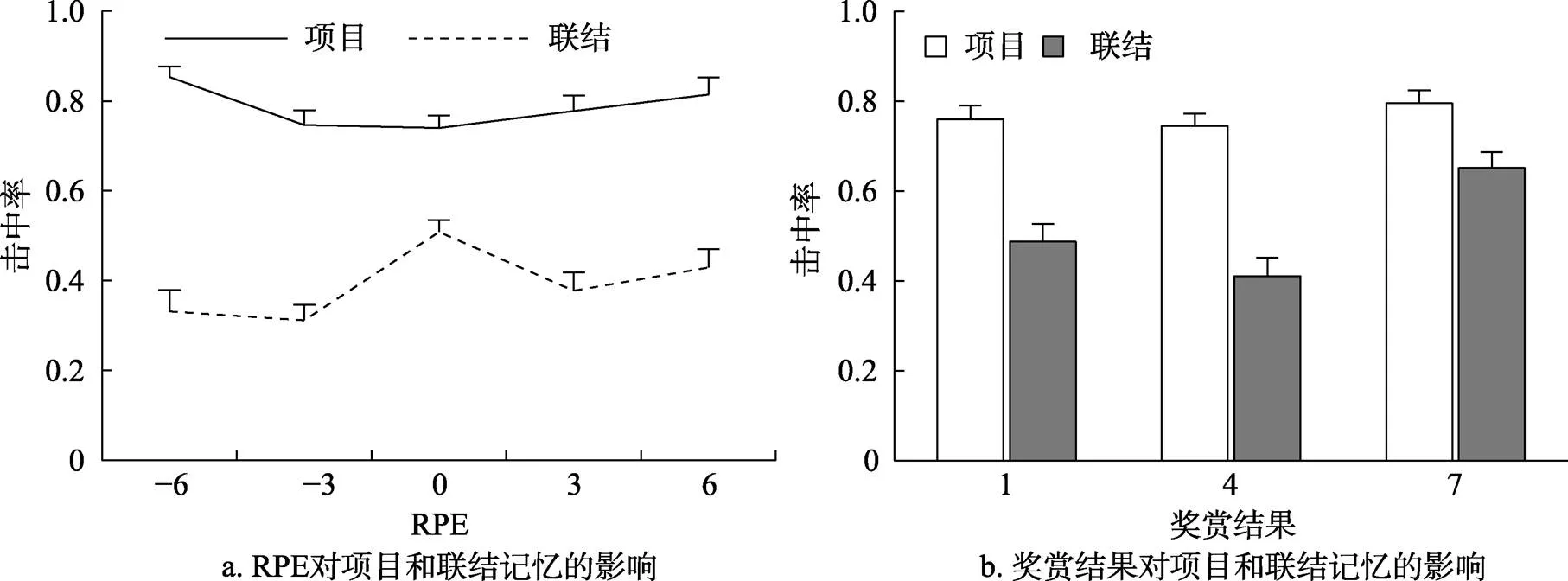
图5 实验2 奖赏(a为RPE, b为奖赏结果)对项目和联结记忆击中率的影响(误差线为标准误)
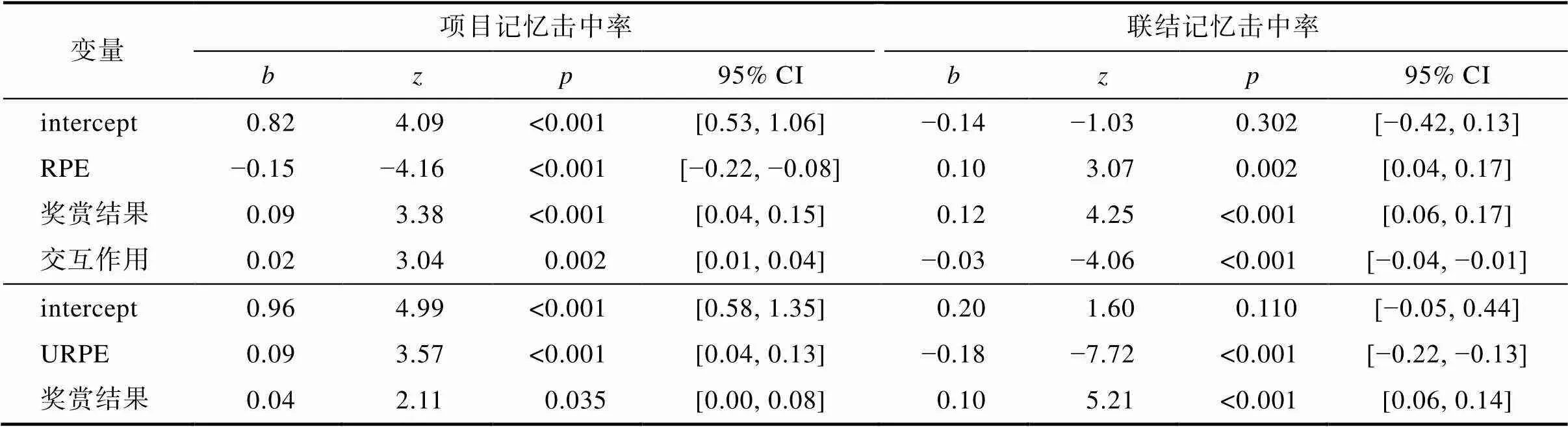
表7 实验2项目和联结记忆击中率广义混合线性模型分析结果
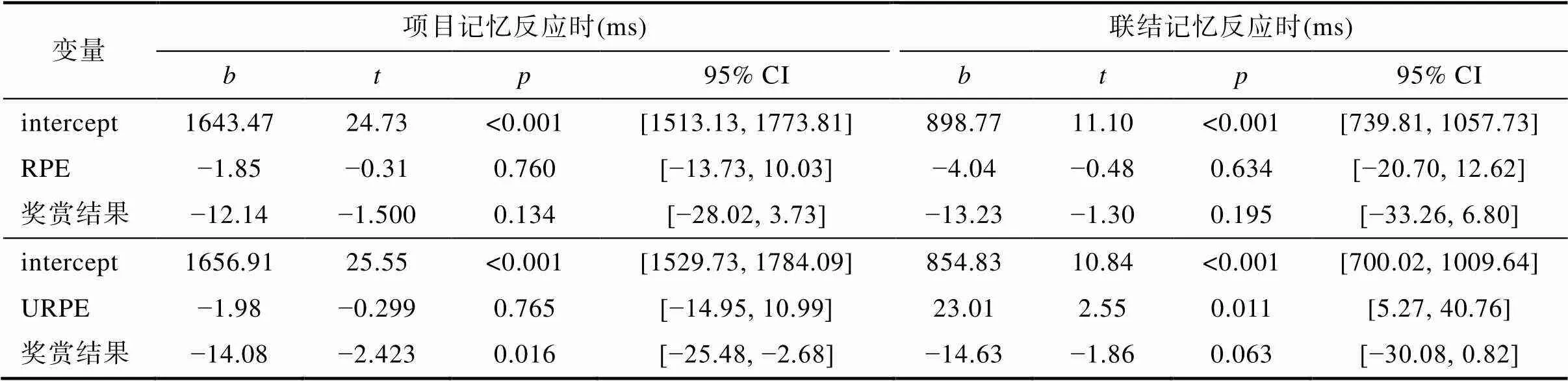
表8 实验2项目和联结记忆反应时广义混合线性模型分析结果

表9 实验2注视时间(ms)和瞳孔变化(μm)的均值和标准差(n = 20)

表10 实验2眼动结果的混合线性模型分析结果
考察RPE对图片和分值注视时间的影响。结果发现, URPE对图片注视时间影响显著(= 0.016), RPE凸显性的增大会使图片注视时间延长。URPE对分值注视时间也有显著影响(= 0.006), RPE凸显性更小时, 被试对分值的注视时间越长。奖赏结果和RPE对图片注视时间的影响都不显著, 奖赏结果和RPE对分值注视时间的影响也都不显著(s > 0.100)。
首先进行瞳孔基线校正, 选取价值反馈屏呈现前500 ms的平均瞳孔直径作为基线, 通过减法换算(瞳孔变化值 = 反馈屏瞳孔大小 − 基线值), 得到校正后的瞳孔变化平均值和最大值(杨晓梦等, 2020)。考察RPE对瞳孔变化的影响, 结果发现, 对于瞳孔变化平均值, RPE (= 0.002)和URPE (= 0.003)的主效应显著, 且奖赏结果和RPE有显著正向交互作用(= 0.023), 奖赏结果和URPE也有显著正向交互作用(= 0.034), 表明RPE正效价和低凸显性都促进了瞳孔变化平均值的增加, 同时奖赏结果的增大会增强效价和凸显性的效应。对于瞳孔变化最大值, 奖赏结果(= 0.037)、RPE (< 0.001)和URPE (= 0.003)的主效应显著, 且奖赏结果和URPE有显著正向交互作用(< 0.001), 表明RPE正效价和低凸显性都促进了瞳孔变化最大值的增加, 同时奖赏结果的增大会增强凸显性的效应。
3.3 讨论
在缩短预期阶段时长, 并延长反馈阶段的呈现时间之后, 实验2发现, 项目记忆中存在RPE负效价与高凸显性优势, 与我们的预期相符。项目记忆对价值反馈阶段认知资源的竞争并没有改变联结记忆中的RPE效应, 实验2再次验证了联结记忆中的RPE正效价和低凸显性优势。
眼动指标反映了元记忆控制过程, 其中注视时间反映了个体对不同刺激的学习时间分配(姜英杰等, 2016), 主要受到了RPE凸显性的影响。当RPE凸显性更低时, 被试采取优先编码联结信息的策略, 延长了对分值的学习时间, 此时对应的联结记忆成绩也更高。而当RPE凸显性增大, 奖赏联结的编码优先级降低, 被试对图片的学习时间相应延长。
瞳孔直径变化体现了被试的心理努力程度(Ariel & Castel, 2014)。校正后的瞳孔变化平均值和最大值结果都表明, RPE正效价和低凸显性促进了瞳孔变化, 同时奖赏结果更高时, RPE对瞳孔变化的影响会更大。这与RPE对联结记忆的影响基本相符, 可能表明瞳孔直径的变化主要反映了个体在奖赏动机作用(参见综述:杨晓梦等, 2020)下对分值加工的心理努力程度。
实验1和2发现了RPE效价和凸显性对项目和联结记忆的分离影响, 并进一步揭示了该影响发生的认知机制——奖赏信息通过元记忆控制改变了个体对项目和联结编码的认知资源投入。但在这两个实验中, 奖赏结果只包含3个水平, 导致高低奖赏结果分别与正负效价RPE重叠较大, 虽然统计分析中始终考虑了奖赏结果的影响, 已经较准确地体现了RPE效价本身的效应, 但为增强该结果的信度, 补充进行实验3, 目的是考察实验1和2中RPE效价对记忆成绩影响的稳定性, 并再次验证RPE凸显性的影响。
4 实验3:奖赏预测误差对项目和联结记忆成绩影响的稳定性
实验1和2中, 奖赏结果只有1、4和7三种, 导致高奖赏结果7对应的RPE只有0和负效价, 低奖赏结果1对应的RPE只有0和正效价, 只有中等奖赏结果4同时对应正效价、0和负效价。因此在实验3中, 将奖赏结果设置为1、3、5和7四种, 以增加RPE水平, 减小RPE效价和高低奖赏结果的重叠, 验证RPE效价和凸显性对项目和联结记忆影响的稳定性。
4.1 方法
4.1.1 被试
招募被试29人, 剔除2名项目记忆击中率低于0.5的被试, 最后保留被试27人。其中女性24人, 年龄19~25岁(= 22.11岁,= 1.98岁), 视力或矫正视力正常, 无神经系统和心理疾病病史。所有被试均自愿参加实验, 并签署被试知情同意书。每名被试获得真实现金奖励平均约为19元。
4.1.2 实验材料
刺激材料和量表与前两个实验相同。
4.1.3 实验设计与流程
实验设计与实验1相似。但在自变量的操纵上, 奖赏结果序列变为1、3、5和7, 它们出现的比例在高价值图片中是1 : 2 : 3 : 4, 而在低价值图片中为4: 3: 2: 1。由奖赏结果和被试的给出的猜测价值之差产生RPE共有−6、−4、−2、0、2、4和6七种。
总体实验流程和指导语与实验2相似。不同的是, 首先, 只保留了试次开始时的注视点屏; 其次, 考虑到分值序列增加对记忆难度的改变, 将学习阶段价值反馈屏的呈现时间延长到5秒。学习阶段包括100试次, 测试阶段包括200试次。
4.2 结果分析
删去学习阶段被试没有做出价值猜测按键的试次后, 不同RPE条件下, 项目和联结记忆击中率的均值和标准差如表11所示, RPE和奖赏结果对记忆击中率的影响如图6所示。
对记忆成绩进行分析(表12)。对于项目记忆, 与实验2相同, 奖赏结果(= 0.001)、RPE (< 0.001)和URPE (< 0.001)的影响均显著, 且RPE和奖赏结果有显著的负向交互作用(< 0.001), 奖赏结果的增大促进了项目记忆成绩的提高, 项目记忆存在RPE负效价优势以及高凸显性优势, 但奖赏结果的提高会削弱效价效应。联结记忆的结果与前两个实验相似, RPE (< 0.001)和URPE (< 0.001)的影响均显著, 且存在RPE与奖赏结果显著的负向交互作用(< 0.001), 但奖赏结果的影响只达到了边缘显著水平(= 0.056), 表明联结记忆成绩存在稳定的RPE正效价和低凸显性优势, 存在随奖赏结果增大而提高的趋势, 且其中的RPE效价效应还会受到高奖赏结果的削弱。

表11 实验3项目和联结记忆击中率均值和标准差(n = 27)
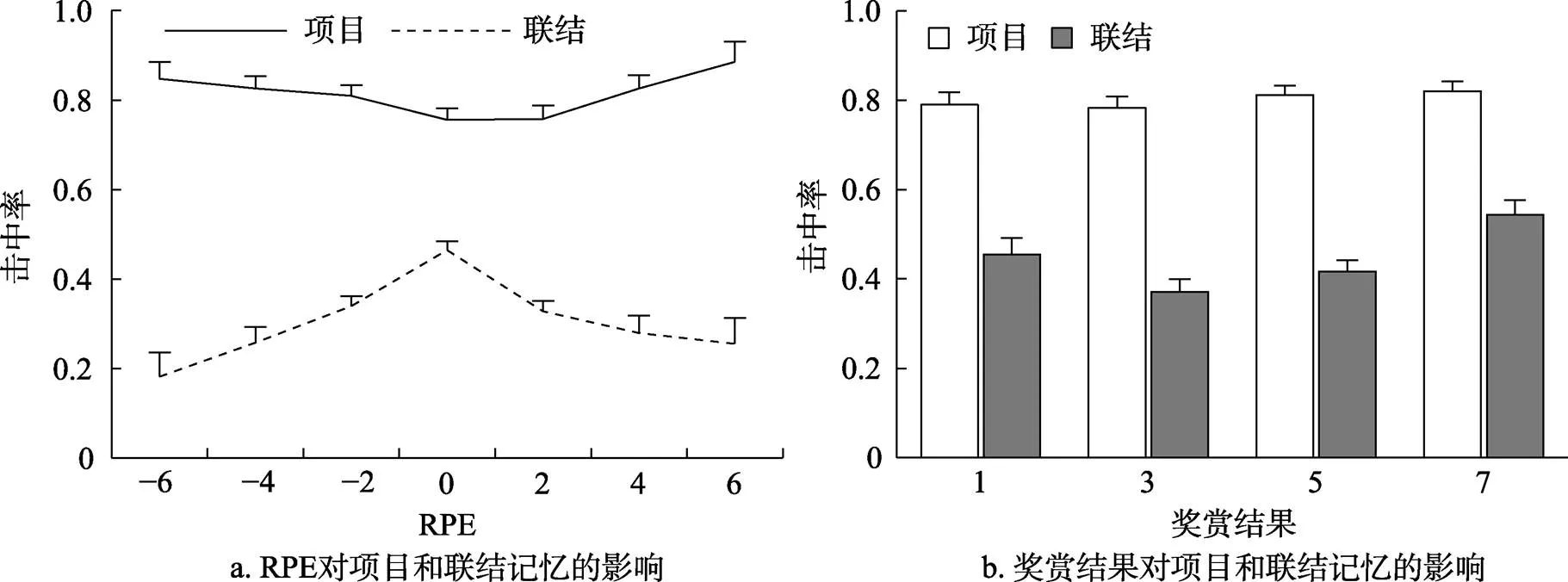
图6 实验3奖赏(a为RPE, b为奖赏结果)对项目和联结记忆击中率的影响(误差线为标准误)

表13 实验3项目和联结记忆反应时混合线性模型分析结果
对再认正确试次的反应时进行分析(表13), RPE (= 0.001)和URPE (< 0.001)对联结记忆反应时的影响均显著, 且奖赏结果与URPE的交互作用显著(= 0.049), 表明联结记忆的提取速度在RPE正效价或凸显性更低时加快, 且奖赏结果增大后会削弱凸显性的效应。
奖惩敏感性差值与正负效价间项目记忆成绩差值(= 0.02,= 0.940)和联结记忆成绩差值(= 0.18,= 0.370)的相关都不显著。
4.3 讨论
将RPE的水平数增加到7后, 正负效价与高低奖赏结果的重叠减小, 但RPE对项目和联结记忆成绩的影响与实验1和2中相同, 这表明RPE效价和凸显性对项目和联结记忆的影响是稳定存在的, RPE效价的影响并非是由奖赏结果差异引起的假阳性结果。
对于联结记忆提取过程, 实验1中发现了高奖赏结果对提取流畅性的促进, 而实验3将RPE效价与奖赏结果高低的影响进一步分离后, 发现RPE正效价时联结记忆提取速度更快, 同时奖赏结果的影响不再显著。这表明实验1中的奖赏结果的影响可能源自于RPE的效价效应。
实验2和3中均未发现奖惩敏感性与项目和联结记忆中RPE效价效应的相关, 且实验1中的相关程度偏低, 这可能是由于受招募而来的被试群体对奖惩的敏感性类似。通过将标准差除以平均数计算离散系数, 发现被试对奖赏和惩罚的敏感性原始分数的离散系数均低于0.5 (实验1, 奖赏:0.43, 惩罚:0.40; 实验2, 奖赏:0.46, 惩罚:0.29; 实验3, 奖赏:0.15, 惩罚:0.17), 离散程度处于较低水平, 验证了上述推论。
5 总讨论
基于价值学习−测试范式, 本研究通过3个实验探讨了RPE效价和凸显性对同一任务中的项目和联结记忆的不同影响。实验1发现, 联结记忆成绩存在RPE正效价和低凸显性优势, 其JOCs准确性在RPE正效价时更高。实验2进一步发现项目记忆成绩存在与联结记忆相反的RPE负效价和高凸显性优势, 且通过眼动技术考察记忆编码中的元认知控制过程发现, RPE正效价和低凸显性提高了个体的瞳孔变化平均值和峰值, 且RPE低凸显性增加了分值注视时间, 缩短了图片注视时间。实验3增加了RPE水平, 再次验证了RPE对项目和联结记忆的相反影响。
5.1 奖赏预测误差对项目和联结记忆成绩影响的分离
RPE效价对项目和联结记忆存在分离的影响。项目记忆成绩中的RPE负效价优势与Wimmer等(2014)的发现一致。RPE正效价能够促进联结记忆成绩的提高, 与使用词对联结(Ergo et al., 2020)、名字−面孔联结(Calderon et al., 2021)和面孔−物品图像联结(Aberg et al., 2017)的前人实验结果一致, 体现了联结记忆中RPE正效价优势的类别一般性。
RPE凸显性对项目和联结记忆也存在分离的影响。RPE高凸显性对项目记忆的促进作用与前人相同(Rouhani & Niv, 2019, 2021; Rouhani et al., 2018)。RPE高凸显性对联结记忆的抑制作用也与Rouhani等(2020)的结果相符。而且与前人研究不同, 本研究中的项目−奖赏联结记忆涉及实验的主要任务, 受到奖赏的直接影响, 联结记忆中的凸显性效应体现的是RPE凸显性的直接影响。此外, 在实验1中, 项目记忆在不同奖赏条件下的成绩相似, 占用了相似的认知资源, 而联结记忆的高凸显性优势仍然存在, 再次表明RPE凸显性是直接作用于联结记忆, 而非通过影响不同凸显性时项目记忆对认知资源的占用间接产生。
5.2 奖赏预测误差影响记忆编码中的元记忆控制
5.2.1 效价对元记忆控制的影响
情景记忆中的奖赏联结记忆(Murty et al., 2016)能够引导适应性决策, 在认知层面, 当面对意味着更高收益的RPE正效价时, 个体的瞳孔变化增大, 这可能体现了个体有了更强的奖赏动机后, 主动通过元记忆控制增强对联结记忆的认知资源分配的过程。根据注意的双重竞争模型(Pessoa, 2009), 一方面, 奖赏相关刺激在视觉皮层上的表征得到增强,能够被优先注意; 另一方面, 个体会通过增强执行功能, 促进奖赏相关加工的效率。此外, 在生理层面, RPE正效价促使腹侧被盖区的多巴胺分泌增加, 而负效价时多巴胺分泌减少(Schultz et al., 1997), 这些多巴胺传入海马后能够使瞬时记忆痕迹获得更大的时间持久性, 从而在联结记忆编码时或编码前后产生促进作用(Bethus et al., 2010)。
而RPE负效价时, 对联结记忆的资源投入减少, 导致此时联结记忆成绩降低。但对于项目记忆, 有核磁研究发现, 在编码阶段, RPE负效价虽然对纹状体的激活更弱, 但负效价的图片的再认正确率比正效价图片更高; 且再认成功的图片在编码中对应的双侧海马激活更大(Wimmer et al., 2014)。这表明, RPE负效价虽然诱发了更弱的奖赏动机, 却会促进项目记忆编码, 从而提高了项目记忆表现。
5.2.2 凸显性对元记忆控制的影响
眼动结果表明, 凸显性对图片和分值编码时长的影响是“此消彼长”的, 这一元记忆控制过程体现了项目和奖赏联结对认知资源的竞争, 也是二者受RPE凸显性的影响表现出分离形式的主要原因。RPE凸显性代表结果与预期的偏离程度的大小, 低凸显性意味着更少的分值信息更新负荷, 降低了联结编码难度, 加工流畅性更高。而加工流畅性作为编码过程元记忆监测的内在线索(Koriat, 1997), 会促使被试采取优先对联结信息分配更多认知资源的元记忆控制策略。一方面, 延长对分值的学习时间, 以加深奖赏联结的记忆痕迹, 另一方面, 此时瞳孔变化增强, 表明了被试增加了联结编码的心理努力程度。
RPE凸显性增大后, 联结记忆加工流畅性降低, 奖赏联结的优先级降低, 对图片的认知资源分配相应增加。在生理层面, 此时被试的意外程度更大, 可能会引起蓝斑中去甲肾上腺素分泌的增加, 去甲肾上腺素与多巴胺在海马中共同释放能够调节编码后记忆增强(Takeuchi et al., 2016), 促进了此时的项目记忆编码。
5.3 奖赏预测误差影响联结提取中的元记忆监测
联结记忆提取过程的元记忆监测准确性受到了RPE正效价的促进, 流畅性受到RPE正效价和低凸显性的促进。根据记忆再认的双加工理论, 联结记忆提取需要检索特定项目的情景信息, 只能通过更复杂的回想过程完成, 不能像项目记忆一样通过熟悉性过程而快速地、自动化地完成再认(Woroch & Gonsalves, 2010)。因此编码阶段中的奖赏在提取阶段的效应主要体现在对回想过程的促进。
研究者发现积极情绪刺激在编码阶段会被赋予更多认知资源, 促进对视觉细节的加工, 从而促进情景记忆的回想过程(毛新瑞等, 2015)。而相比于基于熟悉性做出信心判断, 当个体的信心判断是基于回想时, 元记忆监测更准确(Souchay et al., 2013)。由于比预期更高的奖赏结果通常会引起积极情绪, 这可能解释了奖赏对联结记忆提取中的元记忆监测产生促进作用的机制——RPE正效价通过在编码阶段中促进对细节的加工, 增强了联结提取中的回想过程, 从而提高了元记忆监测准确性。
5.4 高奖赏结果同时促进项目和联结记忆
越来越多的研究者认为奖赏结果主要是通过RPE产生作用, 因而着重探索RPE对记忆的影响, 同时忽略了奖赏结果的作用(Ergo et al., 2020; Jang et al., 2019; Rouhani et al., 2018)。但本研究结果表明, 奖赏结果在项目和联结记忆中都发挥着重要作用, 尤其当结果令人足够满意时, 结果与预期孰优孰劣将不再作为个体判断其损益的主要标准。
综合三个实验结果, 奖赏结果的增大同时促进了项目记忆和联结记忆的提高。奖赏结果能够正向促进情景记忆成绩, 这与前人研究的结果符合(Castanheira et al., 2021)。但Murty等(2016)发现面孔−低奖赏联结的记忆成绩更好, 这可能是因为他们使用具有社会性的独裁者游戏范式, 被试采取“避害”的记忆策略。总的来说, 奖赏结果对记忆的影响具有“趋利避害”的适应性。
5.5 不足与展望
本研究考察了RPE效价和凸显性如何同时作用于项目和联结记忆, 发现二者在编码阶段中存在认知资源竞争, 被试会以RPE效价和凸显性为线索对其进行适应性的选择性加工。在课堂的记忆促进中, 对奖赏的利用通常局限于奖赏结果本身, 但本研究结果表明, 若同时操纵了学习者的奖赏预期, 使其形成不同的RPE, 对记忆效果可能有更多的促进作用。
但值得注意的是, 本研究选取的联结记忆指标为奖赏联结, 与前人研究中的人物−物品联结(Aberget al., 2017)以及外语−母语词汇联结(Calderon et al., 2021; Ergo et al., 2021)等存在一个共同点, 即RPE凸显性大小对应了不同的联结编码难度, 这可能是导致RPE低凸显性时联结记忆成绩升高的重要原因。因此, 当联结编码的难度与凸显性无关时, 凸显性的影响是否仍存在, 是未来研究需要考虑的问题。
个体本身的特质能够影响奖赏的动机作用从而作用于项目记忆(Rouhani & Niv, 2019)和联结记忆(Aberg et al., 2017), 但本研究只在实验1中发现了奖惩敏感性与联结记忆中RPE效价效应的低相关, 这可能是由被试奖惩敏感性的低离散程度导致的。之后的研究可以考虑在实验前选取高低敏感性两组被试, 探索其情景记忆受奖赏动机影响的差异。
此外, 实验2通过眼动技术对记忆编码过程的学习时间分配和瞳孔变化表征的心理努力程度进行了考察, 发现了编码项目和联结信息的认知资源分配随RPE而变化。但因为瞳孔直径容易受物理环境中的光刺激影响, 而EEG研究能在时间维度更精细地反映记忆编码过程中的神经激活程度, 未来的研究可以通过分析RPE影响情景记忆的EEG时程变化, 进一步验证两者的编码过程受奖赏信息影响的差异。
6 结论
RPE对项目和联结记忆存在分离的影响, 元记忆过程在其中发挥着重要作用。在编码阶段, 个体以RPE为线索进行元记忆控制, RPE高凸显性增加了对项目编码的认知资源投入, RPE正效价和低凸显性增加了对联结编码的认知资源投入; 在提取阶段, RPE正效价还通过回想过程促进联结记忆提取的元记忆监测准确性。
Aberg, K. C., Muller, J., & Schwartz, S. (2017). Trial-by-trial modulation of associative memory formation by reward prediction error and reward anticipation as revealed by a biologically plausible computational model.,, 56.
Ariel, R., & Castel, A. D. (2014). Eyes wide open: Enhanced pupil dilation when selectively studying important information.,(1), 337−344.
Bethus, I., Tse, D., & Morris, R. G. M. (2010). Dopamine and memory: Modulation of the persistence of memory for novel hippocampal nmda receptor-dependent paired associates.,(5), 1610−1618.
Calderon, C. B., De Loof, E., Ergo, K., Snoeck, A., Boehler, C. N., & Verguts, T. (2021). Signed reward prediction errors in the ventral striatum drive episodic memory.,(8), 1716−1726.
Da Silva Castanheira, K., Lalla, A., Ocampo, K., Otto, A. R., & Sheldon, S. (2021). Reward at encoding but not retrieval modulates memory for detailed events.,, 104957.
Ergo, K., De Loof, E., Debra, G., Pastotter, B., & Verguts, T. (2020). Failure to modulate reward prediction errors in declarative learning with theta (6 Hz) frequency transcranial alternating current stimulation.,(12), e0237829.
Ergo, K., De Vilder, L., De Loof, E., & Verguts, T. (2021). Reward prediction errors drive declarative learning irrespectiveof agency.,(6), 2045−2056.
Guo, Y., Song, G., Zhao, P., & Ma, Y. (2011). Revision of the sensitivity to punishment and sensitivity to reward questionnaire., (1), 91−94+97.
[郭永香, 宋广文, 赵平平, 马玉花. (2011). 大学生惩罚和奖励敏感性问卷(SPSRQ)的修订., (1), 91−94+97. ]
Höltje, G., & Mecklinger, A. (2020). Feedback timing modulates interactions between feedback processing and memory encoding: Evidence from event-related potentials.,(2), 250−264.
Jang, A. I., Nassar, M. R., Dillon, D. G., & Frank, M. J. (2019). Positive reward prediction errors during decision-making strengthen memory encoding.,(7), 719−732.
Jiang, Y., Wang, Z., Zheng, M., & Jin, X. (2016). How value- based agendas affect study time allocation: An eye tracking study.,(10), 1229−1238.
[姜英杰, 王志伟, 郑明玲, 金雪莲. (2016). 基于价值的议程对学习时间分配影响的眼动研究.,(10), 1229−1238.]
Koriat, A. (1997). Monitoring one's own knowledge during study:A cue-utilization approach to judgments of learning.,, 349−370.
Mao, X., Xu, H., & Guo, C. (2015). Emotional memory enhancement effect in dual-processing recognition retrieval..(9), 1111−1123.
[毛新瑞, 徐慧芳, 郭春彦. (2015). 双加工再认提取中的情绪记忆增强效应.,(9), 1111−1123.]
Mason, A., Lorimer, A., & Farrell, S. (2019). Expected value of reward predicts episodic memory for incidentally learnt reward-item associations.,(1), 40.
Murty, V. P., FeldmanHall, O., Hunter, L. E., Phelps, E. A., & Davachi, L. (2016). Episodic memories predict adaptive value-based decision-making.,(5), 548−558.
Pessoa, L. (2009). How do emotion and motivation direct executive control?,(4), 160−166.
Rouhani, N., & Niv, Y. (2019). Depressive symptoms bias the prediction-error enhancement of memory towards negative events in reinforcement learning.,(8), 2425−2435.
Rouhani, N., & Niv, Y. (2021). Signed and unsigned reward prediction errors dynamically enhance learning and memory.,, e61077.
Rouhani, N., Norman, K. A., & Niv, Y. (2018). Dissociable effects of surprising rewards on learning and memory.,(9), 1430−1443.
Rouhani, N., Norman, K. A., Niv, Y., & Bornstein, A. M. (2020). Reward prediction errors create event boundaries in memory.,, 104269.
Schultz, W., Dayan, P., & Montague, P. R. (1997). A neural substrate of prediction and reward.,(5306), 1593−1599.
Souchay, C., Guillery-Girard, B., Pauly-Takacs, K., Wojcik, D. Z., & Eustache, F. (2013). Subjective experience of episodic memory and metacognition: A neurodevelopmental approach.,, 212.
Takeuchi, T., Duszkiewicz, A. J., Sonneborn, A., Spooner, P. A., Yamasaki, M., Watanabe, M.,…., Morris, R. G. M. (2016). Locus coeruleus and dopaminergic consolidation of everyday memory.,(7620), 357.
Tulving, E. (2001). Episodic memory and common sense: How far apart?,(1413), 1505−1515.
Wimmer, G. E., Braun, E. K., Daw, N. D., & Shohamy, D. (2014). Episodic memory encoding interferes with reward learning and decreases striatal prediction errors.,(45), 14901−14912.
Woroch, B., & Gonsalves, B. D. (2010). Event-related potential correlates of item and source memory strength.,, 180−191.
Yang, X., Wang F., Wang, Y., Zhao, T., Gao, C., & Hu, X. (2020). Are pupils the window of our mind? Pupil-related application in psychology and pupillometry.,(7), 1029−1041.
[杨晓梦, 王福兴, 王燕青, 赵婷婷, 高春颍, 胡祥恩. (2020). 瞳孔是心灵的窗口吗?——瞳孔在心理学研究中的应用及测量.,(7), 1029−1041.]
The distinct effects of reward prediction error on item and associative memory:The influence of metamemory
LONG Yiting1, JIANG Yingjie1, CUI Can2, YUE Yang1
(1School of Psychology, Northeast Normal University, Changchun 130024, China) (2Jiangsu Key Laboratory of Brain Disease and Bioinformation, Research Center for Biochemistry and Molecular Biology, Xuzhou Medical University, Xuzhou 221004, China)
Episodic memory consists of item memory and associative memory. Individual cognitive resources are typically allocated to more valuable information during encoding through metamemory, leading to competitive processing of item and associative information. Reward prediction error (RPE), defined as the difference between reward results and reward expectations, has two properties: valence (positive or negative) and salience (degree of difference). To examine the impact of reward prediction error valence and salience on item and associative memory, and how reward prediction error influences memory based on metamemory, three experiments were conducted.
In the learning stage, participants were presented with indoor and outdoor scene pictures. They were asked to predict the score of each picture and then received feedback on the actual score. Through this reinforcement learning process, participants had to find out which type of pictures is more valuable, and 30% of the scores were accumulated into the total score. To induce the effect of reward motivation on memory, participants were introduced to the opportunity to choose between two pictures and receive the value of the selected picture, although the actual program did not include a decision-making stage. After the learning stage, participants were tested on item and reward associative memory.
The findings of the study showed that: (1) There were advantages in associative memory performance for positive reward prediction error valence and low salience, with higher accuracy of JOCs at positive valence. In contrast, there were advantages in item memory performance for negative valence and high salience. (2) In the eye-tracking results during the encoding process, positive valence and low salience of reward prediction error resulted in increased mean and peak pupil dilation after feedback presentation, as well as longer value fixation duration and shorter picture fixation duration at low salience. (3) When the reward prediction error level was increased to reduce overlap between reward results and reward prediction error effects, the separation effect of reward prediction error on item and associative memory performance remained stable.
The results of the study suggest that the effects of reward prediction error on item and associative memory are distinct. During the encoding stage, individuals use the valence and salience of reward prediction error as cues to allocate cognitive resources differently in item and associative memory encoding through metamemory control. In the retrieval stage, positive valence of reward prediction error enhances the metamemory monitoring level of associative memory retrieval.
reward prediction error, associative memory, eye movements, episodic memory, metamemory
2022-04-14
* 吉林省自然科学基金面上项目(20230101149JC)和国家自然科学基金面上项目(32271095)资助。
姜英杰, E-mail: jiangyj993@nenu.edu.cn
B842
猜你喜欢
工会博览(2022年8期)2022-06-30
心理学探新(2022年1期)2022-06-07
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
猪业科学(2018年5期)2018-07-17
中国医疗保险(2018年3期)2018-07-14
中国当代医药(2015年8期)2015-03-01
中成药(2014年9期)2014-02-28
