
异构边缘资源的任务卸载和协同调度
2023-06-07 03:40李小平周志星
计算机研究与发展 2023年6期
李小平 周志星 陈 龙 朱 洁
1 (东南大学计算机科学与工程学院 南京 211189)
2 (东南大学网络空间安全学院 南京 211189)
3 (南京邮电大学计算机学院 南京 210036)
移动边缘计算广泛应用于物联网、车联网和在线游戏等领域,通过获取分布在网络边缘的计算能力和存储空间,可执行终端设备产生具有不同资源需求和延迟敏感的任务[1].如何减少延迟、提高用户体验是移动边缘计算关注的主要目标.任务通过邻近接入点(access point, AP)传输至边缘服务器执行,以缓解终端设备有限的计算能力与高资源和高延迟敏感需求间的矛盾[2];但单个边缘计算资源能力有限[3-4],难以同时满足多个用户提交的任务,边缘服务器任务量过多容易陷入过载状态,导致待处理任务长时间等待.通过多边缘协同调度[5]将过载边缘服务器上的任务转移至较为空闲的服务器上执行可减少任务的完成时间,但会产生传输代价,根据服务器状态如何卸载任务以权衡任务执行时间和传输时间难以决策;不同任务具有不同计算量和截止期,如何合理调度卸载分配到服务器资源上的任务以尽量满足截止期约束也是关键问题.因此,任务卸载和调度是移动边缘计算的2 个关键问题.
本文考虑异构边缘环境下带截止期约束任务卸载和协同调度问题,二者紧密关联.终端设备通过邻近AP 节点转发任务请求[6],通过卸载决策将任务指派到具体边缘服务器上执行,但每个边缘节点计算资源有限,且边缘节点的计算能力和传输能力等具有差异性;各任务有不同的计算量、数据量和截止期需求;有限资源的约束导致卸载和调度通常不能完全满足截止期约束,即部分任务延迟,如何最小化总延迟时间是用户关注的优化目标.这些问题是典型的NP-hard 问题,其主要挑战为:1)异构边缘环境下各边缘节点的计算能力和传输能力不同,导致相同任务在不同边缘节点上执行时间和传输时间不同,如何进行任务卸载以实现任务执行时间与传输时间的权衡是一个难题;2)相同边缘节点的能力有限,如何调度多个不同截止期任务以最小化总延迟时间是一个挑战性问题.
考虑到这些问题的特点,本文首先基于现有边缘计算中通用架构,设计异构边缘协同的任务卸载和调度框架;分析所考虑问题的特征,建立相应的数学模型;提出一个异构边缘环境下带截止期的约束任务卸载和调度算法,包括边缘网络拓扑节点排序、边缘节点内任务排序、任务卸载决策、任务调度和结果调优5 个部分;设计多种任务卸载策略和任务调度策略.
1 相关工作
不同边缘计算架构[7]下的任务卸载有较多研究,本文所考虑的问题涉及多服务器边缘计算、任务卸载、截止期约束调度等方面.
1)多服务器边缘计算方面.文献[8]研究应用程序在本地执行或传输到边缘服务器以最小化移动设备能耗.文献[9]研究单服务器边缘系统中的计算任务调度,设计双时间尺度随机优化调度策略,大时间尺度决定任务卸载,小时间尺度考虑具体任务传输过程,采用马尔可夫决策以优化延迟.文献[10]提出将用户连接至最近边缘服务器,以提供最快的响应时间和最佳通信条件.这些工作都集中于单服务器边缘场景,忽略边缘服务器在处理多任务时造成的拥塞,易于陷入过载状态.文献[11]考虑多边缘计算系统,当单个服务器陷入过载状态时将计算负载转移到邻近空闲服务器,以最小化任务执行延迟和用户能耗.文献[12]考虑用户通过异构网络将任务卸载至任意边缘服务器,综合考虑用户卸载决策、用户传输功率及服务器计算能力等.文献[13]考虑边缘服务器的有限计算资源,提出分层边缘计算调度架构,利用邻近边缘节点空闲的计算能力,在邻近区域引入备份服务器解决边缘服务器的计算瓶颈问题,采用Stackelberg 博弈论方法设计多层级卸载方案.文献[14]研究终端设备可通过无线局域网获得多个边缘服务器的服务,用户可直接将所需卸载任务传输至云服务器,提出一种基于本地/卸载执行代价最小化的鲁棒计算卸载选择策略.
2)任务卸载方面.文献[15]考虑在终端设备附近范围内有多个可用边缘服务器场景,提出一种通过代理服务器进行能耗和延迟感知的边缘服务器选择策略.文献[16]考虑将过载服务器任务迁移到空闲服务器,以平衡多服务器负载,设计一种调度算法为超过负载阈值服务器选择可迁移的候选虚拟机,提出根据迁移效率选择最合适服务器的策略;这些研究只考虑任务卸载,而不考虑任务调度.文献[17]考虑共享信道和有限计算资源,构建混合整数线性优化模型,提出基于拥塞感知的动态启发式算法,包括生成初始卸载决策、任务分配、冲突时的重调度策略.文献[18]考虑多用户通过共享信道与边缘服务器连接时的带宽分配影响,提出一种高效卸载决策算法以最小化平均响应时间.文献[19]考虑大量用户对云计算资源的竞争,提出一种离线启发式算法以最小化用户平均完成时间.文献[20]进一步研究移动边缘云中延迟敏感应用的计算卸载和资源分配,考虑计算资源和网络带宽二维资源分配,提出一种高效启发式算法.文献[8-20]考虑不同场景下任务卸载和资源分配,当任务增加截止期等约束时,这些算法不再适用.文献[21]考虑了任务迁移引起的大量数据传输问题,提出了基于延时传输机制的多目标工作流调度遗传算法,能够有效地优化移动设备的能耗和工作流的完工时间.文献[22]考虑数据流调度优化问题,将该问题转换成为一个新的连续合作博弈,设计出快速收敛的基于博弈论的调度算法,保证资源效率和公平度.
3)截止期约束调度方面.文献[23]同时考虑通信资源分配和作业到服务器的映射,提出基于合作博弈的调度方法,在截止期约束下最大化任务成功执行数量.文献[24]以最小化总延迟时间为目标,采用匹配理论求解任务卸载,提出启发式算法.文献[25]研究边缘计算中在线延迟感知任务分派和调度,最大化满足截止期约束的任务数量,提出贪心算法,将新到任务插入到当前队列以满足任务截止期.文献[26]基于最高残留密度优先规则,提出云边环境下在线任务分派和调度算法,最小化加权响应时间.文献[27]考虑任务的硬截止期约束,设计最小化总代价的启发式算法.文献[28]考虑边缘计算场景中用户各自的截止期约束,采用博弈论方式分别优化,达到最终的纳什平衡.文献[29]将并行数据处理应用上的请求封装成任务包,提出一个调度策略组AutoBoT,包括实时决策定价、虚拟机获取和释放、任务放置、检查点设置和迁移,以保证在硬截止日期约束下任务的按期完成.文献[30]将任务包应用在混合云下的异构资源分配问题模型化成二元线性规划问题,具有截止日期和资源约束,以所有任务包应用总代价为优化目标,利用CPLEX(IBM 的建模优化引擎)计算解决方案.文献[31]研究具有截止日期约束的云工作流调度问题,提出了一种新的自适应惯性权重计算方法更加精确地描述粒子状态,提高权重的自适应性,在此基础上提出了改进粒子群算法,该算法可以更好地平衡粒子全局与局部搜索,避免陷入局部最优.文献[32]提出具有机器启动时间感知的虚拟机扩展策略,以缓解机器启动时间造成的实时任务延误问题,设计具有启动时间感知能力的调度算法来调度实时任务和资源.
综上所述,异构边缘计算环境下综合考虑任务截止期约束的多边缘协同的任务卸载和调度问题尚未有相关的研究.
2 系统框架和数学模型
针对本文考虑问题,基于现有边缘计算调度框架,提出如图1 所示的改进调度框架,主要包含用户层、边缘层和云数据中心层.用户层的终端设备产生资源需求高且延迟敏感任务,终端设备计算能力有限且电池寿命并不足以支持此类任务执行,通过邻近AP 节点将任务传输至边缘层或云数据中心;边缘层包含部署在网络边缘的AP 节点及位于AP 节点上的边缘服务器,边缘服务器所部署的位置及所能处理的任务数量不同,当1 个边缘节点任务数量过多导致长时间等待时,可将部分待处理任务传输至其他边缘节点执行;云数据中心层为边缘节点提供计算支持与各AP 节点通过网络链路直接相连,拥有充足的计算资源,当边缘层中负载过大时将任务传输至云中执行以缓解负载压力,但由于云服务器距离边缘层较远需付出较高的传输代价.
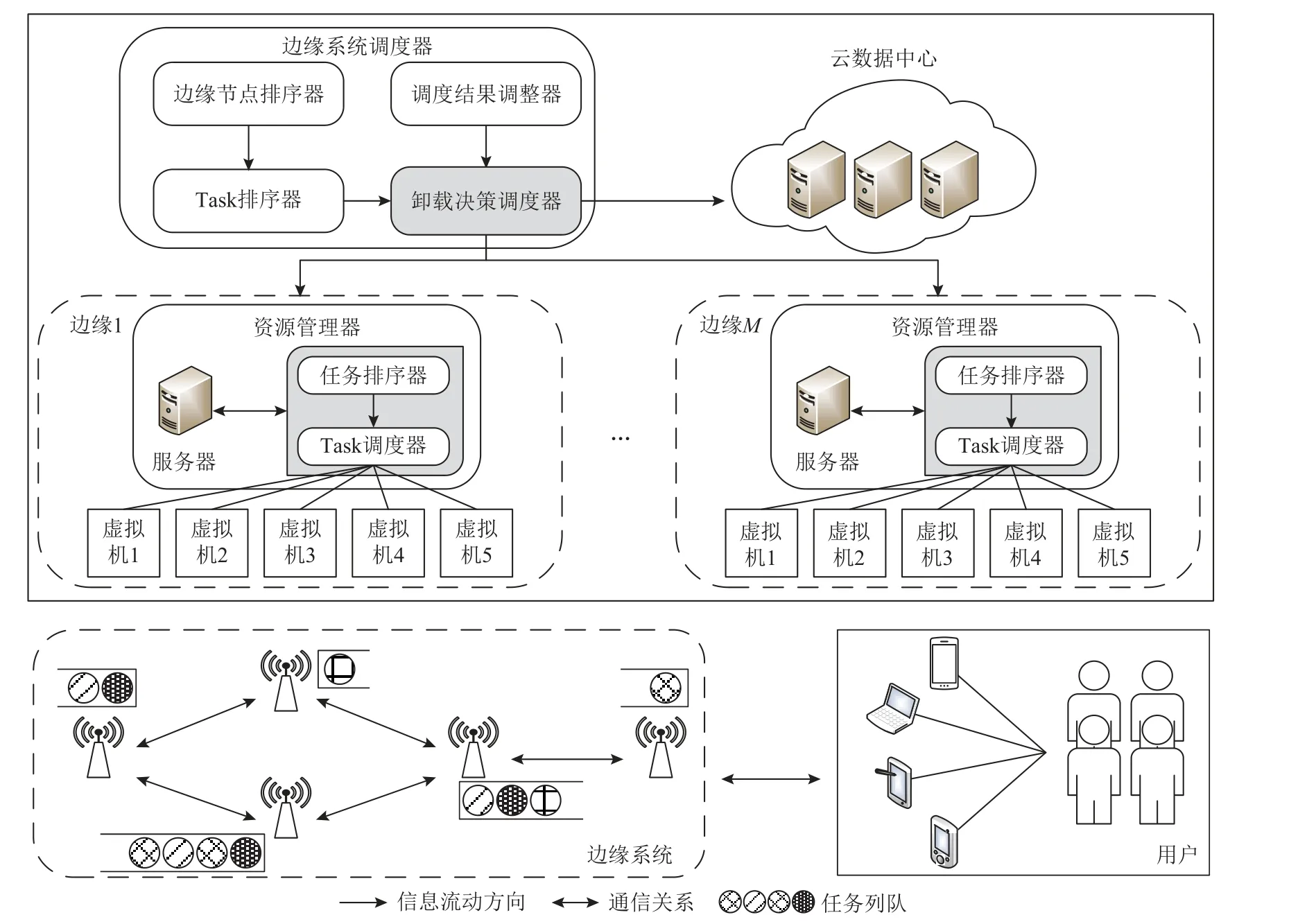
Fig.1 Multi-edge cooperative scheduling framework图1 多边缘协同调度框架
为方便起见,做4 点假设:1)终端设备仅通过最近AP 将任务上传边缘系统,边缘系统可获得所有任务计算量、数据量和截止期约束等信息;2)任务具有软截止期约束,即允许任务超过截止期执行;3)边缘系统中不同边缘节点间的网络带宽和延迟事先给定,且调度时不发生变化;4)边缘服务器的异构性体现为计算能力、服务器中虚拟机个数等不同;5)任务执行不可中断,且不考虑终端设备的移动性.
边缘环境的网络拓扑可视为一个无向图G=(V,E),其中V={V1,V2,…,VM}表示边缘环境下AP 节点集合,表示AP 节点间的网络链路,边ej,k连通代表Vj,Vk间可互相传输数据,设Bj,k为链的带宽,Lj,k为ej,k传播延迟,Pj,k为Vj,Vk间的最短路径(当需要从节点Vj传输任务到Vk时多条可达路径中的最短路径).设每个AP 节点有且仅有1 台服务器,即共有M台异构边缘服务器S=表示服务器S j的虚拟机,为服务器S j上第l个虚拟机的处理速度.终端设备产生的独立任务需传输至服务器执行,设当前有N个分布在不同AP 节点覆盖范围内的任务T={T1,T2,…,TN}需执行,每个任务Ti先通过邻近的AP 节点 θi(集合V中的1 个元素)上传至边缘系统,Ti可表示为四元组(θi,γi,ci,di),其中 γi为数据量大小、di为截止期、ci为 计算量大小.任务提交后,通过最短路径将该任务传输至目的边缘服务器上执行.云数据中心S0通过网络链路与每个AP 节点相连,计算资源充足,f0为S0虚拟机的计算速度,B0和 L0分别为AP 节点到S0的网络带宽和延迟.边缘系统通过卸载决策决定任务分配到哪台服务器上,决策变量xi∈{0,1}(i=1,2,…,N),xi=0表示任务Ti在云服务器执行,xi=1表示在边缘服务器执行;决策变量yi,j∈{0,1}(j=1,2,…,M),yi,j=1表示任务Ti指派到边缘服务器S j上执行;决策变量zi,j,l=1,表示Ti匹配至边缘服务器S j的虚拟机.本文考虑最小化边缘系统总延迟时间δ,即minδ=的完成时间,其中S Ti=max{TTi,ES Ti}为Ti的开始时间,PTi和DTi为Ti的执行时间和执行结果回传时间,TTi,ES Ti为Ti的传输时间与最早可执行时间;执行时间和执行结果回传时间分别由计算;决策变量满足
3 异构边缘协同任务卸载和调度
针对所考虑问题,提出异构边缘环境下带截止期约束任务卸载和调度 (task offloading and scheduling with deadline, TOSD)算法,主要包括边缘网络拓扑节点排序、被卸载任务排序、卸载目的选择策略、任务调度、结果调优等组件.首先要确定哪些边缘网络节点的任务太多,需要卸载,即对边缘网络拓扑节点排序;其次确定各节点上需卸载哪些任务,即对卸载任务排序;再次,确定任务卸载到哪些服务器,即卸载目的选择策略;随后依据卸载至相同服务器的任务优先级规则和任务的可选资源,产生任务调度序列;最后选用调整方法改进调度结果.TOSD 算法框架如算法1 所示:
3.1 边缘网络拓扑节点排序
边缘节点承接任务过多时会陷入过载,需将过载节点任务卸载到其他节点,以减少任务的等待时间.首先对边缘网络拓扑节点赋予不同优先级,优先级高的节点先任务卸载.设计优先级规则时需考虑3点因素:1)节点计算量.设 Φj为边缘节点Sj(j=1,2,…,M)的任务集合,nj=为其任务数,即Φj={Tr|为Sj的计算负载.若CLj>CLj′,则节点 Sj的计算负载压力越大,陷入过载的可能性越大,优先级应更高.2)节点度数.与边缘节点直接相连的邻近节点数量考虑最小化任务卸载成本,度数越大其邻近节点数量越多,可有更多选择将任务卸载至邻近边缘节点;相反,度数越小其可选择余地越少.因此节点度数越小优先级越高.3)节点空闲程度.异构边缘协同计算场景下的多个边缘服务器的负载动态变化,设节点 Sj上任务 Tr的预估完成时间为,定义所有节点最晚完成时间FTmax=节点 Sj的空闲程度[0,1],Δj值越大表明该节点 Sj空闲程度越高,特别是Δj=1表明节点处于完全空闲.
基于这3 点因素,提出3 种边缘节点排序方法:
①节点计算负载排序法(computationloadbased sequencing,CLBS).按照计算量降序排列边缘节点.
②节点度数排序法(nodedegreebasedsequencing,NDBS).按照度数升序排列边缘节点.
③节点空闲程度排序法(idledegreebasedsequencing,IDBS).按照空闲程度升序排列边缘节点.
这3种方法采用简单规则对边缘网络边缘节点排序,平均时间复杂度为(其中 M为边缘网络的节点数量).
3.2 被卸载任务排序
因待卸载任务可能较多,如何选择被卸载任务将对目标函数产生重要影响,选择策略受截止期、计算量和数据量等因素的影响.尽早卸载截止期临近的任务,计算密集型任务(计算量大、数据量相对较小)需卸载至性能更好、等待时间更短的节点;数据密集型任务(计算量小而数据量大)更适合本地边缘节点.由此,构造2 种被卸载任务排序法:
3.3 卸载目的选择策略
在确定哪些任务需要卸载后,选择卸载目的服务器.本地节点服务器任务可传输至其他节点或云数据中心.选择策略主要考虑处理时间和传输时间等因素.异构性主要表现为边缘服务器虚拟机处理速度的差异,即同一任务在不同虚拟机上执行的时间不同.任务传输到网络拓扑不同位置边缘节点,传输代价也不同.任务卸载决策(task offloading decision,TOD)算法基本框架如算法2 所示:
设边缘节点S j(j=1,2,…,M)上待卸载任务集合为的初始位置为 θi(初始化为用户提交任务时的最邻近边缘节点),服务器选择策略从j(j≠θi)中选择最适合Ti卸载的边缘服务器Starget.根据不同选择准则提出不同服务器选择:
1)贪心选择法 (greedy selection rule, GSR).贪心选择Ti预估完成时间最早的服务器,先计算Ti在初始边缘节点服务器上执行的最早完成时间=(此时传输代价为0);依次估计Ti卸载至服务器S j的最早完成时间其中TTi,j(i≠j)为传输时间,采用处理速度最快虚拟机预估任务执行时间,平均等待时间为在节点S j上尝试执行所有待卸载任务的平均等待时间
2)最大收益选择法 (maximum benefit selection,MBR).任务Ti的初始预估执行时间为,将其传输至其他边缘节点时,执行时间减少量与传输时间增加量的差值定义为卸载收益当BTi,j>0时,表明卸载到节点S j能缩短任务完成时间,选择其中收益最大的边缘服务器作为该任务的目的服务器.
3)最近最小负载法 (minimum nearest and load rule,MNR).定义度量不同边缘节点服务器的负载状态和距离当前任务所在节点的距离远近程度,选择S R最小边缘节点.
卸载目的服务器的选择需遍历所有边缘节点,这3 个准则的时间复杂度均为O(M).
3.4 任务调度
通常服务器有多个虚拟机,接收到多个任务,任务都有截止期约束,如何合理调度多个任务到多个虚拟机是最小化总延迟时间、尽可能减少任务超期时间的关键.涉及2 个基本问题:任务按照什么顺序调度、每个任务安排到哪台虚拟机上执行,即任务排序和资源分配.任务调度 (task scheduling, TS)过程如算法3 所示:
3.4.1 任务排序
考虑任务截止期约束和属性设计不同的任务排序规则:
1)先来先服务 (first come first service, FCFS).根据任务到达目的服务器的先后顺序排序.
2)截止期最逼近优先 (nearest deadline first, NDF).按照接近截止期程度由紧到松对任务排序.
3)最小松弛时间优先 (minimum slack time first,MSTF).按照任务松弛时间S Ti=di--AS Ti由小到大的顺序排序,为任务在此边缘服务器上的预估执行时间,AS Ti表示任务到达该边缘节点的时间.
3.4.2 资源分配
任务具有不同计算负载、不同截止期、不同截止期逼近程度.不同边缘节点的计算能力不同、同一边缘服务器上多种虚拟机计算能力不同导致同一任务在不同节点或不同虚拟机的处理时间也不同,某时刻不同虚拟机的可用时间不同,综合考虑这些因素设计资源分配规则:
1)最早完成时间优先 (earliest finish time first,EFTF).尝试将任务Ti’(i’∈{1,2,…,nj})放到当前边缘服务器中所有虚拟机上执行,计算其完成时间,选择具有最早完成时间的虚拟机,即
2)最早开始时间优先 (earliest start time first,ESTF).选择具有最早空闲时间的虚拟机=执行任务
3)负载均衡优先 (load balance first, LBF).选择当前虚拟机列表中负载均衡度最小的虚拟机执行任务,负载均衡程度其中为服务器第个虚拟机的实际运行时间.图2 所示某节点有VM1,VM2,VM3这3种不同处理速度的虚拟机,初始LBR值为0.060.任务调度到VM1的执行时间为0.75,LBR值为0.039(情况1);调度到VM2的执行时间为0.5,LBR值为0.110(情况2);调度到VM3的执行时间为0.25,LBR值为0.125(情况3).情况1 使得负载均衡度最小,故选择虚拟机VM1执行任务.
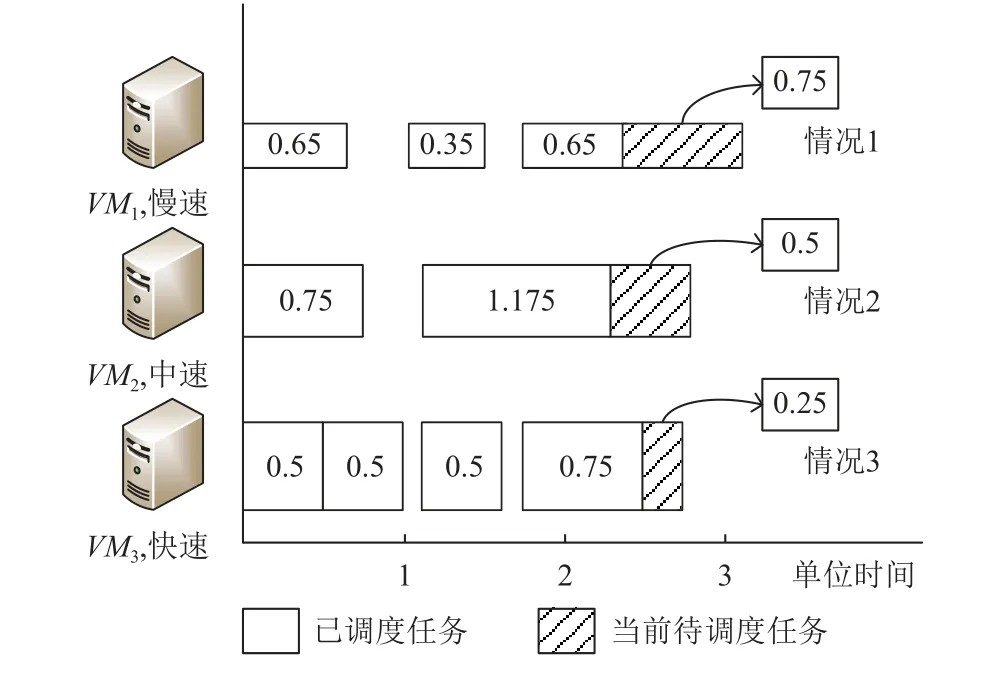
Fig.2 Illustration of resource allocation图2 资源分配示意图
3.5 调度结果调优
不同任务卸载和调度策略直接影响最终调度结果,为此提出调度结果调优算法以期提高解的质量.迭代过程τmax次:
1)除已经产生的初始解X(0)外,随机产生K-1个解;
2)以概率pm∈(0,1)随机选择2 个解K1,K2进行合成操作,即随机挑选一个位置作为合成点,将 K1的前半段和 K2后半段合成为一个新解,同理剩余部分组成另外一个新解;
3)以概率pd∈(0,1)随机选择一个解 K 进行分解操作,即随机选择一个位置作为分解点,分解为新解K1,K2,其中 K1继承其前半段,K2继承其后半段,K1,K2的其他位置随机产生;
4)从所有解中选择最好解作为下次迭代的初始解X(0).
4 实验结果与分析
为评价和分析所提出算法的性能,采取相对百分比偏差 (relative percentage deviation, RPD )作为评估标准,借助多因素方差分析 (analysis of variance,ANOVA)方法分析算法参数和算子校正结果、比较算法.对独立任务集合T,设当前算法获得解 πω的总延迟时间为,所有算法运行最优解的总延迟时间为,定义
采用EdgeCloudSim[33]实验平台作为边缘计算仿真工具,模拟边缘环境,所有算法均采用Java 编写,在同一配置(Intel®Core(TM)i5-8265CPU @1.60 GHz,内存8 GB,Window10 操作系统)的机器上运行.所有实验参数设置借鉴文献[23],采用BRITE[34]拓扑生成器生成各边缘的位置分布,各边缘节点任务服从分布,任务的数量规模从1 000 到2 000 每次增长200,任务数据量大小服从均匀分布U~(1 000,2 000)(单位为KB),任务计算量大小服从均匀分布U~(0.4,2.4)(×109CPU周期数);边缘服务器上虚拟机的处理速度从{0.5,0.6,…,1.0}(单位为GHz)中取值,各边缘AP 节点间的网络带宽服从U~(30,50)(单位为Mbps),链路间延迟Lj,k(j,k∈{1,2,…,M})服从均匀分布U~(0.01,0.05)(单位为s),云数据中心与边缘AP 节点间的带宽为100 Mbps,链路网络延迟为0.5 s.
4.1 算法算子和参数校正
为得到统计意义上的校正结果,每个任务数随机生成10 组实例;任务Zipf 分布不均匀程度因子λ ∈{0,0.1,0.2,0.3,0.4};边缘节点数M随机从{15,20,30,40}中取值,分别为M1,M2,M3,M4;任务截止期D从[0.5, 2],[0.5, 3],[0.5, 4],[0.5, 5]中取值,分别称为D1,D2,D3,D4;故共有10×4×5×4×10=8000组随机实例.另外,考虑3 种边缘节点排序方法(CLBS, NDBS,IDBS)、2 种被卸载任务排序法(DCIS, RSDS)、3 种卸载目的选择策略(GSR, MBR, MNR)、3 种任务排序方法(FCFS, NDF, MSTF)和3 种资源分配规则(EFTF,ESTF, LBF),τmax=μ×N,K=ν×N,其中μ ∈{0.1,0.2,0.3,0.4,0.5},ν ∈{0.05,0.1,0.15,0.2,0.25}.共3×2×3×3×3×5×5=4050种组合;总共进行8000×4050=32400000次实验.经多次实验发现pm=0.4,pd=0.6效果最好.
采用ANOVA 分析实验结果,3 个主要假设(正态性、齐次性、残差独立性)都做了验证,实验结果表明3 个假设都可接受,p值都小于0.05,表明所有因素在95%置信水平上都有显著性差别.相应结果如图3~5 所示:
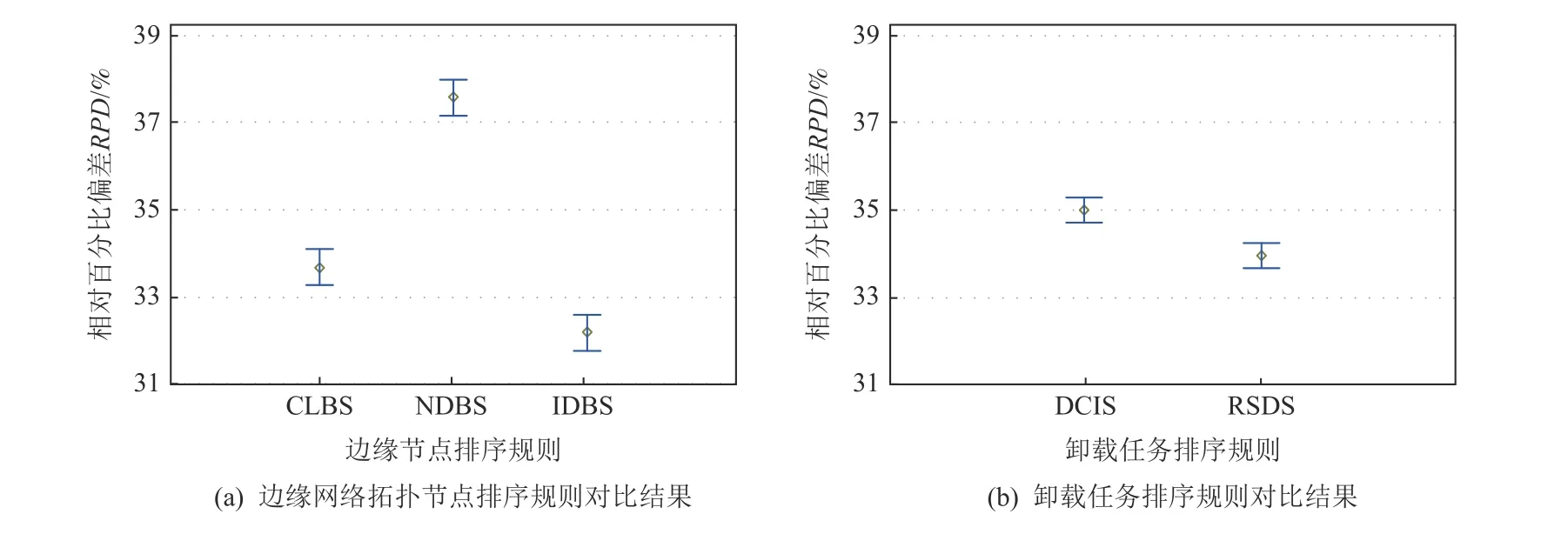
Fig.3 Comparison results of edge network node sequencing rules and offloaded task sequencing rules with 95% Tukey HSD confidence intervals图3 95% Tukey HSD 置信区间下边缘网络节点排序规则和卸载任务排序规则对比结果
由图3(a)可以看出,CLBS 和IDBS 的RPD值小于NDBS 的RPD值.CLBS 优先处理负载压力大的节点任务以缓解过载压力;NDBS 考虑边缘网络结构,度数小的节点传输任务至其他节点上需付出更大传输代价,但未考虑边缘系统中不同节点的任务分布;IDBS 考虑节点的任务负载和其计算能力,更适合于减少总的任务延迟.本文选择IDBS 排序边缘网络拓扑节点.
由图3(b)可以看出,DCIS 和RSDS 间RPD值的差距较小,但RSDS 显著优于DCIS.本文将选择RSDS.
由图4(a)可以看出,选择策略GSR 和MNR 的RPD值远小于MBR 的.GSR 考虑多任务间的竞争及节点中负载的动态变化;MBR 卸载任务至收益最高的节点,但会导致多个任务卸载至高收益的节点上致其陷入过载状态;MNR 将任务优先卸载至最近最小负载的节点上,综合考虑节点负载和多任务间的竞争.GSR 和MNR 更加适合于减少总的任务延迟时间.MNR 将用于选择卸载目的服务器.

Fig.4 Comparison results of offloading destination selecting rules, task sequencing strategies rules and resource allocation rules with 95%Tukey HSD confidence intervals图4 95% Tukey HSD 置信区间下卸载目的选择规则、任务排序规则和资源分配规则对比结果
由图4(b)可以看出,ND F 显著优于FCFS 和MSTF,其RPD值远小于FCFS 和MSTF 的;FCFS的RPD值小于MSTF 的,表明MSTF 效果最差.FCFS 优先处理先到来任务,使计算资源可能空闲,但未考虑任务自身属性,尤其是其截止期约束,影响总延迟时间;NDF 基于截止期逼近程度进行任务排序,充分考虑任务达到边缘节点时间和截止期约束,可尽量减小总延迟时间;MSTF 将松弛时间大的任务推迟执行,在一定程度上减少任务延迟时间,但当任务数多时将造成多个任务都超期完成,使总延迟时间更大.因此,选择NDF 进行任务排序较好.
由图4(c)可以看出,EFTF 相比ESTF 和LBF 其RPD值更小.EFTF 为任务分配具有最早完成时间的虚拟机,使任务具有最短执行时间;ESTF 规则选择最早可用的虚拟机,尽早地开始执行任务,避免任务长时间等待,造成任务超期完成;LBF 均衡节点中各虚拟机负载,避免高性能虚拟机过度占用,导致后续截止期逼近程度大的任务无法获取高性能计算资源而超出截止期.本文选择EFTF 规则进行资源分配.
由图5 可以看出,随着μ,ν取值的增加,RPD值呈下降趋势,但在统计意义上RPD没有显著性差别,因此本文 μ = 0.3,ν = 0.15.

Fig.5 Mean plots of RPD with difference μ,ν under 95% Tukey HSD confidence intervals图5 95%Tukey HSD 置信区间下不同μ,ν的RPD 均值图
4.2 算法比较
由于所考虑的问题是新问题,尚未有现成的方法可以参考,因此我们将3 个同类相关问题的常见策略与所提出的TOSD 算法进行比较:
1)单边缘本地独立卸载法LOCAL.每个边缘节点覆盖范围内的任务只能传输至当前边缘节点或云数据中心执行,不能卸载至其他边缘节点上执行,这种策略属于边缘.
2)最早完成时间优先的多边缘协同卸载方法TOMES.每个边缘节点都可以接收其他边缘节点附近的任务,按照最早完成时间优先规则进行任务指派.
3)最早开始时间优先的多边缘协同卸载方法NOPSO.每个边缘节点都可以接收其他边缘节点附近的任务,按照最早开始时间优先规则进行任务指派,NOPSO 与TOSD 类似,但无结果调优步骤,仍然采用该方法产生随机实例,比较这4 个算法与任务数、边缘节点数、任务分布和截止期等关键参数在95%Tukey HSD 置信区间统计意义下的相互作用,RPD结果如图6~7 所示.
图6(a)表明随着任务数量的增加,各算法的RPD值下降.任意任务数量规模下,TOSD 的性能都最佳;LOCAL 性能最差,其主要原因在于LOCAL 未进行多边缘协同调度,没有充分利用异构边缘系统中其他空闲边缘节点的计算能力;TOMES 的RPD均值相较TOSD 的有一定差距,其原因在于TOMES 仅考虑任务卸载,权衡任务传输时间和执行时间,但未考虑多用户间对资源的竞争;NOPSO 相较于TOSD的RPD均值较高,表明进行调度结果调优减少任务超出截止期的比例.随任务数的增大,RPD均值间的差距越来越小,其原因在于任务数量增多时,每个节点上的负载增加,计算资源逐渐到达瓶颈,每个任务在执行过程中超出截止期的可能性增大,导致总延迟时间差值变小.
由图6(b)可以看出,在所有边缘节点数,TOSD的性能都最佳.随着边缘节点数增加,TOSD 的RPD均值呈下降趋势、NOPSO 的RPD均值先降后升、LOCAL 和TOMES的RPD均值增加;其他3 种算法与TOSD 算法的RPD均值差距变大,其原因在于当边缘节点数增加时,计算资源更加丰富,任务卸载和任务调度对结果影响更大.
图7(a)表明,随着参数 λ的变化,TOSD 算法性能最稳定;NOPSO 和LOCAL 的RPD均值随 λ值增加而增加;尽管TOMES 的RPD均值随 λ值增加而减少,但其初始值远大于TOSD 的初始值.采取ZipF 分布模拟边缘系统中任务分布,λ值越大表明任务分布越不均匀,λ=0表示任务均匀分布在边缘系统中各节点覆盖范围内.随参数 λ值的增大,任务分布不均匀程度变大,LOCAL 算法RPD均值逐渐增大的原因在于部分边缘节点过载,导致在其上执行的任务延迟时间较长,未采用卸载策略充分利用其他较为空闲的边缘节点.TOSD 比NOPSO 算法的RPD均值小,其原因在于其采取调度结果调优,性能得以提升.
由图7(b)可以看出,TOSD 算法对任务截止期区间不敏感且任何情形平均RPD值都最小;其他3 个算法随着截止期区间的增加RPD值也增加(性能下降),其原因在于随着任务延迟敏感程度的降低,任务传输至其他边缘节点上执行所需付出的代价较大,造成任务延迟时间增长.当任务截止期在[0.5, 2]中取值时,4 种算法的RPD均值基本差不多.
经过实验比较可以看出,单边缘本地独立卸载法LOCAL 在所有测试实例参数变化下表现最差,其主要原因是边缘节点只能处理其附近产生的任务,虽然就近策略可以产生较少的通信延迟时间,但是如果边缘节点附近产生任务过多,容易产生任务积压,从而造成总延迟时间变长.TOMES 和NOPSO 能够很好地在空闲边缘节点与繁忙边缘节点之间进行协同任务调度,因此性能较LOCAL 更好.但是TOMES 和NOPSO 均未像TOSD那样考虑多用户间对资源的竞争,因此性能也有所降低.TOSD 的优势主要在于:1)度量了边缘节点的空闲程度,保证了负载均衡;2)优先卸载松弛度低的任务,降低了任务超期执行的概率;3)在为任务决定指派节点时,综合考虑了节点距离和负载情况,以尽量降低通信延迟和等待时间;4)引入了具有一定随机性的调优策略,避免上述贪婪选择陷入局部最优,有一定概率跳出局部最优,逼近全局最优.
5 总 结
本文考虑异构边缘环境下带截止期约束的任务卸载和调度问题,提出异构边缘协同的任务卸载和调度算法框架TOSD,解决确定哪些边缘网络节点的任务太多需要卸载、确定各节点上需卸载哪些任务、确定任务卸载到哪些服务器、任务按照什么顺序调度、如何为每个任务分配资源等核心问题.采用多因素方差分析技术ANOVA 对算法算子和参数进行校正,选取最佳的算子和参数组合作为解决所考虑问题的算法.将TOSD 算法与其变种算法对比,通过实验结果可以看出,所提出算法在不同参数设置下都明显优于其他对比算法,验证了所提出算法算子对所考虑问题都有效.
本文从异构边缘环境资源层面考虑边缘服务器和云数据中心服务器,还有很多值得研究的问题,如:1)终端设备往往拥有一定的计算能力,可执行一定数量的任务,如何进行任务调度值得研究;2)终端设备具有移动性,任务提交位置与结果返回位置可能不同,如何考虑终端设备移动的任务调度值得研究.
作者贡献声明:李小平负责算法设计、论文观点的提炼和论文撰写工作;周志星负责算法开发与实验环境搭建;陈龙负责实验设计与实验数据分析;朱洁负责研究实验调研、论文修改.
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
通信产业报(2016年44期)2017-03-13
组合机床与自动化加工技术(2015年1期)2015-11-03
传感技术学报(2014年9期)2014-09-06
北京航空航天大学学报(2012年12期)2012-06-22
湖北民族大学学报(自然科学版)(2010年1期)2010-01-18
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
