
HyWarm:针对处理器 RTL 仿真的自适应混合预热方法
2023-06-07 03:40:40周耀阳韩博阳蔺嘉炜王凯帆张林隽余子濠孙凝晖包云岗
计算机研究与发展 2023年6期
周耀阳 韩博阳 蔺嘉炜 王凯帆 张林隽 余子濠 唐 丹,3 王 卅,2 孙凝晖包云岗,2
1 (处理器芯片全国重点实验室(中国科学院计算技术研究所)北京 100190)
2 (中国科学院大学计算机科学与技术学院 北京 100049)
3 (北京开源芯片研究院 北京 100080)
4 (香港大学电机电子工程系 香港 999077)
在近几年的芯片敏捷开发浪潮中,得益于Chisel,BlueSpec,PyMtl 等新兴的硬件描述语言和Rocketchip等SoC 平台,直接基于寄存器传输级(register-transfer level,RTL)描述进行CPU 架构的设计变得越来越常见[1-6].随着社区的不断发展,基于这些语言的开源设计架构越来越先进,其设计也越来越复杂,例如加州大学伯克利分校开源的Boom 和中国科学院计算技术研究所开源的香山处理器[4,6-8].复杂的设计对现有的性能评估设施提出了更高的要求,例如AWS 的云化FPGA 已经难以容纳目前最复杂的开源处理器核[4].
为了使设计规模不受限制,部分工作[4]采用了基于RTL 软件仿真器的技术路线.但是对于复杂设计而言,常用的RTL 软件仿真器(例如Verilator[9]和VCS)仿真复杂设计的速度仅有500~3 000 cycle/s[4].为了加速仿真流程,利用采样和功能预热来减少仿真指令数是最常见的方法[10-12].虽然这些方法起初是在GEM5等CPU 架构模拟器上诞生,但在RTL 软件仿真器上,有越来越多的工作通过采样和检查点等方法来减少仿真指令数、缩短仿真时间[4,13].
采样方法基于机器学习或者统计学方法从冗长的程序中选择很少一部分片段作为代表来进行性能测量,获得程序性能计数器,用于估算整个程序的性能(如图1 所示).这些采样方法的典型代表是SimPoint[10]和SMARTS[11].对于SPECCPU®这样的大型程序而言,这些采样方法[10-11]可以将总测量指令数缩减到千分之一以下.
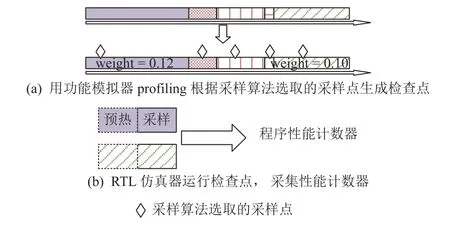
Fig.1 Existing sampling-based simulation methods图1 现有的基于采样的仿真方法
采样方法会引入冷启动问题,即程序在特定采样点(region of interest, ROI)开始执行时,处理器的微架构状态与从头开始运行时是不同的.为此,引入了预热机制,即在采样点开始之前增加一段不参与数据统计的预热执行阶段(如图1(b)所示),使微结构状态更贴近从头开始执行[10-11,14].在提高其准确度的同时,预热也造成了额外的仿真指令数.为此,通过功能预热、虚拟化预热等方法来降低预热带来的额外开销[11,15-17].
如图2 所示,即使应用了现有的检查点技术[4]和Verilator 的多线程加速[9],仍然存在需要仿真超30 h的检查点(每个检查点均采用Verilator 开启16 线程仿真,运行40M 指令).研究表明,为了降低单检查点的指令数,可以缩短单个检查点的采样长度[10-11],但不能缩短预热长度,否则会损失性能[14,18](详见1.3节).因此预热时间占比会从现在的约50%进一步上升,可见,加速RTL 预热非常重要.
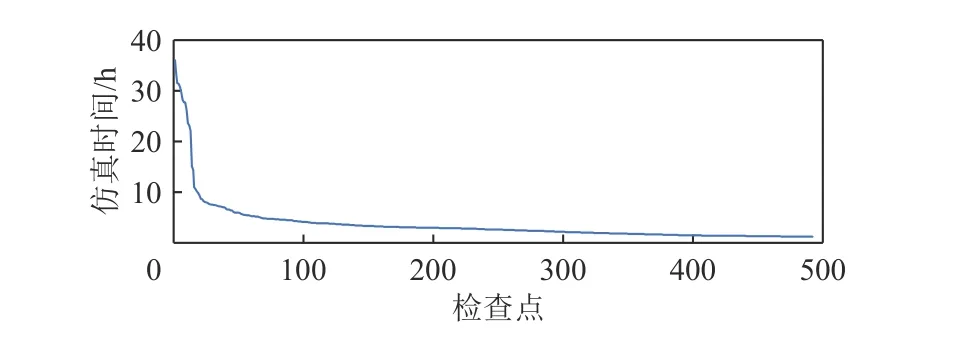
Fig.2 Emulation time distribution of 492 checkpoints from SPECCPU® 2006图2 来自SPECCPU® 2006 的492 个检查点的仿真时间分布
为了加速RTL 仿真预热,本文通过profiling(尝试不同的预热长度)根据程序预热需求将预热过程分为3 段,如图3 所示.对这3 段分而治之:1)完全跳过非必要预热;2)对可功能预热段采用功能预热加速;3)对必须采用RTL 仿真的部分使用并行加速和调度优化.为了达成修改方案,需要回答3 个问题:1)在RTL 仿真极其缓慢的背景下,面对快速迭代的设计,如何高效地profiling;2)在快速迭代的设计上,如何实现可复用的功能预热;3)在任务时长分布不均、多任务间存在性能干扰的情况下,如何调度计算资源尽快完成全细节仿真.
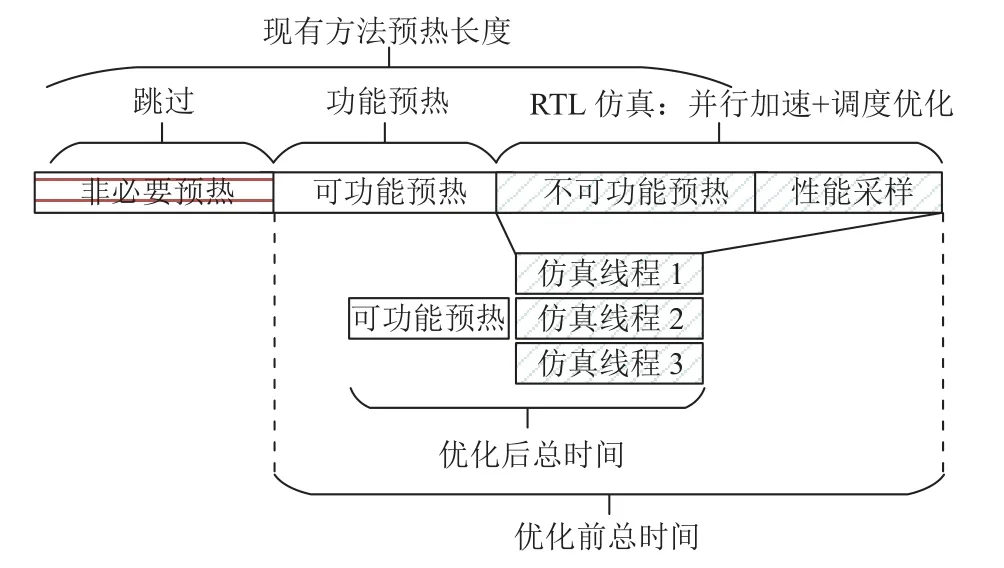
Fig.3 Optimization overview of HyWarm: Existing fixed warm up duration is divided into three segments图3 HyWarm 的优化概览:将现存固定预热长度分为3 段
问题1:在RTL 仿真极其缓慢的背景下,面对快速迭代的设计,如何高效地profiling.现有工作通过profiling 来获取应用的实际预热需求(指令数),这可以缩短不必要的预热长度[14,17,19-20].但每当面对新设计(比如缓存容量增加)时,重新profiling 反而增加了全细节仿真指令数[20].面对该挑战,我们发现架构模拟器不仅运行速度比RTL 快,而且可以得到近似的程序预热需求(实验数据见2.1 节和4.2 节).因此,用模拟器替代RTL 仿真进行profiling可以兼顾速度和准确度.
问题2:在快速迭代的设计上,如何实现可复用的功能预热.尽管模拟器上的功能预热已经得到了充分研究,但是没有现存的在RTL 上实现功能预热的方法.其中,最大的难题是我们很难锚定RTL 生成的C++数据结构进行功能预热.因为从RTL 生成的C++数据结构可读性非常差,且变量名和存储结构会随着设计的变化而变化.面对该挑战,我们发现虽然生成的C++数据结构会改变,但是总线协议是相对固定的,例如AMBA[21],TileLink[22].如果锚定通用的缓存协议实现缓存功能预热,那么只要总线协议不改变就可以复用功能预热模块.
问题3:在任务时长分布不均,多任务间存在性能干扰的情况下,如何调度计算资源尽快完成全细节仿真.图2 表明一部分负载的仿真时间较长,成为了影响仿真时间的最重要因素,因此任务调度需要避免负载不均衡.此外,在应用满载运行多个多线程任务时观察到了相较于单任务运行时的45%的性能损失,如表1 所示,其中IPS 是每秒仿真的指令数量,仿真对象为香山处理器运行dhrystone.这促使我们重新思考多线程和多任务对全系统吞吐的影响,并得出了CPU 核分簇方案(见2.2 节).在此基础上,以CPU 簇为调度粒度,对任务采用长作业优先(long job first, LJF)调度算法,该算法被证明最大完成时间在最差情况下只有最优调度的4/3[23-24].
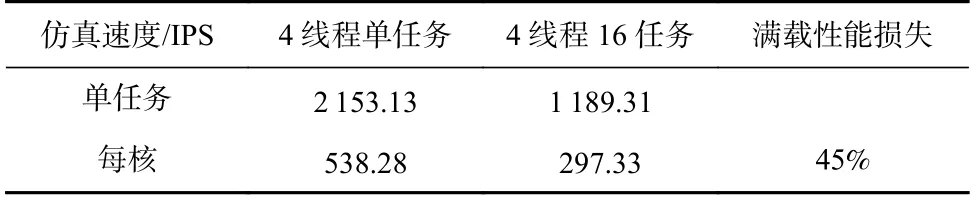
Table 1 Emulation Speed of Verilator with Different Parallelism on AMD EPYC 7H12 Server with 64 Cores表1 在AMD EPYC 7H12 64 核服务器上运行不同并行任务数的Verilator 的仿真速度
综上,本文提出了HyWarm 框架,它包括:1)基于架构模拟器进行预热需求分析,可以快速获得负载的预热需求的工具WarmProfiler;2)通过锚定总线协议实现可复用的RTL 功能预热的工具TLWarmer;3)最大化系统吞吐、缩短最大完成时间的分簇LJF调度算法.
我们在香山处理器[4]上实现了HyWarm 框架.其中,TLWarmer 将8 MB 缓存预热时间从10~100 h 缩短到少于0.5 h.相对于MINJIE[4]平台的检查点采样方案,HyWarm 能达到接近25M 指令全细节预热的准确度(HyWarm 的 L1 缺失惩罚准确率为95.1%,分支的每千条指令分支预测错误数(MPKI)准确率为 91.6%;25M 全细节预热的L1 缺失惩罚准确率为91.3%,分支MPKI 准确率为94.1%).在准确率与基线配置(25M)接近的情况下,相比于25M 预热+随机调度的基线,HyWarm 将仿真完成时间缩短了53%.
本文的贡献包括3 个部分:
1)提出了 HyWarm 预热框架,通过架构模拟器识别应用的预热需求,预测应用仿真时长;然后利用功能预热和调度优化来缩短仿真时长.
2)提出了一种利用总线协议来进行缓存功能预热的思路,并在TileLink 协议上实现,大幅缩短了功能预热的时间.
3)分析了多核扩展和任务间性能干扰对Verilator仿真的性能影响,得出了效率最优的CPU 簇划分策略,并在此基础上应用LJF 调度算法来减少最大完成时间.
1 背景与挑战
1.1 硅前性能测算方法
在芯片设计中,硅前性能测算对设计决策至关重要.现存的硅前性能测算手段主要包括3 类:RTL软件仿真器、基于FPGA 的硬件加速仿真和基于仿真加速器的硬件加速仿真.表2 列出了芯片设计过程中进行仿真的4 种常用方法.

Table 2 Comparison of Commonly Used RTL Performance Evaluation Methods表2 常用的RTL 性能评估方法对比
此前,基于FPGA 的硬件加速仿真被充分研究,有的工作[25]优化了从CPU 模块到FPGA 资源的映射,使得基于FPGA 的硬件加速仿真达到更高的运行频率.有的工作[26]利用AWS 的云FPGA 来提高FPGA硬件加速的易用性.还有工作[27]利用FPGA 进行电路的功耗预测和建模.然而文献[25-27]的工作都未能解决FPGA 的资源容量限制CPU 设计规模的问题[28-29],例如AWS F1 提供的vu9p FPGA 芯片就因为BRAM 和LUT 的开销无法容纳双核标配的香山处理器[4].
在工业界,商业公司设计复杂SoC 时往往会使用仿真加速器,例如Cadence Palladium[30],Mentor Veloce[31]和Synopsys Zebu[32].仿真加速器拥有比FPGA 更高的扩展性,但是一台仿真加速器的价格往往超过一千万人民币,这导致一个商业公司内部往往只有少量的仿真加速器.而且仿真加速器的仿真频率一般在几个MHz[4],比FPGA 慢1%~10%,用一台仿真加速器来进行SPECCPU®2006 的测评至少需要几个月的时间,在实际的场景中也是不可接受的.
相比于FPGA 和仿真加速器,RTL 软件仿真拥有最好的可扩展性、易调试性,它可以同时支持波形和文字打印,并且电路的规模只受限于服务器的内存容量.但RTL 软件仿真器速度非常慢,根据仿真性能估算,如果用最快的开源RTL 仿真平台Verilator 来仿真香山处理器并评估SPECCPU®2006/2017 的性能,预估需要超过7 年的时间[4,9].
开源RTL 仿真器Verilator 和商业仿真器VCS 是被开源处理器社区广泛采用的两大仿真平台.Verilator 通过块重排序、网表级优化获得了比商业仿真器更快的仿真速度.Verilator 还能将仿真任务划分到多个CPU 核上并行执行来提升仿真速度.ESSENT使用了重用不变信号等技术,获得了相较于Verilator 1.5~11.5 倍的性能提升[33].然而即使获得了近1 个数量级的提升仍然无法让RTL 仿真速度胜任香山处理器的性能评估(预计耗时数月到1 年).
1.2 仿真采样
针对RTL 软件仿真速度慢的问题,可以采用体系结构研究中常用的采样方法来减少仿真指令数.SimPoint[10]和SMARTS[11]是最广泛使用的2 种采样方法.SimPoint 通过功能模拟器获得基本块向量,然后对基本块向量进行聚类,得到具有代表性的程序片段和相应的权重,并通过运行这些片段来估算整体性能,如 图4(a)所示.SMARTS 则在程序中选取大量且均匀的采样点来估算整体性能,如 图4(b)所示.二者都可以大幅减少仿真的指令数(减少到0.1%以下).此外,在SimPoint 和SMARTS 的基础上,后续的工作改进了预热方法[11,14,16-17,34-36],支持多线程应用[37-39], 捕捉微结构相关特征[40].虽然文献[10-11]的采样算法可以减少总仿真指令数并加速RTL 软件仿真,但是这些算法无法直接应用于RTL 软件仿真.GEM5 模拟器与RTL 仿真器最大的不同在于GEM5 为从功能模型中串行化得到体系结构状态、从串行化的体系结构状态中恢复状态到微架构模型做了很多支持,但是RTL 仿真器缺乏类似的串行化和去串行化支持.
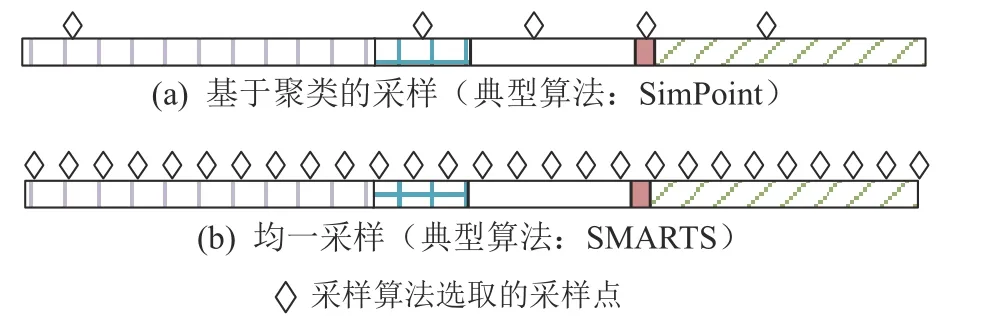
Fig.4 Mainstream sampling-based simulation methods图4 主流的基于采样的仿真方法
为了解决在RTL 上对体系结构状态去串行化的问题,现有研究采用通过软件自动去串行化的方法来实现跨硬件平台的体系结构状态检查点[4,13].这些方法的共同点在于,它们都选择了一个在指令集定义中较稳定的接口,并通过软件的方式来恢复.Dromajo 使用了RISC-V 调试模块来恢复体系结构状态[13,41];而香山处理器采用了RISC-V 特权指令来恢复体系结构状态[4].这2 种体系结构检查点的实现方法都可以支持SimPoint 等采样方法,从而让RTL 软件仿真的时间大幅度缩短.例如MinJie 平台所使用的检查点技术[4]让香山处理器在理论上需要数年才能完成,而SPECCPU®2006[42]的仿真在2~14 天就可以完成.
图2 展示了采用体系结构检查点和SimPoint 采样算法后,香山处理器仿真检查点的时间(40M 指令).这些负载的仿真时间分布非常不均匀,假设计算资源充足,那么多数负载可以在10 h 内完成,而剩下的负载需要超过30 h 才能完成,少数检查点由于运行时间过长已经成为整个流程的关键路径.
为了进一步加速性能测算,可以降低单个检查点的采样长度.研究表明,在总采样指令数一定的前提下,减少每个采样片段执行的指令并相应地增加采样片段个数,不会损失准确度[10-11].例如,将N个20M 指令的采样片段变为4N个5M 指令的片段.虽然这种方法能保证准确度,但会增加仿真的总指令数.例如从(20M+20M)×N变为(20M+5M)×4N,总仿真指令数增加了150%,预热指令数占比上升到80%.因此,为了缩短仿真时间,需要缩短预热时间.
1.3 预热加速技术
已有研究表明部分应用的预热需求超过200M[14,18],因此200M 指令的预热长度不能进一步缩短.虽然预热长度无法缩短,但是研究者发明了“功能预热”来减少全细节预热的长度.具体而言,功能预热通过功能模拟以更快的速度预热一部分微结构模块,然后再用全细节仿真来预热整个CPU.
功能预热是最常用的预热加速技术,它与全细节预热的最大区别是用功能CPU 来驱动缓存,以提高预热速度.例如,在GEM5 模拟器中,可以用一个运行速度较快的顺序CPU 驱动多级缓存,待缓存充分填充缓存块之后,再将CPU 换为乱序执行架构.得益于良好的软件接口,在GEM5 模拟器切换CPU 时只需要将SoC 的CPU 指针指向乱序CPU 即可.
但在RTL 中,我们难以实现一个针对RTL 生成的C++数据结构的功能预热模块.因为处理器设计迭代会带来新的RTL,导致RTL 生成的C++代码的数据结构也会随之变化,旧的功能预热模块难以复用到新的设计上.此外,功能预热模块还需要精确地复刻RTL 中的微结构状态.即使业界顶尖的公司进行该工作也是非常困难的,因为对齐模拟器的工作量巨大[43-44].因此,为了实现RTL 功能预热需要新的解决方案.
虽然某些应用的预热需求很长,但是文献[14,18]的结果表明部分应用的预热需求很短.因此,可以通过缩短这部分应用的预热长度来节省预热时间.为了获得这部分应用的预热需求,需要对多种不同的预热长度进行尝试,并找到性能准确度损失较小的最短预热长度.在后续的重复运行中,可以采用较短的预热长度.但是这种profiling 方法并不适用于快速迭代的架构,也不适合架构参数搜索,因为随着缓存架构和规格的变化,旧的profiling 结果会失效,导致profiling 的开销无法均摊到多次的运行中[20].
2 观察与设计决策
2.1 混合预热加速的机会
1.2 节和1.3 节总结了RTL 软件仿真中现存的采样技术尚未解决的3 个挑战:1)RTL 仿真缺乏功能预热的基础设施,且难以实现针对RTL 生成的C++数据结构的功能预热模块;2)面对架构和参数的变化,难以通过多次运行来均摊profiling 预热需求的开销;3)少数的检查点由于运行时间过长已经成为整个流程的关键路径.
关于RTL 预热,我们有3 个观察:
1)CPU 的部分模块使用稳定的总线协议,例如缓存模块通常基于TileLink 协议[3,22]或者AMBA 总线协议[21].虽然缓存内部的微结构设计会不断迭代,但这些总线协议是稳定的.因此,只要设计一套基于总线协议而非针对微架构的功能预热方法,就可以在多个版本的RTL 中重复使用功能预热模块.
2)同一应用对不同模块的预热需求不同,特别是分支预测模块与缓存模块的预热需求通常存在较大差异.如图5 所示,sjeng 的分支MPKI 在预热长度为25M 时饱和,而L2 MPKI 在预热长度为4M 时饱和.因此,如果实现了功能预热,并提前了解某个应用对各个微结构模块的预热需求,可以针对性地调节功能预热和全细节预热的长度,以尽可能缩短完整预热所需时间.而为了“预知”负载的“可功能预热段”,需要提前测试多种可能的预热长度,从中选取既高效又精确的预热长度.
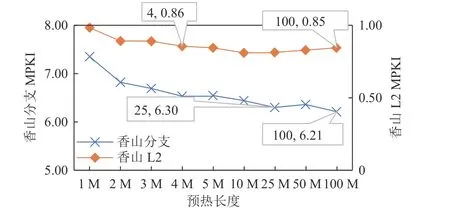
Fig.5 Warm up demand curve of sjeng图5 sjeng 的预热需求曲线
3)不同应用的预热需求不同.4.2 节的预热需求分析实验表明,约38%检查点的预热需求大于20M;约62%检查点的预热需求小于20M,其中约57%需求小于5M.如果我们能预知负载的预热需求,就可以在预热需求较小的应用上节约大量时间,同时为预热需求大的应用提供更长的预热以获得更高的准确性.
为了通过profiling 获得负载的预热需求,需要搜索多种不同的预热长度,这可能导致较大的时间开销.在搜索过程中,需要测量不同预热长度下的缓存MPKI 或者分支MPKI,从而构建如图6 所示的曲线;然后找到让MPKI 满足误差阈值的最小预热长度.在该过程中,必须测试多个预热长度:如果对9 个可选的预热长度进行二分查找(假设曲线单调),那么至少需要仿真4 个点,而仿真指令数量会增加约4 倍.增加的仿真工作量如果无法通过多次运行均摊,那么profiling 后缩短预热长度的收益无法填补profiling的代价[20].
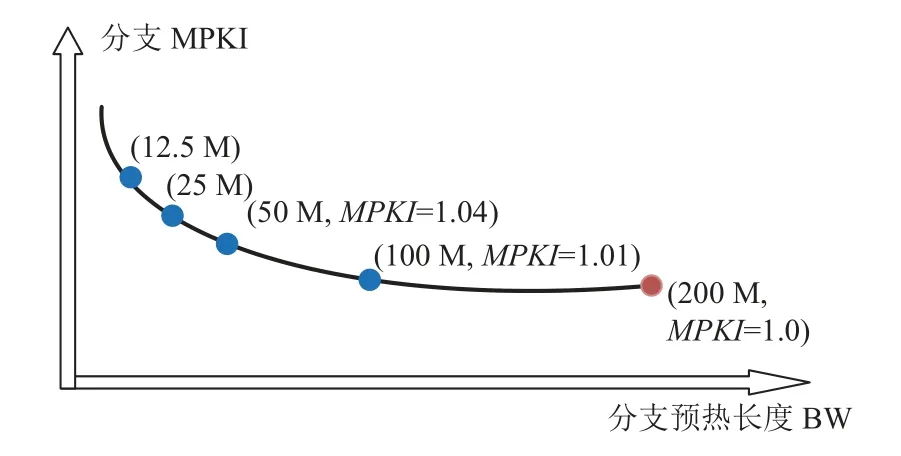
Fig.6 Warm up length search process图6 预热长度搜索过程
面对预热需求搜索的挑战,我们有2 个观察:1)架构模拟器的仿真速度是RTL 仿真器的100 倍左右(Verilator 仿真香山约1KCPS (cycle per second);GEM5约100KIPS(kilo instruction per second)),如果可以用架构模拟器进行profiling,那么整体的仿真时间就不会被profiling 拖累.2)相同的微结构算法的不同实现经过相同长度的预热之后留存的状态往往是相似的.这是因为受到了文献[45]的启发,文献[45]设计了简化的LRU 缓存用来恢复完整实现的LRU 缓存的状态,并取得了不错的准确率,并在预热需求上也观察到了类似的现象,如图7 所示,同为 32KB 的TAGE预测器,虽然由于循环预测器[46]和Statistical Corrector[47]的区别导致香山处理器与GEM5 的MPKI 存在差异,但是二者的预热需求都在50M 条指令附近饱和(更多数据见4.2 节和4.3 节).综合这2 个观察,为了高效地搜索预热需求,可以用微结构算法、规格相似的架构模拟器来近似估计RTL 的预热需求.
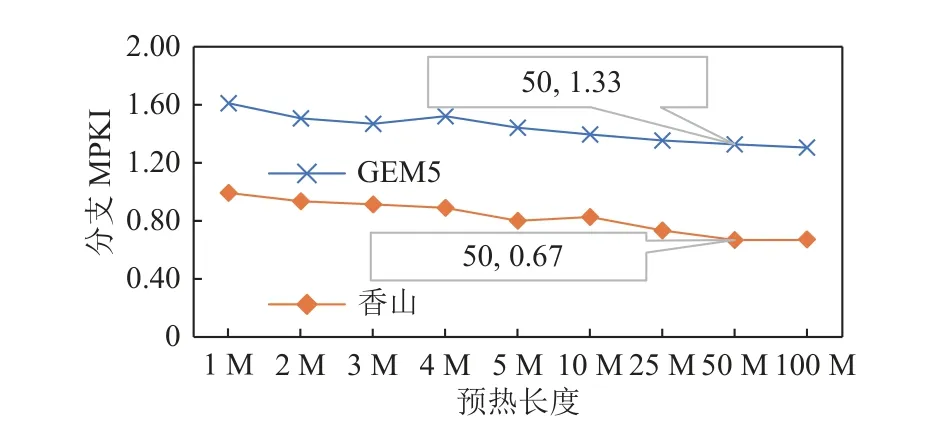
Fig.7 Warm up demand of branch predictors in GEM5 simulator and Xiangshan processor图7 GEM5 模拟器与香山处理器的分支预测器预热需求
2.2 CPU 分簇与调度方案
尽管我们努力缩短了负载的预热时间,但是未能改变整体的仿真时间分布特征.图2 中少量负载的仿真时长显著多于其它负载的现象仍然存在.这些检查点在不恰当地调度下有可能大幅度增加总仿真时间,例如将运行时间较长的多个任务调度到同一个核.因此,合理地调度任务使负载均衡分配非常重要.
然而,在实际系统中,对Verilator 仿真任务的调度比传统的作业调度更复杂:1)很难预知任务时长;2)Verilator 提供了多线程加速功能,如何在多线程非线性扩展的情况下找到较好的调度策略是个问题;3)多个仿真任务之间存在性能干扰.尤其是2)和3),使得本就是NP-hard 的任务调度问题变得更加复杂.
为了预知任务时长,我们利用profiling 阶段在架构模拟器中得到的IPC 来估算仿真任务的周期数作为仿真时间的近似(Verilator 的总仿真时间与周期数正相关).文献[43]表明,模拟器估算的每秒提交指令数(IPC)与RTL 的真实IPC 可能存在一定差距,但误差一般在可接受范围内,并且能较好地反映程序之间每秒提交指令数(IPC)的相对差距[43].这种排序的预测质量可以用归一化折现累积增益(normalized discounted cumulative gain,NDCG[48])描述.本文用GEM5 模拟器的模拟周期数排序来预测香山处理器的真实RTL 仿真时间排序效果较好,预测结果的NDCG 为0.88(1.0 为完美预测).
针对多线程调度问题,发现在任务时长分布不均时,为长任务开启多线程可以缩短仿真时间,如图8 所示,调度2 比调度1 的完成时间更短.如表3所示,各种多线程选项中,系统整体吞吐最高的方案是4 线程.

Table 3 Comparison of Multi-threading Scaling Efficiency of Verilator Emulation When Server Load is Low表3 服务器低负载时Verilator 仿真的多线程扩展效率对比
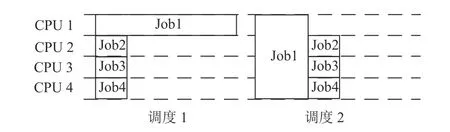
Fig.8 Impact of enabling multi-threading in Verilator on scheduling policy图8 开启Verilator 多线程对调度策略的影响
然而,表3 实验结果未能考虑任务间的性能干扰.当服务器的全部64 个核都被仿真任务占用时,观察到了相反的性能数据:8 线程和16 线程下的每核IPS 高于4 线程,这可能与Verilator 巨大的访存足迹有关[49],而这类访存足迹巨大的应用会在末级缓存或内存带宽对邻居造成干扰[50-55].对比运行单个4 线程任务和满载运行16 个4 线程任务下的性能计数器,发现满载时的宿主机进程IPC 比单任务时下降了约66%.
基于表3 和表4 的实验,将每个64 核服务器划分为N核的簇(N=8),总共有64/N= 8 个CPU 簇,并以CPU 簇为最小粒度进行调度.虽然,将CPU 核分簇调度不一定能得到全局最优调度,但是在考虑多核和系统干扰时最优调度难以获得,分簇调度至少是系统效率较高的一种方案.

Table 4 Comparison of Multi-threading Scaling Efficiency of Verilator Emulation When Server is Fully Loaded表4 服务器满载时Verilator 仿真的多线程扩展效率对比
在利用模拟器IPC 估算仿真时间和将服务器划分为线程簇的基础上,任务调度问题可规约为传统的作业调度问题.虽然要保证图9(c)的最优调度非常困难(NP-hard)[56-59],但是我们希望避免出现图9(a)那样糟糕的调度.因此选择了LJF.如图9(b)所示,已有工作证明LJF 的最大完成时间在最差情况下是最优调度的4/3[23-24,59].
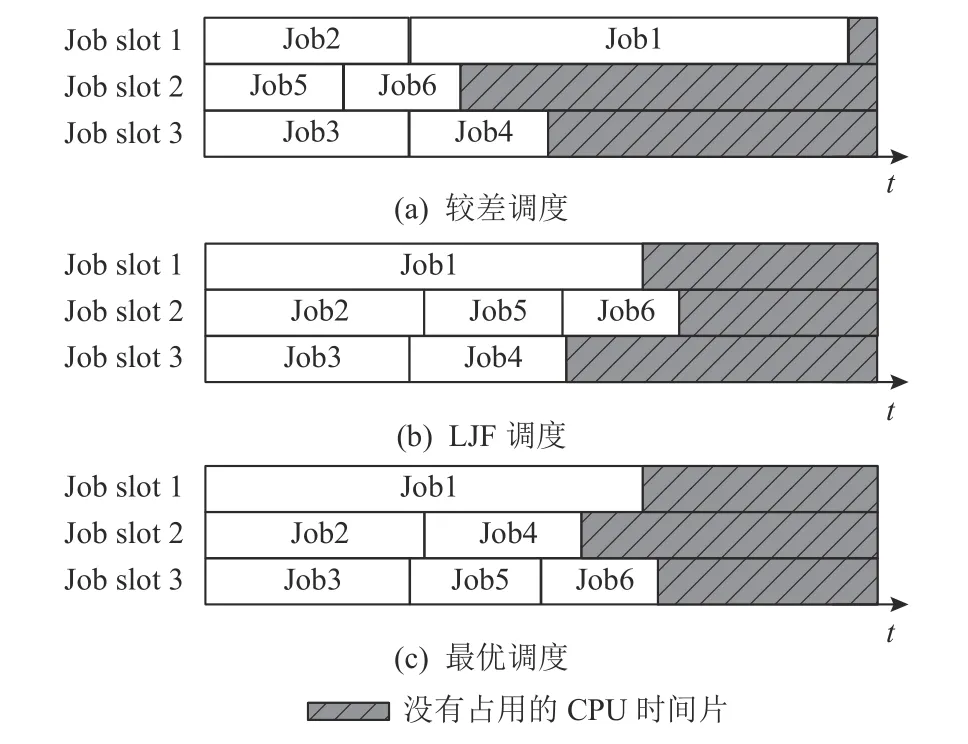
Fig.9 Comparison of maximum completion time under different scheduling policies.图9 不同的调度策略下最大完成时间对比
3 方法设计
基于观察和设计决策,本文提出了HyWarm 框架.HyWarm 分为3 部分:1)预热需求搜索模块Warm-Profiler,它会为每个检查点列出3 段预热需求区间((图3).2)功能预热加速模块TLWarmer,它基于通用总线协议进行缓存功能预热.3)并行调度模块,该部分利用WarmProfiler 得到的IPC 数据估算任务完成时间,以CPU 线程簇为粒度进行LJF 调度.HyWarm 的工作流程如图10 所示.WarmProfiler 首先会对不同的预热长度进行尝试(profiling),以获得检查点的全细节预热长度和功能预热长度;然后由TLWarmer 进行功能预热;在功能预热之后,会根据模拟器的IPC 预测每个负载的仿真时间T,并按照LJF 调度依次运行任务.
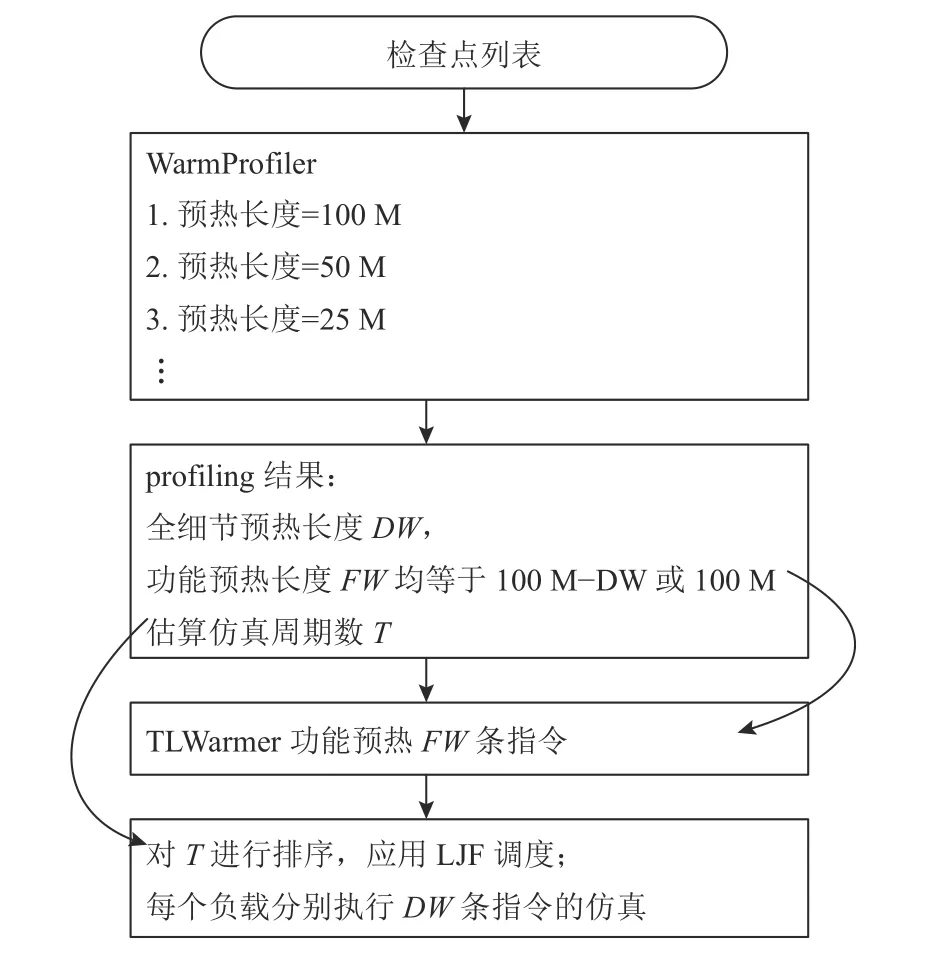
Fig.10 Workflow of HyWarm图10 HyWarm 工作流程
3.1 WarmProfiler
WarmProfiler 要搜索不同的预热长度以得到如图6 所示的MPKI 曲线.本文选择用9(1+N)个样本点来绘制MPKI 曲线,样本点的数量可以结合场景进行调整.
关于样本点的预热长度选取,在较长的区间选择几何级数递减的预热长度(100M,50M,25M,10M),在较短的区间采用等差数列递减的预热长度(5M,4M,…,1M).我们没有选择样本的预热区间均匀长度分布(100M,90M,…,10M),这是因为我们发现预热需求较小的应用占多数,如果采用均匀分布会导致大量的应用落到0~10M 的区间里并会选择10M 的预热长度,即使它们的需求只有1M.
在搜索过程中,WarmProfiler 首先用最长预热长度进行仿真(比如100M 指令)以获取基准MPKI,然后尝试寻找能达到MPKI 误差阈值的最小预热长度.对余下的8(N)个点,采用二分查找,最多需要运行3lbN 种配置就能找到满足要求的预热长度.
图6 展示了一个样本点数为5 的搜索过程,假设基准点预热200M,余下4 个点预热分别为100M,50M,25M,12.5M.假设MPKI阈值系数为103%.首先测得200M 预热下的MPKI=1.0;然后尝试50M 预热,得到的MPKI=1.04,其值大于MPKI阈值1.03,因此需要尝试更长的预热;其次得到100M 预热下的MPKI=1.01;最终从满足要求(MPKI<1.03)的点中选择预热长度最短的点(100M).该二分查找算法只在MPKI 与预热长度的函数关系单调递减时保证选到满足要求的最短预热长度.当函数不是单调递减时,可能会无法选到最短预热长度,但是不会损失性能准确度.在实践中发现,大部分应用的MPKI 都是关于预热长度的单调函数.这与之前的工作中预热越长MPKI 越低的观察相符[14,17].
通常情况下,缓存MPKI 曲线与分支预测MPKI相互独立,因此需要进行2 次WarmProfiler 的搜索过程,分别找到缓存MPKI 饱和点和分支预测MPKI 饱和点.假设缓存MPKI 的饱和预热长度为CW,分支预测MPKI 的饱和预热长度为BW.其中缓存预热可以由功能预热完成,而分支预测器需要全细节预热.据此,可以计算出全细节预热的长度为BW,功能预热的长度为FW=max(0,CW-BW).在实践中,因为功能预热的速度往往比全细节预热快1~2 个数量级,因此也可以选择固定的较长的CW(比如100M,200M 等).
3.2 TLWarmer
TLWarmer 的核心思想是利用像TileLink 这样的总线协议给二级、三级缓存注入预热后的缓存内容.注入时,用协议定义的接口向缓存发送访存请求,并从相应的缓存块取出缓存.值得讨论的是应该发送完整的访存请求还是经过过滤的访存请求.
为了完成缓存注入,有2 种技术路线:第1 种路线是发送完整的访存请求,即按程序顺序依次发送所有的访存指令到缓存中,并由RTL 的缓存替换算法决定留下哪些缓存块.第2 种路线是用模拟器的替换算法作为过滤器,只将最终留存于缓存中的块按照LRU 顺序注入RTL 缓存中.因为缓存块的数量一般远少于访存请求的数量,可以缩短功能预热的时间,所以我们选择了第2 种路线.为了方便起见,本文把第2 种路线命名为Filter 模式.
图11 展示了Filter 模式下的典型工作流程.首先用功能模拟器生成访存trace(一般只需20 s 左右即可采集200M 指令的trace),然后在缓存模拟器中重放这些trace,从而使缓存模拟器按某种替换算法留下缓存块.在缓存模拟器中留存的缓存块会通过TileLink 协议注入到缓存子系统中,缓存子系统如图12 所示.注入过程需要RTL 缓存子系统接收并处理128k 个访存请求(8MB/64B),该过程消耗的时间一般是几十分钟.
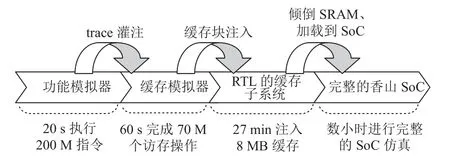
Fig.11 Workflow of Filter mode图11 Filter 模式的工作流程
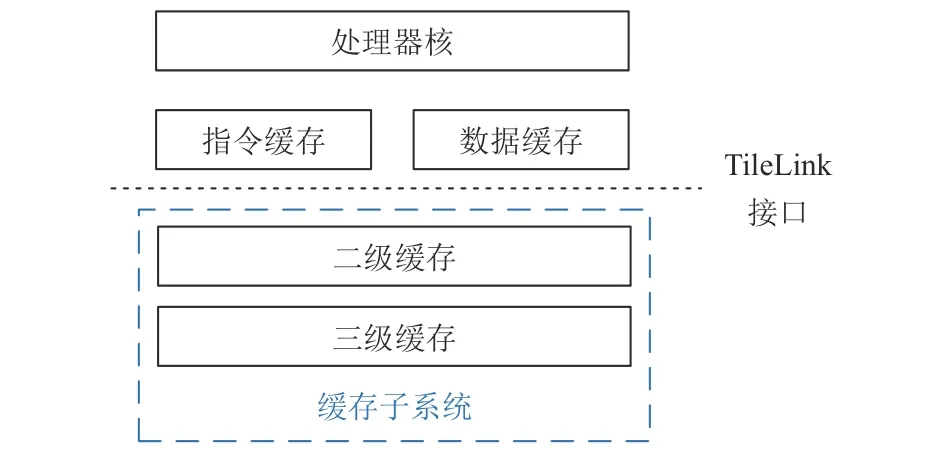
Fig.12 Cache subsystem that receives TileLink requests图12 接收TileLink 请求的缓存子系统
在完成缓存子系统预热之后,下一个挑战是现代处理器的缓存并不是一块简单的SRAM,而是需要分bank 和分块(block)[4,60],导致一块缓存经常包含几十个SRAM 实例.为此,我们利用Chisel/Firrtl 实现了自动化的SRAM 转储和恢复:首先在Chisel 中选择需要功能预热的缓存模块,并为这些模块包含的SRAM对象打上标记;然后在Firrtl 中对带标记的SRAM 对象自动生成转储和恢复的代码;最后当缓存块注入完成后,缓存子系统的SRAM 中的数据会被转储到很多个文件中,然后完整的SoC 启动时会将这些文件加载到对应的SRAM 中.
3.3 分簇调度模块
本文将64 核处理器核划分为8 个8 核的CPU 簇,然后在此基础上对所有任务进行LJF 调度:每完成一个任务,挑选剩下的任务中时长最长的任务运行.为了实现LJF 调度,需要知道任务时长排序,本文用任务的预估仿真周期数排序来替代任务时长排序.任务的预估仿真周期数是根据WarmProfiler 的架构模拟器的IPC 估算的,即预估周期数 等于负载指令数和IPC 相除.
4 实验评估
本节介绍HyWarm 带来的性能评估速度的收益.首先展示WarmProfiler 对SPECCPU®的预热需求的分析,以及功能预热能减少的仿真指令数;然后展示检查点的准确率和仿真时间对比,以证明功能预热能兼顾准确度和速度;最后展示负载的运行时间分布不均的问题,以及如何通过分簇调度来缓解少数负载仿真时间过长的问题.
4.1 实验配置与测量指标
1)实验配置.本文选取的实验负载是SPECCPU®2006 中用SimPoint 选取的检查点[10].由于实验需要测试大量的预热长度配置,为了缩短测试时间,本文为每一个子项的每一个输入数据选取权重最大的Sim-Point 检查点来进行实验.本文实验所采用的香山处理器架构配置如表5 所示.重放访存trace 所使用的缓存模拟器的规格与香山处理器的缓存规格一致[4].

Table 5 Microarchitectural Configuration表5 微结构配置
2)测量指标.本文研究预热长度时所使用的指标主要包括每条指令周期数(CPI)、一级缓存缺失惩罚(L1MP,一级缓存缺失时等待响应的周期数)、分支跳转MPKI.其中,L1MP 用于讨论缓存预热效果,BMPKI 用于讨论分支预测器预热效果,CPI 用于讨论整体预热效果.因为在现有的三级缓存实现中较难区分来自二级缓存的demand 请求和预取请求,所以三级缓存MPKI 未被纳入对比指标.虽然没有包含三级缓存MPKI 的数据,但是L1MP 能体现三级缓存中demand miss 带来的性能损失.
4.2 预热需求分析
图13 展示了WarmProfiler 在492 个SPECCPU®检查点上搜索预热需求的结果.本文首先统计了每个检查点的总预热需求,即取分支预测器预热需求和缓存预热需求的较大值.如果没有WarmProfiler,对所有的检查点都需要保守地运行100M 指令的预热.相反地,有了WarmProfiler 的指导,只有19 个检查点需要100M 预热和只有47 个检查点需要50M 预热.相对于100M 预热的baseline,WarmProfiler 将总的预热指令数减少了85.7%.
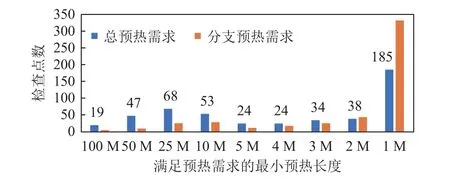
Fig.13 Distribution of warm up demand (the number of instructions) or checkpoints.图13 检查点的预热需求(指令数)分布
此外,因为TLWarmer 预热缓存不依赖于全细节预热,只考虑分支预测器预热,所以全细节预热的需求可以被进一步压缩:只有2 个检查点需要100M 的全细节预热和只有9 个检查点需要50M 的全细节预热.如果以100M 全细节预热为基线,总的全细节预热指令数减少 了95.6%.在WarmProfiler 中,本文借助了GEM5 这样的架构模拟器来搜索合适的预热需求.为了验证GEM5 所获得的预热需求是否与RTL的实际预热需求一致,本文对比了每个子项权重最大的检查点在GEM5 和RTL 上的预热需求曲线,并发现当GEM5 的参数与RTL 一致时,GEM5 与RTL的预热需求的趋势也较为接近.如图14 所示,多数子项的模拟器和RTL 的分支预热需求一致.而像gobmk.trevoc这样的子项在GEM5 上展示出了比RTL 更长或更短的预热需求.如果预热需求预测偏长会导致执行仿真时间增长;而预热需求预测偏短会导致分支MPKI 偏高.根据本文的实验结果,预测偏短导致分支MPKI 偏高超0.1 的负载占比为7.5%(4/53),详细数据在4.3 节给出.
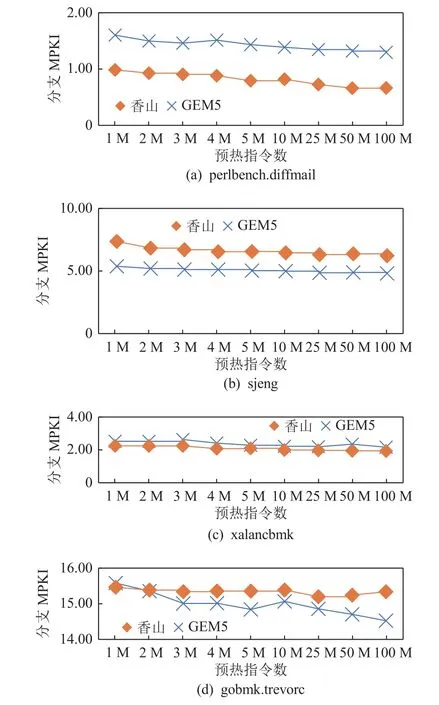
Fig.14 Warm up demand curve of GEM5 simulator and Xiangshan processor图14 GEM5 模拟器与香山处理器的预热需求曲线
除此之外,我们还发现了部分应用对预热长度并不敏感.以缓存为例,通过计算了各个子项的一级缓存缺失惩罚(L1MP)与预热长度之间的相关性(Pearson’s correlation),在53 个负载中,34 个负载的L1MP 与预热长度的相关性小于-0.5(我们预期L1MP与预热长度负相关),但是余下19 个负载没有显著的负相关.例如GemsFDTD,lbm,libquantum等负载的L1MP,L2 MPKI 均与预热长度没有明显的相关性,我们将这类负载称为预热不敏感应用.在接下来讨论预热效果时,本文仅讨论缓存或分支预热敏感型负载.
4.3 功能预热与混合预热
本节主要展示了功能预热和混合预热能在节约仿真时间的同时兼顾性能准确率.我们主要对比不同方案的仿真完成时间和性能准确率.对比了当性能测量长度为5M 条指令时的多种预热方案见表6,其中配置X+Y表示长度为X的功能预热之后进行长度为Y的全细节预热,Ada 表示根据WarmProfiler 的结果选取的预热方案,FixedFW(95+5)则是在没有WarmProfiler 的指导下进行固定长度的功能预热和全细节预热.
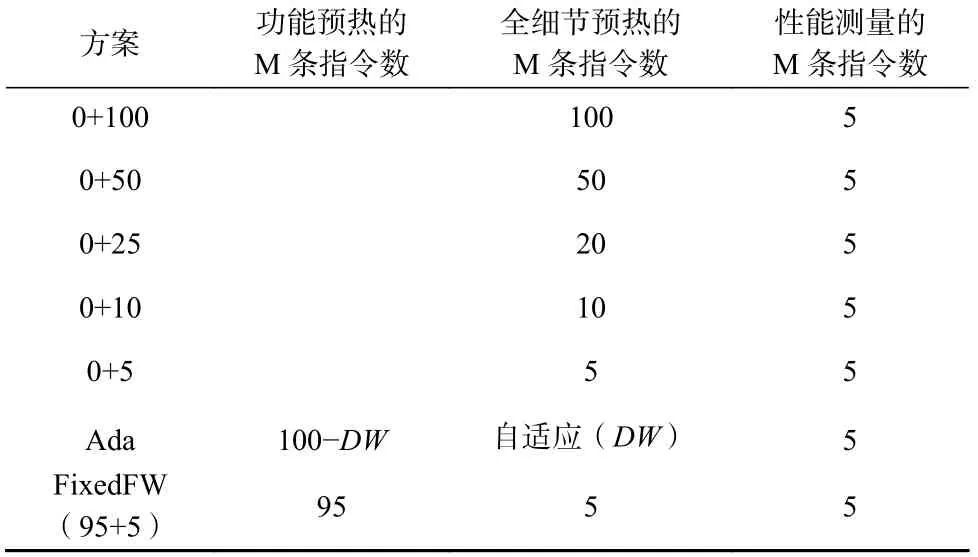
Table 6 Warm up Configurations表6 预热配置
图15 展示了不同预热方案相对于100M 全细节预热的L1MP 增幅.实验结果表明FixedFW (95+5)的混合预热方案显著优于0+5 的全细节预热方案,这体现了功能预热的有效性.Ada 和FixedFW 部分负载的L1MP 比100M 预热的基线更低(出现了负值),这可能与替换算法、预取算法有关,因为TLWarmer 只能恢复缓存的SRAM 中的内容,不能恢复预取器和影响块替换的metadata 的状态.对一部分负载,这会让有用的缓存块更容易留下,而对另一部分负载会让有用的缓存块更容易被替换.这也解释了为什么FixedFW(95+5)的方案无法达到100M 的全细节预热基线的L1MP.
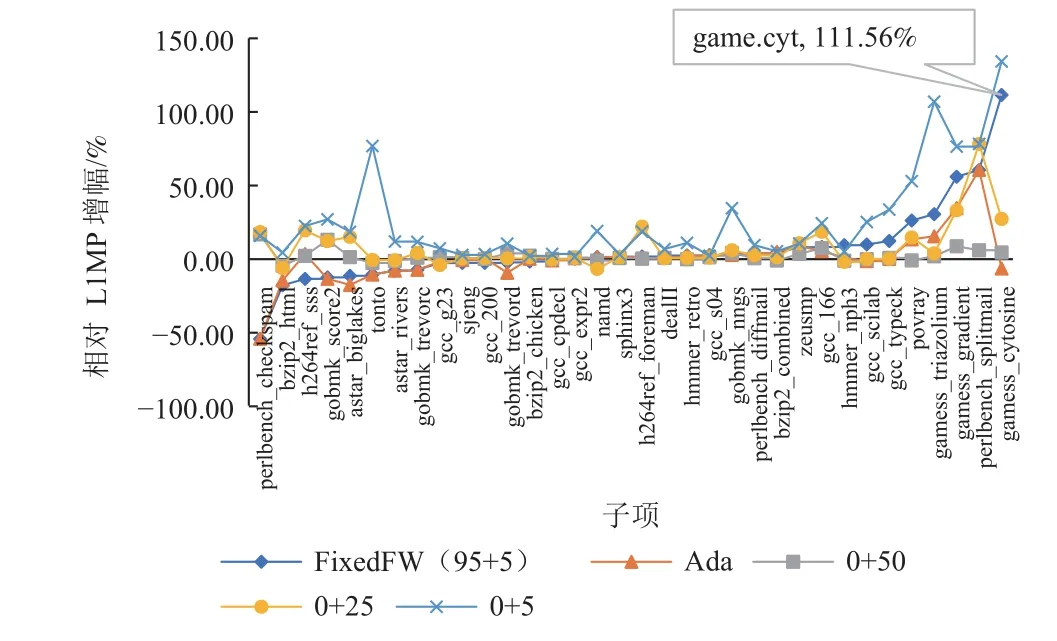
Fig.15 Impact of different warm up schemes on L1MP图15 不同预热方案对L1MP 的影响
从仿真总时间来看,功能预热的时间取决于需要恢复的缓存块的个数,一般仅需要5~30 min.得益于此,混合功能预热方案FixedFW(38.5 h)只需要比0+5 方案(35.8 h)略多的总仿真时间,就能获得与0+25 相当的缓存预热效果,见表7.
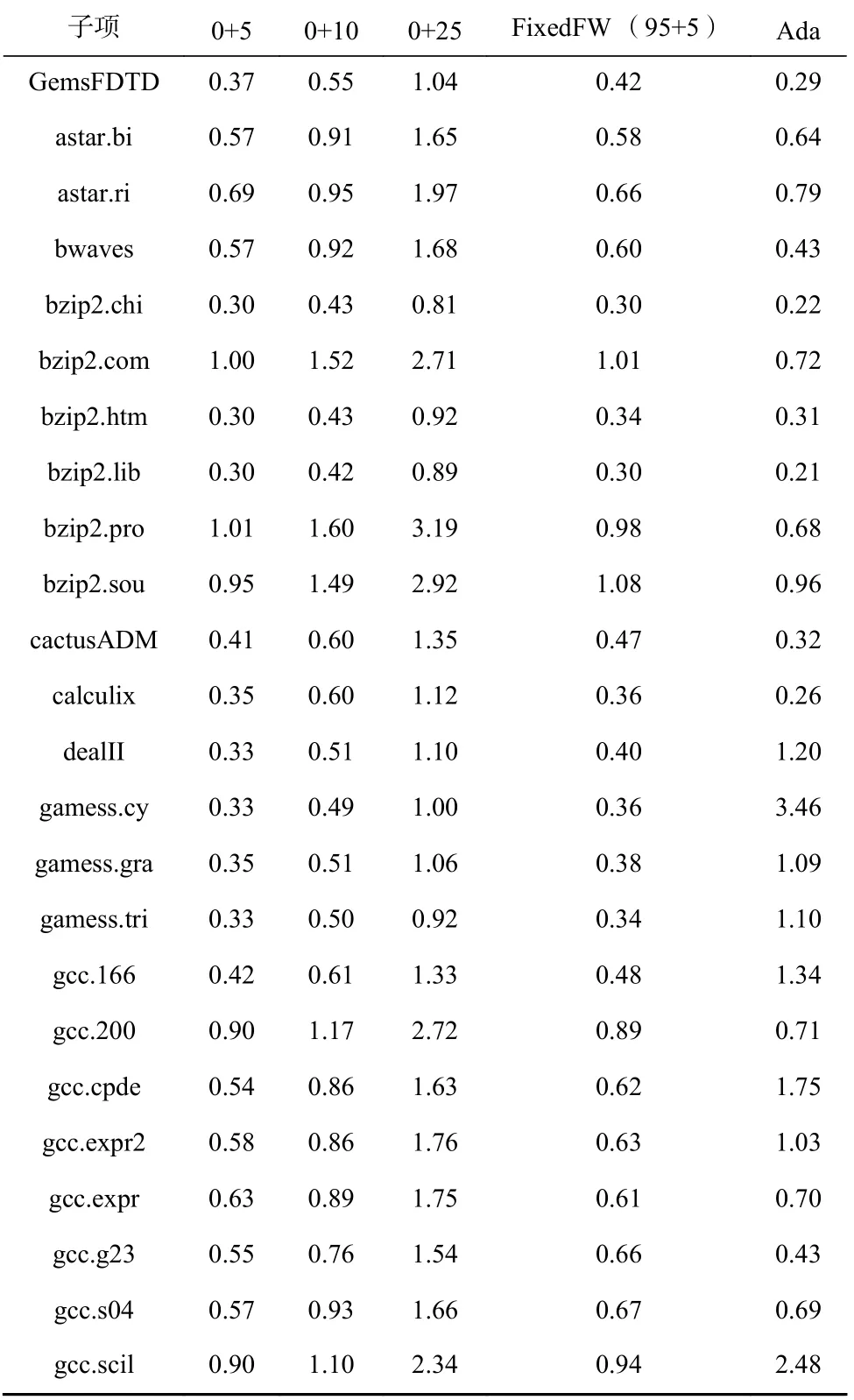
Table 7 Comparison of Total Simulation Time for Different Functional Warm up Schemes表7 不同功能预热方案的总仿真时长对比 h
从4.2 节的性能评估结果可以看出,负载的预热需求往往是随着负载特征变化的,盲目地选取FixedFW (95+5)的方案实际上无法适应这种变化.而在WarmProfiler 的支持下,可以选择出对性能评估准确度牺牲较小,同时又节约时间的全细节预热长度.在图15、图16 和图17 中由WarmProfiler 指导的混合预热方案被标注为Ada (adaptive),数据点按FixedFW 方案的相对增幅排序.实验结果表明,自适应混合预热达到了与0+25 接近的准确率见表8;而所需的总串行仿真时间为54.40 h,仅略大于0+10 方案,见表7.
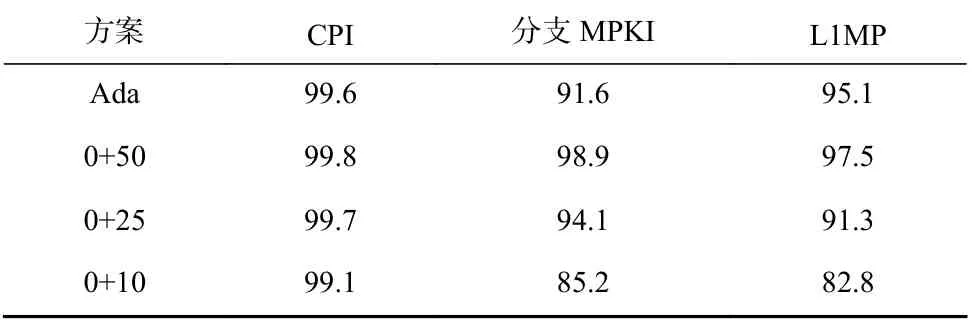
Table 8 Accuracy Comparison of Different Schemes表8 不同方案准确率对比%
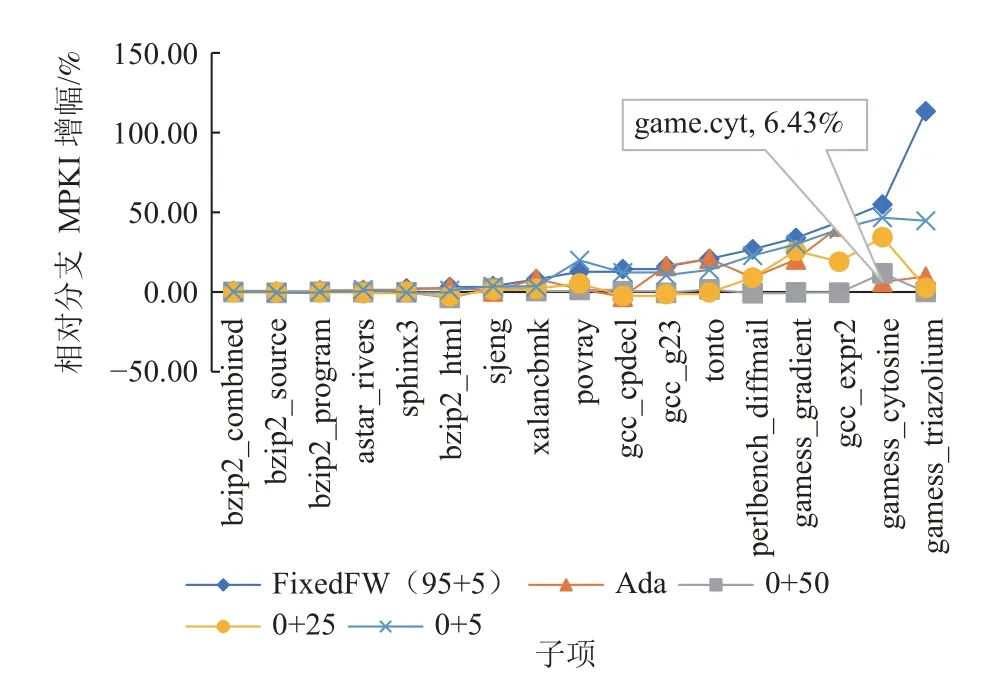
Fig.16 Impact of different warm up schemes on branch MPKI图16 不同预热方案对分支MPKI 的影响
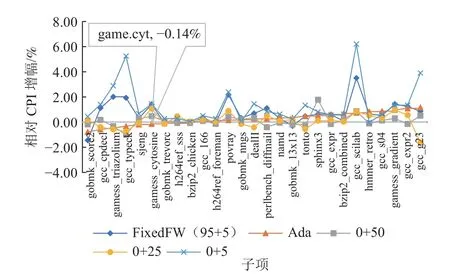
Fig.17 Impact of different warm up schemes on CPI图17 不同预热方案对CPI 的影响
gamess_cytosine 是一个体现自适应预热优势的例子,在使用FixedFW 混合预热方案时,gamess_cytosine的L1MP,分支MPKI 和CPI 增幅都较大.而Warm-Profiler 的全细节预热需求很大,即使0+50 的全细节预热也无法使它的分支MPKI 达到接近0+100 的情况.因此,为了保证准确性,WarmProfiler 直接为gamess_cytosine 选择了0+100 的预热方案.在gamess_triazolium上,也看到了类似的现象,WarmProfiler 选择了75+25的混合预热方案.
本文将基于模拟器的预热需求预测和完美预测作了对比,其中完美预测直接利用RTL 进行预热需求搜索,得到分支预测器预热饱和点.表9 列出了所有GEM5 预测预热需求偏低造成MPKI 偏高的负载点(因为更低的MPKI 更接近完整的100M 预热,所以我们认为MPKI 更低是更准确的表现),其中仅4个负载点遭遇了超过0.1 的分支MPKI 误差.而根据计算,0.1 的分支MPKI 误差导致的CPI 误差一般不超过0.3%.在预热时间方面,本文的实验结果表明,模拟器预测的预热饱和点误差造成了8.85%的额外仿真时间.作为对比,直接用RTL 进行预热需求搜索会增加数倍的时间,因此用模拟器预测预热需求更加高效.
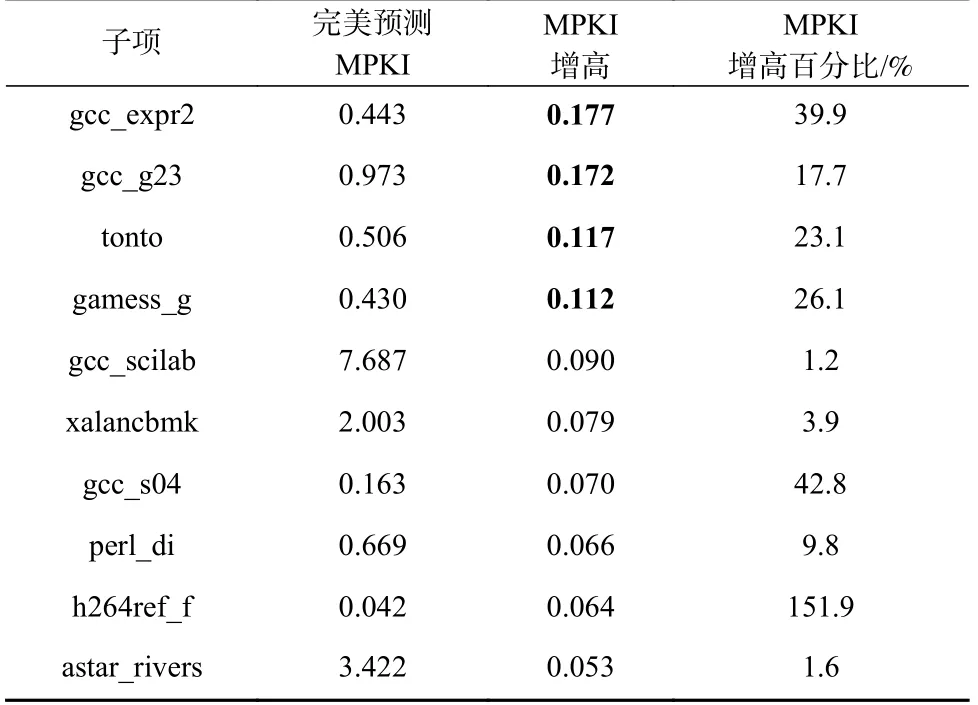
Table 9 Branch MPKI Prediction Error Caused by WarmProfiler (increase)表9 WarmProfiler 的分支MPKI 预测误差(增高)
4.4 并行调度
虽然本文的方案大幅缩短了预热所需指令数,但是并不能改变总仿真时间在每个负载上的分布.少数负载仍然因为预热指令较多、IPC 较低导致仿真周期数显著长于其他负载.如图18 所示,检查点的仿真周期数非常不均衡,如果简单地让53 个负载并行地开始仿真,那么仿真的后半段会只剩下几个最慢的负载.这个问题并不仅存在于自适应预热方案,负载时长不均衡在普通预热方案下也存在(见图5).
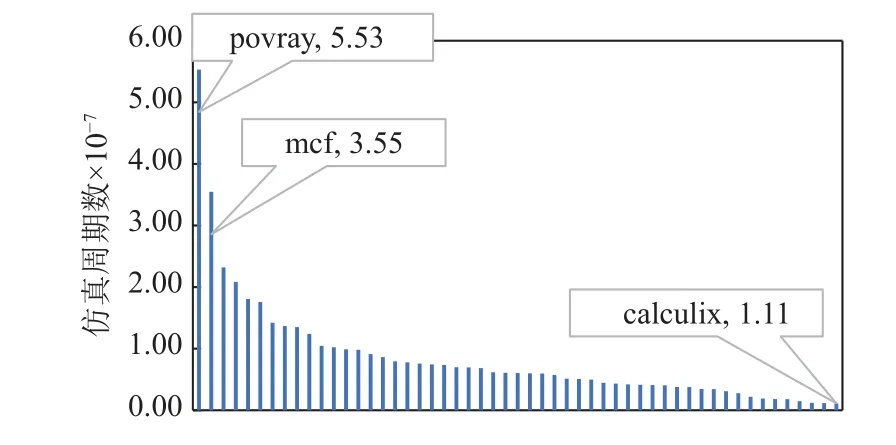
Fig.18 Distribution of total detailed simulation cycle counts for 53 workloads using adaptive warm up图18 使用自适应预热时53 个负载的全细节仿真周期数分布
2.2 节中的例子定性说明了CPU 多核并行仿真给调度带来的好处,本文的实验结果印证了分簇的收益.首先定义了调度均衡度用于描述负载均衡的程度:调度均衡度=平均完成时间/最长完成时间.其次对比了64 核下3 种配置的调度均衡度.如表10 所示,在同样的负载集下,CPU 簇数量越少,调度均衡度越高,无论是随机调度还是LJF 调度.这说明CPU簇越少,调度的“难度”越低,越容易达到均衡的调度.而从另一个角度看,LJF 总是能获得比随机调度更高的均衡度.在端到端性能对比中,见表11,同样能看到LJF 的优势:在多种配置下,LJF 比随机调度节省了11%~20%的时间.
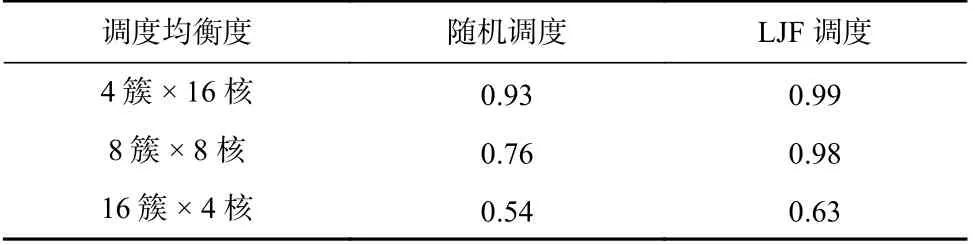
Table 10 Impact of Cluster Count on Scheduling Balance表10 簇的数量对调度均衡度的影响
为了探究通过架构模拟器的IPC 预测仿真时间带来的影响,本文对比了通过模拟器预测和先知预测的调度结果(先知预测,即用RTL 的真实IPC 进行LJF 调度).表12 的结果表明模拟器预测对调度结果的影响很小,这是因为GEM5 预测香山处理器仿真时间的NDCG 较高(见2.2 节),非常接近真实仿真时间的排序.
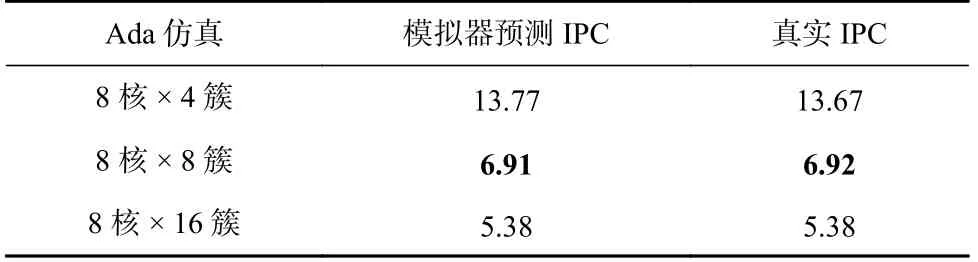
Table 12 Maximum Completion Time of LJF Scheduling Guided by Simulator IPC and Real IPC of RTL表12 采用模拟器IPC 和RTL 的真实IPC 指导LJF调度的最大完成时间h
5 讨 论
本节讨论3 个设计决策的局限性.
1)在用访存指令实现功能预热方面.在此前的体系结构相关工作中,有工作[45]尝试用访存时间戳的方式维护一个软件LRU 缓存,用于功能预热.实际实现时,除了像本文一样通过缓存协议注入外,还可以选择从访存时间戳生成一系列访存指令,将需要预热的缓存块加载到缓存.在实际操作中,后者具有更好的可迁移性,但是其存在2 方面的问题:一是预热指令本身会在缓存中留下足迹,影响预热结果;二是预热时的访存并发度依赖于处理器的流水线设计、指令窗口大小、MSHR 数量配置,在比较保守的配置下访存并发度较低、预热速度较慢.
2)在功能预热方面.本文没有解决分支预测组件的功能预热问题,因为分支预测组件普遍采用私有接口,并且接口随架构发生变化.
3)在任务调度方面.本文未展开更细粒度的分簇方式的探索,以及未找到理论最优调度策略.
6 总 结
在技术方面,本文提出了较为通用的RTL 缓存功能预热解决方案和预热需求搜索方案.这些方案具有普适性,可以将类似的思路应用于AMBA 协议的缓存和用于其他指令集/微架构处理器.在负载特征刻画方面,本文指出了当前CPU 仿真的负载运行时长分布严重不均的问题,这是因为负载IPC 分布不均、预热需求分布不均.时长分布严重不均导致了要最小化最大完成时间,现阶段需要加速的就是仿真指令数最多的应用.因此,未来的工作可以关注如何继续减少全细节仿真的指令数,以及提高仿真器仿真效率.
作者贡献声明:周耀阳完成部分实验开发任务、整理和分析数据,并撰写论文;韩博阳、蔺嘉炜、王凯帆、张林隽完成部分实验开发任务;余子濠、唐丹、王卅、孙凝晖、包云岗提供实验开发思路, 给予工作支持和指导意见.
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
计算机系统应用(2022年4期)2022-05-10 08:41:10
小哥白尼(趣味科学)(2021年6期)2021-11-02 05:23:48
天津医科大学学报(2021年4期)2021-08-21 02:14:52
故事作文·高年级(2021年4期)2021-05-06 03:20:04
小哥白尼(神奇星球)(2021年11期)2021-03-08 09:00:18
国际呼吸杂志(2019年4期)2019-03-12 01:08:18
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
现代计算机(2015年31期)2015-09-28 05:31:51
