
MediaPipe“面部网格”识别
2023-06-06 11:02牟晓东
电脑报 2023年21期
牟晓东
MediaPipe是一个机器学习(MachineLearning)视觉算法工具库,我们已经体验过它的手势识别与跟踪功能,它的“面部网格”(FaceMesh)识别应用可以快速地从图像或视频画面中进行人脸的3D网格重建,实时检测人脸的468个关键点以及10个瞳孔关键点。
你可以对比GitHub中这张标注有478个关键点的人脸模型网格可视化示意图(https://github.com/google/mediapipe/blob/master/mediapipe/modules/face_geometry/data/canonical_face_model_uv_visualization.png),了解面部各个关键点,比如上嘴唇的中上为0、鼻子的中间为2、眉心处为8,脸的正中顶端是10、底端下巴尖为152,左右两侧则分别为234和454……每一组相邻的三个标注点均通过连线构成一个三角形,因此被称为“面部网格”(如图1)。
下面我们分别测试对静态图像文件和摄像头监控画面中的人脸进行“面部网格”识别的效果。
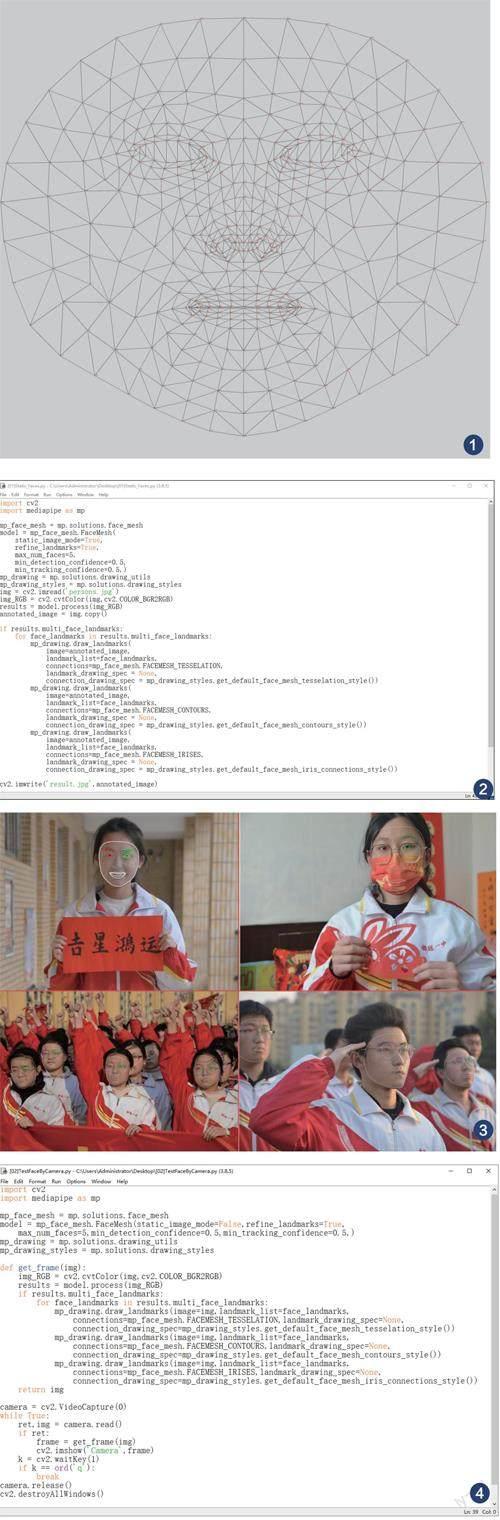
1.识别图像文件的人脸
首先,导入OpenCV和MediaPipe库模块:“importcv2”、“importmediapipeasmp”;接着,调用与配置人脸关键点的检测模型,建立变量mp_face_mesh,赋值为“mp.solutions.face_mesh”;再建立变量model,赋值为“mp_face_mesh.FaceMesh(static_image_mode=True,refine_landmarks=True,max_num_faces=5,min_detection_confidence=0.5,min_tracking_confidence=0.5,)”;其中的“static_image_mode”参数的值为True表示检测模式为静态图像(检测视频时应该设置为False),“refine_landmarks”参数的值为True表示对嘴唇、眼睛和瞳孔等关键点进行精细定位,“max_num_faces”参数表示每次最多检测的人臉数目为5;“min_detection_confidence”和“min_tracking_confidence”参数的值均为0.5,分别表示置信度和追踪的阈值(越接近1越精准)。
然后,进行人脸面部网格可视化函数和可视化样式的导入:建立变量mp_drawing,赋值为“mp.solutions.drawing_utils”;建立变量mp_drawing_styles,赋值为“mp.solutions.drawing_styles”。再建立变量img,赋值为“cv2.imread('persons.jpg')”,利用OpenCV读入当前目录中的图像文件persons.jpg;建立变量img_RGB,赋值为“cv2.cvtColor(img,cv2.COLOR_BGR2RGB)”,作用是转换图像模式(从BGR转为RGB);建立变量results,赋值为“model.process(img_RGB)”,作用是将转换为RGB模式后的图像输入至面部网格模型,此时可再添加一条“print("检测到人脸的数目为:",len(results.multi_face_landmarks))”语句来输出显示检测到几张有效的人脸。
接下来,进行人脸面部网格的整体轮廓、眼眉、眼眶、嘴唇以及瞳孔的绘制。建立变量annotated_image并赋值为“img.copy()”,作用是复制生成副本图像文件;如果检测到人脸(“ifresults.multi_face_landmarks:”),则开始遍历每一张人脸:“forface_landmarksinresults.multi_face_landmarks:”,通过调用“mp_drawing.draw_landmarks”并修改其中的参数分别来绘制“tesselation”曲面细分、“contours”外形(包括眼眉、眼眶和嘴唇)和“iris”瞳孔,其中各参数均保持默认的可视化样式即可,而且三次调用“mp_drawing.draw_landmarks”的模式几乎完全相同,只需要修改对应项目的参数值。最后,添加新图像文件生成保存的语句:“cv2.imwrite('result.jpg',annotated_image)”,并将程序保存为“[01]Static_Faces.py”(如图2)。
准备四张静态图像文件分别进行测试:第一张是不戴眼镜和口罩的单人正面照,经程序检测后正确识别并标注了脸的整体轮廓、眼眉、眼眶、瞳孔(双眼以红色和绿色进行区分)以及嘴唇;第二张是戴眼镜和口罩的单人正面照,程序同样也进行了正确识别,包括口罩所遮挡的鼻子、嘴唇等脸的下半部均做了“猜想”式标注;第三张是多人正面照,程序识别并标注了四张人脸的面部网格,嘴唇或眼睛等个别位置有一定的误差,有遮挡的“半张脸”并未进行标注;第四张是多人侧面照,三张人脸均识别并在遮挡的一侧也进行了“猜想”式标注,效果非常理想(如图3)。

2.识别摄像头监控画面中的人脸
由于人脸“面部网格”识别部分的代码几乎完全相同,所以先将“[01]Static_Faces.py”复制粘贴为“[02]Camera_Faces.py”,来进行代码的修改:从开始库模块的导入到调用与配置人脸关键点的检测模型部分,只需将变量model中的“static_image_mode”参数值设置为False;然后,新定义一个名为get_frame(img)的函数,作用是处理摄像头监控中的每一帧画面,将之前从变量img_RGB存储BGR至RBG转换后的图像,一直到调用“mp_drawing.draw_landmarks”绘制人脸的各部分区域,最后再通过“returnimg”返回处理好的图像。
程序的后半部分代码是读取摄像头监控画面、调用函数get_frame(img)来处理单帧图面、热键q响应程序退出等操作代码(包括释放摄像头资源及关闭窗口),不再一一赘述(如图4)。
运行程序进行各种测试,包括正面的裸眼直视、戴眼镜、戴口罩、加小人偶“同镜”以及张嘴、小幅度的偏头等,程序对人脸的面部网格识别效果也都还不错(如图5)。
猜你喜欢
榆林学院学报(2022年4期)2022-08-02
小学生学习指导(低年级)(2018年9期)2018-09-26
计算机与生活(2018年8期)2018-08-15
延河(2017年7期)2017-07-19
档案管理(2017年1期)2017-01-17
理科考试研究·高中(2016年9期)2016-05-14
绍兴文理学院学报(自然科学版)(2013年2期)2013-12-19
网络与信息(2009年9期)2009-10-30
中小学教学研究(2009年8期)2009-09-08
消费导刊(2009年9期)2009-06-20
