
基于残差卷积神经网络的语音识别算法*
2023-06-04 06:24冯成立
计算机与数字工程 2023年2期
冯成立 程 雯
(武汉邮电科学研究院 武汉 430000)
1 引言
语音识别技术是人工智能领域发展较为迅猛的方向。其目的是为了将人说话的声音转换为其对应的语言文本信息。传统语音识别由声学模型和语言模型构成。传统的声学建模采用高斯混合模型(Gaussian Mixture Model,GMM)来提取语音的声学特征信息,语言模型则使用隐马尔可夫模型[1](Hidden Markov Model,HMM),提取其对应的语言特性。随着深度学习发展,基于神经网络的语音识别迅速发展起来,声学模型渐渐发展为深度神经网络(Deep Neural Network,DNN),循环神经网络(Recurrent Network Network,RNN),卷积神经网络(Convolutional Neural Network,Cnn)等。如,科大讯飞的DFCNN、百度的Deep Speech 等。文本以DFCNN 作为基础模型进行研究,分析了其模型优缺点,并基于此进行改进,对改进前后的准确率效果进行对比。
2 声学模型
2.1 语音数据处理
文本采用的是16k 语音数据,语音数据预处理通常两种做法,提取MFCC和Filter bank特征。MFCC 是在Mel 标度频率域提取出来的倒谱参数,是一种在语音识别领域与说话人识别领域中广泛使用的特征。Mel 标度模拟了人耳频率的非线性特性,它与频率的关系可用下式近似表示:
主要对音频数据处理过程分为以下几步骤:预加重,分帧,加窗,快速傅里叶变换(STFT),梅尔滤波,去均值,离散余弦变换(DCT)等。最后构造成一个基于人耳频率的语音特征频谱图。Fbank 和MFCC 基本类似,但是在最后一步没有使用离散余弦变换,因此fbank包括更丰富的语音特征信息,在使用深度神经网络的时候,我们通常使用filter bank特征来作为网络特征的输入。
2.2 DFCNN模型
获得MFCC 语音频谱特征后,需要使用深度残差CNN 提取音频特征。文本提出的声学模型使用5层的3×3卷积神经网络增强卷积层的局部特征提取能力。其中每一层中间是两层的CNN 结构。并且使用批正则化(Batch Normalization),对每层的输入数据的分布进行归一化处理。加快深度网络中的训练速度。
其中该CNN 结构是借助于2016 年VGGNet[5]中的CNN3×3 大小的卷积核思想。VGG Net 由Google DeepMind 公司的研究员和牛津大学的视觉几何组一起研发的深度卷积神经网络,在2014 的ILSVRC 比赛上取得了优异的成绩,将top5 错误率降到7.3%。它使用多层3×3 的卷积神经网络进行堆叠,将语音频谱特征看成一张图,提取频谱图的深度局部特征。并且其感受野大小为3,相比直接使用5×5,7×7 等卷积核大小,采用深度卷积核为(3,3)的感受野大小类似,但却不增加太多训练参数的量。VGGNet中的该方法在不增加参数的情况下,更好的增强深度卷积神经网络对数据的拟合能力。
2.3 连接时序分类
在语音识别技术中,序列帧和标准目标之间的长度通常都是不一致的,所以在连接时序分类(Connection Temporal Classification,CTC)提出前,通长使用GMM 来将序列帧与目标之间强制对齐,序列帧和目标帧对齐问题是一个较难处理的问题,会产生较大误差。针对这个问题链接时序分类(CTC)被研究人员提出。CTC 通过引入空符号blank,在不对音素对齐的前提下,最大化解码路径中组合的后验概率。
其中p(xi)为组成X 序列的一条路径概率。通过极大似然估计将所有路径之和的最大值,可以求得最优解。其路径变换后的结果及为CTC 解码结果。变换的过程则是合并相同字符,并且将空字符合并并分割不同字符。
2.4 Network in Network
NiN(Network in Network)是一种2014 年提出的一种深度网络结构[11]。它可以增强模型在感受野内对局部区域的辨别能力。传统CNN是一种广义线性变换,仅仅是将输入进行线性组合,因此其抽象能力是比较低的。NiN 中为了提取更深层特征提出MLP conv(multi-layer perception)卷积网络。在CNN后使用1×1的卷积网络,相当于在CNN后加一层多层感知机。从特征效果上看,在通道之间做了特征融合。
每一层卷积之后加一个激活函数,比原结构多了一层激活函数,增加了模型的非线性表达能力。在NiN 网络中,还提出一种方法全局平均池化(Global Average Pool,GAP),GAP 是在网络输出层代替全连接层。对CNN 卷积通道上进行求平均,直接输出通道上的平均值。
在语音识别求softmax 的时候,由于输入维度过大,导致全连接参数过多,容易发生过拟合,虽然使用dropout,但是仍然不好把控dense 的拟合程度。为了解决这个问题,我们使用GAP 来代替全连接层。全局平均池化可以大大降低参数,并且直接接在CNN 后,对每个通道求一个平均,具有实际含义,易解释。
2.5 残差连接
本文使用的残差SENet 是继ResNet 之后的更有效残差机制网络[19],SeNet 引入一种通道加权残差技术SE-Block。针对传统残差结构只是将输入加到输出里,而无法对输入中不同通道内特征进行选择。通过该方法,可以对通道数据进行加权,强调多通道内有效信息,抑制无效信息,类似一个通道内注意力机制。如图1 所示,SE-Block 主要分为两个部分,Squeeze 操作和Excitation 操作。Squeeze将一个channel上整个空间特征编码为一个全局特征,采用全局平均池化来实现,得到一个channel上的全局描述特征。Excitation 操作针对不同channal上的关系进行建模。学习到一个channel 上的权重。利用两个全连接层,第一个FC 层起到降维的作用,降维系数为r 是个超参数,然后采用ReLU 激活。最后的FC层恢复原始的维度。最后将学习到的各个channel的激活值。
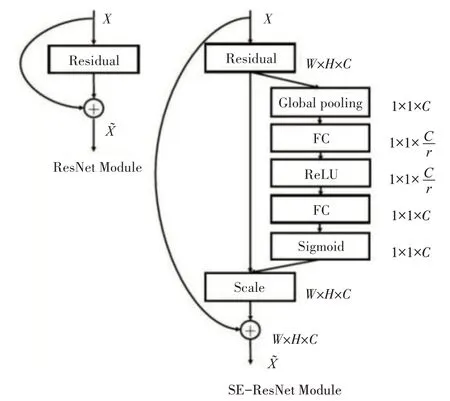
图1 SE-Block残差机制
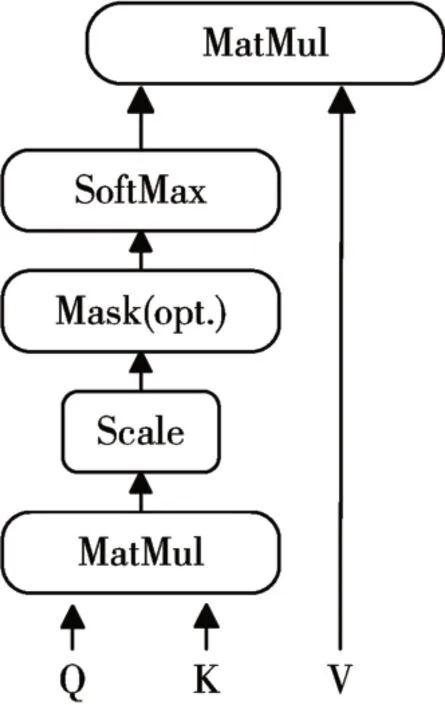
图2 self attention注意力机制
其中zc为squeeze后得到的每个通道上的全局平均池特征。再使用两个全连接变换得到匹配度s,第一个全连接层对z进行降维,降维系数维r。将原始通道树C,变换到C/r,并且使用Relu 激活函数对其非线性变换。然后进行第二层全连接恢复其维度C,通过这两个操作得到不同通道间的权重。然后针对s进行softmax 操作,即可得到通道的权重归一化数值,再对uc进行加权求和得到通道加权后的特征。相当于对不同通道添加了一个注意力机制。
3 语言模型
语言模型采用的是transformer 结构,transformer 是2017 年谷歌公司提出的一种特殊的序列特征提取网络[3]。分为编码与解码两个部分,每个部分包括6 层,编码器部分可以拆分为自注意力机制(self attention)以及前馈神经网络(feed forward neural network)。解码器部分拆分为自注意力机制(self attention),编码解码注意力机制(encoder-decoder attention)和前馈神经网络。编码器对拼音序列的上下文进行建模,解码器则根据这种依赖关系对拼音汉字的过程实现转换。
Transformer 是一种极其高效的序列特征提取器。其中起主要作用的是自注意力机制(self attention)。self attention 也叫"Scaled Dot-Product Attention"(缩放点乘注意力)。是一种对序列自身的不同序列帧之间的依赖关系进行建模的注意力机制,通过该方法,可以获得充足的上下文信息。Self attention计算图如下所示。
通过Q,K 来计算query 与key 之间的匹配系数,经过softmax归一化处理作为权重与V乘积。前馈神经网络是通过两层的全链接层对数据进行融合计算。通过max函数提取融合后的特征信息。
相比于传统的循环神经网络(Recurrent Neural Network,RNN),transformer 可以解决长距离上的依赖难以传递的问题,并且可以实现并行计算。充分提高训练速度以及增强序列上下文建模能力。使用该方法作为语言模型,实现拼音到中文汉字的转换是具有稳定性以及鲁棒性的。
4 实验
4.1 数据集
本项目自动语音识别模型采用开源中文普通话数据集,使用了四个开源数据集,除去测试验证集合,总训练数据样本大约为400h,如表1所示。
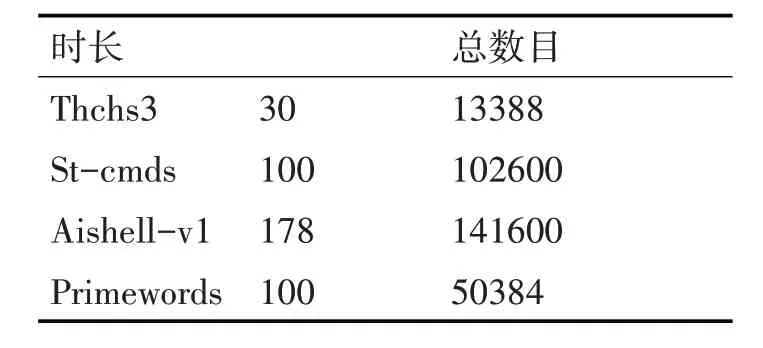
表1 中文语音数据集
Thchs30 是清华大学开源的30 小时中文语音库。采样频率16kHz,采样大小16bits。ST-CMDS是由AI 数据公司发布的中文语音数据集,包含10万余条语音文件,大约100 余小时的语音数据。AiShell-V1 是由北京希尔公司发布的一个中文语音数据集,其中包含约178h 的开源版数据,采样率为16kHz。Primewords 包含了大约100h 的中文语音数据。
4.2 实验过程
使用声学模型搭建语言模型进行实验,声学模型采用DFCNN 作为baseline,并改进为文本提出的DRCNN,语言模型则采用HMM 和transformer-encoder,使用HMM 作为baseline。采用四个数据集音频fbank 帧序列以及其拼音数据。Fbank 帧长为15ms,帧移为10ms,提取fbank200 维的语音特征。构建序列语音长度为1600 帧(大约为16s),超过该长度的语音信号剔除掉不作处理。声学模型采用采用5 大层3×3 的CNN 的结构,每一层使用两小层CNN,卷积深度依次由浅到深,分别为32、64、128、256、256,且所有的卷积核步长都为2。池化层采用NiN 网络中提出的全局平均池化。其中每一层的CNN 前都使用Batch Normalization加以处理。最后使用全连接层缩放到拼音词表维度,送入CTC解码,输出层为CTC 的损失函数。采用Adam 优化器,初始学习率设置为0.001,采用指数学习率衰减,设置warm-up 预热机制,训练到100pochs。降低到0.1 左右。语言模型,数据采用四个数据集训练样本,即带声标的拼音以及所对应的汉字数据,模型搭建一个6 层的transformer-encoder 结构,输入数据为拼音的度独热编码,输出为汉字的向量。设置初始学习率设置为0.003,采用预热机制,采用指数学习率衰减,训练大约50epoch,即可得到较好的语言模型。
4.3 实验结果分析
基于以上实验,统计在四个数据集合中测试集的中文语音识别字错误率。字错误率的计算为计算预测与标准标签的编辑距离与总字的个数的比例。
采用上述实验得到的声学模型和语言模型,对四个数据集的测试集综合进行验证,实验数据结果字错误率如表2 所示,证明本文所提出的改进CNN声学模型,及transformer-encoder的语言模型,在四个数据集的测试集上平均WER 降低到19.12。相比传统DFCNN-HMM 而言的23.15 比较,词错误率降低了4.03%。并且统一在transformer 语言模型下,采用不同声学模型来实验,得到数据显示,本文所提出的DRCNN 模型相比传统DFCNN 模型大约有2.28%提升。在统一的DRCNN 模型下,采用transformer 语言模型相比HMM 语言模型,WER 大约提升了1.76%。本文所提出的DRCNN 声学模型及transformer 语言模型,在传统的DFCNN 模型及HMM 语言模型基础上语音识别效果均有所提升。

表2 实验结果WER
5 结语
本文提出一种改进的CNN 声学模型结构,通过卷积神经网络构建深度CNN,并融入残差机制,全局平均池化网络等,使用SENet 机制对残差网络进行通道上的权重,提取强相关特征,弱化无关特征,学习到深层的语音特征表示。使用NiN 网络多特征进行多通道融合以及对上下层参数进行降维。并采用链接时序分类CTC 对语音特征进行解码,并且采用transformer 的encoder 语言模型,学习中文汉字的语言特征。解决了传统语音识别模块难训练,难收敛等问题。结果表明本文提出的DRCNN-CTC 模型能够有效提高中文语音识别准确率。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
家庭影院技术(2020年6期)2020-07-27
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
