
基于多帧特征融合的视频中夜间行人检测方法*
2023-06-04 06:24王宇凡张姗姗
计算机与数字工程 2023年2期
王宇凡 张姗姗
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
行人检测中存在一些困难的挑战,如运动模糊、虚焦、行人之间的频繁遮挡、尺度变化。夜间的行人检测由于光照、模糊等问题获得的图像质量更差。视频具有时间顺序上的连续性,行人特征在相邻帧中不会产生剧烈变化,可以利用时间维度上的特征信息来进行检测。对冗余的处理同样是视频行人检测中的挑战。
现有的许多行人检测方法为了提升检测性能,增加了额外的模型(如FlowNet[1]),耗费大量的计算资源和时间。本文提出一种基于多帧特征融合的视频中夜间行人检测方法来解决夜间行人图像特征质量下降问题。我们在夜间视频数据集上进行测试,结果显示本方法对小尺度行人和严重遮挡的行人的检测结果有所提升。
2 相关工作
本节主要介绍行人检测、视频目标检测、特征融合三个方面的相关工作。
2.1 行人检测
行人检测(Pedestrian Detection)是目标检测的一个重要分支。2005 年Navneet Dalal 提出了基于HOG 和SVM 的行人检测方法[2],使用HOG 直方图描述行人的外观特征。由于计算量太大,基于HOG和AdaBoost的方法[3]被提出。积分通道特征[4]获得了更强力的特征。近年来神经网络也被应用到行人检测当中。Faster R-CNN[5]是一个端到端(end-to-end)的检测模型,提出了区域建议网络。YOLO[6]将整张图划分为固定数量的网格进行打分和回归。SSD[7]使用预先设定好的多尺度的边界框对图像特征进行回归。
2.2 视频目标检测
视频目标检测(Video Object Detection)中的视频数据集拥有时间特征,可以利用时间信息来加强邻近帧中同一物体特征之间的关联。视频目标检测方法分为两种模式:1)先进行目标检测,使用跟踪结果对目标检测进行修正,如T-CNN[8]将对候选框进行跟踪并重新打分。2)使用运动信息提升特征质量。如FGFA[9]使用光流信息和时间信息。为了减少计算量,提出了Association LSTM[10],利用LSTM增强检测的稳定性。
2.3 特征融合
许多方法采取特征融合(Feature Fusion)的方法来获得增强的目标特征信息。融合方法可以分为早融合(Early fusion)和晚融合(Late fusion)两类[11]。早融合先将得到的特征进行融合,再用融合后的特征进行训练,如MOD[12]方法。晚融合则将不同来源得到的检测结果进行筛选和合并。低层特征拥有细节同时存在许多噪声,高层特征的语义信息更强,FPN[13]方法结合了两种融合方法,对不同尺度的目标均有所响应。
3 本文算法
本方法主要由三个模块构成:1)单帧行人检测模块;2)行人跟踪模块;3)多帧特征融合模块。图1 为主要网络结构,多帧图像先并行通过行人检测网络(a)得到行人的图像的初步特征,经过行人跟踪网络(b)得到行人在邻近帧的坐标,最后经过多帧特征融合网络(c),并将特征进行分类和回归。

图1 主要网络框架流程图
3.1 单帧行人检测模块
行人检测模块的网络结构如图1(a)所示。行人检测模块首先获得特征图xl∈RHl×Wl×Dl,其中Wl,Hl和Dl分别为第l层输出特征图的宽,高和通道数。随后通过候选框得到更准确的边界框。检测网络损失函数为
其中Ncls表示anchor 的minibatch 个数,Nreg表示anchor 位置的个数,i表示第i个anchor,Lcls是对数损失函数,p表示预测概率,p*表示ground truth的标签(ground truth为正样本时p*=1,ground truth为负样本时p*=0),Lreg是平滑L1损失函数,t表示预测预测框的坐标,t*表示正样本的坐标。
3.2 行人跟踪模块
行人跟踪模块的网络的具体结构如图2 所示。行人跟踪给定初始的模板图像z,通过相似度函数f(z,x)在相邻的连续t帧上搜索和z最为相似的图像区域x作为行人跟踪的位置结果。相似度函数的表达式为
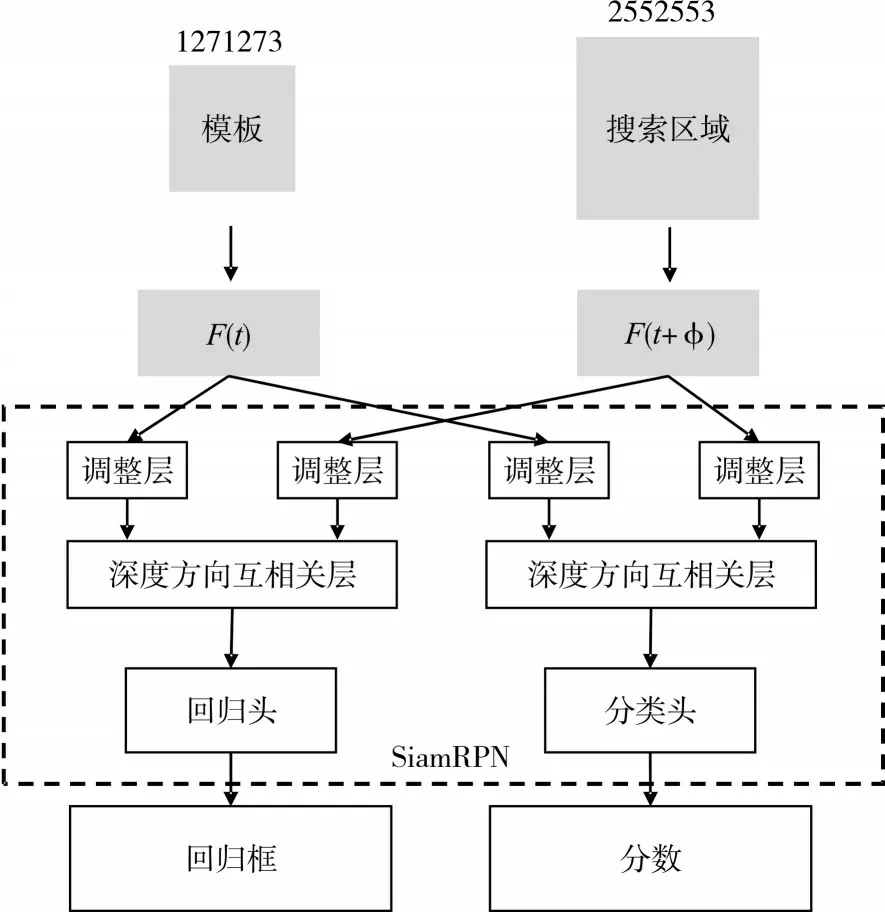
图2 行人跟踪网络框架
其中φ表示经过全卷积网络,卷积之后分别得到的模板图像z和搜索区域x的特征图,*表示互相关(cross-correlation)操作,得到模板特征和搜索区域特征的响应图,b是相似度的偏移量。
我们的行人检测和行人跟踪使用同一个主干网络并行提取图像特征。在行人跟踪的时候融合了网络的后三层(第3 层至第5 层)输出的特征,得到跟踪的坐标ℬ 及坐标区域特征和模板图像特征的相似程度S。
3.3 多帧特征融合模块
我们将检测行人及其跟踪结果的全卷积网络的最后一层特征用平均池化层融合起来,以此来增强小尺度行人和被遮挡行人的特征。融合公式为
其中以检测行人所在的帧为基准,分别向前和向后跟踪t帧。特征融合模块的网络结构如图1(c)所示。用行人跟踪得到的特征进行融合,再用这个融合后的特征进行回归和分类。
4 实验结果与分析
本章节主要阐述本文使用的数据集和实验内容,并给出相应的分析,对本文的方法效果进行验证。
4.1 数据集
Nightowls[15]数据集是一个夜间驾驶条件下的行人检测数据集,夜间存在光照不足、颜色信息较少、对比度的变化、反射等夜间特有的问题。该数据集拍摄了40 个视频序列,共27.9 万帧夜间数据。CityPersons[16]是一个图像行人检测数据集,包含来自50个不同城市的2975张高质量的训练图片和500张验证图片。
4.2 实验细节
本方法使用ResNet-50 作为主干网络。行人检测首先在CityPersons 数据集上预训练,再在Nightowls 数据集上进行微调。在行人检测时我们修改最后一层stride 为2 来扩大接受的视野范围。在行人跟踪时我们将第3层至第5层特征维度降至256 进行融合。我们把短期跟踪轨迹(tracklet)的帧数设定为5 帧。在特征融合的时候,我们根据跟踪相似性为特征进行加权,再进行融合。我们选用sgd作为训练优化器。
4.3 实验性能以及对比
本节将本文方法与现有的方法作对比。将评估集按照测试行人的高度和测试行人的可见度划分成不同的测试子集,实验结果如表1 所示。本文使用的评测指标是miss rate[17],即目标丢失率,表达式为

表1 本文方法与常用的行人检测方法在小尺度行人集合上Miss Rate(↓)对比
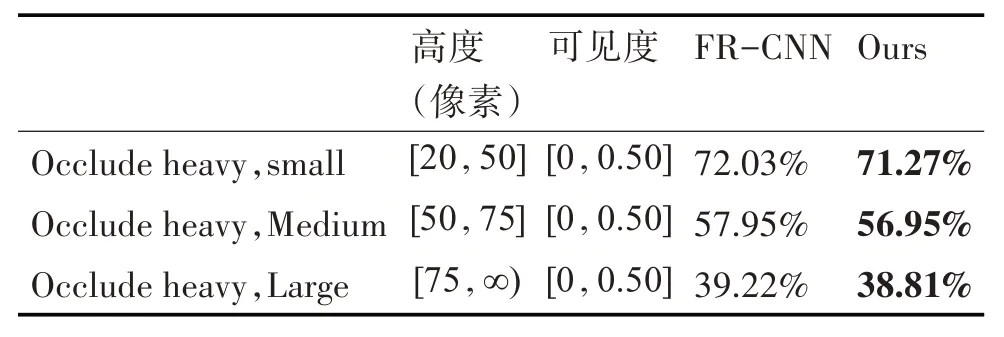
表2 本文方法与常用的行人检测方法在被遮挡严重集合上Miss Rate(↓)对比
从表1 中可以看出,我们的方法在针对小尺度行人(高度在20 像素到50 像素之间)的评估集合上,性能有所提升。我们的方法在被严重遮挡(可见度小于50%)的评估集合上,对行人的检测性能有所提升。综上所述,在检测小尺度行人和被遮挡行人的情况下,本文使用的基于跟踪的检测器对行人检测有帮助。
5 结语
本文提出一个基于多帧特征融合的视频中夜间行人检测方法,增强了行人在夜间情况下质量较差的特征。实验结果表明,本方法能提升夜间视频行人检测中较为困难的小尺度行人和被部分遮挡的行人的检测的性能。未来我们将优化行人跟踪,动态使用跟踪结果,提高行人检测的速度和质量。
猜你喜欢
意林(2021年5期)2021-04-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
扬子江(2019年1期)2019-03-08
数学小灵通·3-4年级(2017年9期)2017-10-13
小天使·一年级语数英综合(2017年6期)2017-06-07
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
河南科技(2014年23期)2014-02-27
