
基于知识图谱路径最优化的自然语言推理方法*
2023-06-04 06:24李世宝殷乐乐刘建航黄庭培
计算机与数字工程 2023年2期
李世宝 殷乐乐 刘建航 黄庭培
(1.中国石油大学(华东)海洋与空间信息学院 青岛 266580)(2.中国石油大学(华东)计算机科学与技术学院 青岛 266580)
1 引言
自然语言推理(Natural Language Inference,NLI)是自然语言理解任务中的一项基础性研究,又称文本蕴含识别(Textual Entailment)[1]。对于给定的文本,通常称为前提和假设,主要目标是判断前提与假设之间存在的推理关系,包括蕴含、矛盾和中立三种关系。自然语言推理任务的特殊性在于仅仅依靠训练数据并不能将模型准确率提升到理想的程度,融合外部知识库的自然语言推理模型能够发挥更好的性能。
知识图谱以结构化的方式描述客观世界中的概念、实体、事件及其之间的关系,将互联网的信息表达成更接近人类认知世界的形式[2]。大型知识图谱的应用在为模型提供更多的结构化知识信息的同时也不可避免地引入大量噪声,为了尽可能提取出与前提或假设文本相关度更高的知识子图,提出路径最优化的子图构建方法,引入权重信息过滤掉相关度较低的节点路径,降低噪声对模型准确率的影响。同时为了更进一步获取子图中的知识信息,采用图神经网络编码前提和假设构成的子图,将得到的定长向量融入基于文本的推理模型做训练,从而构建出文本与图联合训练的推理模型,为基于文本的推理模型丰富了外部知识信息。
2 相关工作
2.1 基于句内文本的自然语言推理
这一类推理模型专注于从前提和假设文本获取推理信息,Bowman 等[3]首次将LSTM 句子模型带入NLI领域,具体做法是将句子中的每个词依次输入LSTM 网络,以最终输出的状态作为句子的表示。Rocktäschel等[4]使用两个LSTM 对前提和假设文本分别建模,同时提出Word-by-word Attention机制,实现了前提文本和假设文本对应部分的软对齐。mLSTM[5]的设计机制更符合人类的感知习惯,将前提文本中的单词和假设文本中的单词进行匹配,无匹配词则与NULL 进行匹配,通过门控制记录匹配信息从而判定文本对是否为蕴含关系。ESIM[6]使用句子间的注意力机制(intra-sentence attention),模型主要包括三个部分:输入编码,局部推理模型和推理增强,该模型在SNLI(Stanford Natural Language Inference)数据集[3]下优于以前所有句子编码模型,为后续相关研究提供了很高的参考价值。
2.2 融合外部知识库的自然语言推理
近几年的自然语言推理研究开始对训练文本之外的知识库进行深入探索,Chen等[7]验证了外部知识库能够增强推理模型,从WordNet中提取了五个特征作为前提和假设词对的特征扩充。文献[8]面向医学领域,把对齐后的词分别应用文本嵌入和图嵌入方法,将得到的文本向量和图向量拼接送入ESIM模型做训练。Wang等[9]提出基于文本的推理模型和基于图的推理模型相融合的概念,在构建知识子图的过程中分别考虑了纯概念子图、一跳邻域子节点和两跳邻域子节点的情况。(KG-augmented Entailment System,KES)[10]在此基础上使用(Personalized PageRank,PPR)排序算法对提取的包含一跳邻域子节点的知识子图进行过滤。
3 知识子图构建
目前中文领域融合知识图谱的自然语言推理研究还较少,中文知识图谱推理语料库大多存在规模较小,质量较差等问题,ConceptNet[11]集合了超过十种核心语言的知识图谱,中文词汇量达到24万,包含中文三元组关系60 万条。我们首先提取ConceptNet 中所有中文数据构建中文知识图谱,然后分别对前提和假设文本进行分词并去停用词后得到token 集合P={p1,p2,p3…pn},H={ℎ1,ℎ2,ℎ3…ℎn},再由P 和H 构建前提到假设的关系子图,在关系子图中pi和ℎi我们称为核心节点,与pi和ℎi直接相连的称为邻节点,受限于ConceptNet中文知识图谱数据的规模,若只考虑一跳邻节点会使部分核心节点之间找不到有效的连接路径,若考虑两跳或者更多跳数的邻节点则会引入更多的噪声,这些噪声是指未出现在上下文中的实体节点,并且不作为中间节点出现在前提到假设的路径当中,为了滤除这些无用的节点,我们同时考虑节点间路径长度信息和路径权重信息设计一种优选路径的子图构建方法,实现了不定跳数的节点路径选取,使得知识子图尽可能的涵盖前提和假设中的实体概念。如图1 所示,对于得到的token 集合P 和H,给定起始节点u,终止节点i,其中u∈P,i∈H。对于(u,i)对之间的知识图谱路径P(u,i)={P1,P2,P3…Pk},首先对路径长度取最小值,见式(1):
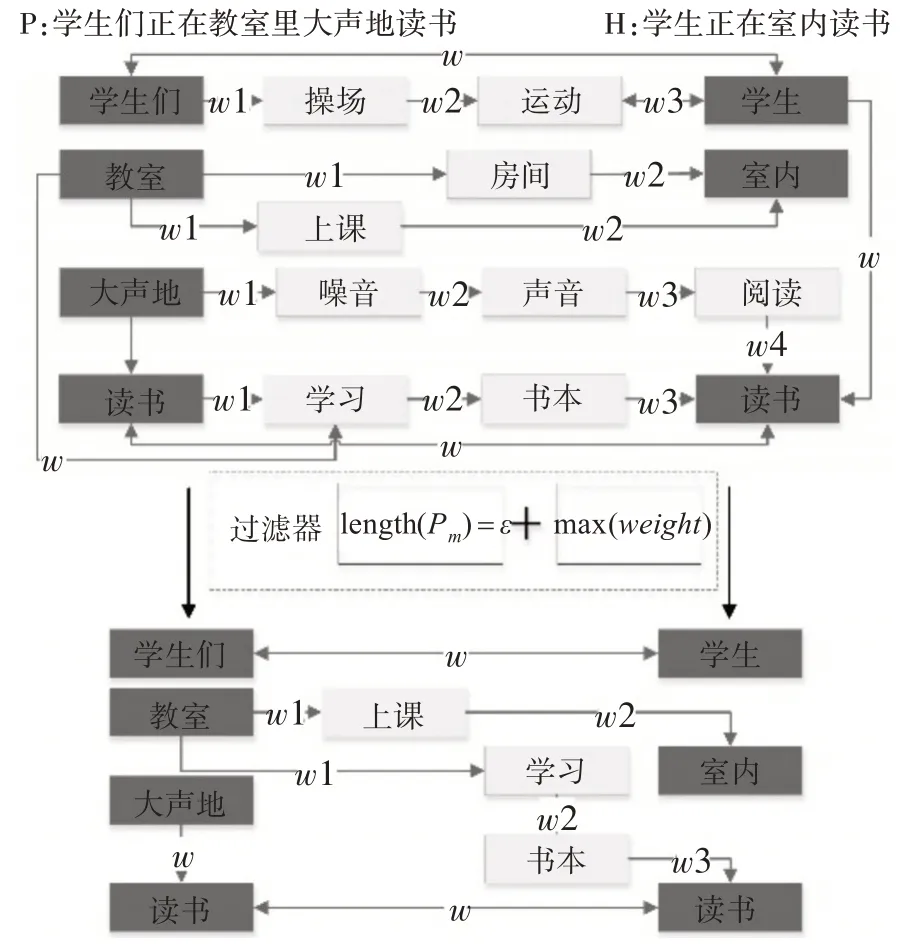
图1 子图构建流程图
得到初步过滤的路径集合P(u,i)={P1,P2,P3…Pm},其中Pm满足lengtℎ(Pm)=ℰ,若多条路径长度相同,则分别计算每条路径中关系的权值,见式(2):
保留权值最大的作为最终路径,舍弃其余路径,最终将所有token 对的路径集合构成子图Gp,ℎ(Ep,ℎ,Rp,ℎ),其中Ep,ℎ为图中包含的所有实体节点,Rp,ℎ为节点之间存在的关系。
4 推理模型
推理模型结构图如图2所示。

图2 推理模型框图
4.1 图编码层
我们首先使用ConceptNet Numberbatch[11]对子图中的节点进行嵌入初始化,对于图数据来说,实体之间含有非常丰富的依赖关系,GCN[12]能够同时对节点特征信息与结构信息进行端对端学习,GCN逐层更新公式为
对构建的子图Gp,ℎ(Ep,ℎ,Rp,ℎ)使用式(3)融合知识子图中边的权重信息进行编码,然后使用式(4)得到定长向量作为图的表示,其中wj为第j个节点编码后的向量表示,N为图中节点的个数。
4.2 文本编码层
设前提语句p=[p1,p2,p3,…,pl] ,假设语句h=[ℎ1,ℎ2,ℎ3,…,ℎm] ,其中pi,ℎj∈EN,EN为N 维预训练的词向量,使用BiLSTM网络分别对p和h进行编码(式(5)~(6)),得到上下文相关的隐藏层向量,
继续使用BiLSTM 网络整合局部推断信息,对编码结果分别应用平均池化和最大池化,拼接处理后得到定长向量作为最终文本编码的结果。
4.3 分类层
将图编码层和文本编码层得到的定长向量拼接送入多层感知器做分类(式(12)),多层感知器包括tanh 激活函数和softmax 隐含层,引入dropout 函数缓解训练过程的过拟合问题。
5 实验与分析
5.1 数据集
本文采用CNLI(Chinese Natural Language Inference)数据集做相关实验,CNLI由SNLI数据集通过机器翻译和人工筛选得来。使用jieba 分词工具对原始语料做分词处理,初始化向量采用腾讯AI实验室发布的200 维中文预训练词向量,对于未包含词则使用高斯分布的随机数进行初始化。
5.2 实验参数设置
首先BiLSTM 网络隐藏层维度设置为300,dropout 随机丢弃比例设置为0.5,训练批量大小设置为32,采用Adam[13]优化器,初始化学习率设置为0.0004。图编码网络部分,GCN 网络隐藏层维度设置为128,节点向量维度为300,未包含词同样使用高斯分布的随机数进行初始化。
5.3 实验结果
为了探究不同子图提取方案对最终模型性能的影响,我们设定平均句内词数量和平均句外词数量的比值以表示子图的上下文相关度σ,式(13)。
其中Si代表所有子图节点中出现在原上下文的数量,Kj代表所有子图节点中未出现在原上下文的数量,M代表前提假设对的数量,实验结果如表1所示。

表1 节点间不同跳数对提取子图上下文相关度的影响
在分别考虑一跳邻节点[10]、两跳邻节点[9~10]和不定跳数邻节点的情况下,平均句内词数量分别为2.8,3.5和4.0,在动态选择节点跳数的情况下,平均句外词数量为4.8,上下文相关度达到0.83,而两跳情况下最差,上下文相关度只有0.33,说明两跳情况下引入了更多的噪声。在测试集下对三种方法训练的模型进行对比发现,在不定跳数的情况下能够得到更高的测试准确率,综合以上分析,在动态选择节点跳数的情况下能够获得上下文相关度更高的子图,减少了子图构建过程中引入的噪声,实现了节点路径的优化。
我们对比了不同模型在CNLI数据集下的准确率,其中包括DiSAN 模型[14],双向LSTM 模型[15],HBMP模型[16]和ESIM模型。实验结果如表2所示。

表2 不同模型在CNLI数据集下训练集和测试集准确率
实验结果表明,本文提出的模型在CNLI 数据集下识别准确率优于对比的基线模型,有1.2%~4.4%的提升,为纯文本模型增加了结构化的知识信息。
此外,为了节省子图查询与构建的时间,我们限制了节点路径的最大查询条目为60,并在此基础上以最高识别准确率为目标,调整核心节点间的跳数的最大值,经过多组对比实验,当设置最大跳数为3,最小跳数为1的情况下,模型训练集准确率可以达到89.1%,测试集准确率可以达到81.8%,模型训练过程如图3所示。
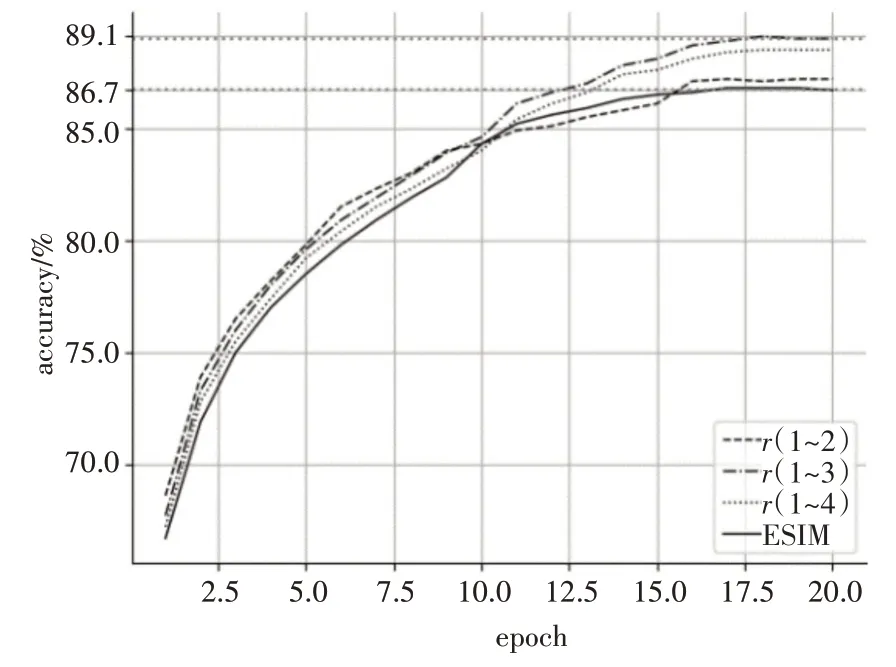
图3 不同跳数范围和ESIM的训练过程对比
6 结语
本文针对ConceptNet 中文知识图谱数据规模的限制,提出基于知识图谱路径最优化的自然语言推理方法,有效减少子图构建过程中引入的噪声,并验证了方法的有效性。模型架构分为文本编码和图编码两部分,其中图编码部分根据所提取的知识子图应用GCN 学习图的结构化知识信息,最后将编码后的图向量与文本向量相融合送入推理模型,从而实现文本和图的联合训练,为基于文本的推理模型增加了结构化知识信息。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
同济大学学报(自然科学版)(2019年2期)2019-04-02
疯狂英语·新读写(2018年3期)2018-11-29
科技风(2017年10期)2017-05-30
现代电子技术(2017年7期)2017-04-14
电子科技大学学报(2016年2期)2016-08-31
电脑知识与技术(2016年7期)2016-05-19
科技资讯(2014年26期)2014-12-03
