
基于FPGA加速的低功耗的MobileNetV2网络识别系统
2023-06-02 06:48:46孙小坚林瑞全方子卿
计算机测量与控制 2023年5期
孙小坚,林瑞全,方子卿,马 驰
(福州大学 电气工程与自动化学院,福州 350000)
0 引言
卷积神经网络善于从海量数据中提取目标的特征,由于其出色的分类识别能力,已被广泛的应用于图像分类、语音识别、医疗诊断、国防安全等领域。庞大的参数量使得卷积神经网络部署在资源有限的嵌入式设备上存在困难。轻量级网络的诞生,很大程度上降低了网络的参数量,适合部署在小容量的嵌入式设备上,应用于目标分类的场景[1-3],轻量级网络如MobileNetV2[4],采用深度可分离的卷积结构,在减少了网络参数量的同时又能保证识别精度。
目前将CNN部署在嵌入式设备上主要有几种方式,如处理器CPU、GPU、专用集成电路(ASIC,application specific integrated circuit)和现场可编程门阵列(FPGA,field programmable gate array)等。将CNN部署于传统的处理器CPU上,会带来高延迟。若是使用并行计算GPU会存在较大的功耗。使用专用的集成电路ASIC虽然性能好,但是成本较高。FPGA具有实时性、低功耗、可重构的优点,特别适用于作为CNN的硬件加速器。将AI领域主流的CNN网络部署在FPGA上的工作仍然面临着内存带宽不足和计算并行度低的限制。由于FPGA片内存储资源有限文献[5]将卷积计算中间缓存放在了片外DDR上,文献[6]则把DDR当做权重数据的存储区,这样虽能缓解片内存储的压力,但是片外的DDR存在带宽的限制,同时也增加了额外的功耗。而文献[7-8]将参数均存在片内存储资源上,无需访问片外DDR,虽然降低了系统功耗,但是需要足够大的片内存储资源。在探索提升计算并行度的方案上,文献[9-11]采用单一的计算结构,不同的卷积层复用该计算结构,可以将大部分资源分配给该计算结构,最大程度提升该计算阵列的并行度,但是难以适应不同卷积的计算方式,导致效率低下。文献[12-13]以全流水线的形式将CNN网络展开,层与层之间流水计算,每层分别占用不同的资源,资源消耗较大,适用于浅层次的网络,无法部署深层次的网络。文献[14]综合了单一计算结构与全流水线结构的优点,针对MobileNetV2网络提出了一种半流式结构,该结构只针对专用的CNN设计,结构固定,通用性不强。
针对上述问题,本文采用量化感知训练的方式在量化的过程中对模型进行二次训练将模型精度由静态量化的73.33%提升到了93.89%,压缩模型尺寸为原来的1/4,用8位定点整数表示权重与缓存。将压缩后的权重参数全部存放在片内,克服了片外存储带宽限制的同时,降低了功耗,硬件加速部分功耗仅为6.13 W;并且优化了存储器的存储结构与数据的读取方式,根据不同层的卷积计算方式与并行度设计权重和输入数据在BRAM中的排列方式,进一步节约了内存,卷积运算中对输入图片数据进行复用减少了对内存的访问次数;提出了一种层内、层间协同配合的流水线结构,在卷积层内,相邻PW层间流水线展开,采用十二级流水线的设计方法,极大的提升了网络的实时性,在短暂延时后,能够实现每0.64 ms推断一张图片。通过实验分析与对比,本文的方法在一定程度上解决了将CNN网络部署在FPGA上时内存带宽不足和计算并行度低所带来的限制,同时还降低了功耗。
1 轻量级网络MobileNetV2及其量化处理
1.1 轻量级网络MobileNetV2
MobileNetV2由gogle团队于2018年提出,采用深度可分离卷积,即将一个标准的卷积层拆分为逐层卷积(DW,depthwise convolution)与逐点卷积(PW,pointwise convolution)操作。使得网络的参数量与计算量大为降低,但是却能保持较高的准确率,因此被广泛的应用于小容量嵌入式应用场景。MobileNetV2的网络结构如表1所示,其中t代表着缩放系数,c代表输出通道数,n代表重复次数,s代表着步长。
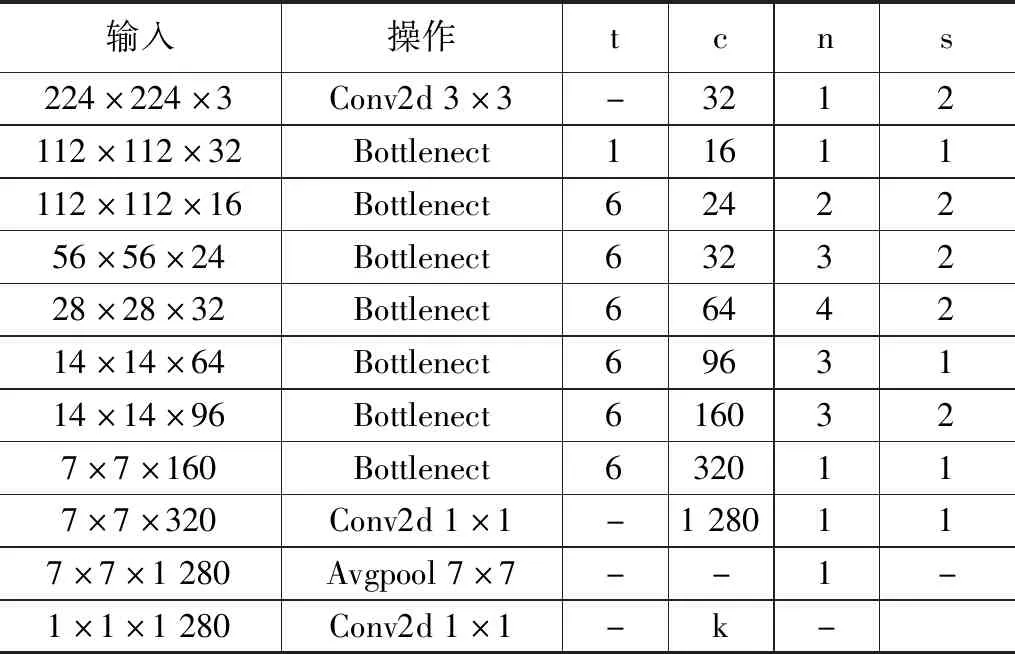
表1 MobileNetV2网络结构
与MobileNetV1[15]相比MobileNetV2参数更少,准确度却更高,改进的地方在于它采用了倒残差瓶颈模块(Inverted residual block)先用1×1 conv 将k维网络进行升维到tk维,后通过1×1 DW层进行特征的提取,最后由1×1 conv操作重新降低为k维。倒残差瓶颈模块输出部分借鉴了RseNet[16]的short-cut操作,当中间DW层进行下采样时(stride=2)时,直接输出,当中间DW层不进行下采样(stride=1)时,瓶颈模块输入与输出相加,具体操作如图1所示。
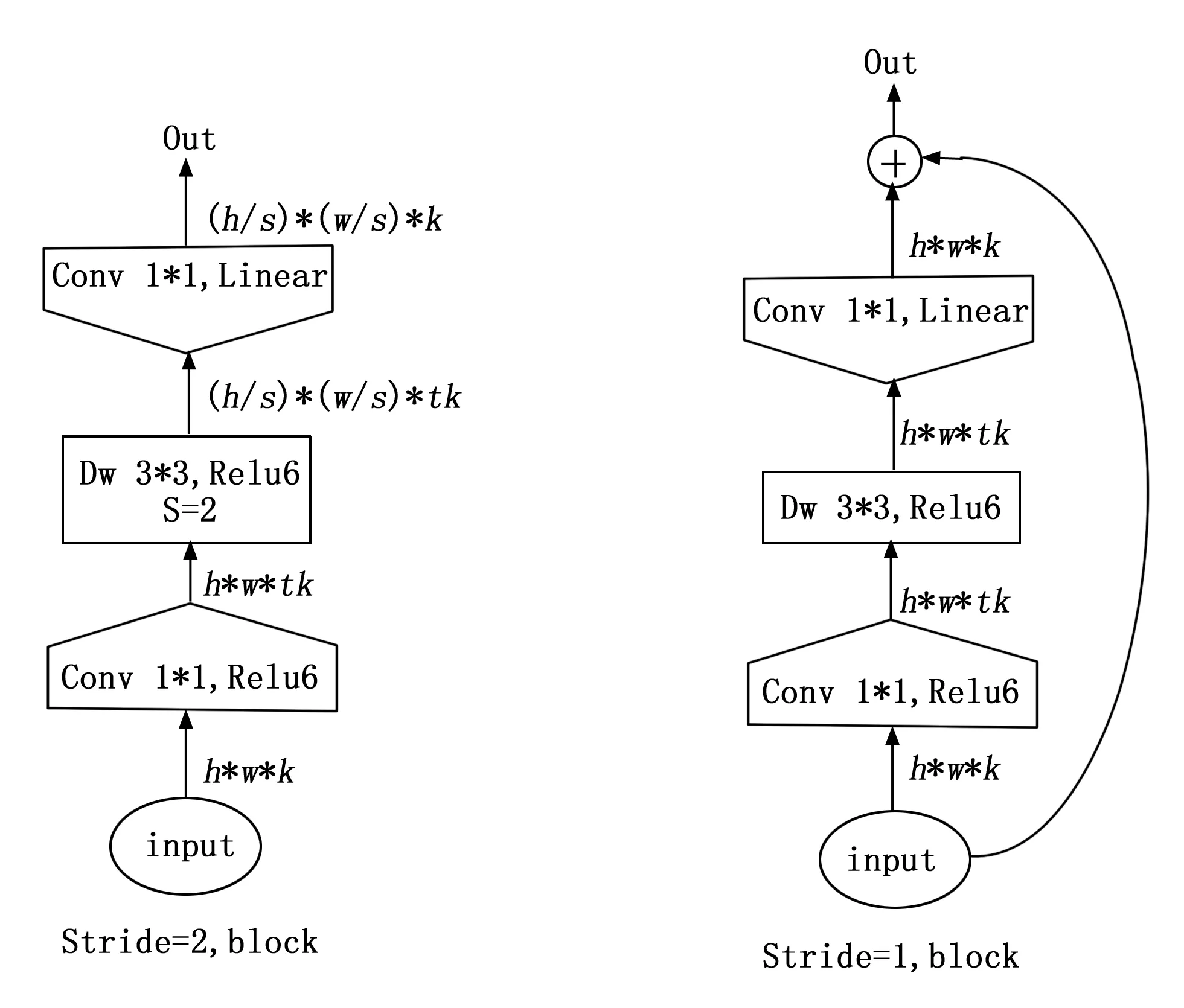
图1 倒残差瓶颈模块具体操作
1.2 网络的量化处理
通常PC端保存训练好的卷积神经网络模型参数为32位的浮点数。MobileNetV2网络的参数量为3.4 M,FPGA的片内BRAM资源十分的有限,如果网络的参数均采用32浮点数表示存入FPGA中,FPGA内存将严重不足。这就需要对网络模型进行量化处理,压缩模型参数,缓解FPGA内存不足的压力。量化方式有静态量化、动态量化、量化感知训练3种方式,前两种方法是针对训练好的模型进行量化,而量化感知训练则会对模型进行二次训练。小型的网络,如果采用前两种量化方式会带来较大的精度损失[17],而量化感知训练不仅可以压缩模型参数,且模型的精度损失还较小,与此同时相较于浮点数运算,FPGA更加擅长处理定点数运算。因此本文采用量化感知训练的方式,将32位浮点数参数用INT8型表示。
假设卷积的权重参数为w,偏置为b,输入为x,输出激活值为a,卷积运算可以表示为下式所示:
(1)
用Xfloat表示浮点实数,q表示量化后的定点数,S为量化的尺度因子,Z则表示0经过量化后对应的数值。则浮点数与定点数的转化公式如公式(2)与公式(3)所示:
Xfloat=S(q-Z)
(2)
(3)
将公式(1)中的w、b、x分别用量化后的定点数表示,同时偏置的量化尺度因子取为Sb=SwSx就得到了公式(4)。
(4)
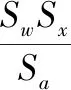
量化感知训练在对网络进行二次训练的过程中将式(2)加入到了它的前向传播的训练过程,卷积计算时将浮点数转化为定点数。计算完成后进行反量化操作,通过式(3)将定点数重新转化为浮点数。在网络训练的反向传播过程中则按浮点数的计算方式进行,以此来提高模型对量化效应的适应度,最终提高量化后模型的精度每一层的量化操作按照式(5)进行
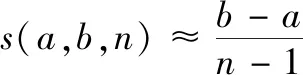
(5)
其中:r代表要量化的实数值,a,b是该实数的量化范围,即该层Tensor里的最小值与最大值,n则代表量化级数,若最终需量化为8位则n=28=256。
在PyTorch框架下对东北大学发布的热轧带钢表面缺陷数据集进行试验测试,输入图片尺寸为96×96×3,运用静态量化将模型参数压缩至INT8型后缺陷分类正确率下降到了73.33%,采用量化感知训练方式将模型参数压缩至INT8型的同时进行再次训练,在未采用按通道(per-channel)优化的情况下8轮EPOCH后,正确率可以达到93.89%,如图2所示。
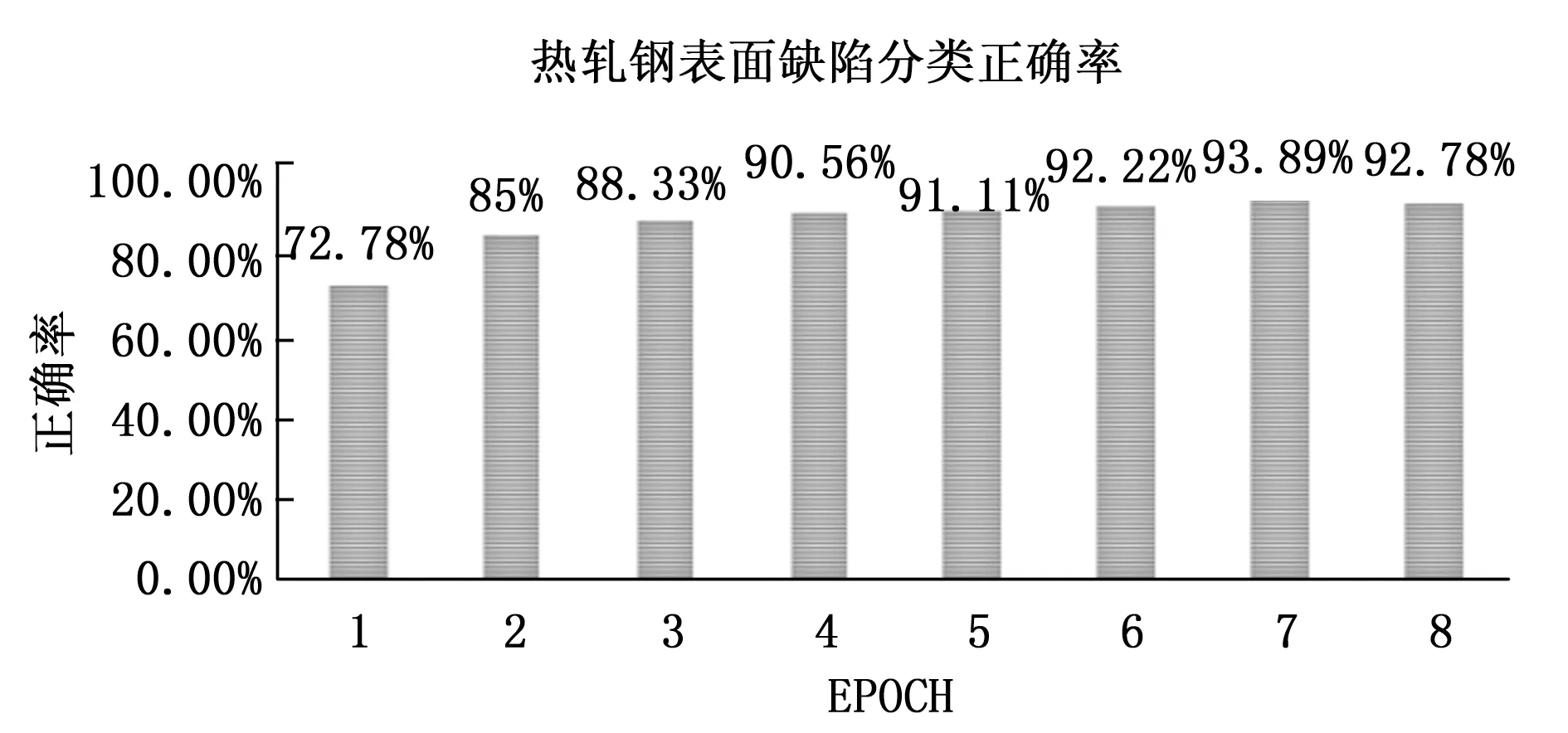
图2 热轧带钢表面缺陷分类正确率
未量化前浮点数模型的精度为96.10%,量化后精度损失为2.21%,满足精度要求。
2 MobileNetV2网络识别系统的硬件设计
2.1 系统整体结构
系统的整体架构如图3所示,由Host上位机、硬件加速模块(Accelerator)、显示模块(LCD)组成。其中网络的权重,经量化后根据DW、PW层的并行度以及数据读取规则进行有序排列,提前写入On-chip Memory中。上位机只负责通过PCIE总线传输输入图片数据到Input-buffer中。硬件加速部分在监测到图片数据已经加载完成后,从On-chip Memory读入权重,即开始前向推理加速。硬件加速模块对应着MobileNetV2网络结构进行部署,主要由Conv2d层、DW层、PW层、池化层(Pooling Layer)组成。最终分类结果显示在Virtex-7 FPGA挂载的LCD上。
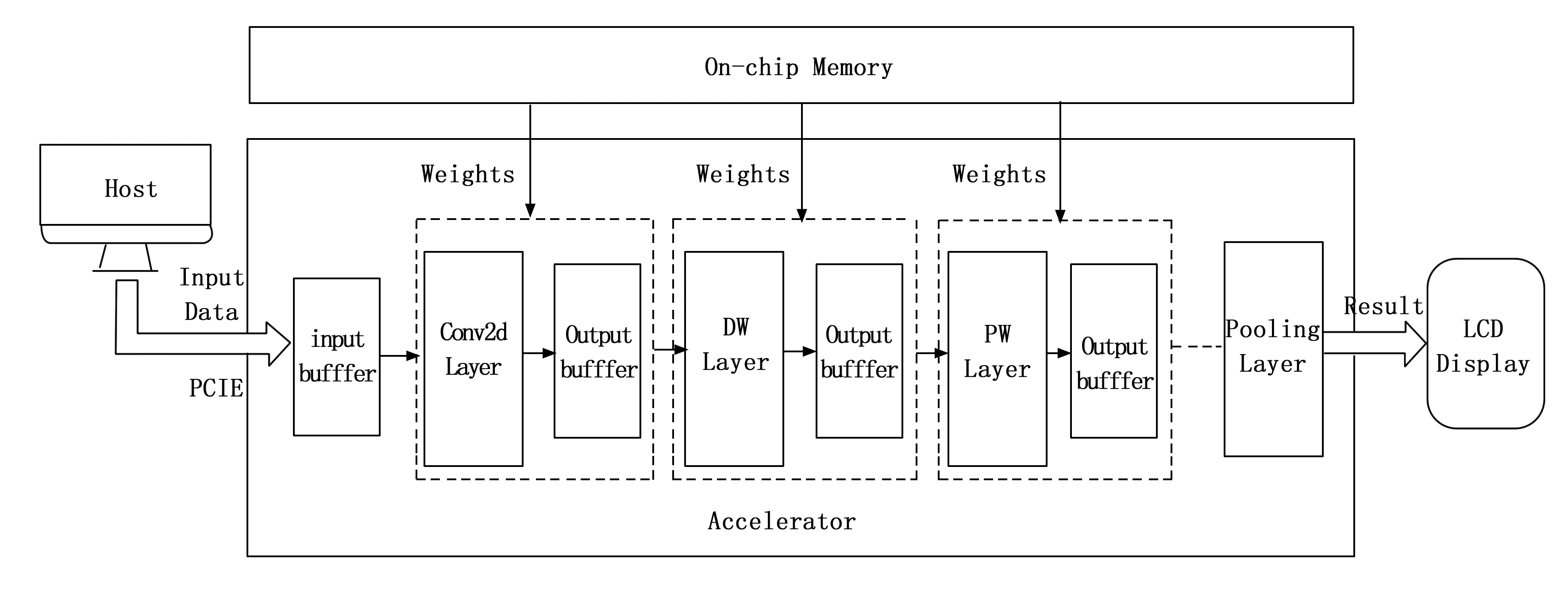
图3 MobileNetV2网络识别系统整体结构
2.2 存储器与数据读取的优化策略
针对片内资源短缺的问题,为了进一步的节约片内BRAM的存储资源,本文提出了一种存储器与数据读取的优化策略,优化了权重与缓存的存储结构以及数据的读取方式。
将一个最基本的卷积运算展开,要做到多通道并行,最简单的方法就是将每一路通道上的输入图片与权重数据,分别用一个BRAM存储。这样做程序实现简单,但由于MobileNetV2网络输入通道数量最多可达1 280,这样的实现方法会造成片内BRAM资源的严重浪费,本文根据FPGA片内BRAM资源的构成特点,采用一个地址拼接多个通道数据的方式将卷积计算合理的在输入、输出通道进行展开,根据卷积计算的特点,上一层卷积的输出通道并行度需与下一层输入通道的并行度保持一致,且该数值应为MobileNetV2网络每层通道数的公因数,18 K BRAM空间按512×36进行配置则每层网络中权重消耗的18 K BRAM资源与输入通道、输出通道并行度的关系如式(6)所示:
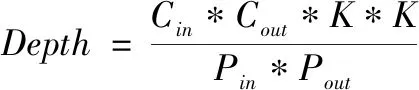
(6)
其中:Dataw表示权重数据在BRAM中每个地址的数据位宽,Pin、Pout则表示卷积运算输入通道与输出通道设置的并行度,nw代表量化的位宽,由于采用的是8位量化所以这里的nw=8。Depth表示BRAM的数据深度,Cin、Cout为本层网络的输入与输出通道数,卷积核的尺寸大小为K*K。最终可由Depth与Dataw的数值大小确定本层网络消耗的18 K BRAM资源数。结合Virtex-7 FPGA片内资源情况通过计算可知当每层的Pin、Pout都取4时,在兼顾网络推理速度时能够留有一定的存储裕度,为了进一步提升处理速度,在MobileNetV2网络计算密集的层增大了输入与输出通道的并行度。每层网络权重消耗的BRAM资源数值情况与并行度如表2所示。
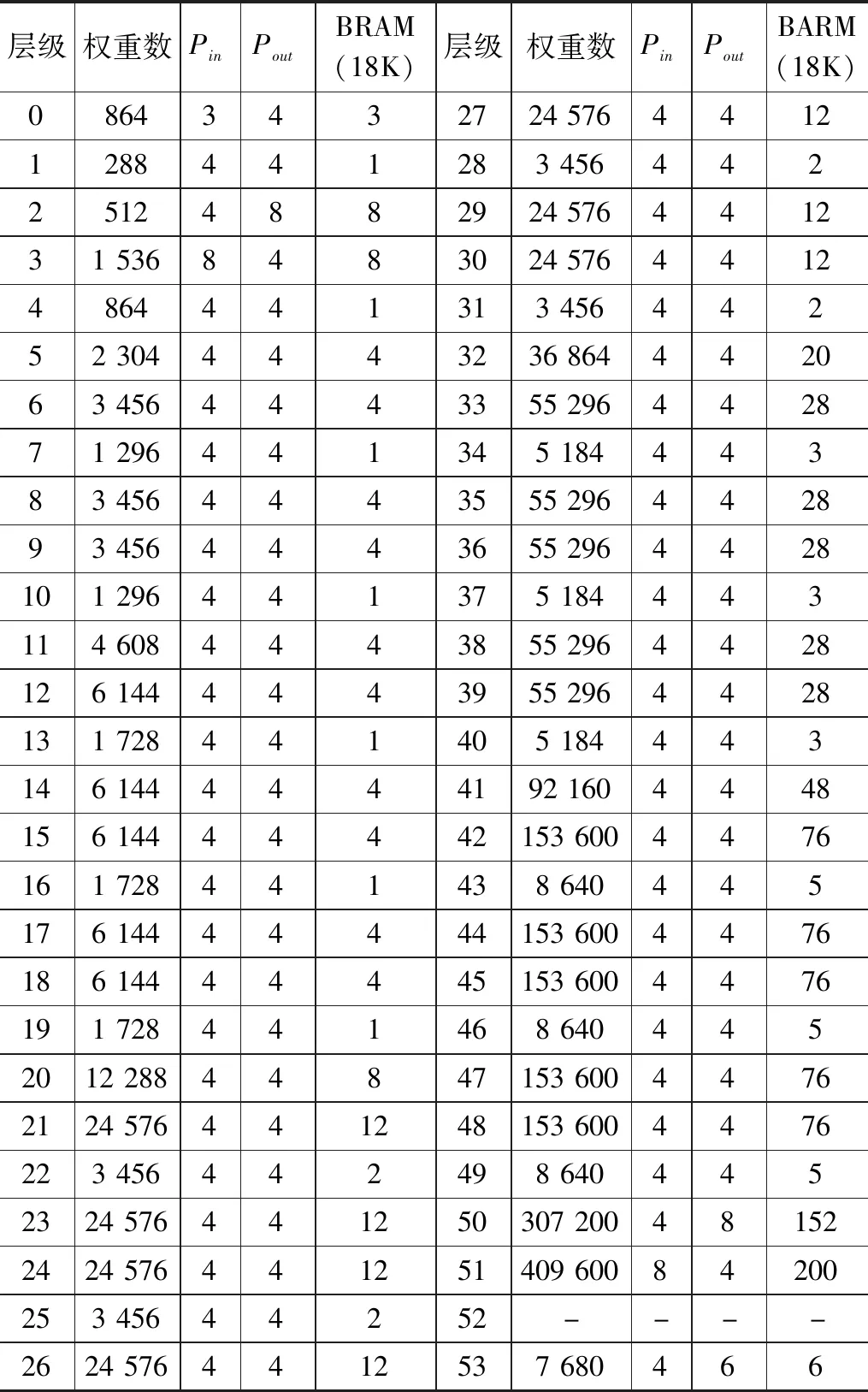
表2 MobileNetV2每层网络存储资源消耗情况
以PW层为例,数据的存储结构与读取方式如图4所示。假设输入图片的尺寸为Map(k×k×n),权重则为Weight(n×m)。在PW层设计的并行度为16,即在一个时钟周期完成16组的1×1的逐点卷积运算。需要在一个周期内读入4个通道的输入数据,ram里的每个地址存入由4个通道拼接成的32位宽的数据,同理Weight-rom中的每个地址拼接了4个通道的各4个权重,即一个地址存入128位宽的数据。
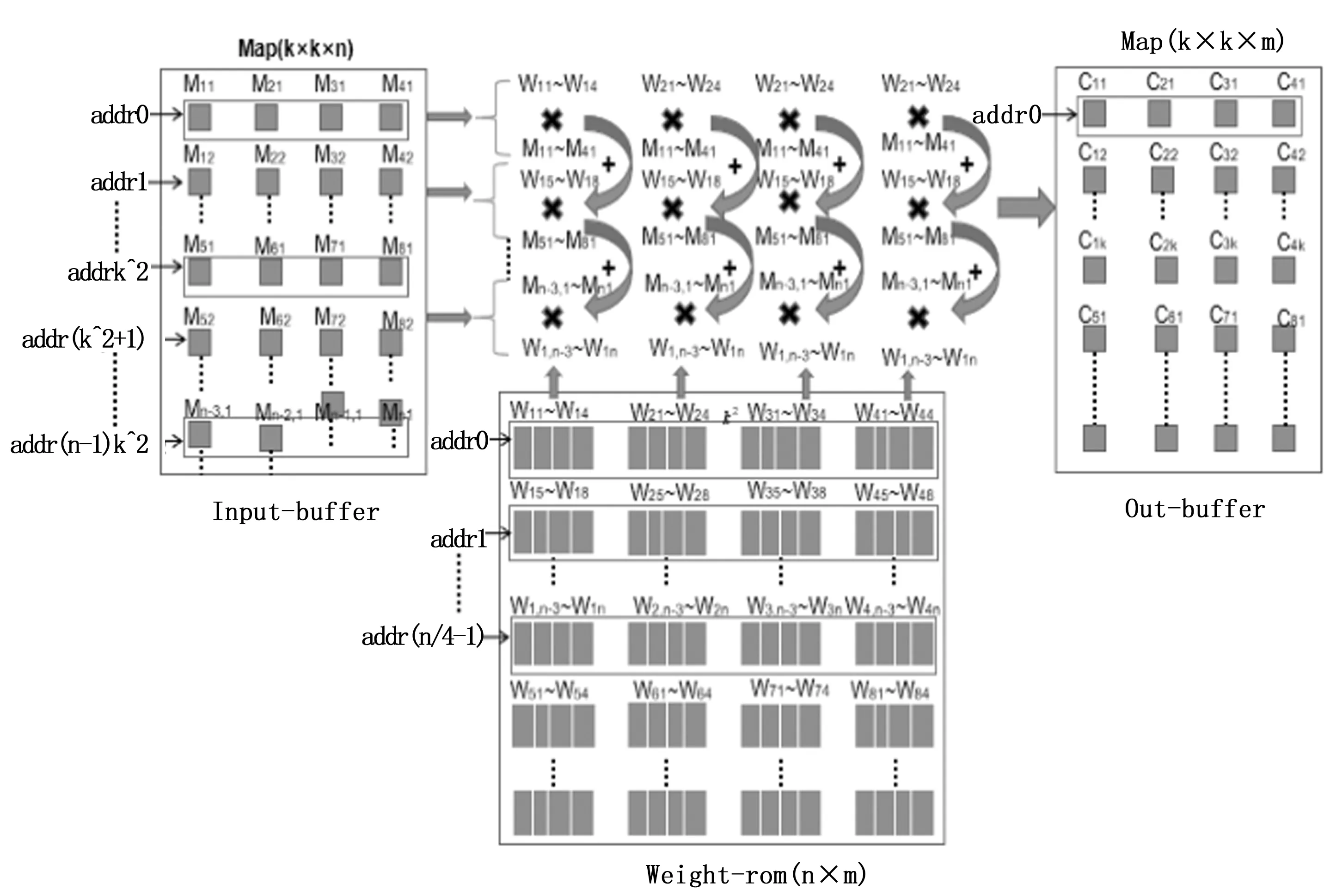
图4 数据的存储结构与读取方式
数据的读取方式按输入图片尺寸大小进行地址跳转读取,如输入图片的尺寸为(k×k×n)则每时钟周期按addr0、addrk^2、…addr(n-1)k^2进行跳转读取。频繁的数据访问会带来额外的功耗,因此在卷积计算过程中应加强数据的复用来减少访问的次数,降低功耗。可采用多个卷积核共享输入图片数据的方法减少对内存的访问次数[10],具体实现如下:在第一个CLK读入层间缓存中的M11~M14,同时读入4个通道的各4个权重值,W11~W14、W21~W24、W31~W34、W41~W44进行相乘后各自累加,n个通道累加完毕后,同时输出4个输出通道的同一位置的数,拼接后存入一个地址。
2.3 量化模块的硬件实现
量化模块依据上文公式(4)进行实现,卷积计算累加的结果,需要乘上对应的量化乘数,量化乘数为浮点数的表示形式,要变成定点数的表示形式则需先进行放大,找出误差合适的M0乘数。使得乘法在定点数上进行,乘法结果通过右移位进行缩小还原,最终重新截成int8型数据输出,整个过程流水线排开,具体实现过程如图5所示。
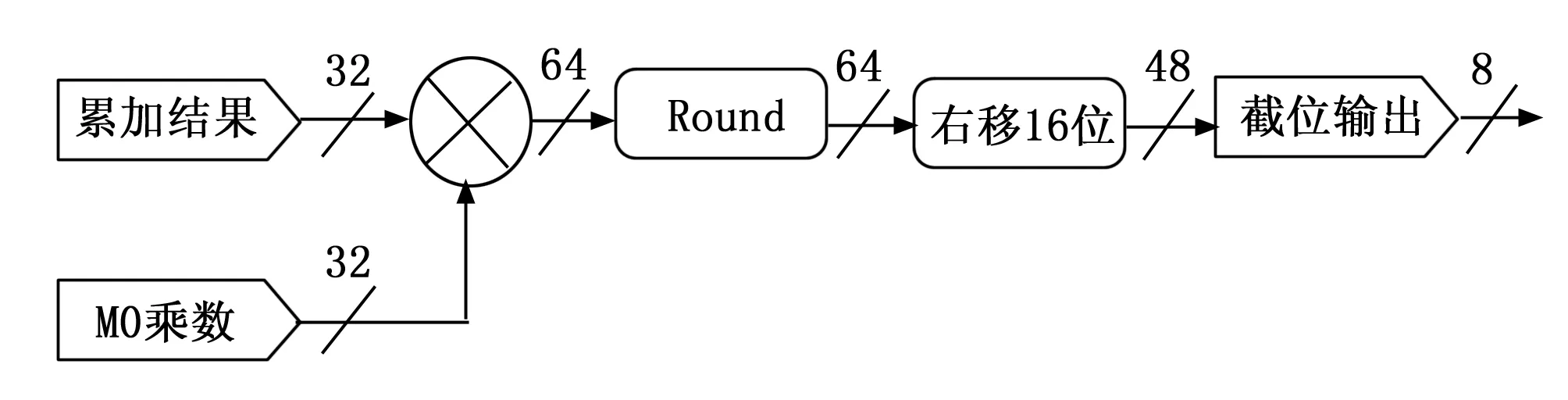
图5 量化模块的硬件结构
2.4 DW层设计与实现
DW卷积不同于一般的常规卷积,它的一个卷积核只负责一个通道,输入图片的通道数经过DW层后,通道数不变,在DW层并行度上,按4输入通道与卷积核内并行相结合的策略,DW层的卷积过程如图6所示。
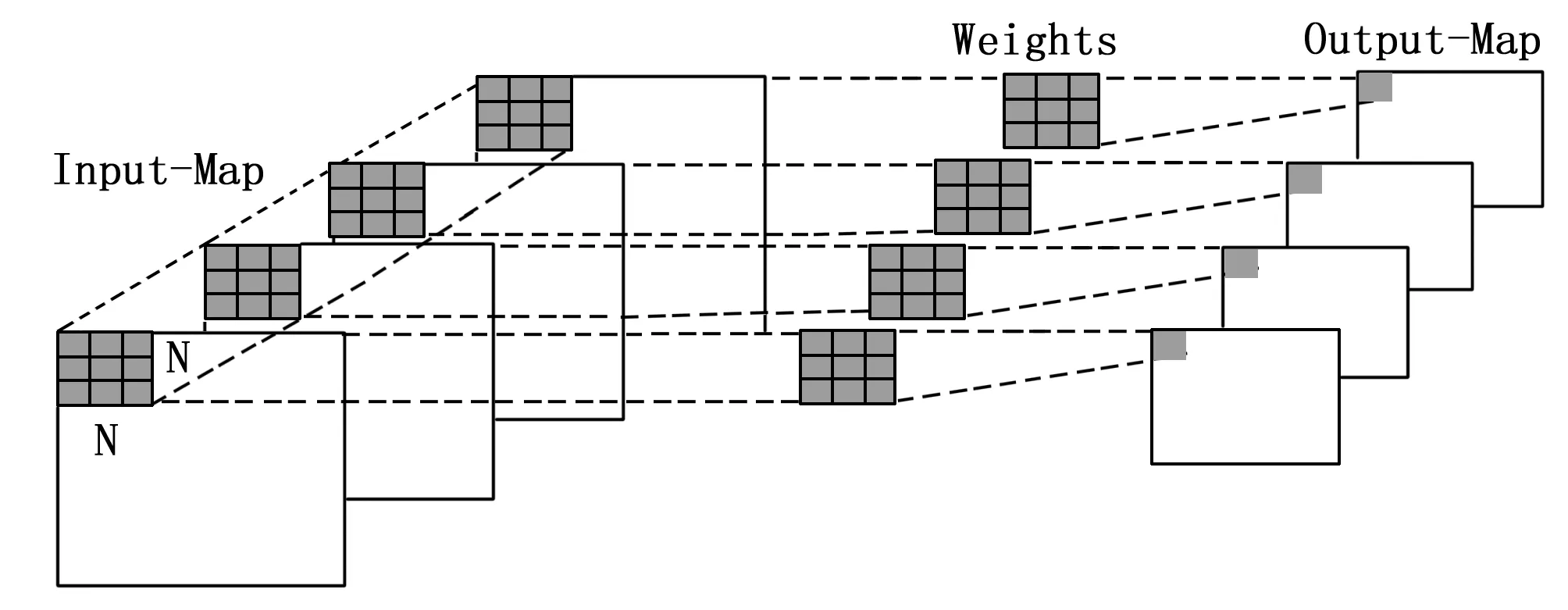
图6 DW层并行结构
DW层硬件架构如图7所示,在并行计算上,将卷积计算从输入通道展开。每个输入通道将3×3的窗口数据分别送入每组由9个乘法器组成的乘法阵列中,在下一个周期通过加法树将乘结果累加起来,存入32位的Sum寄存器中,经过量化单元量化及Relu后,截成8位的整型数据。最后对每个通道的卷积结果进行拼接,存入BRAM的地址中。
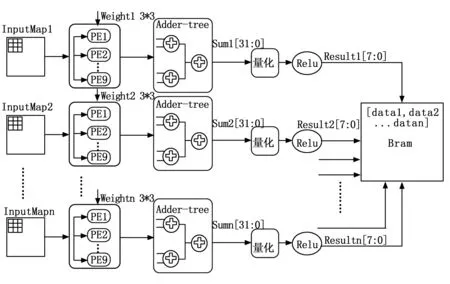
图7 DW层的硬件架构
2.5 PW层设计与实现
PW为点卷积操作,用于对上一层的输出map在深度方向进行加权组合。在PW层采取了4输入通道与4输出通道相结合的并行方式。在一个CLK同时读取4输入通道同一个位置的数据与4组通道上的权重进行计算,依次按输入通道方向读取输入Map数据,经过n个CLK后遍历整个输入通道,输出4个输出通道同一位置的数据。PW层的并行设计如图8所示。
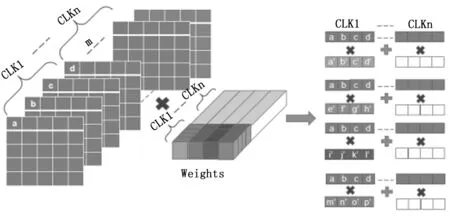
图8 PW层并行结构
每个时钟周期输入由4个输入通道拼接而成的32位数据进入乘累加阵列,当前4通道累加结果存入Sum1_1寄存器中与先前通道的累加结果Sum1相加,1×1的点卷积将输入通道遍历后,输出最终的累加结果给量化模块,Relu操作后输出8位整型数,最后将4个输出通道结果拼接成32位数存入Bram中,PW层的硬件实现如图9所示。
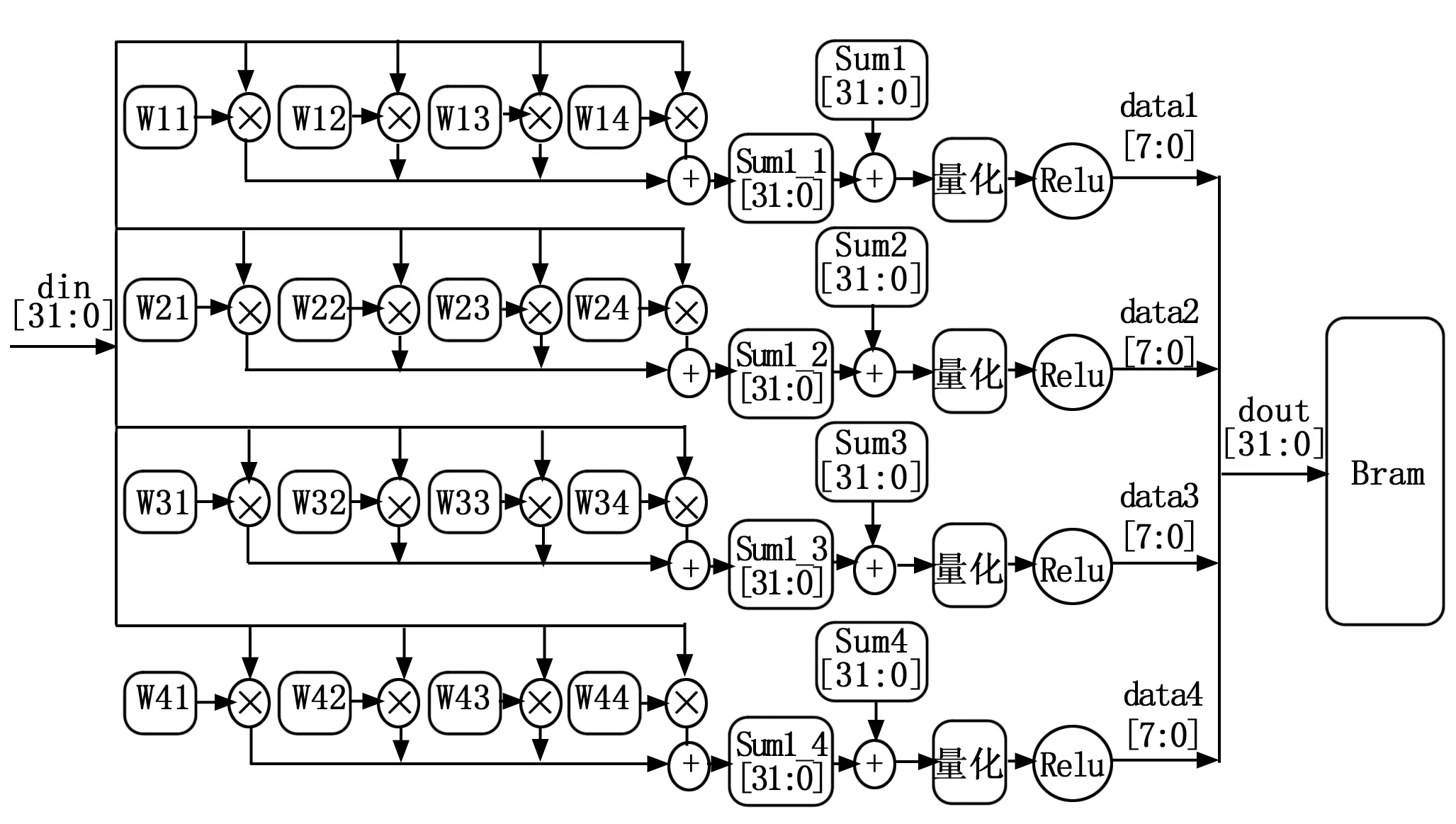
图9 PW层的硬件架构
2.6 层内层间协同配合的流水线结构
构成MobileNetV2网络的卷积层类型为标准卷积层、DW卷积层、PW卷积层,其中标准卷积层的计算量可由公式(7)得到,DW卷积层、PW卷积层的计算量可由公式(8)、(9)计算得出。
Osc=h*w*Cin*Cout*K*K
(7)
Odw=h*w*Cin*K*K
(8)
Opw=h*w*Cin*Cout
(9)
h和w分别为输出特征图的行数与列数,Cin和Cout为输入与输出的通道数,K为卷积核的尺寸。
当输入为96*96*3时可得MobileNetV2网络各部分的计算量如表3所示。PW层的计算量占到了总网络计算量的89.79%,因此在相邻两个PW层间设计层间流水计算结构可以大幅度提升网络的实时性。
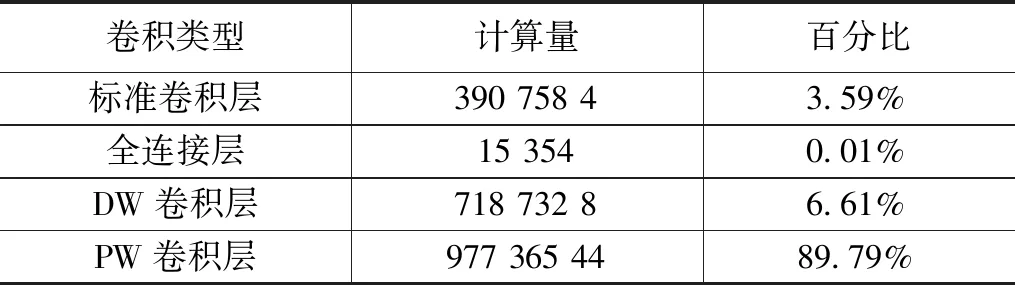
表3 MobileNetV2网络各部分计算量
本文在MobileNetV2网络相邻的PW层内及层间以流水线的方式运行计算,流水结构如图10所示。数据从PW1层输入直到PW2层结果输出,一共采用了十二级流水线的设计方式。
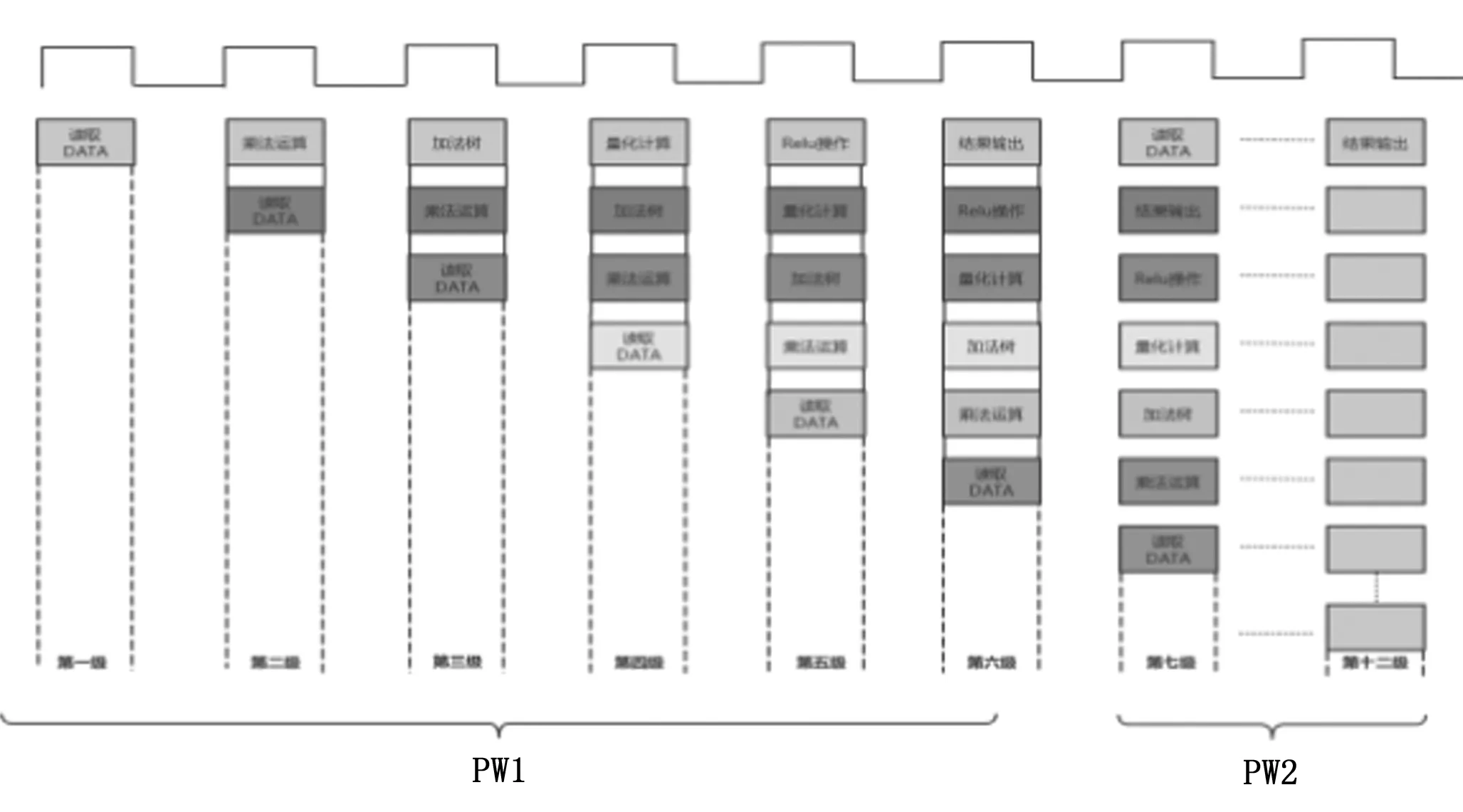
图10 十二级流水线
在相邻的PW层间流水线计算结构设计如图11所示,点卷积操作只需单个点的像素就能进行卷积操作,但是完整输出一次操作结果需要遍历整个输入通道。PW1的权重为(m,n)的二维数组形式,这里m为输出通道数,n为输入通道数。PW层并行度设置为k=4,则PW1层在一个周期读取前一层输出的4张图片的4个数据后,同时读取4组n输入通道上的4个数,即4×4个权重数据,进入PW1层计算。在下一个周期PW1模块读取下一组输入数据后,权重则按输入通道的方向读取下一组4×4个权重数据,以此类推遍历整个输入通道完成一组运算。PW1层的输出图片尺寸为(y,y,m),当遍历完整个输出通道,m张图片的首位数据全部写入缓存时,PW1层发给PW2一个start信号,PW2开始读入数据进行运算,PW2层的权重读取顺序与PW1层一致。点卷积运算不改变输入图片的尺寸大小,由于PW2的输入、输出通道数的乘积大于PW1,即x×m≥m×n,所以PW2遍历完整个输入、输出通道的时间要大于等于PW1。PW2只需延迟等待PW1层写入缓存的m张图片的首位数据后启动,PW1的写和PW2读就不会发生冲突,两层就能以流水的计算方式同时运行计算。
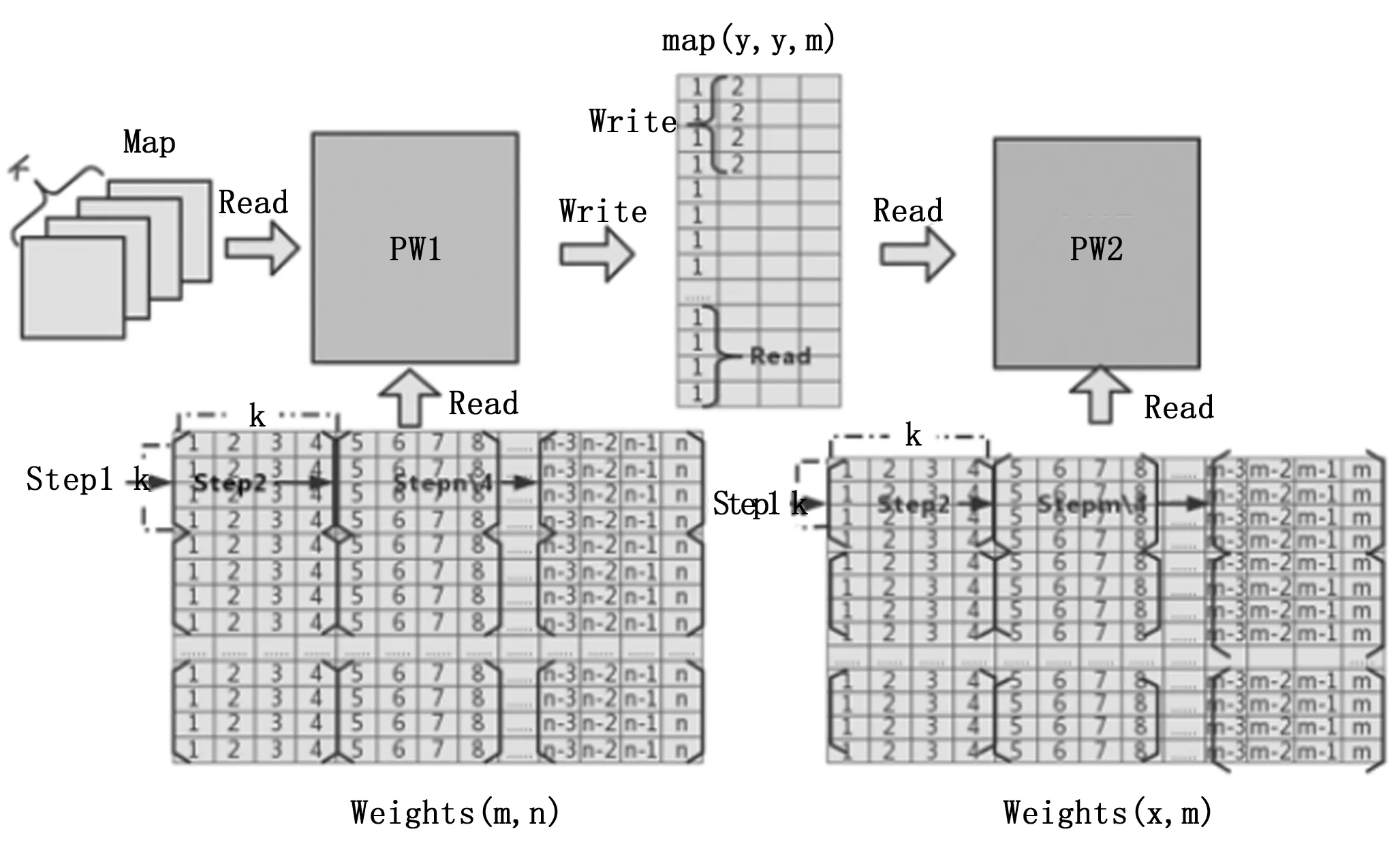
图11 层间流水计算结构
3 结果分析
3.1 实验环境
本文采用Xilinx Virtex-7 VC707开发板作为实验平台,该开发板芯片具有485 760个逻辑单元、2 800 DSP、37.08 MB的Block RAM,所用开发工具为Vivado 2018.3,采用Verilog语言进行编程,PC端网络的训练与量化采用了基于Python的PyTorch框架,CPU型号为Inter Core i5 -6200U,主频为2.3 GHz。下面讨论实现的效果及性能比较。
3.2 资源与能耗
主要资源消耗情况如表4所示,其中LUT资源表示查找表,BRAM代表片内存储资源,FF为触发器资源,DSP为计算单元。LUT、FF、DSP资源主要用在了卷积功能模块以及数据流的实现上,消耗量均不大。由于本文为了减少片外DDR的访问降低系统功耗,将所有的权重及层间缓存都布置在了片内BRAM中,所以片内BRAM资源消耗较大。
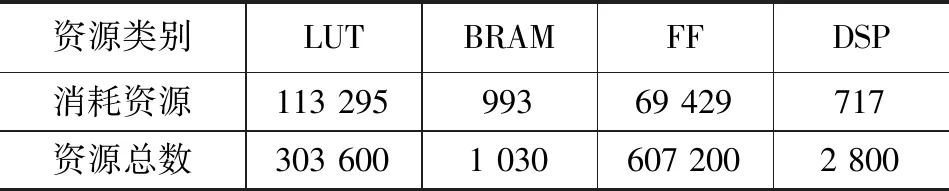
表4 资源占用情况
整个系统的能耗如图12所示,在200 MHz时钟下整体功耗为8.24 W,扣除数据传输接口PCIE功耗2.108 W,整个硬件加速部分的功耗仅为6.13 W。
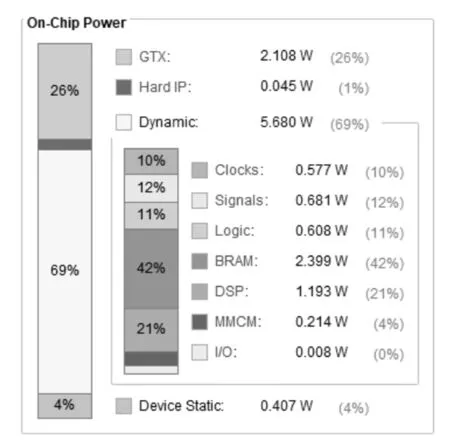
图12 系统功耗
表5列出了本文实现与CPU、GPU平台性能的对比。200 MHz时钟下本文的硬件实处理单张图片仅耗时0.64 ms,能耗比为27.74 GOP/s/W 是CPU平台的92倍,GPU平台的25倍。可见将CNN部署在FPGA上无论从推理时间还是功耗上都具有极大的优势。
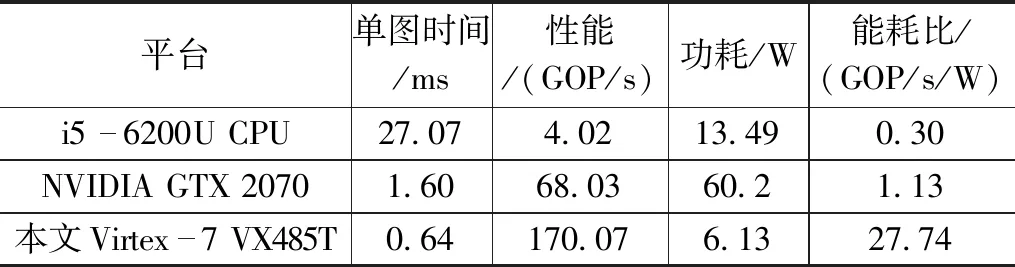
表5 不同平台性能对比
表6列出了在不同的FPGA平台实现CNN的性能对比,可以看出本文较文献[14]、[19]和文献[20]在计算性能上存在一定的优势,虽然计算性能上较文献[18]还有一定差距,但是在功耗上优势明显,能效比(Gop/s/W)较高。在追求高计算性能的同时能够兼顾功耗,达到计算性能与功耗两者的平衡,更加适用于实际的应用场景。
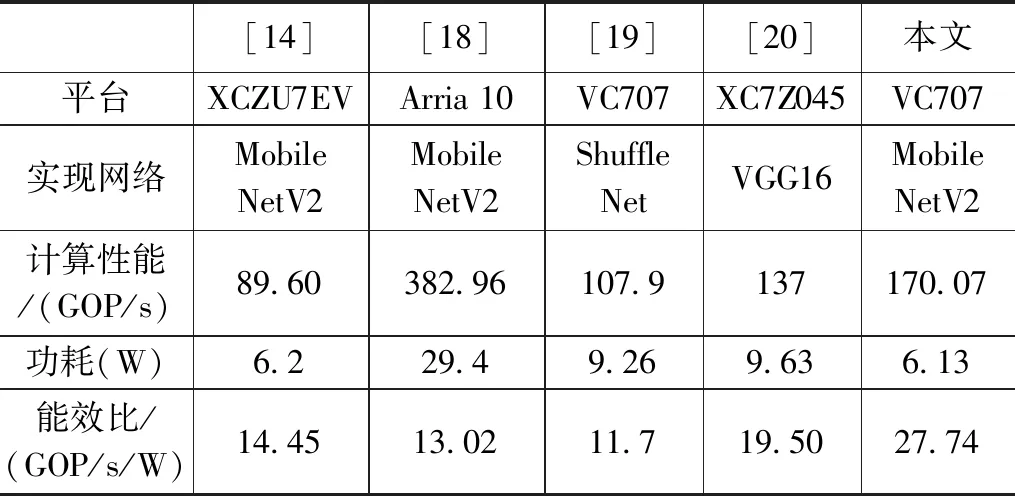
表6 不同FPGA实现性能对比
4 结束语
本文提出的基于FPGA加速的低功耗的MobileNetV2网络识别系统,将权重和缓存均放入片内存储,克服了片外存储带来的带宽限制与额外的功耗,小型网络量化会带来较大的精度损失,因此采用量化感知训练的方式进行二次训练提高网络的精度。为了进一步节约片内存储资源,优化了数据存储结构,复用了输入特征图。在相邻的PW卷积层内与层间以流水线的方式展开,极大的提升了网络的实时性。
本文设计的MobileNetV2网络虽然将权重和层间缓存均放入片内存储,在一定程度上克服了片外存储带来的带宽限制,但是受限于片内BRAM资源,每层的并行度并不能设计的足够高,如何在有限的片内BRAM资源下,进一步提高网络的并行度是需要在未来的研究中考虑的问题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电脑报(2021年11期)2021-07-01 08:26:31
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
船电技术(2017年1期)2017-10-13 04:23:24
个人电脑(2016年12期)2017-02-13 15:24:40
电子技术应用(2016年3期)2016-12-03 07:39:22
电子制作(2016年19期)2016-08-24 07:49:54
电子世界(2015年22期)2015-12-29 02:49:44
电源技术(2015年11期)2015-08-22 08:51:02
